жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢеёёз”ЁзҪ‘з»ңзҲ¬иҷ«жЁЎеқ—жҳҜд»Җд№ҲпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жүҖ收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»жҺўи®Ёеҗ§пјҒ
urllibжЁЎеқ—
urllibеә“жҳҜpythonдёӯиҮӘеёҰзҡ„жЁЎеқ—пјҢд№ҹжҳҜдёҖдёӘжңҖеҹәжң¬зҡ„зҪ‘з»ңиҜ·жұӮеә“пјҢиҜҘжЁЎеқ—жҸҗдҫӣдәҶдёҖдёӘurlopen()ж–№жі•пјҢйҖҡиҝҮиҜҘж–№жі•жҢҮе®ҡURLеҸ‘йҖҒзҪ‘з»ңиҜ·жұӮжқҘиҺ·еҸ–ж•°жҚ®гҖӮ
urllib жҳҜдёҖдёӘ收йӣҶдәҶеӨҡдёӘж¶үеҸҠ URL зҡ„жЁЎеқ—зҡ„еҢ…
urllib.request жү“ејҖе’ҢиҜ»еҸ– URL
дёүиЎҢд»Јз ҒеҚіеҸҜзҲ¬еҸ–зҷҫеәҰйҰ–йЎөжәҗд»Јз Ғпјҡ
import urllib.request
# жү“ејҖжҢҮе®ҡйңҖиҰҒзҲ¬еҸ–зҡ„зҪ‘йЎө
response=urllib.request.urlopen('http://www.baidu.com')
# жҲ–иҖ…жҳҜ
# from urllib import request
# response = request.urlopen('http://www.baidu.com')
# жү“еҚ°зҪ‘йЎөжәҗд»Јз Ғ
print(response.read().decode())еҠ е…Ҙdecode()жҳҜдёәдәҶйҒҝе…ҚеҮәзҺ°дёӢеӣҫдёӯеҚҒе…ӯиҝӣеҲ¶еҶ…е®№

еҠ е…Ҙdecode()иҝӣиЎҢи§Јз ҒеҗҺ

дёӢйқўдёүз§Қжң¬зҜҮе°ҶдёҚеҒҡиҜҰиҝ°
urllib.error еҢ…еҗ« urllib.request жҠӣеҮәзҡ„ејӮеёё
urllib.parse з”ЁдәҺи§Јжһҗ URL
urllib.robotparser з”ЁдәҺи§Јжһҗ robots.txt ж–Ү件
requestsжЁЎеқ—
requestsжЁЎеқ—жҳҜpythonдёӯе®һзҺ°HTTPиҜ·жұӮзҡ„дёҖз§Қж–№ејҸпјҢжҳҜ第дёүж–№жЁЎеқ—пјҢиҜҘжЁЎеқ—еңЁе®һзҺ°HTTPиҜ·жұӮж—¶иҰҒжҜ”urllibжЁЎеқ—з®ҖеҢ–еҫҲеӨҡпјҢж“ҚдҪңжӣҙеҠ дәәжҖ§еҢ–гҖӮ
д»ҘGETиҜ·жұӮдёәдҫӢпјҡ
import requests
response = requests.get('http://www.baidu.com/')
print('зҠ¶жҖҒз Ғпјҡ', response.status_code)
print('иҜ·жұӮең°еқҖпјҡ', response.url)
print('еӨҙйғЁдҝЎжҒҜпјҡ', response.headers)
print('cookieдҝЎжҒҜпјҡ', response.cookies)
# print('ж–Үжң¬жәҗз Ғпјҡ', response.text)
# print('еӯ—иҠӮжөҒжәҗз Ғпјҡ', response.content)иҫ“еҮәз»“жһңеҰӮдёӢпјҡ
зҠ¶жҖҒз Ғпјҡ 200
иҜ·жұӮең°еқҖпјҡ http://www.baidu.com/
еӨҙйғЁдҝЎжҒҜпјҡ {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'keep-alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Sun, 10 May 2020 02:43:33 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:23 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
cookieдҝЎжҒҜпјҡ <RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>иҝҷйҮҢи®Іи§ЈдёҖдёӢresponse.textе’Ң response.contentзҡ„еҢәеҲ«:
response.contentжҳҜзӣҙжҺҘд»ҺзҪ‘з»ңдёҠйқўжҠ“еҸ–зҡ„ж•°жҚ®,жІЎжңүз»ҸиҝҮд»»дҪ•и§Јз Ғ,жүҖд»ҘжҳҜдёҖдёӘ bytesзұ»еһӢ
response.textжҳҜе°Ҷresponse.contentиҝӣиЎҢи§Јз Ғзҡ„еӯ—з¬ҰдёІ,и§Јз ҒйңҖиҰҒжҢҮе®ҡдёҖдёӘзј–з Ғж–№ејҸ, requestsдјҡж №жҚ®иҮӘе·ұзҡ„зҢңжөӢжқҘеҲӨж–ӯзј–з Ғзҡ„ж–№ејҸ,жүҖд»Ҙжңүж—¶еҖҷеҸҜиғҪдјҡзҢңжөӢй”ҷиҜҜ,е°ұдјҡеҜјиҮҙи§Јз Ғдә§з”ҹд№ұз Ғ,иҝҷж—¶еҖҷе°ұеә”иҜҘдҪҝз”Ё response.content.decode(вҖҳutf-8вҖҷ)
иҝӣиЎҢжүӢеҠЁи§Јз Ғ
д»ҘPOSTиҜ·жұӮдёәдҫӢ
import requests
data={'word':'hello'}
response = requests.post('http://www.baidu.com',data=data)
print(response.content)иҜ·жұӮheadersеӨ„зҗҶ
еҪ“зҲ¬еҸ–йЎөйқўз”ұдәҺиҜҘзҪ‘йЎөдёәйҳІжӯўжҒ¶ж„ҸйҮҮйӣҶдҝЎжҒҜиҖҢдҪҝз”ЁеҸҚзҲ¬иҷ«и®ҫзҪ®пјҢд»ҺиҖҢжӢ’з»қз”ЁжҲ·и®ҝй—®пјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮжЁЎжӢҹжөҸи§ҲеҷЁзҡ„еӨҙйғЁдҝЎжҒҜжқҘиҝӣиЎҢи®ҝй—®пјҢиҝҷж ·е°ұиғҪи§ЈеҶіеҸҚзҲ¬иҷ«и®ҫзҪ®зҡ„й—®йўҳгҖӮ
йҖҡиҝҮжөҸи§ҲеҷЁиҝӣе…ҘжҢҮе®ҡзҪ‘йЎөпјҢеҸіеҮ»йј ж ҮпјҢйҖүдёӯвҖңжЈҖжҹҘвҖқпјҢйҖүжӢ©вҖңNetworkвҖқпјҢеҲ·ж–°йЎөйқўеҗҺйҖүжӢ©з¬¬дёҖжқЎдҝЎжҒҜпјҢеҸідҫ§ж¶ҲжҒҜеӨҙйқўжқҝе°ҶжҳҫзӨәдёӢеӣҫдёӯиҜ·жұӮеӨҙйғЁдҝЎжҒҜ
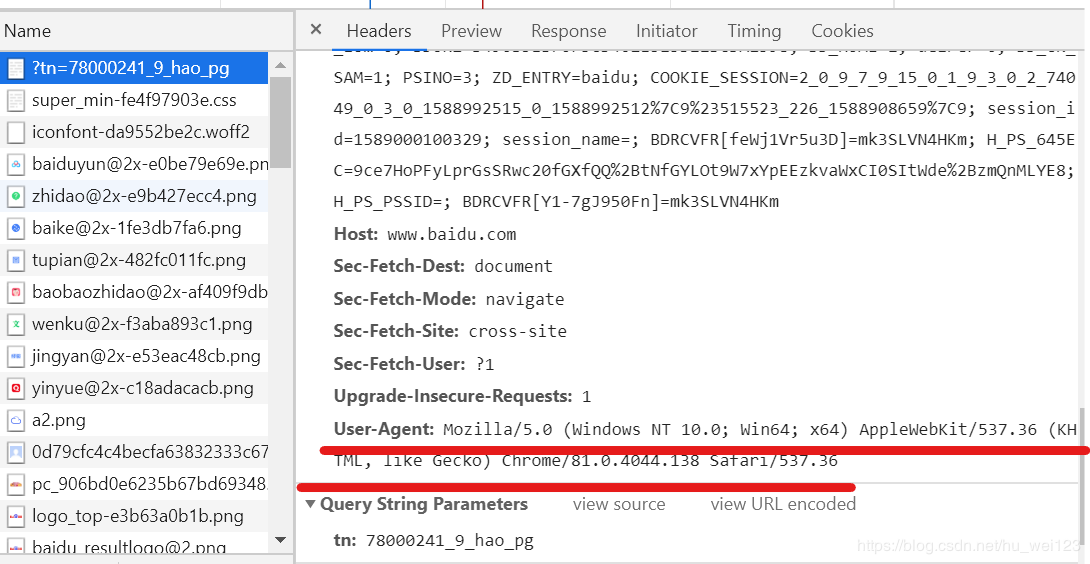
дҫӢеҰӮпјҡ
import requests
url = 'https://www.bilibili.com/'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36'}
response = requests.get(url, headers=headers)
print(response.content.decode())зҪ‘з»ңи¶…ж—¶
еңЁи®ҝй—®дёҖдёӘйЎөйқўпјҢеҰӮжһңиҜҘйЎөйқўй•ҝж—¶й—ҙжңӘе“Қеә”пјҢзі»з»ҹе°ұдјҡеҲӨж–ӯиҜҘзҪ‘йЎөи¶…ж—¶пјҢжүҖд»Ҙж— жі•жү“ејҖзҪ‘йЎөгҖӮ
дҫӢеҰӮпјҡ
import requests
url = 'http://www.baidu.com'
# еҫӘзҺҜеҸ‘йҖҒиҜ·жұӮ50ж¬Ў
for a in range(0, 50):
try:
# timeoutж•°еҖјеҸҜж №жҚ®з”ЁжҲ·еҪ“еүҚзҪ‘йҖҹпјҢиҮӘиЎҢи®ҫзҪ®
response = requests.get(url, timeout=0.03) # и®ҫзҪ®и¶…ж—¶дёә0.03
print(response.status_code)
except Exception as e:
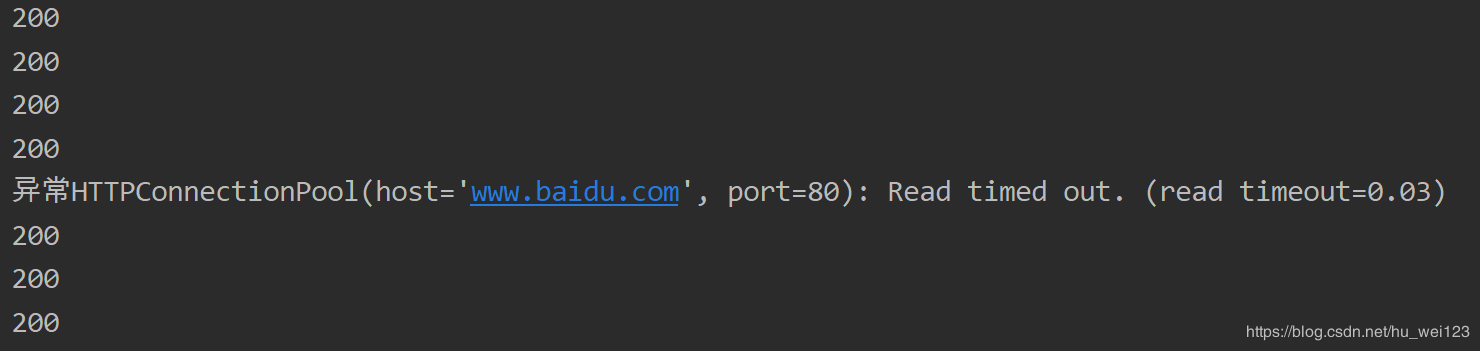
print('ејӮеёё'+str(e)) # жү“еҚ°ејӮеёёдҝЎжҒҜйғЁеҲҶиҫ“еҮәз»“жһңеҰӮдёӢпјҡ
д»ЈзҗҶжңҚеҠЎ
и®ҫзҪ®д»ЈзҗҶIPеҸҜд»Ҙи§ЈеҶідёҚд№…еүҚеҸҜд»ҘзҲ¬еҸ–зҡ„зҪ‘йЎөзҺ°еңЁж— жі•зҲ¬еҸ–дәҶпјҢ然еҗҺжҠҘй”ҷвҖ”вҖ”з”ұдәҺиҝһжҺҘж–№еңЁдёҖж®өж—¶й—ҙеҗҺжІЎжңүжӯЈзЎ®зӯ”еӨҚжҲ–иҝһжҺҘзҡ„дё»жңәжІЎжңүеҸҚеә”пјҢиҝһжҺҘе°қиҜ•еӨұиҙҘзҡ„й—®йўҳгҖӮ
д»ҘдёӢзҪ‘з«ҷеҸҜд»ҘжҸҗдҫӣе…Қиҙ№д»ЈзҗҶIP https://www.xicidaili.com/
дҫӢеҰӮпјҡ
import requests
# и®ҫзҪ®д»ЈзҗҶIP
proxy = {'http': '117.45.139.139:9006',
'https': '121.36.210.88:8080'
}
# еҸ‘йҖҒиҜ·жұӮ
url = 'https://www.baidu.com'
response = requests.get(url, proxies=proxy)
# д№ҹе°ұжҳҜиҜҙеҰӮжһңжғіеҸ–ж–Үжң¬ж•°жҚ®еҸҜд»ҘйҖҡиҝҮresponse.text
# еҰӮжһңжғіеҸ–еӣҫзүҮпјҢж–Ү件пјҢеҲҷеҸҜд»ҘйҖҡиҝҮ response.content
# д»Ҙеӯ—иҠӮжөҒзҡ„еҪўејҸжү“еҚ°зҪ‘йЎөжәҗд»Јз Ғ,bytesзұ»еһӢ
print(response.content.decode())
# д»Ҙж–Үжң¬зҡ„еҪўејҸжү“еҚ°зҪ‘йЎөжәҗд»Јз ҒпјҢдёәstrзұ»еһӢ
print(response.text) # й»ҳи®ӨвҖқiso-8859-1вҖқзј–з ҒпјҢжңҚеҠЎеҷЁдёҚжҢҮе®ҡзҡ„иҜқжҳҜж №жҚ®зҪ‘йЎөзҡ„е“Қеә”жқҘзҢңжөӢзј–з ҒгҖӮBeautiful SoupжЁЎеқ—
Beautiful SoupжЁЎеқ—жҳҜдёҖдёӘз”ЁдәҺHTMLе’ҢXMLж–Ү件дёӯжҸҗеҸ–ж•°жҚ®зҡ„pythonеә“гҖӮBeautiful SoupжЁЎеқ—иҮӘеҠЁе°Ҷиҫ“е…Ҙзҡ„ж–ҮжЎЈиҪ¬жҚўдёәUnicodeзј–з ҒпјҢиҫ“еҮәж–ҮжЎЈиҪ¬жҚўдёәUTF-8зј–з ҒпјҢдҪ дёҚйңҖиҰҒиҖғиҷ‘зј–з Ғж–№ејҸпјҢйҷӨйқһж–ҮжЎЈжІЎжңүжҢҮе®ҡдёҖдёӘзј–з Ғж–№ејҸпјҢиҝҷж—¶пјҢBeautiful Soupе°ұдёҚиғҪиҮӘеҠЁиҜҶеҲ«зј–з Ғж–№ејҸдәҶпјҢ然еҗҺпјҢд»…д»…йңҖиҰҒиҜҙжҳҺдёҖдёӢеҺҹе§Ӣзј–з Ғж–№ејҸе°ұеҸҜд»ҘдәҶгҖӮ
дҫӢеҰӮпјҡ
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# еҲӣе»әеҜ№иұЎ
soup = BeautifulSoup(html_doc, features='lxml')
# жҲ–иҖ…еҲӣе»әеҜ№иұЎжү“ејҖйңҖиҰҒи§Јжһҗзҡ„htmlж–Ү件
# soup = BeautifulSoup(open('index.html'), features='lxml')
print('жәҗд»Јз Ғдёәпјҡ', soup)# жү“еҚ°и§Јжһҗзҡ„HTMLд»Јз ҒиҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
<html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> </body></html>
з”ЁBeautiful SoupзҲ¬еҸ–зҷҫеәҰйҰ–йЎөж Үйўҳ
from bs4 import BeautifulSoup
import requests
response = requests.get('http://news.baidu.com')
soup = BeautifulSoup(response.text, features='lxml')
print(soup.find('title').text)иҝҗиЎҢз»“жһңеҰӮдёӢпјҡ
зҷҫеәҰж–°й—»вҖ”вҖ”жө·йҮҸдёӯж–Үиө„и®Ҝе№іеҸ°
зңӢе®ҢдәҶиҝҷзҜҮж–Үз« пјҢзӣёдҝЎдҪ еҜ№еёёз”ЁзҪ‘з»ңзҲ¬иҷ«жЁЎеқ—жҳҜд»Җд№ҲжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ