жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚзҲ¬иҷ«жҠ“еҸ–зҪ‘йЎөж•°жҚ®зҡ„ж–№жі•пјҢж–ҮдёӯзӨәдҫӢд»Јз Ғд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
зҲ¬иҷ«жҠ“еҸ–зҪ‘йЎөж•°жҚ®зҡ„ж–№жі•пјҡ
е°ҶзҪ‘еқҖеҪ“еҸӮж•°дј йҖ’з»ҷrequestsеҢ…зҡ„getж–№жі•е°ұеҸҜд»ҘзҲ¬еҲ°з®ҖеҚ•зҪ‘йЎөдёҠйқўзҡ„жүҖжңүдҝЎжҒҜпјҢ然еҗҺз”ЁвҖңprintвҖқиҜӯеҸҘжү“еҚ°еҮәжқҘе°ұеҸҜд»ҘдәҶ
зӨәдҫӢеҰӮдёӢпјҡ
зҲ¬еҸ–зҷҫеәҰйҰ–йЎөзҡ„зҪ‘йЎөеҶ…е®№пјҡ
д»Јз ҒеҰӮдёӢпјҡ
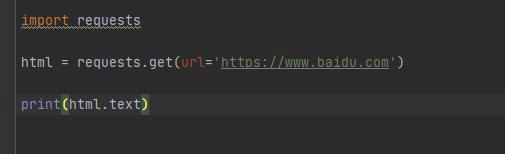
жү§иЎҢз»“жһңеҰӮдёӢпјҡ
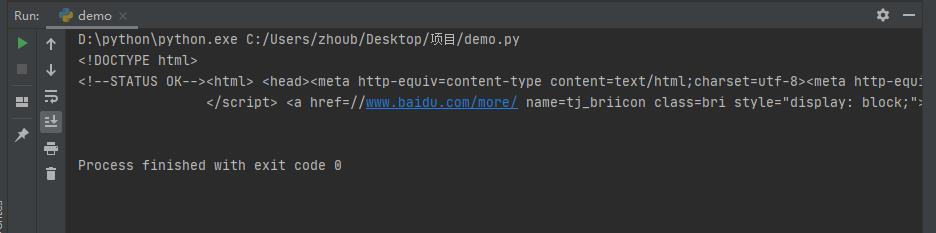
д»ҘдёҠжҳҜзҲ¬иҷ«жҠ“еҸ–зҪ‘йЎөж•°жҚ®зҡ„ж–№жі•зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ