您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
前言
首先,我们要讲的是JVM的垃圾回收机制,我默认准备阅读本篇的人都知道以下两点:
因为我们即将要讲的就是发生在JVM的Java堆上的垃圾回收,为了突出核心,其他的一些与本篇不太相关的东西我就一笔略过了
众所周知,Java堆上保存着对象的实例,而Java堆的大小是有限的,所以我们只能把一些已经用完的,无法再使用的垃圾对象从内存中释放掉,就像JVM帮助我们手动在代码中添加一条类似于C++的free语句的行为
然而这些垃圾对象是怎么回收的,现在不知道没关系,我们马上就会讲到
怎么判断对象为垃圾对象
在了解具体的GC(垃圾回收)算法之前,我们先来了解一下JVM是怎么判断一个对象是垃圾对象的
顾名思义,垃圾对象,就是没有价值的对象,用更严谨的语句来说,就是没有被访问的对象,也就是说没有被其他对象引用,这就牵引出我们的第一个判断方案:引用计数法
引用计数法
这种算法的原理是,每有一个其他对象产生对A对象的引用,则A对象的引用计数值就+1,反之,每有一个对象对A对象的引用失效的时候,A对象的引用计数值就-1,当A对象的引用计数值为0的时候,其就被标明为垃圾对象
这种算法看起来很美好,了解C++的应该知道,C++的智能指针也有类似的引用计数,但是在这种看起来“简单”的方法,并不能用来判断一个对象为垃圾对象,我们来看以下场景:
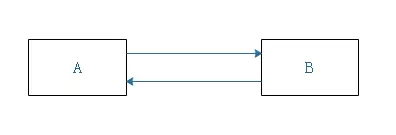
在这个场景中,A对象有B对象的引用,B对象也有A对象的引用,所以这两个对象的引用计数值均不为0,但是,A、B两个对象明明就没有任何外部的对象引用,就像大海上两个紧挨着的孤岛,即使他们彼此依靠着,但仍然是孤岛,其他人过不去,而且由于引用计数不为0,也无法判断为垃圾对象,如果JVM中存在着大量的这样的垃圾对象,最终就会频繁抛出OOM异常,导致系统频繁崩溃
总而言之,如果有人问你为什么JVM不采用引用计数法来判断垃圾对象,只需要记住这一句话:引用计数法无法解决对象循环依赖的问题
可达性分析法
引用计数法已经很接近结果了,但是其问题是,为什么每有一个对象来引用就要给引用计数值+1,就好像有人来敲门就开一样,我们应该只给那些我们认识的、重要的人开门,也就是说,只有重要的对象来引用时,才给引用计数值+1
但是这样还不行,因为重要的对象来引用只要有一个就够了,并不需要每有一个引用就+1,所以我们可以将引用计数法优化为以下形式:
给对象设置一个标记,每有一个“重要的对象”来引用时,就将这个标记设为true,当没有任何“重要的对象”引用时,就将标记设为false,标记为false的对象为垃圾对象
这就是可达性分析法的雏形,我们可以继续进行修正,我们并不需要主动标记对象,而只需要等待垃圾回收时找到这些“重要的对象”,然后从它们出发,把我们能找到的对象都标记为非垃圾对象,其余的自然就是垃圾对象
我们将上文提到的“重要的对象”命名为GC Roots,这样就得到了最终的可达性分析算法的概念:
创建垃圾回收时的根节点,称为GC Roots,从GC Roots出发,不能到达的对象就被标记为垃圾对象
其中,可以作为GC Roots的区域有:
换句话说,GC Roots就是方法中的局部变量、类属性,以及常量
垃圾回收算法
终于到本文的重点了,我们刚刚分析了如何判断一个对象属于垃圾对象,接下来我们就要重点分析如何将这些垃圾对象回收掉
标记-清除算法
标记-清除很容易理解,该算法有两个过程,标记过程和清除过程,标记过程中通过上文提到的可达性分析法来标记出所有的非垃圾对象,然后再通过清除过程进行清理
比方说,我们现在有下面的这样的一个Java堆,已经通过可达性分析法来标记出所有的垃圾对象(用橙色表明,蓝色的是普通对象):
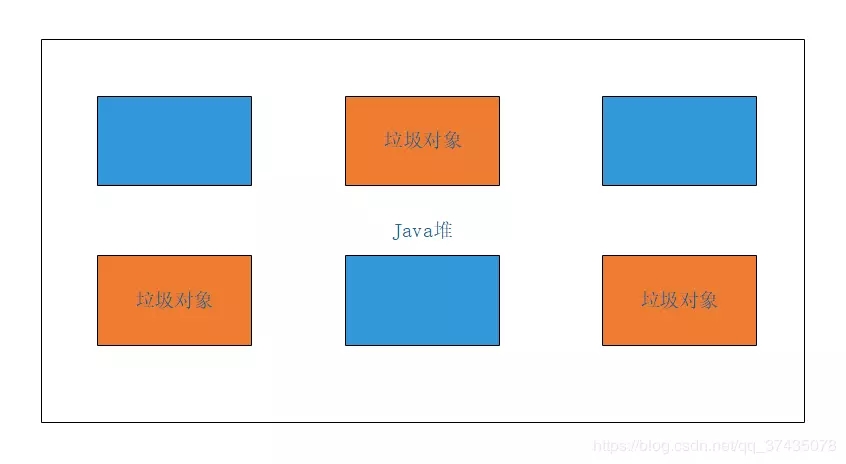
然后我们通过清除阶段进行清理,结果是下图:
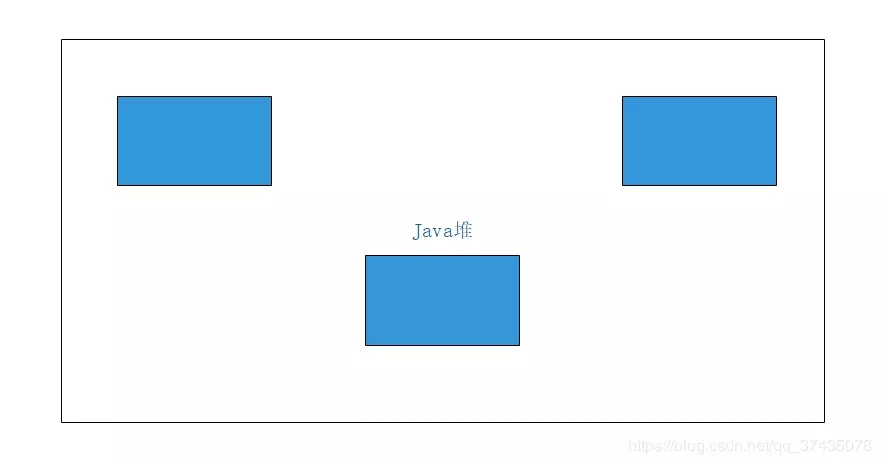
发现什么问题了吗,没错,清理完后的空间是不连续的,也就是说,整个算法最大的缺点就是:
这里引出一个FGC的概念,为了避免主题跑偏,本文中暂时不进行深入,只需要知道垃圾回收分为YGC(年轻代垃圾回收)和FGC(完全垃圾回收),可以把YGC理解为扫扫地,倒倒垃圾,把FGC理解为给家里来个大扫除
复制算法
复制算法将Java堆划分为两块区域,每次只使用其中的一块区域,当垃圾回收发生时,将所有被标记的对象(GC Roots可达,为非垃圾对象)复制到另一块区域,然后进行清理,清理完成后交换两块区域的可用性
这种方式因为每次只需要一整块一起删除即可,就不用一个个地删除了,同时还能保证另一块区域是连续的,也解决了空间碎片的问题
整个流程我们再来看一遍
1.首先我们有两块区域S1和S2,标记为灰色的区域为当前激活可用的区域:
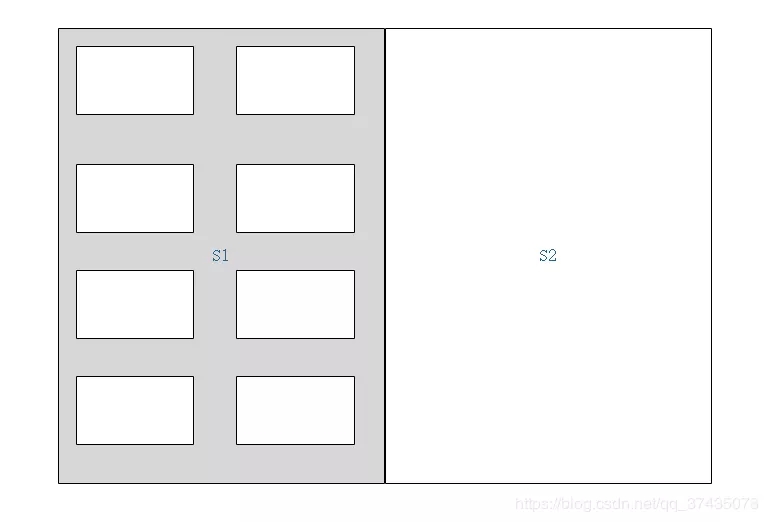
2.对Java堆上的对象进行标记,其中蓝色的为GC Roots可达的对象,其余的均为垃圾对象:
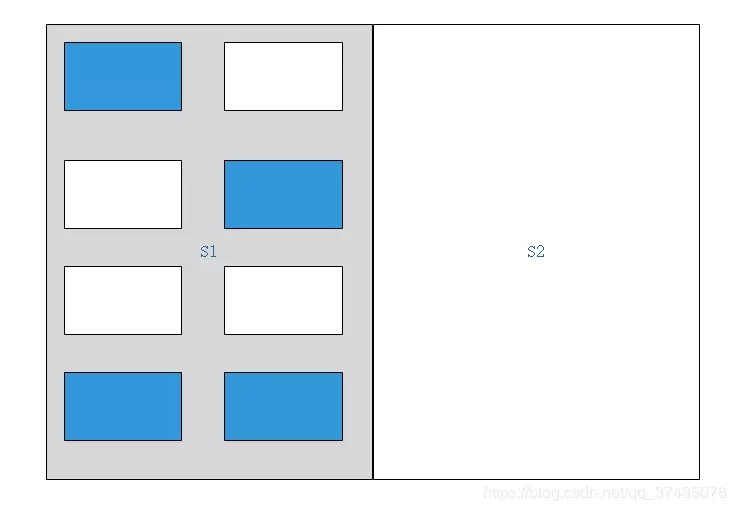
3.接下来将所有可用的对象复制到另一块区域中:
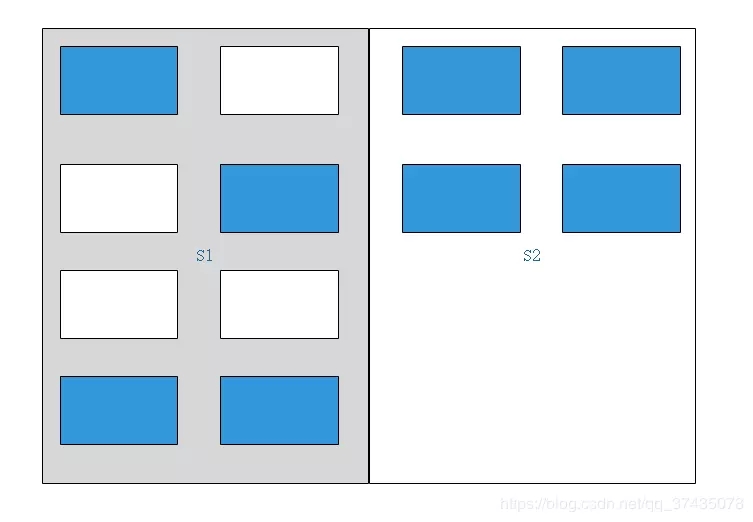
4.将原区域中所有内容删除,并将另一块区域激活
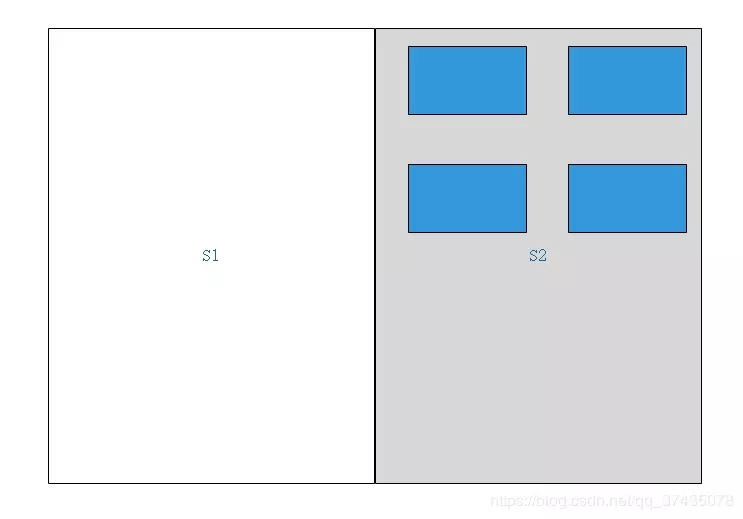
这种方法的优缺点也很明显:
为了解决这一缺点,就引出了下面这个算法
优化的复制算法
至于为什么不另起一个名字,其实是因为这个算法也叫做复制算法,更确切的说,刚才介绍的只是优化算法的雏形,没有虚拟机会使用上面的那种复制算法,所以接下来要讲的,就是真正的复制算法
这个算法的思路和刚才讲的一样,不过这个算法将内存分为3块区域:1块Eden区,和2块Survivor区,其中,Eden区要占到80%
这两块Survivor区就可以理解为我们刚才提到的S1和S2两块区域,我们每次只使用整个Eden区和其中一块Survivor区,整个算法的流程可以简要概括为:
1.当发生垃圾回收时,将Eden区+Survivor区中仍然存活的对象一次性复制到另一块Survivor区上
2.清理掉Eden区和使用的Survivor区中的所有对象
3.交换两块Survivor的激活状态
光看文字描述比较抽象,我们来看图像的形式:
1.我们有以下这样的一块Java堆,其中灰色的Survivor区为激活状态
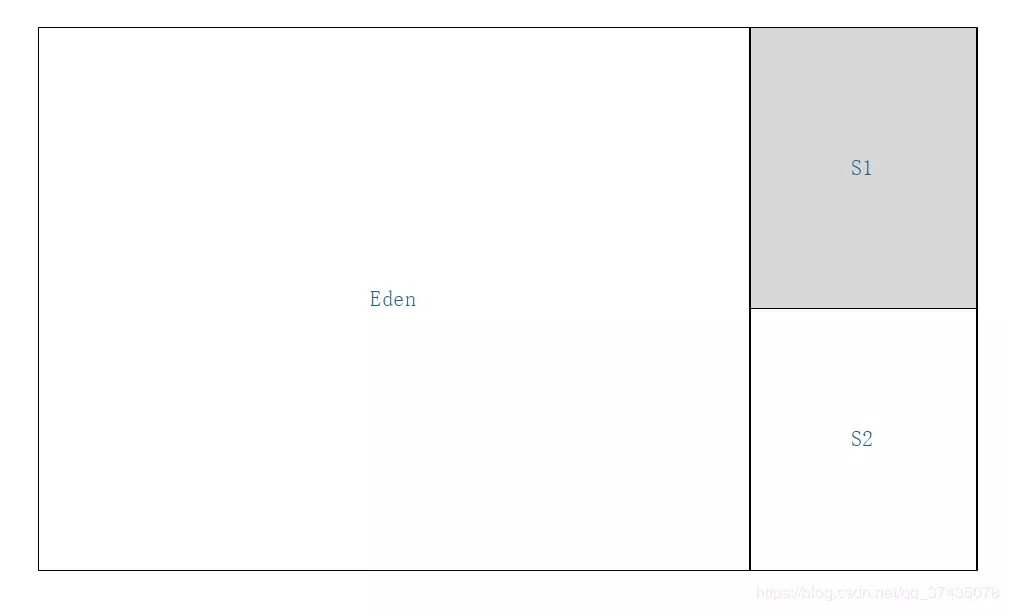
2.标记所有的GC Roots可达对象(蓝色标记)
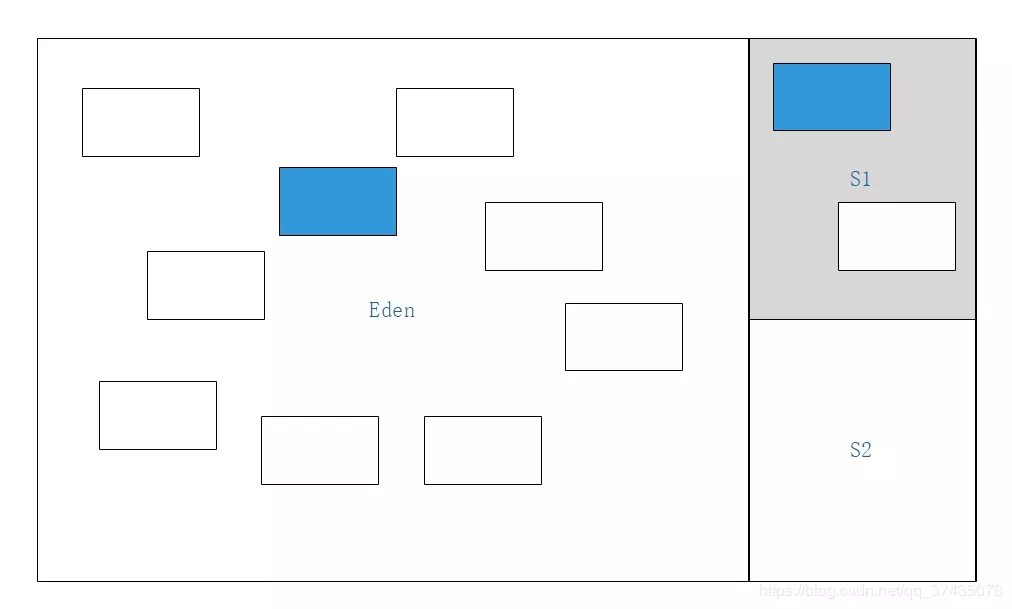
3.将标记对象全部复制到另一块Survivor区域中
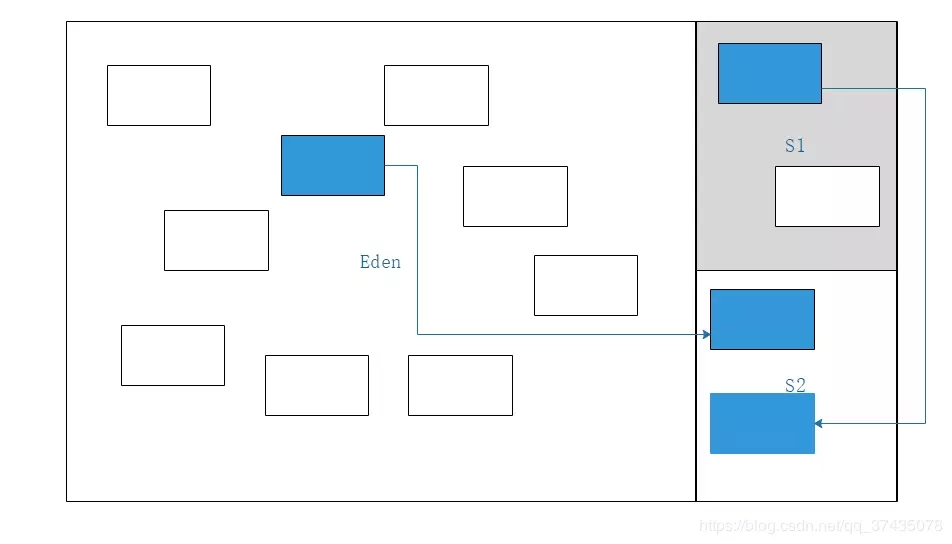
4.清理掉Eden区和激活的Survivor区中的所有对象,然后交换两块区域的激活状态
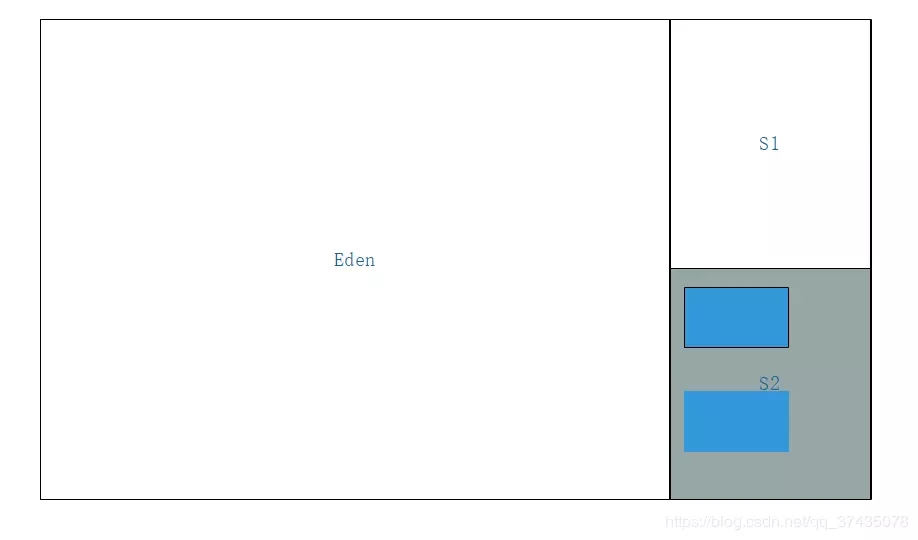
以上就是整个复制算法的全过程了,有人可能会问了,为什么Survivor区这么小,就不怕放不下吗?其实平均来说,每次垃圾回收的时候基本都会回收98%左右的对象,也就是说,我们完全可以保证大部分情况下剩余的对象都小于10%,放在一块Survivor区中是没问题的。当然,也可能会发生Survivor区不够用的问题,这时候就需要依赖其他内存给我们提供后备了
这种算法较好地解决了内存利用率低的问题,但是复制算法的两个问题依然没有解决:
标记-整理算法
这种算法可以说是专门针对对象存活率高的程序,具体的流程如下:
1.GC发生时,将所有被标记的存活对象移动到内存的一端
2.移动完成后,清理掉所有移动后的边界以外的对象
我相信大家在理解了前面几个算法之后,这个算法也能很方便地理解,我就不画图了,用一个例子来解释:
问题:对于一个长度为n的数组,我们想要保留其中所有小于10的数字,其余的数字删掉
方案:可以遍历一遍数据,将所有小于10的数字全部放到数组的最左侧,最终,数组的0~m(0<=m<=n)位置全部都是小于10的数字,然后我们只需要删除m+1~n的所有数字即可
这种方法的优点也显而易见:
但是依然还是有缺点的:
分代收集算法
别急,我们还没说完,还有最后一个分代收集算法,这个算法将Java堆划分为两块区域:
可以看出,分代收集算法按照对象在GC后的存活率将Java堆分为这样两块区域,针对不同区域采用不同的算法,就能尽可能地做到“扬长补短”,来提高垃圾回收的效率
总结
最后,垃圾回收的几种常见算法已经为大家介绍完毕,接下来如果有机会我会再介绍一下几种常见的垃圾回收器
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。