您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了Python爬虫中正则表达式的使用方法,具有一定借鉴价值,需要的朋友可以参考下。希望大家阅读完这篇文章后大有收获。下面让小编带着大家一起了解一下。
正则表达式
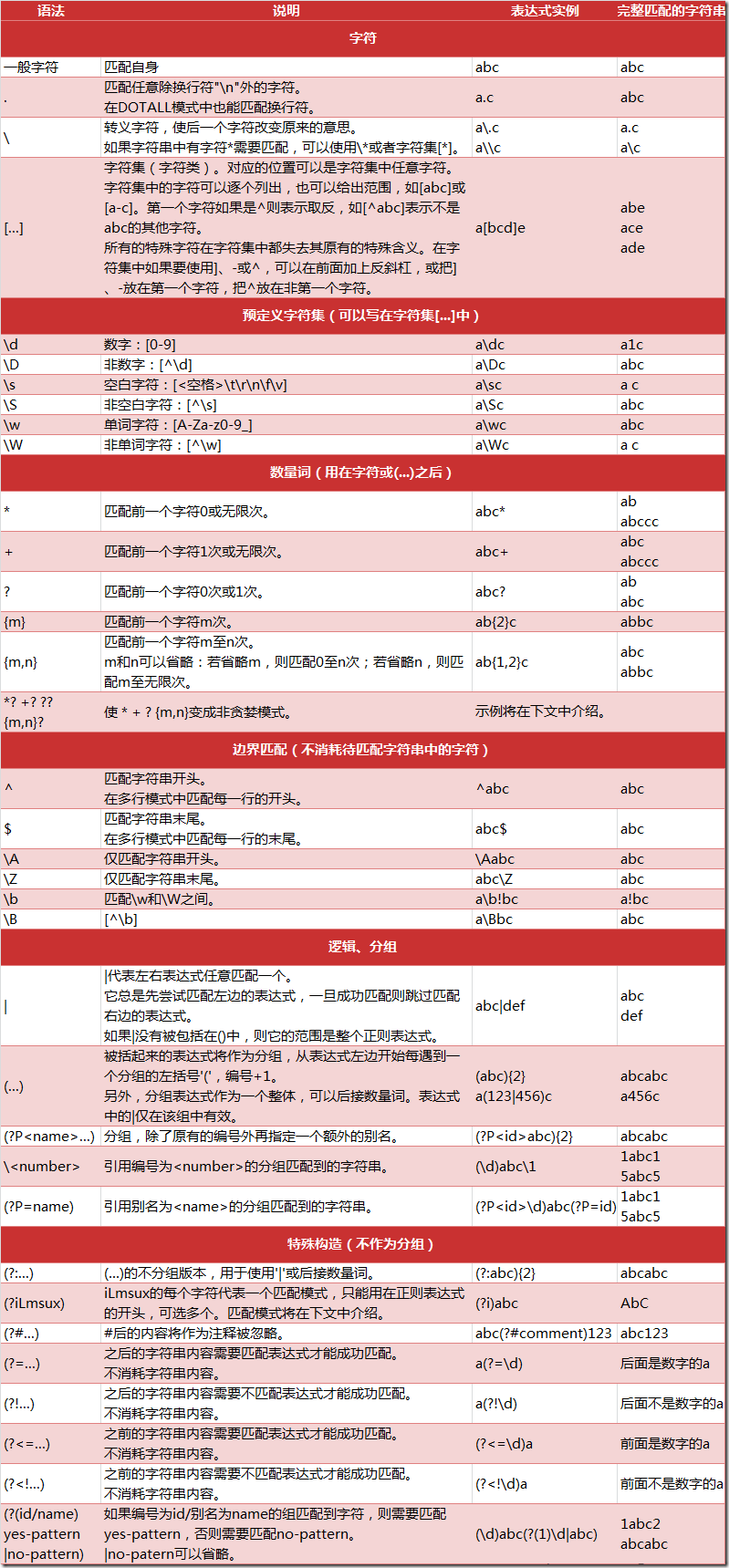
re 模块的一般使用步骤如下:
使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象。
通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象。
最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作。
pattern = re.compile('\d') #将正则表达式编译成一个pattern规则对象
pattern.match() #从起始位置开始往后查找,返回第一个符合规则的,只匹配一次
pattern.search() #从任意位置开始往后查找,返回第一个符合规则的,只匹配一次
pattern.findall() #所有的全部匹配,返回列表
pattern.finditer() #所有的全部匹配,返回的是一个迭代器
pattern.split() #分割字符串,返回列表
pattern.sub() #替换
re.I #表示忽略大小写
re.S #表示全文匹配1.match()
import re
pattern = re.compile('\d+')
m = pattern.match('aaa123bbb456',3,5) #可以指定match起始和结束的位置match(string,begin,end)
print m.group() #12
m = pattern.match('aaa123bbb456',3,6)
print m.group() #123import re
#匹配两组, re.I忽略大小写
pattern = re.compile(r"([a-z]+) ([a-z]+)",re.I) #第一组(字母)和第二组(字母)之间以空格分开
m = pattern.match("Hello world and Python")
print m.group(0) #Hello world group(0)获取所有子串
print m.group(1) #Hello group(1)所有子串里面的第一个子串
print m.group(2) #world group(2)所有子串里面的第二个子串2.search()
import re
pattern = re.compile(r'\d+')
m = pattern.search('aaa123bbb456')
print m.group() #123
m = pattern.search('aaa123bbb456',2,5)
print m.group() #123.findall()
import re
pattern = re.compile(r'\d+')
m = pattern.findall('hello 123456 789') #
print m #['123456', '789']
m = pattern.findall('hello 123456 789',5,10)
print m #['1234']4.split()
# _*_ coding:utf-8 _*_ import re pattern = re.compile(r'[\s\d\\\;]+') #以空格,数字,'\',';'做分割 m = pattern.split(r'a b22b\cc;d33d ee') print m #['a', 'b', 'b', 'cc', 'd', 'd', 'ee']
5.sub()
# _*_ coding:utf-8 _*_
import re
pattern = re.compile(r'(\w+) (\w+)')
str = 'good 111,job 222'
m = pattern.sub('hello python',str)
print m #hello python,hello python
m = pattern.sub(r"'\1':'\2'",str)
print m #'good':'111','job':'222'# _*_ coding:utf-8 _*_
import re
pattern = re.compile(r'\d+')
str = 'a1b22c33d4e5f678'
m = pattern.sub('*',str) #a*b*c*d*e*f* 把数字替换成'*'
print m内涵段子实例
爬取贴吧所有内容,并通过正则表达式爬取出所有的段子
url变化
第一页url: http: //www.neihan8.com/article/list_5_1 .html
第二页url: http: //www.neihan8.com/article/list_5_2 .html
第三页url: http: //www.neihan8.com/article/list_5_3 .html

pattern = re.compile('<dd\sclass="content">(.*?)</dd>', re.S)
每个段子内容都是在 <dd class='content'>......</dd>里面,通过正则可以获取内
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import urllib2
import re
class Spider:
def __init__(self):
# 初始化起始页位置
self.page = 1
# 爬取开关,如果为True继续爬取
self.switch = True
def loadPage(self):
"""
作用:下载页面
"""
print "正在下载数据...."
url = "http://www.neihan.net/index_" + str(self.page) + ".html"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/60.0.3112.101 Safari/537.36'}
request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
# 获取每页的HTML源码字符串
html = response.read()
#print html
# 创建正则表达式规则对象,匹配每页里的段子内容,re.S 表示匹配全部字符串内容
pattern = re.compile('<dd\sclass="content">(.*?)</dd>', re.S)
# 将正则匹配对象应用到html源码字符串里,返回这个页面里的所有段子的列表
content_list = pattern.findall(html)
# 调用dealPage() 处理段子里的杂七杂八
self.dealPage(content_list)
def dealPage(self, content_list):
"""
处理每页的段子
content_list : 每页的段子列表集合
"""
for item in content_list:
# 将集合里的每个段子按个处理,替换掉无用数据
item = item.replace("<p>","").replace("</p>", "").replace("<br/>", "")
# 处理完后调用writePage() 将每个段子写入文件内
self.writePage(item)
def writePage(self, item):
"""
把每条段子逐个写入文件里
item: 处理后的每条段子
"""
# 写入文件内
print "正在写入数据...."
with open("tieba.txt", "a") as f:
f.write(item)
def startWork(self):
"""
控制爬虫运行
"""
# 循环执行,直到 self.switch == False
while self.switch:
# 用户确定爬取的次数
self.loadPage()
command = raw_input("如果继续爬取,请按回车(退出输入quit)")
if command == "quit":
# 如果停止爬取,则输入 quit
self.switch = False
# 每次循环,page页码自增1
self.page += 1
print "谢谢使用!"
if __name__ == "__main__":
duanziSpider = Spider()
duanziSpider.startWork()可以按回车接着爬取下一页内容,输入QUIT退出。
爬取后的内容:

感谢你能够认真阅读完这篇文章,希望小编分享Python爬虫中正则表达式的使用方法内容对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,遇到问题就找亿速云,详细的解决方法等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。