您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Java爬虫中怎么爬取需要登录的网站,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
在做爬虫时,遇到需要登陆的问题也比较常见,比如写脚本抢票之类的,但凡需要个人信息的都需要登陆,对于这类问题主要有两种解决方式:一种方式是手动设置 cookie ,就是先在网站上面登录,复制登陆后的 cookies ,在爬虫程序中手动设置 HTTP 请求中的 Cookie 属性,这种方式适用于采集频次不高、采集周期短,因为 cookie 会失效,如果长期采集的话就需要频繁设置 cookie,这不是一种可行的办法,第二种方式就是使用程序模拟登陆,通过模拟登陆获取到 cookies,这种方式适用于长期采集该网站,因为每次采集都会先登陆,这样就不需要担心 cookie 过期的问题。
为了能让大家更好的理解这两种方式的运用,我以获取豆瓣个人主页昵称为例,分别用这两种方式来获取需要登陆后才能看到的信息。获取信息如下图所示:
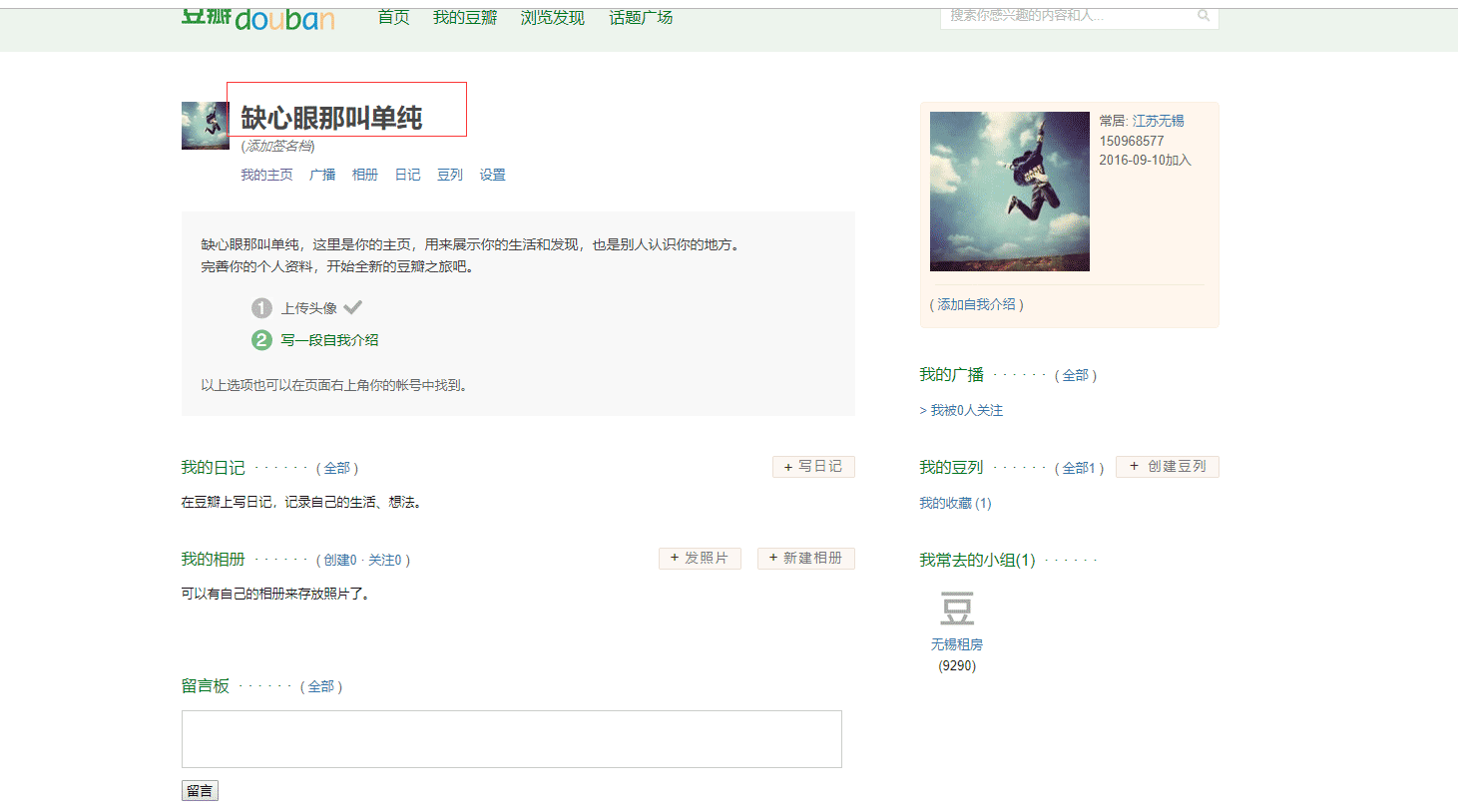
获取图片中的缺心眼那叫单纯,这个信息显然是需要登陆后才能看到的,这就符合我们的主题啦。接下来分别用上面两种办法来解决这个问题。
手动设置 cookie
手动设置 cookie 的方式,这种方式比较简单,我们只需要在豆瓣网上登陆,登陆成功后就可以获取到带有用户信息的cookie,豆瓣网登录链接:https://accounts.douban.com/passport/login。如下图所示:
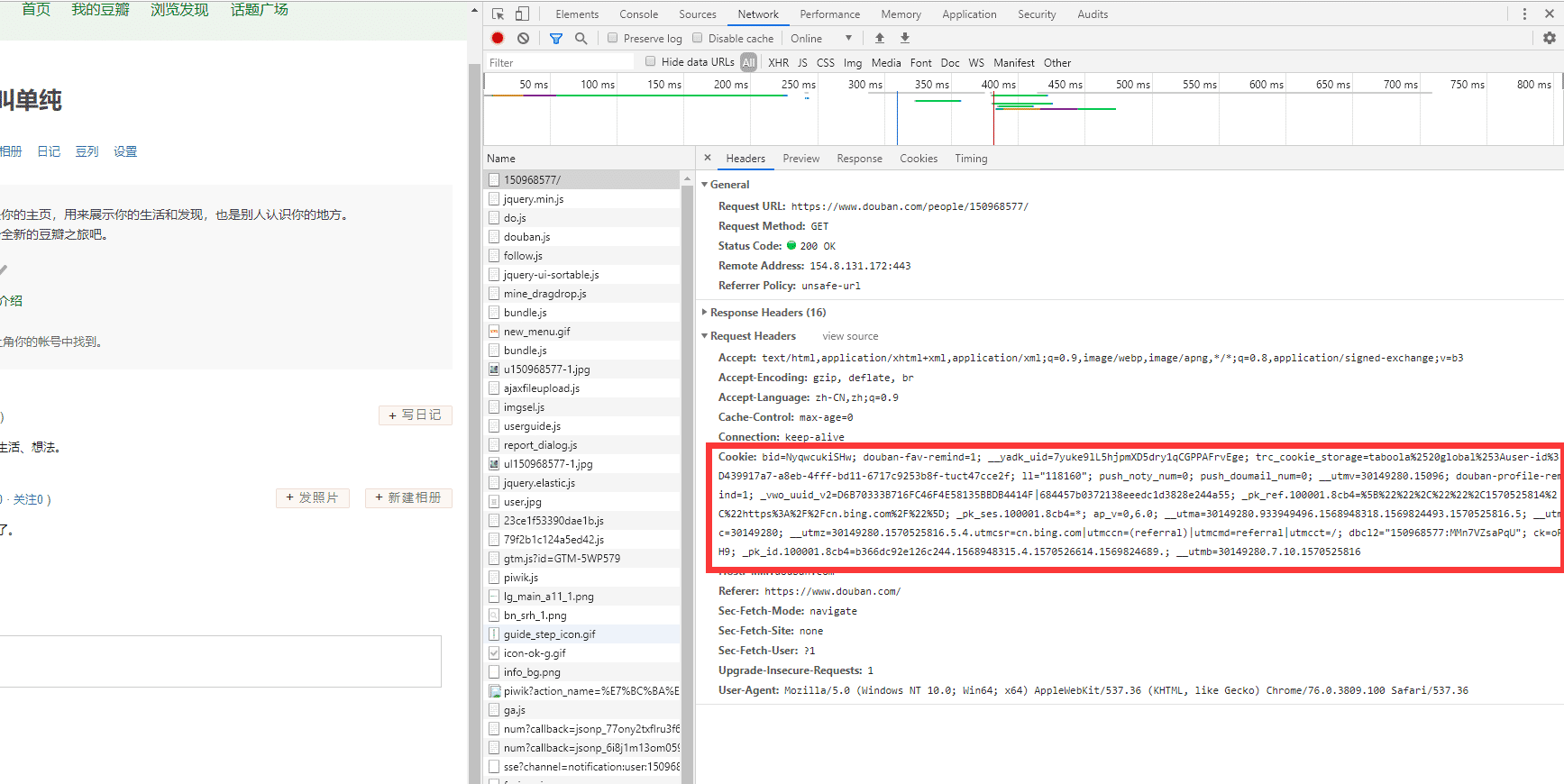
图中的这个 cookie 就携带了用户信息,我们只需要在请求时携带这个 cookie 就可以查看到需要登陆后才能查看到的信息。我们用 Jsoup 来模拟一下手动设置 cookie 方式,具体代码如下:
/**
* 手动设置 cookies
* 先从网站上登录,然后查看 request headers 里面的 cookies
* @param url
* @throws IOException
*/
public void setCookies(String url) throws IOException {
Document document = Jsoup.connect(url)
// 手动设置cookies
.header("Cookie", "your cookies")
.get();
//
if (document != null) {
// 获取豆瓣昵称节点
Element element = document.select(".info h2").first();
if (element == null) {
System.out.println("没有找到 .info h2 标签");
return;
}
// 取出豆瓣节点昵称
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}从代码中可以看出跟不需要登陆的网站没什么区别,只是多了一个.header("Cookie", "your cookies") ,我们把浏览器中的 cookie 复制到这里即可,编写 main 方法
public static void main(String[] args) throws Exception {
// 个人中心url
String user_info_url = "https://www.douban.com/people/150968577/";
new CrawleLogin().setCookies(user_info_url);运行 main 得到结果如下:
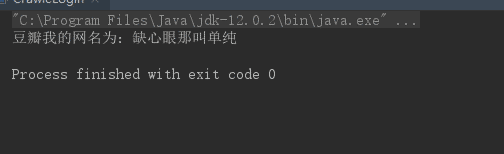
可以看出我们成功获取到了缺心眼那叫单纯,这说明我们设置的 cookie 是有效的,成功的拿到了需要登陆的数据。这种方式是真的比较简单,唯一的不足就是需要频繁的更换 cookie,因为 cookie 会失效,这让你使用起来就不是很爽啦。
模拟登陆方式
模拟登陆的方式可以解决手动设置 cookie 方式的不足之处,但同时也引入了比较复杂的问题,现在的验证码形形色色、五花八门,很多都富有挑战性,比如在一堆图片中操作某类图片,这个还是非常有难度,不是随便就能够编写出来。所以对于使用哪种方式这个就需要开发者自己去衡量利弊啦。今天我们用到的豆瓣网,在登陆的时候就没有验证码,对于这种没有验证码的还是比较简单的,关于模拟登陆方式最重要的就是找到真正的登陆请求、登陆需要的参数。 这个我们就只能取巧了,我们先在登陆界面输入错误的账号密码,这样页面将不会跳转,所以我们就能够轻而易举的找到登陆请求。我来演示一下豆瓣网登陆查找登陆链接,我们在登陆界面输入错误的用户名和密码,点击登陆后,在 network 查看发起的请求链接,如下图所示:
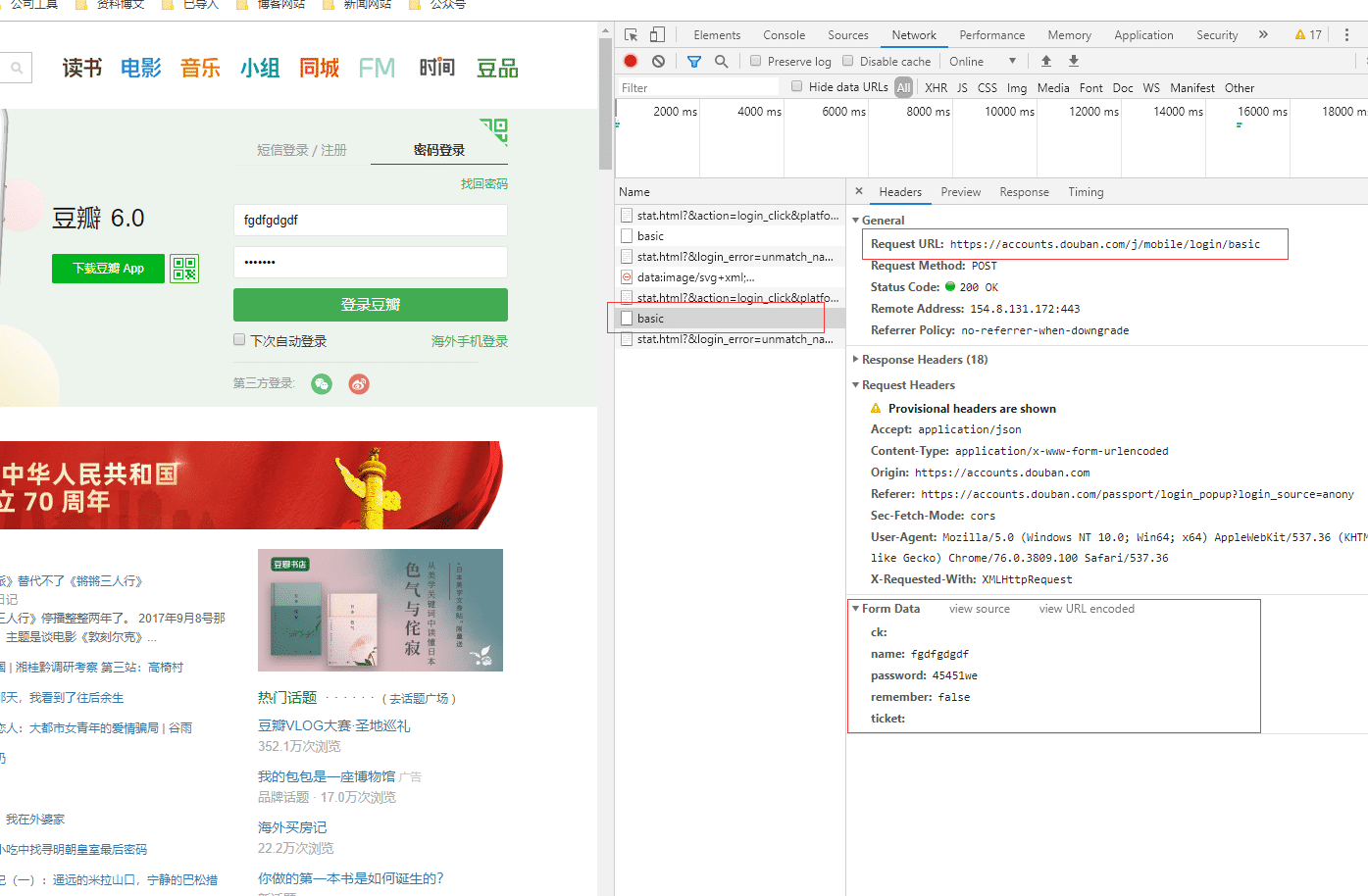
从 network 中我们可以查看到豆瓣网的登陆链接为https://accounts.douban.com/j/mobile/login/basic,需要的参数有五个,具体参数查看图中的 Form Data,有了这些之后,我们就能够构造请求模拟登陆啦。登陆后进行后续操作,接下来我们就用 Jsoup 来模拟登陆到获取豆瓣主页昵称,具体代码如下:
/**
* Jsoup 模拟登录豆瓣 访问个人中心
* 在豆瓣登录时先输入一个错误的账号密码,查看到登录所需要的参数
* 先构造登录请求参数,成功后获取到cookies
* 设置request cookies,再次请求
* @param loginUrl 登录url
* @param userInfoUrl 个人中心url
* @throws IOException
*/
public void jsoupLogin(String loginUrl,String userInfoUrl) throws IOException {
// 构造登陆参数
Map<String,String> data = new HashMap<>();
data.put("name","your_account");
data.put("password","your_password");
data.put("remember","false");
data.put("ticket","");
data.put("ck","");
Connection.Response login = Jsoup.connect(loginUrl)
.ignoreContentType(true) // 忽略类型验证
.followRedirects(false) // 禁止重定向
.postDataCharset("utf-8")
.header("Upgrade-Insecure-Requests","1")
.header("Accept","application/json")
.header("Content-Type","application/x-www-form-urlencoded")
.header("X-Requested-With","XMLHttpRequest")
.header("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
.data(data)
.method(Connection.Method.POST)
.execute();
login.charset("UTF-8");
// login 中已经获取到登录成功之后的cookies
// 构造访问个人中心的请求
Document document = Jsoup.connect(userInfoUrl)
// 取出login对象里面的cookies
.cookies(login.cookies())
.get();
if (document != null) {
Element element = document.select(".info h2").first();
if (element == null) {
System.out.println("没有找到 .info h2 标签");
return;
}
String userName = element.ownText();
System.out.println("豆瓣我的网名为:" + userName);
} else {
System.out.println("出错啦!!!!!");
}
}这段代码分两段,前一段是模拟登陆,后一段是解析豆瓣主页,在这段代码中发起了两次请求,第一次请求是模拟登陆获取到 cookie,第二次请求时携带第一次模拟登陆后获取的cookie,这样也可以访问需要登陆的页面,修改 main 方法
public static void main(String[] args) throws Exception {
// 个人中心url
String user_info_url = "https://www.douban.com/people/150968577/";
// 登陆接口
String login_url = "https://accounts.douban.com/j/mobile/login/basic";
// new CrawleLogin().setCookies(user_info_url);
new CrawleLogin().jsoupLogin(login_url,user_info_url);
}运行 main 方法,得到如下结果:
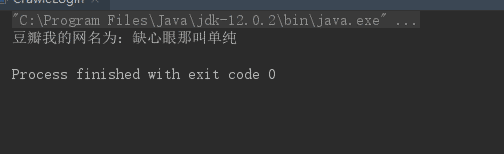
模拟登陆的方式也成功的获取到了网名缺心眼那叫单纯,虽然这已经是最简单的模拟登陆啦,从代码量上就可以看出它比设置 cookie 要复杂很多,对于其他有验证码的登陆,我就不在这里介绍了,第一是我在这方面也没什么经验,第二是这个实现起来比较复杂,会涉及到一些算法和一些辅助工具的使用,有兴趣的朋友可以参考崔庆才老师的博客研究研究。模拟登陆写起来虽然比较复杂,但是只要你编写好之后,你就能够一劳永逸,如果你需要长期采集需要登陆的信息,这个还是值得你的做的。
除了使用 jsoup 模拟登陆外,我们还可以使用 httpclient 模拟登陆,httpclient 模拟登陆没有 Jsoup 那么复杂,因为 httpclient 能够像浏览器一样保存 session 会话,这样登陆之后就保存下了 cookie ,在同一个 httpclient 内请求就会带上 cookie 啦。httpclient 模拟登陆代码如下:
/**
* httpclient 的方式模拟登录豆瓣
* httpclient 跟jsoup差不多,不同的地方在于 httpclient 有session的概念
* 在同一个httpclient 内不需要设置cookies ,会默认缓存下来
* @param loginUrl
* @param userInfoUrl
*/
public void httpClientLogin(String loginUrl,String userInfoUrl) throws Exception{
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpUriRequest login = RequestBuilder.post()
.setUri(new URI(loginUrl))// 登陆url
.setHeader("Upgrade-Insecure-Requests","1")
.setHeader("Accept","application/json")
.setHeader("Content-Type","application/x-www-form-urlencoded")
.setHeader("X-Requested-With","XMLHttpRequest")
.setHeader("User-Agent","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36")
// 设置账号信息
.addParameter("name","your_account")
.addParameter("password","your_password")
.addParameter("remember","false")
.addParameter("ticket","")
.addParameter("ck","")
.build();
// 模拟登陆
CloseableHttpResponse response = httpclient.execute(login);
if (response.getStatusLine().getStatusCode() == 200){
// 构造访问个人中心请求
HttpGet httpGet = new HttpGet(userInfoUrl);
CloseableHttpResponse user_response = httpclient.execute(httpGet);
HttpEntity entity = user_response.getEntity();
//
String body = EntityUtils.toString(entity, "utf-8");
// 偷个懒,直接判断 缺心眼那叫单纯 是否存在字符串中
System.out.println("缺心眼那叫单纯是否查找到?"+(body.contains("缺心眼那叫单纯")));
}else {
System.out.println("httpclient 模拟登录豆瓣失败了!!!!");
}
}运行这段代码,返回的结果也是 true。
以上是“Java爬虫中怎么爬取需要登录的网站”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。