您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
博文大纲:
- 一、部署Weave-Scope
- 二、开始配置
- 1、运行Node Server容器
- 2、运行cAdvisor容器
- 3、docker01上运行Prometheus server容器
- 4、docker01上运行grafana容器
- 5、设置Prometheus告警
Prometheus是一个系统和服务监视系统。它以给定的时间间隔从已配置的目标收集指标,评估规则表达式,显示结果,并在发现某些情况为真时触发警报。
与其他监视系统相比,Prometheus的主要区别特征是:
- 一个多维数据模型(时间序列由指标名称定义和设置键/值尺寸)
- 一个灵活的查询语言来利用这一维度
- 不依赖于分布式存储;单服务器节点是自治的
- 时间序列收集通过HTTP 上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持模式
- 支持分层和水平联合
其官方给出的架构示意图如下:

部署该服务,包括四个组件:Prometheus Server、Node Exporter、cAdvrisor、Grafana。
各个组件的作用如下:
- Prometheus Server:Prometheus服务的主服务器 ;
- Node Exporter:收集Host硬件和操作系统的信息;
- cAdvrisor:负责收集Host上运行的容器信息;
- Grafana:用来展示Prometheus监控操作界面(给我们提供一个友好的web界面)。
以上四个组件的所有介绍,还请移步到Github官网,直接搜索相应的docker镜像名称(在下面的部署过程中,每运行一个服务的容器,都会指定其镜像名称,可以参考命令中的镜像名称进行搜索),即可找到到关于组件的详细介绍,这里就不多介绍了。
我这里的环境如下:
该组件需要运行在所有需要监控的主机上,也就是,我这里三台服务器都需要执行下面的命令,运行此容器组件。
[root@docker01 ~]# docker run -d -p 9100:9100 -v /proc:/host/proc -v /sys:/host/sys -v /:/rootfs --net=host --restart=always prom/node-exporter --path.procfs /host/proc --path.sysfs /host/sys --collector.filesystem.ignored-mount-points "^/(sys|proc|dev|host|etc)($|/)"
#基于“prom/node-exporter”镜像运行容器,可以去github官网搜索该镜像,以便了解其主要功能
#注:每台需要被监控的主机都需要执行上述命令以便运行容器,以便收集主机信息每台服务器运行上述命令后,浏览器访问docker服务器的IP地址+9100端口,能够看到以下界面,即说明容器运行没有问题。这些内容看不懂没关系,这些信息本来就不是给我们看的,我们看的是最后给我们提供的web界面。看到的网页如下:
最好访问一下所有运行上述容器的服务器的9100端口,确保可以看到上面的页面。
cAdvrisor是负责收集Host上运行的容器信息的,同样,在所有需要监控的服务器上执行下面的命令运行cAdvisor容器即可:
[root@docker01 ~]# docker run -v /:/rootfs:ro -v /var/run:/var/run:rw -v /sys:/sys:ro -v /var/lib/docker:/var/lib/docker:ro -p 8080:8080 --detach=true --name=cadvisor --net=host google/cadvisor每台服务器运行上述命令后,浏览器访问服务器的IP地址+8080端口,即可看到如下页面:

同样,最好访问每一台服务器的8080端口,以便确认成功。
Prometheus Server是主服务器,所以只需要在其中一台运行此容器即可。这里我在docker01服务器上运行:
[root@docker01 ~]# docker run -d -p 9090:9090 --name prometheus --net=host prom/prometheus
#先基于prom/prometheus镜像随便运行一个容器,我们需要将其主配置文件复制一份进行更改
[root@docker01 ~]# docker cp prometheus:/etc/prometheus/prometheus.yml /root/
#复制prometheus容器中的主配置文件到宿主机本地
[root@docker01 ~]# docker rm -f prometheus #删除刚刚随便创建的容器即可
[root@docker01 ~]# vim prometheus.yml #打开复制出来的配置文件,直接跳转到配置文件的最后一行
.......................#省略部分内容
#修改如下:
- targets: ['localhost:9090','localhost:8080','localhost:9100','192.168.20.7:9100','192.168.20.7:8080','192.168.20.8:9100','192.168.20.8:8080']
#上述内容看似杂乱无章,其实无非就是指定了本机的9090、8080、9100这三个端口,
#还增加了另外两台被监控的服务器的8080端口和9100端口
#若需要监控更多的服务器,只需依次在上面指定添加即可,当然了,被监控端需要运行前面的两个容器
#修改完成后,保存退出即可
[root@docker01 ~]# docker run -d -p 9090:9090 -v /root/prometheus.yml:/etc/prometheus/prometheus.yml --name prometheus --net=host prom/prometheus
#执行上述命令,运行新的prometheus容器,并将刚刚修改的主配置文件挂载到容器中的指定位置
#以后若要修改主配置文件,则直接修改本地的即可。
#挂载主配置文件后,本地的和容器内的相当于同一份,在本地修改内容的话,会同步到容器中客户端访问docker01的9090端口,会看到以下页面:
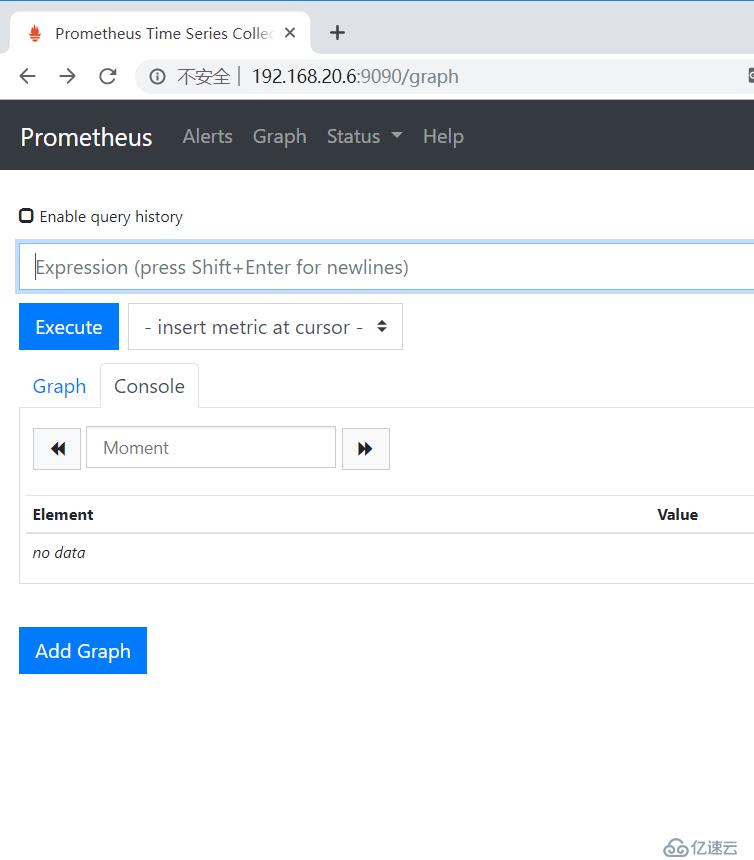
然后单击上方的“status”,然后点击“Targets”,如下图所示: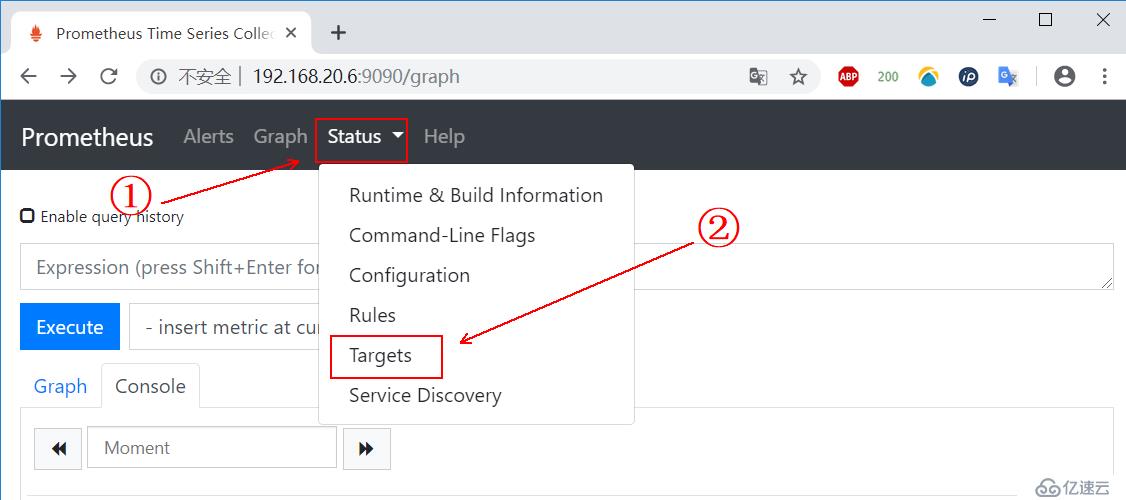
看到下面的页面,则表示至此的所有操作都没有问题:

此容器是为我们提供一个友好的web展示页面。
[root@docker01 ~]# mkdir grafana-storage
[root@docker01 ~]# chmod 777 -R grafana-storage/
[root@docker01 ~]# docker run -d -p 3000:3000 --name grafana -v /root/grafana-storage:/var/lib/grafana -e "GF_SECURITY_ADMIN_PASSWORD=123.com" grafana/grafana
#上述命令中的“-e”选项是为了设置默认的登录用户admin,密码为“123.com”。
#如果启动容器的过程中,提示iptables等相关的错误信息,
#则需要执行命令systemctl restart docker,重启docker服务,然后重新运行容器
#但是需要注意,若运行容器时没有增加“--restart=always”选项的话,
#那么在重启docker服务后,还需将所有容器手动重启。
#重启所有容器命令“docker ps -a -q | xargs docker start”容器运行后,即可使用客户端访问docker01IP地址+3000端口,可以看到以下页面:

在上面的登录页面,输入用户名“admin”,密码就是我们运行时指定的密码,我这里是“123.com”。输入后登录,会看到以下界面,然后单击添加数据源: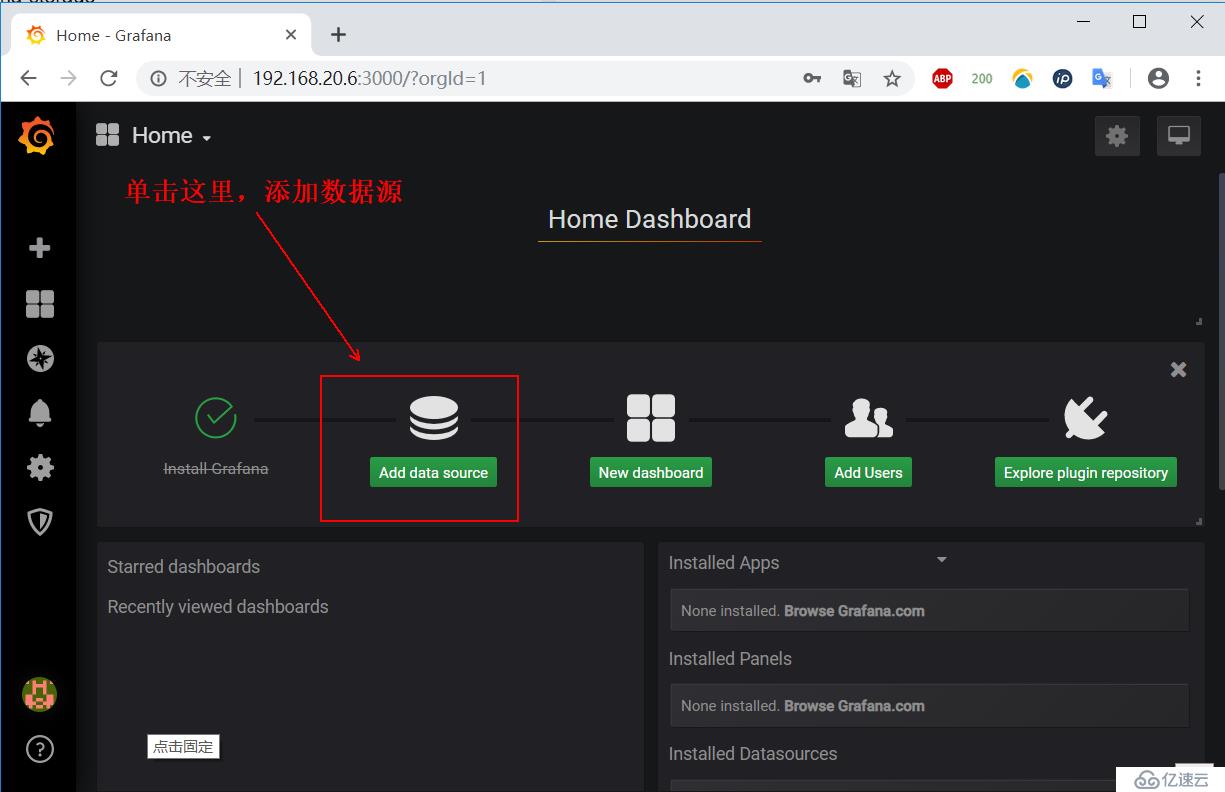
看到下面的界面,找到Prometheus,并点击“select”选择它:

根据下图给的提示进行修改配置:
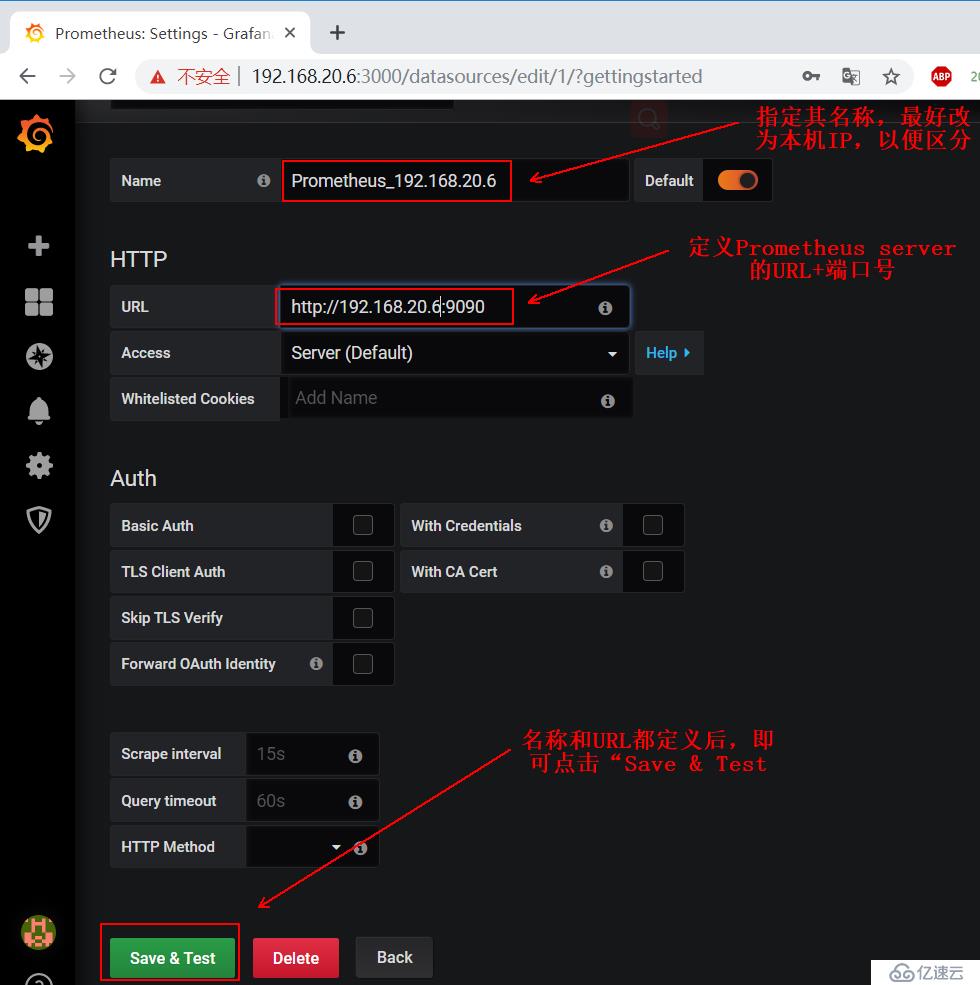
上述配置完成后,我们就需要配置它以什么样的形式来给我们展示了,可以自定义,但是很麻烦,我选择直接去grafana官网寻找现成的模板。
登录grafana官网,点击下面的选项:
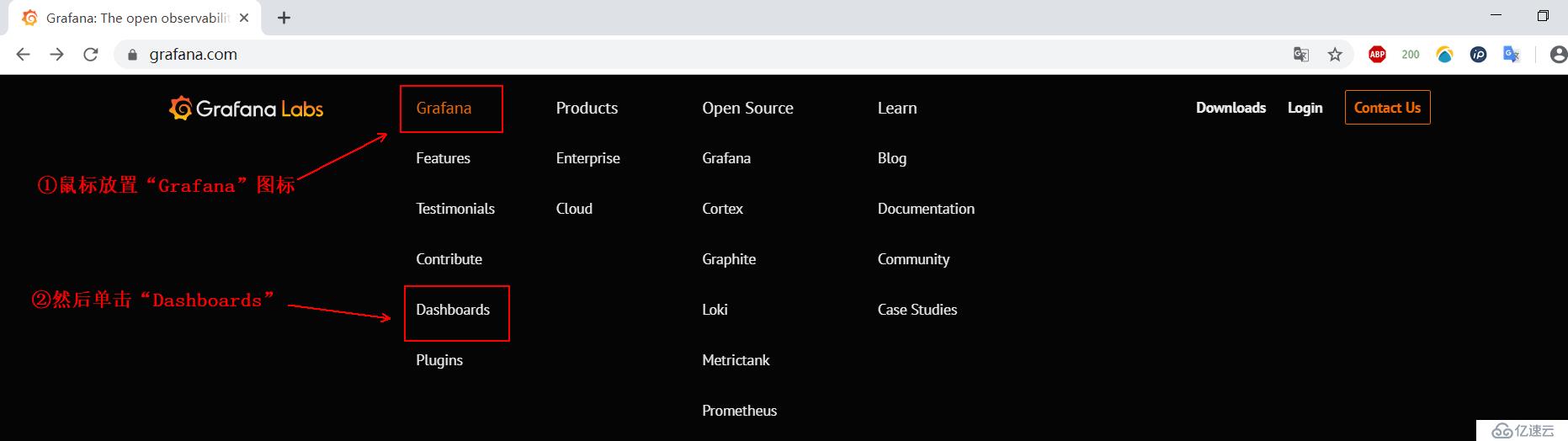
看图操作:
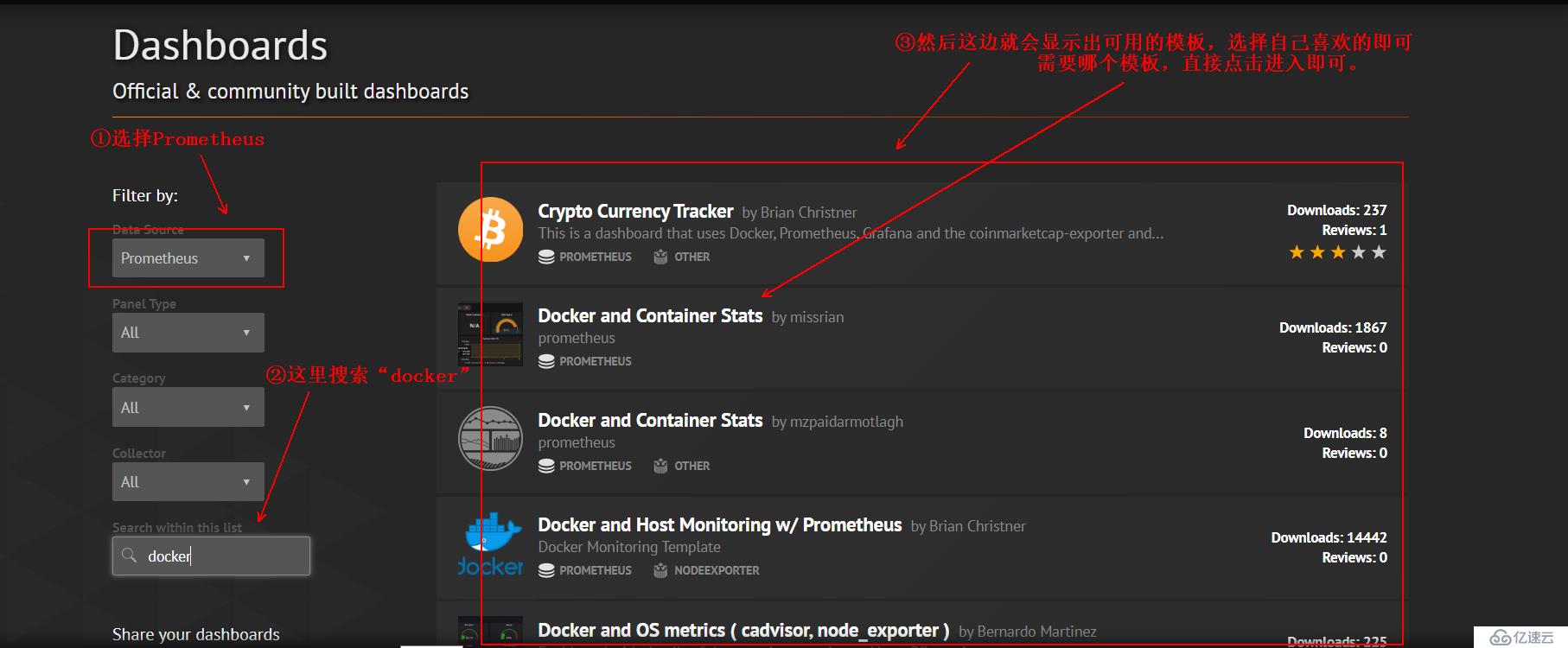
将这些模板导入到我们grafana的web界面有两种方式:
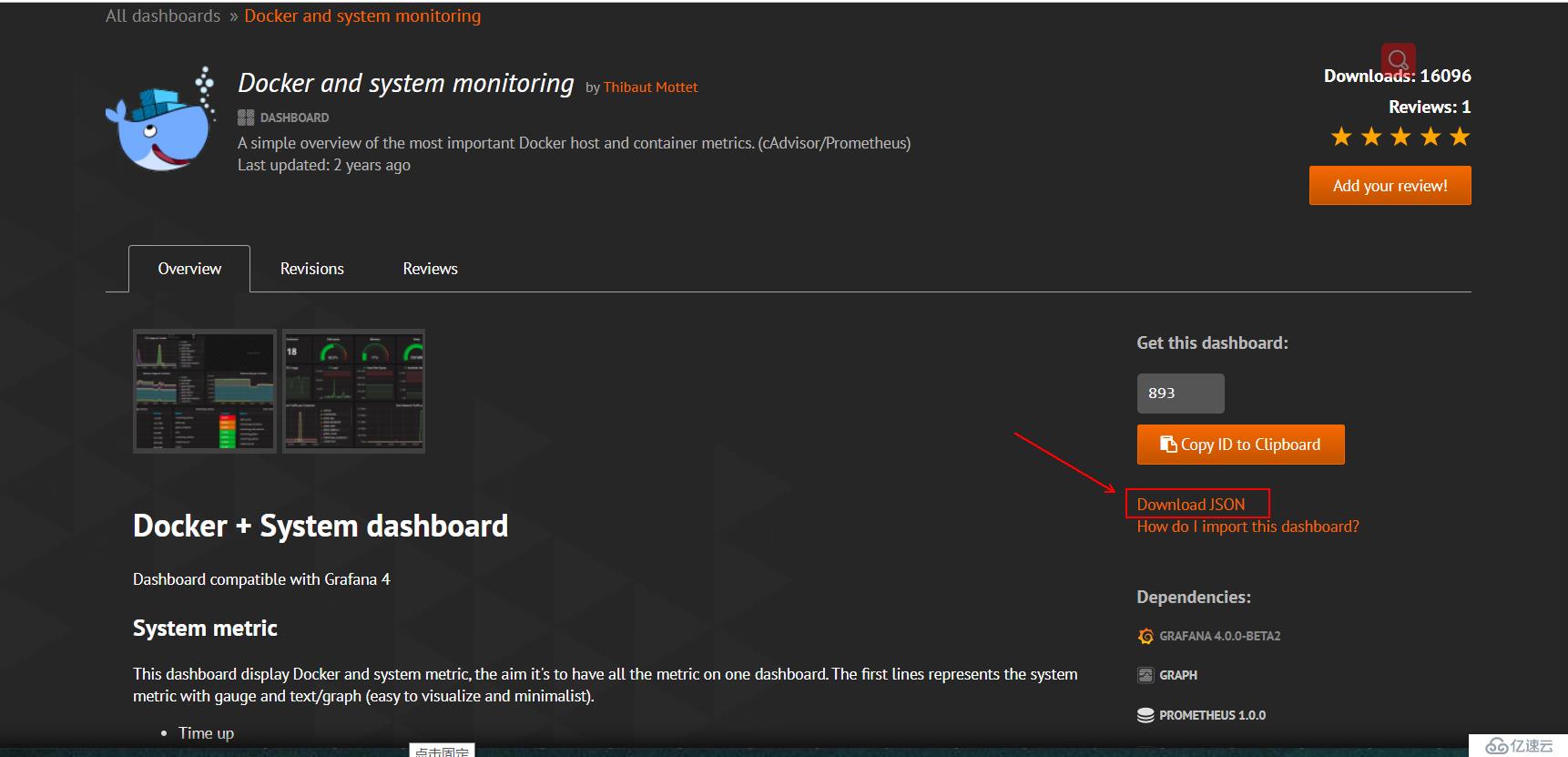
1)进入模板后,点击“Download JSON”,以便下载:
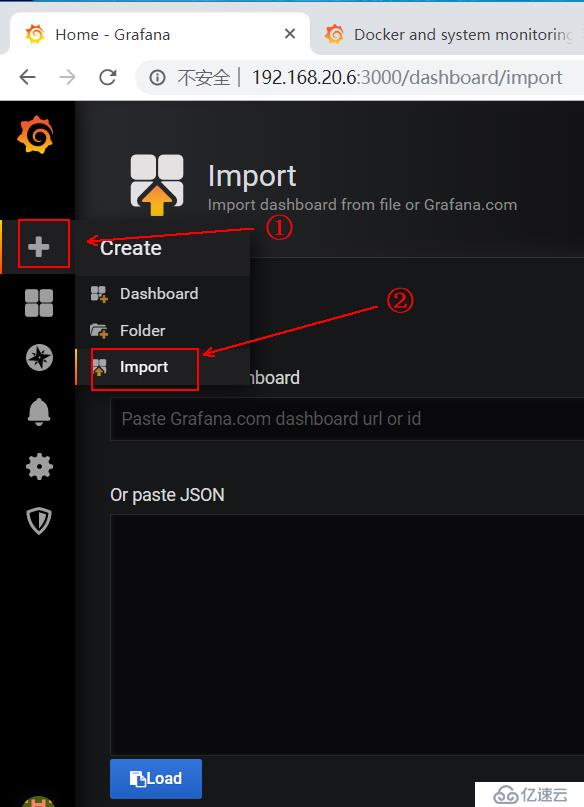
2)下载后,回到grafana界面,点击如下:
3)单击“Upload.json file”,然后上传我们在grafana官网下载的模板:
4)上传后,请看下图进行操作:
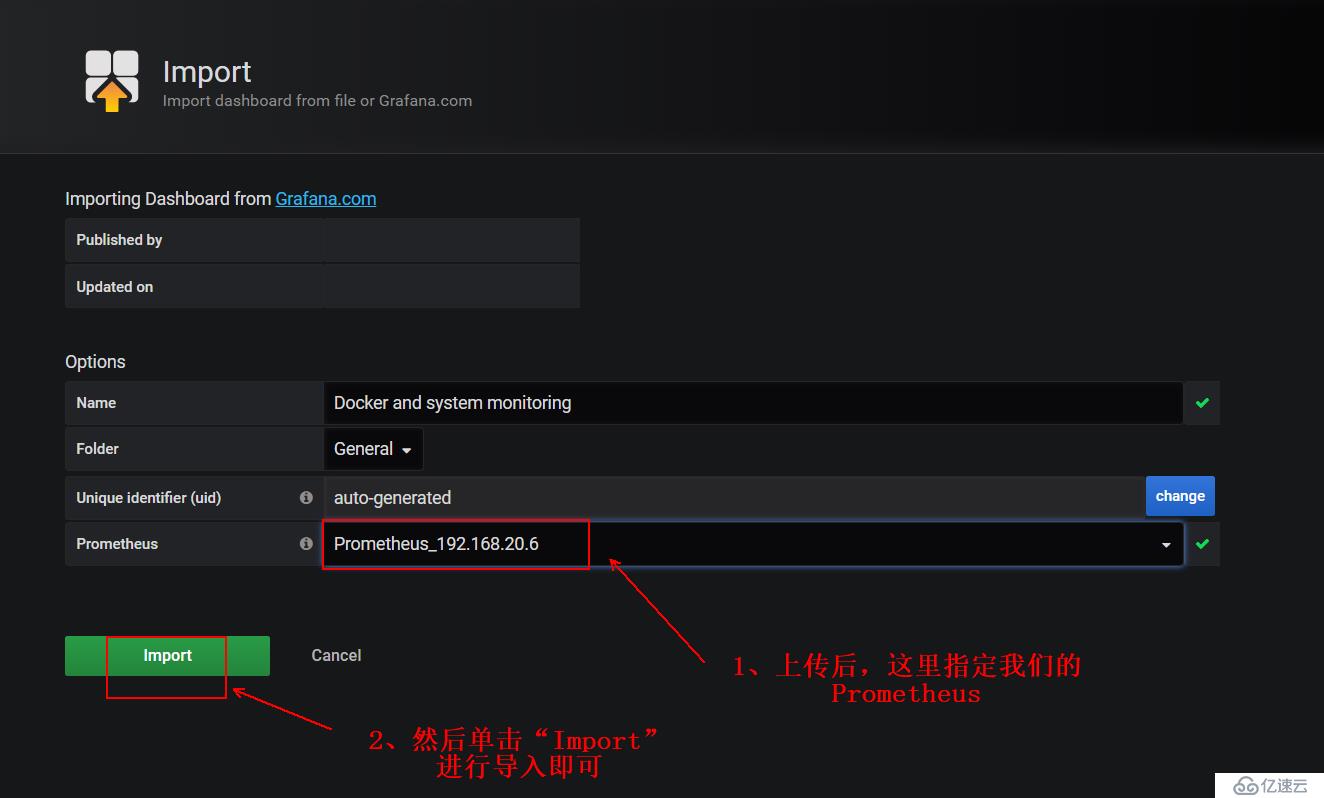
5)至此,即可看到下面的监控页面,说明导入成功了:
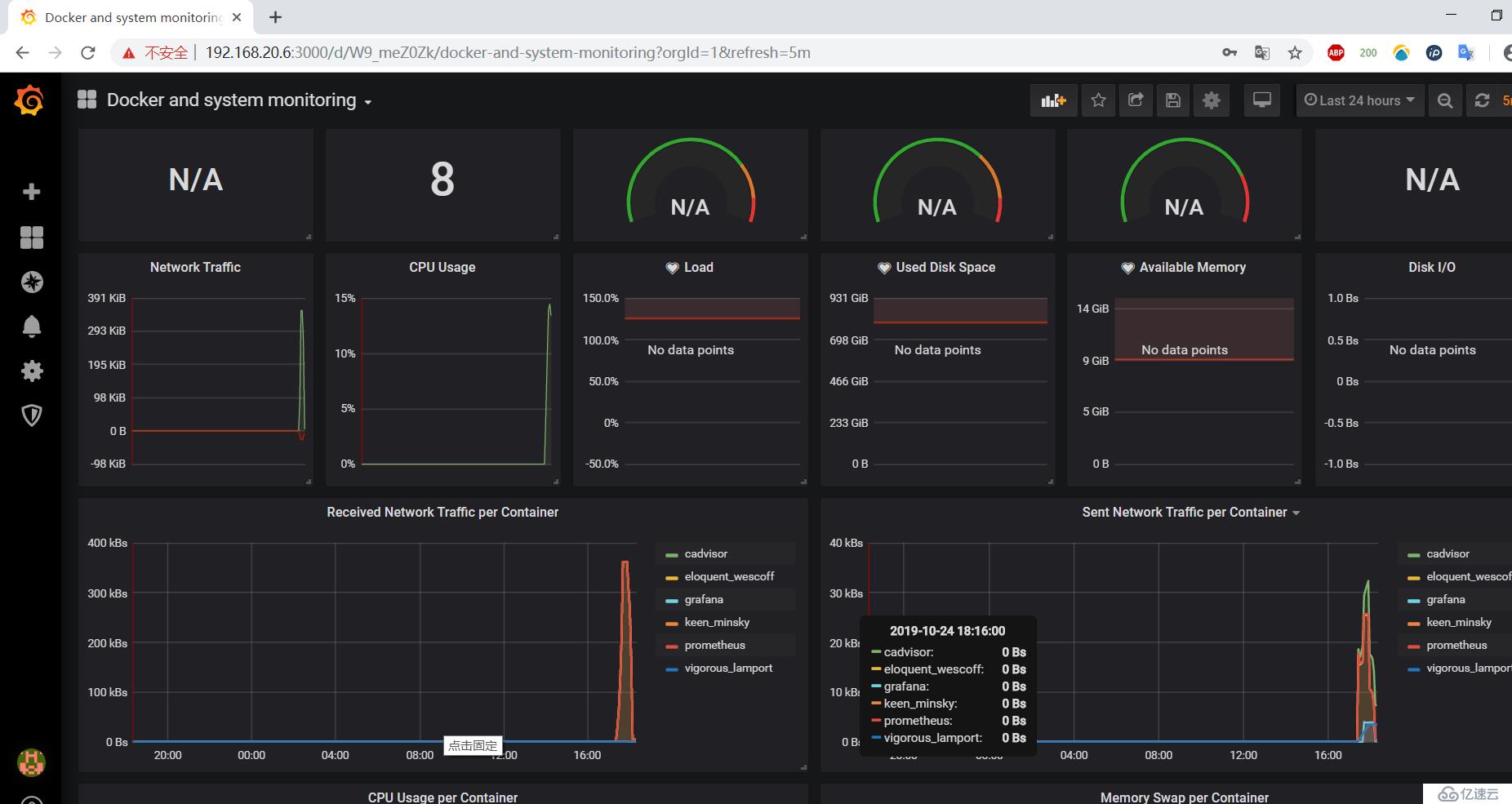
但是注意看的话,会发现这个模板有些信息都检测不到,所以这里只是为了展示这第一种导入模板的方式,我更推荐使用方式2进行导入。
1)在进入官网提供的模板后,我们需要记录其ID号,如下:
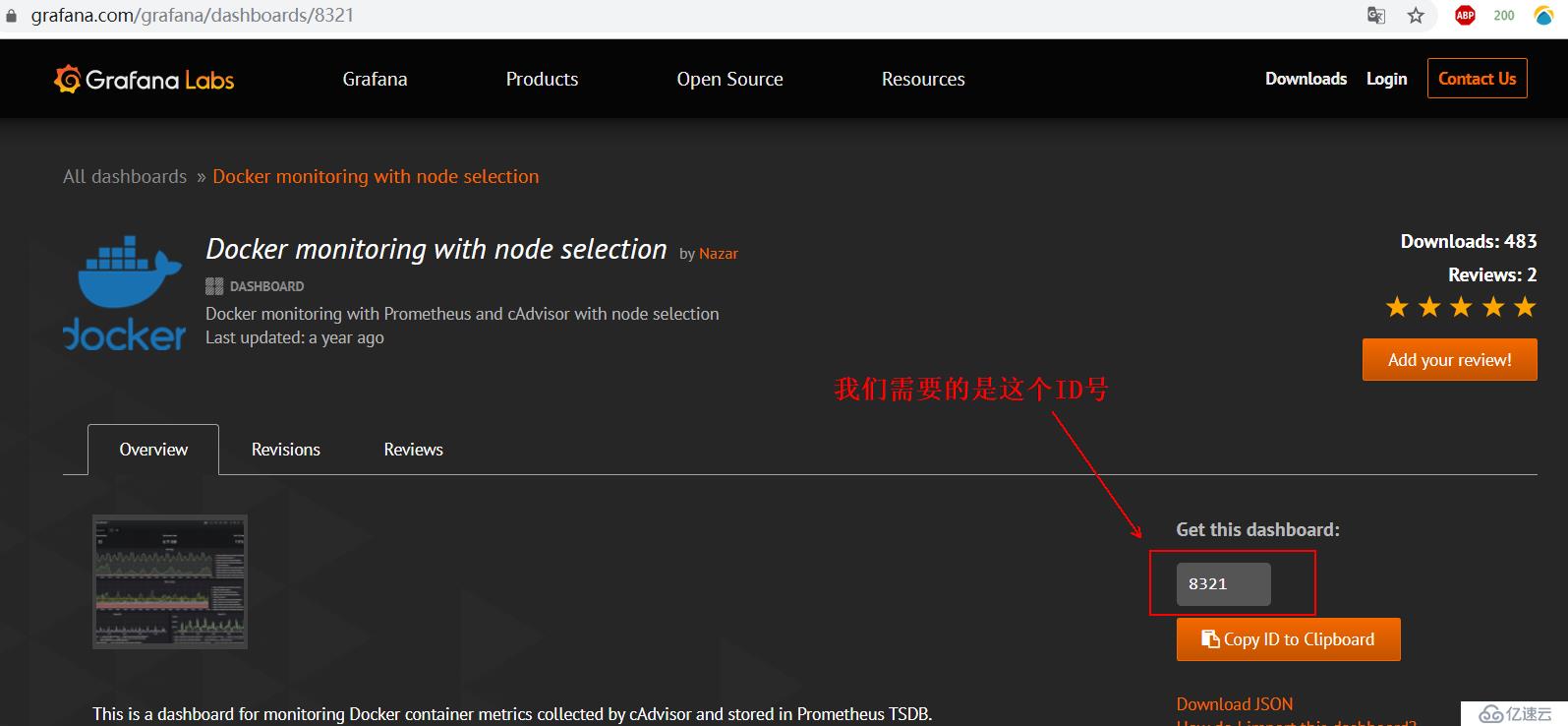
2)然后回到grafana的web界面,同样点击如下,进行导入操作:
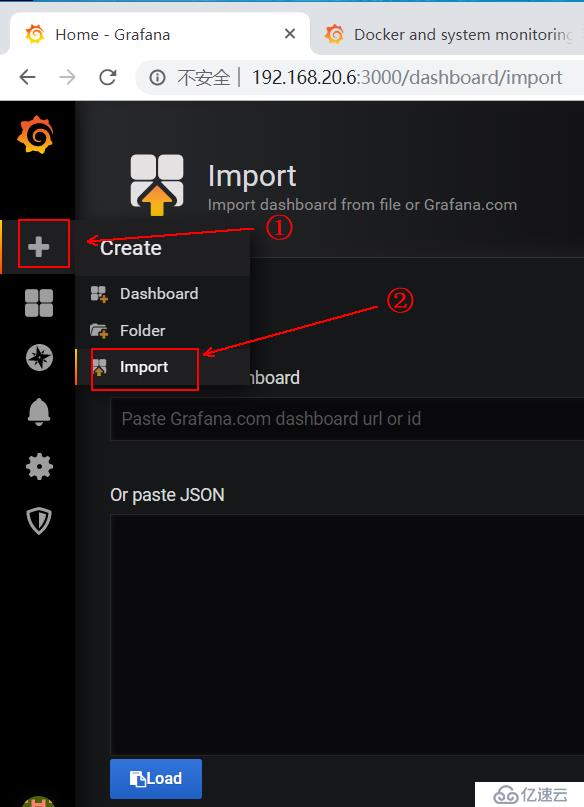
3)在下面的红框中输入我们记录的ID号即可:
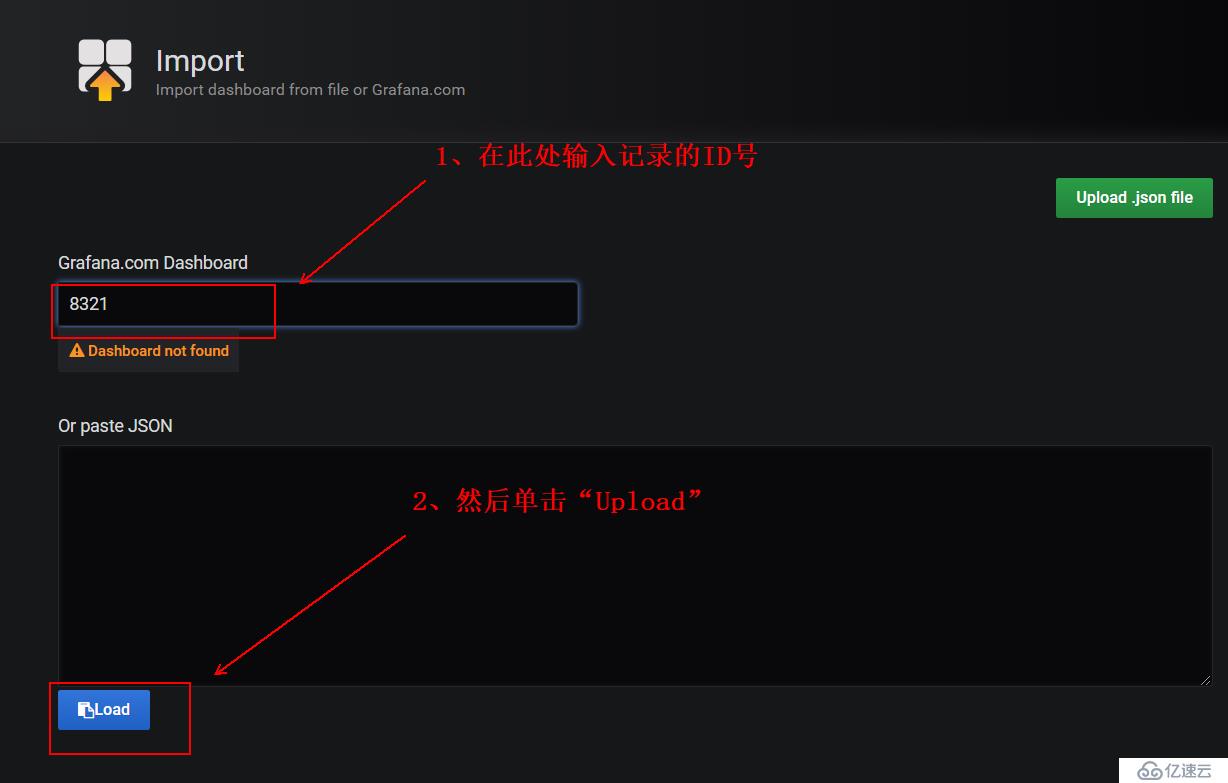
4)接下来的操作和方式1中的一样,如下:
5)导入此模板后,会看到该模板给我们提供的界面,如下:
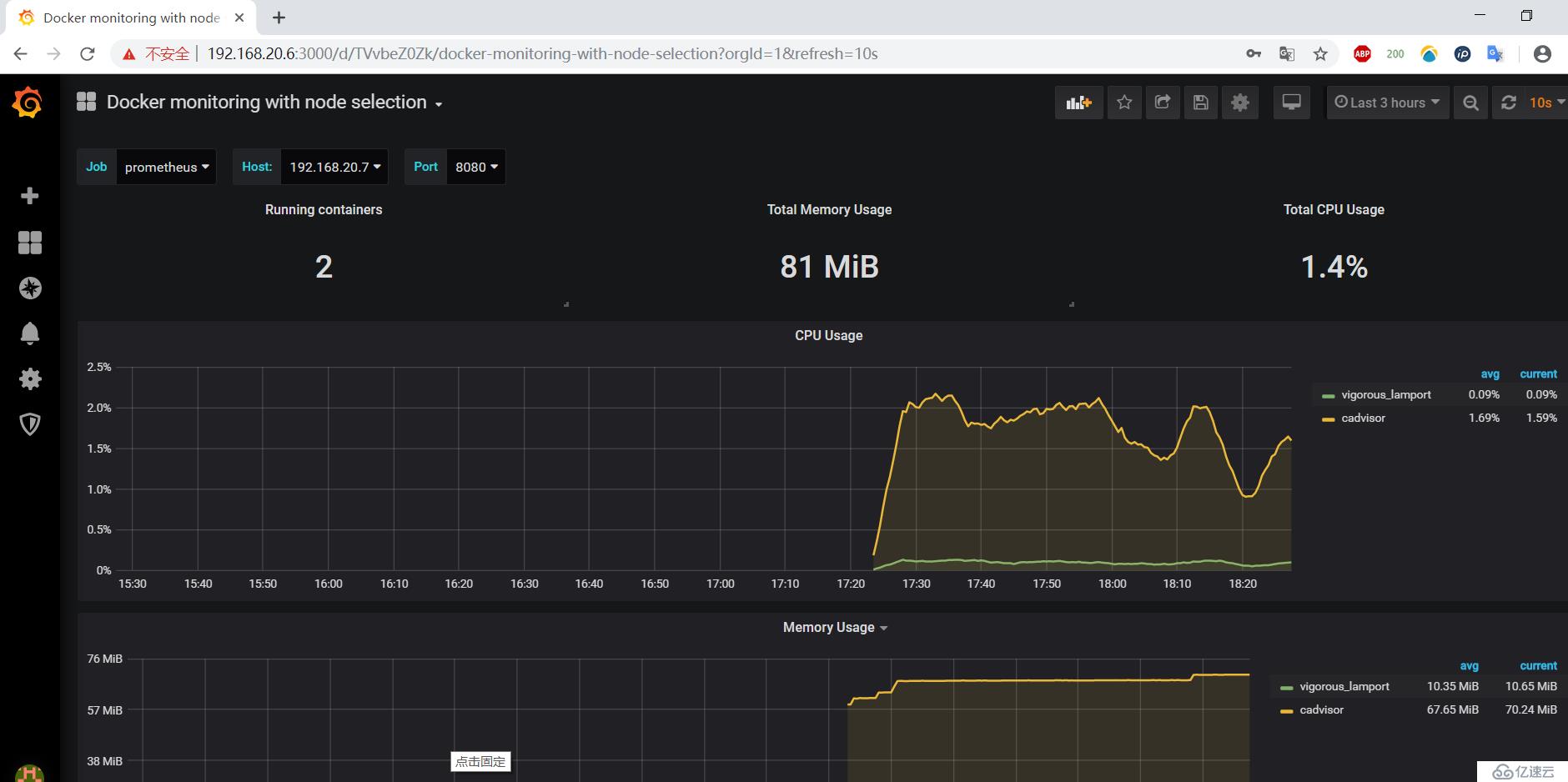
至此,web界面的监控就部署完成了。
Prometheus的告警方式有好几种方式,邮箱、钉钉、微信等,我这里选择邮箱的告警方式。
[root@docker01 ~]# docker run --name alertmanager -d -p 9093:9093 prom/alertmanager
#先简单运行一个容器
[root@docker01 ~]# docker cp alertmanager:/etc/alertmanager/alertmanager.yml /root
#将容器中的配置文件复制到本地
[root@docker01 ~]# docker rm -f alertmanager #删除之前随便运行的容器
[root@docker01 ~]# vim alertmanager.yml #编辑复制出来的配置文件
#配置文件中可以分为以下几组:
#global:全局配置。设置报警策略,报警渠道等;
#route:分发策略;
#receivers:接收者,指定谁来接收你发送的这些信息;
#inhibit_rules:抑制策略。当存在于另一组匹配的警报,抑制规则将禁用于一组匹配的警报。我这里更改后的配置文件如下:
[root@docker01 ~]# vim alertmanager.yml #编辑复制出来的配置文件
#将以下所有的邮箱账号及auth_password更改为自己的账户即可
global:
resolve_timeout: 5m
smtp_from: '916551516@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '916551516@qq.com'
smtp_auth_password: 'abdgwyaxickabccb0'
smtp_require_tls: false
smtp_hello: 'qq.com'
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '916551516@qq.com'
send_resolved: true #这行的作用是,当容器恢复正常后,也会发送一份邮件
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
#更改完成后,保存退出即可
[root@docker01 ~]# docker run -d --name alertmanger -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml --restart=always prom/alertmanager
#运行新的alertmanager容器,并挂载更改后的配置文件
#如果配置文件有错误,那么这个容器是运行不了的。[root@docker01 ~]# mkdir -p prometheus/rules
[root@docker01 ~]# cd prometheus/rules/
[root@docker01 rules]# vim node-up.rules #编辑规则如下
groups:
- name: node-up #设置报警的名称
rules:
- alert: node-up
expr: up{job="prometheus"} == 0 #该job必须和Prometheus的配置文件中job_name完全一致
for: 15s
labels:
severity: 1 #一级警告
team: node
annotations:
summary: "{{ $labels.instance }} 已停止运行超过 15s!
"
#定义完成后,保存退出即可。若想自己编写报警规则,可以参考它的官方文档,我这里的报警规则是有些问题的,但是可以收到它的报警信息
[root@docker01 ~]# vim prometheus.yml #更改以下内容
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.20.6:9093 #将此行的注释去掉,改为alertmanager容器的IP+端口
rule_files:
- "/usr/local/prometheus/rules/*.rules" #注意,这个路径是容器内的路径
#必须格外注意配置文件的格式,注意缩进。更改完成后,保存退出即可。为了防止格式错误,我这里附一个配置文件的截图:

[root@docker01 ~]# docker rm -f prometheus #删除此容器
[root@docker01 ~]# docker run -d -p 9090:9090 -v /root/prometheus.yml:/etc/prometheus/prometheus.yml -v /root/prometheus/rules:/usr/local/prometheus/rules --name prometheus --net=host prom/prometheus
#重新运行此容器,挂载新的文件
[root@docker01 ~]# docker logs prometheus #若启动遇到错误,可以查看容器的日志拍错
至此,如果Prometheus页面中的target有down掉的容器,那么就会给你的邮箱发送报警信息。当容器正常后,它还会给你反馈

我收到的报警邮件如下:

[root@docker01 ~]# cd prometheus/
[root@docker01 prometheus]# mkdir alertmanager-tmpl
[root@docker01 prometheus]# cd alertmanager-tmpl/
[root@docker01 alertmanager-tmpl]# vim email.tmpl #编辑报警模板
{{ define "email.from" }}916551516@qq.com{{ end }} #将此改为自己的邮箱
{{ define "email.to" }}916551516@qq.com{{ end }} #改为自己的邮箱
{{ define "email.to.html" }}
{{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert<br>
告警级别: {{ .Labels.severity }} 级<br>
告警类型: {{ .Labels.alertname }}<br>
故障主机: {{ .Labels.instance }}<br>
告警主题: {{ .Annotations.summary }}<br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{{ end }}
{{ end }}
#更改完自己的邮箱即可保存退出
[root@docker01 ~]# cd
[root@docker01 ~]# vim alertmanager.yml #编辑alertmanager配置文件,修改以下有注释的行即可
global:
resolve_timeout: 5m
smtp_from: '916551516@qq.com'
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: '916551516@qq.com'
smtp_auth_password: 'abdgwyaxickabccb0'
smtp_require_tls: false
smtp_hello: 'qq.com'
templates: #添加此行
- '/etc/alertmanager-tmpl/*.tmpl' #添加此行
route:
group_by: ['alertname']
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receiver: 'email'
receivers:
- name: 'email'
email_configs:
- to: '{{ template "email.to" }}' #必须和{{ define "email.to" }}916551516@qq.com{{ end }} 中的对应
html: '{{ template "email.to.html" . }}' #必须和{{ define "email.to.html" }} 中的名字对应
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
#修改完成后,保存退出
[root@docker01 ~]# docker rm -f alertmanger #删除此容器
[root@docker01 ~]# docker run -d --name alertmanger -p 9093:9093 -v /root/alertmanager.yml:/etc/alertmanager/alertmanager.yml -v /root/prometheus/alertmanager-tmpl:/etc/alertmanager-tmpl --restart=always prom/alertmanager
#运行一个新的容器
[root@docker01 ~]# docker ps #确定9093端口运行映射正常
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f9d718071d4d prom/alertmanager "/bin/alertmanager -…" 7 seconds ago Up 6 seconds 0.0.0.0:9093->9093/tcp alertmanger
1b1379e3e12a prom/prometheus "/bin/prometheus --c…" 11 minutes ago Up 11 minutes prometheus
65240a28e383 grafana/grafana "/run.sh" 2 hours ago Up 2 hours 0.0.0.0:3000->3000/tcp grafana
3bd83eb145e2 google/cadvisor "/usr/bin/cadvisor -…" 2 hours ago Up 2 hours cadvisor
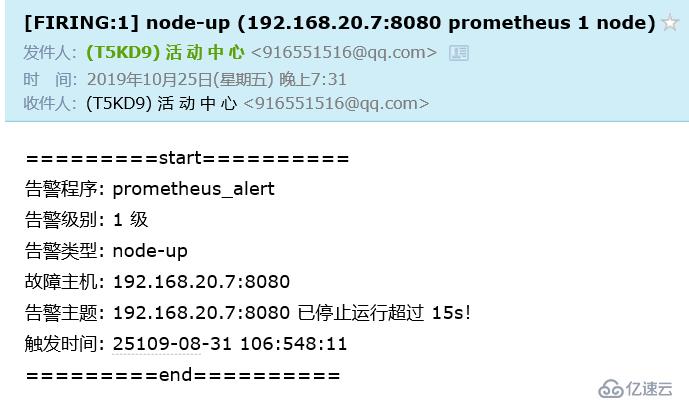
a57b77a33e79 prom/node-exporter "/bin/node_exporter …" 2 hours ago Up 2 hours eloquent_wescoff至此,新的报警模板也生成了,如果以下容器有Down的,就会给你发送新的邮件,恢复正常后,也会发送邮件,同样,邮件中的内容格式是有误的,但是你可以正常接收到报警信息,若想要更改其报警模板,可以参考github官方文档
我邮箱收到的报警信息如下:
———————— 本文至此结束,感谢阅读 ————————
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。