жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonзҲ¬иҷ«жӯЈеҲҷиЎЁиҫҫејҸжҖҺд№ҲзҗҶи§ЈвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
е…ғеӯ—з¬Ұ
^ $ * + . | ? {} [] () иҝҷе°ұжҳҜе…ғеӯ—з¬ҰдәҶпјҢеӯҰдјҡиҝҷдәӣеә”иҜҘе°ұеӨҹдҪ з”Ёзҡ„дәҶгҖӮ
pythonдёӯзҡ„жӯЈеҲҷиЎЁиҫҫејҸйҖҡиҝҮimport re жқҘдҪҝз”ЁгҖӮ
1гҖҒpythonзҲ¬иҷ«жӯЈеҲҷиЎЁиҫҫејҸпјҢ[] еёёз”ЁжқҘжҢҮе®ҡдёҖдёӘеӯ—з¬ҰйӣҶпјҢеҰӮпјҡ[abc ]; [a-z] йҮҢйқўжүҖжңүзҡ„еӯ—жҜҚдјҡиў«дёҖдёҖеҢ№й…Қ дҫӢеӯҗпјҡ
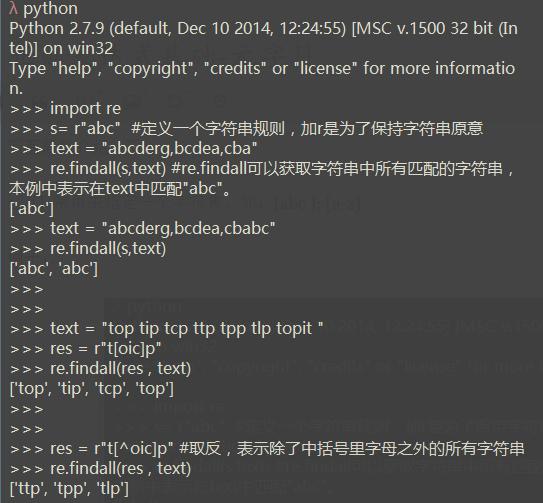
йқўдҫӢеӯҗйғҪи§ЈйҮҠзҡ„еҫҲжё…жҘҡдәҶпјҢжҲ‘е°ұдёҚйҮҚеӨҚдёҖиЎҢиЎҢи§ЈйҮҠдәҶгҖӮ жіЁпјҡ зӨәдҫӢдёӯ^иЎЁзӨәеҸ–еҸҚгҖӮ
[a-z]иЎЁзӨә д»Һеӯ—жҜҚaеҲ°zжүҖжңүзҡ„еӯ—жҜҚгҖӮ
[0-9]зӯүд»·дәҺ[0123456789] д№ҹеҸҜд»Ҙз”Ёd иЎЁзӨәгҖӮ жүҖжңүе…¶е®ғзҡ„е…ғеӯ—з¬ҰеңЁ[]дёӯе°ҶеӨұеҺ»еҺҹжңүзҡ„ж„Ҹд№үпјҢжҜ”еҰӮзӨәдҫӢдёӯзҡ„^еңЁ[]иЎЁзӨәеҸ–еҸҚгҖӮ
2гҖҒ^ иЎЁзӨәеҢ№й…Қеӯ—з¬ҰдёІзҡ„ејҖеӨҙгҖӮеңЁеӨҡиЎҢжЁЎејҸдёӢеҢ№й…ҚжҜҸдёҖиЎҢзҡ„ејҖеӨҙгҖӮ
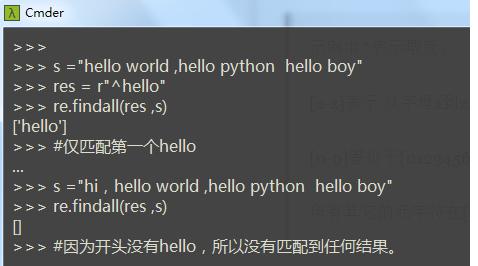
жіЁпјҡ^дёҖиҲ¬ж”ҫеңЁеӯ—з¬ҰдёІејҖеӨҙ
3гҖҒ$ иЎЁзӨәеҢ№й…Қеӯ—з¬ҰдёІзҡ„з»“е°ҫгҖӮеңЁеӨҡиЎҢжЁЎејҸдёӢеҢ№й…ҚжҜҸдёҖиЎҢзҡ„е°ҫйғЁгҖӮ
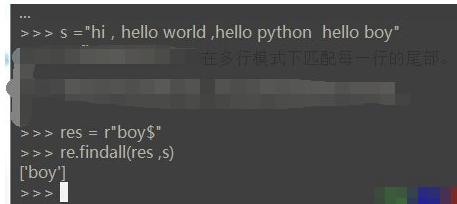
жіЁпјҡ$дёҖиҲ¬ж”ҫеңЁеӯ—з¬ҰдёІз»“е°ҫгҖӮ
дёҠйқўдёүдёӘеҸҜд»ҘзңӢжҲҗдёҖдёӘе°Ҹеқ—пјҢдҪ и®°дҪҸдәҶеҗ—пјҹзҗҶи§ЈдәҶеҗ—пјҹзңӢжҳҺзҷҪдәҶеҗ—пјҹиҝҳжңүдҪ иҮӘе·ұж•ІдёҖйҒҚд»Јз ҒдәҶеҗ—пјҹпјҹпјҹпјҹпјҹпјҒпјҒпјҒпјҒдёҖе®ҡиҮӘе·ұе°қиҜ•ж•ІдёҖйҒҚд»Јз ҒпјҒ
еҘҪжҺҘдёӢжқҘпјҢ继з»ӯ з”ұдәҺе…ғеӯ—з¬ҰжҳҜзү№ж®Ҡеӯ—з¬ҰпјҢеҰӮжһңжҲ‘们иҰҒеҢ№й…Қе…ғеӯ—з¬Ұжң¬иә«зҡ„еӯ—з¬Ұеә”иҜҘжҖҺд№ҲеҠһе‘ўпјҹ еҪ“жҲ‘们жғіжҠҠе…ғеӯ—з¬ҰеҸҳдёәдёәжҷ®йҖҡз¬ҰеҸ·жҳҜеҸҜд»ҘдҪҝз”ЁпјҲеҸҚж–ңжқ пјүиҝӣиЎҢиҪ¬д№үгҖӮ
4гҖҒеҸҚж–ңжқ еҗҺйқўеҸҜд»ҘеҠ дёҚеҗҢзҡ„еӯ—з¬Ұд»ҘиЎЁзӨәзү№ж®Ҡж„Ҹд№үгҖӮ д№ҹеҸҜз”ЁдәҺеҸ–ж¶ҲжүҖжңүе…ғеӯ—з¬ҰпјҢеҸҳдёәжҷ®йҖҡз¬ҰеҸ·гҖӮ

дҪ еҸӘиҰҒиғҪи®°дҪҸеҠ й»‘еҠ зІ—зҡ„е…¶е®ғзҡ„жҲ‘жү“иөҢдҪ иӮҜе®ҡд№ҹе…ЁдјҡдәҶгҖӮжүҖд»Ҙи®°дҪҸеҠ зІ—зҡ„пјҢиҮӘе·ұжҠҠдёӢйқўзҡ„д»Јз Ғж•ІдёҖйҒҚгҖӮ зӨәдҫӢ

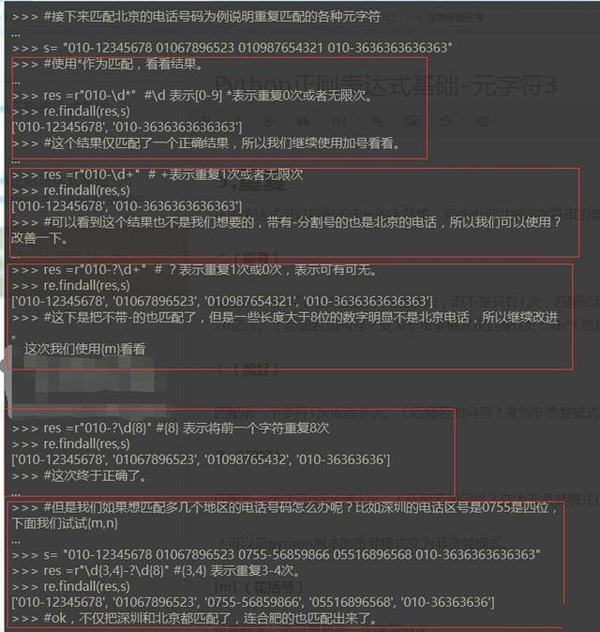
жӯЈеҲҷиЎЁиҫҫејҸеҸҜд»ҘеҢ№й…ҚдёҚе®ҡй•ҝзҡ„еӯ—з¬ҰйӣҶпјҢеҸҰеӨ–д№ҹеҸҜд»ҘжҢҮе®ҡеӯ—з¬ҰдёІзҡ„йҮҚеӨҚж¬Ўж•°гҖӮ
* пјҲжҳҹеҸ·пјү жҢҮе®ҡеүҚдёҖдёӘеӯ—з¬ҰеҸҜд»ҘеҢ№й…Қ0ж¬ЎжҲ–иҖ…еӨҡж¬ЎпјҢиҖҢдёҚжҳҜеҸӘжңү1ж¬ЎпјҢеҢ№й…Қз»“жһңдјҡе°ҪеҸҜиғҪзҡ„йҮҚеӨҚеӨҡж¬Ў***дёҚи¶…иҝҮ20дәҝж¬ЎгҖӮпјҲеҗҺйқўиӢҘеҠ й—®еҸ·пјҹеҸҳдёәйқһиҙӘе©ӘжЁЎејҸд»…еҢ№й…Қ0ж¬Ўпјҡab*? з»“жһңдёәaпјү
+ пјҲеҠ еҸ·пјү еҢ№й…ҚеүҚдёҖдёӘеӯ—з¬Ұ1ж¬ЎжҲ–иҖ…еӨҡж¬ЎгҖӮпјҲеҗҺйқўиӢҘеҠ й—®еҸ·пјҹеҸҳдёәйқһиҙӘе©ӘжЁЎејҸд»…еҢ№й…Қ1ж¬Ўпјҡab+? з»“жһңдёәabпјү
пјҹ пјҲй—®еҸ·пјү еҢ№й…ҚеүҚдёҖдёӘеӯ—з¬Ұ0ж¬ЎжҲ–иҖ…1ж¬ЎгҖӮпјҲеҗҺйқўиӢҘеҠ й—®еҸ·пјҹеҸҳдёәйқһиҙӘе©ӘжЁЎејҸд»…еҢ№й…Қ0ж¬Ўпјҡab?? з»“жһңдёәaпјү пјҹеҸҜд»ҘжҳҜpythonеҺҹжң¬зҡ„иҙӘе©ӘжЁЎејҸеҸҳдёәйқһиҙӘе©ӘжЁЎејҸгҖӮ
{m} пјҲиҠұжӢ¬еҸ·пјү mжҳҜж•°еӯ—пјҢиЎЁзӨәйҮҚеӨҚеүҚдёҖдёӘеӯ—з¬Ұmж¬ЎгҖӮ
{m,n} иЎЁзӨәйҮҚеӨҚеүҚдёҖдёӘеӯ—з¬Ұm-nж¬ЎгҖӮиӢҘзңҒз•ҘmеҲҷиЎЁзӨә0-nж¬ЎпјҢиӢҘзңҒз•ҘnиЎЁзӨәmеҲ°***ж¬ЎгҖӮпјҲеҗҺйқўиӢҘеҠ й—®еҸ·пјҹеҸҳдёәйқһиҙӘе©ӘжЁЎејҸд»…еҢ№й…Қ0ж¬Ўпјҡab{2,100}? з»“жһңдёәabbпјү
пјҲпјү | . . е®ғеҢ№й…ҚйҷӨдәҶжҚўиЎҢеӯ—з¬ҰеӨ–зҡ„д»»дҪ•еӯ—з¬ҰпјҢеңЁ alternate жЁЎејҸпјҲre.DOTALLпјүдёӢе®ғз”ҡиҮіеҸҜд»ҘеҢ№й…ҚжҚўиЎҢ
| д»ЈиЎЁе·ҰеҸіиЎЁиҫҫејҸд»»ж„ҸеҢ№й…ҚдёҖдёӘгҖӮa|b еҢ№й…ҚaжҲ–иҖ…еҢ№й…Қb гҖӮ еҰӮжһңжІЎжңүиў«(...)жӢ¬иө·жқҘе®ғзҡ„иҢғеӣҙжҳҜж•ҙдёӘжӯЈеҲҷиЎЁиҫҫејҸгҖӮ
(...) е°ҶжӯЈеҲҷиЎЁиҫҫејҸеҲҶз»„пјҢжҜҸдёӘеҲҶз»„дёәдёҖдёӘж•ҙдҪ“пјҢе°Ҷдјҳе…Ҳиҝ”еӣһеҲҶз»„еҶ…зҡ„ж•°жҚ®
вҖңPythonзҲ¬иҷ«жӯЈеҲҷиЎЁиҫҫејҸжҖҺд№ҲзҗҶи§ЈвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ