您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
网络爬虫的原理是什么?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
互联网上,公开数据(各种网页)都是以http(或加密的http即https)协议传输的。所以,我们这里介绍的爬虫技术都是基于http(https)协议的爬虫。
在Python的模块海洋里,支持http协议的模块是相当丰富的,既有官方的urllib,也有大名鼎鼎的社区(第三方)模块 requests。它们都很好的封装了http协议请求的各种方法,因此,我们只需要熟悉这些模块的用法,不再进一步讨论http协议本身。
认识浏览器和服务器
大家对浏览器应该一点都不陌生,可以说,只要上过网的人都知道浏览器。可是,明白浏览器各种原理可不一定多哦。
作为要开发爬虫,是一定一定要明白浏览器的工作原理的。这是你写爬虫的必备工具,别无他。
不知道大家在面试的时候,有没有遇到这么一个非常宏观而又处处细节的解答题:
请说说从你在浏览器地址栏输入网站到你看到网页中间都发生了什么?
这真是一个考验知识面的题啊,经验老道的既可以滔滔不绝的讲上三天三夜,也可以提炼出几分钟的精华讲个大概。而大家恐怕对整个过程就一知半解了。
巧的是,对这个问题理解的越透彻,越对写爬虫有帮助。换句话说,爬虫是一个考验综合技能的领域。那么,准备好迎接这个综合技能挑战了吗?
废话不多说,我们就从解答这个题目开始,认识浏览器和服务器,看看这中间有哪些知识是爬虫要用到的。
前面也说过,这个问题可以讲上三天三夜,但我们没那么多时间,其中一些细节就略过,把大致流程结合爬虫讲一讲,分成三部分:
浏览器发出请求
服务器做出响应
浏览器接收响应
1. 浏览器发出请求
在浏览器地址栏输入网址后回车,浏览器请服务器提出网页请求,也就是告诉服务器,我要看你的某个网页。
上面短短一句话,蕴藏了无数玄机啊,让我不得不费点口舌一一道来。主要讲述:
网址是不是有效的?
服务器在哪里?
浏览器向服务器发送了些什么?
服务器返回了些什么?
1) 网址是不是有效的?
首先,浏览器要判断你输入的网址(URL)是否合法有效。对应URL,小猿们并不陌生吧,以http(s)开头的那一长串的字符,但是你知道它还可以以ftp, mailto, file, data, irc开头吗?下面是它最完整的语法格式:
URI = scheme:[//authority]path[?query][#fragment] # 其中, authority 又是这样的: authority = [userinfo@]host[:port] # userinfo可以同时包含user name和password,以:分割 userinfo = [user_name:password]
用图更形象的表现处理就是这样的:

要判断URL的合法性
Python里面可以用urllib.parse来进行URL的各种操作
In [1]: import urllib.parse In [2]: url = 'http://dachong:the_password@www.yuanrenxue.com/user/info?page=2' In [3]: zz = urllib.parse.urlparse(url) Out[4]: ParseResult(scheme='http', netloc='dachong:the_password@www.yuanrenxue.com', path='/user/info', params='', query='page=2', fragment='')
我们看到,urlparse函数把URL分析成了6部分:
scheme://netloc/path;params?query#fragment
需要主要的是 netloc 并不等同于 URL 语法定义中的host
2) 服务器在哪里?
上面URL定义中的host,就是互联网上的一台服务器,它可以是一个IP地址,但通常是我们所说的域名。域名通过DNS绑定到一个(或多个)IP地址上。浏览器要访问某个域名的网站就要先通过DNS服务器解析域名,得到真实的IP地址。
这里的域名解析一般是由操作系统完成的,爬虫不需要关心。然而,当你写一个大型爬虫,像Google、百度搜索引擎那样的爬虫的时候,效率变得很主要,爬虫就要维护自己的DNS缓存。
大型爬虫要维护自己的DNS缓存
3) 浏览器向服务器发送些什么?
浏览器获得了网站服务器的IP地址,就可以向服务器发送请求了。这个请求就是遵循http协议的。写爬虫需要关心的就是http协议的headers。
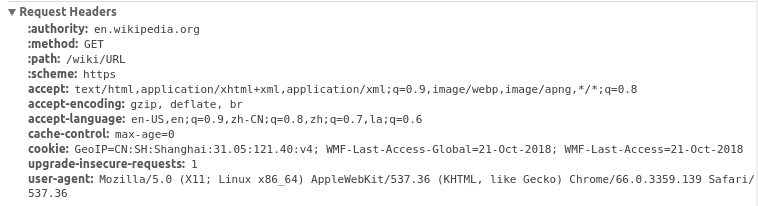
可能已经从图中看出来些端倪,发送的http请求头是类似一个字典的结构:
authority: 就是访问的目标机器;
method: http请求的方法有很多:
GET
HEAD
POST
PUT
DELETE
CONNECT
OPTIONS
TRACE
PATCH
一般,爬虫使用最多的是GET和POST
path: 访问的网站的路径
scheme: 请求的协议类型,这里是https
accept: 能够接受的回应内容类型(Content-Types)
accept-encoding: 能够接受的编码方式列表
accept-language: 能够接受的回应内容的自然语言列表
cache-control: 指定在这次的请求/响应链中的所有缓存机制 都必须 遵守的指令
cookie: 之前由服务器通过 Set- Cookie发送的一个 超文本传输协议Cookie
这是爬虫很关心的一个东东,登录信息都在这里。
upgrade-insecuree-requests: 非标准请求字段,可忽略之。
user-agent: 浏览器身份标识
这也是爬虫很关心的部分。比如,你需要得到手机版页面,就要设置浏览器身份标识为手机浏览器的user-agent。
通过设置headers跟服务器沟通
4) 服务器返回了些什么?
如果我们在浏览器地址栏输入一个网页网址(不是文件下载地址),回车后,很快就看到了一个网页,里面包含排版文字、图片、视频等数据,是一个丰富内容格式的页面。然而,我通过浏览器查看源代码,看到的却是一对文本格式的html代码。
没错,就是一堆的代码,却让浏览器给渲染成了漂亮的网页。这对代码里面有:
css: 浏览器根据它来排版,安排文字、图片等的位置;
JavaScript: 浏览器运行它可以让用户和网页交互;
图片等链接: 浏览器再去下载这些链接,最终渲染成网页。
而我们想要爬取的信息就藏在html代码中,我们可以通过解析方法提取其中我们想要的内容。如果html代码里面没有我们想要的数据,但是在网页里面却看到了,那就是浏览器通过ajax请求异步加载(偷偷下载)了那部分数据。
这个时候,我们就要通过观察浏览器的加载过程来发现具体是哪个ajax请求加载了我们需要的数据。
关于网络爬虫的原理是什么问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。