жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еңЁи®Ёи®әжҹҗдёӘж•°жҚ®еә“ж—¶пјҢеӯҳеӮЁ ( Storage ) е’Ңи®Ўз®— ( Query Engine ) йҖҡеёёжҳҜи®Ёи®әзҡ„зғӯзӮ№пјҢд№ҹжҳҜзҲұеҘҪиҖ…们дәҶи§ЈжҹҗдёӘж•°жҚ®еә“дёҚеҸҜжҲ–зјәзҡ„йғЁеҲҶгҖӮжҜҸдёӘж•°жҚ®еә“йғҪжңүе…¶зӢ¬жңүзҡ„еӯҳеӮЁгҖҒи®Ўз®—ж–№ејҸпјҢд»ҠеӨ©е°ұе’ҢеӣҫеӣҫжқҘеӯҰд№ дёӢеӣҫж•°жҚ®еә“ Nebula Graph зҡ„еӯҳеӮЁйғЁеҲҶгҖӮ
Nebula зҡ„ Storage еҢ…еҗ«дёӨдёӘйғЁеҲҶпјҢ дёҖжҳҜ meta зӣёе…ізҡ„еӯҳеӮЁпјҢ жҲ‘们称д№ӢдёәВ Meta ServiceВ пјҢеҸҰдёҖдёӘжҳҜ data зӣёе…ізҡ„еӯҳеӮЁпјҢ жҲ‘们称д№ӢдёәВ Storage ServiceгҖӮ иҝҷдёӨдёӘжңҚеҠЎжҳҜдёӨдёӘзӢ¬з«Ӣзҡ„иҝӣзЁӢпјҢж•°жҚ®д№ҹе®Ңе…Ёйҡ”зҰ»пјҢеҪ“然йғЁзҪІд№ҹжҳҜеҲҶеҲ«йғЁзҪІпјҢ дёҚиҝҮдёӨиҖ…ж•ҙдҪ“жһ¶жһ„зӣёе·®дёҚеӨ§пјҢжң¬ж–ҮжңҖеҗҺдјҡжҸҗеҲ°иҝҷзӮ№гҖӮ еҰӮжһңжІЎжңүзү№ж®ҠиҜҙжҳҺпјҢжң¬ж–ҮдёӯВ Storage Service д»ЈжҢҮ data зҡ„еӯҳеӮЁжңҚеҠЎгҖӮжҺҘдёӢжқҘпјҢеӨ§е®¶е°ұйҡҸжҲ‘дёҖиө·зңӢдёҖдёӢ Storage Service зҡ„ж•ҙдёӘжһ¶жһ„гҖӮ Let's go~
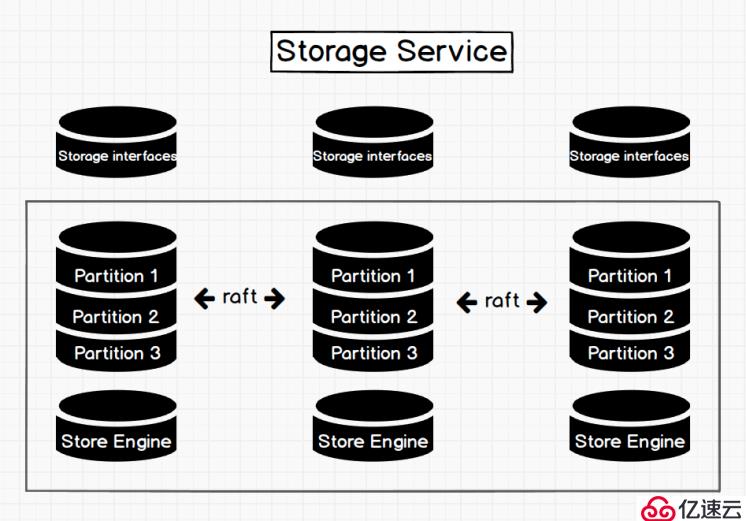 В еӣҫдёҖВ storage service жһ¶жһ„еӣҫ
В еӣҫдёҖВ storage service жһ¶жһ„еӣҫ
еҰӮеӣҫ1 жүҖзӨәпјҢStorage Service е…ұжңүдёүеұӮпјҢжңҖеә•еұӮжҳҜ Store EngineпјҢе®ғжҳҜдёҖдёӘеҚ•жңәзүҲ local store engineпјҢжҸҗдҫӣдәҶеҜ№жң¬ең°ж•°жҚ®зҡ„В getВ /В putВ /В scanВ /В deleteВ ж“ҚдҪңпјҢзӣёе…ізҡ„жҺҘеҸЈж”ҫеңЁ KVStore / KVEngine.h йҮҢйқўпјҢз”ЁжҲ·е®Ңе…ЁеҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„йңҖжұӮе®ҡеҲ¶ејҖеҸ‘зӣёе…і local store pluginпјҢзӣ®еүҚ Nebula жҸҗдҫӣдәҶеҹәдәҺ RocksDB е®һзҺ°зҡ„В Store EngineгҖӮ
еңЁ local store engine д№ӢдёҠпјҢдҫҝжҳҜжҲ‘们зҡ„ Consensus еұӮпјҢе®һзҺ°дәҶ Multi Group RaftпјҢжҜҸдёҖдёӘ Partition йғҪеҜ№еә”дәҶдёҖз»„ Raft GroupпјҢиҝҷйҮҢзҡ„ Partition дҫҝжҳҜжҲ‘们зҡ„ж•°жҚ®еҲҶзүҮгҖӮзӣ®еүҚ Nebula зҡ„еҲҶзүҮзӯ–з•ҘйҮҮз”ЁдәҶВ йқҷжҖҒ HashВ зҡ„ж–№ејҸпјҢе…·дҪ“жҢүз…§д»Җд№Ҳж–№ејҸиҝӣиЎҢ HashпјҢеңЁдёӢдёҖдёӘз« иҠӮ schema йҮҢдјҡжҸҗеҸҠгҖӮз”ЁжҲ·еңЁеҲӣе»ә SPACE ж—¶йңҖжҢҮе®ҡ Partition ж•°пјҢPartition ж•°йҮҸдёҖж—Ұи®ҫзҪ®дҫҝдёҚеҸҜжӣҙж”№пјҢдёҖиҲ¬жқҘи®ІпјҢPartition ж•°зӣ®иҰҒиғҪж»Ўи¶ідёҡеҠЎе°ҶжқҘзҡ„жү©е®№йңҖжұӮгҖӮ
еңЁ Consensus еұӮдёҠйқўд№ҹе°ұжҳҜ Storage Service зҡ„жңҖдёҠеұӮпјҢдҫҝжҳҜжҲ‘们зҡ„ Storage interfacesпјҢиҝҷдёҖеұӮе®ҡд№үдәҶдёҖзі»еҲ—е’Ңеӣҫзӣёе…ізҡ„ APIгҖӮ иҝҷдәӣ API иҜ·жұӮдјҡеңЁиҝҷдёҖеұӮиў«зҝ»иҜ‘жҲҗдёҖз»„й’ҲеҜ№зӣёеә” Partition зҡ„ kv ж“ҚдҪңгҖӮжӯЈжҳҜиҝҷдёҖеұӮзҡ„еӯҳеңЁпјҢдҪҝеҫ—жҲ‘们зҡ„еӯҳеӮЁжңҚеҠЎеҸҳжҲҗдәҶзңҹжӯЈзҡ„еӣҫеӯҳеӮЁпјҢеҗҰеҲҷпјҢStorage Service еҸӘжҳҜдёҖдёӘ kv еӯҳеӮЁзҪўдәҶгҖӮиҖҢ Nebula жІЎжҠҠ kv дҪңдёәдёҖдёӘжңҚеҠЎеҚ•зӢ¬жҸҗеҮәпјҢе…¶жңҖдё»иҰҒзҡ„еҺҹеӣ дҫҝжҳҜеӣҫжҹҘиҜўиҝҮзЁӢдёӯдјҡж¶үеҸҠеҲ°еӨ§йҮҸи®Ўз®—пјҢиҝҷдәӣи®Ўз®—еҫҖеҫҖйңҖиҰҒдҪҝз”Ёеӣҫзҡ„ schemaпјҢиҖҢ kv еұӮжҳҜжІЎжңүж•°жҚ® schema жҰӮеҝөпјҢиҝҷж ·и®ҫи®ЎдјҡжҜ”иҫғе®№жҳ“е®һзҺ°и®Ўз®—дёӢжҺЁгҖӮ
еӣҫеӯҳеӮЁзҡ„дё»иҰҒж•°жҚ®жҳҜзӮ№е’Ңиҫ№пјҢдҪҶ Nebula еӯҳеӮЁзҡ„ж•°жҚ®жҳҜдёҖеј еұһжҖ§еӣҫпјҢд№ҹе°ұжҳҜиҜҙйҷӨдәҶзӮ№е’Ңиҫ№д»ҘеӨ–пјҢNebula иҝҳеӯҳеӮЁдәҶе®ғ们еҜ№еә”зҡ„еұһжҖ§пјҢд»Ҙдҫҝжӣҙй«ҳж•Ҳең°дҪҝз”ЁеұһжҖ§иҝҮж»ӨгҖӮ
еҜ№дәҺзӮ№жқҘиҜҙпјҢжҲ‘们дҪҝз”ЁдёҚеҗҢзҡ„ Tag иЎЁзӨәдёҚеҗҢзұ»еһӢзҡ„зӮ№пјҢеҗҢдёҖдёӘ VertexID еҸҜд»Ҙе…іиҒ”еӨҡдёӘ TagпјҢиҖҢжҜҸдёҖдёӘ Tag йғҪжңүиҮӘе·ұеҜ№еә”зҡ„еұһжҖ§гҖӮеҜ№еә”еҲ° kv еӯҳеӮЁйҮҢйқўпјҢжҲ‘们дҪҝз”Ё vertexID + TagID жқҘиЎЁзӨә key,В жҲ‘们жҠҠзӣёе…ізҡ„еұһжҖ§зј–з ҒеҗҺж”ҫеңЁ value йҮҢйқўпјҢе…·дҪ“ key зҡ„ format еҰӮеӣҫ2 жүҖзӨәпјҡ
 В еӣҫдәҢ Vertex Key Format
В еӣҫдәҢ Vertex Key Format
TypeВ :В 1 дёӘеӯ—иҠӮпјҢз”ЁжқҘиЎЁзӨә key зұ»еһӢпјҢеҪ“еүҚзҡ„зұ»еһӢжңү data, index, system зӯү
Part IDВ : 3 дёӘеӯ—иҠӮпјҢз”ЁжқҘиЎЁзӨәж•°жҚ®еҲҶзүҮ PartitionпјҢжӯӨеӯ—ж®өдё»иҰҒз”ЁдәҺВ Partition йҮҚж–°еҲҶеёғ(balance)В ж—¶ж–№дҫҝж №жҚ®еүҚзјҖжү«жҸҸж•ҙдёӘ Partition ж•°жҚ®
Vertex IDВ : 4 дёӘеӯ—иҠӮпјҢ з”ЁжқҘиЎЁзӨәзӮ№зҡ„ ID
Tag IDВ : 4 дёӘеӯ—иҠӮ, з”ЁжқҘиЎЁзӨәе…іиҒ”зҡ„жҹҗдёӘ tag
TimestampВ : 8 дёӘеӯ—иҠӮпјҢеҜ№з”ЁжҲ·дёҚеҸҜи§ҒпјҢжңӘжқҘе®һзҺ°еҲҶеёғејҸдәӢеҠЎ ( MVCC ) ж—¶дҪҝз”Ё
еңЁдёҖдёӘеӣҫдёӯпјҢжҜҸдёҖжқЎйҖ»иҫ‘ж„Ҹд№үдёҠзҡ„иҫ№пјҢеңЁ NebulaВ Graph дёӯдјҡе»әжЁЎжҲҗдёӨдёӘзӢ¬з«Ӣзҡ„ key-valueпјҢеҲҶеҲ«з§°дёә out-key е’Ңin-keyгҖӮout-key дёҺиҝҷжқЎиҫ№жүҖеҜ№еә”зҡ„иө·зӮ№еӯҳеӮЁеңЁеҗҢдёҖдёӘ partition дёҠпјҢin-key дёҺиҝҷжқЎиҫ№жүҖеҜ№еә”зҡ„з»ҲзӮ№еӯҳеӮЁеңЁеҗҢдёҖдёӘpartition дёҠгҖӮйҖҡеёёжқҘиҜҙпјҢout-key е’Ң in-key дјҡеҲҶеёғеңЁдёӨдёӘдёҚеҗҢзҡ„ Partition дёӯгҖӮ
дёӨдёӘзӮ№д№Ӣй—ҙеҸҜиғҪеӯҳеңЁеӨҡз§Қзұ»еһӢзҡ„иҫ№пјҢNebula з”Ё Edge TypeВ жқҘиЎЁзӨәиҫ№зұ»еһӢгҖӮиҖҢеҗҢдёҖзұ»еһӢзҡ„иҫ№еҸҜиғҪеӯҳеңЁеӨҡжқЎпјҢжҜ”еҰӮпјҢе®ҡд№үдёҖдёӘ edge type "иҪ¬иҙҰ"пјҢз”ЁжҲ·В A еҸҜиғҪеӨҡж¬ЎиҪ¬иҙҰз»ҷ BпјҢ жүҖд»Ҙ Nebula еҸҲеўһеҠ дәҶдёҖдёӘ Rank еӯ—ж®өжқҘеҒҡеҢәеҲҶпјҢиЎЁзӨә A еҲ° B д№Ӣй—ҙеӨҡж¬ЎиҪ¬иҙҰи®°еҪ•гҖӮВ EdgeВ key зҡ„В format еҰӮеӣҫ3 жүҖзӨәпјҡ
 В еӣҫдёү Edge Key Format
В еӣҫдёү Edge Key Format
TypeВ :В 1 дёӘеӯ—иҠӮпјҢз”ЁжқҘиЎЁзӨә key зҡ„зұ»еһӢпјҢеҪ“еүҚзҡ„зұ»еһӢжңү data, index, system зӯүгҖӮ
Part IDВ : 3 дёӘеӯ—иҠӮпјҢз”ЁжқҘиЎЁзӨәж•°жҚ®еҲҶзүҮ PartitionпјҢжӯӨеӯ—ж®өдё»иҰҒз”ЁдәҺВ Partition йҮҚж–°еҲҶеёғ(balance)В ж—¶ж–№дҫҝж №жҚ®еүҚзјҖжү«жҸҸж•ҙдёӘ Partition ж•°жҚ®
Vertex IDВ : 4 дёӘеӯ—иҠӮпјҢ еҮәиҫ№йҮҢйқўз”ЁжқҘиЎЁзӨәжәҗзӮ№зҡ„ IDпјҢ е…Ҙиҫ№йҮҢйқўиЎЁзӨәзӣ®ж ҮзӮ№зҡ„ IDгҖӮ
Edge TypeВ : 4 дёӘеӯ—иҠӮ, з”ЁжқҘиЎЁзӨәиҝҷжқЎиҫ№зҡ„зұ»еһӢпјҢеҰӮжһңеӨ§дәҺ 0 иЎЁзӨәеҮәиҫ№пјҢе°ҸдәҺ 0 иЎЁзӨәе…Ҙиҫ№гҖӮ
RankВ : 4 дёӘеӯ—иҠӮпјҢз”ЁжқҘеӨ„зҗҶеҗҢдёҖз§Қзұ»еһӢзҡ„иҫ№еӯҳеңЁеӨҡжқЎзҡ„жғ…еҶөгҖӮз”ЁжҲ·еҸҜд»Ҙж №жҚ®иҮӘе·ұзҡ„йңҖжұӮиҝӣиЎҢи®ҫзҪ®пјҢиҝҷдёӘеӯ—ж®өеҸҜ_еӯҳж”ҫдәӨжҳ“ж—¶й—ҙ_гҖҒдәӨжҳ“жөҒж°ҙеҸ·гҖҒжҲ–_жҹҗдёӘжҺ’еәҸжқғйҮҚ_
Vertex IDВ : 4 дёӘеӯ—иҠӮ,В В еҮәиҫ№йҮҢйқўз”ЁжқҘиЎЁзӨәзӣ®ж ҮзӮ№зҡ„ IDпјҢ е…Ҙиҫ№йҮҢйқўиЎЁзӨәжәҗзӮ№зҡ„ IDгҖӮ
TimestampВ : 8 дёӘеӯ—иҠӮпјҢеҜ№з”ЁжҲ·дёҚеҸҜи§ҒпјҢжңӘжқҘе®һзҺ°еҲҶеёғејҸеҒҡдәӢеҠЎзҡ„ж—¶еҖҷдҪҝз”ЁгҖӮ
й’ҲеҜ№ Edge Type зҡ„еҖјпјҢиӢҘеҰӮжһңеӨ§дәҺ 0 иЎЁзӨәеҮәиҫ№пјҢеҲҷеҜ№еә”зҡ„ edge key format еҰӮеӣҫ4 жүҖзӨәпјӣиӢҘ Edge Type зҡ„еҖје°ҸдәҺ 0пјҢеҲҷеҜ№еә”зҡ„ edge key format еҰӮеӣҫ5 жүҖзӨә
 В еӣҫ4 еҮәиҫ№зҡ„ Key FormatВ
В еӣҫ4 еҮәиҫ№зҡ„ Key FormatВ  В еӣҫ5 е…Ҙиҫ№зҡ„ Key Format
В еӣҫ5 е…Ҙиҫ№зҡ„ Key Format
еҜ№дәҺзӮ№жҲ–иҫ№зҡ„еұһжҖ§дҝЎжҒҜпјҢжңүеҜ№еә”зҡ„дёҖз»„ kv pairsпјҢNebula е°Ҷе®ғ们编з ҒеҗҺеӯҳеңЁеҜ№еә”зҡ„ value йҮҢгҖӮз”ұдәҺ Nebula дҪҝз”Ёејәзұ»еһӢ schemaпјҢжүҖд»ҘеңЁи§Јз Ғд№ӢеүҚпјҢйңҖиҰҒе…ҲеҺ» Meta Service дёӯеҸ–е…·дҪ“зҡ„ schema дҝЎжҒҜгҖӮеҸҰеӨ–пјҢдёәдәҶж”ҜжҢҒеңЁзәҝеҸҳжӣҙ schemaпјҢеңЁзј–з ҒеұһжҖ§ж—¶пјҢдјҡеҠ е…ҘеҜ№еә”зҡ„ schema зүҲжң¬дҝЎжҒҜпјҢе…·дҪ“зҡ„зј–и§Јз Ғз»ҶиҠӮеңЁиҝҷйҮҢдёҚдҪңеұ•ејҖпјҢеҗҺз»ӯдјҡжңүдё“й—Ёзҡ„ж–Үз« и®Іи§Јиҝҷеқ—еҶ…е®№гҖӮ
OKпјҢеҲ°иҝҷйҮҢжҲ‘们еҹәжң¬дёҠдәҶи§ЈдәҶ Nebula жҳҜеҰӮдҪ•еӯҳеӮЁж•°жҚ®зҡ„пјҢйӮЈж•°жҚ®жҳҜеҰӮдҪ•иҝӣиЎҢеҲҶзүҮе‘ўпјҹеҫҲз®ҖеҚ•пјҢеҜ№ Vertex IDВ еҸ–жЁЎВ еҚіеҸҜгҖӮйҖҡиҝҮеҜ№ Vertex ID еҸ–жЁЎпјҢеҗҢдёҖдёӘзӮ№зҡ„жүҖжңү_еҮәиҫ№_пјҢ_е…Ҙиҫ№_д»ҘеҸҠиҝҷдёӘзӮ№дёҠжүҖжңүе…іиҒ”зҡ„В _Tag дҝЎжҒҜ_йғҪдјҡиў«еҲҶеҲ°еҗҢдёҖдёӘ PartitionпјҢиҝҷз§Қж–№ејҸеӨ§еӨ§ең°жҸҗеҚҮдәҶжҹҘиҜўж•ҲзҺҮгҖӮеҜ№дәҺеңЁзәҝеӣҫжҹҘиҜўжқҘи®ІпјҢжңҖеёёи§Ғзҡ„ж“ҚдҪңдҫҝжҳҜд»ҺдёҖдёӘзӮ№ејҖе§Ӣеҗ‘еӨ– BFSпјҲе№ҝеәҰдјҳе…ҲпјүжӢ“еұ•пјҢдәҺжҳҜжӢҝдёҖдёӘзӮ№зҡ„еҮәиҫ№жҲ–иҖ…е…Ҙиҫ№жҳҜжңҖеҹәжң¬зҡ„ж“ҚдҪңпјҢиҖҢиҝҷдёӘж“ҚдҪңзҡ„жҖ§иғҪд№ҹеҶіе®ҡдәҶж•ҙдёӘйҒҚеҺҶзҡ„жҖ§иғҪгҖӮBFS дёӯеҸҜиғҪдјҡеҮәзҺ°жҢүз…§жҹҗдәӣеұһжҖ§иҝӣиЎҢеүӘжһқзҡ„жғ…еҶөпјҢNebula йҖҡиҝҮе°ҶеұһжҖ§дёҺзӮ№иҫ№еӯҳеңЁдёҖиө·пјҢжқҘдҝқиҜҒж•ҙдёӘж“ҚдҪңзҡ„й«ҳж•ҲгҖӮеҪ“еүҚи®ёеӨҡзҡ„еӣҫж•°жҚ®еә“йҖҡиҝҮВ Graph 500 жҲ–иҖ… Twitter зҡ„ж•°жҚ®йӣҶиҜ•жқҘйӘҢиҜҒиҮӘе·ұзҡ„й«ҳж•ҲжҖ§пјҢиҝҷ并没жңүд»ЈиЎЁжҖ§пјҢеӣ дёәиҝҷдәӣж•°жҚ®йӣҶжІЎжңүеұһжҖ§пјҢиҖҢе®һйҷ…зҡ„еңәжҷҜдёӯеӨ§йғЁеҲҶжғ…еҶөйғҪжҳҜеұһжҖ§еӣҫпјҢ并且е®һйҷ…дёӯзҡ„ BFS д№ҹйңҖиҰҒиҝӣиЎҢеӨ§йҮҸзҡ„еүӘжһқж“ҚдҪңгҖӮ
дёәд»Җд№ҲиҰҒиҮӘе·ұеҒҡ KVStoreпјҢиҝҷжҳҜжҲ‘д»¬ж— ж•°ж¬Ўиў«й—®иө·зҡ„й—®йўҳгҖӮзҗҶз”ұеҫҲз®ҖеҚ•пјҢеҪ“еүҚејҖжәҗзҡ„ KVStore йғҪеҫҲйҡҫж»Ўи¶іжҲ‘们зҡ„иҰҒжұӮпјҡ
жҖ§иғҪпјҢжҖ§иғҪпјҢжҖ§иғҪпјҡNebula зҡ„йңҖжұӮеҫҲзӣҙжҺҘпјҡй«ҳжҖ§иғҪ pure kvпјӣ
д»Ҙ library зҡ„еҪўејҸжҸҗдҫӣпјҡеҜ№дәҺејә schema зҡ„ Nebula жқҘи®ІпјҢи®Ўз®—дёӢжҺЁйңҖиҰҒ schema дҝЎжҒҜпјҢиҖҢи®Ўз®—дёӢжҺЁе®һзҺ°зҡ„еҘҪеқҸпјҢжҳҜ Nebula жҳҜеҗҰй«ҳж•Ҳзҡ„е…ій”®пјӣ
ж•°жҚ®ејәдёҖиҮҙпјҡиҝҷжҳҜеҲҶеёғејҸзі»з»ҹеҶіе®ҡзҡ„пјӣ
дҪҝз”Ё C++е®һзҺ°пјҡиҝҷз”ұеӣўйҳҹзҡ„жҠҖжңҜзү№зӮ№еҶіе®ҡпјӣ
еҹәдәҺдёҠиҝ°иҰҒжұӮпјҢNebula е®һзҺ°дәҶиҮӘе·ұзҡ„ KVStoreгҖӮеҪ“然пјҢеҜ№дәҺжҖ§иғҪе®Ңе…ЁдёҚж•Ҹж„ҹдё”дёҚеӨӘеёҢжңӣжҗ¬иҝҒж•°жҚ®зҡ„з”ЁжҲ·жқҘиҜҙпјҢNebula д№ҹжҸҗдҫӣдәҶж•ҙдёӘKVStore еұӮзҡ„ pluginпјҢзӣҙжҺҘе°Ҷ Storage Service жҗӯе»әеңЁз¬¬дёүж–№зҡ„ KVStore дёҠйқўпјҢзӣ®еүҚе®ҳж–№жҸҗдҫӣзҡ„жҳҜ HBase зҡ„ pluginгҖӮ
Nebula KVStore дё»иҰҒйҮҮз”Ё RocksDB дҪңдёәжң¬ең°зҡ„еӯҳеӮЁеј•ж“ҺпјҢеҜ№дәҺеӨҡзЎ¬зӣҳжңәеҷЁпјҢдёәдәҶе……еҲҶеҲ©з”ЁеӨҡзЎ¬зӣҳзҡ„并еҸ‘иғҪеҠӣпјҢNebula ж”ҜжҢҒиҮӘе·ұз®ЎзҗҶеӨҡеқ—зӣҳпјҢз”ЁжҲ·еҸӘйңҖй…ҚзҪ®еӨҡдёӘдёҚеҗҢзҡ„ж•°жҚ®зӣ®еҪ•еҚіеҸҜгҖӮеҲҶеёғејҸ KVStore зҡ„з®ЎзҗҶз”ұ Meta Service жқҘз»ҹдёҖи°ғеәҰпјҢе®ғи®°еҪ•дәҶжүҖжңү Partition зҡ„еҲҶеёғжғ…еҶөпјҢд»ҘеҸҠеҪ“еүҚжңәеҷЁзҡ„зҠ¶жҖҒпјҢеҪ“з”ЁжҲ·еўһеҮҸжңәеҷЁж—¶пјҢеҸӘйңҖиҰҒйҖҡиҝҮ console иҫ“е…Ҙзӣёеә”зҡ„жҢҮд»ӨпјҢMeta Service дҫҝиғҪеӨҹз”ҹжҲҗж•ҙдёӘ balance plan 并жү§иЎҢгҖӮпјҲд№ӢжүҖд»ҘжІЎжңүйҮҮз”Ёе®Ңе…ЁиҮӘеҠЁ balance зҡ„ж–№ејҸпјҢдё»иҰҒжҳҜдёәдәҶеҮҸе°‘ж•°жҚ®жҗ¬иҝҒеҜ№дәҺзәҝдёҠжңҚеҠЎзҡ„еҪұе“ҚпјҢbalance зҡ„ж—¶жңәз”ұз”ЁжҲ·иҮӘе·ұжҺ§еҲ¶гҖӮпјү
дёәдәҶж–№дҫҝеҜ№дәҺ WAL иҝӣиЎҢе®ҡеҲ¶пјҢNebula KVStore е®һзҺ°дәҶиҮӘе·ұзҡ„ WAL жЁЎеқ—пјҢжҜҸдёӘ partition йғҪжңүиҮӘе·ұзҡ„ WALпјҢиҝҷж ·еңЁиҝҪж•°жҚ®ж—¶пјҢдёҚйңҖиҰҒиҝӣиЎҢ wal split ж“ҚдҪңпјҢ жӣҙеҠ й«ҳж•ҲгҖӮ еҸҰеӨ–пјҢдёәдәҶе®һзҺ°дёҖдәӣзү№ж®Ҡзҡ„ж“ҚдҪңпјҢдё“й—Ёе®ҡд№үдәҶ Command Log иҝҷдёӘзұ»еҲ«пјҢиҝҷдәӣ log еҸӘдёәдәҶдҪҝз”Ё Raft жқҘйҖҡзҹҘжүҖжңү replica жү§иЎҢжҹҗдёҖдёӘзү№е®ҡж“ҚдҪңпјҢ并没жңүзңҹжӯЈзҡ„ж•°жҚ®гҖӮйҷӨдәҶ Command Log еӨ–пјҢNebula иҝҳжҸҗдҫӣдәҶдёҖзұ»ж—Ҙеҝ—жқҘе®һзҺ°й’ҲеҜ№жҹҗдёӘ Partition зҡ„ atomic operationпјҢдҫӢеҰӮ CASпјҢread-modify-write,В е®ғе……еҲҶеҲ©з”ЁдәҶRaft дёІиЎҢзҡ„зү№жҖ§гҖӮ
е…ідәҺеӨҡеӣҫз©әй—ҙпјҲspaceпјүзҡ„ж”ҜжҢҒпјҡдёҖдёӘ Nebula KVStore йӣҶзҫӨеҸҜд»Ҙж”ҜжҢҒеӨҡдёӘ spaceпјҢжҜҸдёӘ space еҸҜи®ҫзҪ®иҮӘе·ұзҡ„ partition ж•°е’Ң replica ж•°гҖӮдёҚеҗҢ space еңЁзү©зҗҶдёҠжҳҜе®Ңе…Ёйҡ”зҰ»зҡ„пјҢиҖҢдё”еңЁеҗҢдёҖдёӘйӣҶзҫӨдёҠзҡ„дёҚеҗҢ space еҸҜж”ҜжҢҒдёҚеҗҢзҡ„ store engine еҸҠеҲҶзүҮзӯ–з•ҘгҖӮ
дҪңдёәдёҖдёӘеҲҶеёғејҸзі»з»ҹпјҢKVStore зҡ„ replicationпјҢscale out зӯүеҠҹиғҪйңҖ Raft зҡ„ж”ҜжҢҒгҖӮеҪ“еүҚпјҢеёӮйқўдёҠи®І Raft зҡ„ж–Үз« йқһеёёеӨҡпјҢе…·дҪ“еҺҹзҗҶжҖ§зҡ„еҶ…е®№пјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°пјҢжң¬ж–Үдё»иҰҒиҜҙдёҖдәӣ Nebula Raft зҡ„дёҖдәӣзү№зӮ№д»ҘеҸҠе·ҘзЁӢе®һзҺ°гҖӮ
з”ұдәҺ Raft зҡ„ж—Ҙеҝ—дёҚе…Ғи®ёз©әжҙһпјҢеҮ д№ҺжүҖжңүзҡ„е®һзҺ°йғҪдјҡйҮҮз”Ё Multi Raft Group жқҘзј“и§ЈиҝҷдёӘй—®йўҳпјҢеӣ жӯӨ partition зҡ„ж•°зӣ®еҮ д№ҺеҶіе®ҡдәҶж•ҙдёӘ Raft Group зҡ„жҖ§иғҪгҖӮдҪҶиҝҷд№ҹ并дёҚжҳҜиҜҙ Partition зҡ„ж•°зӣ®и¶ҠеӨҡи¶ҠеҘҪпјҡжҜҸдёҖдёӘ Raft Group еҶ…йғЁйғҪиҰҒеӯҳеӮЁдёҖзі»еҲ—зҡ„зҠ¶жҖҒдҝЎжҒҜпјҢ并且жҜҸдёҖдёӘ Raft Group жңүиҮӘе·ұзҡ„ WAL ж–Ү件пјҢеӣ жӯӨВ Partition ж•°зӣ®еӨӘеӨҡдјҡеўһеҠ ејҖй”ҖгҖӮжӯӨеӨ–пјҢеҪ“ Partition еӨӘеӨҡж—¶пјҢ еҰӮжһңиҙҹиҪҪжІЎжңүи¶іеӨҹй«ҳпјҢbatch ж“ҚдҪңжҳҜжІЎжңүж„Ҹд№үзҡ„гҖӮжҜ”еҰӮпјҢдёҖдёӘжңү 1w tps зҡ„зәҝдёҠзі»з»ҹеҚ•жңәпјҢе®ғзҡ„еҚ•жңә partition зҡ„ж•°зӣ®и¶…иҝҮ 1wпјҢеҸҜиғҪжҜҸдёӘ Partition жҜҸз§’зҡ„ tps еҸӘжңү 1пјҢиҝҷж · batch ж“ҚдҪңе°ұеӨұеҺ»дәҶж„Ҹд№үпјҢиҝҳеўһеҠ дәҶ CPU ејҖй”ҖгҖӮ е®һзҺ° Multi Raft Group зҡ„жңҖе…ій”®д№ӢеӨ„жңүдёӨзӮ№пјҢ** 第дёҖжҳҜе…ұдә« Transport еұӮ**пјҢеӣ дёәжҜҸдёҖдёӘ Raft Group еҶ…йғЁйғҪйңҖиҰҒеҗ‘еҜ№еә”зҡ„ peerВ еҸ‘йҖҒж¶ҲжҒҜпјҢеҰӮжһңдёҚиғҪе…ұдә« Transport еұӮпјҢиҝһжҺҘзҡ„ејҖй”Җе·ЁеӨ§пјӣ第дәҢжҳҜзәҝзЁӢжЁЎеһӢпјҢMutli Raft Group дёҖе®ҡиҰҒе…ұдә«дёҖз»„зәҝзЁӢжұ пјҢеҗҰеҲҷдјҡйҖ жҲҗзі»з»ҹзҡ„зәҝзЁӢж•°зӣ®иҝҮеӨҡпјҢеҜјиҮҙеӨ§йҮҸзҡ„ context switch ејҖй”ҖгҖӮ
еҜ№дәҺжҜҸдёӘ PartitionжқҘиҜҙпјҢз”ұдәҺдёІиЎҢеҶҷ WALпјҢдёәдәҶжҸҗй«ҳеҗһеҗҗпјҢеҒҡ batch жҳҜеҚҒеҲҶеҝ…иҰҒзҡ„гҖӮдёҖиҲ¬жқҘи®ІпјҢbatch 并没жңүд»Җд№Ҳзү№еҲ«зҡ„ең°ж–№пјҢдҪҶжҳҜ Nebula еҲ©з”ЁжҜҸдёӘ part дёІиЎҢзҡ„зү№зӮ№пјҢеҒҡдәҶдёҖдәӣзү№ж®Ҡзұ»еһӢзҡ„ WALпјҢеёҰжқҘдәҶдёҖдәӣе·ҘзЁӢдёҠзҡ„жҢ‘жҲҳгҖӮ
дёҫдёӘдҫӢеӯҗпјҢNebula еҲ©з”Ё WAL е®һзҺ°дәҶж— й”Ғзҡ„ CAS ж“ҚдҪңпјҢиҖҢжҜҸдёӘ CAS ж“ҚдҪңйңҖиҰҒд№ӢеүҚзҡ„ WAL е…ЁйғЁ commit д№ӢеҗҺжүҚиғҪжү§иЎҢпјҢжүҖд»ҘеҜ№дәҺдёҖдёӘ batchпјҢеҰӮжһңдёӯй—ҙеӨ№жқӮдәҶеҮ жқЎ CAS зұ»еһӢзҡ„ WAL, жҲ‘们иҝҳйңҖиҰҒжҠҠиҝҷдёӘ batch еҲҶжҲҗзІ’еәҰжӣҙе°Ҹзҡ„еҮ дёӘ groupпјҢgroup д№Ӣй—ҙдҝқиҜҒдёІиЎҢгҖӮиҝҳжңүпјҢcommand зұ»еһӢзҡ„ WAL йңҖиҰҒе®ғеҗҺйқўзҡ„ WAL еңЁе…¶ commit д№ӢеҗҺжүҚиғҪжү§иЎҢпјҢжүҖд»Ҙж•ҙдёӘ batch еҲ’еҲҶ group зҡ„ж“ҚдҪңе·ҘзЁӢе®һзҺ°дёҠжҜ”иҫғжңүзү№иүІгҖӮз„ҰдҪңеӣҪеҢ»иғғиӮ еҢ»йҷўжӯЈи§„еҗ—_еҚ«з”ҹеұҖи®ӨиҜҒ з„ҰдҪңиҖҒе“ҒзүҢпјҡhttps://www.jianshu.com/p/3c43af3bb611
Learner иҝҷдёӘи§’иүІзҡ„еӯҳеңЁдё»иҰҒжҳҜдёәдәҶВ еә”еҜ№жү©е®№В ж—¶пјҢж–°жңәеҷЁйңҖиҰҒ"иҝҪ"зӣёеҪ“й•ҝдёҖж®өж—¶й—ҙзҡ„ж•°жҚ®пјҢиҖҢиҝҷж®өж—¶й—ҙжңүеҸҜиғҪдјҡеҸ‘з”ҹж„ҸеӨ–гҖӮеҰӮжһңзӣҙжҺҘд»Ҙ follower зҡ„иә«д»ҪејҖе§ӢиҝҪж•°жҚ®пјҢе°ұдјҡдҪҝеҫ—ж•ҙдёӘйӣҶзҫӨзҡ„ HA иғҪеҠӣдёӢйҷҚгҖӮ Nebula йҮҢйқў learner зҡ„е®һзҺ°е°ұжҳҜйҮҮз”ЁдәҶдёҠйқўжҸҗеҲ°зҡ„ command walпјҢleader еңЁеҶҷ wal ж—¶еҰӮжһңзў°еҲ° add learner зҡ„ commandпјҢ е°ұдјҡе°Ҷ learner еҠ е…ҘиҮӘе·ұзҡ„ peersпјҢ并жҠҠе®ғж Үи®°дёә learnerпјҢиҝҷж ·еңЁз»ҹи®ЎеӨҡж•°жҙҫзҡ„ж—¶еҖҷпјҢе°ұдёҚдјҡз®—дёҠ learnerпјҢдҪҶжҳҜж—Ҙеҝ—иҝҳжҳҜдјҡз…§еёёеҸ‘йҖҒз»ҷе®ғ们гҖӮеҪ“然 learner д№ҹдёҚдјҡдё»еҠЁеҸ‘иө·йҖүдёҫгҖӮ
Transfer leadership иҝҷдёӘж“ҚдҪңеҜ№дәҺ balance жқҘи®ІиҮіе…ійҮҚиҰҒпјҢеҪ“жҲ‘们жҠҠжҹҗдёӘВ ParititionВ д»ҺдёҖеҸ°жңәеҷЁжҢӘеҲ°еҸҰдёҖеҸ°жңәеҷЁж—¶пјҢйҰ–е…ҲдҫҝдјҡжЈҖжҹҘ source жҳҜдёҚжҳҜ leaderпјҢеҰӮжһңжҳҜзҡ„иҜқпјҢйңҖиҰҒе…ҲжҠҠд»–жҢӘеҲ°еҸҰеӨ–зҡ„ peer дёҠйқўпјӣеңЁжҗ¬иҝҒж•°жҚ®е®ҢжҜ•д№ӢеҗҺпјҢйҖҡеёёиҝҳиҰҒжҠҠ leader иҝӣиЎҢдёҖж¬Ў balanceпјҢиҝҷж ·жҜҸеҸ°жңәеҷЁжүҝжӢ…зҡ„иҙҹиҪҪд№ҹиғҪдҝқиҜҒеқҮиЎЎгҖӮ
е®һзҺ° transfer leadershipпјҢ йңҖиҰҒжіЁж„Ҹзҡ„жҳҜ leader ж”ҫејғиҮӘе·ұзҡ„ leadershipпјҢе’Ң follower ејҖе§ӢиҝӣиЎҢ leader election зҡ„ж—¶жңәгҖӮеҜ№дәҺ leader жқҘи®ІпјҢеҪ“ transfer leadership command еңЁ commit зҡ„ж—¶еҖҷпјҢе®ғж”ҫејғ leadershipпјӣиҖҢеҜ№дәҺ follower жқҘи®ІпјҢеҪ“收еҲ°жӯӨ command зҡ„ж—¶еҖҷе°ұиҰҒејҖе§ӢиҝӣиЎҢ leader electionпјҢ иҝҷеҘ—е®һзҺ°иҰҒе’Ң Raft жң¬иә«зҡ„ leader election иө°дёҖеҘ—и·Ҝеҫ„пјҢеҗҰеҲҷеҫҲе®№жҳ“еҮәзҺ°дёҖдәӣйҡҫд»ҘеӨ„зҗҶзҡ„ corner caseгҖӮ
дёәдәҶйҒҝе…Қи„‘иЈӮпјҢеҪ“дёҖдёӘ Raft Group зҡ„жҲҗе‘ҳеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢйңҖиҰҒжңүдёҖдёӘдёӯй—ҙзҠ¶жҖҒпјҢ иҝҷдёӘзҠ¶жҖҒдёӢ old group зҡ„еӨҡж•°жҙҫдёҺ new group зҡ„еӨҡж•°жҙҫжҖ»жҳҜжңү overlapпјҢиҝҷж ·е°ұйҳІжӯўдәҶ old group жҲ–иҖ…ж–° group еҚ•ж–№йқўеҒҡеҮәеҶіе®ҡпјҢиҝҷе°ұжҳҜи®әж–ҮдёӯжҸҗеҲ°зҡ„В joint consensusВ гҖӮдёәдәҶжӣҙеҠ з®ҖеҢ–пјҢDiego Ongaro еңЁиҮӘе·ұзҡ„еҚҡеЈ«и®әж–ҮдёӯжҸҗеҮәжҜҸж¬ЎеўһеҮҸдёҖдёӘ peer зҡ„ж–№ејҸпјҢд»ҘдҝқиҜҒ old group зҡ„еӨҡж•°жҙҫжҖ»жҳҜдёҺ new group зҡ„еӨҡж•°жҙҫжңү overlapгҖӮ Nebula зҡ„е®һзҺ°д№ҹйҮҮз”ЁдәҶиҝҷдёӘж–№ејҸпјҢеҸӘдёҚиҝҮ add member дёҺ remove member зҡ„е®һзҺ°жңүжүҖеҢәеҲ«пјҢе…·дҪ“е®һзҺ°ж–№ејҸжң¬ж–ҮдёҚдҪңи®Ёи®әпјҢжңүе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘеҸӮиҖғ Raft Part class йҮҢйқўВ addPeerВ /В В removePeerВ зҡ„е®һзҺ°гҖӮ
Snapshot еҰӮдҪ•дёҺ Raft жөҒзЁӢз»“еҗҲиө·жқҘпјҢи®әж–Үдёӯ并没жңүз»Ҷи®ІпјҢдҪҶжҳҜиҝҷдёҖйғЁеҲҶжҲ‘и®ӨдёәжҳҜдёҖдёӘ Raft е®һзҺ°йҮҢжңҖе®№жҳ“еҮәй”ҷзҡ„ең°ж–№пјҢеӣ дёәиҝҷйҮҢдјҡдә§з”ҹеӨ§йҮҸзҡ„ corner caseгҖӮ
дёҫдёҖдёӘдҫӢеӯҗпјҢеҪ“ leader еҸ‘йҖҒ snapshot иҝҮзЁӢдёӯпјҢеҰӮжһң leader еҸ‘з”ҹдәҶеҸҳеҢ–пјҢиҜҘжҖҺд№ҲеҠһпјҹ иҝҷдёӘж—¶еҖҷпјҢжңүеҸҜиғҪ follower еҸӘжҺҘеҲ°дәҶдёҖеҚҠзҡ„ snapshot ж•°жҚ®гҖӮ жүҖд»ҘйңҖиҰҒжңүдёҖдёӘВ Partition ж•°жҚ®жё…зҗҶиҝҮзЁӢпјҢз”ұдәҺеӨҡдёӘВ PartitionВ е…ұдә«дёҖд»ҪеӯҳеӮЁпјҢеӣ жӯӨеҰӮдҪ•жё…зҗҶж•°жҚ®еҸҲжҳҜдёҖдёӘеҫҲйә»зғҰзҡ„й—®йўҳгҖӮеҸҰеӨ–пјҢsnapshot иҝҮзЁӢдёӯпјҢдјҡдә§з”ҹеӨ§йҮҸзҡ„ IOпјҢдёәдәҶжҖ§иғҪиҖғиҷ‘пјҢжҲ‘们дёҚеёҢжңӣиҝҷдёӘиҝҮзЁӢдёҺжӯЈеёёзҡ„ Raft е…ұз”ЁдёҖдёӘ IO threadPoolпјҢ并且ж•ҙдёӘиҝҮзЁӢдёӯпјҢиҝҳйңҖиҰҒдҪҝз”ЁеӨ§йҮҸзҡ„еҶ…еӯҳпјҢеҰӮдҪ•дјҳеҢ–еҶ…еӯҳзҡ„дҪҝз”ЁпјҢеҜ№дәҺжҖ§иғҪеҚҒеҲҶе…ій”®гҖӮз”ұдәҺзҜҮе№…еҺҹеӣ пјҢжҲ‘们并дёҚдјҡеңЁжң¬ж–ҮеҜ№иҝҷдәӣй—®йўҳеұ•ејҖи®Іиҝ°пјҢжңүе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘеҸӮиҖғВ SnapshotManagerВ зҡ„е®һзҺ°гҖӮ
еңЁ KVStore зҡ„жҺҘеҸЈд№ӢдёҠпјҢNebula е°ҒиЈ…жңүеӣҫиҜӯд№үжҺҘеҸЈпјҢдё»иҰҒзҡ„жҺҘеҸЈеҰӮдёӢпјҡ
getNeighborsВ :В жҹҘиҜўдёҖжү№зӮ№зҡ„еҮәиҫ№жҲ–иҖ…е…Ҙиҫ№пјҢиҝ”еӣһиҫ№д»ҘеҸҠеҜ№еә”зҡ„еұһжҖ§пјҢ并且йңҖиҰҒж”ҜжҢҒжқЎд»¶иҝҮж»Өпјӣ
Insert vertex/edgeВ :В жҸ’е…ҘдёҖжқЎзӮ№жҲ–иҖ…иҫ№еҸҠе…¶еұһжҖ§пјӣ
getPropsВ : иҺ·еҸ–дёҖдёӘзӮ№жҲ–иҖ…дёҖжқЎиҫ№зҡ„еұһжҖ§пјӣ
иҝҷдёҖеұӮдјҡе°ҶеӣҫиҜӯд№үзҡ„жҺҘеҸЈиҪ¬еҢ–жҲҗ kv ж“ҚдҪңгҖӮдёәдәҶжҸҗй«ҳйҒҚеҺҶзҡ„жҖ§иғҪпјҢиҝҳиҰҒеҒҡ并еҸ‘ж“ҚдҪңгҖӮ
еңЁ KVStore зҡ„жҺҘеҸЈдёҠпјҢNebula д№ҹеҗҢж—¶е°ҒиЈ…дәҶдёҖеҘ— meta зӣёе…ізҡ„жҺҘеҸЈгҖӮMeta Service дёҚдҪҶжҸҗдҫӣдәҶеӣҫ schema зҡ„еўһеҲ жҹҘж”№зҡ„еҠҹиғҪпјҢиҝҳжҸҗдҫӣдәҶйӣҶзҫӨзҡ„з®ЎзҗҶеҠҹиғҪд»ҘеҸҠз”ЁжҲ·йүҙжқғзӣёе…ізҡ„еҠҹиғҪгҖӮMeta ServiceВ ж”ҜжҢҒеҚ•зӢ¬йғЁзҪІпјҢд№ҹж”ҜжҢҒдҪҝз”ЁеӨҡеүҜжң¬жқҘдҝқиҜҒж•°жҚ®зҡ„е®үе…ЁгҖӮ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еӨ§иҮҙд»Ӣз»ҚдәҶВ Nebula Storage еұӮзҡ„ж•ҙдҪ“и®ҫи®ЎпјҢ з”ұдәҺзҜҮе№…еҺҹеӣ пјҢ еҫҲеӨҡз»ҶиҠӮжІЎжңүеұ•ејҖи®ІпјҢ ж¬ўиҝҺеӨ§е®¶еҲ°жҲ‘们зҡ„еҫ®дҝЎзҫӨйҮҢжҸҗй—®пјҢеҠ е…Ҙ Nebula Graph дәӨжөҒзҫӨпјҢиҜ·иҒ”зі» Nebula Graph е®ҳж–№е°ҸеҠ©жүӢеҫ®дҝЎеҸ·пјҡNebulaGraphbotгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ