您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关怎么用Python实现数据筛选与匹配的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
数据筛选要求我们在表中筛选出符合条件的数据。
数据匹配需要我们在多个表之间匹配相关的数据。
与之前一样,完成项目问题的代码,需要我们先分析数据筛选和数据匹配的需求,再找到对应知识点,确定代码的执行顺序,从而实现项目代码。
这个案例需要我们筛选出迟到人员的信息,来具体看看。
在【10月考勤统计.xlsx】工作簿中,保存了公司一百名员工的迟到信息,这些信息包含了迟到时间和迟到次数。
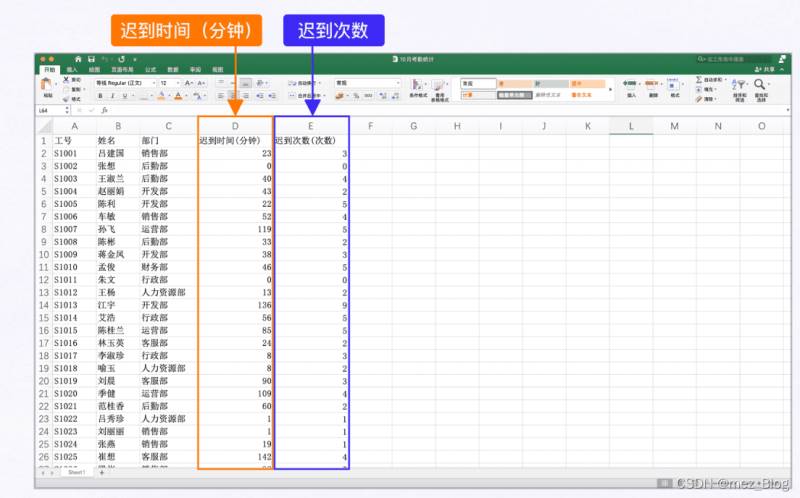
公司规定,迟到时间超过45分钟且迟到过3次以上的员工记为考勤不合格,需要扣除300的考勤保证金。

之前的同事需要把筛选后的结果保存为【10月迟到人员信息.xlsx】,并将整理后的信息上报给领导。
那么如何用代码实现这个场景呢?
在编写代码之前,我们要先明确任务需求。
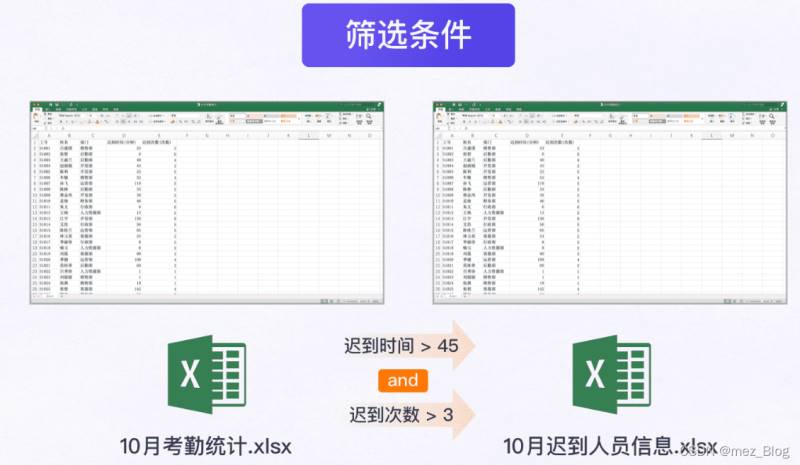
根据公司的规定,筛选出【10月考勤统计.xlsx】中迟到时间大于45分钟并且迟到次数超过3次以上的员工信息,将迟到人员信息打印出来后再存入新工作簿【10月迟到人员信息.xlsx】中。
代码实现:
from openpyxl import load_workbook, Workbook
# 打开【10月考勤统计.xlsx】工作簿
wb = load_workbook('./material/10月考勤统计.xlsx')
# 获取活动工作表
ws = wb.active
print(ws)
print(ws[1])
print('----------------')
# 获取表头
late_header = []
for cell in ws[1]:
late_header.append(cell.value)
print(cell.value)
# 新建工作簿
new_wb = Workbook()
# 获取新工作簿中的工作表
new_ws = new_wb.active
# 将表头写入新工作簿的工作表中
new_ws.append(late_header)
# 从第二行开始遍历表格
for row in ws.iter_rows(min_row=2, values_only=True):
# 取出姓名,迟到时间和迟到次数
name = row[1]
time = row[3]
number = row[-1]
# 判断是否迟到
if time > 45 and number > 3:
print('{}迟到了{}分钟,迟到了{}次'.format(name, time, number))
# 将迟到人员信息写入新工作簿的工作表中
new_ws.append(row)
# 将新工作簿保存为【10月迟到人员信息.xlsx】
new_wb.save('./material/10月迟到人员信息.xlsx')运行结果:
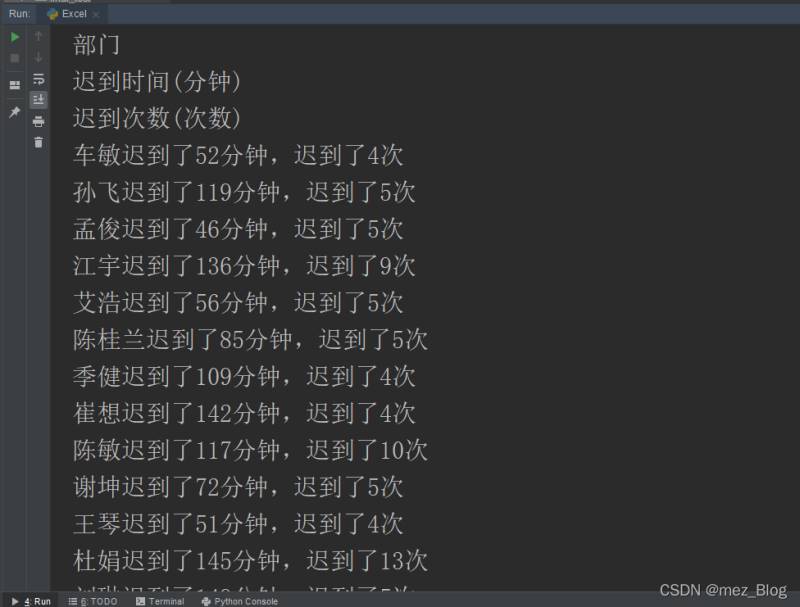

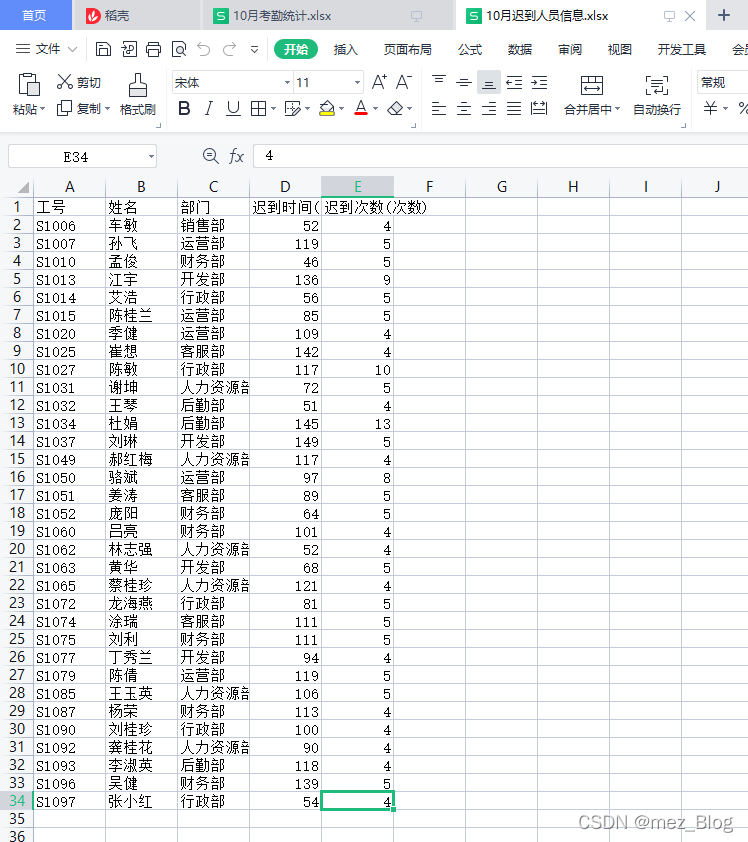
根据任务需求,我们需要获取两部分数据:表头数据和表头以外的所有数据。
你可能会比较疑惑,为什么要单独获取表头数据呢?

由于任务需要我们生成新的工作簿【10月迟到人员信息.xlsx】,新工作簿中的表头与【10月考勤统计.xlsx】相同,所以我们需要获取到表头的数据以便后续使用。
使用数据
我们需要在这一步实现数据筛选功能,通过分析任务需求可以总结出三个筛选条件:
1)迟到时间大于45分钟。
2)迟到次数大于3次。
3)同时满足上面两个条件。
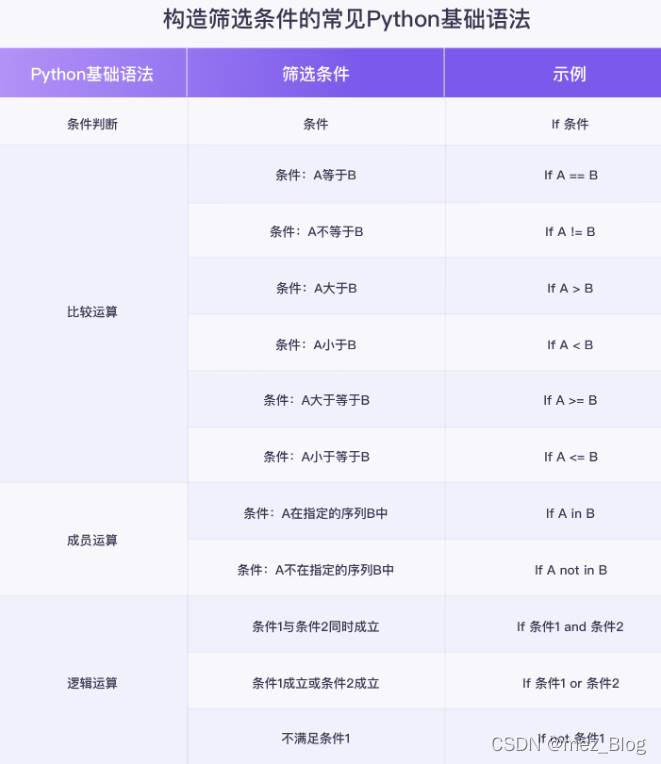
明确了筛选条件后,就可以借助条件判断语句,比较运算符,成员运算符和逻辑运算符等Python基础知识,实现对于数据的筛选,即将上面得到的筛选条件用Python语言实现出来。
假设我们用time来代表迟到时间,用number代表迟到次数,那么筛选条件就可以写为:if time > 45 and number > 3:
数据输出
完成筛选后,我们需要根据实际需求将筛选结果输出到终端,或将筛选结果保存起来。
本次任务要求我们将筛选后的员工信息打印出来,并且存储到【10月迟到人员信息.xlsx】中。
如果需要获取工作簿中满足某些条件的数据,这种场景就可以被归类为数据筛选场景。
处理该场景时,可以按照获取数据,使用数据和数据输出这三个步骤来处理。
首先是获取数据,使用上节课学习过的表格读写的相关知识,根据任务需求,确定要获取的是零散的单元格,是单行/单列,还是多行/多列的数据。
数据筛选的关键落在了筛选二字上,我们可以在使用数据这一步中实现筛选功能。
在这一步,要仔细理解任务需求,明确筛选条件,然后根据实际情况,选择Python基础语法的相关知识(条件判断语句,比较运算符,成员运算符和逻辑运算符),构造筛选条件。

最后是数据输出部分,根据实际需要输出筛选结果,或将筛选结果保存起来。总结起来可以分为三类:
1)将筛选的结果存入学过的数据结构里,比如:列表,元组或字典。
2)将筛选的结果存入文件中。
3)将筛选的结果打印出来。
这个案例需要我们匹配两张表格中指定的迟到次数,先来看看案例场景。
现有两张表格,【10月考勤统计.xlsx】中记录了员工十月份的迟到次数数据,这份表格是公司行政手动记录的。
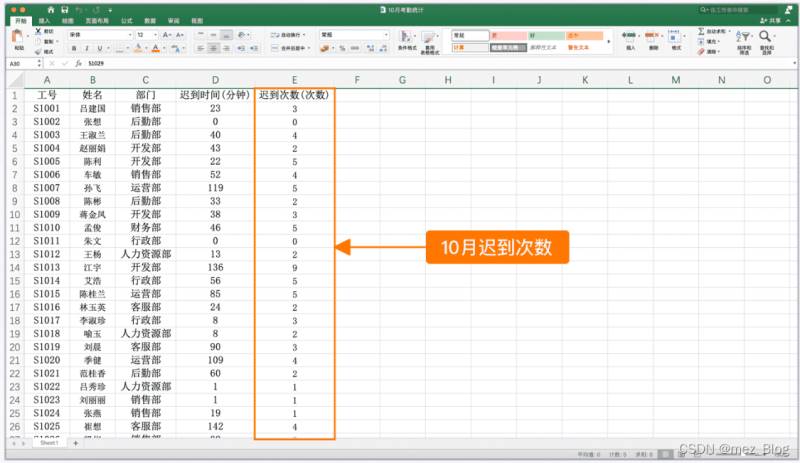
【迟到次数月度统计(10月更新).xlsx】中按月记录了员工每月的迟到次数数据,这份表格是由公司的考勤系统自动生成的。

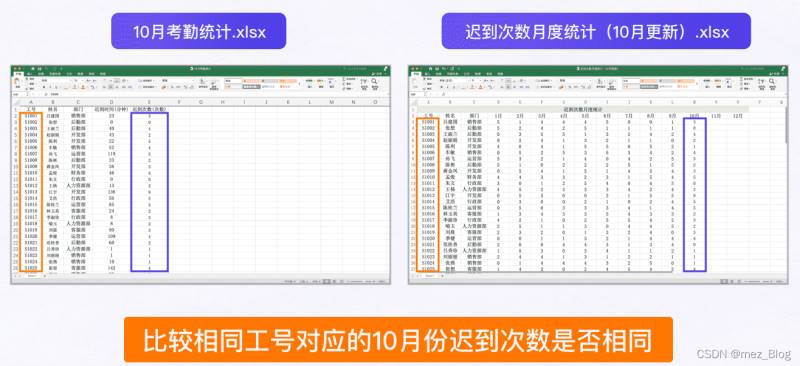
两份表格中的数据可以通过工号一一对应。
现需要核对两张表格中10月迟到次数是否匹配(即两表中相同工号在十月份的迟到次数是否一致),并在终端提醒相关人员去核查不匹配的情况。
代码实现:
from openpyxl import load_workbook
# 打开工作簿【10月考勤统计.xlsx】,获取活动工作表
wb = load_workbook('./material/10月考勤统计.xlsx')
ws = wb.active
# 创建迟到人员字典
info_dict = {}
# 循环读取除表头外的表格数据
for row in ws.iter_rows(min_row=2, values_only=True):
# 取出员工工号
staff_id = row[0]
# 取出迟到次数
staff_late = row[-1]
# 将信息添加入字典,字典格式为{'员工工号': '迟到次数'}
info_dict[staff_id] = staff_late
# 打开工作簿【迟到次数月度统计(10月更新).xlsx】,获取活动工作表
monthly_wb = load_workbook('./material/迟到次数月度统计(10月更新).xlsx')
monthly_ws = monthly_wb.active
# 循环读取出表头外的表格数据
for monthly_row in monthly_ws.iter_rows(min_row=3, max_col=13, values_only=True):
# 取出员工工号
member_id = monthly_row[0]
# 取出十一月份的迟到次数
member_late = monthly_row[-1]
# 匹配迟到次数是否相等
if member_late != info_dict[member_id]:
print('工号{}迟到情况不匹配,请核查后更新'.format(member_id))运行结果:
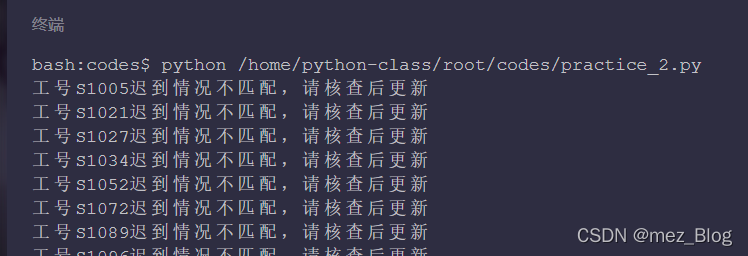
为什么会选择存储到字典中呢?
因为字典可以很好地体现出工号与迟到次数的对应关系,即{'工号': '迟到次数'}。
然后把【迟到次数月度统计(10月更新).xlsx】中的迟到次数,与字典中存储的迟到次数进行匹配,再判断相同工号对应的迟到次数是否相同。
感谢各位的阅读!关于“怎么用Python实现数据筛选与匹配”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。