жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
зӣ®еҪ•пјҡ
иҜҙеңЁеүҚйқўзҡ„иҜқпјҢзҺ°еңЁзӣ‘жҺ§йҰ–йҖүзҡ„иҜқпјҢиӮҜе®ҡжҳҜPrometheus+Grafana,д№ҹе°ұжҳҜеҫҲеӨҡеӨ§еһӢе…¬еҸёд№ҹйғҪеңЁз”ЁпјҢеғҸRBMпјҢ360пјҢзҪ‘жҳ“пјҢеҹәжң¬йғҪжҳҜдҪҝз”ЁиҝҷдёҖеҘ—зӣ‘жҺ§зі»з»ҹгҖӮ
дёҖгҖҒPrometheus жҳҜд»Җд№Ҳпјҹ
PrometheusпјҲжҷ®зҪ—зұідҝ®ж–ҜпјүжҳҜдёҖдёӘжңҖеҲқеңЁSoundCloudдёҠжһ„е»әзҡ„зӣ‘жҺ§зі»з»ҹгҖӮSoundCloudжҳҜжҗһдә‘и®Ўз®—зҡ„дёҖ家еӣҪеӨ–зҡ„е…¬еҸёпјҢд№ҹжҳҜз”ұдёҖдёӘи°·жӯҢзҡ„дёҖдҪҚе·ҘзЁӢеёҲжқҘеҲ°иҝҷ家公еҸёд№ӢеҗҺејҖеҸ‘зҡ„иҝҷдёӘзі»з»ҹпјҢиҮӘ2012е№ҙжҲҗдёәзӨҫеҢәејҖжәҗйЎ№зӣ®пјҢжӢҘжңүйқһеёёжҙ»и·ғзҡ„ејҖеҸ‘дәәе‘ҳе’Ңз”ЁжҲ·зӨҫеҢәгҖӮдёәејәи°ғејҖжәҗеҸҠзӢ¬з«Ӣз»ҙжҠӨпјҢPrometheusдәҺ2016е№ҙеҠ е…Ҙдә‘еҺҹз”ҹдә‘и®Ўз®—еҹәйҮ‘дјҡ
пјҲCNCFпјүпјҢжҲҗдёә继Kubernetesд№ӢеҗҺзҡ„第дәҢдёӘжүҳз®ЎйЎ№зӣ®пјҢиҝҷдёӘйЎ№зӣ®еҸ‘еұ•зҡ„иҝҳжҳҜжҜ”иҫғеҝ«зҡ„пјҢйҡҸзқҖk8sзҡ„еҸ‘еұ•пјҢе®ғд№ҹиө·жқҘдәҶгҖӮ
https://prometheus.io е®ҳж–№зҪ‘з«ҷ
https://github.com/prometheus GitHubең°еқҖ
Prometheusз»„жҲҗеҸҠжһ¶жһ„
жҺҘдёӢжқҘзңӢдёҖдёӢе®ғиҝҷдёӘе®ҳж–№з»ҷеҮәзҡ„жһ¶жһ„еӣҫпјҢжҲ‘们жқҘз ”з©¶дёҖдёӢ
жңҖе·Ұиҫ№иҝҷеқ—е°ұжҳҜйҮҮйӣҶзҡ„пјҢйҮҮйӣҶи°Ғзӣ‘жҺ§и°ҒпјҢдёҖиҲ¬жҳҜдёҖдәӣзҹӯе‘Ёжңҹзҡ„д»»еҠЎпјҢжҜ”еҰӮcronjobиҝҷж ·зҡ„д»»еҠЎ,д№ҹеҸҜд»ҘжҳҜдёҖдәӣжҢҒд№…жҖ§зҡ„д»»еҠЎпјҢе…¶е®һдё»иҰҒе°ұжҳҜдёҖдәӣжҢҒд№…жҖ§зҡ„д»»еҠЎпјҢжҜ”еҰӮwebжңҚеҠЎпјҢд№ҹе°ұжҳҜжҢҒз»ӯиҝҗиЎҢзҡ„пјҢжҡҙйңІдёҖдәӣжҢҮж ҮпјҢеғҸзҹӯжңҹд»»еҠЎе‘ўпјҢеӨ„зҗҶдёҖдёӢе°ұе…ідәҶпјҢеҲҶдёәиҝҷдёӨдёӘзұ»еһӢпјҢзҹӯжңҹд»»еҠЎдјҡз”ЁеҲ°Pushgateway,专门收йӣҶиҝҷдәӣзҹӯжңҹд»»еҠЎзҡ„гҖӮ
дёӯй—ҙиҝҷеқ—е°ұжҳҜPrometheusе®ғжң¬иә«пјҢеҶ…йғЁжҳҜжңүдёҖдёӘTSDBзҡ„ж•°жҚ®еә“зҡ„пјҢд»ҺеҶ…йғЁзҡ„йҮҮйӣҶе’Ңеұ•зӨәPrometheusе®ғйғҪеҸҜд»Ҙе®ҢжҲҗпјҢеұ•зӨәиҝҷеқ—иҮӘе·ұзҡ„иҝҷеқ—UIжҜ”иҫғlouпјҢжүҖд»ҘеҖҹеҠ©дәҺиҝҷдёӘејҖжәҗзҡ„GrafanaжқҘеұ•зӨәпјҢжүҖжңүзҡ„иў«зӣ‘жҺ§з«ҜжҡҙйңІе®ҢжҢҮж Үд№ӢеҗҺпјҢPrometheusдјҡдё»еҠЁзҡ„жҠ“еҸ–иҝҷдәӣжҢҮж ҮпјҢеӯҳеӮЁеҲ°иҮӘе·ұTSDBж•°жҚ®еә“йҮҢйқўпјҢжҸҗдҫӣз»ҷWeb UI,жҲ–иҖ…GrafanaпјҢжҲ–иҖ…API clientsйҖҡиҝҮPromQLжқҘи°ғз”Ёиҝҷдәӣж•°жҚ®пјҢPromQLзӣёеҪ“дәҺMysqlзҡ„SQLпјҢдё»иҰҒжҳҜжҹҘиҜўиҝҷдәӣж•°жҚ®зҡ„гҖӮ
дёӯй—ҙдёҠйқўиҝҷеқ—жҳҜеҒҡжңҚеҠЎеҸ‘зҺ°зҡ„пјҢд№ҹе°ұжҳҜдҪ жңүеҫҲеӨҡзҡ„иў«зӣ‘жҺ§з«Ҝж—¶пјҢжүӢеҠЁзҡ„еҺ»еҶҷиҝҷдәӣиў«зӣ‘жҺ§з«ҜжҳҜдёҚзҺ°е®һзҡ„пјҢжүҖд»ҘйңҖиҰҒиҮӘеҠЁзҡ„еҺ»еҸ‘зҺ°ж–°еҠ е…Ҙзҡ„иҠӮзӮ№пјҢжҲ–иҖ…д»Ҙжү№йҮҸзҡ„иҠӮзӮ№пјҢеҠ е…ҘеҲ°иҝҷдёӘзӣ‘жҺ§дёӯпјҢеғҸk8sе®ғеҶ…зҪ®дәҶk8sжңҚеҠЎеҸ‘зҺ°зҡ„жңәеҲ¶пјҢд№ҹе°ұжҳҜе®ғдјҡиҝһжҺҘk8sзҡ„APIпјҢеҺ»еҸ‘зҺ°дҪ йғЁзҪІзҡ„е“Әдәӣеә”з”ЁпјҢе“ӘдәӣpodпјҢйҖҡйҖҡзҡ„йғҪз»ҷдҪ жҡҙйңІеҮәеҺ»пјҢзӣ‘жҺ§еҮәжқҘпјҢд№ҹе°ұжҳҜдёәд»Җд№ҲK8SеҜ№prometheusзү№еҲ«еҸӢеҘҪзҡ„ең°ж–№пјҢд№ҹе°ұжҳҜе®ғеҶ…зҪ®дәҶеҒҡиҝҷз§Қзӣёе…ізҡ„ж”ҜжҢҒдәҶгҖӮ
еҸідёҠи§’жҳҜPrometheusзҡ„е‘ҠиӯҰпјҢе®ғе‘ҠиӯҰе®һзҺ°жҳҜжңүдёҖдёӘ组件зҡ„пјҢAlertmanager,иҝҷдёӘ组件жҳҜжҺҘ收prometheusеҸ‘жқҘзҡ„е‘ҠиӯҰе°ұжҳҜи§ҰеҸ‘дәҶдёҖдәӣйў„еҖјпјҢдјҡйҖҡзҹҘAlertmanager,иҖҢAlertmanagerжқҘеӨ„зҗҶе‘ҠиӯҰзӣёе…ізҡ„еӨ„зҗҶпјҢ然еҗҺеҸ‘йҖҒз»ҷжҺҘ收дәәпјҢеҸҜд»ҘжҳҜemail,д№ҹеҸҜд»ҘжҳҜдјҒдёҡеҫ®дҝЎпјҢжҲ–иҖ…й’үй’үпјҢд№ҹе°ұжҳҜе®ғж•ҙдёӘзҡ„иҝҷдёӘжЎҶжһ¶пјҢеҲҶдёәиҝҷ5еқ—гҖӮ
е°Ҹз»“пјҡ
вҖў Prometheus Serverпјҡ收йӣҶжҢҮж Үе’ҢеӯҳеӮЁж—¶й—ҙеәҸеҲ—ж•°жҚ®пјҢ并жҸҗдҫӣжҹҘиҜўжҺҘеҸЈ
вҖў ClientLibraryпјҡе®ўжҲ·з«Ҝеә“пјҢиҝҷдәӣеҸҜд»ҘйӣҶжҲҗдёҖдәӣеҫҲеӨҡзҡ„иҜӯиЁҖдёӯпјҢжҜ”еҰӮдҪҝз”ЁJAVAејҖеҸ‘зҡ„дёҖдёӘWebзҪ‘з«ҷпјҢйӮЈд№ҲеҸҜд»ҘйӣҶжҲҗJAVAзҡ„е®ўжҲ·з«ҜпјҢеҺ»жҡҙйңІзӣёе…ізҡ„жҢҮж ҮпјҢжҡҙйңІиҮӘиә«зҡ„жҢҮж ҮпјҢдҪҶеҫҲеӨҡзҡ„дёҡеҠЎжҢҮж ҮйңҖиҰҒејҖеҸ‘еҺ»еҶҷзҡ„пјҢ
вҖў Push GatewayпјҡзҹӯжңҹеӯҳеӮЁжҢҮж Үж•°жҚ®гҖӮдё»иҰҒз”ЁдәҺдёҙж—¶жҖ§зҡ„д»»еҠЎ
вҖў ExportersпјҡйҮҮйӣҶе·Іжңүзҡ„第дёүж–№жңҚеҠЎзӣ‘жҺ§жҢҮж Ү并жҡҙйңІmetricsпјҢзӣёеҪ“дәҺдёҖдёӘйҮҮйӣҶз«Ҝзҡ„agent,
вҖў Alertmanagerпјҡе‘ҠиӯҰ
вҖў Web UIпјҡз®ҖеҚ•зҡ„WebжҺ§еҲ¶еҸ°
ж•°жҚ®жЁЎеһӢ
Prometheusе°ҶжүҖжңүж•°жҚ®еӯҳеӮЁдёәж—¶й—ҙеәҸеҲ—пјӣе…·жңүзӣёеҗҢеәҰйҮҸеҗҚз§°д»ҘеҸҠж ҮзӯҫеұһдәҺеҗҢдёҖдёӘжҢҮж ҮгҖӮ
жҜҸдёӘж—¶й—ҙеәҸеҲ—йғҪз”ұеәҰйҮҸж ҮеҮҶеҗҚз§°е’ҢдёҖз»„й”®еҖјеҜ№пјҲд№ҹжҲҗдёәж Үзӯҫпјүе”ҜдёҖж ҮиҜҶгҖӮ д№ҹе°ұжҳҜжҹҘиҜўж—¶
д№ҹдјҡдҫқжҚ®иҝҷдәӣж ҮзӯҫжқҘжҹҘиҜўе’ҢиҝҮж»ӨпјҢе°ұжҳҜеҶҷPromQLж—¶
ж—¶й—ҙеәҸеҲ—ж јејҸпјҡ
<metric name>{<label name>=<label value>, ...}
жҢҮж Үзҡ„еҗҚеӯ—+иҠұжӢ¬еҸ·йҮҢйқўжңүеҫҲеӨҡзҡ„еҖј
зӨәдҫӢпјҡapi_http_requests_total{method="POST", handler="/messages"}
пјҲ еҗҚз§° пјүпјҲйҮҢйқўеҢ…еҗ«зҡ„POSTиҜ·жұӮпјҢGETиҜ·жұӮпјҢиҜ·жұӮйҮҢйқўиҝҳеҢ…еҗ«дәҶиҜ·жұӮзҡ„иө„жәҗпјҢжҜ”еҰӮmessagesжҲ–иҖ…APIпјүйҮҢйқўеҸҜд»ҘиҝҳжңүеҫҲеӨҡзҡ„жҢҮж ҮпјҢжҜ”еҰӮиҜ·жұӮзҡ„еҚҸи®®пјҢжҲ–иҖ…жҗәеёҰдәҶе…¶д»–HTTPеӨҙзҡ„еӯ—ж®өпјҢйғҪеҸҜд»ҘиҝӣиЎҢж Үи®°еҮәжқҘпјҢе°ұжҳҜжғізӣ‘жҺ§зҡ„йғҪеҸҜд»ҘйҖҡиҝҮиҝҷз§Қж–№ејҸзӣ‘жҺ§еҮәжқҘгҖӮ
дҪңдёҡе’Ңе®һдҫӢ
е®һдҫӢпјҡеҸҜд»ҘжҠ“еҸ–зҡ„зӣ®ж Үз§°дёәе®һдҫӢпјҲInstancesпјүпјҢз”ЁиҝҮzabbixзҡ„йғҪзҹҘйҒ“иў«зӣ‘жҺ§з«ҜжҳҜз§°дёәд»Җд№ҲпјҢдёҖиҲ¬е°ұжҳҜз§°дёәдё»жңәпјҢиў«зӣ‘жҺ§з«ҜпјҢиҖҢеңЁprometheusз§°дёәдёҖдёӘе®һдҫӢгҖӮ
дҪңдёҡпјҡе…·жңүзӣёеҗҢзӣ®ж Үзҡ„е®һдҫӢйӣҶеҗҲз§°дёәдҪңдёҡпјҲJobпјүпјҢд№ҹе°ұжҳҜе°ҶдҪ зҡ„иў«зӣ‘жҺ§з«ҜдҪңдёәдҪ дёӘйӣҶеҗҲпјҢжҜ”еҰӮеҒҡдёҖдёӘеҲҶз»„пјҢweb жңҚеҠЎжңүеҮ еҸ°пјҢжҜ”еҰӮжңү3еҸ°пјҢеҶҷдёҖдёӘjobдёӢпјҢиҝҷдёӘjobдёӢе°ұжҳҜ3еҸ°пјҢе°ұжҳҜеҒҡдёҖдёӘйҖ»иҫ‘дёҠзҡ„еҲҶз»„пјҢ
дәҢгҖҒK8Sзӣ‘жҺ§жҢҮж Ү
Kubernetesжң¬иә«зӣ‘жҺ§
вҖў Nodeиө„жәҗеҲ©з”ЁзҺҮ пјҡдёҖиҲ¬з”ҹдә§зҺҜеўғеҮ еҚҒдёӘnodeпјҢеҮ зҷҫдёӘnodeеҺ»зӣ‘жҺ§
вҖў Nodeж•°йҮҸ пјҡдёҖиҲ¬иғҪзӣ‘жҺ§еҲ°nodeпјҢе°ұиғҪзӣ‘жҺ§еҲ°е®ғзҡ„ж•°йҮҸдәҶпјҢеӣ дёәе®ғжҳҜдёҖдёӘе®һдҫӢпјҢдёҖдёӘnodeиғҪи·‘еӨҡе°‘дёӘйЎ№зӣ®пјҢд№ҹжҳҜйңҖиҰҒеҺ»иҜ„дј°зҡ„пјҢж•ҙдҪ“иө„жәҗзҺҮеңЁдёҖдёӘд»Җд№Ҳж ·зҡ„зҠ¶жҖҒпјҢд»Җд№Ҳж ·зҡ„еҖјпјҢжүҖд»ҘйңҖиҰҒж №жҚ®йЎ№зӣ®пјҢи·‘зҡ„иө„жәҗеҲ©з”ЁзҺҮпјҢиҝҳжңүеҖјеҒҡдёҖдёӘиҜ„дј°зҡ„пјҢжҜ”еҰӮеҶҚи·‘дёҖдёӘйЎ№зӣ®пјҢйңҖиҰҒеӨҡе°‘иө„жәҗгҖӮ
вҖў Podsж•°йҮҸпјҲNodeпјүпјҡе…¶е®һд№ҹжҳҜдёҖж ·зҡ„пјҢжҜҸдёӘnodeдёҠйғҪи·‘еӨҡе°‘pod,дёҚиҝҮй»ҳи®ӨдёҖдёӘnodeдёҠиғҪи·‘110дёӘpodпјҢдҪҶеӨ§еӨҡж•°жғ…еҶөдёӢдёҚеҸҜиғҪи·‘иҝҷд№ҲеӨҡпјҢжҜ”еҰӮдёҖдёӘ128Gзҡ„еҶ…еӯҳпјҢ32ж ёcpu,дёҖдёӘjavaзҡ„йЎ№зӣ®пјҢдёҖдёӘеҲҶй…Қ2G,д№ҹе°ұжҳҜиғҪи·‘50-60дёӘпјҢдёҖиҲ¬жңәеҷЁпјҢpodд№ҹе°ұи·‘еҮ еҚҒдёӘпјҢеҫҲе°‘еҫҲе°‘и¶…иҝҮ100дёӘгҖӮ
вҖў иө„жәҗеҜ№иұЎзҠ¶жҖҒ пјҡжҜ”еҰӮpodпјҢservice,deployment,jobиҝҷдәӣиө„жәҗзҠ¶жҖҒпјҢеҒҡдёҖдёӘз»ҹи®ЎгҖӮ
Podзӣ‘жҺ§
вҖў Podж•°йҮҸпјҲйЎ№зӣ®пјүпјҡдҪ зҡ„йЎ№зӣ®и·‘дәҶеӨҡе°‘дёӘpodзҡ„ж•°йҮҸпјҢеӨ§жҰӮзҡ„еҲ©зӣҠзҺҮжҳҜеӨҡе°‘пјҢеҘҪиҜ„дј°дёҖдёӢиҝҷдёӘйЎ№зӣ®и·‘дәҶеӨҡе°‘дёӘиө„жәҗеҚ жңүеӨҡе°‘иө„жәҗпјҢжҜҸдёӘpodеҚ дәҶеӨҡе°‘иө„жәҗгҖӮ
вҖў е®№еҷЁиө„жәҗеҲ©з”ЁзҺҮ пјҡжҜҸдёӘе®№еҷЁж¶ҲиҖ—дәҶеӨҡе°‘иө„жәҗпјҢз”ЁдәҶеӨҡе°‘CPUпјҢз”ЁдәҶеӨҡе°‘еҶ…еӯҳ
вҖў еә”з”ЁзЁӢеәҸпјҡиҝҷдёӘе°ұжҳҜеҒҸеә”з”ЁзЁӢеәҸжң¬иә«зҡ„жҢҮж ҮдәҶпјҢиҝҷдёӘдёҖиҲ¬еңЁжҲ‘们иҝҗз»ҙеҫҲйҡҫжӢҝеҲ°зҡ„пјҢжүҖд»ҘеңЁзӣ‘жҺ§д№ӢеүҚе‘ўпјҢйңҖиҰҒејҖеҸ‘еҺ»з»ҷдҪ жҡҙйңІеҮәжқҘпјҢиҝҷйҮҢжңүеҫҲеӨҡе®ўжҲ·з«Ҝзҡ„йӣҶжҲҗпјҢе®ўжҲ·з«Ҝеә“е°ұжҳҜж”ҜжҢҒеҫҲеӨҡиҜӯиЁҖзҡ„пјҢйңҖиҰҒи®©ејҖеҸ‘еҒҡдёҖдәӣејҖеҸ‘йҮҸе°Ҷе®ғйӣҶжҲҗиҝӣеҺ»пјҢжҡҙйңІиҝҷдёӘеә”з”ЁзЁӢеәҸзҡ„жғізҹҘйҒ“зҡ„жҢҮж ҮпјҢ然еҗҺзәіе…Ҙзӣ‘жҺ§пјҢеҰӮжһңејҖеҸ‘йғЁй…ҚеҗҲпјҢеҹәжң¬иҝҗз»ҙеҫҲйҡҫеҒҡеҲ°иҝҷдёҖеқ—пјҢйҷӨйқһиҮӘе·ұеҶҷдёҖдёӘе®ўжҲ·з«ҜзЁӢеәҸпјҢйҖҡиҝҮshell/pythonиғҪдёҚиғҪд»ҺеӨ–йғЁиҺ·еҸ–еҶ…йғЁзҡ„е·ҘдҪңжғ…еҶөпјҢеҰӮжһңиҝҷдёӘзЁӢеәҸжҸҗдҫӣAPIзҡ„иҜқпјҢиҝҷдёӘеҫҲе®№жҳ“еҒҡеҲ°гҖӮ
Prometheusзӣ‘жҺ§K8Sжһ¶жһ„
еҰӮжһңжғізӣ‘жҺ§nodeзҡ„иө„жәҗпјҢе°ұеҸҜд»Ҙж”ҫдёҖдёӘnode_exporter,иҝҷжҳҜзӣ‘жҺ§nodeиө„жәҗзҡ„пјҢnode_exporterжҳҜLinuxдёҠзҡ„йҮҮйӣҶеҷЁпјҢдҪ ж”ҫдёҠеҺ»дҪ е°ұиғҪйҮҮйӣҶеҲ°еҪ“еүҚиҠӮзӮ№зҡ„CPUгҖҒеҶ…еӯҳгҖҒзҪ‘з»ңIOпјҢзӯүеҫ…йғҪеҸҜд»ҘйҮҮйӣҶзҡ„гҖӮ
еҰӮжһңжғізӣ‘жҺ§е®№еҷЁпјҢk8sеҶ…йғЁжҸҗдҫӣcAdvisorйҮҮйӣҶеҷЁпјҢpodе‘ҖпјҢе®№еҷЁйғҪеҸҜд»ҘйҮҮйӣҶеҲ°иҝҷдәӣжҢҮж ҮпјҢйғҪжҳҜеҶ…зҪ®зҡ„пјҢдёҚйңҖиҰҒеҚ•зӢ¬йғЁзҪІпјҢеҸӘзҹҘйҒ“жҖҺд№ҲеҺ»и®ҝй—®иҝҷдёӘCadvisorе°ұеҸҜд»ҘдәҶгҖӮ
еҰӮжһңжғізӣ‘жҺ§k8sиө„жәҗеҜ№иұЎпјҢдјҡйғЁзҪІдёҖдёӘkube-state-metricsиҝҷдёӘжңҚеҠЎпјҢе®ғдјҡе®ҡж—¶зҡ„APIдёӯиҺ·еҸ–еҲ°иҝҷдәӣжҢҮж ҮпјҢеё®дҪ еӯҳеҸ–еҲ°PrometheusйҮҢпјҢиҰҒжҳҜе‘ҠиӯҰзҡ„иҜқпјҢйҖҡиҝҮAlertmanagerеҸ‘йҖҒз»ҷдёҖдәӣжҺҘ收方пјҢйҖҡиҝҮGrafanaеҸҜи§ҶеҢ–еұ•зӨәгҖӮ
жңҚеҠЎеҸ‘зҺ°пјҡ
https://prometheus.io/docs/prometheus/latest/configuration/configuration/#kubernetes_sd_config
дёүгҖҒеңЁK8SдёӯйғЁзҪІPrometheus+Grafana
ж–ҮжЎЈжңүзҡ„yamlж јејҸеҸҜиғҪдёҚеҜ№йғЁзҪІеҸҜиғҪдјҡеҮәзҺ°й—®йўҳ
е»әи®®жӢүеҸ–жҲ‘д»Јз Ғд»“еә“зҡ„ең°еқҖпјҢжӢүеҸ–зҡ„ж—¶еҖҷиҜ·жҠҠдҪ зҡ„е…¬й’Ҙз»ҷжҲ‘пјҢдёҚ然жӢүеҸ–дёҚдёӢжқҘgit clone git@gitee.com:zhaocheng172/prometheus.git
[root@k8s-master prometheus-k8s]# ls
alertmanager-configmap.yaml OWNERS
alertmanager-deployment.yaml prometheus-configmap.yaml
alertmanager-pvc.yaml prometheus-rbac.yaml
alertmanager-service.yaml prometheus-rules.yaml
grafana.yaml prometheus-service.yaml
kube-state-metrics-deployment.yaml prometheus-statefulset-static-pv.yaml
kube-state-metrics-rbac.yaml prometheus-statefulset.yaml
kube-state-metrics-service.yaml README.md
node_exporter.shзҺ°еңЁе…ҲжқҘеҲӣе»әrbacпјҢеӣ дёәйғЁзҪІе®ғзҡ„дё»жңҚеҠЎдё»иҝӣзЁӢиҰҒеј•з”ЁиҝҷеҮ дёӘжңҚеҠЎ
еӣ дёәprometheusжқҘиҝһжҺҘдҪ зҡ„APIпјҢд»ҺAPIдёӯиҺ·еҸ–еҫҲеӨҡзҡ„жҢҮж Ү
并且и®ҫзҪ®дәҶз»‘е®ҡйӣҶзҫӨи§’иүІзҡ„жқғйҷҗпјҢеҸӘиғҪжҹҘзңӢпјҢдёҚиғҪдҝ®ж”№
[root@k8s-master prometheus-k8s]# cat prometheus-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: prometheus
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- nonResourceURLs:
- "/metrics"
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-system
[root@k8s-master prometheus-k8s]# kubectl create -f prometheus-rbac.yaml зҺ°еңЁеҲӣе»әдёҖдёӢconfigmapпјҢ
rule_files:
- /etc/config/rules/*.rulesиҝҷжҳҜеҶҷе…Ҙе‘ҠиӯҰ规еҲҷзҡ„зӣ®еҪ•пјҢд№ҹе°ұжҳҜиҝҷдёӘconfigmapдјҡжҢӮиҪҪеҲ°жҷ®зҪ—зұідҝ®ж–ҜйҮҢйқўпјҢи®©дё»иҝӣзЁӢиҜ»еҸ–иҝҷдәӣй…ҚзҪ®
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090дёӢйқўиҝҷдәӣйғҪжҳҜжқҘй…ҚзҪ®зӣ‘жҺ§з«Ҝзҡ„пјҢjob_nameжҳҜеҲҶз»„пјҢиҝҷжҳҜжҳҜзӣ‘жҺ§е®ғжң¬иә«пјҢдёӢйқўиҝҳжңүзӣ‘жҺ§node,жҲ‘们дјҡеңЁnodeдёҠиө·дёҖдёӘnodeport,иҝҷйҮҢдҝ®ж”№иҰҒзӣ‘жҺ§nodeиҠӮзӮ№
scrape_interval: 30sпјҡиҝҷйҮҢйҮҮйӣҶзҡ„ж—¶й—ҙпјҢжҜҸеӨҡе°‘з§’йҮҮйӣҶдёҖж¬Ўж•°жҚ®
иҝҷйҮҢиҝҳжңүдёҖдёӘalertingзҡ„жңҚеҠЎзҡ„еҗҚеӯ—
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:80"][root@k8s-master prometheus-k8s]# kubectl create -f prometheus-configmap.yaml
[root@k8s-master prometheus-k8s]# cat prometheus-configmap.yaml
# Prometheus configuration format https://prometheus.io/docs/prometheus/latest/configuration/configuration/
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
prometheus.yml: |
rule_files:
- /etc/config/rules/*.rules
scrape_configs:
- job_name: prometheus
static_configs:
- targets:
- localhost:9090
- job_name: kubernetes-nodes
scrape_interval: 30s
static_configs:
- targets:
- 192.168.30.22:9100
- 192.168.30.23:9100
- job_name: kubernetes-apiservers
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: default;kubernetes;https
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_service_name
- __meta_kubernetes_endpoint_port_name
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-kubelet
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-nodes-cadvisor
kubernetes_sd_configs:
- role: node
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __metrics_path__
replacement: /metrics/cadvisor
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
- job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-services
kubernetes_sd_configs:
- role: service
metrics_path: /probe
params:
module:
- http_2xx
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_probe
- source_labels:
- __address__
target_label: __param_target
- replacement: blackbox
target_label: __address__
- source_labels:
- __param_target
target_label: instance
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- source_labels:
- __meta_kubernetes_service_name
target_label: kubernetes_name
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:80"]еҶҚй…ҚзҪ®иҝҷдёӘи§’иүІпјҢиҝҷдёӘе°ұжҳҜй…ҚзҪ®е‘ҠиӯҰ规еҲҷзҡ„пјҢиҝҷйҮҢеҲҶдёәдёӨеқ—е‘ҠиӯҰ规еҲҷпјҢдёҖдёӘжҳҜйҖҡз”Ёзҡ„е‘ҠиӯҰ规еҲҷпјҢйҖӮз”ЁжүҖжңүзҡ„е®һдҫӢпјҢеҰӮжһңе®һдҫӢиҰҒжҳҜжҢӮдәҶпјҢ然еҗҺеҸ‘йҖҒе‘ҠиӯҰпјҢе®һдҫӢжҲ‘们被зӣ‘жҺ§з«Ҝзҡ„agentпјҢиҝҳжңүдёҖдёӘnodeи§’иүІпјҢиҝҷдёӘзӣ‘жҺ§жҜҸдёӘnodeзҡ„CPUгҖҒеҶ…еӯҳгҖҒзЈҒзӣҳеҲ©з”ЁзҺҮпјҢеңЁprometheusеҶҷе‘ҠиӯҰеҖјжҳҜйҖҡиҝҮpromQLеҺ»еҶҷзҡ„пјҢжқҘжҹҘиҜўдёҖдёӘж•°жҚ®жқҘжҜ”еҜ№пјҢеҰӮжһңз¬ҰеҗҲиҝҷдёӘжҜ”еҜ№зҡ„иЎЁиҫҫејҸпјҢе°ұжҳҜдёәзңҹзҡ„жғ…еҶөдёӢпјҢеҺ»и§ҰеҸ‘еҪ“еүҚиҝҷжқЎе‘ҠиӯҰпјҢжҜ”еҰӮе°ұжҳҜдёӢйқўиҝҷжқЎпјҢ然еҗҺдјҡе°ҶиҝҷжқЎе‘ҠиӯҰжҺЁйҖҒз»ҷalertmanagerпјҢе®ғжқҘеӨ„зҗҶиҝҷдёӘдҝЎжҒҜзҡ„е‘ҠиӯҰгҖӮexpr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
[root@k8s-master prometheus-k8s]# kubectl create -f prometheus-rules.yaml
[root@k8s-master prometheus-k8s]# cat prometheus-rules.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: kube-system
data:
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: error
annotations:
summary: "Instance {{ $labels.instance }} еҒңжӯўе·ҘдҪң"
description: "{{ $labels.instance }} job {{ $labels.job }} е·Із»ҸеҒңжӯў5еҲҶй’ҹд»ҘдёҠ."
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} : {{ $labels.mountpoint }} еҲҶеҢәдҪҝз”ЁзҺҮиҝҮй«ҳ"
description: "{{ $labels.instance }}: {{ $labels.mountpoint }} еҲҶеҢәдҪҝз”ЁеӨ§дәҺ80% (еҪ“еүҚеҖј: {{ $value }})"
- alert: NodeMemoryUsage
expr: 100 - (node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} еҶ…еӯҳдҪҝз”ЁзҺҮиҝҮй«ҳ"
description: "{{ $labels.instance }}еҶ…еӯҳдҪҝз”ЁеӨ§дәҺ80% (еҪ“еүҚеҖј: {{ $value }})"
- alert: NodeCPUUsage
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 60
for: 1m
labels:
severity: warning
annotations:
summary: "Instance {{ $labels.instance }} CPUдҪҝз”ЁзҺҮиҝҮй«ҳ"
description: "{{ $labels.instance }}CPUдҪҝз”ЁеӨ§дәҺ60% (еҪ“еүҚеҖј: {{ $value }})"然еҗҺеҶҚйғЁзҪІдёҖдёӢstatefulset
[root@k8s-master prometheus-k8s]# cat prometheus-statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: prometheus
namespace: kube-system
labels:
k8s-app: prometheus
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v2.2.1
spec:
serviceName: "prometheus"
replicas: 1
podManagementPolicy: "Parallel"
updateStrategy:
type: "RollingUpdate"
selector:
matchLabels:
k8s-app: prometheus
template:
metadata:
labels:
k8s-app: prometheus
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: prometheus
initContainers:
- name: "init-chown-data"
image: "busybox:latest"
imagePullPolicy: "IfNotPresent"
command: ["chown", "-R", "65534:65534", "/data"]
volumeMounts:
- name: prometheus-data
mountPath: /data
subPath: ""
containers:
- name: prometheus-server-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9090/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
- name: prometheus-server
image: "prom/prometheus:v2.2.1"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/prometheus.yml
- --storage.tsdb.path=/data
- --web.console.libraries=/etc/prometheus/console_libraries
- --web.console.templates=/etc/prometheus/consoles
- --web.enable-lifecycle
ports:
- containerPort: 9090
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
# based on 10 running nodes with 30 pods each
resources:
limits:
cpu: 200m
memory: 1000Mi
requests:
cpu: 200m
memory: 1000Mi
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: prometheus-data
mountPath: /data
subPath: ""
- name: prometheus-rules
mountPath: /etc/config/rules
terminationGracePeriodSeconds: 300
volumes:
- name: config-volume
configMap:
name: prometheus-config
- name: prometheus-rules
configMap:
name: prometheus-rules
volumeClaimTemplates:
- metadata:
name: prometheus-data
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "16Gi"иҝҷйҮҢе‘ўеӣ дёәжҲ‘д№ӢеүҚе°ұжҠҠnfsеҠЁжҖҒеҲӣе»әpvcзҡ„жҗӯе»әеҘҪдәҶпјҢдҪҝз”Ёзҡ„nfsеҒҡзҡ„зҪ‘з»ңеӯҳеӮЁпјҢжүҖд»ҘиҝҷйҮҢжІЎжңүжј”зӨәпјҢеҸҜд»ҘзңӢжҲ‘д№ӢеүҚзҡ„еҚҡе®ўпјҢ然еҗҺиҝҷйҮҢе·Із»ҸеҲӣе»әеҘҪдәҶ
[root@k8s-master prometheus-k8s]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-bccdc95cf-kqxwv 1/1 Running 3 2d4h
coredns-bccdc95cf-nwkbp 1/1 Running 3 2d4h
etcd-k8s-master 1/1 Running 2 2d4h
kube-apiserver-k8s-master 1/1 Running 2 2d4h
kube-controller-manager-k8s-master 1/1 Running 5 2d4h
kube-flannel-ds-amd64-dc5z9 1/1 Running 1 2d4h
kube-flannel-ds-amd64-jm2jz 1/1 Running 1 2d4h
kube-flannel-ds-amd64-z6tt2 1/1 Running 1 2d4h
kube-proxy-9ltx7 1/1 Running 2 2d4h
kube-proxy-lnzrj 1/1 Running 1 2d4h
kube-proxy-v7dqm 1/1 Running 1 2d4h
kube-scheduler-k8s-master 1/1 Running 5 2d4h
prometheus-0 2/2 Running 0 3m3s然еҗҺзңӢдёҖдёӢserviceпјҢжҲ‘们дҪҝз”ЁNodeportзұ»еһӢпјҢз«ҜеҸЈдҪҝз”Ё9090гҖӮеҪ“然д№ҹеҸҜд»ҘдҪҝз”ЁingressжҡҙйңІеҮәеҺ»
[root@k8s-master prometheus-k8s]# cat prometheus-service.yaml
kind: Service
apiVersion: v1
metadata:
name: prometheus
namespace: kube-system
labels:
kubernetes.io/name: "Prometheus"
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
spec:
type: NodePort
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
selector:
k8s-app: prometheusзҺ°еңЁеҸҜд»ҘеҺ»и®ҝй—®дёҖдёӢдәҶпјҢи®ҝй—®йҡҸжңәз«ҜеҸЈ32276,жҲ‘们зҡ„prometheusе·Із»ҸйғЁзҪІжҲҗеҠҹ
[root@k8s-master prometheus-k8s]# kubectl create -f prometheus-service.yaml
[root@k8s-master prometheus-k8s]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.1.0.10 <none> 53/UDP,53/TCP,9153/TCP 2d4h
prometheus NodePort 10.1.58.1 <none> 9090:32276/TCP 22sдёҖдёӘйқһеёёз®ҖжҙҒзҡ„UIйЎөйқўпјҢжІЎжңүд»Җд№ҲеҘҪзҡ„еҠҹиғҪпјҢеҫҲйҡҫж»Ўи¶ідјҒдёҡUIзҡ„иҰҒжұӮзҡ„пјҢдёҚиҝҮеҸӘеңЁиҝҷйҮҢеҒҡдёҖдёӘи°ғиҜ•пјҢдёҠйқўдё»иҰҒеҶҷpromQLзҡ„иЎЁиҫҫејҸзҡ„пјҢжҖҺд№ҲеҺ»жҹҘиҝҷдёӘж•°жҚ®пјҢе°ұеҘҪжҜ”mysqlзҡ„SQL,еҺ»жҹҘиҜўеҮәдҪ зҡ„ж•°жҚ®пјҢеҸҜд»ҘеңЁstatusйҮҢйқўеҺ»иҝӣиЎҢи°ғиҜ•пјҢиҖҢйҮҢйқўзҡ„configй…ҚзҪ®ж–Ү件жҲ‘们еўһеҠ дәҶе‘ҠиӯҰйў„еҖјпјҢеўһеҠ дәҶеҜ№nodeportзҡ„ж”ҜжҢҒиҝҳжңүжҢҮе®ҡдәҶalertmanagerзҡ„ең°еқҖпјҢ然еҗҺrulesпјҢжҲ‘们д№ҹжҳҜ规еҲ’дәҶдёӨеқ—пјҢдёҖдёӘжҳҜйҖҡ用规еҲҷпјҢдёҖдёӘжҳҜnodeиҠӮзӮ№и§„еҲҷпјҢдё»иҰҒзӣ‘жҺ§дёүеӨ§еқ—пјҢеҶ…еӯҳгҖҒзЈҒзӣҳгҖҒCPU
зҺ°еңЁжҹҘзңӢCPUзҡ„еҲ©з”ЁзҺҮпјҢдёҖиҲ¬йғҪжҳҜдҪҝз”ЁGrafanaеҺ»еұ•зӨә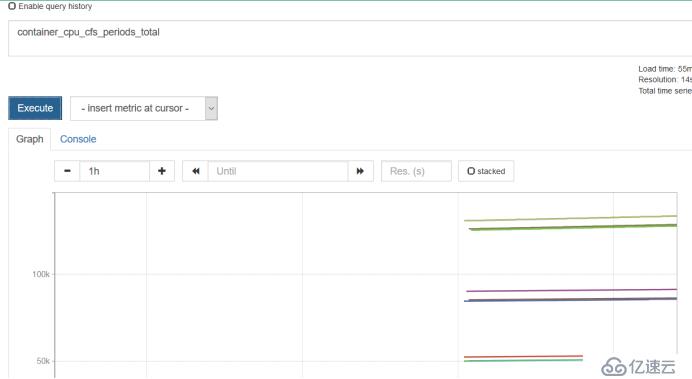
дә”гҖҒеңЁK8Sе№іеҸ°йғЁзҪІGrafana
иҝҷйҮҢд№ҹжҳҜз”ЁstatefulsetеҺ»еҒҡзҡ„пјҢд№ҹжҳҜиҮӘеҠЁеҲӣе»әpvпјҢе®ҡд№үзҡ„з«ҜеҸЈжҳҜ30007
[root@k8s-master prometheus-k8s]# cat grafana.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: grafana
namespace: kube-system
spec:
serviceName: "grafana"
replicas: 1
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana
ports:
- containerPort: 3000
protocol: TCP
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- name: grafana-data
mountPath: /var/lib/grafana
subPath: grafana
securityContext:
fsGroup: 472
runAsUser: 472
volumeClaimTemplates:
- metadata:
name: grafana-data
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "1Gi"
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-system
spec:
type: NodePort
ports:
- port : 80
targetPort: 3000
nodePort: 30007
selector:
app: grafanaй»ҳи®ӨиҙҰеҸ·еҜҶз ҒйғҪжҳҜadmin
йҰ–е…ҲжҲ‘们е°ҶprometheusеҒҡдёәж•°жҚ®жәҗпјҢж·»еҠ дёҖдёӘж•°жҚ®жәҗ并йҖүжӢ©prometheus
ж·»еҠ дёҖдёӘURLең°еқҖпјҢеҸҜд»ҘеҶҷдҪ и®ҝй—®UIйЎөйқўзҡ„ең°еқҖд№ҹеҸҜд»ҘеҶҷserviceзҡ„ең°еқҖ
[root@k8s-master prometheus-k8s]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.1.246.143 <none> 80:30007/TCP 11m
kube-dns ClusterIP 10.1.0.10 <none> 53/UDP,53/TCP,9153/TCP 2d5h
prometheus NodePort 10.1.58.1 <none> 9090:32276/TCP 40m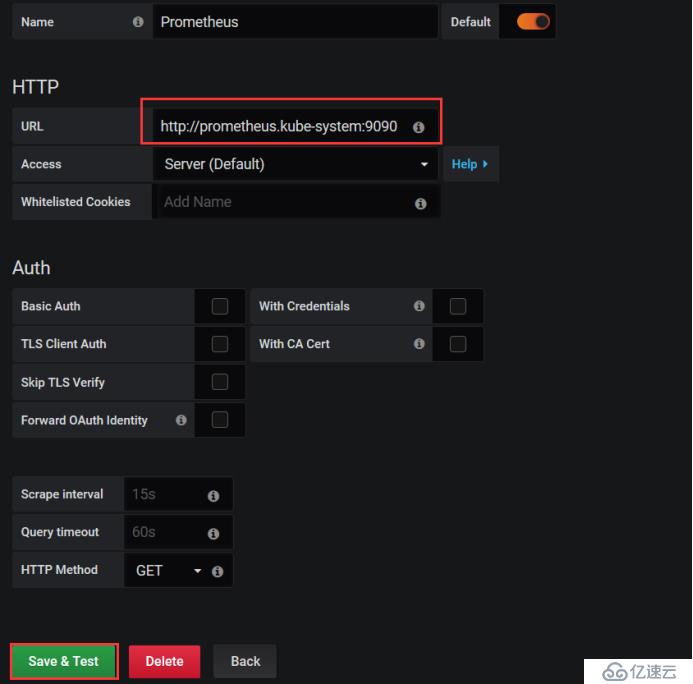
жҹҘзңӢж•°жҚ®жәҗе·Із»ҸжңүдёҖдёӘдәҶ
е…ӯгҖҒзӣ‘жҺ§K8SйӣҶзҫӨдёӯPodгҖҒNodeгҖҒиө„жәҗеҜ№иұЎ
пҒ¬ Pod
kubeletзҡ„иҠӮзӮ№дҪҝз”ЁcAdvisorжҸҗдҫӣзҡ„metricsжҺҘеҸЈиҺ·еҸ–иҜҘиҠӮзӮ№жүҖжңүPodе’Ңе®№еҷЁзӣёе…ізҡ„жҖ§иғҪжҢҮж Үж•°жҚ®гҖӮ
д№ҹе°ұжҳҜkubeletдјҡжҡҙйңІдёӨдёӘжҺҘеҸЈең°еқҖпјҡ
https://NodeIP:10255/metrics/cadvisor еҸӘиҜ»
https://NodeIP:10250/metrics/cadvisor kubeletзҡ„API,жҺҲжқғжІЎй—®йўҳзҡ„иҜқеҸҜд»ҘеҒҡд»»дҪ•ж“ҚдҪң
еҸҜд»ҘеңЁnodeиҠӮзӮ№еҺ»зңӢдёҖдёӢпјҢиҝҷдёӘз«ҜеҸЈдё»иҰҒз”ЁдҪңдәҺи®ҝй—®kubeletзҡ„дёҖдәӣAPIйүҙжқғпјҢе’ҢжҸҗдҫӣдёҖдәӣcAdvisorжҢҮж Үз”Ёзҡ„пјҢе’ұ们йғЁзҪІprometheusзҡ„ж—¶еҖҷпјҢе°ұе·Із»ҸејҖе§Ӣ收йӣҶcAdvisorж•°жҚ®дәҶпјҢдёәд»Җд№ҲдјҡйҮҮйӣҶпјҢеӣ дёәprometheusй…ҚзҪ®ж–Ү件е°ұе·Із»ҸеҺ»е®ҡд№үжҖҺд№ҲеҺ»йҮҮйӣҶж•°жҚ®дәҶ
[root@k8s-node1 ~]# netstat -antp |grep 10250
tcp6 0 0 :::10250 :::* LISTEN 107557/kubelet
tcp6 0 0 192.168.30.22:10250 192.168.30.23:58692 ESTABLISHED 107557/kubelet
tcp6 0 0 192.168.30.22:10250 192.168.30.23:46555 ESTABLISHED 107557/kubelet пҒ¬ Node
дҪҝз”Ёnode_exporter收йӣҶеҷЁйҮҮйӣҶиҠӮзӮ№иө„жәҗеҲ©з”ЁзҺҮгҖӮ
https://github.com/prometheus/node_exporter
дҪҝз”Ёж–ҮжЎЈпјҡhttps://prometheus.io/docs/guides/node-exporter/
пҒ¬ иө„жәҗеҜ№иұЎ
kube-state-metricsйҮҮйӣҶдәҶk8sдёӯеҗ„з§Қиө„жәҗеҜ№иұЎзҡ„зҠ¶жҖҒдҝЎжҒҜпјҢ
https://github.com/kubernetes/kube-state-metrics
зҺ°еңЁеҜје…ҘдёҖдёӘиғҪеӨҹжҹҘзңӢpodж•°жҚ®зҡ„жЁЎзүҲпјҢд№ҹе°ұжҳҜйҖҡиҝҮжЁЎзүҲжӣҙиғҪзӣҙи§ӮеҺ»еұ•зӨәиҝҷдәӣж•°жҚ®
дёғгҖҒдҪҝз”ЁGrafanaеҸҜи§ҶеҢ–еұ•зӨәPrometheusзӣ‘жҺ§ж•°жҚ®
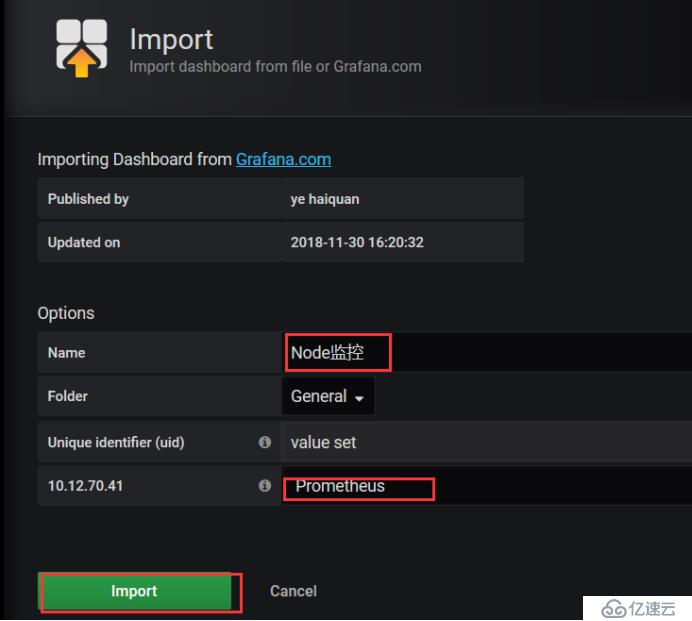
жҺЁиҚҗжЁЎжқҝпјҡ д№ҹе°ұжҳҜеңЁgrafanaе…ұдә«дёӯеҝғйҮҢйқўзҡ„пјҢд№ҹе°ұжҳҜеҲ«дәәеҶҷзҡ„жЁЎзүҲдёҠдј еҲ°иҝҷйҮҢеә“йҮҢйқўзҡ„пјҢиҮӘе·ұд№ҹеҸҜд»ҘеҶҷпјҢеҶҷе®ҢдёҠдј дёҠеҺ»пјҢеҲ«дәәд№ҹеҸҜд»Ҙи®ҝй—®еҲ°пјҢдёӢйқўжҳҜжЁЎзүҲзҡ„id,еҸӘиҰҒиҺ·еҸ–иҝҷдёӘIDпјҢе°ұиғҪдҪҝз”ЁиҝҷдёӘжЁЎзүҲдәҶпјҢеҸӘиҰҒиҝҷдёӘжЁЎзүҲпјҢеҗҺз«ҜжҸҗдҫӣжү§иЎҢpromeQL,еҸӘиҰҒжңүж•°жҚ®е°ұиғҪеё®дҪ еұ•зӨәеҮәжқҘ
Grafana.com
вҖў йӣҶзҫӨиө„жәҗзӣ‘жҺ§пјҡ3119
вҖў иө„жәҗзҠ¶жҖҒзӣ‘жҺ§ пјҡ6417
вҖў Nodeзӣ‘жҺ§ пјҡ9276
зҺ°еңЁдҪҝз”ЁиҝҷдёӘ3319жЁЎзүҲпјҢжқҘеұ•зӨәжҲ‘们зҡ„йӣҶзҫӨзҡ„иө„жәҗпјҢжү“ејҖж·»еҠ жЁЎзүҲпјҢйҖүжӢ©dashboard
йҖүжӢ©еҜје…ҘжЁЎзүҲ
еҶҷе…Ҙ3119,е®ғиғҪиҮӘеҠЁеё®дҪ иҜҶеҲ«иҝҷдёӘжЁЎзүҲзҡ„еҗҚеӯ—
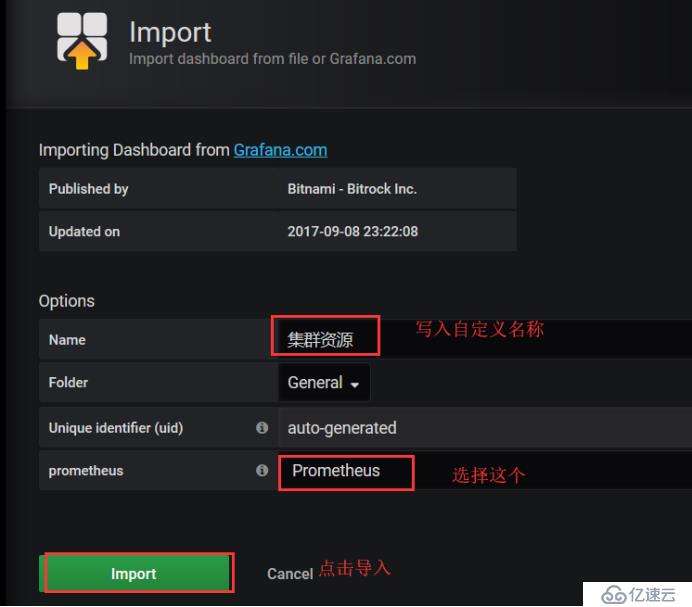
еӣ дёәиҝҷдәӣйғҪжңүж•°жҚ®дәҶпјҢжүҖд»Ҙе°ұзӣҙжҺҘиғҪжҹҘзңӢеҲ°жүҖжңүйӣҶзҫӨзҡ„иө„жәҗ
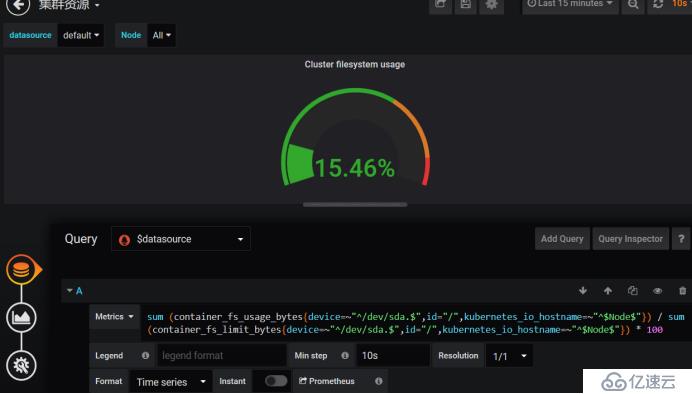
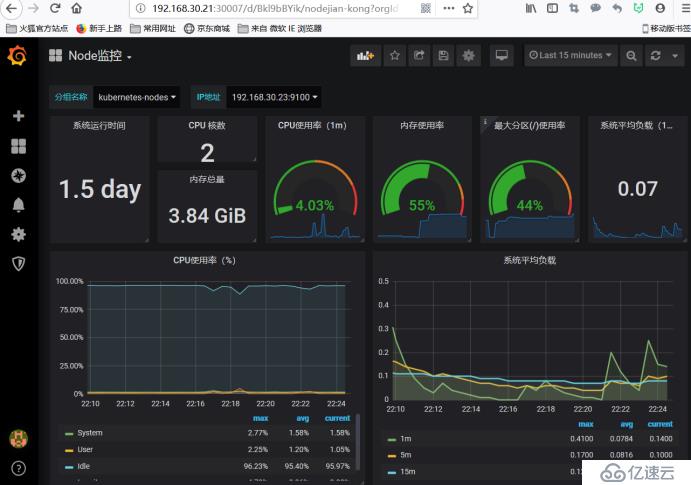
дёӢйқўиҝҷдёӘжҳҜзҪ‘з»ңIOзҡ„еӣҫиЎЁпјҢдёҖдёӘжҳҜжҺҘ收пјҢдёҖдёӘжҳҜеҸ‘йҖҒ
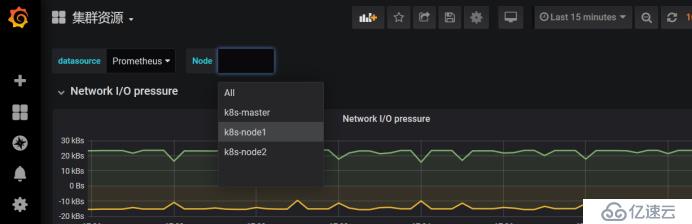
дёӢйқўиҝҷдёӘжҳҜйӣҶзҫӨеҶ…еӯҳзҡ„дҪҝз”Ёжғ…еҶө
иҝҷйҮҢжҳҜ4GпјҢеҸӘиҜҶеҲ«дәҶ3.84G,дҪҝз”Ё2.26GпјҢCPUжҳҜеҸҢж ёпјҢдҪҝз”ЁдәҶ0.11пјҢеҸіиҫ№иҝҷдёӘжҳҜйӣҶзҫӨж–Ү件系з»ҹпјҢдҪҶжҳҜжІЎжңүжҳҫзӨәеҮәжқҘпјҢжҲ‘们еҸҜд»ҘзңӢдёҖдёӢе®ғPromQLжҖҺд№ҲеҶҷзҡ„пјҢжҠҠиҝҷдёӘеҶҷpromQLжӢҝеҲ°promQL UiдёҠжөӢиҜ•дёҖдёӢжңүжІЎжңүж•°жҚ®пјҢдёҖиҲ¬жҳҜжІЎжңүеҢ№й…ҚеҲ°ж•°жҚ®еҜјиҮҙзҡ„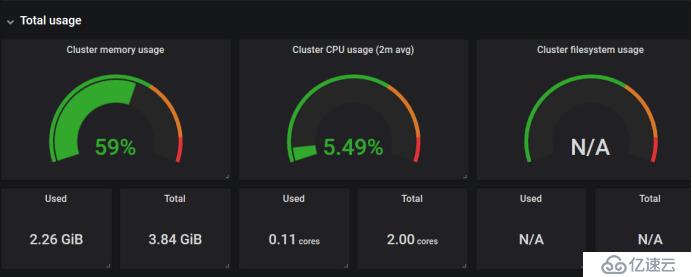
жқҘзңӢдёҖдёӢиҝҷдёӘжҖҺд№Ҳи§ЈеҶі
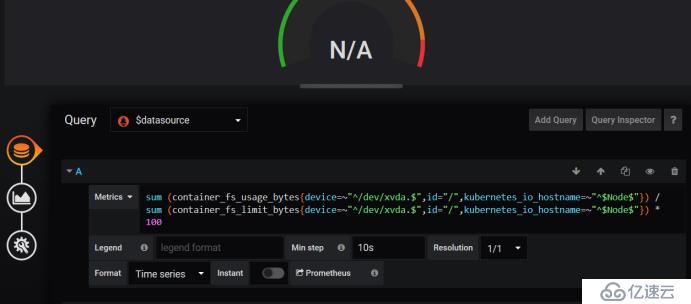
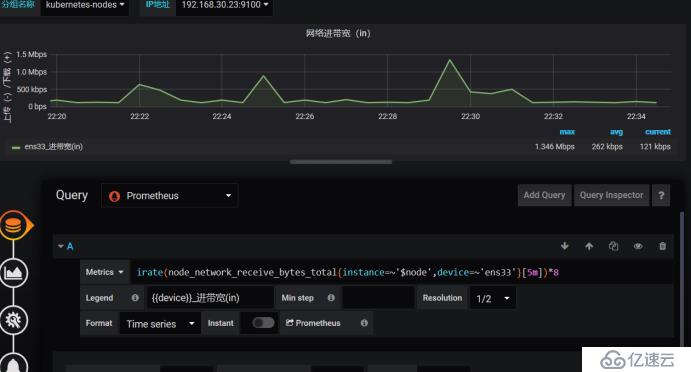
жӢҝиҝҷдёӘж•°жҚ®еҺ»жҜ”еҜ№пјҢжүҫеҲ°ж•°жҚ®пјҢдёҖзӮ№дёҖзӮ№еҺ»еҲ йҷӨпјҢзҺ°еңЁжҲ‘们жүҫеҲ°ж•°жҚ®дәҶпјҢиҝҷйҮҢжҳҜеҢ№й…Қзҡ„дҪ иҠӮзӮ№зҡ„еҗҚз§°пјҢж №жҚ®иҝҷдёӘжҲ‘们еҺ»жүҫпјҢеӣ дёәиҝҷдёӘжЁЎзүҲжҳҜеҲ«дәәдёҠдј зҡ„пјҢжҲ‘们иҮӘе·ұз”ЁиӮҜе®ҡж №жҚ®иҮӘе·ұзҡ„еҶ…е®№еҺ»еҢ№й…ҚпјҢиҝҷйҮҢеҸҜд»ҘеҺ»еҢ№й…Қзӣёе…ізҡ„promQL,然еҗҺж”№дёҖдёӢжҲ‘们grafanaзҡ„promQL,зҺ°еңЁжҳҜиҺ·еҸ–еҲ°ж•°жҚ®дәҶ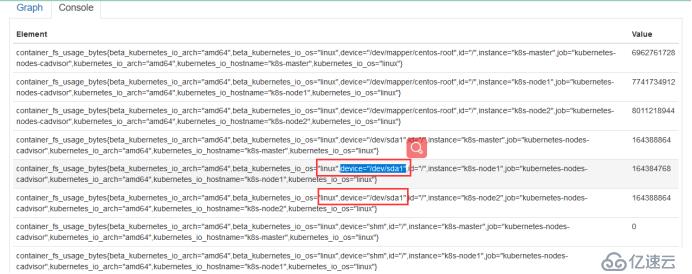
еҸҰеӨ–жҲ‘们еҸҜиғҪиҝҳеҒҡдёҖдәӣе…¶д»–зҡ„жЁЎзүҲзҡ„зӣ‘жҺ§пјҢеҸҜд»ҘеңЁе®ғGrafanaзҡ„е®ҳж–№еҺ»жүҫдёҖдәӣжЁЎзүҲпјҢдҪҶжҳҜжңүзҡ„еҸҜиғҪдёҚиғҪз”ЁпјҢиҮӘе·ұйңҖиҰҒеҺ»дҝ®ж”№пјҢжҜ”еҰӮиҫ“е…Ҙk8s,иҝҷйҮҢжҳҜзӣ‘жҺ§etcdйӣҶзҫӨзҡ„
Node
дҪҝз”Ёnode_exporter收йӣҶеҷЁйҮҮйӣҶиҠӮзӮ№иө„жәҗеҲ©з”ЁзҺҮгҖӮ
https://github.com/prometheus/node_exporter
дҪҝз”Ёж–ҮжЎЈпјҡhttps://prometheus.io/docs/guides/node-exporter/
иҝҷдёӘзӣ®еүҚжІЎжңүдҪҝз”ЁpodеҺ»йғЁзҪІпјҢеӣ дёәжІЎжңүеұ•зӨәеҲ°дёҖдёӘзЈҒзӣҳзҡ„дҪҝз”ЁзҺҮпјҢе®ҳж–№з»ҷеҮәдәҶдёҖдёӘstatfulsetзҡ„ж–№ејҸпјҢж— жі•еұ•зӨәзЈҒзӣҳпјҢдёҚиҝҮд№ҹеҸҜд»Ҙд»ҘдёҖдёӘе®ҲжҠӨиҝӣзЁӢзҡ„ж–№ејҸйғЁзҪІеңЁnode иҠӮзӮ№дёҠпјҢиҝҷдёӘйғЁзҪІд№ҹжҜ”иҫғз®ҖеҚ•пјҢд»ҘдәҢиҝӣеҲ¶зҡ„ж–№ејҸеҺ»йғЁзҪІпјҢеңЁе®ҝдё»жңәдёҠеҗҜеҠЁдёҖдёӘе°ұеҸҜд»ҘдәҶ
зңӢдёҖдёӢиҝҷдёӘи„ҡжң¬пјҢжҳҜд»ҘsystemdеҺ»иҝҮж»ӨжңҚеҠЎеҗҜеҠЁзӣ‘жҺ§зҡ„зҠ¶жҖҒпјҢеҰӮжһңе®ҲжҠӨиҝӣзЁӢжҢӮдәҶиҜқпјҢд№ҹдјҡиў«PrometheusйҮҮйӣҶеҲ°д№ҹе°ұжҳҜдёӢйқўиҝҷдёӘеҸӮж•°--collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).service
[root@k8s-node1 ~]# bash node_exporter.sh
#!/bin/bash
wget https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
tar zxf node_exporter-0.17.0.linux-amd64.tar.gz
mv node_exporter-0.17.0.linux-amd64 /usr/local/node_exporter
cat <<EOF >/usr/lib/systemd/system/node_exporter.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).service
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable node_exporter
systemctl restart node_exporterprometheusжҳҜдё»еҠЁзҡ„еҺ»йҮҮйӣҶиө„жәҗзҡ„жҢҮж ҮпјҢиҖҢдёҚжҳҜиў«еҠЁзҡ„иў«зӣ‘жҺ§з«ҜжҺЁйҖҒиҝҷдәӣж•°жҚ®
然еҗҺдҪҝз”Ёзҡ„жҳҜ9276иҝҷдёӘжЁЎзүҲпјҢжҲ‘们еҸҜд»Ҙе…Ҳи®©иҝҷдёӘжЁЎзүҲеҜје…ҘиҝӣжқҘ
[root@k8s-node1 ~]# ps -ef |grep node_ex
root 5275 1 0 21:59 ? 00:00:03 /usr/local/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|kubelet|kube-proxy|flanneld).service
root 7393 81364 0 22:15 pts/1 00:00:00 grep --color=auto node_exйҖүжӢ©nodes ,иҝҷйҮҢеҸҜд»ҘзңӢеҲ°дёӨдёӘиҠӮзӮ№зҡ„иө„жәҗзҠ¶жҖҒ
иҺ·еҸ–зҪ‘з»ңеёҰе®ҪеӨұиҙҘпјҢ然еҗҺжҲ‘们еҸҜд»ҘеҺ»жөӢиҝҷдёӘpromeQLпјҢдёҖиҲ¬иҝҷдёӘжғ…еҶөе°ұжҳҜжҹҘзңӢзҪ‘еҚЎзҡ„жҺҘеҸЈеҗҚз§°пјҢжңүзҡ„жҳҜeth0пјҢжңүзҡ„жҳҜens32,ens33пјҢиҝҷдёӘж №жҚ®иҮӘе·ұзҡ„еҺ»еҶҷ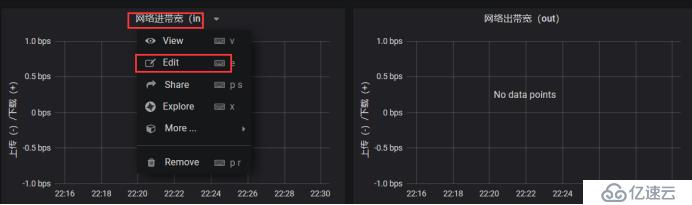
зӮ№еҮ»иҝҷдёӘдҝқеӯҳ
зҺ°еңЁе°ұжңүдәҶ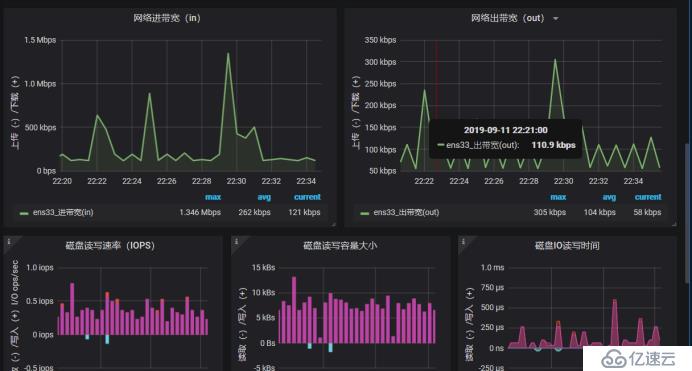
K8sиө„жәҗеҜ№иұЎзҡ„зӣ‘жҺ§
е…·дҪ“е®һзҺ° kube-state-metrics ,иҝҷз§Қзұ»еһӢpod/deployment/service
иҝҷдёӘ组件жҳҜе®ҳж–№ејҖеҸ‘зҡ„пјҢйҖҡиҝҮAPIеҺ»иҺ·еҸ–k8sиө„жәҗзҡ„зҠ¶жҖҒпјҢйҖҡиҝҮmetricsжқҘе®ҢжҲҗж•°жҚ®зҡ„йҮҮйӣҶгҖӮжҜ”еҰӮеүҜжң¬ж•°жҳҜеӨҡе°‘пјҢеҪ“еүҚжҳҜд»Җд№ҲзҠ¶жҖҒдәҶпјҢжҳҜиҺ·еҸ–иҝҷдәӣзҡ„
еҪ“然githubдёҠйғҪжңүиҝҷдәӣпјҢеҸӘйңҖиҰҒжҠҠеӣҪеӨ–зҡ„жәҗжҚўжҲҗеӣҪеӨ–зҡ„е°ұеҸҜд»ҘдәҶпјҢжҲ–иҖ…жҚўжҲҗжҲ‘зҡ„пјҢжҲ‘е·Із»ҸжҠҠй•ңеғҸдёҠдј еҲ°docker hubдёҠдәҶгҖӮ
https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
еҲӣе»әrbacжҺҲжқғ规еҲҷ
[root@k8s-master prometheus-k8s]# cat kube-state-metrics-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources:
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- statefulsets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: kube-state-metrics-resizer
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get"]
- apiGroups: ["extensions"]
resources:
- deployments
resourceNames: ["kube-state-metrics"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics-resizer
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-systemеҲӣе»әdeployment
[root@k8s-master prometheus-k8s]# cat kube-state-metrics-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v1.3.0
spec:
selector:
matchLabels:
k8s-app: kube-state-metrics
version: v1.3.0
replicas: 1
template:
metadata:
labels:
k8s-app: kube-state-metrics
version: v1.3.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: zhaocheng172/kube-state-metrics:v1.3.0
ports:
- name: http-metrics
containerPort: 8080
- name: telemetry
containerPort: 8081
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
- name: addon-resizer
image: zhaocheng172/addon-resizer:1.8.3
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 30Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --container=kube-state-metrics
- --cpu=100m
- --extra-cpu=1m
- --memory=100Mi
- --extra-memory=2Mi
- --threshold=5
- --deployment=kube-state-metrics
volumes:
- name: config-volume
configMap:
name: kube-state-metrics-config
---
# Config map for resource configuration.
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-state-metrics-config
namespace: kube-system
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfigurationеҲӣе»әжҡҙйңІзҡ„з«ҜеҸЈпјҢиҝҷйҮҢдҪҝз”Ёзҡ„жҳҜservice
[root@k8s-master prometheus-k8s]# cat kube-state-metrics-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "kube-state-metrics"
annotations:
prometheus.io/scrape: 'true'
spec:
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
protocol: TCP
- name: telemetry
port: 8081
targetPort: telemetry
protocol: TCP
selector:
k8s-app: kube-state-metricsйғЁзҪІжҲҗеҠҹд№ӢеҗҺпјҢеҜје…ҘжЁЎзүҲе°ұиғҪзӣ‘жҺ§еҲ°жҲ‘们зҡ„ж•°жҚ®
[root@k8s-master prometheus-k8s]# kubectl get pod,svc -n kube-system
NAME READY STATUS RESTARTS AGE
pod/coredns-bccdc95cf-kqxwv 1/1 Running 3 2d9h
pod/coredns-bccdc95cf-nwkbp 1/1 Running 3 2d9h
pod/etcd-k8s-master 1/1 Running 2 2d9h
pod/grafana-0 1/1 Running 0 4h60m
pod/kube-apiserver-k8s-master 1/1 Running 2 2d9h
pod/kube-controller-manager-k8s-master 1/1 Running 5 2d9h
pod/kube-flannel-ds-amd64-dc5z9 1/1 Running 1 2d9h
pod/kube-flannel-ds-amd64-jm2jz 1/1 Running 1 2d9h
pod/kube-flannel-ds-amd64-z6tt2 1/1 Running 1 2d9h
pod/kube-proxy-9ltx7 1/1 Running 2 2d9h
pod/kube-proxy-lnzrj 1/1 Running 1 2d9h
pod/kube-proxy-v7dqm 1/1 Running 1 2d9h
pod/kube-scheduler-k8s-master 1/1 Running 5 2d9h
pod/kube-state-metrics-6474469878-6kpxv 1/2 Running 0 4s
pod/kube-state-metrics-854b85d88-zl777 2/2 Running 0 35s
pod/prometheus-0 2/2 Running 0 5h40mиҝҳжҳҜеҲҡжүҚжӯҘйӘӨдёҖж ·пјҢеҜје…ҘдёҖдёӘ6417зҡ„жЁЎзүҲ
ж•°жҚ®зҺ°еңЁе·Із»Ҹеұ•зӨәеҮәжқҘдәҶпјҢе®ғдјҡд»ҺtargetйҮҢйқўиҺ·еҸ–еҲ°иҝҷдәӣж•°жҚ®пјҢд№ҹе°ұжҳҜиҝҷдёӘжқҘжҸҗдҫӣзҡ„пјҢз”ұprometheusиҮӘеҠЁзҡ„еҸ‘зҺ°дәҶгҖӮе®ғиҝҷдёӘеҸ‘зҺ°жҳҜж №жҚ®йҮҢйқўзҡ„дёҖдёӘжіЁи§ЈжқҘиҺ·еҸ–зҡ„пјҢд№ҹе°ұжҳҜеңЁserviceйҮҢйқў
annotations:
prometheus.io/scrape: 'true'
д№ҹе°ұжҳҜеЈ°жҳҺдәҶйғЁзҪІдәҶе“Әдәӣеә”з”ЁпјҢеҸҜд»Ҙиў«prometheusеҺ»иҮӘеҠЁзҡ„еҸ‘зҺ°,еҰӮжһңеҠ иҝҷжқЎи§„еҲҷпјҢprometheusдјҡиҮӘеҠЁжҠҠиҝҷдәӣеёҰжіЁи§Јзҡ„зӣ‘жҺ§еҲ°пјҢд№ҹе°ұжҳҜиҮӘе·ұйғЁзҪІзҡ„еә”з”ЁпјҢ并жҸҗдҫӣзӣёеә”зҡ„жҢҮж ҮпјҢд№ҹиғҪиҮӘеҠЁеҸ‘зҺ°иҝҷдәӣзҠ¶жҖҒгҖӮ
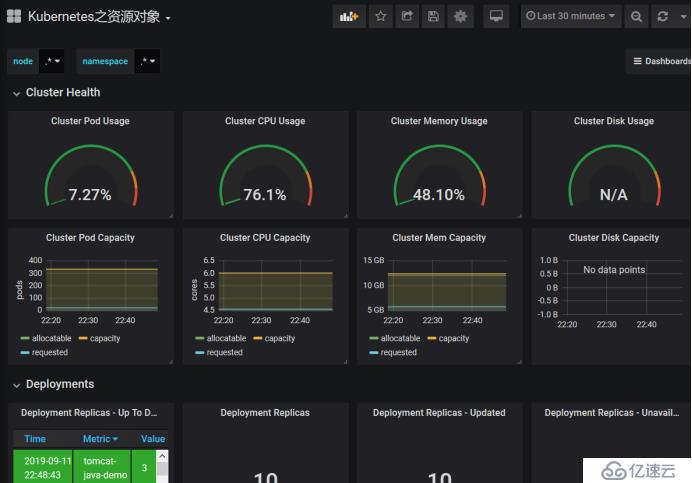
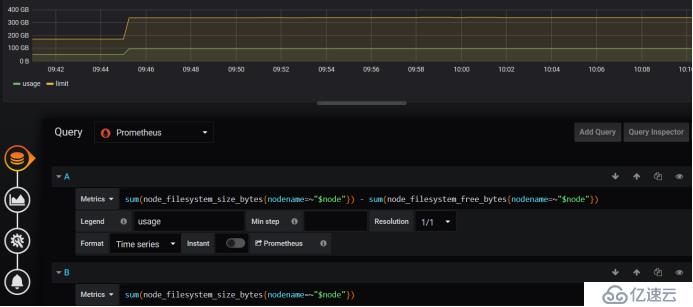
зЈҒзӣҳиҝҷйҮҢйңҖиҰҒжӣҙж”№дёҖдёӘеӣ дёәиҝҷйҮҢжӣҙж–°дәҶпјҢж·»еҠ bytes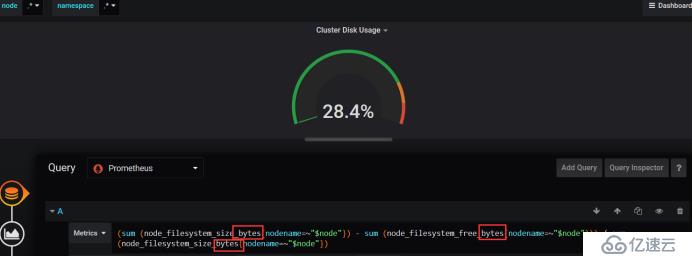
дёӢйқўиҝҷйҮҢжҳҜpodзҡ„е®№йҮҸпјҢжңҖеӨ§еҸҜд»ҘеҲӣе»әзҡ„ж•°йҮҸпјҢд№ҹе°ұжҳҜkubeletеҺ»йҷҗеҲ¶зҡ„пјҢжҖ»е…ұдёҖдёӘиҠӮзӮ№еҸҜд»ҘеҲӣе»ә330дёӘpod,е·Із»ҸеҲҶй…Қ24дёӘгҖӮ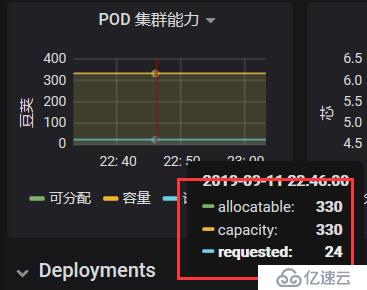
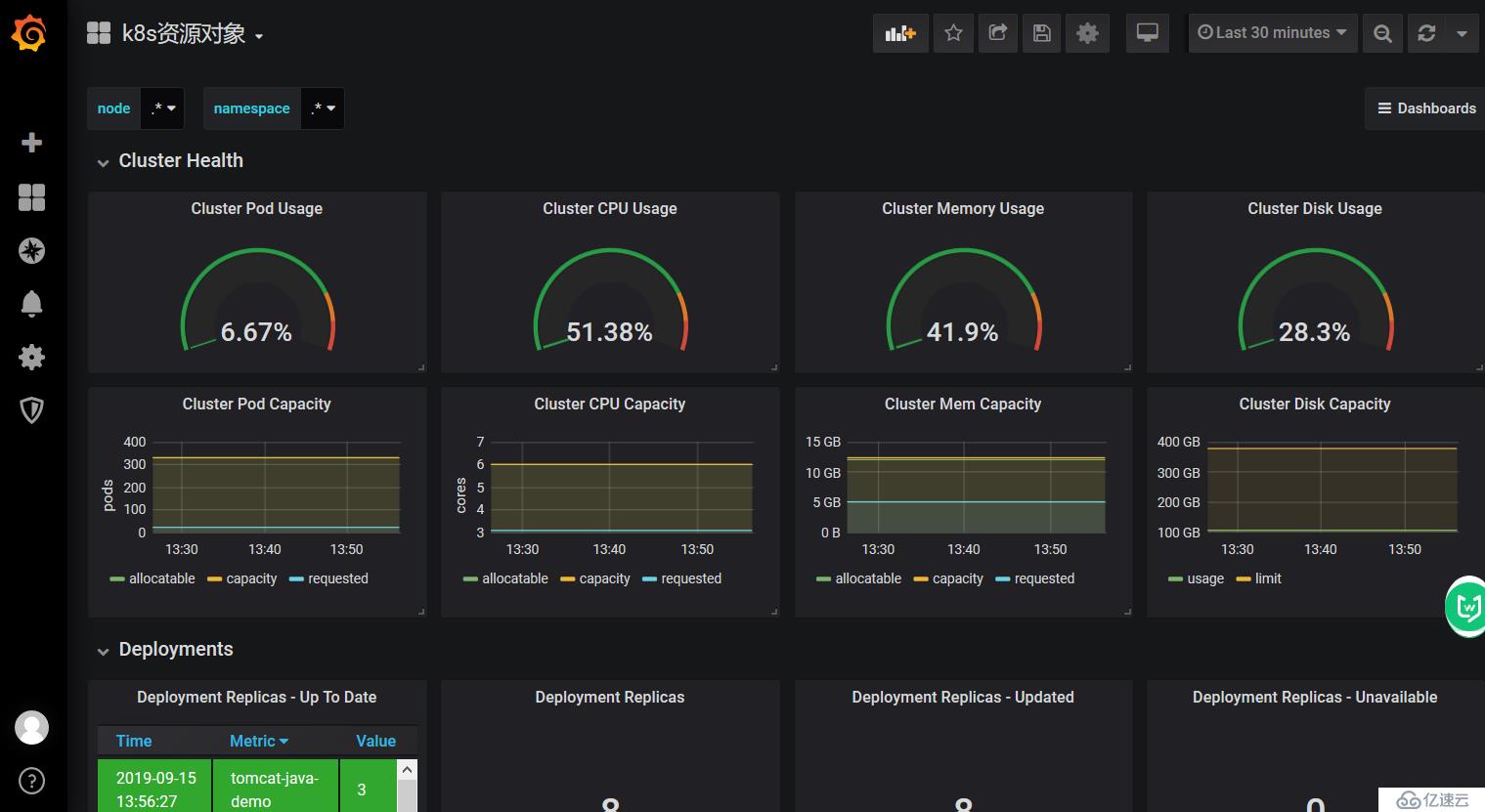
е°Ҹз»“пјҡ
жүҖд»ҘжңүдәҶиҝҷдәӣзӣ‘жҺ§пјҢеҹәжң¬дёҠе°ұиғҪдәҶи§Јk8sзҡ„еҹәжң¬иө„жәҗзҡ„дҪҝз”ЁзҠ¶жҖҒдәҶ
е…«гҖҒе‘ҠиӯҰ规еҲҷдёҺе‘ҠиӯҰйҖҡзҹҘ
еңЁK8SдёӯйғЁзҪІAlertmanager
иҜҙеңЁеүҚйқўзҡ„иҜқпјҢеңЁk8sдҪҝз”Ёе‘ҠиӯҰдҪҝз”Ёзҡ„жҳҜAlertmanagerпјҢе…Ҳе®ҡд№үзӣ‘жҺ§йў„еҖјзҡ„规еҲҷпјҢжҜ”еҰӮnodeзҡ„еҶ…еӯҳеҲ°иҫҫ60%пјҢжүҚиғҪе‘ҠиӯҰпјҢе…Ҳе®ҡд№үеҘҪиҝҷдәӣ规еҲҷпјҢеҰӮжһңprometheusйҮҮйӣҶзҡ„жҢҮж ҮпјҢеҢ№й…ҚеҲ°иҝҷдёӘ规еҲҷпјҢе°ұжҳҜдёәзңҹзҡ„иҜқпјҢе®ғдјҡеҸ‘йҖҒе‘ҠиӯҰпјҢдјҡе°ҶиҝҷдёӘдёӘе‘ҠиӯҰдҝЎжҒҜжҺЁйҖҒз»ҷ
Alertmanager,Alertmanagerз»ҸиҝҮдёҖзі»еҲ—зҡ„еӨ„зҗҶпјҢжңҖз»ҲеҸ‘йҖҒеҲ°е‘ҠиӯҰдәәжүӢдёҠпјҢеҸҜд»ҘжҳҜwebhookпјҢemail,й’үй’үпјҢдјҒдёҡеҫ®дҝЎпјҢзӣ®еүҚжҲ‘们жӢҝemailжқҘеҒҡд»ҘдёӢе®һдҫӢпјҢдјҒдёҡеҫ®дҝЎйңҖиҰҒжіЁеҶҢдјҒдёҡзҡ„дёҖдәӣзӣёе…ідҝЎжҒҜиҗҘдёҡжү§з…§зӯүпјҢиҖҢwebhookйңҖиҰҒеҜ№жҺҘ第дёүж–№зҡ„зі»з»ҹи°ғдёҖдёӘжҺҘеҸЈеҺ»дј еҖјпјҢemailй»ҳи®ӨйғҪж”ҜжҢҒпјҢprometheusеҺҹз”ҹжҳҜдёҚж”ҜжҢҒй’үй’үзҡ„,еҰӮжһңжғіж”ҜжҢҒзҡ„иҜқпјҢйңҖиҰҒжүҫ第дёүж–№пјҢеҒҡиҝҷдёӘж•°жҚ®иҪ¬жҚўзҡ„组件гҖӮеӣ дёәpromethesдј е…Ҙзҡ„ж•°жҚ®пјҢе®ғдёҺй’үй’үдј е…Ҙзҡ„ж•°жҚ®жҳҜдёҚеҢ№й…Қзҡ„пјҢжүҖжңүжңүдёӯй—ҙзҡ„зЁӢеәҸж•°жҚ®д№Ӣй—ҙиҝӣиЎҢиҪ¬жҚўпјҢзҺ°еңЁд№ҹжңүејҖжәҗзҡ„еҸҜд»ҘеҺ»е®һзҺ°гҖӮеҹәжң¬жөҒзЁӢе°ұиЎҢиҝҷж ·зҡ„пјҢжҲ‘们е®ҡд№үзҡ„规еҲҷйғҪжҳҜеңЁprometheusдёӯ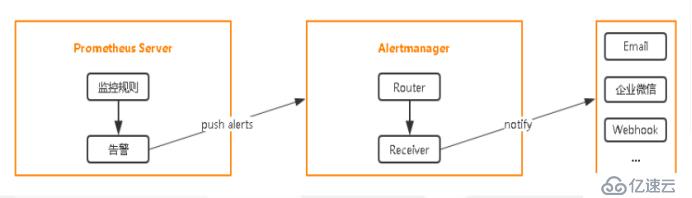
еңЁK8SдёӯйғЁзҪІAlertmanager
иҝҷйҮҢжҳҜе®ҡд№үи°ҒеҸ‘йҖҒиҝҷдёӘе‘ҠиӯҰдҝЎжҒҜзҡ„пјҢи°ҒжҺҘ收иҝҷдёӘйӮ®д»¶
[root@k8s-master prometheus-k8s]# vim alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
data:
alertmanager.yml: |
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'baojingtongzhi@163.com'
smtp_auth_username: 'baojingtongzhi@163.com'
smtp_auth_password: 'liang123'
receivers:
- name: default-receiver
email_configs:
- to: "17733661341@163.com"
route:
group_interval: 1m
group_wait: 10s
receiver: default-receiver
repeat_interval: 1m[root@k8s-master prometheus-k8s]# cat alertmanager-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-system
labels:
k8s-app: alertmanager
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v0.14.0
spec:
replicas: 1
selector:
matchLabels:
k8s-app: alertmanager
version: v0.14.0
template:
metadata:
labels:
k8s-app: alertmanager
version: v0.14.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
containers:
- name: prometheus-alertmanager
image: "prom/alertmanager:v0.14.0"
imagePullPolicy: "IfNotPresent"
args:
- --config.file=/etc/config/alertmanager.yml
- --storage.path=/data
- --web.external-url=/
ports:
- containerPort: 9093
readinessProbe:
httpGet:
path: /#/status
port: 9093
initialDelaySeconds: 30
timeoutSeconds: 30
volumeMounts:
- name: config-volume
mountPath: /etc/config
- name: storage-volume
mountPath: "/data"
subPath: ""
resources:
limits:
cpu: 10m
memory: 50Mi
requests:
cpu: 10m
memory: 50Mi
- name: prometheus-alertmanager-configmap-reload
image: "jimmidyson/configmap-reload:v0.1"
imagePullPolicy: "IfNotPresent"
args:
- --volume-dir=/etc/config
- --webhook-url=http://localhost:9093/-/reload
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: true
resources:
limits:
cpu: 10m
memory: 10Mi
requests:
cpu: 10m
memory: 10Mi
volumes:
- name: config-volume
configMap:
name: alertmanager-config
- name: storage-volume
persistentVolumeClaim:
claimName: alertmanager
жҹҘзңӢжҲ‘们зҡ„pvcиҝҷйҮҢд№ҹжҳҜдҪҝз”Ёзҡ„жҲ‘们зҡ„иҮӘеҠЁдҫӣз»ҷmanaged-nfs-storage
[root@k8s-master prometheus-k8s]# cat alertmanager-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: EnsureExists
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteOnce
resources:
requests:
storage: "2Gi"иҝҷйҮҢдҪҝз”Ёзҡ„жҳҜзұ»еһӢдёәcluster IP
[root@k8s-master prometheus-k8s]# cat alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "Alertmanager"
spec:
ports:
- name: http
port: 80
protocol: TCP
targetPort: 9093
selector:
k8s-app: alertmanager
type: "ClusterIP"然еҗҺжҠҠжҲ‘们зҡ„иө„жәҗйғҪеҲӣе»әеҘҪ
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-configmap.yaml
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-deployment.yaml
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-pvc.yaml
[root@k8s-master prometheus-k8s]# kubectl create -f alertmanager-service.yaml
[root@k8s-master prometheus-k8s]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
alertmanager-5d75d5688f-xw2qg 2/2 Running 0 66s
coredns-bccdc95cf-kqxwv 1/1 Running 2 6d
coredns-bccdc95cf-nwkbp 1/1 Running 2 6d
etcd-k8s-master 1/1 Running 1 6d
grafana-0 1/1 Running 0 14h
kube-apiserver-k8s-master 1/1 Running 1 6d
kube-controller-manager-k8s-master 1/1 Running 2 6d
kube-flannel-ds-amd64-dc5z9 1/1 Running 1 5d23h
kube-flannel-ds-amd64-jm2jz 1/1 Running 1 5d23h
kube-flannel-ds-amd64-z6tt2 1/1 Running 1 6d
kube-proxy-9ltx7 1/1 Running 2 6d
kube-proxy-lnzrj 1/1 Running 1 5d23h
kube-proxy-v7dqm 1/1 Running 1 5d23h
kube-scheduler-k8s-master 1/1 Running 2 6d
kube-state-metrics-6474469878-lkphv 2/2 Running 0 98m
prometheus-0 2/2 Running 0 15h然еҗҺд№ҹеҸҜд»ҘеңЁжҲ‘们зҡ„prometheusдёҠзңӢеҲ°жҲ‘们и®ҫзҪ®зҡ„е‘ҠиӯҰ规еҲҷ
然еҗҺжҲ‘们жөӢиҜ•дёҖдёӢжҲ‘们зҡ„е‘ҠиӯҰпјҢдҝ®ж”№дёҖдёӢжҲ‘们зҡ„prometheusзҡ„rules
жҠҠnodeзЈҒзӣҳиө„жәҗи®ҫзҪ®дёә>20 е°ұжҠҘиӯҰ
[root@k8s-master prometheus-k8s]# vim prometheus-rules.yaml
- alert: NodeFilesystemUsage
expr: 100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs"} / node_filesystem_size_bytes{fstype=~"ext4|xfs"} * 100) > 20йҮҚе»әдёҖдёӢpodпјҢиҝҷйҮҢдјҡиҮӘеҠЁеҗҜеҠЁпјҢжҹҘзңӢprometheus,е·Із»Ҹз”ҹж•ҲпјҢеҸҰеӨ–дёҠдә§зҺҜеўғйғҪжҳҜеҺ»и°ғз”ЁapiпјҢеҸ‘йҖҒдёҖдёӘдҝЎеҸ·з»ҷrules,иҝҷйҮҢжҲ‘жҳҜйҮҚе»әзҡ„пјҢд№ҹеҸҜд»ҘжүҫдёҖдәӣзҪ‘дёҠзҡ„е…¶д»–ж–Үз«
[root@k8s-master prometheus-k8s]# kubectl delete pod prometheus-0 -n kube-system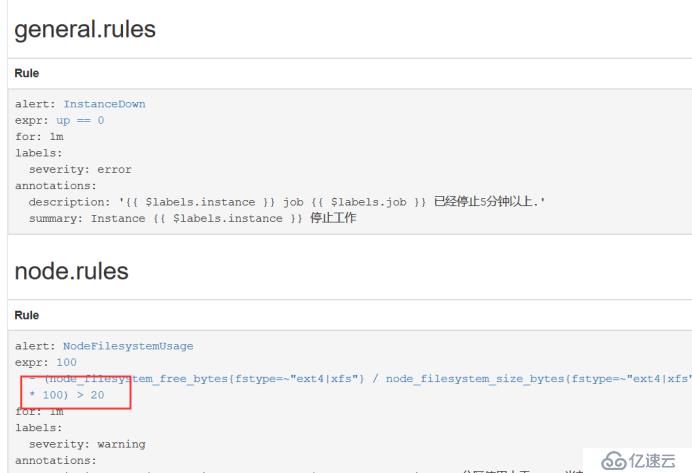
жҹҘзңӢAlertsпјҢиҝҷйҮҢдјҡеҸҳйўңиүІпјҢзӯүдјҡдјҡеҸҳжҲҗзәўиүІпјҢд№ҹе°ұжҳҜalertmanagerе®ғжҳҜжңүдёҖдёӘеӨ„зҗҶзҡ„йҖ»иҫ‘зҡ„пјҢиҝҳжҳҜжҜ”иҫғеӨҚжқӮзҡ„пјҢе®ғдјҡи®ҫи®ЎеҲ°дёҖдёӘйқҷй»ҳпјҢе°ұжҳҜе‘ҠиӯҰ收ж•ӣиҝҷдёҖеқ—пјҢиҝҳжңүдёҖдёӘеҲҶз»„пјҢиҝҳжңүдёҖдёӘеҶҚж¬Ўзӯүеҫ…зҡ„зҡ„зЎ®и®ӨпјҢжүҖжңүдёҚжҳҜдёҖи§ҰеҸ‘е°ұеҸ‘йҖҒ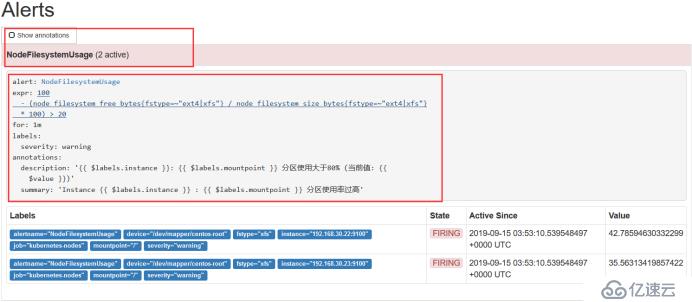
зІүзәўиүІе…¶е®һе·Із»Ҹе°Ҷе‘ҠиӯҰжҺЁйҖҒз»ҷAlertmanagerдәҶпјҢд№ҹе°ұжҳҜиҝҷдёӘзҠ¶жҖҒдёӢжүҚеҺ»еҸ‘йҖҒиҝҷдёӘе‘ҠиӯҰдҝЎжҒҜ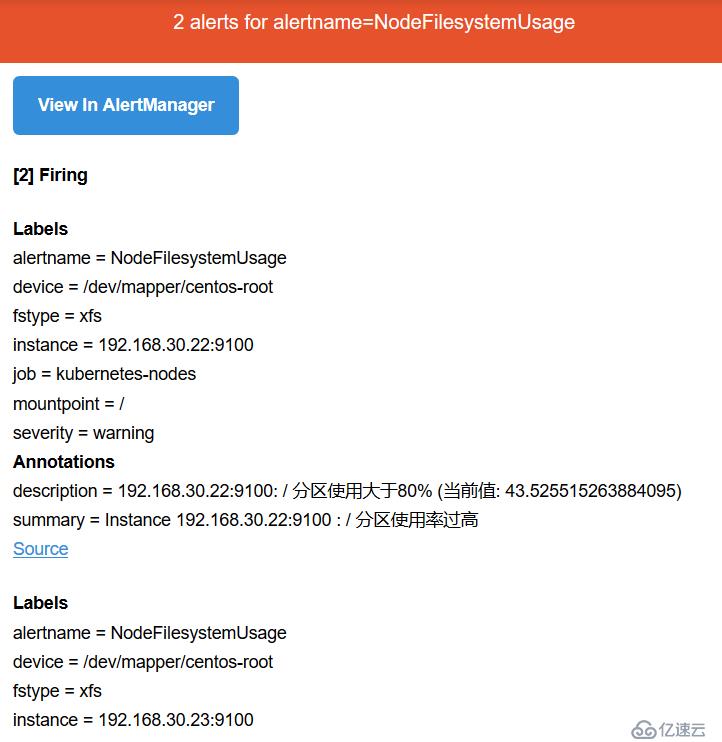
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ