您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这段时间在看周志华大佬的《机器学习》,在看书的过程中,有时候会搜搜其他人写的文章,对比来讲,周教授讲的内容还是比较深刻的,但是前几天看到SVM这一章的时候,感觉甚是晦涩啊,第一感觉就是比较抽象,特别是对于像本人这种IQ不怎么高的,涉及到高维向量之后,对模型的理解就比较懵了,特别是对于那个几何距离(或者说是最大间隔),一直是模棱两可,似懂非懂的感觉,本人也看了其他人写的SVM的文章,好多都没用讲清楚那个最大间隔模型 d = 1/||w|| 为什么分子是1而不是|f(x)|。苦思冥想之后,给了一个适合自己理解的解释。
现有n维数据集Dx={x1, x2, x3, ... , xi, ... , xn},其中样本xi的类别yi∈Y={+1,-1}即数据集为D,且D= {d1, d2, ... ,di , ... ,dm }={(x1,y1), (x2,y2), (x3,y3),... , (xj,yj), (xm,ym)}。其样本分布如下图所示:
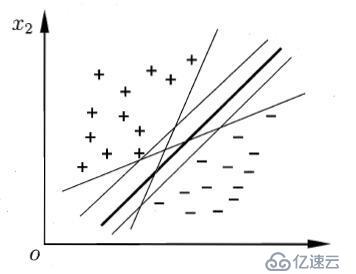
尝试用一条“直线”(超平面)将这两类数据点(向量)进行分类,位于使得位于两侧的样本属于不同的类。显然,这样的直线或者说是超平面有很多,那么应该怎么选取呢,如何定义一个最好的分类超平面呢?
对于最好的超平面,从直觉上最中间的那条粗黑线是最好的,因为它使两类样本点都离其最远,即可以使得分类模型的鲁棒性最好,不至于像其他超平面模型,对于样本的扰动(可理解为“噪声”)“容忍性”小。显然对于该“直线”可以用w、b参数进行表示,其中w=(w1, w2, w3, ... , wi, wn).
超平面为:
wx +b = 0
其中x = (xi1; xi2 ;xi3 ; ... ; xij; xim);位列向量,也可以写成w^T X + b = 0,那么w就是列向量,这里方便公式编辑采用第一种表示,意义一样。显然w、b都是未知的参数,联想到线性规划并进行推广,若样本点(向量)xi满足wxi+ b > 0 ; 则xi属于+1类,即yi = +1 ;若wxi+ b < 0 ; 则xi属于-1类,即yi = -1;定义函数f(xi) = wxi + b ,又定义g(xi,yi)= g(di) = yi * (wxi + b) = yi * f(xi) ,显然,yi与f(xi)总是同号的,故g(xi,yi) > 0。
言归正传,为什么要定义函数f和g呢,因为我们得通过这两个函数来求得权向量w和阈值b,以确定分类最好的超平面,那么问题又来了,“最优”超平面需满足什么条件呢,或者说,在满足什么条件下,这个超平面“最优”?这就转化为了一个优化问题。刚才讨论的时候,我们已经假设了该超平面L:
wx + b = 0 ;那么对于给定的数据集D= {d1, d2, ... ,di , ... ,dn }={(x1,y1), (x2,y2), (x3,y3),... , (xi,yi), (xn,yn)};肯定存在至少一个正样本点 di = (xi, +1),至少一个负样本dj = (xj, -1),他,对于它们各自而言,在正样本中,di是“距离”L最近的样本点(向量),设最近距离为li同理,在负样本中,dj是“距离”L最近的样本点,设最近距离为lj联想二维空间中点到直线的距离公式,同时对此进行一个推广,定义一个距离γ = li + lj = (|wxi + b| + |wxj + b| ) / ||w|| ,显然,只有当γ最大时,L才是我们想要的超平面。即:
max γ
那么问题又来了,单就上述γ定义的形式而言,似乎不怎么好求解最大值,这以上是我自己定义的,在周
的《机器学习》中,直接令:
wxi+ b ≥ 1 (yi = +1)
{
wxi+ b ≤ -1 (yi = -1)
然后,定义距离d = 2/||w||,本人疑惑就来了,为何直接令wxi+ b ≥ 1 (yi = +1) 和 wxi+ b ≤ -1 (yi = -1),就几何意义,这两个面与超平面wxi+ b = 0“平行”且“距离”都为1,就这么“霸气”地令,实在是令我百思不得其解,于是,开始参阅一些其他人写的博客,有很多人都不理解这个2是如何来的,我也没有找到让自己很容易理解的文章,倒是找到了一篇不错的讲SVM的博文(http://www.blogjava.net/zhenandaci/archive/2009/02/13/254519.html),但是也没有讲清楚距离那个d = 2/||w||,只好自己苦想。
我发现,可以这么来解释,上文中提到的li和lj,对于给定的样本集,其到超平面的距离di和dj肯定是
定的,即di = wxi +b中,虽然w和b是未知参数,但是di确定,同理dj = wxj + b中,dj确定,不妨设
DiLj = di + dj
则 DiLj亦是确定的,于是乎:
γ = DiLj / ||w||
对于 max γ <=> max (1 / ||w||),这就相当于分别将di = |wxi + b| / ||w|| ,dj = |wxj + b| / ||w|| 进行归一化得di' = 1 / ||w|| , dj' = 1 / ||w|| ,于是乎:
max 2 / ||w||
s.t. g(di) = g((xi,yi)) ≥ 1 (i = 1, 2, 3, ... , m) ;
其中||w||为范数,一般而言,是指向量长度,w = √w1^2 + w2^2 + ... + wn^2 则上述模型等价于:
min 1/2 * ||w||^2
s.t. g(di) = g((xi,yi)) ≥ 1 (i = 1, 2, 3, ... , m) ;
就好理解了。
位于 wx + b = ±1 上的样本点(向量)称为"支持向量",似乎跟该模型更多的利用了“支持向量”???,自己也不是很确定(待续)。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。