жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶpythonз”ЁжӯЈеҲҷиЎЁиҫҫејҸзӯӣйҖүзҪ‘йЎөеҶ…е®№зҡ„ж–№жі•пјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢйңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢгҖӮеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·гҖӮдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
дёҖгҖҒжӯЈеҲҷиЎЁиҫҫејҸз®Җиҝ°пјҡ
д»Җд№ҲжҳҜжӯЈеҲҷиЎЁиҫҫејҸпјҹжӯЈеҲҷиЎЁиҫҫејҸе°ұжҳҜеҸҜд»ҘеҢ№й…Қж–Үжң¬зүҮж®өзҡ„жЁЎејҸпјҢжңҖз®ҖеҚ•зҡ„жӯЈеҲҷиЎЁиҫҫејҸе°ұжҳҜдёҖдёӘеӯ—з¬ҰдёІпјҢз”ЁдәҺеңЁж–Үжң¬дёӯеҢ№й…ҚеҲ°жӯӨеӯ—з¬ҰдёІиҮӘиә«гҖӮ
дәҢгҖҒеёёз”ЁжӯЈеҲҷиЎЁиҫҫејҸпјҡ
и®ҫи®ЎжӯЈеҲҷиЎЁиҫҫејҸзҡ„ж—¶еҖҷжңүеҮ дёӘжіЁж„ҸзӮ№еҰӮдёӢпјҡ
a.зү№ж®Ҡз¬ҰеҸ·йңҖиҰҒеҠ иҪ¬з§»з¬ҰпјҡеҰӮиҰҒеҢ№й…Қ'china.com'пјҢеҲҷжӯЈеҲҷиЎЁиҫҫејҸж јејҸеә”дёә'china\\.com'пјӣ
b.еӯ—з¬ҰйӣҶпјҲдҪҝз”ЁдёӯжӢ¬еҸ·[]жқҘеҢ…еҗ«еӯ—з¬ҰдёІз»„жҲҗеӯ—з¬ҰйӣҶпјүпјҡеҰӮ[a-z]иЎЁзӨәеҢ№й…Қд»ҺaеҲ°zд№Ӣй—ҙзҡ„еӯ—з¬ҰпјӣжӯӨеӨ–пјҢиҝҳжңүдёҖдёӘеҸҚиҪ¬еӯ—з¬ҰйӣҶпјҢдҪҝз”Ё^з¬ҰеҸ·ејҖеӨҙпјҡеҰӮ[^abc]иЎЁзӨәеҢ№й…ҚйҷӨдәҶaгҖҒbгҖҒcдёүдёӘеӯ—з¬Ұд№ӢеӨ–зҡ„еӯ—з¬Ұпјӣ
c.йҖүжӢ©з¬ҰпјҡеҰӮиҰҒеҢ№й…Қ'python'е’Ң'page'пјҢеҶҷеҮәжқҘзҡ„жЁЎејҸдёә'python|page'пјҢе…¶дёӯвҖҳ|вҖҷжҳҜз®ЎйҒ“з¬ҰеҸ·пјӣ
d.еӯҗжЁЎејҸпјҡеҰӮвҖҳp(ython|age)вҖҷпјӣ
e.еҸҜйҖүйЎ№пјҡеңЁжЁЎејҸеҗҺйқўеҠ дёҠй—®еҘҪ(?)пјҢйӮЈиҜҘжЁЎејҸе°ұеҸҳжҲҗдәҶеҸҜйҖүйЎ№пјҢеҚіе…¶еҸҜиғҪеҮәзҺ°еңЁеҢ№й…ҚеҲ°зҡ„еӯ—з¬ҰдёІдёӯпјҢдҪҶжҳҜ并йқһеҝ…йЎ»зҡ„пјҢеҰӮr'(http://)?(www.)?shuhe.com'еҸҜеҢ№й…Қзҡ„з»“жһңжңүпјҡ
http://www.shuhe.comгҖҒhttp://shuhe.comгҖҒwww.shuhe.comгҖҒshuhe.com
f.йҮҚеӨҚеӯҗжЁЎејҸпјҡ
(pattern)*пјҡе…Ғи®ёжЁЎејҸйҮҚеӨҚ0ж¬ЎжҲ–еӨҡж¬Ў
(pattern)+пјҡе…Ғи®ёжЁЎејҸйҮҚеӨҚ1ж¬ЎжҲ–еӨҡж¬Ў
(pattern){m,n}пјҡе…Ғи®ёжЁЎејҸйҮҚеӨҚm~nж¬Ў
дҫӢеҰӮпјҡ
r'w*\.python\.org'еҢ№й…Қ'www.python.org'гҖҒ'.python.org'гҖҒ'wwwwww.python.org'
r'w+\.python\.org'еҢ№й…Қ'w.python.org'пјӣдҪҶдёҚеҢ№й…Қ'.python.org'
r'w{3,4}\.python\.org'еҸӘиғҪеҢ№й…Қ'www.python.org'е’Ң'wwww.python.org'дёүгҖҒreжЁЎжқҝзҡ„дҪҝз”Ёпјҡ
еңЁpythonдёӯе°ҒиЈ…дәҶдёҖдәӣеёёз”Ёзҡ„жӯЈеҲҷиЎЁиҫҫејҸеңЁreжЁЎжқҝдёӯпјҢдҪҝз”Ёж—¶еҸӘйңҖе°ҶиҜҘжЁЎжқҝеј•е…ҘеҲ°еҪ“еүҚйЎ№зӣ®дёӯеҚіеҸҜпјҡ
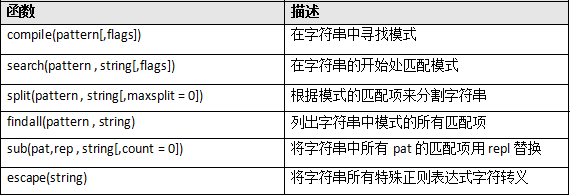
дёҠиҝ°жҳҜreдёӯеёёз”Ёзҡ„жӯЈеҲҷиЎЁиҫҫејҸпјҢдҪҝз”ЁжӯҘйӘӨдёәпјҡ
1.е…Ҳе°ҶжӯЈеҲҷиЎЁиҫҫејҸзҡ„еӯ—з¬ҰдёІеҪўејҸзј–иҜ‘дёәPatternе®һдҫӢпјӣ
2.然еҗҺдҪҝз”ЁPatternе®һдҫӢеӨ„зҗҶж–Үжң¬е№¶иҺ·еҫ—еҢ№й…Қз»“жһңпјҲдёҖдёӘMatchе®һдҫӢпјүпјӣ
3.жңҖеҗҺдҪҝз”ЁMatchе®һдҫӢиҺ·еҫ—дҝЎжҒҜпјҢиҝӣиЎҢе…¶д»–зҡ„ж“ҚдҪңгҖӮ
дҫӢеҰӮпјҡ
# encoding: UTF-8
import re
# е°ҶжӯЈеҲҷиЎЁиҫҫејҸзј–иҜ‘жҲҗPatternеҜ№иұЎ
pattern = re.compile(r'hello')
# дҪҝз”ЁPatternеҢ№й…Қж–Үжң¬пјҢиҺ·еҫ—еҢ№й…Қз»“жһңпјҢж— жі•еҢ№й…Қж—¶е°Ҷиҝ”еӣһNone
match = pattern.match('hello world!')
if match:
# дҪҝз”ЁMatchиҺ·еҫ—еҲҶз»„дҝЎжҒҜ
print match.group()
### иҫ“еҮә ###
# helloж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«pythonз”ЁжӯЈеҲҷиЎЁиҫҫејҸзӯӣйҖүзҪ‘йЎөеҶ…е®№зҡ„ж–№жі•еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢйҒҮеҲ°й—®йўҳе°ұжүҫдәҝйҖҹдә‘пјҢиҜҰз»Ҷзҡ„и§ЈеҶіж–№жі•зӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ