您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关怎样搭建Hadoop2.8.1完全分布式环境的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
实验过程
1、基础集群的搭建
目的:获得一个可以互相通信的三节点集群
下载并安装VMware WorkStation Pro(支持快照,方便对集群进行保存)下载地址,产品激活序列号网上自行查找。
下载CentOS7镜像,下载地址。
使用VMware安装master节点(稍后其他两个节点可以通过复制master节点的虚拟机文件创建)。
三个节点存储均为30G默认安装,master节点内存大小为2GB,双核,slave节点内存大小1GB,单核
2、集群网络配置
目的:为了使得集群既能互相之间进行通信,又能够进行外网通信,需要为节点添加两张网卡(可以在虚拟机启动的时候另外添加一张网卡,即网络适配器,也可以在节点创建之后,在VMware设置中添加)。
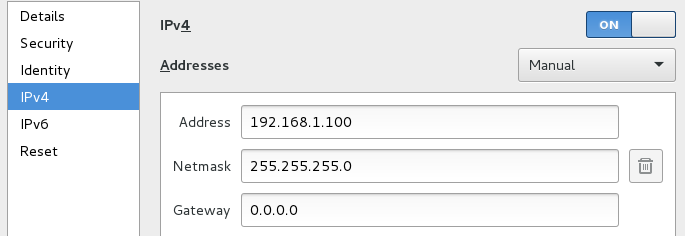
两张网卡上网方式均采用桥接模式,外网IP设置为自动获取(通过此网卡进行外网访问,配置应该按照你当前主机的上网方式进行合理配置,如果不与主机通信的话可以采用NAT上网方式,这样选取默认配置就行),内网IP设置为静态IP。
本文中的集群网络环境配置如下:
master内网IP:192.168.1.100
slave1内网IP:192.168.1.101
slave2内网IP:192.168.1.102
设置完后,可以通过ping进行网络测试
注意事项:通过虚拟机文件复制,在VMware改名快速创建slave1和slave2后,可能会产生网卡MAC地址重复的问题,需要在VMware网卡设置中重新生成MAC,在虚拟机复制后需要更改内网网卡的IP。
每次虚拟机重启后,网卡可能没有自动启动,需要手动重新连接。
3、集群SSH免密登陆设置
目的:创建一个可以ssh免密登陆的集群
3.1 创建hadoop用户
为三个节点分别创建相同的用户hadoop,并在以后的操作均在此用户下操作,操作如下:
$su -
#useradd -m hadoop
#passwd hadoop
为hadoop添加sudo权限
#visudo
在该行root ALL=(ALL) ALL下添加hadoop ALL=(ALL) ALL保存后退出,并切换回hadoop用户
#su hadoop
注意事项:三个节点的用户名必须相同,不然以后会对后面ssh及hadoop集群搭建产生巨大影响
3.2 hosts文件设置
为了不直接使用IP,可以通过设置hosts文件达到ssh slave1这样的的效果(三个节点设置相同)
$sudo vim /etc/hosts
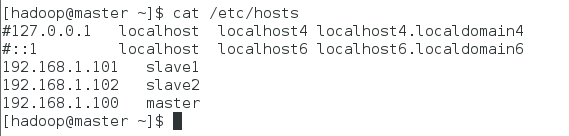
在文件尾部添加如下行,保存后退出:
192.168.1.100 master
192.168.1.101 slave1
192.168.1.102 slave2
注意事项:不要在127.0.0.1后面添加主机名,如果加了master,会造成后面hadoop的一个很坑的问题,在slave节点应该解析出masterIP的时候解析出127.0.0.1,造成hadoop搭建完全正确,但是系统显示可用节点一直为0。
3.3 hostname修改
centos7默认的hostname是localhost,为了方便将每个节点hostname分别修改为master、slave1、slave2(以下以master节点为例)。
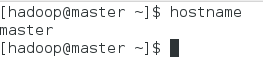
$sudo hostnamectl set-hostname master
重启terminal,然后查看:$hostname
3.3 ssh设置
设置master节点和两个slave节点之间的双向ssh免密通信,下面以master节点ssh免密登陆slave节点设置为例,进行ssh设置介绍(以下操作均在master机器上操作):
首先生成master的rsa密钥:$ssh-keygen -t rsa
设置全部采用默认值进行回车
将生成的rsa追加写入授权文件:$cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
给授权文件权限:$chmod 600 ~/.ssh/authorized_keys
进行本机ssh测试:$ssh maste r正常免密登陆后所有的ssh第一次都需要密码,此后都不需要密码
将master上的authorized_keys传到slave1
sudo scp ~/.ssh/id_rsa.pubhadoop@slave1:~/
登陆到slave1操作:$ssh slave1输入密码登陆
$cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
修改authorized_keys权限:$chmod 600 ~/.ssh/authorized_keys
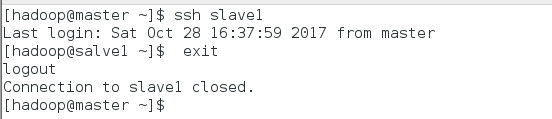
退出slave1:$exit
进行免密ssh登陆测试:$ssh slave1
4、java安装
目的:hadoop是基于Java的,所以要安装配置Java环境(三个节点均需要操作,以下以master节点为例)
下载并安装:$sudo yum install java-1.8.0-openjdkjava-1.8.0-openjdk-devel
验证是否安装完成:$java -version
配置环境变量,修改~/.bashrc文件,添加行: export JAVA_HOME=/usr/lib/jvm/java-1.8.0
使环境变量生效:$source ~/.bashrc

5、Hadoop安装配置
目的:获得正确配置的完全分布式Hadoop集群(以下操作均在master主机下操作)
安装前三台节点都需要需要关闭防火墙和selinux
$sudo systemctl stop firewalld.service $sudo systemctl disable firewalld.service $sudo vim /usr/sbin/sestatus
将SELinux status参数设定为关闭状态
SELinux status: disabled
5.1 Hadoop安装
首先在master节点进行hadoop安装配置,之后使用scp传到slave1和slave2。
下载Hadoop二进制源码至master,下载地址,并将其解压在~/ 主目录下
$tar -zxvf ~/hadoop-2.8.1.tar.gz -C ~/
$mv~/hadoop-2.8.1/* ~/hadoop/
注意事项:hadoop有32位和64位之分,官网默认二进制安装文件是32位的,但是本文操作系统是64位,会在后面hadoop集群使用中产生一个warning但是不影响正常操作。
5.2 Hadoop的master节点配置
配置hadoop的配置文件core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves(都在~/hadoop/etc/hadoop文件夹下)
$cd ~/hadoop/etc/hadoop
$vimcore-site.xml其他文件相同,以下为配置文件内容:
1.core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/hadoop/tmp</value> </property> </configuration>
2.hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop/tmp/dfs/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:9001</value> </property> </configuration>
3.mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4.yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
5.slaves
slave1
slave2
5.3 Hadoop的其他节点配置
此步骤的所有操作仍然是在master节点上操作,以master节点在slave1节点上配置为例
复制hadoop文件至slave1:$scp -r ~/hadoop hadoop@slave1:~/
5.4 Hadoop环境变量配置
配置环境变量,修改~/.bashrc文件,添加行(每个节点都需要此步操作,以master节点为例):
#hadoop environment vars export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
使环境变量生效:$source ~/.bashrc

6、Hadoop启动
格式化namenode:$hadoop namenode -format
启动hadoop:$start-all.sh
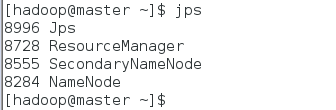
master节点查看启动情况:$jps
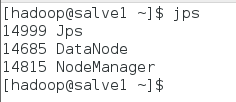
slave1节点查看启动情况:$jps
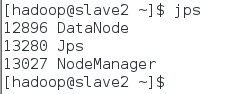
slave2节点查看启动情况:$jps
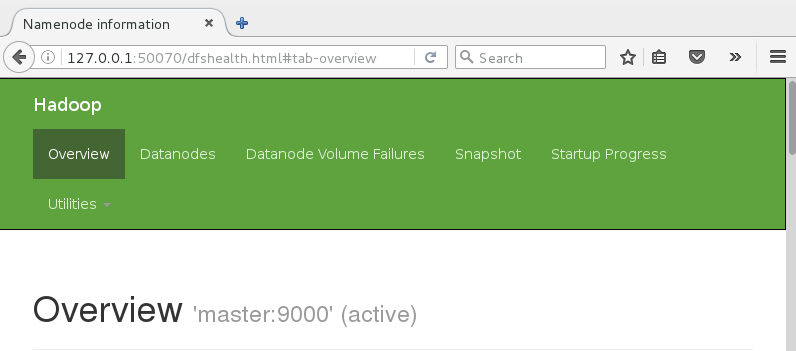
Web浏览器输入127.0.0.1:50070,查看管理界面

7、Hadoop集群测试
目的:验证当前hadoop集群正确安装配置
本次测试用例为利用MapReduce实现wordcount程序
生成文件testWordCount:$echo "My name is Xie PengCheng. This is a example program called WordCount, run by Xie PengCheng " >>testWordCount
创建hadoop文件夹wordCountInput:$hadoop fs -mkdir /wordCountInput
将文件testWordCount上传至wordCountInput文件夹:$hadoop fs -puttestWordCount/wordCountInput
执行wordcount程序,并将结果放入wordCountOutput文件夹:$hadoop jar ~/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar wordcount /wordCountInput /wordCountOutput
注意事项:/wordCountOutput文件夹必须是没有创建过的文件夹
查看生成文件夹下的文件:$hadoop fs -ls /wordCountOutput

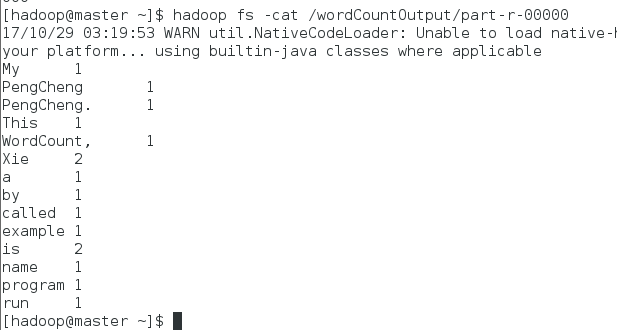
在output/part-r-00000可以看到程序执行结果:$hadoop fs -cat /wordCountOutpart-r-00000
感谢各位的阅读!关于“怎样搭建Hadoop2.8.1完全分布式环境”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。