您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Python中怎么利用Beautifulsoup爬取网站,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
1.开始前准备
1.1 python3,本篇博客内容采用python3来写,如果电脑上没有安装python3请先安装python3.
1.2 Request库,urllib的升级版本打包了全部功能并简化了使用方法。下载方法:
pip install requests
1.3 Beautifulsoup库, 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.。下载方法:
pip install beautifulsoup4
1.4 LXML,用于辅助Beautifulsoup库解析网页。(如果你不用anaconda,你会发现这个包在Windows下pip安装报错)下载方法:
pip install lxml
1.5 pycharm,一款功能强大的pythonIDE工具。下载官方版本后,使用license sever免费使用(同系列产品类似),具体参照http://www.cnblogs.com/hanggegege/p/6763329.html。
2.爬取过程演示与分析
from bs4 import BeautifulSoup import os import requests
导入需要的库,os库用来后期储存爬取内容。
随后我们点开“***笑话”,发现有“全部笑话”这一栏,能够让我们***效率地爬取所有历史笑话!
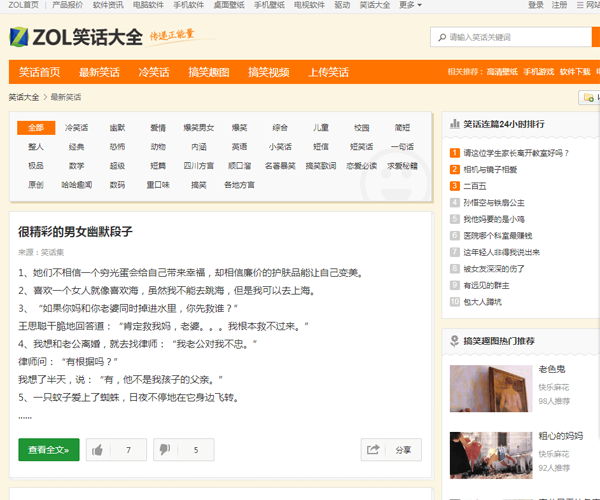
我们来通过requests库来看看这个页面的源代码:
from bs4 import BeautifulSoup import os import requests all_url = 'http://xiaohua.zol.com.cn/new/ headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} all_html=requests.get(all_url,headers = headers) print(all_html.text)header是请求头,大部分网站没有这个请求头会爬取失败
部分效果如下:
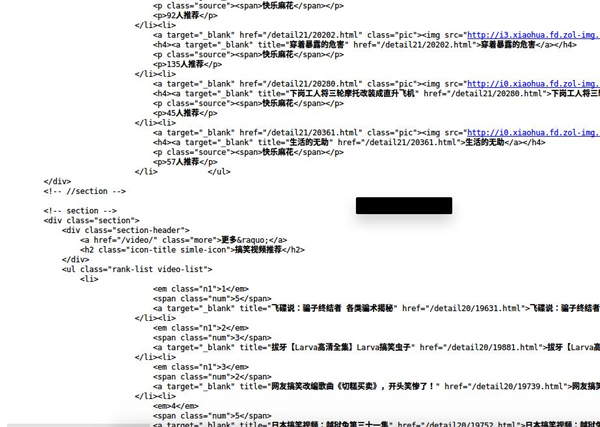
通过源码分析发现我们还是不能通过此网站就直接获取到所有笑话的信息,因此我们在在这个页面找一些间接的方法。
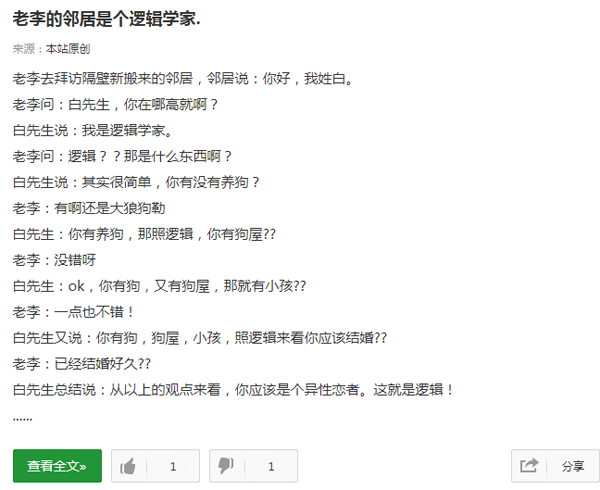
点开一个笑话查看全文,我们发现此时网址变成了http://xiaohua.zol.com.cn/detail58/57681.html,在点开其他的笑话,我们发现网址部都是形如http://xiaohua.zol.com.cn/detail?/?.html的格式,我们以这个为突破口,去爬取所有的内容
我们的目的是找到所有形如http://xiaohua.zol.com.cn/detail?/?.html的网址,再去爬取其内容。
我们在“全部笑话”页面随便翻到一页:http://xiaohua.zol.com.cn/new/5.html ,按下F12查看其源代码,按照其布局发现 :
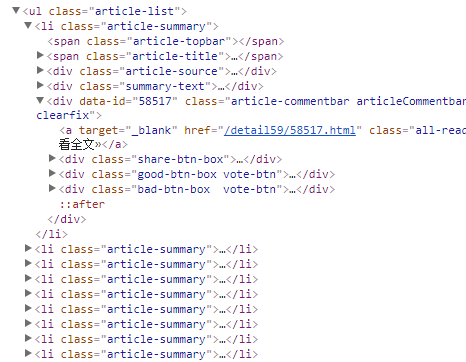
每个笑话对应其中一个<li>标签,分析得每个笑话展开全文的网址藏在href当中,我们只需要获取href就能得到笑话的网址
from bs4 import BeautifulSoup import os import requests all_url = 'http://xiaohua.zol.com.cn/new/ ' headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} all_html=requests.get(all_url,headers = headers) #print(all_html.text) soup1 = BeautifulSoup(all_html.text,'lxml') list1=soup1.find_all('li',class_ = 'article-summary') for i in list1: #print(i) soup2 = BeautifulSoup(i.prettify(),'lxml') list2=soup2.find_all('a',target = '_blank',class_='all-read') for b in list2: href = b['href'] print(href)我们通过以上代码,成功获得***页所有笑话的网址后缀:
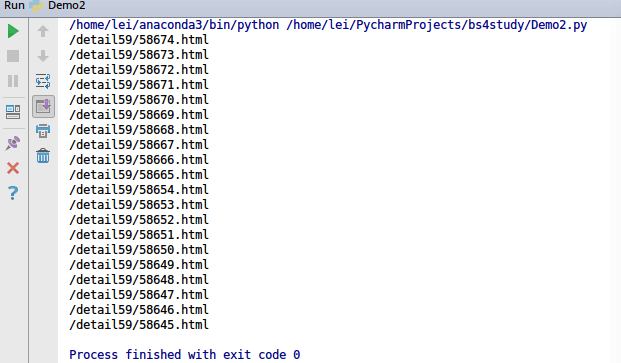
也就是说,我们只需要获得所有的循环遍历所有的页码,就能获得所有的笑话。
上面的代码优化后:
from bs4 import BeautifulSoup import os import requests all_url = 'http://xiaohua.zol.com.cn/new/5.html ' def Gethref(url): headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} html = requests.get(url,headers = headers) soup_first = BeautifulSoup(html.text,'lxml') list_first = soup_first.find_all('li',class_='article-summary') for i in list_first: soup_second = BeautifulSoup(i.prettify(),'lxml') list_second = soup_second.find_all('a',target = '_blank',class_='all-read') for b in list_second: href = b['href'] print(href) Gethref(all_url)使用如下代码,获取完整的笑话地址url
from bs4 import BeautifulSoup import os import requests all_url = 'http://xiaohua.zol.com.cn/new/5.html ' def Gethref(url): list_href = [] headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} html = requests.get(url,headers = headers) soup_first = BeautifulSoup(html.text,'lxml') list_first = soup_first.find_all('li',class_='article-summary') for i in list_first: soup_second = BeautifulSoup(i.prettify(),'lxml') list_second = soup_second.find_all('a',target = '_blank',class_='all-read') for b in list_second: href = b['href'] list_href.append(href) return list_href def GetTrueUrl(liebiao): for i in liebiao: url = 'http://xiaohua.zol.com.cn '+str(i) print(url) GetTrueUrl(Gethref(all_url))简单分析笑话页面html内容后,接下来获取一个页面全部笑话的内容:
from bs4 import BeautifulSoup import os import requests all_url = 'http://xiaohua.zol.com.cn/new/5.html ' def Gethref(url): list_href = [] headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} html = requests.get(url,headers = headers) soup_first = BeautifulSoup(html.text,'lxml') list_first = soup_first.find_all('li',class_='article-summary') for i in list_first: soup_second = BeautifulSoup(i.prettify(),'lxml') list_second = soup_second.find_all('a',target = '_blank',class_='all-read') for b in list_second: href = b['href'] list_href.append(href) return list_href def GetTrueUrl(liebiao): list = [] for i in liebiao: url = 'http://xiaohua.zol.com.cn '+str(i) list.append(url) return list def GetText(url): for i in url: html = requests.get(i) soup = BeautifulSoup(html.text,'lxml') content = soup.find('div',class_='article-text') print(content.text) GetText(GetTrueUrl(Gethref(all_url)))效果图如下:

现在我们开始存储笑话内容!开始要用到os库了
使用如下代码,获取一页笑话的所有内容!
from bs4 import BeautifulSoup import os import requests all_url = 'http://xiaohua.zol.com.cn/new/5.html ' os.mkdir('/home/lei/zol') def Gethref(url): list_href = [] headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} html = requests.get(url,headers = headers) soup_first = BeautifulSoup(html.text,'lxml') list_first = soup_first.find_all('li',class_='article-summary') for i in list_first: soup_second = BeautifulSoup(i.prettify(),'lxml') list_second = soup_second.find_all('a',target = '_blank',class_='all-read') for b in list_second: href = b['href'] list_href.append(href) return list_href def GetTrueUrl(liebiao): list = [] for i in liebiao: url = 'http://xiaohua.zol.com.cn '+str(i) list.append(url) return list def GetText(url): for i in url: html = requests.get(i) soup = BeautifulSoup(html.text,'lxml') content = soup.find('div',class_='article-text') title = soup.find('h2',class_ = 'article-title') SaveText(title.text,content.text) def SaveText(TextTitle,text): os.chdir('/home/lei/zol/') f = open(str(TextTitle)+'txt','w') f.write(text) f.close() GetText(GetTrueUrl(Gethref(all_url)))效果图:

(因为我的系统为linux系统,路径问题请按照自己电脑自己更改)
我们的目标不是抓取一个页面的笑话那么简单,下一步我们要做的是把需要的页面遍历一遍!
通过观察可以得到全部笑话页面url为http://xiaohua.zol.com.cn/new/+页码+html,接下来我们遍历前100页的所有笑话,全部下载下来!
接下来我们再次修改代码:
from bs4 import BeautifulSoup import os import requests num = 1 url = 'http://xiaohua.zol.com.cn/new/ '+str(num)+'.html' os.mkdir('/home/lei/zol') def Gethref(url): list_href = [] headers = { 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} html = requests.get(url,headers = headers) soup_first = BeautifulSoup(html.text,'lxml') list_first = soup_first.find_all('li',class_='article-summary') for i in list_first: soup_second = BeautifulSoup(i.prettify(),'lxml') list_second = soup_second.find_all('a',target = '_blank',class_='all-read') for b in list_second: href = b['href'] list_href.append(href) return list_href def GetTrueUrl(liebiao): list = [] for i in liebiao: url = 'http://xiaohua.zol.com.cn '+str(i) list.append(url) return list def GetText(url): for i in url: html = requests.get(i) soup = BeautifulSoup(html.text,'lxml') content = soup.find('div',class_='article-text') title = soup.find('h2',class_ = 'article-title') SaveText(title.text,content.text) def SaveText(TextTitle,text): os.chdir('/home/lei/zol/') f = open(str(TextTitle)+'txt','w') f.write(text) f.close() while num<=100: url = 'http://xiaohua.zol.com.cn/new/ ' + str(num) + '.html' GetText(GetTrueUrl(Gethref(url))) num=num+1关于Python中怎么利用Beautifulsoup爬取网站就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。