жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іCentOS 7еҰӮдҪ•жҗӯе»әHadoop 2.7.3е®Ңе…ЁеҲҶеёғејҸйӣҶзҫӨзҺҜеўғпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
(дёҖпјүиҪҜ件еҮҶеӨҮ
1пјҢhadoop-2.7.3.tar.gzпјҲеҢ…пјү
2,дёүеҸ°жңәеҷЁиЈ…жңүcetos7зҡ„жңәеӯҗ
пјҲдәҢпјүе®үиЈ…жӯҘйӘӨ
гҖҖгҖҖ1пјҢз»ҷжҜҸеҸ°жңәеӯҗй…ҚзӣёеҗҢзҡ„з”ЁжҲ·
гҖҖгҖҖгҖҖгҖҖиҝӣе…Ҙroot : su root
гҖҖгҖҖгҖҖгҖҖеҲӣе»әз”ЁжҲ·s: useradd s
гҖҖгҖҖгҖҖгҖҖдҝ®ж”№з”ЁжҲ·еҜҶз Ғпјҡpasswd s
гҖҖгҖҖ2.е…ій—ӯйҳІзҒ«еўҷеҸҠдҝ®ж”№жҜҸеҸ°жңәзҡ„hosts(root дёӢпјү
гҖҖгҖҖгҖҖгҖҖvim /etc/hosts еҰӮпјҡпјҲдёүеҸ°жңәеӯҗйғҪдёҖж ·пјү

гҖҖгҖҖгҖҖгҖҖvim /etc/hostsname:еҰӮдҝ®ж”№еҗҺеҸӮзңӢеҗ„иҮӘзҡ„hostname



гҖҖгҖҖгҖҖгҖҖе…ій—ӯйҳІзҒ«еўҷпјҡ
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖsystemctl stop firewalld.service
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖзҰҒз”ЁйҳІзҒ«еўҷпјҡsystemctl disable firewalld.service
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖжҹҘзңӢйҳІзҒ«еўҷзҠ¶жҖҒfirewall-cmd --state
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖйҮҚеҗҜ reboot
гҖҖгҖҖ3,дёәжҜҸеҸ°жңәзҡ„з”ЁжҲ·sй…ҚзҪ®sshпјҢд»Ҙз”ЁжҲ·sиә«д»Ҫзҷ»еҪ• (дёҖе®ҡиҰҒзӣёеҗҢзҡ„з”ЁжҲ·пјҢеӣ дёәsshйҖҡдҝЎй»ҳи®ӨдҪҝз”ЁзӣёеҗҢз”ЁжҲ·иә«д»Ҫи®ҝй—®еҸҰдёҖеҸ°жңәеӯҗпјү
гҖҖгҖҖгҖҖгҖҖ1,root з”ЁжҲ·дёӢдҝ®ж”№пјҡ vim /etc/ssh/sshd_config,и®ҫзҪ®иҝҷдёүйЎ№еҗҺпјҢжү§иЎҢservice sshd restart

гҖҖгҖҖгҖҖгҖҖ2пјҢйҖҖеҮәrootпјҢеңЁз”ЁжҲ·sдёӢж“ҚдҪң
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖз”ҹжҲҗеҜҶй’ҘеҜ№пјҡ ssh-keygen -t dsaпјҲдёҖи·ҜеӣһиҪҰеҚіеҸҜпјү
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖиҪ¬е…Ҙsshзӣ®еҪ•дёӢпјҡcd .ssh
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖеҜје…Ҙе…¬й’ҘпјҡгҖҖcat id_dsa.pub >> authorized_keys
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖдҝ®ж”№authorized_keysжқғйҷҗпјҡchmod 644 гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖauthorized_keys (дҝ®ж”№жқғйҷҗпјҢдҝқиҜҒиҮӘе·ұе…ҚеҜҶз ҒиғҪзҷ»е…Ҙ)
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖйӘҢиҜҒ ssh MasterгҖҖпјҲеңЁдёүеҸ°жңәйғҪжү§иЎҢзӣёеҗҢзҡ„ж“ҚдҪңпјү
гҖҖгҖҖгҖҖгҖҖ3пјҢе®һзҺ°master-slaveе…ҚеҜҶз Ғзҷ»еҪ•
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖеңЁmaster дёҠжү§иЎҢпјҡгҖҖгҖҖ cat ~/.ssh/id_dsa.pub | ssh s@Slave1 'cat - >> ~/.ssh/authorized_keys'
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖcat ~/.ssh/id_dsa.pub | ssh s@Slave2 'cat - >> ~/.ssh/authorized_keys '
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖйӘҢиҜҒ :ssh Slave1
пјҲдёү пјүй…ҚзҪ®HadoopйӣҶзҫӨ
гҖҖгҖҖгҖҖгҖҖ1пјҢи§ЈеҺӢhadoopе’Ңе»әз«Ӣж–Ү件
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖrootз”ЁжҲ·дёӢпјҡtar zxvf /home/hadoop/hadoop-2.7.3.tar.gz -C /usr/
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ йҮҚе‘ҪеҗҚпјҡmv hadoop-2.7.3 hadoop
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ жҺҲжқғз»ҷs: chown -R s /usr/hadoop
гҖҖгҖҖгҖҖгҖҖ2пјҢеҲӣе»әhdfsзӣёе…іж–Ү件пјҲдёүеҸ°жңәеӯҗйғҪйңҖиҰҒж“ҚдҪңпјү
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖеҲӣе»әеӯҳеӮЁhadoopж•°жҚ®ж–Ү件зҡ„зӣ®еҪ•: mkdir /home/hadoopdir
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖеӯҳеӮЁдёҙж—¶ж–Ү件пјҢеҰӮpidпјҡmkdir /home/hadoopdir/tmp
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖеҲӣе»әdfsзі»з»ҹдҪҝз”Ёзҡ„dfsзі»з»ҹеҗҚз§°hdfs-site.xmlдҪҝз”Ё:mkdir /home/hadoopdir/dfs/name
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖеҲӣе»әdfsзі»з»ҹдҪҝз”Ёзҡ„ж•°жҚ®ж–Ү件hdfs-site.xmlж–Ү件дҪҝз”Ё:mkdir /home/hadoopdir/dfs/data
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ жҺҲжқғз»ҷs: chown -R s /home/hadoopdir
гҖҖгҖҖгҖҖгҖҖ3пјҢй…ҚзҪ®зҺҜеўғеҸҳйҮҸ(дёүеҸ°жңәеӯҗйғҪйңҖиҰҒж“ҚдҪңпјү
гҖҖгҖҖгҖҖгҖҖ rootз”ЁжҲ·дёӢпјҡvim /etc/profile ж·»еҠ еҰӮеӣҫпјҡ дҝқеӯҳйҖҖеҮәеҗҺ:source /etc/profile
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖйӘҢиҜҒпјҡhadoop versionпјҲиҝҷйҮҢиҰҒдҝ®ж”№ /usr/hadoop/etc/hadoop/hadoop-env.shпјҢеҚіexport JAVA_HOME=/usr/lib/jvm/jreпјү

гҖҖгҖҖгҖҖгҖҖ4пјҢй…ҚзҪ®hadoopж–Ү件еҶ…е®№
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ4.1 дҝ®ж”№core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoopdir/tmp/</value> <description>A base for other temporary directories.</description> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
гҖҖгҖҖгҖҖгҖҖгҖҖ4.2 дҝ®ж”№hdfs-site.xmlж–Ү件
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>file:///home/hadoopdir/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///home/hadoopdir/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
гҖҖгҖҖгҖҖгҖҖ4.3 дҝ®ж”№mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>Master:50030</value> </property> <property> <name>mapred.job.tracker</name> <value>Master:9001</value> </property> </configuration>
гҖҖгҖҖгҖҖгҖҖ4.4 дҝ®ж”№ yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>Master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>Master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>Master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>Master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>Master:8088</value> </property> </configuration>
гҖҖгҖҖгҖҖгҖҖ4.5,дҝ®ж”№ slavesж–Ү件
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ
гҖҖгҖҖгҖҖ5пјҢжҗӯе»әйӣҶзҫӨпјҲжҷ®йҖҡз”ЁжҲ·sпјү
гҖҖгҖҖгҖҖгҖҖгҖҖж јејҸhadoopж–Ү件пјҡhadoop namenode -format (жңҖеҗҺеҮәзҺ°вҖңutil.ExitUtil: Exiting with status 0вҖқпјҢиЎЁзӨәжҲҗеҠҹ)
гҖҖгҖҖгҖҖгҖҖгҖҖеҸ‘йҖҒdfsеҶ…е®№з»ҷSlave1:scp -r /home/hadoopdir/dfs/* Slave1:/home/hadoopdir/dfs
гҖҖгҖҖгҖҖгҖҖеҸ‘з»ҷdfsеҶ…е®№з»ҷSlave2:scp -r /home/hadoopdir/dfs/* Slave2:/home/hadoopdir/dfs
гҖҖгҖҖгҖҖгҖҖ еҸ‘йҖҒhadoopж–Ү件з»ҷж•°жҚ®иҠӮзӮ№пјҡscp -r /usr/hadoop/* Slave1:/usr/hadoop/гҖҖгҖҖscp -r /usr/hadoop/* Slave2:/usr/hadoop/
гҖҖгҖҖгҖҖ6пјҢеҗҜеҠЁйӣҶзҫӨ
гҖҖгҖҖгҖҖгҖҖ./sbin/start-all.sh
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ1пјҢjps(centos 7 й»ҳи®ӨжІЎжңүпјҢеҸҜд»ҘеҸӮз…§еҲҶеүІзәҝйҮҢзҡ„е®үиЈ…)
--------------------------------------еҲҶеүІзәҝ --------------------------------------
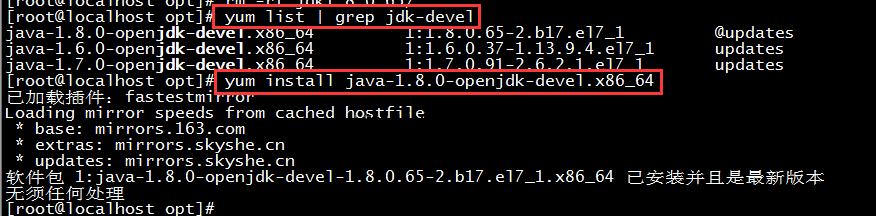
CentOSдёӯдҪҝз”Ёyumе®үиЈ…javaж—¶пјҢжІЎжңүjpsзҡ„й—®йўҳзҡ„и§ЈеҶігҖӮ
и§ЈеҶіж–№жі•пјҡйңҖиҰҒе®үиЈ…java-1.X.X-openjdk-develиҝҷдёӘеҢ…пјҢд»–жҸҗдҫӣдәҶjpsиҝҷдёӘе·Ҙе…·гҖӮ
--------------------------------------еҲҶеүІзәҝ --------------------------------------
жҹҘзңӢпјҡMasterе’ҢSlaveдёӯеҲҶеҲ«еҮәзҺ°еҰӮдёӢжүҖзӨәпјҡ
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ

гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ2пјҢзҰ»ејҖе®үе…ЁжЁЎејҸпјҲmasterпјү: hadoop dfsadmin safemode leave
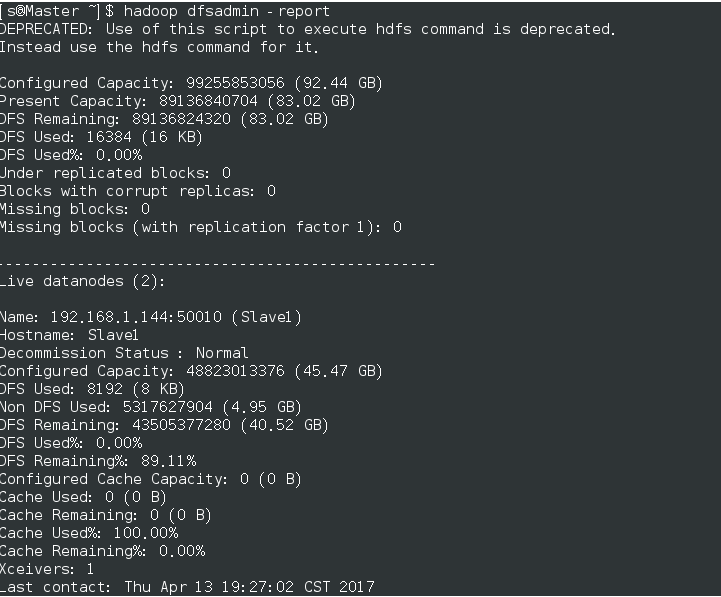
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖжҹҘзңӢз»“жһңпјҡhadoop dfsadmin -report,еҰӮеӣҫ
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ3пјҢзҷ»еҪ•зҪ‘йЎөжҹҘзңӢпјҡhttpпјҡ//Master:50070 (жҹҘзңӢlive node) жҹҘзңӢyarnзҺҜеўғпјҲhttp://Master/8088пјү
е…ідәҺвҖңCentOS 7еҰӮдҪ•жҗӯе»әHadoop 2.7.3е®Ңе…ЁеҲҶеёғејҸйӣҶзҫӨзҺҜеўғвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ