您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下Python异步新闻抓取百度新闻爬虫的案例,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨吧!
要抓取新闻,首先得有新闻源,也就是抓取的目标网站。国内的新闻网站,从中央到地方,从综合到垂直行业,大大小小有几千家新闻网站。百度新闻(news.baidu.com)收录的大约两千多家。那么我们先从百度新闻入手。
打开百度新闻的网站首页:news.baidu.com
我们可以看到这就是一个新闻聚合网页,里面列举了很多新闻的标题及其原始链接。如图所示:
我们的目标就是从这里提取那些新闻的链接并下载。流程比较简单:
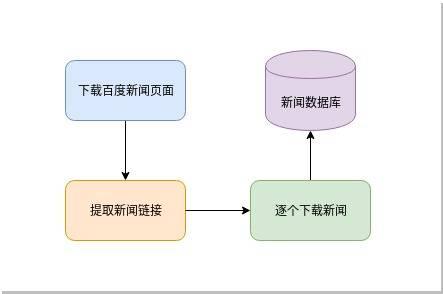
根据这个简单流程,我们先实现下面的简单代码:
#!/usr/bin/env python3
# Author: veelion
import re
import time
import requests
import tldextract
def save_to_db(url, html):
# 保存网页到数据库,我们暂时用打印相关信息代替
print('%s : %s' % (url, len(html)))
def crawl():
# 1. download baidu news
hub_url = 'http://news.baidu.com/'
res = requests.get(hub_url)
html = res.text
# 2. extract news links
## 2.1 extract all links with 'href'
links = re.findall(r'href=[\'"]?(.*?)[\'"\s]', html)
print('find links:', len(links))
news_links = []
## 2.2 filter non-news link
for link in links:
if not link.startswith('http'):
continue
tld = tldextract.extract(link)
if tld.domain == 'baidu':
continue
news_links.append(link)
print('find news links:', len(news_links))
# 3. download news and save to database
for link in news_links:
html = requests.get(link).text
save_to_db(link, html)
print('works done!')
def main():
while 1:
crawl()
time.sleep(300)
if __name__ == '__main__':
main()简单解释一下上面的代码:
1. 使用requests下载百度新闻首页;
2. 先用正则表达式提取a标签的href属性,也就是网页中的链接;然后找出新闻的链接,方法是:假定非百度的外链都是新闻链接
3. 逐个下载找到的所有新闻链接并保存到数据库;保存到数据库的函数暂时用打印相关信息代替。
4. 每隔300秒重复1-3步,以抓取更新的新闻。
以上代码能工作,但也仅仅是能工作,槽点多得也不是一点半点,那就让我们一起边吐槽边完善这个爬虫吧。
1. 增加异常处理
在写爬虫,尤其是网络请求相关的代码,一定要有异常处理。目标服务器是否正常,当时的网络连接是否顺畅(超时)等状况都是爬虫无法控制的,所以在处理网络请求时必须要处理异常。网络请求最好设置timeout,别在某个请求耗费太多时间。timeout 导致的识别,有可能是服务器响应不过来,也可能是暂时的网络出问题。所以,对于timeout的异常,我们需要过段时间再尝试。
2. 要对服务器返回的状态,如404,500等做出处理
服务器返回的状态很重要,这决定着我们爬虫下一步该怎么做。需要处理的常见状态有:
301, 该URL被永久转移到其它URL,以后请求的话就请求被转移的URL
404,基本上是这个网站已经失效了,后面也就别试了
500,服务器内部出错了,可能是暂时的,后面要再次请求试试
3. 管理好URL的状态
记录下此次失败的URL,以便后面再试一次。对于timeout的URL,需要后面再次抓取,所以需要记录所有URL的各种状态,包括:
已经下载成功
下载多次失败无需再下载
正在下载
下载失败要再次尝试
增加了对网络请求的各种处理,这个爬虫就健壮多了,不会动不动就异常退出,给后面运维带来很多的工作量。
Python爬虫知识点
本节中我们用到了Python的几个模块,他们在爬虫中的作用如下:
1. requests模块
它用来做http网络请求,下载URL内容,相比Python自带的urllib.request,requests更加易用。GET,POST信手拈来:
import requests res = requests.get(url, timeout=5, headers=my_headers) res2 = requests.post(url, data=post_data, timeout=5, headers=my_headers)
get()和post()函数有很多参数可选,上面用到了设置timeout,自定义headers,更多参数可参考requests 文档。
requests无论get()还是post()都会返回一个Response对象,下载到的内容就通过这个对象获取:
res.content 是得到的二进制内容,其类型是bytes;
res.text 是二进制内容content decode后的str内容;
它先从response headers里面找到encoding,没找到就通过chardet自动判断得到encoding,并赋值给res.encoding,最后把二进制的content解密为str类型。
In [1]: import requests
In [2]: r = requests.get('http://epaper.sxrb.com/')
In [3]: r.encoding
Out[3]: 'ISO-8859-1'
In [4]: import chardet
In [5]: chardet.detect(r.content)
Out[5]: {'confidence': 0.99, 'encoding': 'utf-8', 'language': ''}上面是用ipython交互式解释器(强烈推荐ipython,比Python自己的解释器好太多)演示了一下。打开的网址是山西日报数字报,手动查看网页源码其编码是utf8,用chardet判断得到的也是utf8。而requests自己判断的encoding是ISO-8859-1,那么它返回的text的中文也就会是乱码。
requests还有个好用的就是Session,它部分类似浏览器,保存了cookies,在后面需要登录和与cookies相关的爬虫都可以用它的session来实现。
2. re模块
正则表达式主要是用来提取html中的相关内容,比如本例中的链接提取。更复杂的html内容提取,推荐使用lxml来实现。
3. tldextract模块
这是个第三方模块,需要pip install tldextract进行安装。它的意思就是Top Level Domain extract,即顶级域名提取。前面我们讲过URL的结构,news.baidu.com 里面的news.baidu.com叫做host,它是注册域名baidu.com的子域名,而com就是顶级域名TLD。它的结果是这样的:
In [6]: import tldextract
In [7]: tldextract.extract('http://news.baidu.com/')
Out[7]: ExtractResult(subdomain='news', domain='baidu', suffix='com')返回结构包含三部分:subdomain, domain, suffix
4. time模块
时间,是我们在程序中经常用到的概念,比如,在循环中停顿一段时间,获取当前的时间戳等。而time模块就是提供时间相关功能的模块。同时还有另外一个模块datetime也是时间相关的,可以根据情况适当选择来用。
看完了这篇文章,相信你对Python异步新闻抓取百度新闻爬虫的案例有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。