您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下Python编写EVE的具体思路,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨方法吧!
大多数熟悉EVE的人都知道,它是用Python语言编写的,如果要说得更具体点,那就是Stackless Python。Stackless是在Python基础上编写的一套微线程框架,它能在不产生大量Python自身额外开销的情况下同时容纳数百万条的线程。
但话还是要说回来,它毕竟还是Python,因此摆脱不了“解释器全局锁”(Global Interpreter Lock,下文将其简称为GIL)。
GIL是一个序列锁,用来保证在任何时候都只能有一个线程利用Python解释器(包括其所有数据)来运行自己。因此,尽管Stackless Python感觉上好像具备多线程处理能力,但实际上它还是单线程的,只不过运用了任务分离、频道、定时器及共享内存等一系列招数而已。
其实过去有些协作式的多任务操作系统也是这样干的,其好处是保证了所有线程都能被执行,不会出现被操作系统提前结束这一情况(除非被操作系统怀疑非法宕机)。GIL的存在使得程序员在编写游戏逻辑时能自信推断出程序的全局状态,省去了一大堆采用异步回调函数的麻烦。
但这样有一大缺点:由于EVE中有部分框架的代码是用Python编写的,因此它们都免不了GIL造成的负面影响。比如,一段用来读取Python数据的C++语言代码必须在获得GIL后才能读取一个字符串。
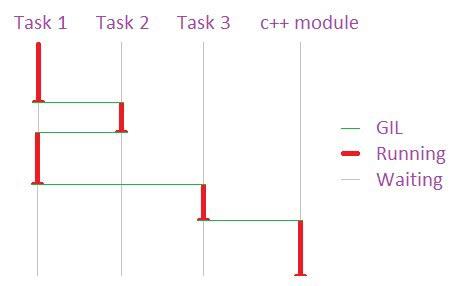
使用Python的任务都要获得GIL才能合法地被处理,这样等同于Python任务都是单线程执行。
(这图画得不太好看,人家只是个程序员,不是美术师哦)
一言以蔽之,Stackless Python 代码的运行速度不会高于你最快的那个CPU核心的速度。在一台4核或8核CPU的服务器上,其中只有一核在超负荷运作,其他都没派上用场。当然,为了让这些CPU核心物尽其用,我们可以在它们身上加载更多的节点。
对于EVE中许多无状态或对共享状态依赖度极低的代码而言,这没什么问题。但对于像太空模拟或空间站行走这样高度依赖共享状态的代码而言,就成了一个大问题。
假设一个CPU核心就能处理所有的逻辑并且写出来的Python代码较为清晰,那我之前说的都不是什么问题。不过,想必我不用说大家也知道,尽管Gridlock等小组已经在优化工作方面做到了其极致,但我们现在面临的情况依旧是单个CPU已经无法处理一场大型会战了。
最近上市的CPU速度是更快、缓存容量也更大、总线也更宽裕并且具备更好的执行流水线,但在EVE需要其给力的地方,却没有任何进步。近期(也可能包括中长期)的趋势是“横向增长”,即同时运行多个CPU核心。
总体而言,多核CPU的流行对EVE的长远发展是一大利好。未来那些30乃至60核CPU的机器能够很好地体现EVE集群部署方式的优势,这是因为CPU核心之间切换的效率将远远大于线程之间切换的效率。
但就目前而言,为了提升游戏运行速度,我们需要把网络及通用读写这样的EVE模块从GIL中解放出来。
多核心、超标量的硬件对当今的网络游戏来说,都是个好消息。这些游戏很适合这种架构,并且能很容易地进行并行处理。可惜对于依赖Python的EVE来说,这就算不得好消息了。
那些对运行速度要求极高、不需要Python便利开发优势的EVE系统需要尽早摆脱GIL的束缚。CarbonIO在这个方向上可以说是向前迈进了一大步。
CarbonIO 是在StacklessIO 基础上的一个自然提升。它实际上是个从头写起的全新引擎,目标非常明确:让网络流量摆脱GIL的束缚,并且让任何C++代码也能这样做。后半个目的是重头戏,我们花了大半年才把它完成。
这里不得不先稍微提一下StacklessIO。对Stackless Python的网络通信而言,它可以说是个质的飞跃。通过让网络操作变得具有“无堆栈的意识”,StacklessIO可以将一个被锁住的操作转移到一个未被GIL锁住的线程上,这样该操作就可以继续等候,而Stackless则继续处理其他事务。
然后,该操作重新获得GIL,告诉Stackless其操作已完成。这样,接收端就可以同步进行,使得通讯速度可以达到操作系统级别,并且能基本上在第一时间内回报给Python。
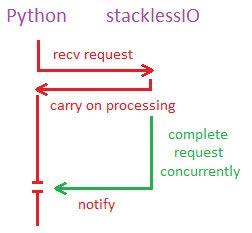
StacklessIO在没有GIL的情况下完成Python请求
CarbonIO在此基础上更上一层楼。由于它是在完全脱离于GIL的情况下运行多线程通信引擎,因此Python与该系统之间的交互便是完全独立了。没有Python的要求,它也能收发数据。
请允许我再强调一下:CarbonIO能在Python不作任何要求的情况下收发数据。这是并发性的,不需要GIL。
当一个连接通过CarbonIO被建立后,系统会调用WSARecv()开始接收数据。与Python进程并行的线程池将这些数据解密、解压缩然后转义到数据包里。这些数据包会排队,等着Python来处理。
当Python觉得它需要一个数据包时,它会往下调用“可能已将此包准备就绪”的CarbonIO。这意味着数据在离开队列被返回整个过程中根本没有用到GIL。这是一个瞬时过程,至少也有纳秒那么快。这个并行读取能力是CarbonIO的第一大好处。
第二大好处便是发送了。数据以其原始形式排在工作线程队列里,然后便等着Python来调用了。
其间的压缩、加密、打包及WSASend()调用都没有触及GIL而发生在另一个线程里,这样操作系统便可以安排它运行在另一颗CPU上了。C++代码也可以调用一个方法来这样做,并不需要特别的架构变更。StacklessIO也可以那样做,但在脱离上述背景的情况下,这会变得很没意义。
让我们再来回顾一下之前提到的“已将此包准备就绪”。但如果我们要安置一个C++回调钩子函数,使得非Python模块能在不触及Machonet的情况下获得那个数据,这可行吗?行啊,这时我们要用的就是BlueNet了。
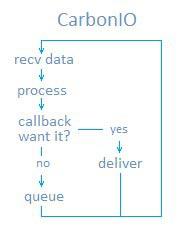
CarbonIO不停地进行数据接收,并且能在无Python介入的情况下告诉C++模块数据已收到。
Machonet是一个大型功能集合,它负责对会话进行分流、导向及管理,负责对数据包的时间计划/发送以及其他一系列将EVE撮合成一个有机整体的功能。
由于它是个Python模块,因此所有的数据迟早都必须触及那倒霉的GIL,无论数据在哪个节点。无论一个C++模块的速度有多快,GIL仍然是个绕不过的瓶颈。这使得我们曾经都不太愿意做大量的C++优化,因为任何优化后取得的优势都会被Machonet 中的GIL吞噬。
但现在情况不一样了。
现在C++的系统能通过BlueNet收发数据包,无需再理会GIL。这原来是专门为了空间站行走设计的。空间站行走功能需要发送大量的表示移动的数据。
EVE中太空飞行的那部分功能所需要收发的数据,我们以前可以用旁门左道的方法来解决,但对于如此近距离的人物动作,就不行了。之前我们做的预测显示,即使把空间站行走发送数据的频率控制在一般程度,该功能也会把整个服务器集群拖垮。
通过在没有GIL干扰的情况下对流入/流出C++原生系统(比如物理系统)的数据进行分流,BlueNet成功地解决了该问题。由于在这种情况下,数据还是保持着其原生态,因此整个系统运行的速度就比之前提高了。
这个具体是怎么运作的呢?BlueNet保存着一份所有必要Machonet结构的只读拷贝,另外,所有的数据包前都会附上很小的一段(8到10个字节的)数据头。这个数据头里含有路径信息。
当BlueNet接到一个数据包时,它会对其进行检测,然后合理地再分发:要么转发到另一个节点上,要么交给被本地的已注册的C++应用程序。如果它转发,那这个过程中将用不到GIL,根本不会调用Machonet/Python。
这意味着我们的代理服务器完全能以并行方式对BlueNet的数据包进行分流,而不必去经过Python导致额外开销的产生。那这效率究竟提高了多少呢?我们还无法确定,但在降低机器负载及延迟方面,它还是非常非常明显的。实际上我们还不能将数据公开,因为它们好得难以置信。
除此之外,CarbonIO也包含了大量底层优化,绝大多数都是小规模的速度提升,但把这些统统叠加起来,整个系统的运行速度也就有了显著提高。以下几点值得一提:
工作分组
虽然我很难在本文中把这事儿说得太细,但CarbonIO非常出色地将工作分组来处理。
简而言之,就是某些操作有了一个固定的开销。网络引擎有许多这样的开销,但其他所有具有重要意义的代码也有大量开销。通过一些别出心裁的技巧,我们是可以将许多这样的工作合并在一起,这样就只产生一次开销。
就像把逻辑数据包都组合在一起发送在一个TCP/IP MTU里一样(EVE一直就是这样干的),CarbonIO将这一做法进一步深化。一个比较简单的例子就是GIL获取集合。
第一个要尝试取得GIL的线程会先建立起一个队列,这样其他要获取GIL的线程只需将自己的唤醒调用排在队列末尾然后返回线程池就行。那GIL最后被取得时,第一个线程会吸干整个队列,不必在每次IO唤醒时释放/重拾GIL。
在一个繁忙的服务器上这种情况很多,因此这种改进对我们来说是一大利好。
openSSL 整合
CarbonIO用openSSL来实现SSL,并且能在不锁定GIL的情况下与该协议数据通信。该库只是用作一个BIO对而已,所有的数据导航还是由CarbonIO通过完成端口进行的。
这有助于我们循序渐进地让EVE变得更安全,甚至将来可以把官方网站上的某些帐号管理功能挪到EVE客户端上去,这样可以更方便大家。
压缩整合
CarbonIO能利用zlib或snappy对每一个数据包都进行压缩/解压缩,这一过程同样是无需GIL的。
实战检验
通过对一个繁忙的代理服务器(人数峰值大约1600人,一个平常工作日)的24小时数据的收集,我们发现CPU的总体使用率与单个用户的CPU使用率都出现了大幅下降。
这都归功于CarbonIO的总体架构,其作用就是降低事务的开销。当服务器变得繁忙之后,这些优化的效果会被逐渐增多且必须处理的事务所抵消,但在最高负载时,CarbonIO还是让我们的游戏增速了不少。
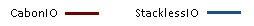
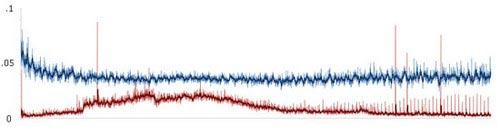
以上为24小时内单个用户的CPU使用率
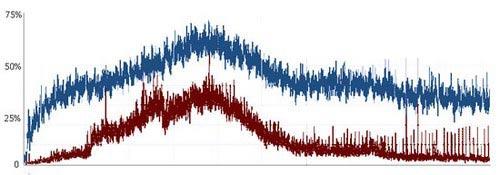
以上为同样的24小时内总体CPU使用率
至于SOL(星系)节点,由于它们的主要职责是游戏机制而非网络管理,因此它们从该优化中获得的优势并不那么明显,但我们还是看到它们的CPU使用率下降了8%-10%。
需要指出的是,在上述的检验中我们没有运用BlueNet,没有用CarbonIO的数据导航,也没有用脱离GIL的数据压缩/解压缩。
总的来说,比起以前,EVE能更好地利用现代服务器硬件带来的优势,能让它在同样的时间内完成更多的工作,这样就间接提升了一个系统所能进行的操作上限。
通过将我们的代码尽量与GIL脱离,我们反而为那些真正需要用它的代码腾出了空间。另外,由于不再有那么多代码需要竞相获取GIL,系统的总体运行效率也会提升。有了BlueNet再加上很好的代码优化,提速空间已被打开。虽然最后的结果仍有待实践检验,但至少,我们已经消除了一大瓶颈。
看完了这篇文章,相信你对Python编写EVE的具体思路有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。