жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іJAVA8жөҒд№ӢжҰӮеҝөе’Ң收йӣҶеҷЁзҡ„зӨәдҫӢеҲҶжһҗпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
еңЁжІЎжңүжөҒд»ҘеүҚпјҢеӨ„зҗҶйӣҶеҗҲйҮҢйқўзҡ„ж•°жҚ®дёҖиҲ¬йғҪдјҡз”ЁеҲ°жҳҫзӨәзҡ„иҝӯд»ЈеҷЁгҖӮз”ЁдёҖдёӢеүҚйқўеӯҰз”ҹзҡ„дҫӢеӯҗеҗ§гҖӮзӣ®ж ҮжҳҜиҺ·еҫ—еӯҰеҲҶеӨ§дәҺ5зҡ„еүҚдҝ©дҪҚеҗҢеӯҰгҖӮ
package com.aomi;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import static java.util.stream.Collectors.toList;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
List<Student> stus = getSources();
Iterator<Student> ite = stus.iterator();
List<String> names = new ArrayList<>();
int limit = 2;
while (ite.hasNext() && limit > 0) {
Student stu = ite.next();
if (stu.getScore() > 5) {
names.add(stu.getName());
limit--;
}
}
for (String name : names) {
System.out.println(name);
}
}
public static List<Student> getSources() {
List<Student> students = new ArrayList<>();
Student stu1 = new Student();
stu1.setName("lucy");
stu1.setSex(0);
stu1.setPhone("13700227892");
stu1.setScore(9);
Student stu2 = new Student();
stu2.setName("lin");
stu2.setSex(1);
stu2.setPhone("15700227122");
stu2.setScore(9);
Student stu3 = new Student();
stu3.setName("lili");
stu3.setSex(0);
stu3.setPhone("18500227892");
stu3.setScore(8);
Student stu4 = new Student();
stu4.setName("dark");
stu4.setSex(1);
stu4.setPhone("16700555892");
stu4.setScore(6);
students.add(stu1);
students.add(stu2);
students.add(stu3);
students.add(stu4);
return students;
}
}еҰӮжһңз”ЁжөҒзҡ„иҜқжҳҜиҝҷж ·еӯҗзҡ„гҖӮ
public static void main(String[] args) {
// TODO Auto-generated method stub
List<Student> stus = getSources();
List<String> names = stus.stream()
.filter(st -> st.getScore() > 5)
.limit(2)
.map(st -> st.getName())
.collect(toList());
for (String name : names) {
System.out.println(name);
}
}жҠҠиҝҷдҝ©ж®өд»Јз ҒзӣёжҜ”иҫғдё»иҰҒжҳҜдёәдәҶиҜҙжҳҺдёҖдёӘжҰӮеҝөпјҡд»ҘеүҚеҒҡжі•йғҪжҳҜеңЁеӨ–йғЁиҝӯд»ЈпјҢжңҖдёәдҪ“зҺ°е°ұжҳҜ笔иҖ…еңЁеӨ–йқўе®ҡд№үдәҶдёҖдёӘйӣҶеҗҲnames гҖӮиҖҢжөҒеҚҙд»Җд№Ҳд№ҹжІЎжңүпјҢзҺ°еңЁжҲ‘们еә”иҜҘиғҪжё…жҘҡж„ҹеҸ—еҲ°жөҒжҳҜеңЁеҶ…йғЁиҝӯд»ЈгҖӮд№ҹе°ұжҳҜиҜҙжөҒе·Із»Ҹеё®дҪ еҒҡеҘҪдәҶиҝӯд»ЈгҖӮжҲ‘们еҸӘиҰҒдј е…Ҙзӣёе…ізҡ„еҮҪж•°е°ұеҸҜд»Ҙеҫ—еҲ°жғіиҰҒзҡ„з»“жһңгҖӮиҮідәҺеҶ…йғЁиҝӯд»Јзҡ„еҘҪеӨ„пјҢ笔иҖ…жІЎжңүеҠһжі•дәІиә«зҡ„ж„ҹеҸ—пјҢе”ҜдёҖзҡ„ж„ҹи§үе°ұжҳҜд»Јз ҒеҸҳзҡ„з®ҖеҚ•жҳҺдәҶдәҶгҖӮдҪҶжҳҜе®ҳж–№иҜҙStreamеә“дёәдәҶжҲ‘们еңЁеҶ…йғЁиҝӯд»ЈйҮҢйқўеҒҡдәҶеҫҲеӨҡдјҳеҢ–е’Ңе……е…¬еҲ©з”ЁжҖ§иғҪзҡ„ж“ҚдҪңгҖӮжҜ”еҰӮ并иЎҢж“ҚдҪңгҖӮжүҖд»Ҙ笔иҖ…е°ұеҗ¬е®ҳж–№дәҶгҖӮ
дәӢе®һдёҠпјҢеңЁз”ЁжөҒзҡ„иҝҮзЁӢдёӯпјҢжҲ‘们用еҲ°еҫҲеӨҡж–№жі•еҮҪж•°гҖӮжҜ”еҰӮдёҠйқўзҡ„limitж–№жі•пјҢfilterж–№жі•зӯүгҖӮиҝҷдёӘе®ҡд№үдёәжөҒж“ҚдҪңгҖӮдҪҶжҳҜдёҚз®ЎжҳҜд»Җд№Ҳж“ҚдҪңпјҢдҪ еҝ…йЎ»иҰҒжңүдёҖдёӘж•°жҚ®жәҗеҗ§гҖӮжҖ»з»“еҰӮдёӢпјҡ
ж•°жҚ®жәҗпјҡз”ЁдәҺз”ҹжҲҗжөҒзҡ„ж•°жҚ®пјҢжҜ”еҰӮйӣҶеҗҲгҖӮ
жөҒж“ҚдҪңпјҡзұ»дјјдәҺlimitж–№жі•пјҢfilterж–№жі•гҖӮ
жөҒиҝҳжңүдёҖз§Қзү№зӮ№вҖ”вҖ”йғЁеҲҶжөҒж“ҚдҪңжҳҜжІЎжңүжү§иЎҢзҡ„гҖӮдёҖиҲ¬йғҪжҳҜеңЁcollectеҮҪж•°жү§иЎҢзҡ„ж—¶еҖҷпјҢжүҚејҖе§Ӣжү§иЎҢдёӘдёӘеҮҪж•°гҖӮжүҖд»ҘжҲ‘们еҸҜд»Ҙз»ҶеҲҶдёҖдёӢжөҒж“ҚдҪңпјҡ
ж•°жҚ®жәҗпјҡз”ЁдәҺз”ҹжҲҗжөҒзҡ„ж•°жҚ®пјҢжҜ”еҰӮйӣҶеҗҲгҖӮ
дёӯй—ҙж“ҚдҪңпјҡзұ»дјјдәҺlimitж–№жі•пјҢfilterж–№жі•гҖӮиҝҷдәӣж“ҚдҪңеҒҡеҸҳдәҶдёҖдёӘж“ҚдҪңй“ҫпјҢжңүдёҖзӮ№жөҒж°ҙзәҝзҡ„жҰӮеҝөгҖӮ
з»Ҳз«Ҝж“ҚдҪңпјҡжү§иЎҢдёҠйқўзҡ„ж“ҚдҪңй“ҫгҖӮжҜ”еҰӮcollectеҮҪж•°гҖӮ
д»ҺдёҠйқўзҡ„и®Іи§ЈжҲ‘们е°ұеҸҜд»Ҙж„ҹи§үжөҒеҘҪеғҸжҳҜе…Ҳ收йӣҶзӣёе…ізҡ„зӣ®ж Үж“ҚдҪңпјҢд»Җд№Ҳж„ҸжҖқе‘ўпјҹе°ұжҳҜе…ҲжҠҠиҰҒеҒҡзҡ„дәӢжғ…и®ЎеҲ’дёҖдёӢпјҢжңҖеҗҺдёҖеЈ°д»ӨдёӢжү§иЎҢгҖӮиҖҢдёӢиҝҷдёӘе‘Ҫд»ӨжҳҜcollectеҮҪж•°гҖӮиҝҷдёҖзӮ№и·ҹ.NETзҡ„LinqжҳҜеҫҲеғҸзҡ„гҖӮеҗҢж—¶и®°еҫ—д»–еҸӘиғҪжү§иЎҢдёҖж¬ЎгҖӮд№ҹе°ұжҳҜиҜҙиҝҷдёӘжөҒжү§иЎҢдёҖж¬Ўд№ӢеҗҺпјҢе°ұдёҚеҸҜиғҪеңЁз”ЁдәҶгҖӮ
笔иҖ…еҲ—дёҖдёӢд»ҘеүҚзҡ„з”ЁеҲ°зҡ„еҮҪж•°
forEachпјҡз»Ҳз«Ҝ
collectпјҡз»Ҳз«Ҝ
countпјҡз»Ҳз«Ҝ
limitпјҡдёӯй—ҙ
filterпјҡдёӯй—ҙ
mapпјҡдёӯй—ҙ
sortedпјҡдёӯй—ҙ
еҲ°зӣ®еүҚдёәжӯўжҲ‘们用еҲ°зҡ„жөҒйғҪжҳҜйҖҡиҝҮйӣҶеҗҲжқҘе»әдёҖдёӘжөҒгҖӮ笔иҖ…еҜ№жӯӨд»ҺжқҘжІЎжңүи®ІиҝҮгҖӮзҺ°еңЁз¬”иҖ…жқҘи®Ідәӣжһ„е»әжөҒзҡ„ж–№ејҸгҖӮ
еңЁstreamеә“йҮҢйқўдёәжҲ‘们жҸҗдҫӣдәҶиҝҷж ·еӯҗдёҖдёӘж–№жі•вҖ”вҖ”Stream.of
package com.aomi;
import java.util.Optional;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
Stream stream = Stream.of("I", "am", "aomi");
Optional<String> firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第дёҖдёӘеӯ—пјҡ"+firstWord.get());
}
}
}иҝҗиЎҢз»“жһңпјҡ
еҺ»зңӢдёҖдёӢofж–№жі•зҡ„д»Јз ҒгҖӮеҰӮдёӢ
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}иҜҙжҳҺжҲ‘们еҸҜиғҪжҢҮе®ҡдёҖдёӘзұ»еһӢжқҘе»әдёҖдёӘжөҒгҖӮдёҠйқўеҸҜд»Ҙдҝ®ж”№дёә
Stream<String> stream = Stream.of("I", "am", "aomi");findFirstеҮҪж•°з”ЁдәҺиЎЁзӨәиҝ”еӣһ第дёҖдёӘеҖјгҖӮйӮЈе°ұжҳҜеҸҜиғҪж•°жҚ®жәҗжҳҜдёҖдёӘз©әе‘ўпјҹжүҖд»Ҙд»–жңүеҸҜд»Ҙдјҡиҝ”еӣһnullгҖӮжүҖд»Ҙе°ұжҳҜз”ЁдёҖдёӘеҸ«Optionalзұ»зҡ„иЎЁзӨәеҸҜд»Ҙдёәз©әгҖӮиҝҷж ·еӯҗжҲ‘们е°ұеҸҜд»Ҙз”ЁOptionalзұ»зҡ„ж–№жі•иҝӣдёҖжӯҘеҒҡе®үе…ЁжҖ§зҡ„ж“ҚдҪңгҖӮжҜ”еҰӮеҲӨж–ӯжңүжІЎжңүеҖјпјҲisPresent()пјү
笔иҖ…жғіиҰҒе»әдёҖдёӘintзұ»еһӢзҡ„ж•°з»„жөҒзҺ©зҺ©гҖӮдёәдәҶж–№дҫҝ笔иҖ…дҫҝиҜ•з»ҷдёҖдёӢдёҠйқўзҡ„д»Јз ҒгҖӮеҚҙеҸ‘зҺ°жҠҘй”ҷдәҶгҖӮ
еҰӮжһңжҲ‘жҠҠintж”№дёәIntegerе‘ўпјҹжІЎжңүй—®йўҳдәҶгҖӮжүҖд»ҘжіЁж„ҸиҰҒз”Ёеј•з”Ёзұ»еһӢзҡ„гҖӮintзұ»еһӢеҜ№еә”дёәIntegerзұ»еһӢгҖӮ
package com.aomi;
import java.util.Optional;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
Stream<Integer> stream = Stream.of(1, 2, 9);
Optional<Integer> firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第дёҖдёӘеӯ—пјҡ"+firstWord.get());
}
}
}иҝҗиЎҢз»“жһңпјҡ

йӮЈжғіиҰҒз”Ёintзұ»еһӢе‘ў?д»Җд№ҲеҠһе‘ўпјҹж”№ж”№
package com.aomi;
import java.util.OptionalInt;
import java.util.stream.IntStream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
IntStream stream = IntStream.of(1, 2, 9);
OptionalInt firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第дёҖдёӘеӯ—пјҡ"+firstWord.getAsInt());
}
}
}иҝҗиЎҢз»“жһңпјҡ

жҲ‘们д»ҘдёҠйқўзҡ„дҫӢеӯҗжқҘдёҖдёӘзҢңжөӢпјҡжҳҜдёҚжҳҜDoubleзұ»еһӢпјҢеҸӘиҰҒдҝ®ж”№дёәDoubleStreamе°ұиЎҢе‘ўпјҹиҜ•иҜ•гҖӮ
package com.aomi;
import java.util.OptionalDouble;
import java.util.stream.DoubleStream;
public class Main {
public static void main(String[] args) {
// TODO Auto-generated method stub
DoubleStream stream = DoubleStream.of(1.3, 2.3, 9.5);
OptionalDouble firstWord = stream.findFirst();
if(firstWord.isPresent())
{
System.out.println("第дёҖдёӘеӯ—пјҡ"+firstWord.getAsDouble());
}
}
}иҝҗиЎҢз»“жһңпјҡ

з»“жһңеҫҲжҳҺжҳҫпјҢжҲ‘们зҡ„зҢңжөӢжҳҜеҜ№зҡ„гҖӮжүҖд»Ҙи§Ғж„ҸеҰӮжһңдҪ ж“ҚдҪңзҡ„жөҒжҳҜдёҖдёӘintжҲ–жҳҜdoubleзҡ„иҜқпјҢиҜ·иҝӣеҸҜиғҪзҡ„з”ЁXxxStream жқҘе»әжөҒгҖӮиҝҷж ·еӯҗеңЁжөҒзҡ„иҝҮзЁӢдёӯдёҚз”ЁиҝӣиЎҢжӢҶиЈ…е’Ңе°ҒиЈ…дәҶгҖӮеҝ…з«ҹиҝҷжҳҜиҰҒжҖ§иғҪзҡ„гҖӮеңЁзңӢдёҖдёӢеҰӮжһңж•°жҚ®жәҗжҳҜдёҖдёӘж•°з»„зҡ„жғ…еҶөжҲ‘们еҰӮдҪ•з”ҹжҲҗжөҒе‘ўпјҹ
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter,
CharSequence prefix,
CharSequence suffix) {
return new CollectorImpl<>(
() -> new StringJoiner(delimiter, prefix, suffix),
StringJoiner::add, StringJoiner::merge,
StringJoiner::toString, CH_NOID);
}еңЁзңӢдёҖдёӘеҸ«toListеҮҪж•°зҡ„д»Јз ҒгҖӮ
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}жҲ‘们еҸ‘зҺ°д»–дјҡе…ұеҗҢзҡ„иҝ”еӣһдёҖдёӘCollectorзұ»еһӢгҖӮд»ҺдёҠйқўжҲ‘们е°ұеҸҜд»ҘзҹҘйҒ“д»–зҡ„д»»еҠЎе°ұжҳҜз”ЁеҺ»еӨ„зҗҶжңҖеҗҺж•°жҚ®гҖӮжҲ‘们жҠҠд»–е®ҡдёә收йӣҶеҷЁгҖӮи®©жҲ‘们зңӢдёҖдёӢ收йӣҶеҷЁзҡ„жҺҘеҸЈд»Јз Ғеҗ§;
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
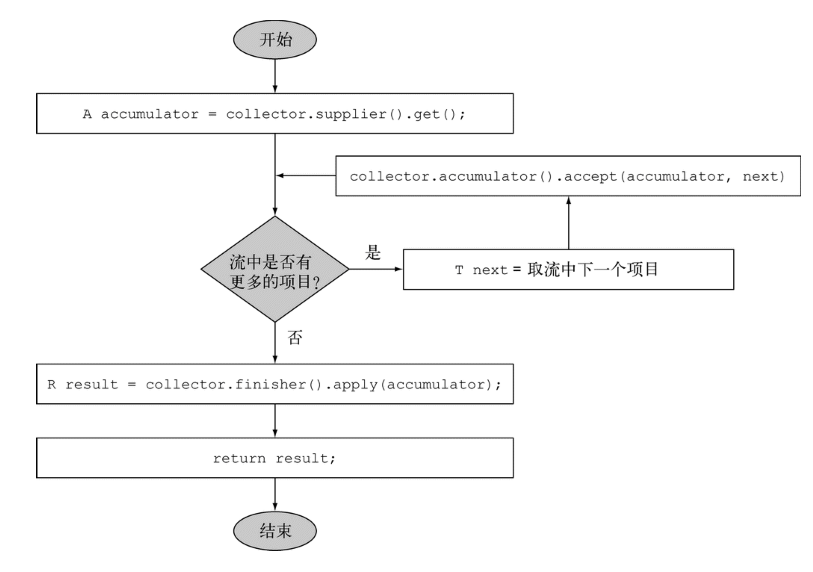
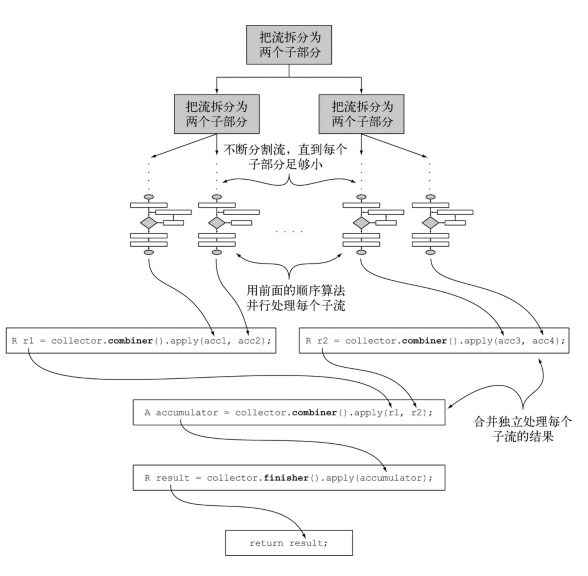
}е…үзңӢеүҚйқўеӣӣдёӘж–№жі•жҳҜдёҚжҳҜжңүдёҖзӮ№зҶҹжӮүзҡ„ж„ҹи§үгҖӮжғіиҰҒиҜҙжҳҺиҝҷдёӘдә”дёӘж–№жі•зҡ„дҪңз”ЁгҖӮе°ұеҝ…йЎ»жҳҺзҷҪдёҖдёӘжҰӮеҝөвҖ”вҖ”并иЎҢеҪ’зәҰгҖӮеүҚйқўз¬”иҖ…и®ІиҝҮжөҒжҳҜдёҖдёӘеҶ…йғЁиҝӯд»ЈпјҢд№ҹиҜҙStreamеә“дёәжҲ‘们еҒҡдёҖдёӘеҫҲеӨҡдјҳеҢ–зҡ„дәӢжғ…гҖӮе…¶дёӯдёҖдёӘе°ұжҳҜ并иЎҢгҖӮд»–з”ЁеҲ°дәҶJAVA 7еј•е…Ҙзҡ„еҠҹиғҪвҖ”вҖ”еҲҶж”Ҝ/еҗҲ并жЎҶжһ¶гҖӮд№ҹе°ұжҳҜиҜҙжөҒдјҡд»ҘйҖ’еҪ’зҡ„ж–№ејҸжӢҶеҲҶжҲҗеҫҲеӨҡеӯҗжөҒпјҢ然еҗҺеӯҗжөҒеҸҜд»Ҙ并иЎҢжү§иЎҢгҖӮжңҖеҗҺеңЁдҝ©дҝ©зҡ„еӯҗжөҒзҡ„з»“жһңеҗҲ并жҲҗдёҖдёӘжңҖз»Ҳз»“жһңгҖӮиҖҢиҝҷдҝ©дҝ©еҗҲ并зҡ„иЎҢдёәе°ұеҸ«еҪ’зәҰ гҖӮеҰӮеӣҫдёӢгҖӮеј•з”ЁдәҺгҖҠJAVA8е®һжҲҳгҖӢ
жҲ‘们еҝ…йЎ»ж №жҚ®еӣҫдёҠзҡ„ж„ҸжҖқжқҘиө°гҖӮеӯҗжөҒзҡ„еӣҫйҮҢйқўдјҡи°ғз”ЁеҲ°Collectorзұ»зҡ„дёүдёӘж–№жі•гҖӮ
supplierж–№жі•пјҡз”ЁеҲӣе»әж•°жҚ®еӯҳеӮЁзҡ„ең°ж–№гҖӮ
accumulatorж–№жі•пјҡз”ЁдәҺеӯҗжөҒжү§иЎҢиҝҮзЁӢзҡ„иҝӯд»Је·ҘдҪңгҖӮеҚіжҳҜйҒҚеҺҶжҜҸдёҖйЎ№йғҪдјҡжү§иЎҢгҖӮжүҖд»ҘеҸҜд»ҘиҝҷйҮҢеҒҡдёҖдәӣе·ҘдҪңгҖӮ
finisherж–№жі•пјҡиҝ”еӣһжңҖеҗҺзҡ„з»“жһңпјҢдҪ еҸҜд»ҘеңЁиҝҷйҮҢиҝӣдёҖжӯҘеӨ„зҗҶз»“жһңгҖӮ
жҜҸдёҖдёӘеӯҗжөҒз»“жқҹиҝҷд№ӢеҗҺпјҢе°ұжҳҜдҝ©дҝ©еҗҲ并гҖӮиҝҷдёӘж—¶еҖҷе°ұиҰҒзңӢжөҒзҡ„жңәеҲ¶еӣҫдәҶгҖӮ
combinerж–№жі•пјҡдјҡдј е…ҘжҜҸдёҖдёӘеӯҗжөҒзҡ„з»“жһңиҝҮжқҘпјҢжҲ‘们е°ұеҸҜд»ҘеңЁиҝҷйҮҢеңЁеҒҡдёҖдәӣе·ҘдҪңгҖӮ
finisherж–№жі•пјҡиҝ”еӣһжңҖеҗҺзҡ„з»“жһңгҖӮеҗҢдёҠйқўеӯҗжөҒзҡ„дёҖж ·еӯҗгҖӮ
еҘҪеғҸжІЎжңүcharacteristicsд»Җд№ҲдәӢжғ…гҖӮдёҚжҳҜиҝҷж ·еӯҗзҡ„гҖӮиҝҷдёӘж–№жі•жҳҜз”ЁжқҘиҜҙжҳҺеҪ“еүҚиҝҷдёӘжөҒе…·еӨҮе“ӘдәӣдјҳеҢ–гҖӮиҝҷж ·еӯҗжү§иЎҢжөҒзҡ„ж—¶еҖҷпјҢе°ұеҸҜд»ҘеҫҲжё…жҘҡзҡ„зҹҘйҒ“иҰҒд»Ҙд»Җд№Ҳж ·еӯҗзҡ„ж–№ејҸжү§иЎҢдәҶгҖӮжҜ”еҰӮ并иЎҢгҖӮ
д»–жҳҜдёҖдёӘenumзұ»гҖӮеҖјеҰӮдёӢ
UNORDEREDпјҡиҝҷдёӘиЎЁзӨәжү§иЎҢиҝҮзЁӢдёӯз»“жһңдёҚеҸ—еҪ’зәҰе’ҢйҒҚеҺҶзҡ„еҪұе“Қ
CONCURRENTпјҡиЎЁзӨәеҸҜд»ҘеӨҡдёӘзәҝе’Ңи°ғз”Ёaccumulatorж–№жі•гҖӮ并且еҸҜд»Ҙжү§иЎҢ并иЎҢгҖӮеҪ“然еүҚж— еәҸж•°жҚ®зҡ„жүҚ并иЎҢгҖӮйҷӨйқһ收йӣҶеҷЁж ҮдәҶUNORDEREDгҖӮ
IDENTITY_FINISHпјҡиЎЁзӨәиҝҷжҳҜдёҖдёӘжҒ’зӯүеҮҪж•°пјҢе°ұжҳҜеҒҡдәҶз»“жһңд№ҹдёҖж ·еӯҗгҖӮдёҚз”ЁеҒҡдәҶеҸҜд»Ҙи·іиҝҮдәҶгҖӮ
з”ұдәҶдёҠйқўзҡ„и®ІиҜҙжҳҺпјҢжҲ‘们еңЁжқҘеҶҷдёҖдёӘиҮӘе·ұзҡ„收йӣҶеҷЁеҗ§вҖ”вҖ”еҺ»йҷӨзӣёеҗҢзҡ„еҚ•иҜҚ
DistinctWordCollectorзұ»пјҡ
package com.aomi;
import java.util.ArrayList;
import java.util.Collections;
import java.util.EnumSet;
import java.util.List;
import java.util.Set;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
public class DistinctWordCollector implements Collector<String, List<String>, List<String>> {
@Override
public Supplier<List<String>> supplier() {
// TODO Auto-generated method stub
return () -> new ArrayList<String>();
}
/**
* еӯҗжөҒзҡ„еӨ„зҗҶйЎ№зҡ„иҝҮзЁӢ
*/
@Override
public BiConsumer<List<String>, String> accumulator() {
// TODO Auto-generated method stub
return (List<String> src, String val) -> {
if (!src.contains(val)) {
src.add(val);
}
};
}
/**
* дҝ©дҝ©е№¶еҗҲзҡ„жү§иЎҢеҮҪж•°
*/
@Override
public BinaryOperator<List<String>> combiner() {
// TODO Auto-generated method stub
return (List<String> src1, List<String> src2) -> {
for (String val : src2) {
if (!src1.contains(val)) {
src1.add(val);
}
}
return src1;
};
}
@Override
public Function<List<String>, List<String>> finisher() {
// TODO Auto-generated method stub
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
// TODO Auto-generated method stub
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH, Characteristics.CONCURRENT));
}
}Main:
public static void main(String[] args) {
// TODO Auto-generated method stub
List<String> words = Arrays.asList("aomi","lili","lucy","aomi","Nono");
List<String> vals = words.stream().collect(new DistinctWordCollector());
for (String val : vals) {
System.out.println(val);
}
}иҝҗиЎҢз»“жһң

з»“жһңзЎ®е®ҡе°ұжҳҜжҲ‘们жғіиҰҒзҡ„вҖ”вҖ”еҺ»жҺүдәҶйҮҚеӨҚзҡ„aomi
е…ідәҺвҖңJAVA8жөҒд№ӢжҰӮеҝөе’Ң收йӣҶеҷЁзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ