жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢpythonзҲ¬иҷ«жҠ“еҸ–зҪ‘йЎөж•°жҚ®зҡ„ж–№жі•пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жүҖ收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»жҺўи®Ёеҗ§пјҒ
pythonз®ҖеҚ•зҪ‘з»ңзҲ¬иҷ«иҺ·еҸ–зҪ‘йЎөж•°жҚ®
дёӢйқўд»ҘиҺ·еҸ–жҷәиҒ”жӢӣиҒҳдёҠдёҖзәҝеҸҠж–°дёҖзәҝеҹҺеёӮжүҖжңүдёҺBIMзӣёе…ізҡ„е·ҘдҪңдҝЎжҒҜд»ҘдҫҝеҒҡдёҖдәӣж•°жҚ®еҲҶжһҗдёәеҲ—
1гҖҒйҰ–е…ҲйҖҡиҝҮchromeеңЁжҷәиҒ”жӢӣиҒҳдёҠжҗңзҙўBIMзҡ„иҒҢдҪҚдҝЎжҒҜпјҢи·іеҮәйЎөйқўеҗҺctrl+uжҹҘзңӢзҪ‘йЎөжәҗд»Јз ҒпјҢеҰӮжІЎжңүжүҫеҲ°еҪ“еүҚйЎөйқўзҡ„иҒҢдҪҚдҝЎжҒҜгҖӮ然еҗҺеҝ«жҚ·й”®F12жү“ејҖејҖеҸ‘иҖ…е·Ҙе…·зӘ—еҸЈпјҢеҲ·ж–°йЎөйқўпјҢйҖҡиҝҮе…ій”®еӯ—иҝҮж»Өж–Ү件пјҢжүҫеҲ°дёҖдёӘеҢ…еҗ«иҒҢдҪҚзҡ„ж•°жҚ®еҢ…гҖӮ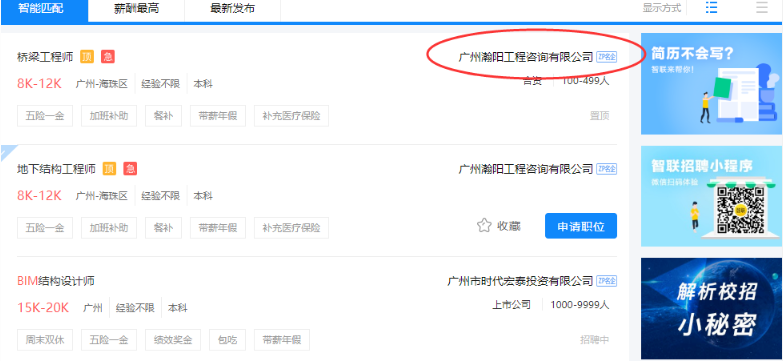
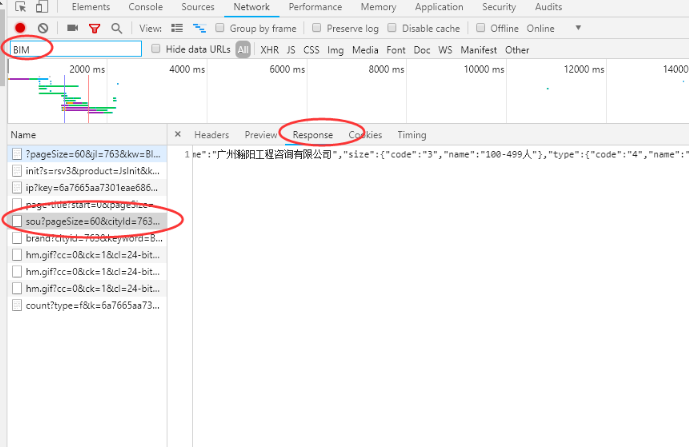
2гҖҒжҹҘзңӢиҝҷдёӘж–Ү件зҡ„иҜ·жұӮURLпјҢеҲҶжһҗе…¶жһ„йҖ еҸ‘зҺ°ж•°жҚ®еҢ…зҡ„иҜ·жұӮURLз”ұ
вҖҳhttps://fe-api.zhaopin.com/c/i/sou?вҖҷ+иҜ·жұӮеҸӮж•°з»„жҲҗпјҢйӮЈд№Ҳж №жҚ®ж јејҸжһ„йҖ дәҶдёҖдёӘж–°зҡ„urlпјҲ вҖҳhttps://fe-api.zhaopin.com/c/i/sou?pageSize=60&cityId=763&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=йҖ д»·е‘ҳ&kt=3вҖҷпјү
еӨҚеҲ¶еҲ°жөҸи§ҲеҷЁиҝӣиЎҢи®ҝй—®жөӢиҜ•пјҢжҲҗеҠҹиҺ·еҫ—зӣёеә”ж•°жҚ®

3гҖҒеҸ–еҫ—зҡ„дёәjsonж јејҸж•°жҚ®пјҢе…Ҳе°Ҷж•°жҚ®ж јејҸеҢ–пјҢеҲҶжһҗжһ„йҖ пјҢзЎ®е®ҡд»Јз Ғдёӯж•°жҚ®зҡ„и§Јжһҗж–№жі•гҖӮ
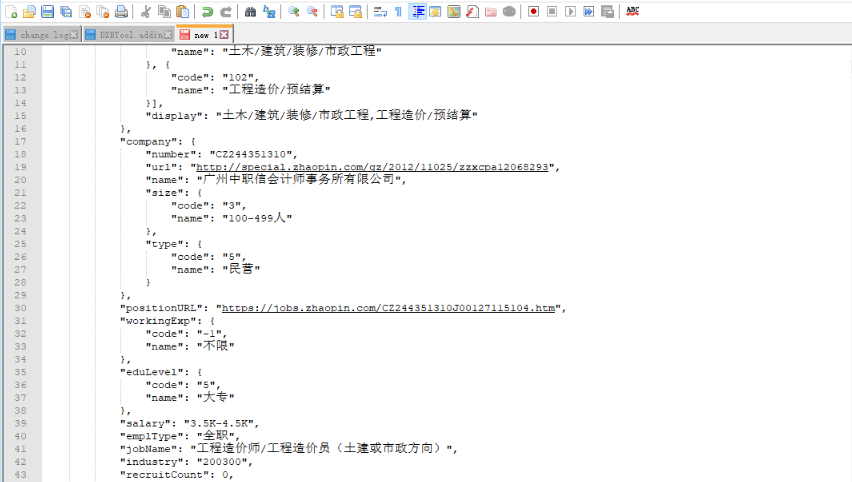
4гҖҒ иҜ·жұӮURLеҸҠж•°жҚ®з»“жһ„йғҪжё…жҘҡеҗҺпјҢеү©дёӢзҡ„е°ұжҳҜеңЁд»Јз Ғдёӯе®һзҺ°URLзҡ„жһ„йҖ гҖҒж•°жҚ®и§ЈжһҗеҸҠеҜјеҮәгҖӮжңҖеҗҺиҺ·еҫ—1215дёӘж•°жҚ®пјҢиҝҳйңҖиҝӣдёҖжӯҘеҜ№ж•°жҚ®иҝӣиЎҢж•ҙзҗҶпјҢд»ҘдҫҝиҝӣиЎҢж•°жҚ®еҲҶжһҗгҖӮ

зңӢе®ҢдәҶиҝҷзҜҮж–Үз« пјҢзӣёдҝЎдҪ еҜ№pythonзҲ¬иҷ«жҠ“еҸ–зҪ‘йЎөж•°жҚ®зҡ„ж–№жі•жңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ