жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҚҡж–ҮеӨ§зәІпјҡ
дёҖгҖҒDockerзҡ„зӣ‘жҺ§
дәҢгҖҒprometheusз®Җд»Ӣ
дёүгҖҒPrometheusз»„жҲҗеҸҠжһ¶жһ„
еӣӣгҖҒйғЁзҪІprometheus
1пјүзҺҜеўғеҮҶеӨҮ
2пјүйғЁзҪІprometheus
3пјүй…ҚзҪ®Peometheusзӣ‘жҺ§е®һзҺ°жҠҘиӯҰ
[root@localhost ~]# docker top wordpress_wordprss_1 //жҹҘзңӢе®№еҷЁзҡ„дҪҝз”ЁзҠ¶жҖҒ
UID PID PPID C STIME TTY TIME CMD
root 5601 5569 0 20:53 ? 00:00:00 apache2 -DFOREGROUND
33 6073 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6074 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6075 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6076 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6077 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6096 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6098 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6099 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6100 5601 0 20:54 ? 00:00:00 apache2 -DFOREGROUND
33 6155 5601 0 20:57 ? 00:00:00 apache2 -DFOREGROUND
[root@localhost ~]# docker stats wordpress_wordprss_1
[root@localhost ~]# docker logs wordpress_wordprss_1
//иҝҷдёүжқЎйғҪжҳҜе®№еҷЁжң¬иә«иҮӘеёҰзҡ„зӣ‘жҺ§е‘Ҫд»Ө[root@localhost ~]# docker run -it --rm --name sysdig --privileged=true --volume=/var/run/docker.sock:/host/var/run/docker.sock --volume=/dev:/host/dev --volume=/proc:/host/proc:ro --volume=/boot:/host/boot:ro --volume=/lib/modules:/host/lib/modules:ro --volume=/usr:/host/usr:ro sysdig/sysdig
//еҲӣе»әдёҖдёӘе®№еҷЁе№¶иҮӘеҠЁиҝӣе…Ҙе®№еҷЁдёӯ
//--rmпјҡйҡҸзқҖйҖҖеҮәе®№еҷЁиҖҢиў«еҲ йҷӨпјӣ
//--privileged=trueпјҡиөӢдәҲзү№ж®Ҡжқғйҷҗпјӣ
root@711dbeb59fdd:/# csysdig //жү§иЎҢиҝҷжқЎе‘Ҫд»ӨеҰӮеӣҫпјҡ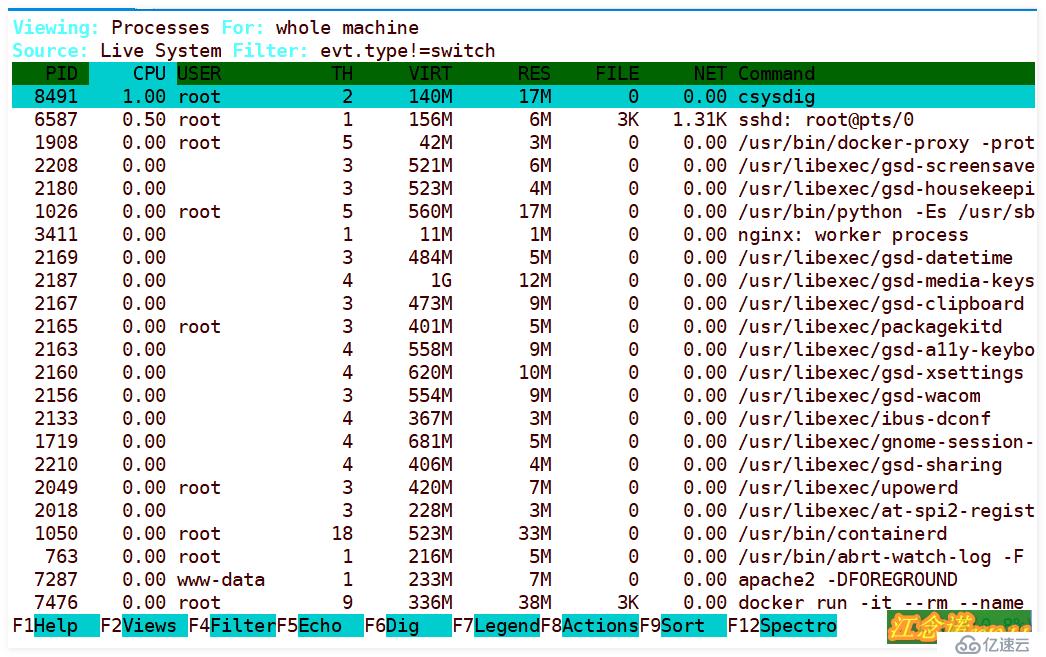
еӣҫдёӯеҸҜд»ҘдҪҝз”Ёй”®зӣҳе’Ңйј ж ҮиҝӣиЎҢж“ҚдҪңпјҒ
[root@localhost ~]# curl -L git.io/scope -o /usr/local/bin/scope
[root@localhost ~]# chmod +x /usr/local/bin/scope //дёӢиҪҪе®үиЈ…и„ҡжң¬
[root@localhost ~]# scope launch //д»Ҙе®№еҷЁж–№ејҸеҗҜеҠЁ
вҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰвҖҰ
Weave Scope is listening at the following URL(s):
* http://172.21.0.1:4040/
* http://192.168.122.1:4040/
* http://172.22.0.1:4040/
* http://172.20.0.1:4040/
* http://172.18.0.1:4040/
* http://172.19.0.1:4040/
* http://192.168.1.1:4040/
//ж №жҚ®жң«е°ҫзҡ„жҸҗзӨәдҝЎжҒҜиҝӣиЎҢи®ҝй—®еҰӮеӣҫпјҡ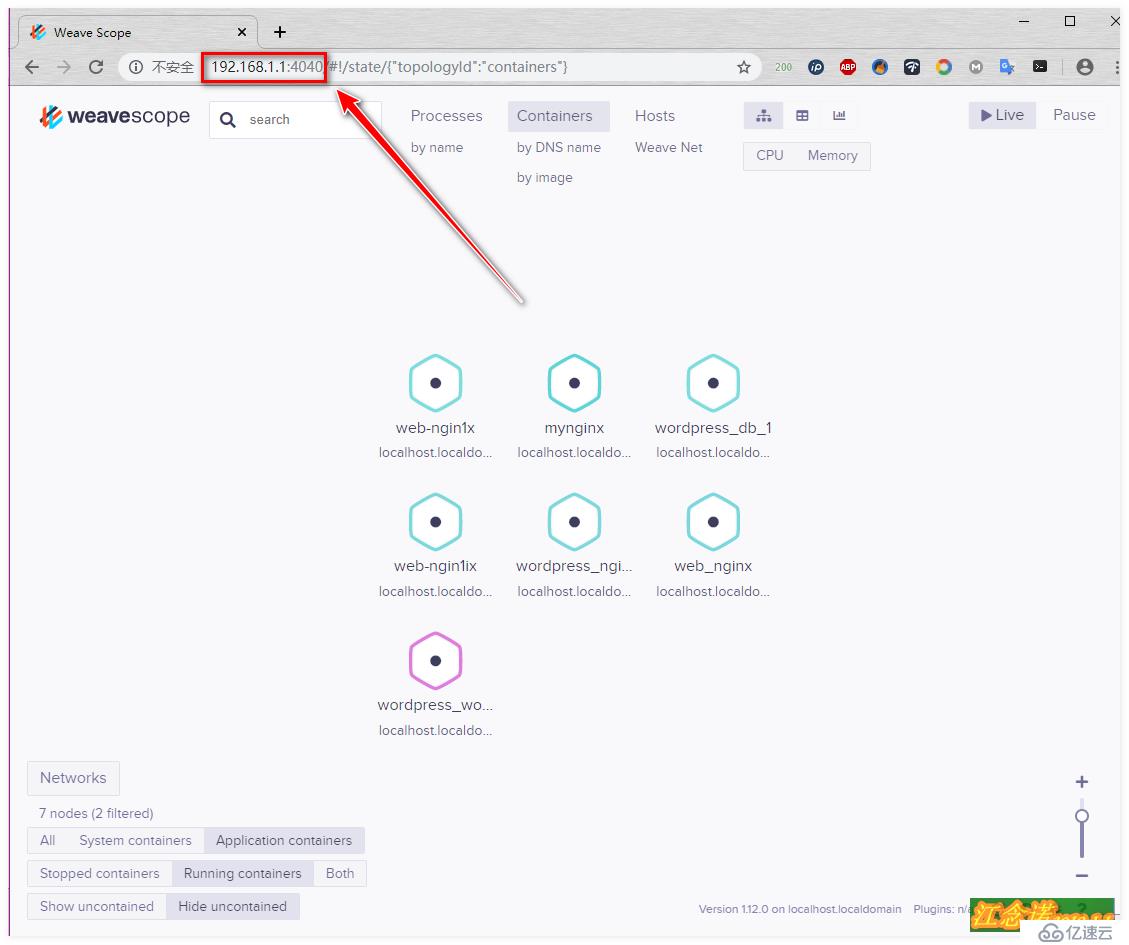
ж №жҚ®еӣҫдёӯзҡ„жҸҗзӨәпјҢиҮӘиЎҢеҸҜд»ҘзӮ№еҮ»иҝӣиЎҢжөӢиҜ•пјҒ
еҰӮжһңиҰҒзӣ‘жҺ§дёӨеҸ°зҡ„иҜқпјҡдё»жңәеҗҚеҝ…йЎ»иҝӣиЎҢеҢәеҲҶж–№жі•еҰӮдёӢпјҡ
[root@dockerA ~]# curl -L git.io/scope -o /usr/local/bin/scope
[root@dockerA ~]# chmod +x /usr/local/bin/scope
[root@dockerA ~]# scope launch 192.168.1.1 192.168.1.2 //йҰ–йҖүжҢҮе®ҡжң¬ең°зҡ„IPпјҢеҶҚжҢҮе®ҡеҜ№ж–№зҡ„IP
[root@dockerA ~]# docker run -itd --name http httpd //иҝҗиЎҢдёҖдёӘе®№еҷЁиҝӣиЎҢжөӢиҜ•
[root@dockerB ~]# curl -L git.io/scope -o /usr/local/bin/scope
[root@dockerB ~]# chmod +x /usr/local/bin/scope
[root@dockerB ~]# scope launch 192.168.1.2 192.168.1.1
[root@dockerB ~]# docker run -itd --name nginx nginxи®ҝй—®пјҲdockerAгҖҒdockerBд»»ж„ҸдёҖеҸ°еҚіеҸҜпјүжөӢиҜ•пјҡ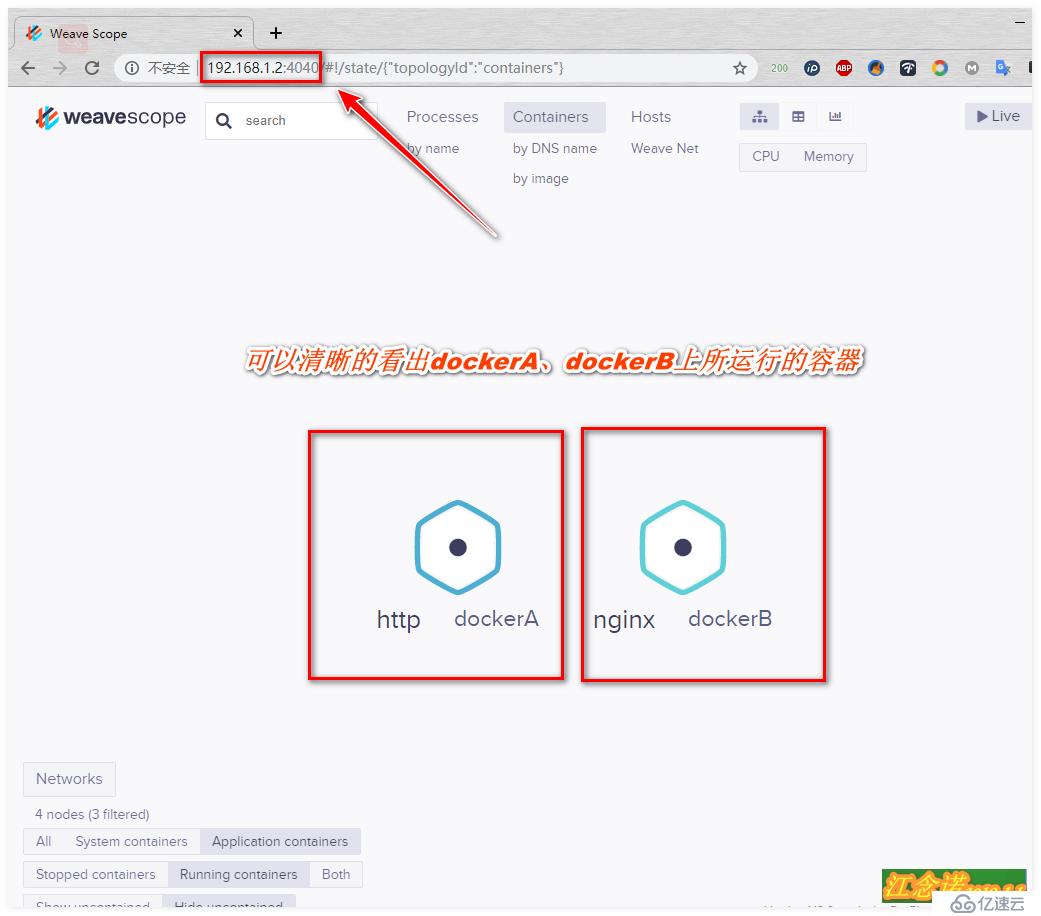
PrometheusжҳҜдёҖеҘ—ејҖжәҗзҡ„зі»з»ҹзӣ‘жҺ§жҠҘиӯҰжЎҶжһ¶гҖӮе®ғд»Ҙз»ҷе®ҡзҡ„ж—¶й—ҙй—ҙйҡ”д»Һе·Ій…ҚзҪ®зҡ„зӣ®ж Ү收йӣҶжҢҮж ҮпјҢиҜ„估规еҲҷиЎЁиҫҫејҸпјҢжҳҫзӨәз»“жһңпјҢ并еңЁеҸ‘зҺ°жҹҗдәӣжғ…еҶөдёәзңҹж—¶и§ҰеҸ‘иӯҰжҠҘгҖӮ
дҪңдёәж–°дёҖд»Јзҡ„зӣ‘жҺ§жЎҶжһ¶пјҢPrometheusе…·жңүд»ҘдёӢзү№зӮ№ пјҡ
- ејәеӨ§зҡ„еӨҡз»ҙеәҰж•°жҚ®жЁЎеһӢпјҡ
пјҲ1пјүж—¶й—ҙеәҸеҲ—ж•°жҚ®йҖҡиҝҮmetricеҗҚе’Ңй”®еҖјеҜ№жқҘеҢәеҲҶпјӣ
пјҲ2пјүжүҖжңүзҡ„metricsйғҪеҸҜд»Ҙи®ҫзҪ®д»»ж„Ҹзҡ„еӨҡз»ҙж Үзӯҫпјӣ
пјҲ3пјүж•°жҚ®жЁЎеһӢжӣҙйҡҸж„ҸпјҢпјҢдёҚйңҖиҰҒеҲ»ж„Ҹи®ҫзҪ®дёәд»ҘзӮ№еҲҶйҡ”зҡ„еӯ—з¬ҰдёІпјӣ
пјҲ4пјүеҸҜд»ҘеҜ№ж•°жҚ®жЁЎеһӢиҝӣиЎҢиҒҡеҗҲгҖҒеҲҮеүІе’ҢеҲҮзүҮж“ҚдҪңпјӣ
пјҲ5пјүж”ҜжҢҒеҸҢзІҫеәҰжө®зӮ№зұ»еһӢпјҢж ҮзӯҫеҸҜд»Ҙи®ҫдёәе…ЁunicodeпјҲз»ҹдёҖз Ғпјүпјӣ- зҒөжҙ»гҖҒејәеӨ§зҡ„жҹҘиҜўиҜӯеҸҘпјҡеңЁеҗҢдёҖдёӘжҹҘиҜўиҜӯеҸҘпјҢеҸҜд»ҘеҜ№еӨҡдёӘ metrics иҝӣиЎҢд№ҳжі•гҖҒеҠ жі•гҖҒиҝһжҺҘгҖҒеҸ–еҲҶж•°дҪҚзӯүж“ҚдҪңпјӣ
- жҳ“дәҺз®ЎзҗҶпјҡдёҚдҫқиө–дәҺеҲҶеёғејҸеӯҳеӮЁпјӣ
- дҪҝз”Ё pull жЁЎејҸйҮҮйӣҶж—¶й—ҙеәҸеҲ—ж•°жҚ®пјӣ
- еҸҜд»ҘйҮҮз”Ё push gateway зҡ„ж–№ејҸжҠҠж—¶й—ҙеәҸеҲ—ж•°жҚ®жҺЁйҖҒиҮі Prometheus server з«Ҝпјӣ
- еҸҜд»ҘйҖҡиҝҮжңҚеҠЎеҸ‘зҺ°жҲ–иҖ…йқҷжҖҒй…ҚзҪ®еҺ»иҺ·еҸ–зӣ‘жҺ§зҡ„ targetsпјӣ
- жңүеӨҡз§ҚеҸҜи§ҶеҢ–еӣҫеҪўз•Ңйқўпјӣ
- жҳ“дәҺдјёзј©гҖӮпјӣ
PrometheusеҢ…еҗ«дәҶи®ёеӨҡ组件пјҢе…¶дёӯи®ёеӨҡ组件йғҪжҳҜеҸҜйҖүзҡ„пјҢеёёз”Ёзҡ„组件жңүпјҡ
- Prometheus Serverпјҡз”ЁдәҺ收йӣҶе’ҢеӯҳеӮЁж—¶й—ҙеәҸеҲ—ж•°жҚ®пјӣ
- Client Libraryпјҡе®ўжҲ·з«Ҝеә“пјҢдёәйңҖиҰҒзӣ‘жҺ§зҡ„жңҚеҠЎз”ҹжҲҗзӣёеә”зҡ„ metrics 并жҡҙйңІз»ҷ Prometheus serverпјӣ
- Push Gatewayпјҡдё»иҰҒз”ЁдәҺзҹӯжңҹзҡ„ jobsгҖӮз”ұдәҺиҝҷзұ» jobs еӯҳеңЁж—¶й—ҙиҫғзҹӯпјҢеҸҜиғҪеңЁ Prometheus жқҘ pull д№ӢеүҚе°ұж¶ҲеӨұдәҶгҖӮдёәжӯӨпјҢиҝҷж¬Ў jobs еҸҜд»ҘзӣҙжҺҘеҗ‘ Prometheus server з«ҜжҺЁйҖҒе®ғ们зҡ„ metricsпјӣ
- Exportersпјҡз”ЁдәҺжҡҙйңІе·Іжңүзҡ„第дёүж–№жңҚеҠЎзҡ„ metrics з»ҷ Prometheusпјӣ
- Alertmanagerпјҡд»Һ Prometheus server з«ҜжҺҘ收еҲ° alerts еҗҺпјҢдјҡиҝӣиЎҢеҺ»йҷӨйҮҚеӨҚж•°жҚ®пјҢеҲҶз»„пјҢ并и·Ҝз”ұеҲ°еҜ№з«Ҝзҡ„жҺҘеҸ—ж–№ејҸпјҢеҸ‘еҮәжҠҘиӯҰпјӣ
вҖҰвҖҰвҖҰвҖҰзӯүзӯүпјҢиҝҳжңүеҘҪеӨҡпјҢиҝҷйҮҢе°ұеҲ—еҮәеҮ дёӘеёёз”Ёзҡ„组件пјҒ
Prometheusе®ҳж–№ж–ҮжЎЈдёӯзҡ„жһ¶жһ„еӣҫпјҡ
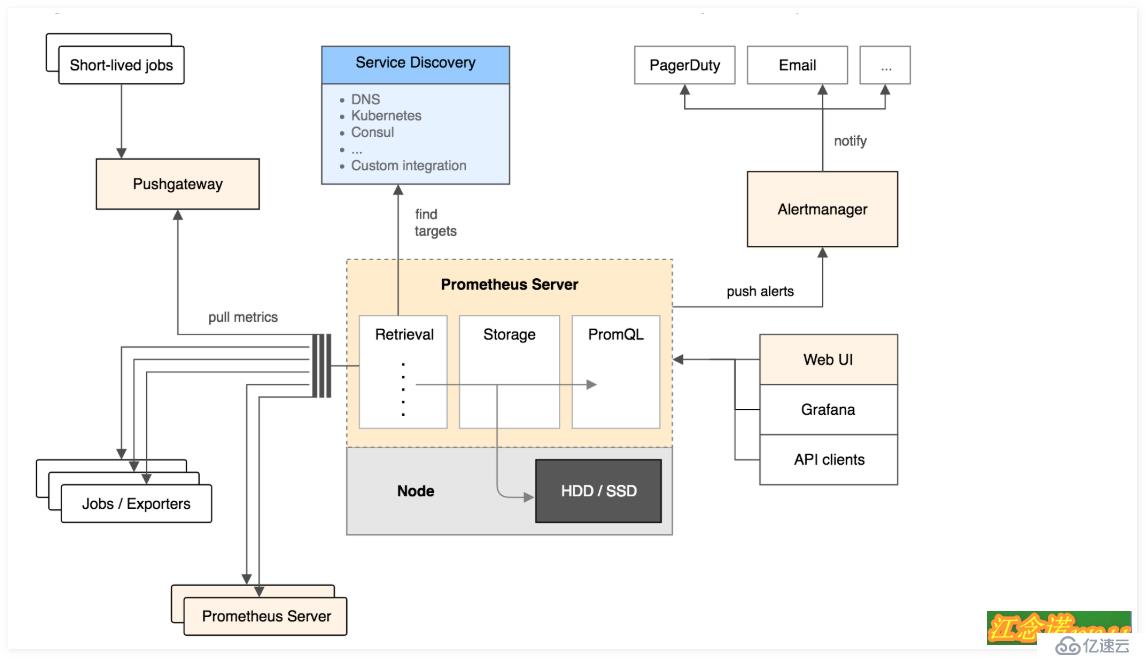
е®ҳж–№зҡ„жһ¶жһ„еӣҫдёӯпјҢдё»иҰҒжЁЎеқ—еқ—еҢ…жӢ¬пјҡPrometheus server, exporters, Pushgateway, PromQL, Alertmanager д»ҘеҸҠеӣҫеҪўз•Ңйқўпјӣ
еӨ§иҮҙзҡ„е·ҘдҪңжөҒзЁӢжҳҜпјҡ
пјҲ1пјүPrometheus server е®ҡжңҹд»Һй…ҚзҪ®еҘҪзҡ„ jobs жҲ–иҖ… exporters дёӯжӢү metricsпјҢжҲ–иҖ…жҺҘ收жқҘиҮӘ Pushgateway еҸ‘иҝҮжқҘзҡ„ metricsпјҢжҲ–иҖ…д»Һе…¶д»–зҡ„ Prometheus server дёӯжӢү metricsпјӣ
пјҲ2пјүPrometheus server еңЁжң¬ең°еӯҳеӮЁж”¶йӣҶеҲ°зҡ„ metricsпјҢ并иҝҗиЎҢе·Іе®ҡд№үеҘҪзҡ„ alert.rulesпјҢи®°еҪ•ж–°зҡ„ж—¶й—ҙеәҸеҲ—жҲ–иҖ…еҗ‘ Alertmanager жҺЁйҖҒиӯҰжҠҘпјӣ
пјҲ3пјүAlertmanager ж №жҚ®й…ҚзҪ®ж–Ү件пјҢеҜ№жҺҘ收еҲ°зҡ„иӯҰжҠҘиҝӣиЎҢеӨ„зҗҶпјҢеҸ‘еҮәе‘ҠиӯҰпјӣ
пјҲ4пјүеңЁеӣҫеҪўз•ҢйқўдёӯпјҢеҸҜи§ҶеҢ–йҮҮйӣҶж•°жҚ®пјӣ
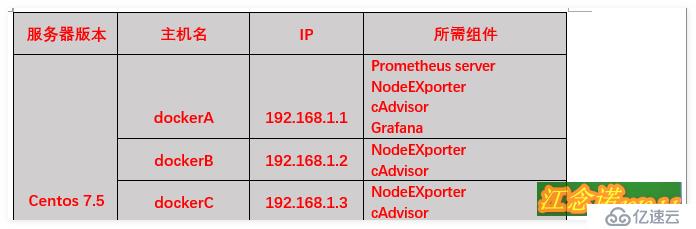
жіЁж„ҸпјҡдёҠиҝ°дёүеҸ°жңҚеҠЎеҷЁдёҠеҝ…йЎ»е…·еӨҮжңҖеҹәжң¬зҡ„dockerзҺҜеўғпјҢдёҠиҝ°зҺҜеўғзҡ„dockerзүҲжң¬дёә18.09.0пјҒ
дёҠиҝ°зҺҜеўғжүҖйңҖ组件зҡ„дҪңз”ЁеҰӮдёӢпјҡ
- Prometheus serverпјҡжҷ®зҪ—зұідҝ®ж–Ҝзҡ„дё»жңҚеҠЎеҷЁпјҲз«ҜеҸЈпјҡ9090пјүпјӣ
- NodeEXporterпјҡиҙҹиҙЈж”¶йӣҶHost硬件дҝЎжҒҜе’Ңж“ҚдҪңзі»з»ҹдҝЎжҒҜпјҢпјҲз«ҜеҸЈпјҡ9100пјүпјӣ
- cAdvisorпјҡиҙҹиҙЈж”¶йӣҶHostдёҠиҝҗиЎҢзҡ„е®№еҷЁдҝЎжҒҜпјҲз«ҜеҸЈпјҡ8080пјүпјӣ
- GrafanaпјҡиҙҹиҙЈеұ•зӨәжҷ®зҪ—зұідҝ®ж–Ҝзӣ‘жҺ§з•ҢйқўпјҲ3000пјүпјӣ
- Alertmanagerпјҡз”ЁжқҘжҺҘ收PrometheusеҸ‘йҖҒзҡ„жҠҘиӯҰдҝЎжҒҜпјҢ并且жү§иЎҢи®ҫзҪ®еҘҪзҡ„жҠҘиӯҰж–№ејҸпјҢжҠҘиӯҰеҶ…е®№пјҲеҗҢж ·д№ҹжҳҜеңЁdockerAдё»жңәдёҠйғЁзҪІпјҢз«ҜеҸЈпјҡ9093пјүпјӣ
еҗ„组件зҡ„е…ізі»пјҡNodeEXporterгҖҒcAdvisorиҙҹиҙЈж”¶йӣҶдҝЎжҒҜеҸ‘йҖҒз»ҷ Prometheus serverпјҢеңЁз”ұ Prometheus serverдәӨз»ҷGrafanaиҝӣиЎҢеӣҫеҪўеҢ–зҡ„жҳҫзӨәгҖӮеҰӮйңҖжҠҘиӯҰпјҢеҲҷз”ұprometheusеҗ‘Alertmanager组件еҸ‘йҖҒдҝЎжҒҜпјҒ
е®һйӘҢзҺҜеўғпјҢдёәдәҶз®ҖеҚ•иө·и§ҒпјҢе…ій—ӯйҳІзҒ«еўҷгҖҒSELinuxпјҢе®һйҷ…зҺҜеўғдёӯйңҖејҖеҗҜзӣёеә”зҡ„з«ҜеҸЈпјҒ
NodeEXporterдё»иҰҒиҙҹиҙЈж”¶йӣҶHost硬件дҝЎжҒҜе’Ңж“ҚдҪңзі»з»ҹдҝЎжҒҜпјҒ
[root@dockerA ~]# docker run -d --name node -p 9100:9100 -v /proc:/host/proc -v /sys:/host/sys -v /:/rootfs --net=host prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
//дҪҝз”Ёprom/node-exporter й•ңеғҸеҲӣе»әдёҖдёӘеҗҚдёәnodeзҡ„е®№еҷЁпјҢз”ЁдәҺ收йӣҶ硬件е’Ңзі»з»ҹдҝЎжҒҜпјӣ
//--net=hostиЎЁзӨәPrometheus serverеҸҜд»ҘзӣҙжҺҘдёҺnode-exporterйҖҡдҝЎпјӣ
//并жҳ е°„9100з«ҜеҸЈжү§иЎҢе®ҢжҲҗеҗҺпјҢе®ўжҲ·з«ҜдҪҝз”ЁжөҸи§ҲеҷЁиҝӣиЎҢи®ҝй—®пјҢеҰӮеӣҫпјҡ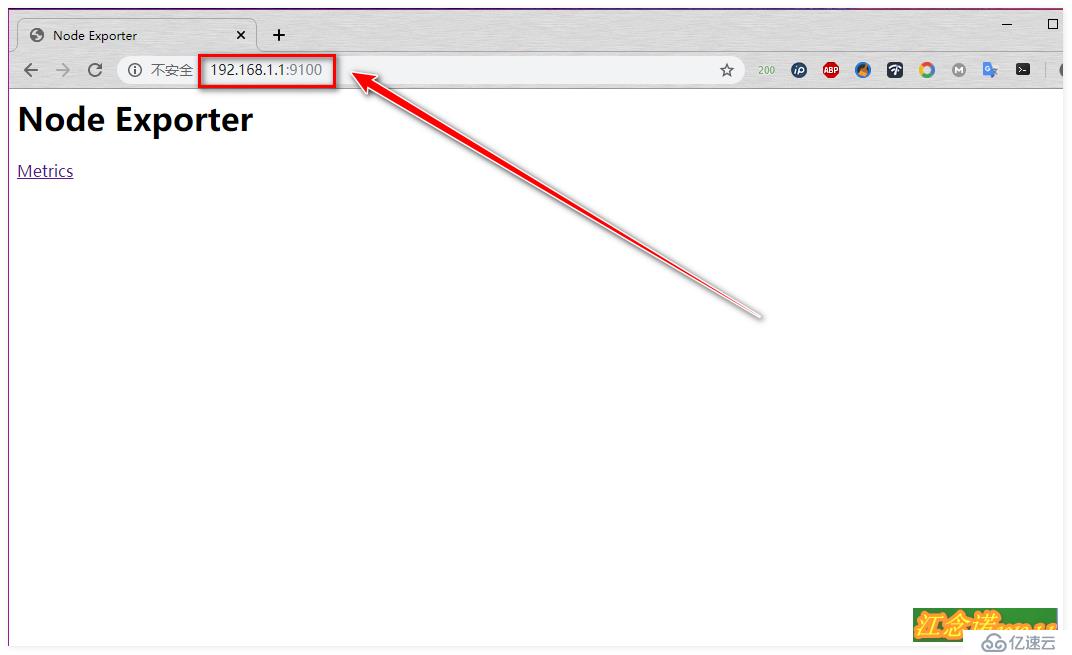
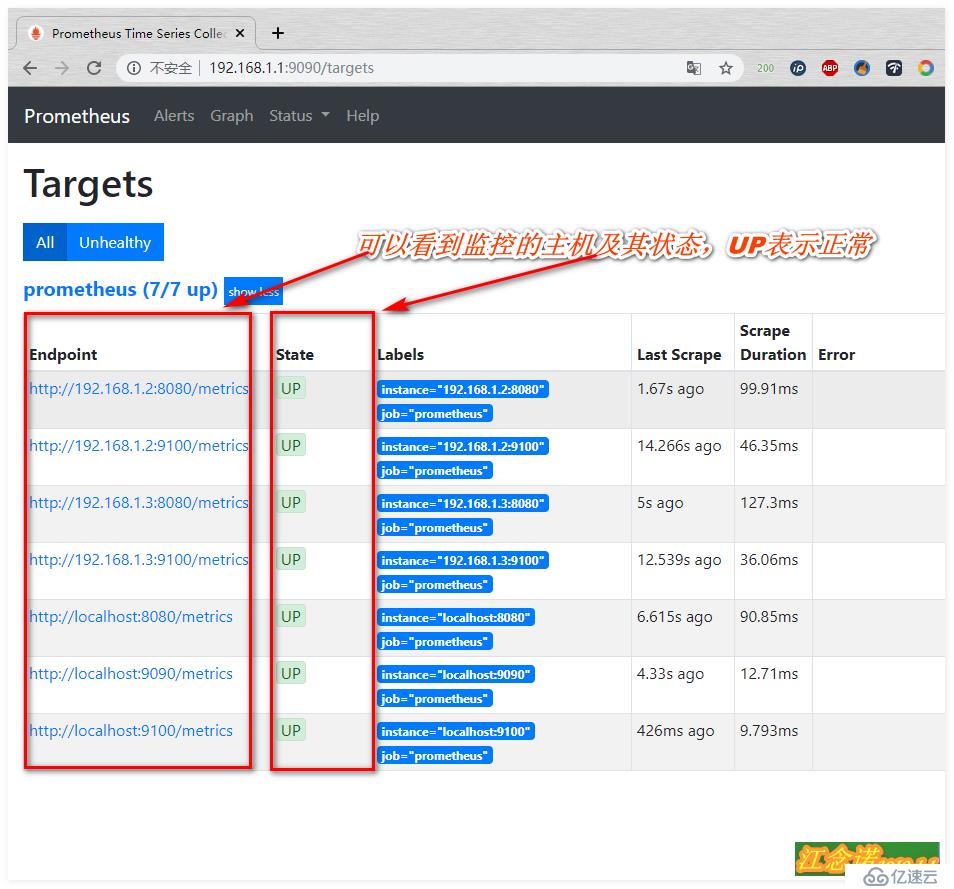
и®ҝй—®еҲ°д»ҘдёҠйЎөйқўиЎЁзӨәnode-exporterиҝҷдёӘ组件е®үиЈ…жҲҗеҠҹпјҒ
з”ұдәҺиҝҷдёӘNodeEXporter组件йңҖиҰҒеңЁдёүеҸ°docker hostдё»жңәдёҠпјҢжүҖд»Ҙд»ҘдёҠе‘Ҫд»Өе°ұйңҖиҰҒеңЁеҸҰеӨ–дёӨеҸ°дё»жңәдёҠйғҪжү§иЎҢгҖӮжү§иЎҢе®ҢжҲҗеҗҺпјҢиҮӘиЎҢдҪҝз”ЁжөҸи§ҲеҷЁи®ҝй—®жөӢиҜ•пјҒ
cAdvisorдё»иҰҒиҙҹиҙЈж”¶йӣҶHostдёҠиҝҗиЎҢзҡ„е®№еҷЁдҝЎжҒҜпјҒ
[root@dockerA ~]# docker run -v /:/rootfs:ro -v /var/run:/var/run/:rw -v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor --net=host google/cadvisorе®ўжҲ·з«Ҝи®ҝй—®жөӢиҜ•пјҡ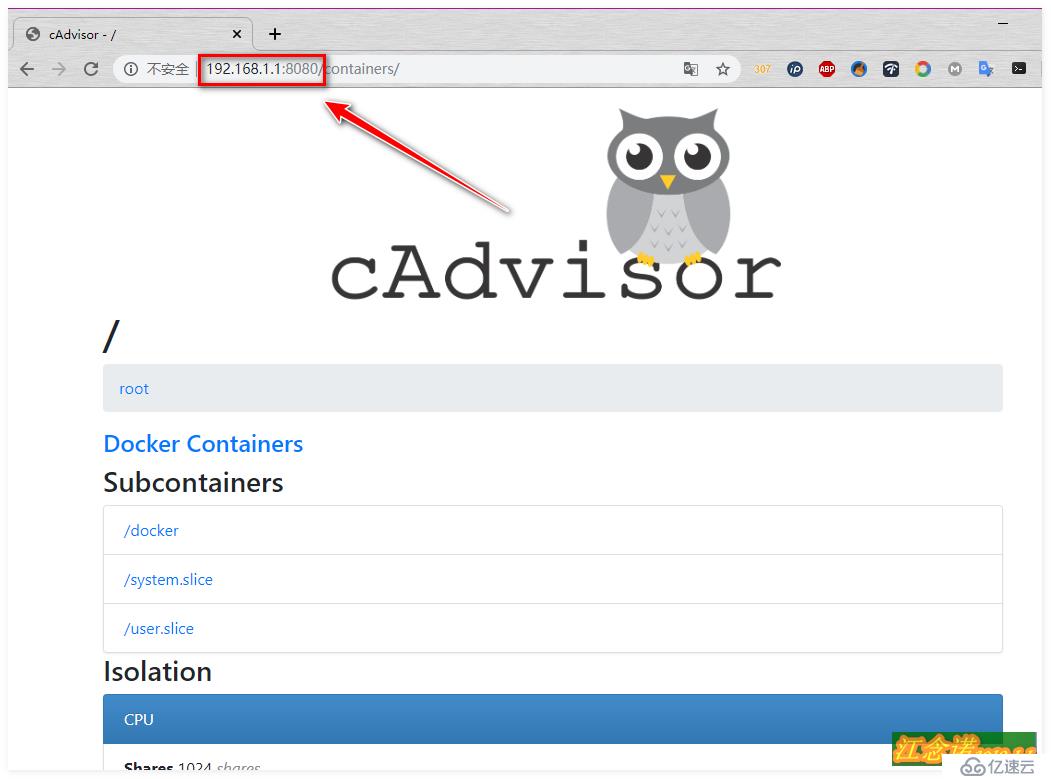
и®ҝй—®еҲ°дёҠиҝ°йЎөйқўеҲҷиЎЁзӨәcAdvisorиҝҷдёӘ组件е®үиЈ…жҲҗеҠҹпјҒ
еҗҢж ·иҝҷдёӘcAdvisor组件д№ҹжҳҜйңҖиҰҒеңЁдёүеҸ°docker hostдёҠе…ЁйғЁе®үиЈ…зҡ„пјҒжүҖд»Ҙд»ҘдёҠе‘Ҫд»Өд№ҹйңҖеңЁеҸҰеӨ–дёӨеҸ°дё»жңәдёҠжү§иЎҢпјҢжү§иЎҢе®ҢжҲҗеҗҺпјҢиҮӘиЎҢжөӢиҜ•пјҒ
PrometheusжҳҜжҷ®зҪ—зұідҝ®ж–Ҝзҡ„дё»жңҚеҠЎеҷЁпјҒ
еңЁйғЁзҪІPrometheusд№ӢеүҚпјҢйңҖиҰҒеҜ№е®ғзҡ„й…ҚзҪ®ж–Ү件иҝӣиЎҢдҝ®ж”№пјҢжүҖд»ҘйҰ–е…ҲиҝҗиЎҢдёҖдёӘPrometheusе®№еҷЁе°Ҷе…¶й…ҚзҪ®ж–Ү件еӨҚеҲ¶еҲ°жң¬ең°пјҢдҫҝдәҺиҝӣиЎҢдҝ®ж”№гҖӮ
[root@dockerA ~]# docker run -d -p 9090:9090 --name prometheus --net=host prom/prometheus
//иҝҗиЎҢдёҖдёӘPrometheusе®№еҷЁжҳҜдёәдәҶе°Ҷе®ғзҡ„й…ҚзҪ®ж–Ү件жӢҝеҲ°жң¬ең°
[root@dockerA ~]# docker cp prometheus:/etc/prometheus/prometheus.yml .
//е°ҶPrometheusе®№еҷЁдёӯзҡ„дё»й…ҚзҪ®ж–Ү件еӨҚеҲ¶еҲ°жң¬ең°
[root@dockerA ~]# vim prometheus.yml //зј–иҫ‘дё»й…ҚзҪ®ж–Ү件
- targets: ['localhost:9090','localhost:8080','localhost:9100','192.168.1.2:8080','192.168.1.2:9100','192.168.1.3:8080','192.168.1.3:9100']
//иҝҷйЎ№еҺҹжң¬жҳҜеӯҳеңЁзҡ„пјҢеҸӘйңҖдҝ®ж”№еҚіеҸҜпјҒ
//з”ЁдәҺжҢҮе®ҡзӣ‘жҺ§жң¬жңәзҡ„9090гҖҒ8080гҖҒ9100иҝҷдёүдёӘз«ҜеҸЈпјҢеҸҰеӨ–ж·»еҠ еҸҰеӨ–дёӨеҸ°dockerдё»жңәзҡ„8080гҖҒ9100иҝҷдёӨдёӘз«ҜеҸЈгҖӮ
//8080з«ҜеҸЈиҝҗиЎҢзҡ„жҳҜcAdvisorжңҚеҠЎ
//9100з«ҜеҸЈиҝҗиЎҢзҡ„жҳҜnode-exporterжңҚеҠЎ
//9090з«ҜеҸЈиҝҗиЎҢзҡ„е°ұжҳҜPrometheusжңҚеҠЎ
[root@dockerA ~]# docker rm prometheus -f //е°ҶеҲҡжүҚиҝҗиЎҢзҡ„е®№еҷЁеҲ йҷӨ
prometheus
[root@dockerA ~]# docker run -d -p 9090:9090 --name prometheus --net=host -v /root/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
//йҮҚж–°иҝҗиЎҢдёҖдёӘprometheusе®№еҷЁпјҢе°ҶеҲҡжүҚдҝ®ж”№е®ҢжҲҗзҡ„й…ҚзҪ®ж–Ү件жҢӮиҪҪеҲ°е®№еҷЁдёӯе®ўжҲ·з«Ҝи®ҝй—®жөӢиҜ•пјҡ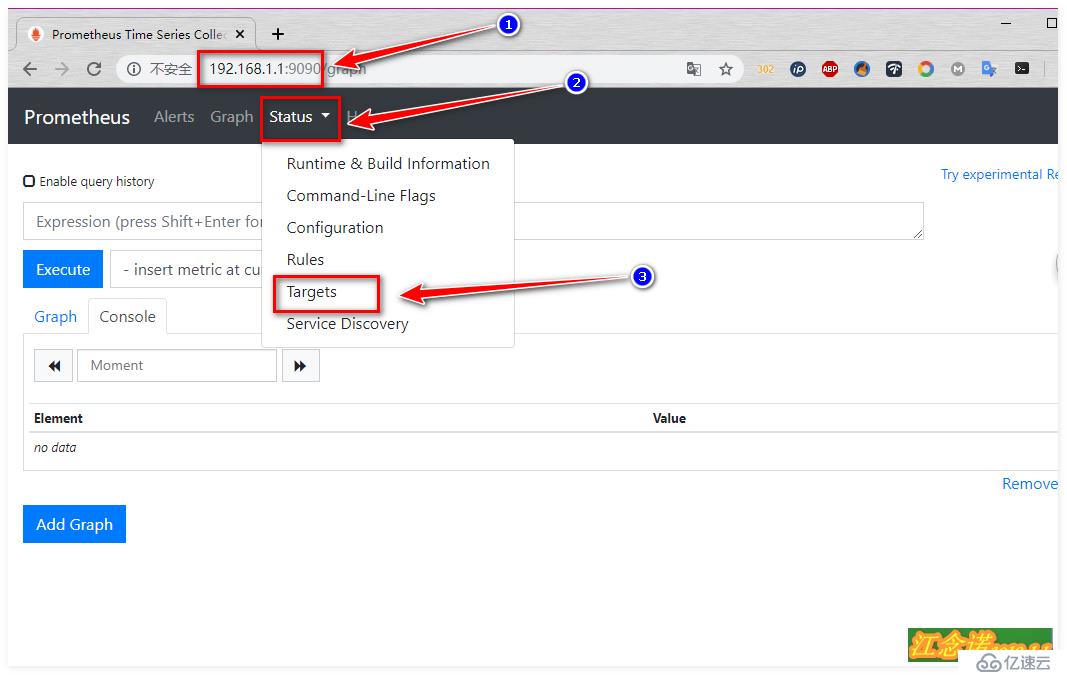
grafanaдё»иҰҒиҙҹиҙЈеұ•зӨәжҷ®зҪ—зұідҝ®ж–Ҝзӣ‘жҺ§з•ҢйқўпјҢз»ҷжҲ‘们жҸҗдҫӣиүҜеҘҪзҡ„еӣҫеҪўеҢ–з•ҢйқўпјҒ
[root@dockerA ~]# mkdir grafana-storage
[root@dockerA ~]# chmod 777 -R grafana-storage
//еҲӣе»әдёҖдёӘзӣ®еҪ•пјҢиөӢдәҲ777зҡ„жқғйҷҗ
[root@dockerA ~]# docker run -d -p 3000:3000 --name grafana -v /root/grafana-storage:/var/lib/grafana -e "GF_SECURITY_ADMIN_PASSWORD=123.com" grafana/grafana
//вҖң-eвҖқйҖүйЎ№иЎЁзӨәдҝ®ж”№е®№еҷЁеҶ…йғЁзҡ„зҺҜеўғеҸҳйҮҸпјҢе°Ҷadminз”ЁжҲ·зҡ„еҜҶз Ғжӣҙж”№дёә123.comпјӣе®ўжҲ·з«Ҝи®ҝй—®жөӢиҜ•пјҡ


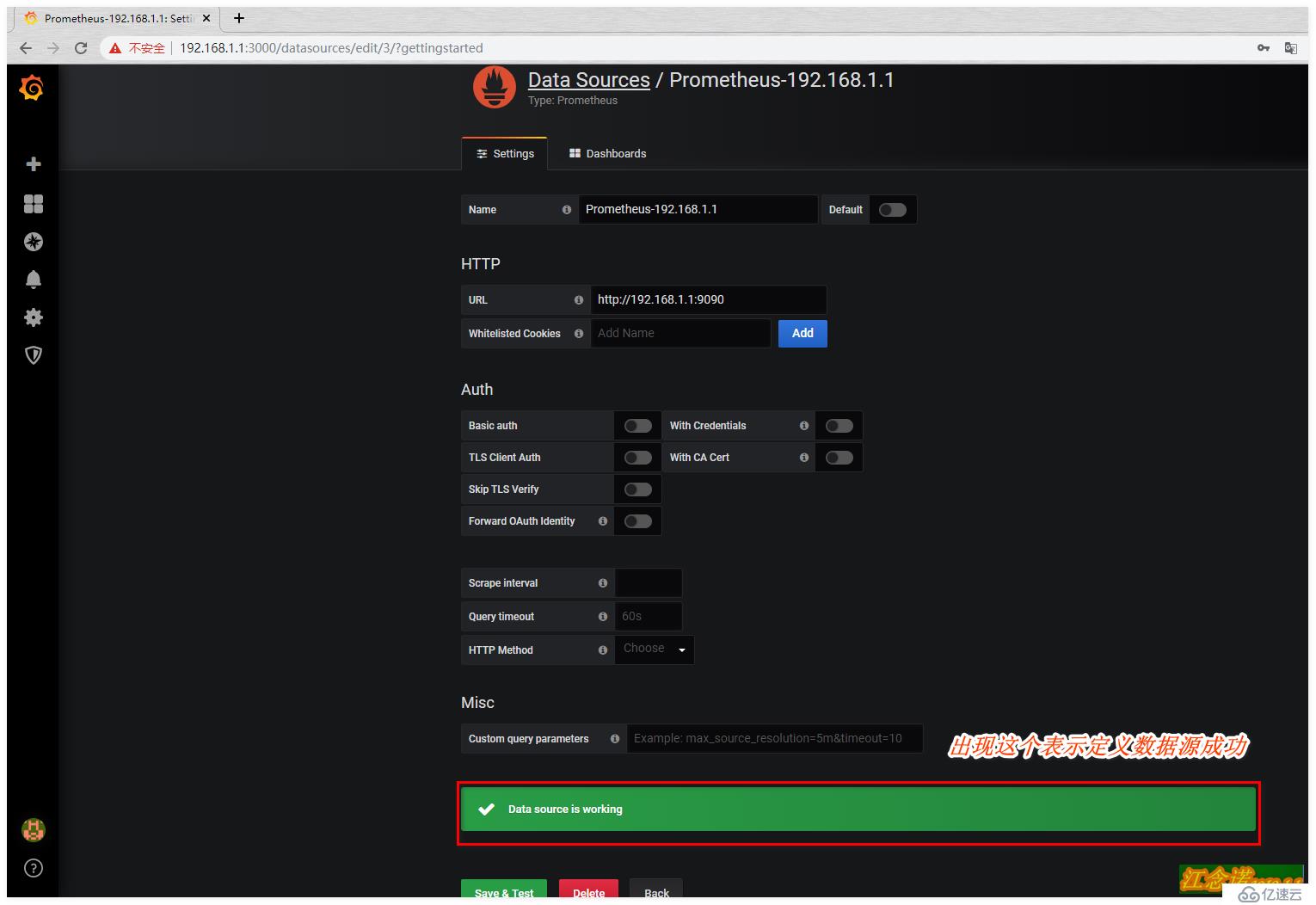
дёҠиҝ°й…ҚзҪ®е®ҢжҲҗеҗҺпјҢжҲ‘们е°ұйңҖиҰҒй…ҚзҪ®е®ғд»Ҙд»Җд№Ҳж ·зҡ„еҪўејҸжқҘз»ҷжҲ‘们еұ•зӨәдәҶпјҢеҸҜд»ҘиҮӘе®ҡд№үпјҢдҪҶжҳҜеҫҲйә»зғҰпјҢжҲ‘йҖүжӢ©зӣҙжҺҘеҺ»grafanaе®ҳзҪ‘еҜ»жүҫзҺ°жҲҗзҡ„жЁЎжқҝгҖӮеҰӮеӣҫпјҡ
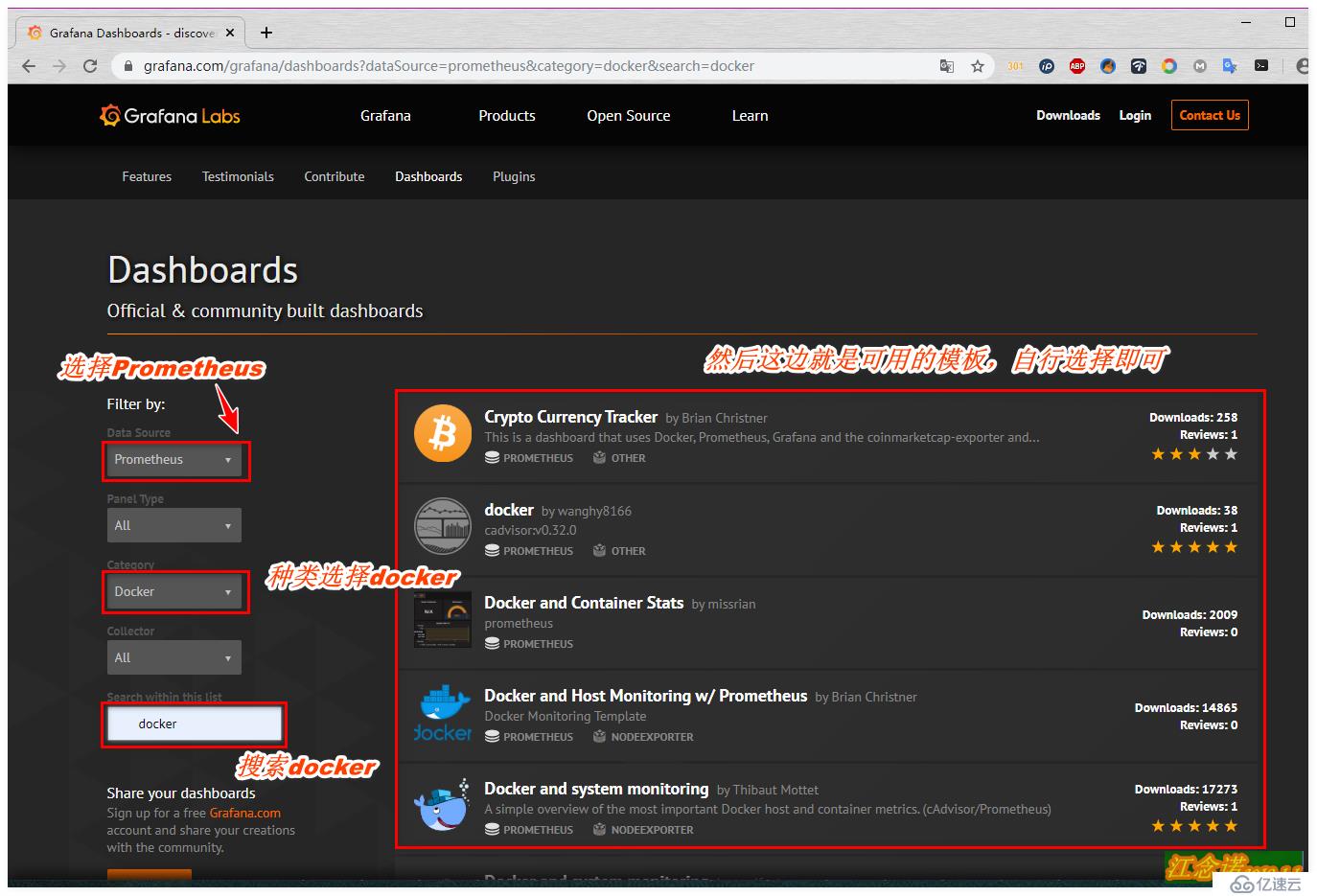
е°Ҷgrafanaе®ҳж–№зҡ„жЁЎжқҝеҜје…ҘеҲ°жҲ‘们зҡ„grafanaе®№еҷЁжҸҗдҫӣзҡ„webйЎөйқўдёӯпјҢж–№жі•жңүдёӨз§Қж–№ејҸпјҡ
еңЁgrafanaе®ҳзҪ‘йҖүжӢ©иҮӘе·ұе–ңж¬ўзҡ„жЁЎжқҝпјҢзӮ№еҮ»иҝӣе…ҘпјҢеҰӮеӣҫпјҡ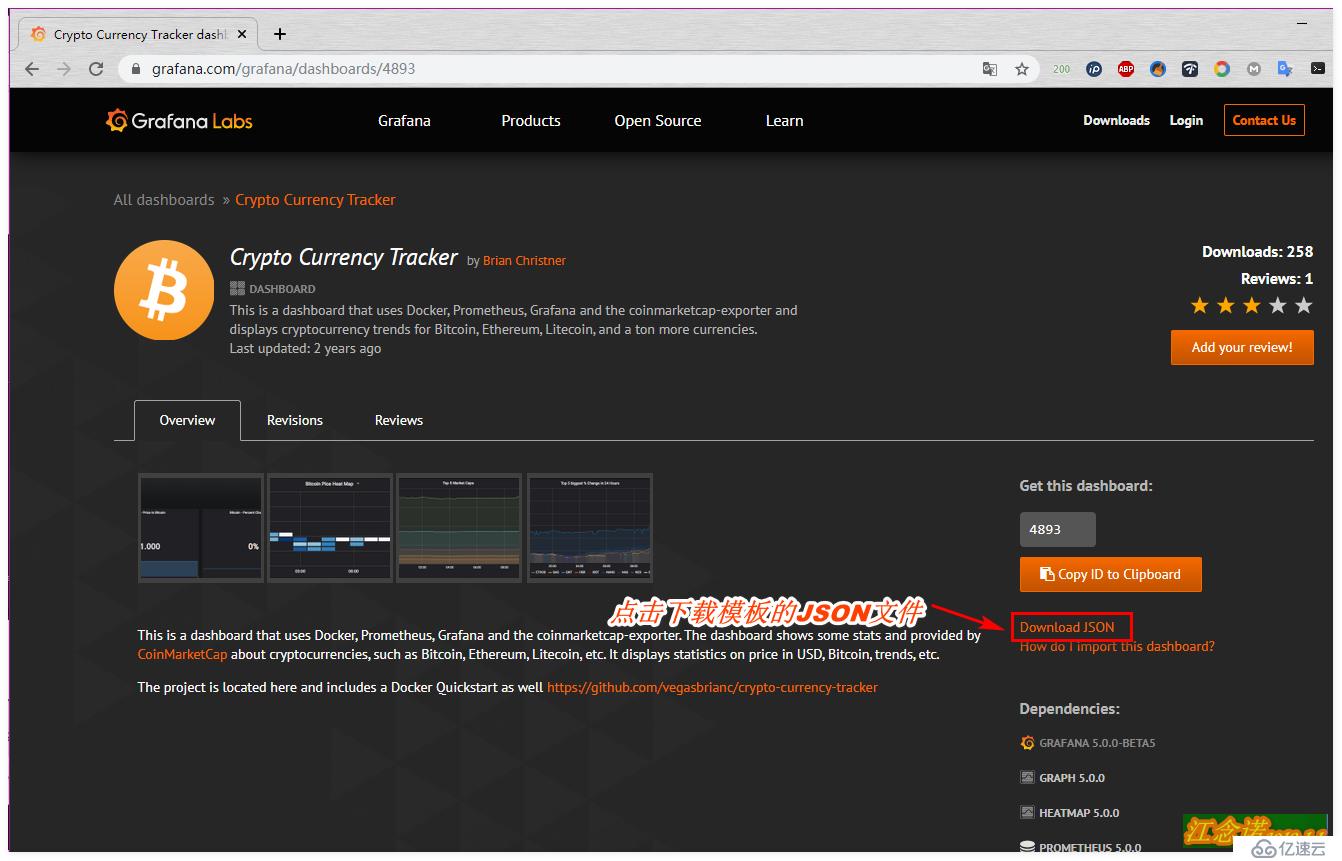
дёӢиҪҪеҗҺпјҢеӣһеҲ°иҮӘе·ұжҗӯе»әзҡ„grafanaе®№еҷЁжҸҗдҫӣзҡ„webйЎөйқўдёӯпјҢеҰӮеӣҫпјҡ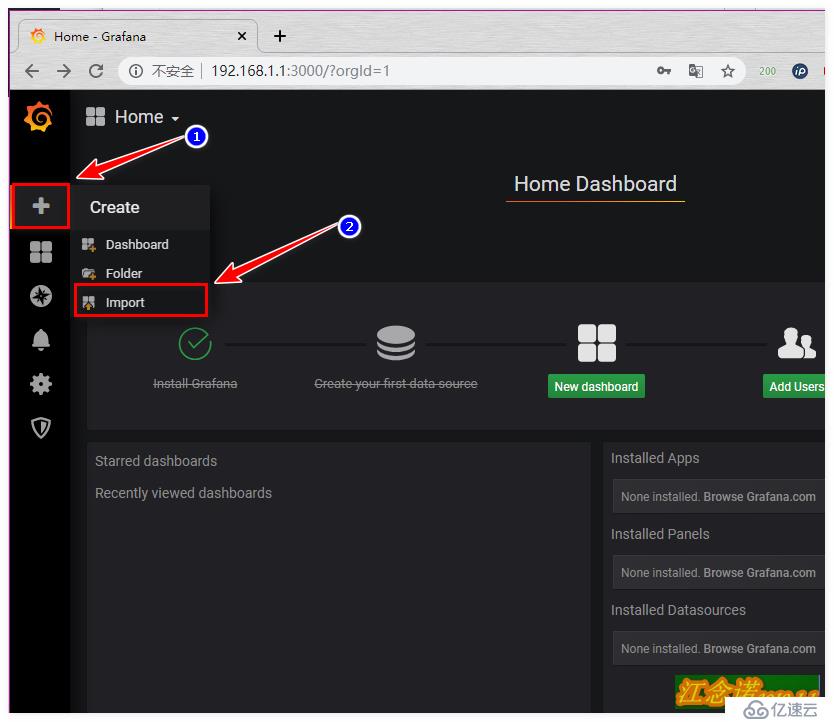
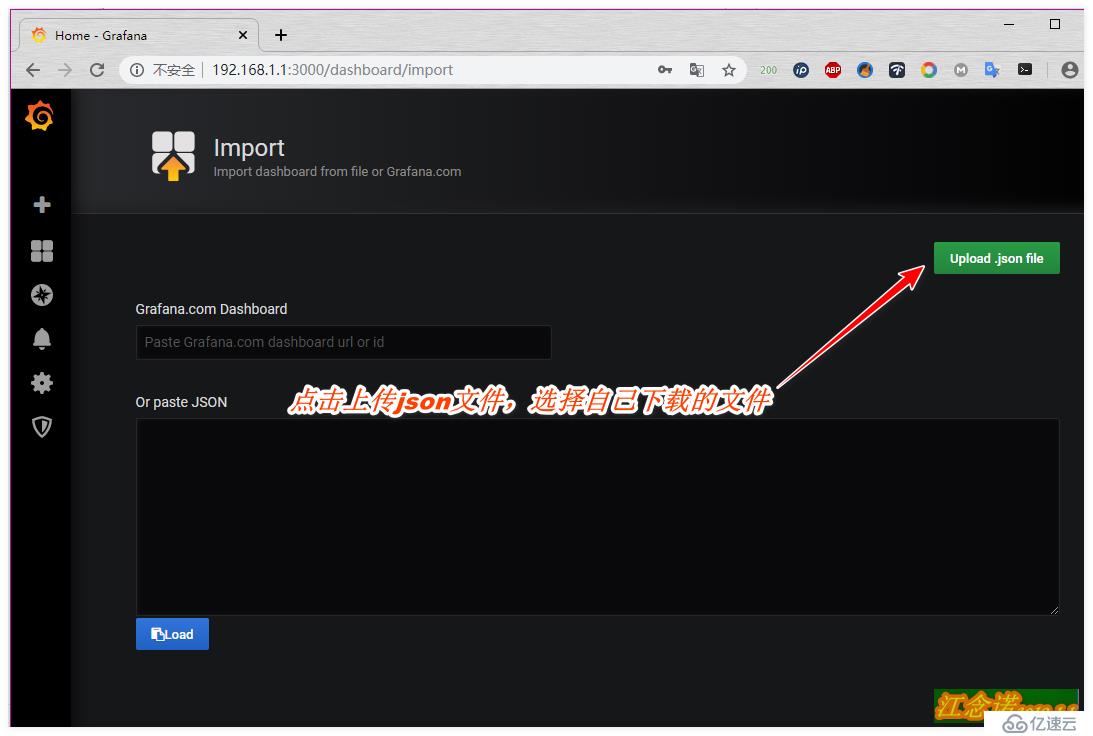
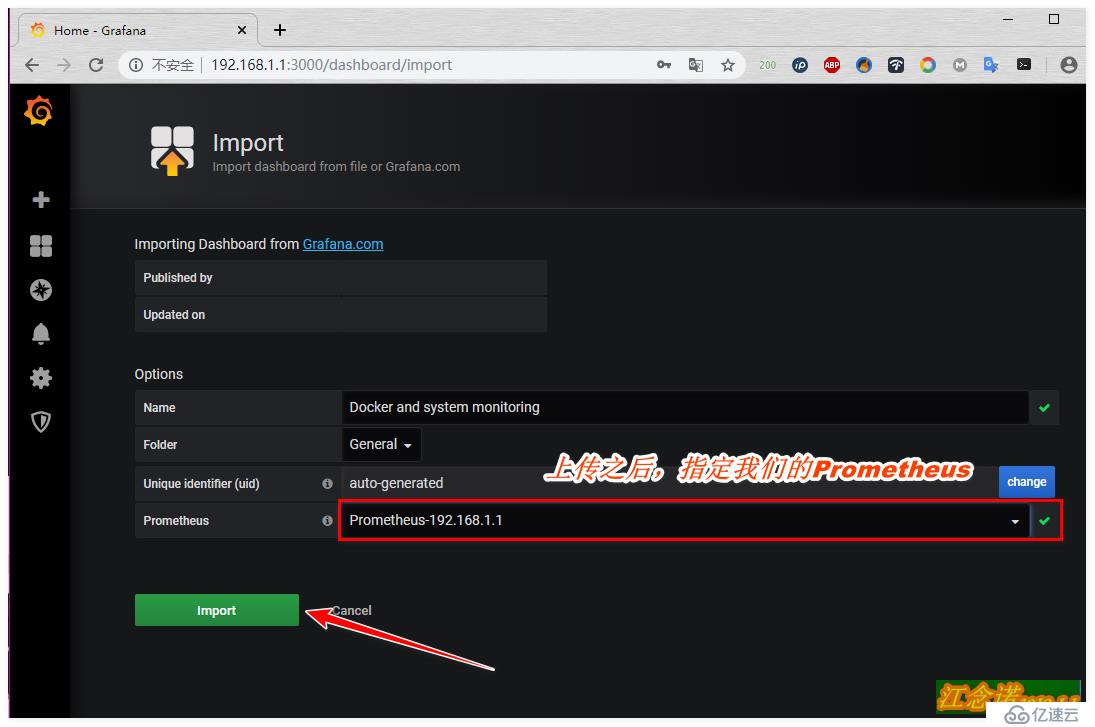
дҪҶжҳҜд»”з»ҶзңӢзҡ„иҜқпјҢдјҡеҸ‘зҺ°иҝҷдёӘжЁЎжқҝжңүдәӣдҝЎжҒҜйғҪжЈҖжөӢдёҚеҲ°пјҢжүҖд»ҘиҝҷйҮҢе°ұжҳҜдёәдәҶеұ•зӨәдёҖз§Қж–№ејҸеҜје…ҘжЁЎжқҝзҡ„ж–№ејҸгҖӮдёӘдәәе»әи®®жҺЁиҚҗдҪҝ用第дәҢз§Қж–№ејҸпјҒ
йҖүжӢ©еҗҲйҖӮзҡ„жЁЎжқҝеҗҺпјҢи®°еҪ•е…¶IDеҸ·пјҢеҰӮеӣҫпјҡ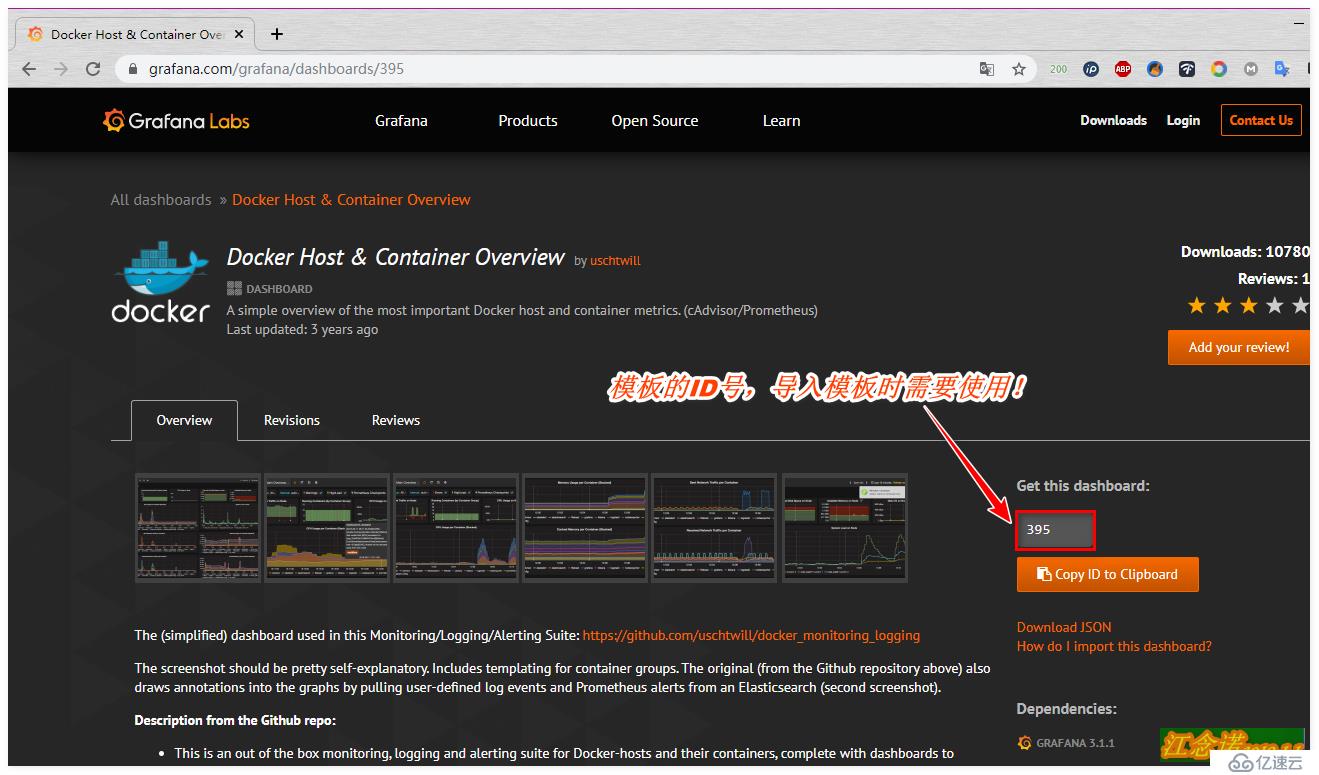
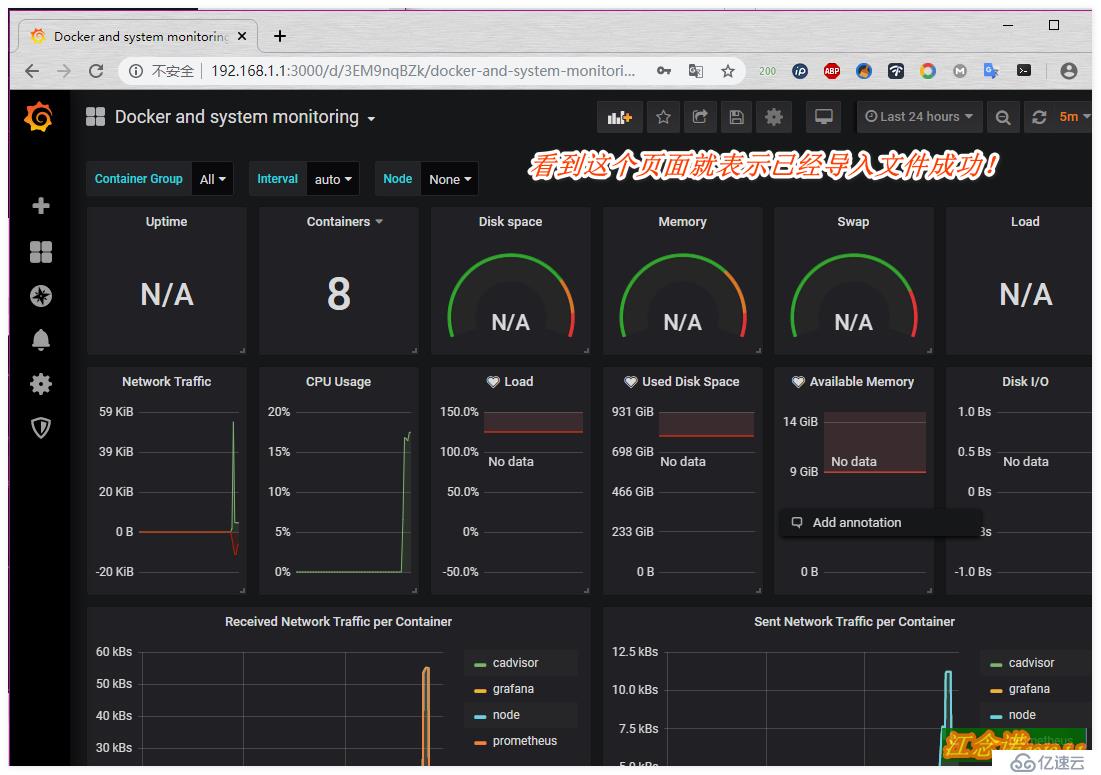
и®°еҪ•дёӢжЁЎжқҝзҡ„IDеҸ·д№ӢеҗҺпјҢеҗҢж ·еӣһеҲ°иҮӘе·ұжҗӯе»әзҡ„grafanaе®№еҷЁжҸҗдҫӣзҡ„webйЎөйқўдёӯпјҢеҰӮеӣҫпјҡ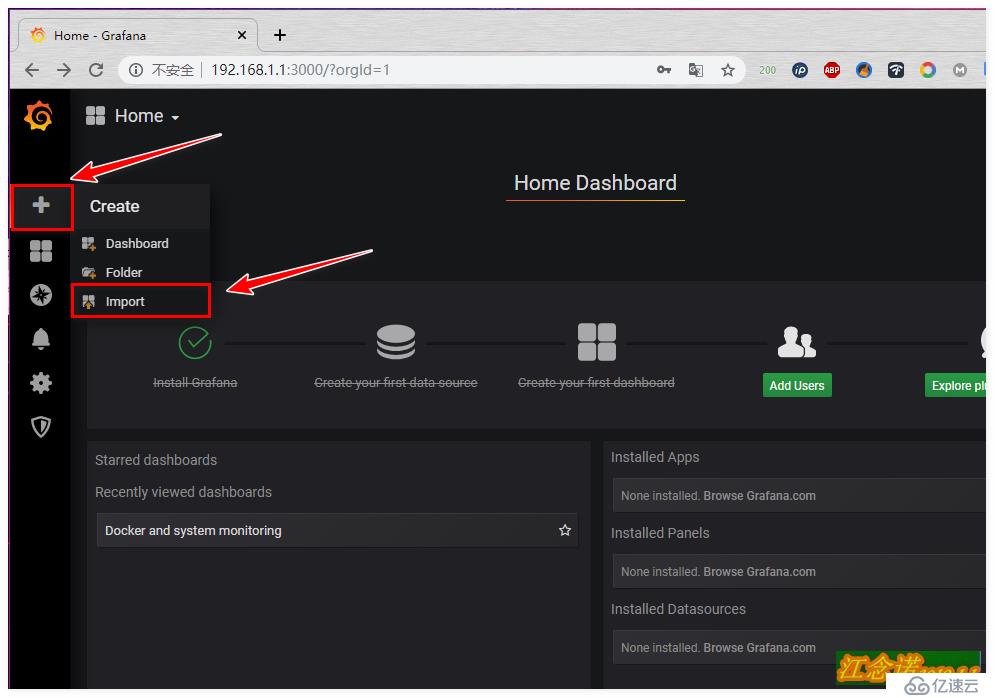
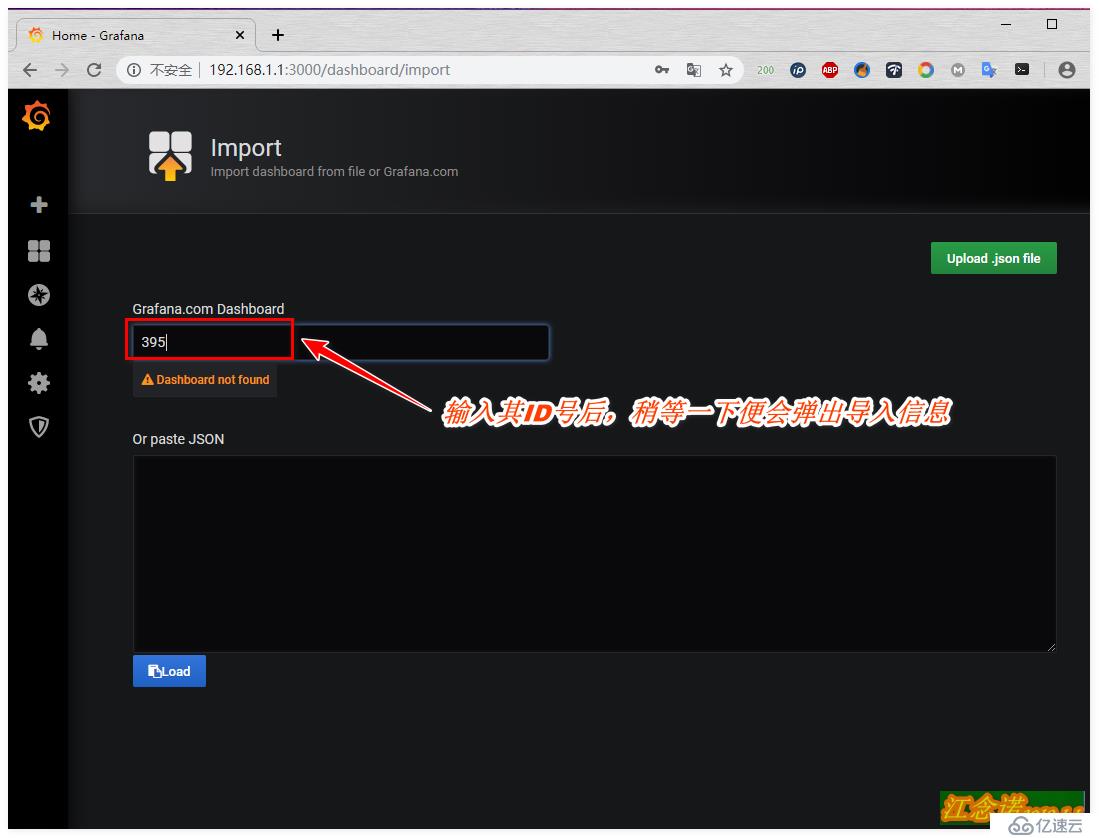
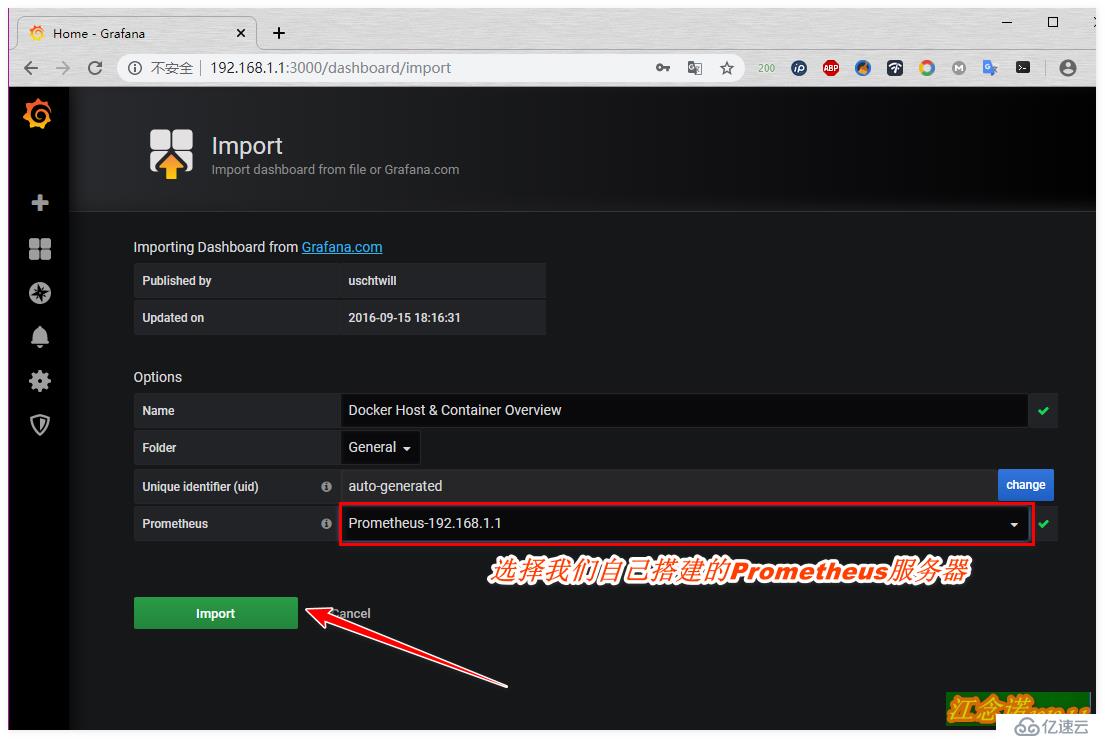
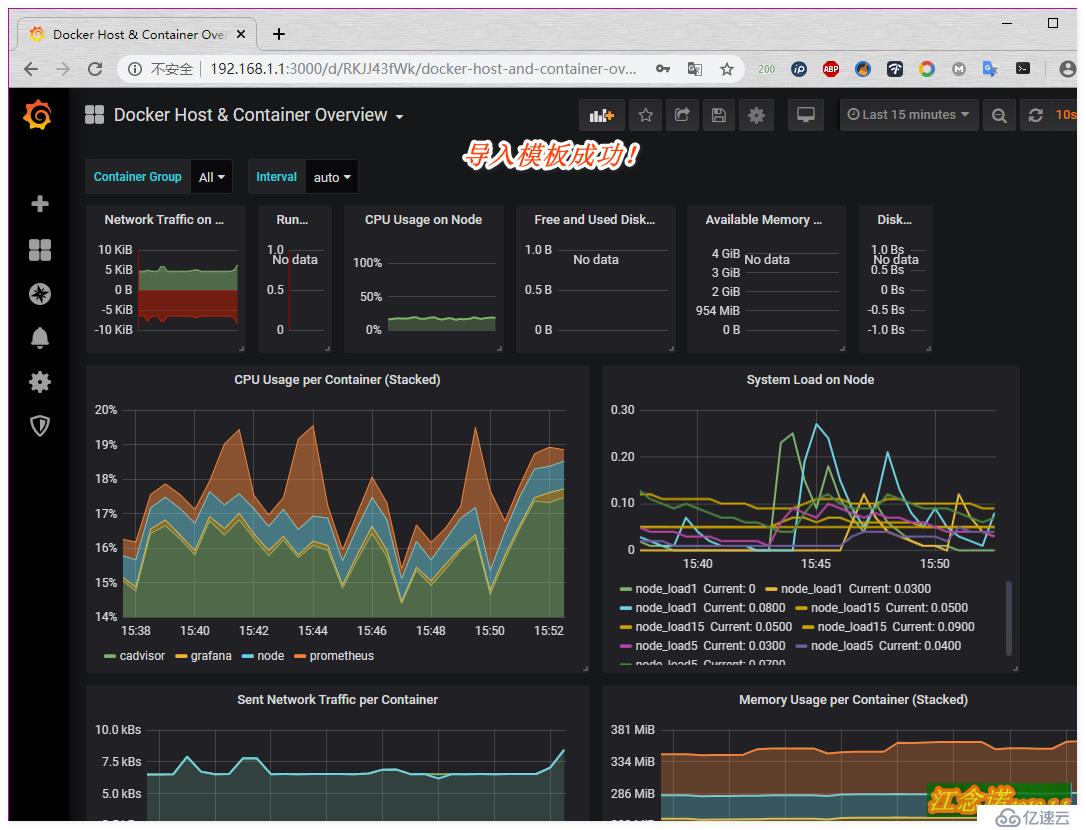
иҮіжӯӨwebз•Ңйқўзҡ„зӣ‘жҺ§е°ұйғЁзҪІе®ҢжҲҗдәҶпјҒ
Prometheusзҡ„жҠҘиӯҰж–№ејҸжңүеҘҪеҮ з§ҚпјҢжҜ”еҰӮпјҡйӮ®з®ұгҖҒеҫ®дҝЎгҖҒй’үй’үзӯүпјҢжң¬ж¬ЎжЎҲдҫӢйҮҮз”ЁйӮ®з®ұе‘ҠиӯҰзҡ„ж–№ејҸгҖӮ
Alertmanager组件主иҰҒжҳҜз”ЁжқҘжҺҘ收PrometheusеҸ‘йҖҒзҡ„жҠҘиӯҰдҝЎжҒҜпјҢ并且жү§иЎҢи®ҫзҪ®еҘҪзҡ„жҠҘиӯҰж–№ејҸпјҢжҠҘиӯҰеҶ…е®№пјӣ
еҸӘйңҖеңЁdockerAдё»жңәдёҠйғЁзҪІеҚіеҸҜпјҒж–№жі•еҰӮдёӢпјҡ
[root@dockerA ~]# docker run -d --name alertmanager -p 9093:9093 prom/alertmanager
//йҡҸдҫҝиҝҗиЎҢдёҖдёӘе®№еҷЁпјҢе…¶зӣ®зҡ„е°ұжҳҜе°Ҷе®№еҷЁдёӯжңҚеҠЎзҡ„й…ҚзҪ®ж–Ү件жӢҝеҲ°жң¬ең°
[root@dockerA ~]# docker cp alertmanager:/etc/alertmanager/alertmanager.yml .
//е°ҶaltermanagerжңҚеҠЎзҡ„ymlй…ҚзҪ®ж–Ү件жӢҝеҲ°жң¬ең°
[root@dockerA ~]# vim alertmanager.yml //зј–иҫ‘й…ҚзҪ®ж–Ү件
global:
resolve_timeout: 5m
smtp_from: '1454295320@qq.com' #еҸ‘йҖҒиҖ…дҝЎжҒҜ
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1454295320@qq.com' #жҺҘ收иҖ…дҝЎжҒҜ
smtp_auth_password: 'gfuxsudyqyulbaad' #дҪҝз”ЁqqйӮ®з®ұз”ҹжҲҗзҡ„жҺҲжқғз Ғ
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname'] #йҮҮз”Ёй»ҳи®Өз»„
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '1454295320@qq.com' //еҸ‘йҖҒиҖ…дҝЎжҒҜ
send_resolved: true //еҪ“е®№еҷЁжҒўеӨҚжӯЈеёёж—¶пјҢд№ҹдјҡеҸ‘йҖҒдёҖд»ҪйӮ®д»¶
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
//й…ҚзҪ®ж–Ү件дёӯеёёз”ЁйңҖиҰҒдҝ®ж”№зҡ„ең°ж–№е·Із»ҸеҒҡдәҶеӨҮжіЁalertmanager.ymlй…ҚзҪ®ж–Ү件дёӯдёҖзә§еӯ—ж®өпјҡ
- globalпјҡе…ЁеұҖй…ҚзҪ®пјҲеҢ…жӢ¬жҠҘиӯҰи§ЈеҶізҡ„и¶…ж—¶ж—¶й—ҙгҖҒSMTPзӣёе…ій…ҚзҪ®гҖҒеҗ„з§Қжё йҒ“йҖҡзҹҘзҡ„APIең°еқҖзӯүж–°ж¶ҲжҒҜпјүпјӣ
- routeпјҡз”ЁжқҘи®ҫзҪ®жҠҘиӯҰзҡ„еҲҶеҸ‘зӯ–з•Ҙпјӣ
- receiversпјҡй…ҚзҪ®е‘ҠиӯҰж¶ҲжҒҜжҺҘ收иҖ…дҝЎжҒҜпјӣ
- inhibit_rulesпјҡжҠ‘еҲ¶и§„еҲҷй…ҚзҪ®пјҢеҪ“еӯҳеңЁдёҺеҸҰдёҖз»„еҢ№й…Қзҡ„иӯҰжҠҘж—¶пјҢжҠ‘еҲ¶и§„еҲҷе°Ҷд»…з”ЁдәҺдёҖз»„еҢ№й…Қзҡ„пјӣ
[root@dockerA ~]# docker rm -f alertmanager //е°ҶеҺҹжң¬зҡ„alertmanager е®№еҷЁеҲ йҷӨ
[root@dockerA ~]# docker run -d --name alertmanager -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml prom/alertmanager
//йҮҚж–°иҝҗиЎҢalertmanager е®№еҷЁпјҢ并е°Ҷй…ҚзҪ®ж–Ү件жҢӮиҪҪеҲ°е®№еҷЁдёӯ
//е»әи®®иҝҗиЎҢе®№еҷЁд№ӢеҗҺпјҢдҪҝз”Ёdocker ps | grep alertmanager зЎ®дҝқе®№еҷЁжӯЈеёёиҝҗиЎҢ
//еҰӮжһңй…ҚзҪ®ж–Ү件编еҶҷй”ҷиҜҜпјҢйӮЈд№ҲиҝҷдёӘе®№еҷЁжҳҜж— жі•еҗҜеҠЁзҡ„[root@dockerA ~]# mkdir -p prometheus/rules && cd prometheus/rules
//еҲӣе»әзӣ®еҪ•з”ЁдәҺеӯҳж”ҫ规еҲҷзҡ„зӣ®еҪ•
[root@dockerA rules]# vim node-up.rules //зј–еҶҷ规еҲҷ
groups:
- name: node-up //иҮӘе®ҡд№үеҗҚз§°
rules:
- alert: node-up
expr: up{job="prometheus"} == 0
// jobзҡ„еҗҚз§°еҝ…йЎ»е’Ңprometheusй…ҚзҪ®ж–Ү件дёӯзҡ„ - job_name: 'prometheus'еҜ№еә”
for: 15s
labels:
severity: 1
team: node
annotations:
summary: "{{ $labels.instance }} е·ІеҒңжӯўиҝҗиЎҢи¶…иҝҮ 15sпјҒ"еҸҜд»Ҙж №жҚ®д»ҘдёҠй…ҚзҪ®ж–Ү件иҝӣиЎҢдҝ®ж”№пјҢиӢҘжғіиҮӘе·ұзј–еҶҷжҠҘиӯҰ规еҲҷпјҢеҸҜд»ҘеҸӮиҖғе®ғзҡ„е®ҳж–№ж–ҮжЎЈпјҢеҰӮеӣҫпјҡ
[root@dockerA ~]# vim prometheus.yml
8 alerting:
9 alertmanagers:
10 - static_configs:
11 - targets:
12 - 192.168.1.1:9093 //жӯӨиЎҢе°ҶеҺҹжң¬зҡ„еҶ…е®№жӣҙж”№дёәalertmanagerе®№еҷЁзҡ„IP+з«ҜеҸЈ
13
14 # Load rules once and periodically evaluate them according to the global 'evaluat ion_interval'.
15 rule_files:
16 - "/usr/local/prometheus/rules/*.rules" //иҝҷдёҖиЎҢйңҖиҰҒжүӢеҠЁж·»еҠ пјҢжҢҮе®ҡе®№еҷЁеҶ…зҡ„и·Ҝеҫ„
[root@dockerA ~]# docker rm -f prometheus //дҝ®ж”№е®Ңй…ҚзҪ®дёәж–Ү件еҗҺпјҢйңҖиҰҒе°Ҷе®№еҷЁеҲ йҷӨпјҢйҮҚж–°иҝҗиЎҢдёҖеҸ°ж–°зҡ„е®№еҷЁ
[root@dockerA ~]# docker run -d -p 9090:9090 --name prometheus --net=host -v /root/prometheus.yml:/etc/prometheus/prometheus.yml -v /root/prometheus/rules/node-up.rules:/usr/local/prometheus/rules/node-up.rules prom/prometheus
//жҢҮе®ҡжӯҘйӘӨпјҲ2пјүзј–еҶҷзҡ„ruleж–Ү件зҡ„и·Ҝеҫ„пјҢдёәйҳІжӯўж јејҸеҸҜиғҪдјҡеҮәзҺ°й”ҷиҜҜпјҢйҷ„дёҠжҲӘеӣҫдёҖеј пјҢеҰӮдёӢпјҡ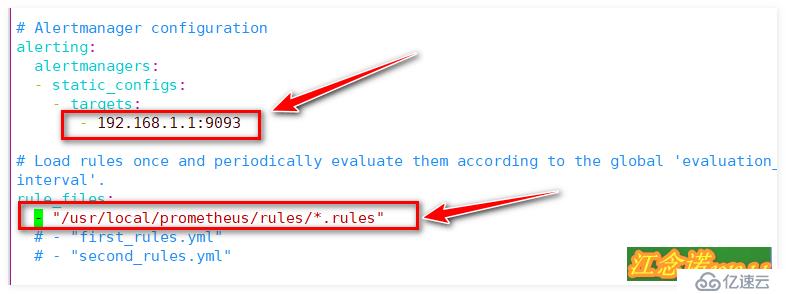
иҮіжӯӨпјҢеҰӮжһңprometheusйЎөйқўдёӯзҡ„targetжңүејӮеёёпјҲжҜ”еҰӮе®•жңәпјүпјҢйӮЈд№Ҳе°ұдјҡз»ҷдҪ зҡ„йӮ®з®ұеҸ‘йҖҒжҠҘиӯҰдҝЎжҒҜгҖӮ
жҲ‘жүӢеҠЁеҒңжҺүе®№еҷЁпјҢ收еҲ°зҡ„йӮ®д»¶еҰӮдёӢпјҡ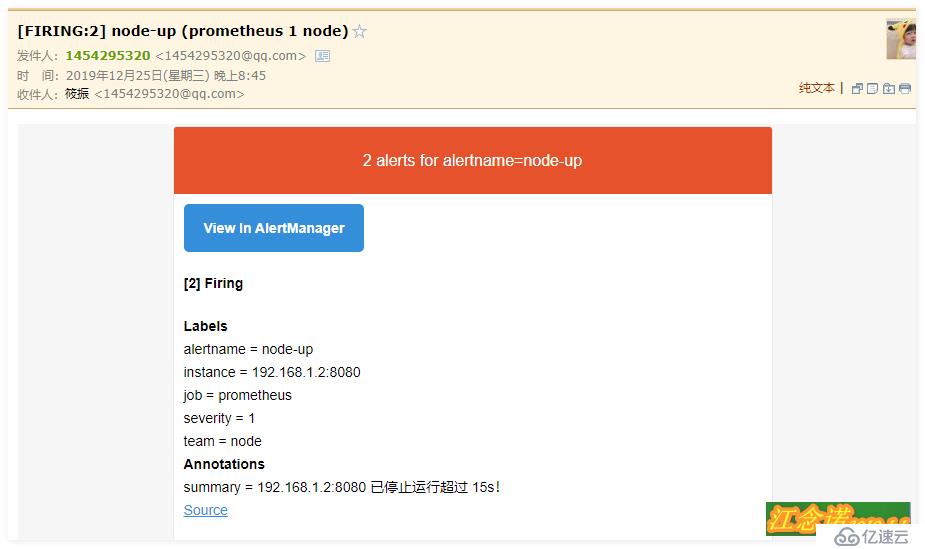
дёәдәҶиҝҪжұӮзҫҺи§ӮпјҢжҲ‘们йҮҮеҸ–и®ҫзҪ®дёҖдёӢжҠҘиӯҰдҝЎжҒҜзҡ„жЁЎжқҝпјҒ
[root@dockerA ~]# cd prometheus
[root@dockerA prometheus]# mkdir alertmanager-tmpl
[root@dockerA prometheus]# cd alertmanager-tmpl/
[root@dockerA prometheus]# vim email.tmpl
{{ define "email.from" }}1454295320@qq.com{{ end }}
{{ define "email.to" }}1454295320@qq.com{{ end }}
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
е‘ҠиӯҰзЁӢеәҸ: prometheus_alert<br>
е‘ҠиӯҰзә§еҲ«: {{ .Labels.severity }} зә§<br>
е‘ҠиӯҰзұ»еһӢ: {{ .Labels.alertname }}<br>
ж•…йҡңдё»жңә: {{ .Labels.instance }}<br>
е‘ҠиӯҰдё»йўҳ: {{ .Annotations.summary }}<br>
и§ҰеҸ‘ж—¶й—ҙ: {{ .StartsAt.Format "2019-08-04 16:58:15" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
[root@dockerA ~]# vim alertmanager.yml
global:
resolve_timeout: 5m
smtp_from: '1454295320@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '1454295320@qq.com'
smtp_auth_password: 'flnuwdktcbzwffag'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates: //ж·»еҠ жӯӨиЎҢ
- '/etc/alertmanager-tmpl/*.tmpl' //жҢҮе®ҡе®№еҷЁдёӯжЁЎжқҝзҡ„и·Ҝеҫ„
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '{{ template "email.to" }}' //еҝ…йЎ»е’ҢжЁЎжқҝдёӯеҜ№еә”
html: '{{ template "email.to.html" . }}' //еҝ…йЎ»е’ҢжЁЎжқҝдёӯеҜ№еә”
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
[root@dockerA ~]# docker rm alertmanager -f
//еҲ йҷӨе®№еҷЁ
[root@dockerA ~]# docker run -d --name alertmanager -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /root/prometheus/alertmanager-tmpl:/etc/alertmanager-tmpl prom/alertmanager
//еҲӣе»әе®№еҷЁжң¬ең°еҲӣе»әзҡ„жЁЎжқҝж–Ү件
//еҲӣе»әе®ҢжҲҗеҗҺпјҢзЎ®е®ҡе®№еҷЁжҳҜжӯЈеёёиҝҗиЎҢиҮіжӯӨпјҢж–°зҡ„жҠҘиӯҰжЁЎжқҝд№ҹз”ҹжҲҗдәҶпјҢеҰӮжһңд»ҘдёӢе®№еҷЁжңүDownзҡ„пјҢе°ұдјҡз»ҷдҪ еҸ‘йҖҒж–°зҡ„йӮ®д»¶пјҢжҒўеӨҚжӯЈеёёеҗҺпјҢд№ҹдјҡеҸ‘йҖҒйӮ®д»¶пјҢеҗҢж ·пјҢйӮ®д»¶дёӯзҡ„еҶ…е®№ж јејҸжҳҜжңүиҜҜзҡ„пјҢдҪҶжҳҜдҪ еҸҜд»ҘжӯЈеёёжҺҘ收еҲ°жҠҘиӯҰдҝЎжҒҜпјҢиӢҘжғіиҰҒжӣҙж”№е…¶жҠҘиӯҰжЁЎжқҝпјҢеҸҜд»ҘеҸӮиҖғе®ҳж–№ж–ҮжЎЈ
йӮ®з®ұ收еҲ°зҡ„жҠҘиӯҰдҝЎжҒҜеҰӮдёӢпјҡ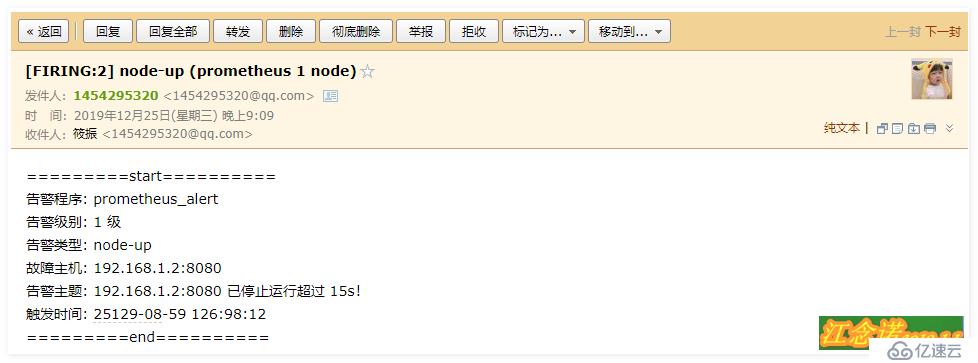
жҜ”еҺҹжң¬зҡ„ж•ҲжһңиҰҒеҘҪеҫҲеӨҡпјҒе°ұз®ҖеҚ•д»Ӣз»ҚдёҖдёӢиҝҷдёҖдёӘеҗ§пјҢжңүе…ҙи¶ЈеҸҜд»ҘеҸӮиҖғе®ҳзҪ‘зҡ„ж–ҮжЎЈпјҢиҮӘиЎҢиҝӣиЎҢзј–еҶҷпјҒ
вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”жң¬ж–ҮеҲ°жӯӨз»“жқҹпјҢж„ҹи°ўйҳ…иҜ»вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”вҖ”
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ