您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
kubernetes运维之使用elk Stack收集k8s平台日志
目录:
一、收集哪些日志
• k8s系统的组件日志 比如kubectl get cs下面的组件
master节点上的controller-manager,scheduler,apiserver
node节点上的kubelet,kube-proxy
• k8s Cluster里面部署的应用程序日志
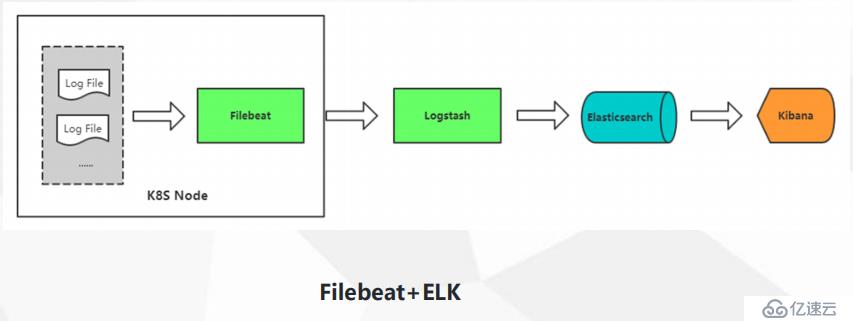
这里就形成一个数据流,首选呢就是Beats,后面是Logstach,后面是ES,后面是kibana,所以这个技术栈是非常完善的。而beats系列的组件也很多,比如对网络数据的采集,对日志文件的采集,对windos事件的采集,运行时间的采集,而elk这个栈呢,不仅仅可以采集数据日志,还能采集性能资源的指标,比如CPU,内存,网络,这里呢主要使用Filebeat收集日志文件。监控呢就找专业的去做,比如prometheus。
话说回来,容器的日志怎么收集?
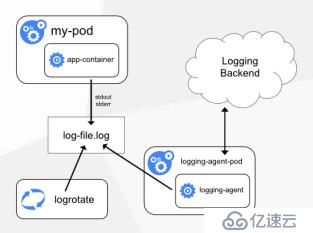
方案一:Node上部署一个日志收集程序
• DaemonSet方式部署日志收集程序
• 对本节点/var/log和 /var/lib/docker/containers/
两个目录下的日志进行采集
• Pod中容器日志目录挂载到宿主机统一目录上
也就是my-pod是容器,然后标准输入输出到控制台了,时间上这里是被docker接管了,落地到一个具体的文件中了,docker会接管标准输出与标准错误输出,然后写到一个日志里,这里会起一个日志采集的agent,去采集这个日志,而这个张图,大概意思就是在你每个的node上部署一个日志采集器,然后采集pod日志,标准输入输出的目录,默认是在 /var/lib/docker/containers/ 下面,这个下面是运行当前的容器的读写层,里面就包含了一个日志,一般就是挂载到分布式存储上,要是挂载到宿主机的目录,也不是很太方便,还要去区别所有的容器。要是使用分布式存储,比如器一个pod,直接让存储专门存储日志这个卷,
挂载到容器中的启动容器中,每起一个都挂这个卷,最终都会落到上面去,这样会好一点。
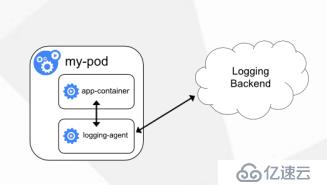
方案二:Pod中附加专用日志收集的容器
• 每个运行应用程序的Pod中增加一个日志
收集容器,使用emtyDir共享日志目录让
日志收集程序读取到。
第二种呢就是一种sidecar的模式,就是在你sidecar模式中再增加一个专门去处理那就想要的事情的容器,这就称为一个旁路,也就是当前你业务旁边,给你增加一个容器,处理你业务的日志的,也就是使用emtyDir让容器A写日志目录,给共享到这个目录里,也就是共享目录,也就是在宿主机的目录里,然后容器B读取也是挂载这个数据卷,它也能自然读取当前数据卷内的内容,所以这种情况呢就附加个Pod就能获取到日志了。
方案三:应用程序直接推送日志
• 超出Kubernetes范围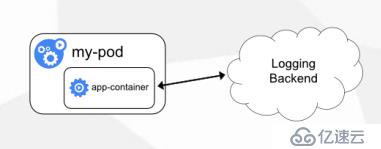
这个小公司会有些,不过也不多,就是应用程序在代码里去修改,直接推送到你远程的存储上,不再输出到控制台,本地文件了,直接推,这个就不再k8s范围之内了,这种方案用的有不多,用的最多的就是前两种
这两种方案有什么优缺点?
像方案一就是需要在每台node节点上去部署一个日志采集的agent,资源消耗少,一般不需要应用程序的介入,但是它需要通过应用程序写到标准输出和标准错误输出,比如tomcat,日志里面都是很多行,需要合并成一行才能进行采集,需要转换成json格式,json在docker方面已经多行分开了,所以不能使用多行匹配了,所以很尴尬。
像方案二就是在pod中附加专用日志收集的容器,附加到每个应用里面,每个pod再加一个容器,就加一个镜像,这种方式低耦合,缺点呢,显而易见,你部署一个应用,加一个采集器,部署又一个又加一个采集器,就是你要启动一套项目,需要加一个容器,就是需要资源的消耗了,并增加运维的维护成本,不过运维维护成本也还好,主要增加资源的消耗比较大一点。
第三种方案,就是让开发去改就行了。
我们使用的是方案二的,附加一个,这个还是比较好实现的
目前呢我们使用fileBeat去做日志的采集,早期呢都是使用logstach去采集,logstach采集呢占用资源也比较大,本身呢是java写的,filebeat是Go写的,资源占用比较小,java它采集的量一大了,之后消耗杠杠的,所以后面官方将logstach采集功能剥离出来,使用GO重写了一个filebeat,所有现在用建议使用fileBeat。
这个fek里面是filebeat,就是部署filebeat,这里面启动用对k8s的支持,目前这个适合比较小的数据量,自己写的yaml,如果你的数据量达到20-30g以上,这个单机的es肯定是很难满足的,如果你的日志量比较大,不建议你把elk部署到k8s中,建议把你的logstack,es,存储部署到k8s之外,特别是es,建议部署到集群之外,物理机去组件集群,kibana可以部署在k8s 中,但是es是有状态的部署
为了避免以下yaml出错,建议拉取我代码仓库的代码
拉取地址:git clone git@gitee.com:zhaocheng172/elk.git
拉代码的时候请把你的公钥给我,不然拉不下来
[root@k8s-master elk]# ls
fek k8s-logs.yaml nginx-deployment.yaml tomcat-deployment.yaml
[root@k8s-master elk]# ls
fek k8s-logs.yaml nginx-deployment.yaml tomcat-deployment.yaml
[root@k8s-master elk]# cd fek/
[root@k8s-master fek]# ls
elasticsearch.yaml filebeat-kubernetes.yaml kibana.yaml[root@k8s-master fek]# cat filebeat-kubernetes.yaml
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: kube-system
labels:
k8s-app: filebeat
data:
filebeat.yml: |-
filebeat.config:
inputs:
path: ${path.config}/inputs.d/*.yml
reload.enabled: false
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
output.elasticsearch:
hosts: ['${ELASTICSEARCH_HOST:elasticsearch}:${ELASTICSEARCH_PORT:9200}']
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-inputs
namespace: kube-system
labels:
k8s-app: filebeat
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
spec:
template:
metadata:
labels:
k8s-app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: elastic/filebeat:7.3.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch
- name: ELASTICSEARCH_PORT
value: "9200"
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: inputs
mountPath: /usr/share/filebeat/inputs.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: inputs
configMap:
defaultMode: 0600
name: filebeat-inputs
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
k8s-app: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
k8s-app: filebeat
---[root@k8s-master fek]# cat elasticsearch.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: kube-system
labels:
k8s-app: elasticsearch
spec:
serviceName: elasticsearch
selector:
matchLabels:
k8s-app: elasticsearch
template:
metadata:
labels:
k8s-app: elasticsearch
spec:
containers:
- image: elasticsearch:7.3.1
name: elasticsearch
resources:
limits:
cpu: 1
memory: 2Gi
requests:
cpu: 0.5
memory: 500Mi
env:
- name: "discovery.type"
value: "single-node"
- name: ES_JAVA_OPTS
value: "-Xms512m -Xmx2g"
ports:
- containerPort: 9200
name: db
protocol: TCP
volumeMounts:
- name: elasticsearch-data
mountPath: /usr/share/elasticsearch/data
volumeClaimTemplates:
- metadata:
name: elasticsearch-data
spec:
storageClassName: "managed-nfs-storage"
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 20Gi
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: kube-system
spec:
clusterIP: None
ports:
- port: 9200
protocol: TCP
targetPort: db
selector:
k8s-app: elasticsearch
[root@k8s-master fek]# cat kibana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-system
labels:
k8s-app: kibana
spec:
replicas: 1
selector:
matchLabels:
k8s-app: kibana
template:
metadata:
labels:
k8s-app: kibana
spec:
containers:
- name: kibana
image: kibana:7.3.1
resources:
limits:
cpu: 1
memory: 500Mi
requests:
cpu: 0.5
memory: 200Mi
env:
- name: ELASTICSEARCH_HOSTS
value: http://elasticsearch:9200
ports:
- containerPort: 5601
name: ui
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-system
spec:
ports:
- port: 5601
protocol: TCP
targetPort: ui
selector:
k8s-app: kibana
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: kube-system
spec:
rules:
- host: kibana.ctnrs.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601 [root@k8s-master fek]# kubectl create -f .
[root@k8s-master fek]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
alertmanager-5d75d5688f-xw2qg 2/2 Running 0 6h42m
coredns-bccdc95cf-kqxwv 1/1 Running 2 6d6h
coredns-bccdc95cf-nwkbp 1/1 Running 2 6d6h
elasticsearch-0 1/1 Running 0 7m15s
etcd-k8s-master 1/1 Running 1 6d6h
filebeat-8s9cx 1/1 Running 0 7m14s
filebeat-xgdj7 1/1 Running 0 7m14s
grafana-0 1/1 Running 0 21h
kibana-b7d98644-cmg9k 1/1 Running 0 7m15s
kube-apiserver-k8s-master 1/1 Running 1 6d6h
kube-controller-manager-k8s-master 1/1 Running 2 6d6h
kube-flannel-ds-amd64-dc5z9 1/1 Running 1 6d6h
kube-flannel-ds-amd64-jm2jz 1/1 Running 1 6d6h
kube-flannel-ds-amd64-z6tt2 1/1 Running 1 6d6h
kube-proxy-9ltx7 1/1 Running 2 6d6h
kube-proxy-lnzrj 1/1 Running 1 6d6h
kube-proxy-v7dqm 1/1 Running 1 6d6h
kube-scheduler-k8s-master 1/1 Running 2 6d6h
kube-state-metrics-6474469878-lkphv 2/2 Running 0 8h
prometheus-0 2/2 Running 0 5h7m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/elasticsearch ClusterIP None <none> 9200/TCP 46m
service/kibana ClusterIP 10.1.185.95 <none> 5601/TCP 46m
service/kube-dns ClusterIP 10.1.0.10 <none> 53/UDP,53/TCP,9153/TCP 6d7h
NAME HOSTS ADDRESS PORTS AGE
ingress.extensions/kibana kibana.ctnrs.com 80 46m然后我们去访问一下,这里我是做的测试所以把它的域名写到了本地的hosts文件进行解析
这里选择Explore导入自己的数据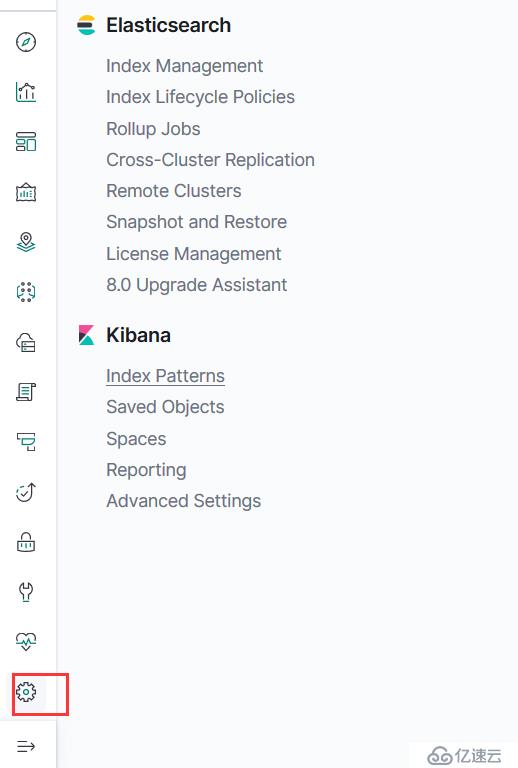
现在数据已经收集到了,看一下它的索引有没有写入成功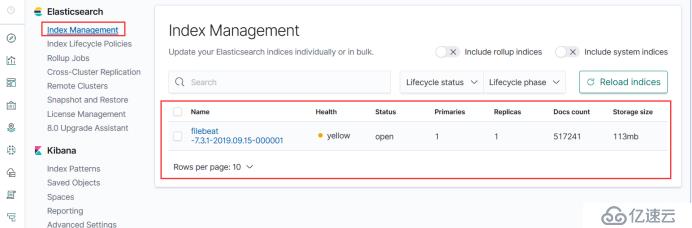
也就是创建的三个yaml文件之后,默认的创建filebeat索引,这就像数据库,索引呢查询到ES里面的数据库,索引匹配呢就是让kibana拿这个索引匹配查看里面的数据。
创建索引的匹配filebeat,这里会帮你去匹配所以有filebeat开头的,因为它是按每天去存储这个索引的,也就是每一天都有一个命名,所以打个星就能匹配所有,你访问这个模式就能查看以这个开头的数据这里还要点一下保存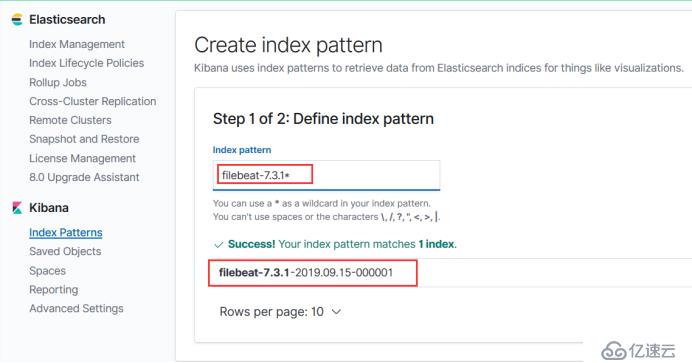
这里添加一个过滤时间的字段,一般使用这个时间戳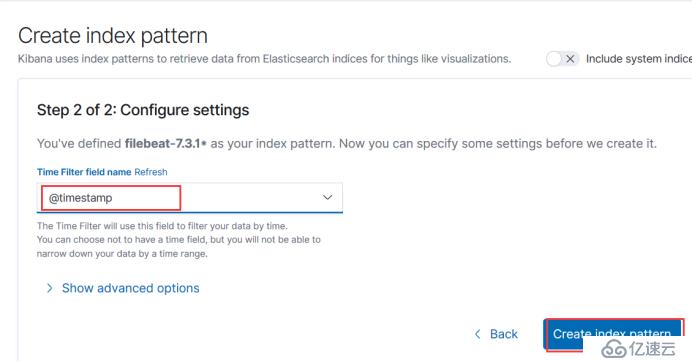
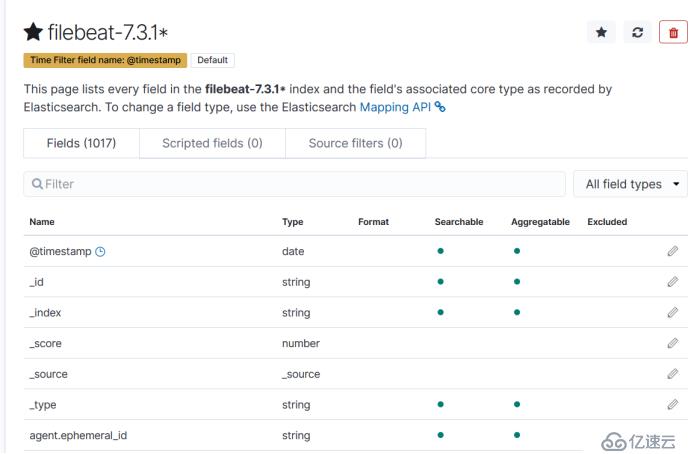
然后点最上面的按钮就能看到数据了。这里默认的就是使用这个filebeat,要是多个的话,这里会有一个选择框,下面的输出是所有控制台输出的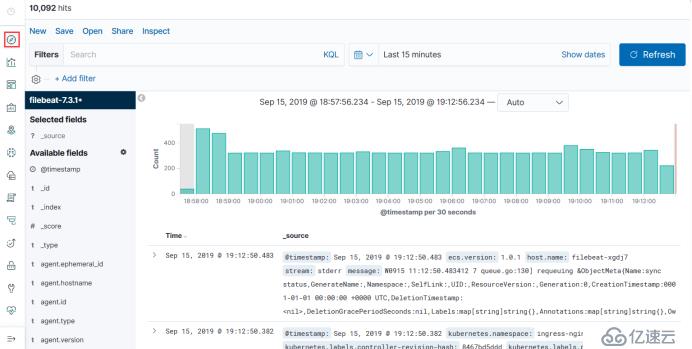
这里会可以看一些相关的日志,比如命名空间,很多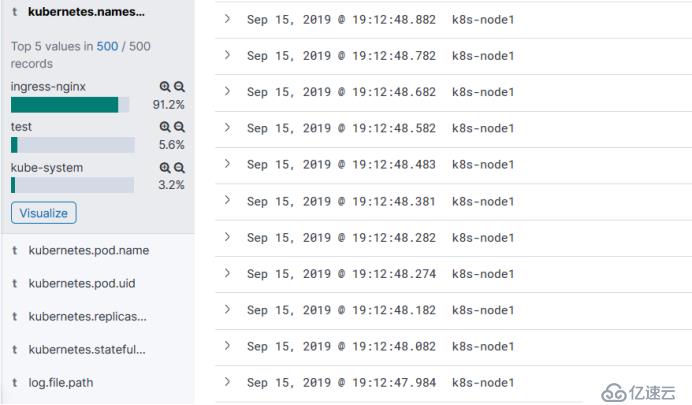
比如看容器的保存路径下的容器的日志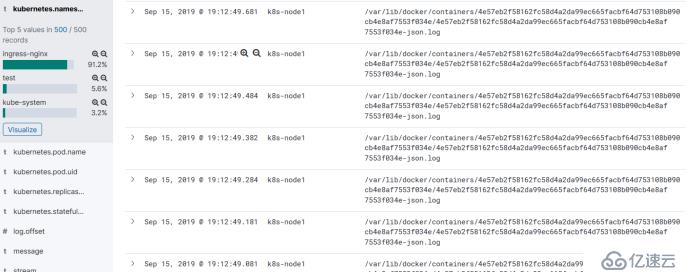
还有messages输出整体的日志内容,能看出它采用的哪个命名空间,能看出pod的名称,node的名称,也能看出采集的日志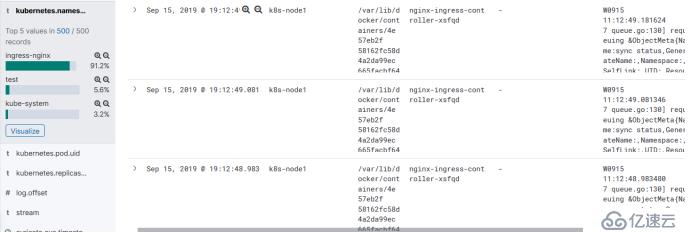
比如单独看一些想要的日志,通过过滤条件去筛选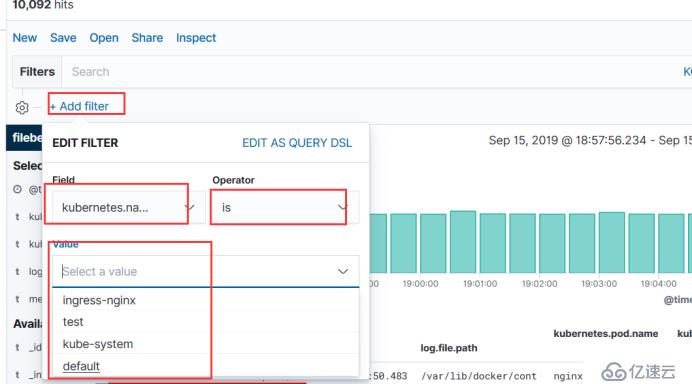
我们现在要收集k8s的日志,也就是你的ELK平台部署起来了,它是一个独立的系统部署起来了,要是使用set car方式去收集这个日志。
要是采集k8s日志,需要采集
[root@k8s-master elk]# tail /var/log/messages
这个文件,收集这个,我们先编写一个filebeat,这里就指定你要收集那些文件,这个filebeat这个pod,是不能访问到宿主机的,所以我们要通过数据卷挂载这个文件,es的索引相当于mysql 的db,所以要根据es里要创建不同的索引,也就是按天,记录某一个日志,这一天产生的日志放到这个索引中,这个索引呢要自定义名称,根据你当前部署的业务写一个名称,这样为了方面后面做查询,做一定的分类,别到时候几个项目了,k8s项目了,php项目了,Tomcat项目了,都在一个索引里面,当去查询也比较困难,所以把他们分成不同的索引,要指定这些的话就需要加这三个参数
setup.ilm.enabled: false
setup.template.name: "k8s-module"
setup.template.pattern: "k8s-module-*"下面是通过deemonset部署的filebeat到每个节点上,通过hostpath将宿主机上的/var/log/messages/挂载到容器中的/var/log/messages,这样容器中就有这个日志文件了,就能读取到了,这就是收集k8s的日志。
[root@k8s-master elk]# cat k8s-logs.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: k8s-logs-filebeat-config
namespace: kube-system
data:
filebeat.yml: |
filebeat.inputs:
- type: log
paths:
- /var/log/messages
fields:
app: k8s
type: module
fields_under_root: true
setup.ilm.enabled: false
setup.template.name: "k8s-module"
setup.template.pattern: "k8s-module-*"
output.elasticsearch:
hosts: ['elasticsearch.kube-system:9200']
index: "k8s-module-%{+yyyy.MM.dd}"
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: k8s-logs
namespace: kube-system
spec:
selector:
matchLabels:
project: k8s
app: filebeat
template:
metadata:
labels:
project: k8s
app: filebeat
spec:
containers:
- name: filebeat
image: elastic/filebeat:7.3.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
requests:
cpu: 100m
memory: 100Mi
limits:
cpu: 500m
memory: 500Mi
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: k8s-logs
mountPath: /var/log/messages
volumes:
- name: k8s-logs
hostPath:
path: /var/log/messages
- name: filebeat-config
configMap:
name: k8s-logs-filebeat-config[root@k8s-master elk]# kubectl create -f k8s-logs.yaml
[root@k8s-master elk]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-kqxwv 1/1 Running 2 6d8h
coredns-bccdc95cf-nwkbp 1/1 Running 2 6d8h
elasticsearch-0 1/1 Running 0 94m
etcd-k8s-master 1/1 Running 1 6d8h
filebeat-8s9cx 1/1 Running 0 94m
filebeat-xgdj7 1/1 Running 0 94m
k8s-logs-5s9kl 1/1 Running 0 37s
k8s-logs-txz4q 1/1 Running 0 37s
kibana-b7d98644-cmg9k 1/1 Running 0 94m
kube-apiserver-k8s-master 1/1 Running 1 6d8h
kube-controller-manager-k8s-master 1/1 Running 2 6d8h
kube-flannel-ds-amd64-dc5z9 1/1 Running 1 6d7h
kube-flannel-ds-amd64-jm2jz 1/1 Running 1 6d7h
kube-flannel-ds-amd64-z6tt2 1/1 Running 1 6d8h
kube-proxy-9ltx7 1/1 Running 2 6d8h
kube-proxy-lnzrj 1/1 Running 1 6d7h
kube-proxy-v7dqm 1/1 Running 1 6d7h
kube-scheduler-k8s-master 1/1 Running 2 6d8h还是原来的步骤,最后的一个按钮索引管理这里
这是我们自定义采集的日志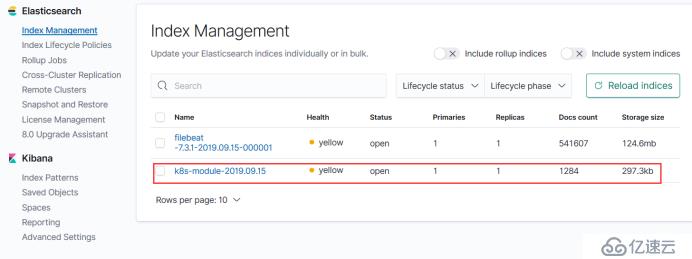
然后在创建一个索引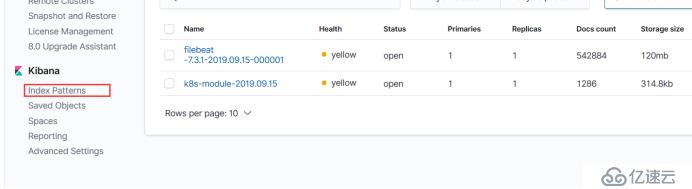
选择这个然后保存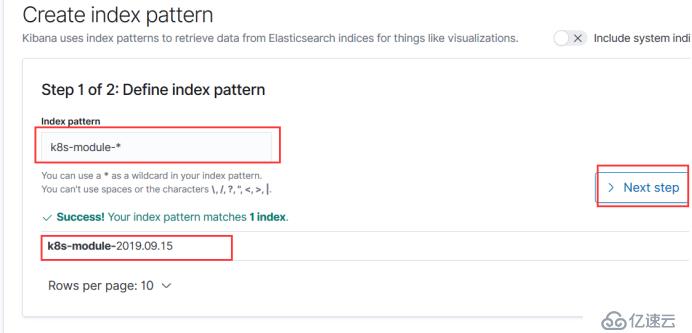
创建索引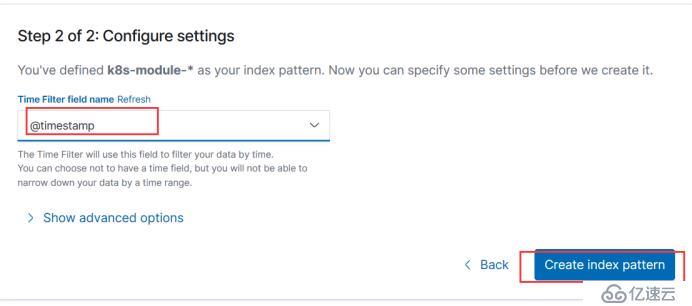
选择module-这里就能看到我们var/log/messages的日志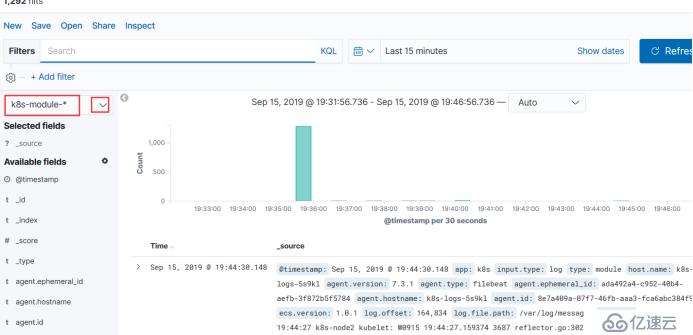
做一个简单的测试比如这样
[root@k8s-node1 ~]# echo hello > /var/log/messages
然后接收一下tomcat的日志
一般需要看的话,tomcat前面由nginx去做反向代理,而Tomcat需要看的日志是catalina
jc日志主要调试的时候需要看。
[root@k8s-master elk]# cat tomcat-deployment.yaml
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: tomcat-java-demo
namespace: test
spec:
replicas: 3
selector:
matchLabels:
project: www
app: java-demo
template:
metadata:
labels:
project: www
app: java-demo
spec:
imagePullSecrets:
- name: registry-pull-secret
containers:
- name: tomcat
image: 192.168.30.24/test/tomcat-java-demo:latest
imagePullPolicy: Always
ports:
- containerPort: 8080
name: web
protocol: TCP
resources:
requests:
cpu: 0.5
memory: 1Gi
limits:
cpu: 1
memory: 2Gi
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 20
readinessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 20
volumeMounts:
- name: tomcat-logs
mountPath: /usr/local/tomcat/logs
- name: filebeat
image: elastic/filebeat:7.3.1
args: [
"-c", "/etc/filebeat.yml",
"-e",
]
resources:
limits:
memory: 500Mi
requests:
cpu: 100m
memory: 100Mi
securityContext:
runAsUser: 0
volumeMounts:
- name: filebeat-config
mountPath: /etc/filebeat.yml
subPath: filebeat.yml
- name: tomcat-logs
mountPath: /usr/local/tomcat/logs
volumes:
- name: tomcat-logs
emptyDir: {}
- name: filebeat-config
configMap:
name: filebeat-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: test
data:
filebeat.yml: |-
filebeat.inputs:
- type: log
paths:
- /usr/local/tomcat/logs/catalina.*
fields:
app: www
type: tomcat-catalina
fields_under_root: true
multiline:
pattern: '^\['
negate: true
match: after
setup.ilm.enabled: false
setup.template.name: "tomcat-catalina"
setup.template.pattern: "tomcat-catalina-*"
output.elasticsearch:
hosts: ['elasticsearch.kube-system:9200']
index: "tomcat-catalina-%{+yyyy.MM.dd}"滚动更新一下,一般要是错误日志的话,日志量会增加,肯定需要去解决,又不是访问日志。另外滚动更新需要一分钟时间
[root@k8s-master elk]# kubectl get pod -n test
[root@k8s-master elk]# kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
tomcat-java-demo-7ffd4dc7c5-26xjf 2/2 Running 0 5m19s
tomcat-java-demo-7ffd4dc7c5-lwfgr 2/2 Running 0 7m31s
tomcat-java-demo-7ffd4dc7c5-pwj77 2/2 Running 0 8m50s我们的日志收集到了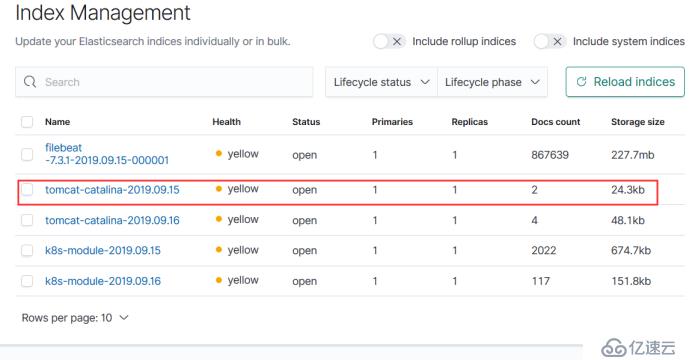
然后在创建一个索引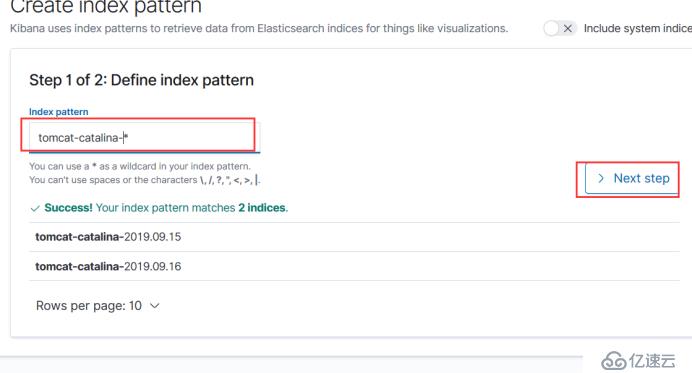
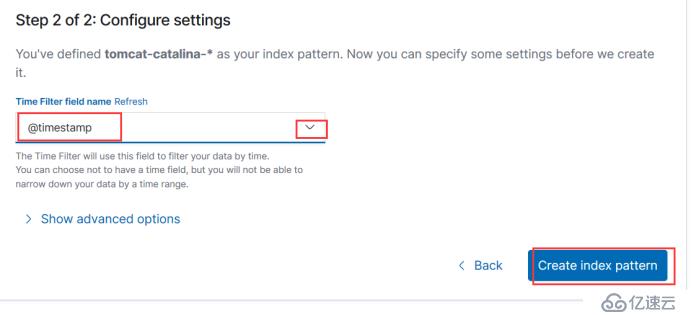

然后也可以去测试一下去容器,比如访问日志等等,和刚才的测试一样。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。