您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
最近“全网域(Web Scale)”一词被炒得火热,人们也正在通过扩展他们的应用程序架构来使他们的系统变得更加“全网域”。但是究竟什么是全网域?或者说如何确保全网域?
全网域被炒作的最多的是扩展负载(Scaling load),比如支持单个用户访问的系统也可以支持10 个、100个、甚至100万个用户访问。在理想情况下,我们的系统应该保持尽可能的“无状态化(stateless)”。即使必须存在状态,也可以在网络的不同处理终端上转化并进行传输。当负载成为瓶颈时候,可能就不会出现延迟。所以对于单个请求来说,耗费50到100毫秒也是可以接受的。这就是所谓的横向扩展(Scaling out)。
扩展在全网域优化中的表现则完全不同,比如确保成功处理一条数据的算法也可成功处理10条、100条甚至100万条数据。无论这种度量类型是是否可行,事件复杂度(大O符号)是最佳描述。延迟是性能扩展杀手。你会想尽办法将所有的运算处理在同一台机器上进行。这就是所谓的纵向扩展(Scaling up)。
如果天上能掉馅饼的话(当然这是不可能的),我们或许能把横向扩展和纵向扩展组合起来。但是,今天我们只打算介绍下面几条提升效率的简单方法。
Java 7的 ForkJoinPool 和Java8 的并行数据流(parallel Stream) 都对并行处理有所帮助。当在多核处理器上部署Java程序时表现尤为明显,因所有的处理器都可以访问相同的内存。
所以,这种并行处理较之在跨网络的不同机器上进行扩展,根本的好处是几乎可以完全消除延迟。
但不要被并行处理的效果所迷惑!请谨记下面两点:
降低算法复杂度毫无疑问是改善性能最行之有效的办法。比如对于一个 HashMap 实例的 lookup() 方法来说,事件复杂度 O(1) 或者空间复杂度 O(1) 是最快的。但这种情况往往是不可能的,更别提轻易地实现。
如果你不能降低算法的复杂度,也可以通过找到算法中的关键点并加以改善的方法,来起到改善性能的作用。假设我们有下面这样的算法示意图:
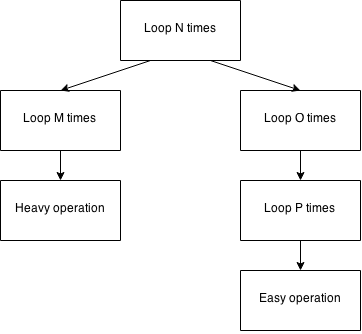
该算法的整体时间复杂度为 O(N3),如果按照单独访问顺序计算也可得出复杂度为 O(N x O x P)。但是不管怎样,在我们分析这段代码时会发现一些奇怪的场景:
在没有生产数据参照的情况下,我们可能会轻易的得出要优化“高开销操作”的结论。但我们做出的优化对交付的产品没有起到任何效果。
优化的金科玉律不外乎以下内容:
理论就先谈到这里。假设我们已经发现了问题出现在了右分支上,很有可能是因产品中的简单处理因耗费了大量的时间而失去响应(假设N、O和 P 的值非常大), 请注意文章中提及的左分支的时间复杂度为 O(N3)。这里所做出的努力并不能扩展,但可以为用户节省时间,将困难的性能改善推迟到后面再进行。
这里有10条改善Java性能的小建议:
1、使用StringBuilder
StingBuilder 应该是在我们的Java代码中默认使用的,应该避免使用 + 操作符。或许你会对 StringBuilder 的语法糖(syntax sugar)持有不同意见,比如:
String x = "a" + args.length + "b";
将会被编译为:
0 new java.lang.StringBuilder [16] 3 dup 4 ldc <String "a"> [18] 6 invokespecial java.lang.StringBuilder(java.lang.String) [20] 9 aload_0 [args] 10 arraylength 11 invokevirtual java.lang.StringBuilder.append(int) : java.lang.StringBuilder [23] 14 ldc <String "b"> [27] 16 invokevirtual java.lang.StringBuilder.append(java.lang.String) : java.lang.StringBuilder [29] 19 invokevirtual java.lang.StringBuilder.toString() : java.lang.String [32] 22 astore_1 [x]
但究竟发生了什么?接下来是否需要用下面的部分来对 String 进行改善呢?
String x = "a" + args.length + "b"; if (args.length == 1) x = x + args[0];
现在使用到了第二个 StringBuilder,这个 StringBuilder 不会消耗堆中额外的内存,但却给 GC 带来了压力。
StringBuilder x = new StringBuilder("a");
x.append(args.length);
x.append("b");
if (args.length == 1);
x.append(args[0]);
在上面的样例中,如果你是依靠Java编译器来隐式生成实例的话,那么编译的效果几乎和是否使用了 StringBuilder 实例毫无关系。请记住:在 N.O.P.E 分支中,每次CPU的循环的时间到白白的耗费在GC或者为 StringBuilder 分配默认空间上了,我们是在浪费 N x O x P 时间。
一般来说,使用 StringBuilder 的效果要优于使用 + 操作符。如果可能的话请在需要跨多个方法传递引用的情况下选择 StringBuilder,因为 String 要消耗额外的资源。JOOQ在生成复杂的SQL语句便使用了这样的方式。在整个抽象语法树(AST Abstract Syntax Tree)SQL传递过程中仅使用了一个 StringBuilder 。
更加悲剧的是,如果你仍在使用 StringBuffer 的话,那么用 StringBuilder 代替 StringBuffer 吧,毕竟需要同步字符串的情况真的不多。
正则表达式给人的印象是快捷简便。但是在 N.O.P.E 分支中使用正则表达式将是最糟糕的决定。如果万不得已非要在计算密集型代码中使用正则表达式的话,至少要将 Pattern 缓存下来,避免反复编译Pattern。
static final Pattern HEAVY_REGEX =
Pattern.compile("(((X)*Y)*Z)*");
如果仅使用到了如下这样简单的正则表达式的话:
String[] parts = ipAddress.split("\\.");
这是最好还是用普通的 char[] 数组或者是基于索引的操作。比如下面这段可读性比较差的代码其实起到了相同的作用。
int length = ipAddress.length();
int offset = 0;
int part = 0;
for (int i = 0; i < length; i++) {
if (i == length - 1 ||
ipAddress.charAt(i + 1) == '.') {
parts[part] =
ipAddress.substring(offset, i + 1);
part++;
offset = i + 2;
}
}
上面的代码同时表明了过早的优化是没有意义的。虽然与 split() 方法相比较,这段代码的可维护性比较差。
挑战:聪明的小伙伴能想出更快的算法吗?
正则表达式是十分有用,但是在使用时也要付出代价。尤其是在 N.O.P.E 分支深处时,要不惜一切代码避免使用正则表达式。还要小心各种使用到正则表达式的JDK字符串方法,比如 String.replaceAll() 或 String.split()。可以选择用比较流行的开发库,比如 Apache Commons Lang 来进行字符串操作。
这条建议不适用于一般的场合,仅适用于在 N.O.P.E 分支深处的场景。尽管如此也应该有所了解。Java 5格式的循环写法非常的方便,以至于我们可以忘记内部的循环方法,比如:
for (String value : strings) {
// Do something useful here
}
当每次代码运行到这个循环时,如果 strings 变量是一个 Iterable 的话,代码将会自动创建一个Iterator 的实例。如果使用的是 ArrayList 的话,虚拟机会自动在堆上为对象分配3个整数类型大小的内存。
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
int expectedModCount = modCount;
// ...
也可以用下面等价的循环方式来替代上面的 for 循环,仅仅是在栈上“浪费”了区区一个整形,相当划算。
int size = strings.size();
for (int i = 0; i < size; i++) {
String value : strings.get(i);
// Do something useful here
}
如果循环中字符串的值是不怎么变化,也可用数组来实现循环。
for (String value : stringArray) {
// Do something useful here
}
无论是从易读写的角度来说,还是从API设计的角度来说迭代器、Iterable接口和 foreach 循环都是非常好用的。但代价是,使用它们时是会额外在堆上为每个循环子创建一个对象。如果循环要执行很多很多遍,请注意避免生成无意义的实例,最好用基本的指针循环方式来代替上述迭代器、Iterable接口和 foreach 循环。
一些与上述内容持反对意见的看法(尤其是用指针操作替代迭代器)详见Reddit上的讨论。
有些方法的开销很大。以 N.O.P.E 分支为例,我们没有提到叶子的相关方法,不过这个可以有。假设我们的JDBC驱动需要排除万难去计算 ResultSet.wasNull() 方法的返回值。我们自己实现的SQL框架可能像下面这样:
if (type == Integer.class) {
result = (T) wasNull(rs,
Integer.valueOf(rs.getInt(index)));
}
// And then...
static final <T> T wasNull(ResultSet rs, T value)
throws SQLException {
return rs.wasNull() ? null : value;
}
在上面的逻辑中,每次从结果集中取得 int 值时都要调用 ResultSet.wasNull() 方法,但是 getInt() 的方法定义为:
返回类型:变量值;如果SQL查询结果为NULL,则返回0。
所以一个简单有效的改善方法如下:
static final <T extends Number> T wasNull(
ResultSet rs, T value
)
throws SQLException {
return (value == null ||
(value.intValue() == 0 && rs.wasNull()))
? null : value;
}
这是轻而易举的事情。
将方法调用缓存起来替代在叶子节点的高开销方法,或者在方法约定允许的情况下避免调用高开销方法。
上面介绍了来自 jOOQ的例子中使用了大量的泛型,导致的结果是使用了 byte、 short、 int 和 long 的包装类。但至少泛型在Java 10或者Valhalla项目中被专门化之前,不应该成为代码的限制。因为可以通过下面的方法来进行替换:
//存储在堆上 Integer i = 817598;
……如果这样写的话:
// 存储在栈上 int i = 817598;
在使用数组时情况可能会变得更加糟糕:
//在堆上生成了三个对象
Integer[] i = { 1337, 424242 };
……如果这样写的话:
// 仅在堆上生成了一个对象
int[] i = { 1337, 424242 };
当我们处于 N.O.P.E. 分支的深处时,应该极力避免使用包装类。这样做的坏处是给GC带来了很大的压力。GC将会为清除包装类生成的对象而忙得不可开交。
所以一个有效的优化方法是使用基本数据类型、定长数组,并用一系列分割变量来标识对象在数组中所处的位置。
遵循LGPL协议的 trove4j 是一个Java集合类库,它为我们提供了优于整形数组 int[] 更好的性能实现。
下面的情况对这条规则例外:因为 boolean 和 byte 类型不足以让JDK为其提供缓存方法。我们可以这样写:
Boolean a1 = true; // ... syntax sugar for: Boolean a2 = Boolean.valueOf(true); Byte b1 = (byte) 123; // ... syntax sugar for: Byte b2 = Byte.valueOf((byte) 123);
其它整数基本类型也有类似情况,比如 char、short、int、long。
不要在调用构造方法时将这些整型基本类型自动装箱或者调用 TheType.valueOf() 方法。
也不要在包装类上调用构造方法,除非你想得到一个不在堆上创建的实例。这样做的好处是为你为同事献上一个巨坑的愚人节笑话。
当然了,如果你还想体验下堆外函数库的话,尽管这可能参杂着不少战略决策,而并非最乐观的本地方案。一篇由Peter Lawrey和 Ben Cotton撰写的关于非堆存储的很有意思文章请点击: OpenJDK与HashMap——让老手安全地掌握(非堆存储!)新技巧。
现在,类似Scala这样的函数式编程语言都鼓励使用递归。因为递归通常意味着能分解到单独个体优化的尾递归(tail-recursing)。如果你使用的编程语言能够支持那是再好不过。不过即使如此,也要注意对算法的细微调整将会使尾递归变为普通递归。
希望编译器能自动探测到这一点,否则本来我们将为只需使用几个本地变量就能搞定的事情而白白浪费大量的堆栈框架(stack frames)。
这节中没什么好说的,除了在 N.O.P.E 分支尽量使用迭代来代替递归。
当我们想遍历一个用键值对形式保存的 Map 时,必须要为下面的代码找到一个很好的理由:
for (K key : map.keySet()) {
V value : map.get(key);
}
更不用说下面的写法:
for (Entry<K, V> entry : map.entrySet()) {
K key = entry.getKey();
V value = entry.getValue();
}
在我们使用 N.O.P.E. 分支应该慎用map。因为很多看似时间复杂度为 O(1) 的访问操作其实是由一系列的操作组成的。而且访问本身也不是免费的。至少,如果不得不使用map的话,那么要用 entrySet() 方法去迭代!这样的话,我们要访问的就仅仅是Map.Entry的实例。
在需要迭代键值对形式的Map时一定要用 entrySet() 方法。
8、使用EnumSet或EnumMap
在某些情况下,比如在使用配置map时,我们可能会预先知道保存在map中键值。如果这个键值非常小,我们就应该考虑使用 EnumSet 或 EnumMap,而并非使用我们常用的 HashSet 或 HashMap。下面的代码给出了很清楚的解释:
private transient Object[] vals;
public V put(K key, V value) {
// ...
int index = key.ordinal();
vals[index] = maskNull(value);
// ...
}
上段代码的关键实现在于,我们用数组代替了哈希表。尤其是向map中插入新值时,所要做的仅仅是获得一个由编译器为每个枚举类型生成的常量序列号。如果有一个全局的map配置(例如只有一个实例),在增加访问速度的压力下,EnumMap 会获得比 HashMap 更加杰出的表现。原因在于 EnumMap 使用的堆内存比 HashMap 要少 一位(bit),而且 HashMap 要在每个键值上都要调用 hashCode() 方法和 equals() 方法。
Enum 和 EnumMap 是亲密的小伙伴。在我们用到类似枚举(enum-like)结构的键值时,就应该考虑将这些键值用声明为枚举类型,并将之作为 EnumMap 键。
在不能使用EnumMap的情况下,至少也要优化 hashCode() 和 equals() 方法。一个好的 hashCode() 方法是很有必要的,因为它能防止对高开销 equals() 方法多余的调用。
在每个类的继承结构中,需要容易接受的简单对象。让我们看一下jOOQ的 org.jooq.Table 是如何实现的?
最简单、快速的 hashCode() 实现方法如下:
// AbstractTable一个通用Table的基础实现:
@Override
public int hashCode() {
// [#1938] 与标准的QueryParts相比,这是一个更加高效的hashCode()实现
return name.hashCode();
}
name即为表名。我们甚至不需要考虑schema或者其它表属性,因为表名在数据库中通常是唯一的。并且变量 name 是一个字符串,它本身早就已经缓存了一个 hashCode() 值。
这段代码中注释十分重要,因继承自 AbstractQueryPart 的 AbstractTable 是任意抽象语法树元素的基本实现。普通抽象语法树元素并没有任何属性,所以不能对优化 hashCode() 方法实现抱有任何幻想。覆盖后的 hashCode() 方法如下:
// AbstractQueryPart一个通用抽象语法树基础实现:
@Override
public int hashCode() {
// 这是一个可工作的默认实现。
// 具体实现的子类应当覆盖此方法以提高性能。
return create().renderInlined(this).hashCode();
}
换句话说,要触发整个SQL渲染工作流程(rendering workflow)来计算一个普通抽象语法树元素的hash代码。
equals() 方法则更加有趣:
// AbstractTable通用表的基础实现:
@Override
public boolean equals(Object that) {
if (this == that) {
return true;
}
// [#2144] 在调用高开销的AbstractQueryPart.equals()方法前,
// 可以及早知道对象是否不相等。
if (that instanceof AbstractTable) {
if (StringUtils.equals(name,
(((AbstractTable<?>) that).name))) {
return super.equals(that);
}
return false;
}
return false;
}
首先,不要过早使用 equals() 方法(不仅在N.O.P.E.中),如果:
注意:如果我们过早使用 instanceof 来检验兼容类型的话,后面的条件其实包含了argument == null。我在以前的博客中已经对这一点进行了说明,请参考10个精妙的Java编码最佳实践。
在我们对以上几种情况的比较结束后,应该能得出部分结论。比如jOOQ的 Table.equals() 方法说明是,用来比较两张表是否相同。不论具体实现类型如何,它们必须要有相同的字段名。比如下面两个元素是不可能相同的:
如果我们能方便地判断传入参数是否等于实例本身(this),就可以在返回结果为 false 的情况下放弃操作。如果返回结果为 true,我们还可以进一步对父类(super)实现进行判断。在比较过的大多数对象都不等的情况下,我们可以尽早结束方法来节省CPU的执行时间。
一些对象的相似度比其它对象更高。
在jOOQ中,大多数的表实例是由jOOQ的代码生成器生成的,这些实例的 equals() 方法都经过了深度优化。而数十种其它的表类型(衍生表 (derived tables)、表值函数(table-valued functions)、数组表(array tables)、连接表(joined tables)、数据透视表(pivot tables)、公用表表达式(common table expressions)等,则保持 equals() 方法的基本实现。
最后,还有一种情况可以适用于所有语言而并非仅仅同Java有关。除此以外,我们以前研究的 N.O.P.E. 分支也会对了解从 O(N3) 到 O(n log n)有所帮助。
不幸的是,很多程序员的用简单的、本地算法来考虑问题。他们习惯按部就班地解决问题。这是命令式(imperative)的“是/或”形式的函数式编程风格。这种编程风格在由纯粹命令式编程向面对象式编程向函数式编程转换时,很容易将“更大的场景(bigger picture)”模型化,但是这些风格都缺少了只有在SQL和R语言中存在的:
声明式编程。
在SQL中,我们可以在不考虑算法影响下声明要求数据库得到的效果。数据库可以根据数据类型,比如约束(constraints)、键(key)、索引(indexes)等不同来采取最佳的算法。
在理论上,我们最初在SQL和关系演算(relational calculus)后就有了基本的想法。在实践中,SQL的供应商们在过去的几十年中已经实现了基于开销的高效优化器CBOs (Cost-Based Optimisers) 。然后到了2010版,我们才终于将SQL的所有潜力全部挖掘出来。
但是我们还不需要用set方式来实现SQL。所有的语言和库都支持Sets、collections、bags、lists。使用set的主要好处是能使我们的代码变的简洁明了。比如下面的写法:
SomeSet INTERSECT SomeOtherSet
而不是
// Java 8以前的写法 Set result = new HashSet(); for (Object candidate : someSet) if (someOtherSet.contains(candidate)) result.add(candidate); // 即使采用Java 8也没有很大帮助 someSet.stream() .filter(someOtherSet::contains) .collect(Collectors.toSet());
有些人可能会对函数式编程和Java 8能帮助我们写出更加简单、简洁的算法持有不同的意见。但这种看法不一定是对的。我们可以把命令式的Java 7循环转换成Java 8的Stream collection,但是我们还是采用了相同的算法。但SQL风格的表达式则是不同的:
SomeSet INTERSECT SomeOtherSet
在这篇文章中,我们讨论了关于N.O.P.E.分支的优化。比如深入高复杂性的算法。作为jOOQ的开发者,我们很乐于对SQL的生成进行优化。
jOOQ处在“食物链的底端”,因为它是在离开JVM进入到DBMS时,被我们电脑程序所调用的最后一个API。位于食物链的底端意味着任何一条线路在jOOQ中被执行时都需要 N x O x P 的时间,所以我要尽早进行优化。
我们的业务逻辑可能没有N.O.P.E.分支那么复杂。但是基础框架有可能十分复杂(本地SQL框架、本地库等)。所以需要按照我们今天提到的原则,用Java Mission Control 或其它工具进行复查,确认是否有需要优化的地方。
原文链接: jaxenter 翻译: ImportNew.com - 一直在路上
译文链接: http://www.importnew.com/16181.html
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。