жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
RedisдёӯеҶ…йғЁж•°жҚ®з»“жһ„quicklistзҡ„дҪңз”ЁжҳҜд»Җд№ҲпјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
RedisеҜ№еӨ–жҡҙйңІзҡ„дёҠеұӮlistж•°жҚ®зұ»еһӢпјҢз»Ҹеёёиў«з”ЁдҪңйҳҹеҲ—дҪҝз”ЁгҖӮжҜ”еҰӮе®ғж”ҜжҢҒзҡ„еҰӮдёӢдёҖдәӣж“ҚдҪңпјҡ
lpush: еңЁе·Ұдҫ§пјҲеҚіеҲ—иЎЁеӨҙйғЁпјүжҸ’е…Ҙж•°жҚ®гҖӮ
rpop: еңЁеҸідҫ§пјҲеҚіеҲ—иЎЁе°ҫйғЁпјүеҲ йҷӨж•°жҚ®гҖӮ
rpush: еңЁеҸідҫ§пјҲеҚіеҲ—иЎЁе°ҫйғЁпјүжҸ’е…Ҙж•°жҚ®гҖӮ
lpop: еңЁе·Ұдҫ§пјҲеҚіеҲ—иЎЁеӨҙйғЁпјүеҲ йҷӨж•°жҚ®гҖӮ
иҝҷдәӣж“ҚдҪңйғҪжҳҜO(1)ж—¶й—ҙеӨҚжқӮеәҰзҡ„гҖӮ
еҪ“然пјҢlistд№ҹж”ҜжҢҒеңЁд»»ж„Ҹдёӯй—ҙдҪҚзҪ®зҡ„еӯҳеҸ–ж“ҚдҪңпјҢжҜ”еҰӮlindexе’ҢlinsertпјҢдҪҶе®ғ们йғҪйңҖиҰҒеҜ№listиҝӣиЎҢйҒҚеҺҶпјҢжүҖд»Ҙж—¶й—ҙеӨҚжқӮеәҰиҫғй«ҳпјҢдёәO(N)гҖӮ
жҰӮеҶөиө·жқҘпјҢlistе…·жңүиҝҷж ·зҡ„дёҖдәӣзү№зӮ№пјҡе®ғжҳҜдёҖдёӘиғҪз»ҙжҢҒж•°жҚ®йЎ№е…ҲеҗҺйЎәеәҸзҡ„еҲ—иЎЁпјҲеҗ„дёӘж•°жҚ®йЎ№зҡ„е…ҲеҗҺйЎәеәҸз”ұжҸ’е…ҘдҪҚзҪ®еҶіе®ҡпјүпјҢдҫҝдәҺеңЁиЎЁзҡ„дёӨз«ҜиҝҪеҠ е’ҢеҲ йҷӨж•°жҚ®пјҢиҖҢеҜ№дәҺдёӯй—ҙдҪҚзҪ®зҡ„еӯҳеҸ–е…·жңүO(N)зҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮиҝҷдёҚжӯЈжҳҜдёҖдёӘеҸҢеҗ‘й“ҫиЎЁжүҖе…·жңүзҡ„зү№зӮ№еҗ—пјҹ
listзҡ„еҶ…йғЁе®һзҺ°quicklistжӯЈжҳҜдёҖдёӘеҸҢеҗ‘й“ҫиЎЁгҖӮеңЁquicklist.cзҡ„ж–Ү件еӨҙйғЁжіЁйҮҠдёӯпјҢжҳҜиҝҷж ·жҸҸиҝ°quicklistзҡ„пјҡ
A doubly linked list of ziplists
е®ғзЎ®е®һжҳҜдёҖдёӘеҸҢеҗ‘й“ҫиЎЁпјҢиҖҢдё”жҳҜдёҖдёӘziplistзҡ„еҸҢеҗ‘й“ҫиЎЁгҖӮ
иҝҷжҳҜд»Җд№Ҳж„ҸжҖқе‘ўпјҹ
жҲ‘们зҹҘйҒ“пјҢеҸҢеҗ‘й“ҫиЎЁжҳҜз”ұеӨҡдёӘиҠӮзӮ№пјҲNodeпјүз»„жҲҗзҡ„гҖӮиҝҷдёӘжҸҸиҝ°зҡ„ж„ҸжҖқжҳҜпјҡquicklistзҡ„жҜҸдёӘиҠӮзӮ№йғҪжҳҜдёҖдёӘziplistгҖӮziplistжҲ‘们已з»ҸеңЁ дёҠдёҖзҜҮд»Ӣз»ҚиҝҮгҖӮ
ziplistжң¬иә«д№ҹжҳҜдёҖдёӘиғҪз»ҙжҢҒж•°жҚ®йЎ№е…ҲеҗҺйЎәеәҸзҡ„еҲ—иЎЁпјҲжҢүжҸ’е…ҘдҪҚзҪ®пјүпјҢиҖҢдё”жҳҜдёҖдёӘеҶ…еӯҳзҙ§зј©зҡ„еҲ—иЎЁпјҲеҗ„дёӘж•°жҚ®йЎ№еңЁеҶ…еӯҳдёҠеүҚеҗҺзӣёйӮ»пјүгҖӮжҜ”еҰӮпјҢдёҖдёӘеҢ…еҗ«3дёӘиҠӮзӮ№зҡ„quicklistпјҢеҰӮжһңжҜҸдёӘиҠӮзӮ№зҡ„ziplistеҸҲеҢ…еҗ«4дёӘж•°жҚ®йЎ№пјҢйӮЈд№ҲеҜ№еӨ–иЎЁзҺ°дёҠпјҢиҝҷдёӘlistе°ұжҖ»е…ұеҢ…еҗ«12дёӘж•°жҚ®йЎ№гҖӮ
quicklistзҡ„з»“жһ„дёәд»Җд№Ҳиҝҷж ·и®ҫи®Ўе‘ўпјҹжҖ»з»“иө·жқҘпјҢеӨ§жҰӮеҸҲжҳҜдёҖдёӘз©әй—ҙе’Ңж—¶й—ҙзҡ„жҠҳдёӯпјҡ
еҸҢеҗ‘й“ҫиЎЁдҫҝдәҺеңЁиЎЁзҡ„дёӨз«ҜиҝӣиЎҢpushе’Ңpopж“ҚдҪңпјҢдҪҶжҳҜе®ғзҡ„еҶ…еӯҳејҖй”ҖжҜ”иҫғеӨ§гҖӮйҰ–е…ҲпјҢе®ғеңЁжҜҸдёӘиҠӮзӮ№дёҠйҷӨдәҶиҰҒдҝқеӯҳж•°жҚ®д№ӢеӨ–пјҢиҝҳиҰҒйўқеӨ–дҝқеӯҳдёӨдёӘжҢҮй’Ҳпјӣе…¶ж¬ЎпјҢеҸҢеҗ‘й“ҫиЎЁзҡ„еҗ„дёӘиҠӮзӮ№жҳҜеҚ•зӢ¬зҡ„еҶ…еӯҳеқ—пјҢең°еқҖдёҚиҝһз»ӯпјҢиҠӮзӮ№еӨҡдәҶе®№жҳ“дә§з”ҹеҶ…еӯҳзўҺзүҮгҖӮ
ziplistз”ұдәҺжҳҜдёҖж•ҙеқ—иҝһз»ӯеҶ…еӯҳпјҢжүҖд»ҘеӯҳеӮЁж•ҲзҺҮеҫҲй«ҳгҖӮдҪҶжҳҜпјҢе®ғдёҚеҲ©дәҺдҝ®ж”№ж“ҚдҪңпјҢжҜҸж¬Ўж•°жҚ®еҸҳеҠЁйғҪдјҡеј•еҸ‘дёҖж¬ЎеҶ…еӯҳзҡ„reallocгҖӮзү№еҲ«жҳҜеҪ“ziplistй•ҝеәҰеҫҲй•ҝзҡ„ж—¶еҖҷпјҢдёҖж¬ЎreallocеҸҜиғҪдјҡеҜјиҮҙеӨ§жү№йҮҸзҡ„ж•°жҚ®жӢ·иҙқпјҢиҝӣдёҖжӯҘйҷҚдҪҺжҖ§иғҪгҖӮ
дәҺжҳҜпјҢз»“еҗҲдәҶеҸҢеҗ‘й“ҫиЎЁе’Ңziplistзҡ„дјҳзӮ№пјҢquicklistе°ұеә”иҝҗиҖҢз”ҹдәҶгҖӮ
дёҚиҝҮпјҢиҝҷд№ҹеёҰжқҘдәҶдёҖдёӘж–°й—®йўҳпјҡеҲ°еә•дёҖдёӘquicklistиҠӮзӮ№еҢ…еҗ«еӨҡй•ҝзҡ„ziplistеҗҲйҖӮе‘ўпјҹжҜ”еҰӮпјҢеҗҢж ·жҳҜеӯҳеӮЁ12дёӘж•°жҚ®йЎ№пјҢж—ўеҸҜд»ҘжҳҜдёҖдёӘquicklistеҢ…еҗ«3дёӘиҠӮзӮ№пјҢиҖҢжҜҸдёӘиҠӮзӮ№зҡ„ziplistеҸҲеҢ…еҗ«4дёӘж•°жҚ®йЎ№пјҢд№ҹеҸҜд»ҘжҳҜдёҖдёӘquicklistеҢ…еҗ«6дёӘиҠӮзӮ№пјҢиҖҢжҜҸдёӘиҠӮзӮ№зҡ„ziplistеҸҲеҢ…еҗ«2дёӘж•°жҚ®йЎ№гҖӮ
иҝҷеҸҲжҳҜдёҖдёӘйңҖиҰҒжүҫе№іиЎЎзӮ№зҡ„йҡҫйўҳгҖӮжҲ‘们еҸӘд»ҺеӯҳеӮЁж•ҲзҺҮдёҠеҲҶжһҗдёҖдёӢпјҡ
жҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistи¶ҠзҹӯпјҢеҲҷеҶ…еӯҳзўҺзүҮи¶ҠеӨҡгҖӮеҶ…еӯҳзўҺзүҮеӨҡдәҶпјҢжңүеҸҜиғҪеңЁеҶ…еӯҳдёӯдә§з”ҹеҫҲеӨҡж— жі•иў«еҲ©з”Ёзҡ„е°ҸзўҺзүҮпјҢд»ҺиҖҢйҷҚдҪҺеӯҳеӮЁж•ҲзҺҮгҖӮиҝҷз§Қжғ…еҶөзҡ„жһҒз«ҜжҳҜжҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistеҸӘеҢ…еҗ«дёҖдёӘж•°жҚ®йЎ№пјҢиҝҷе°ұиң•еҢ–жҲҗдёҖдёӘжҷ®йҖҡзҡ„еҸҢеҗ‘й“ҫиЎЁдәҶгҖӮ
жҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistи¶Ҡй•ҝпјҢеҲҷдёәziplistеҲҶй…ҚеӨ§еқ—иҝһз»ӯеҶ…еӯҳз©әй—ҙзҡ„йҡҫеәҰе°ұи¶ҠеӨ§гҖӮжңүеҸҜиғҪеҮәзҺ°еҶ…еӯҳйҮҢжңүеҫҲеӨҡе°Ҹеқ—зҡ„з©әй—Із©әй—ҙпјҲе®ғ们еҠ иө·жқҘеҫҲеӨҡпјүпјҢдҪҶеҚҙжүҫдёҚеҲ°дёҖеқ—и¶іеӨҹеӨ§зҡ„з©әй—Із©әй—ҙеҲҶй…Қз»ҷziplistзҡ„жғ…еҶөгҖӮиҝҷеҗҢж ·дјҡйҷҚдҪҺеӯҳеӮЁж•ҲзҺҮгҖӮиҝҷз§Қжғ…еҶөзҡ„жһҒз«ҜжҳҜж•ҙдёӘquicklistеҸӘжңүдёҖдёӘиҠӮзӮ№пјҢжүҖжңүзҡ„ж•°жҚ®йЎ№йғҪеҲҶй…ҚеңЁиҝҷд»…жңүзҡ„дёҖдёӘиҠӮзӮ№зҡ„ziplistйҮҢйқўгҖӮиҝҷе…¶е®һиң•еҢ–жҲҗдёҖдёӘziplistдәҶгҖӮ
еҸҜи§ҒпјҢдёҖдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistиҰҒдҝқжҢҒдёҖдёӘеҗҲзҗҶзҡ„й•ҝеәҰгҖӮйӮЈеҲ°еә•еӨҡй•ҝеҗҲзҗҶе‘ўпјҹиҝҷеҸҜиғҪеҸ–еҶідәҺе…·дҪ“еә”з”ЁеңәжҷҜгҖӮе®һйҷ…дёҠпјҢRedisжҸҗдҫӣдәҶдёҖдёӘй…ҚзҪ®еҸӮж•°list-max-ziplist-sizeпјҢе°ұжҳҜдёәдәҶи®©дҪҝз”ЁиҖ…еҸҜд»ҘжқҘж №жҚ®иҮӘе·ұзҡ„жғ…еҶөиҝӣиЎҢи°ғж•ҙгҖӮ
list-max-ziplist-size -2
жҲ‘们жқҘиҜҰз»Ҷи§ЈйҮҠдёҖдёӢиҝҷдёӘеҸӮж•°зҡ„еҗ«д№үгҖӮе®ғеҸҜд»ҘеҸ–жӯЈеҖјпјҢд№ҹеҸҜд»ҘеҸ–иҙҹеҖјгҖӮ
еҪ“еҸ–жӯЈеҖјзҡ„ж—¶еҖҷпјҢиЎЁзӨәжҢүз…§ж•°жҚ®йЎ№дёӘж•°жқҘйҷҗе®ҡжҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistй•ҝеәҰгҖӮжҜ”еҰӮпјҢеҪ“иҝҷдёӘеҸӮж•°й…ҚзҪ®жҲҗ5зҡ„ж—¶еҖҷпјҢиЎЁзӨәжҜҸдёӘquicklistиҠӮзӮ№зҡ„ziplistжңҖеӨҡеҢ…еҗ«5дёӘж•°жҚ®йЎ№гҖӮ
еҪ“еҸ–иҙҹеҖјзҡ„ж—¶еҖҷпјҢиЎЁзӨәжҢүз…§еҚ з”Ёеӯ—иҠӮж•°жқҘйҷҗе®ҡжҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistй•ҝеәҰгҖӮиҝҷж—¶пјҢе®ғеҸӘиғҪеҸ–-1еҲ°-5иҝҷдә”дёӘеҖјпјҢжҜҸдёӘеҖјеҗ«д№үеҰӮдёӢпјҡ
-5: жҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistеӨ§е°ҸдёҚиғҪи¶…иҝҮ64 KbгҖӮпјҲжіЁпјҡ1kb => 1024 bytesпјү
-4: жҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistеӨ§е°ҸдёҚиғҪи¶…иҝҮ32 KbгҖӮ
-3: жҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistеӨ§е°ҸдёҚиғҪи¶…иҝҮ16 KbгҖӮ
-2: жҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistеӨ§е°ҸдёҚиғҪи¶…иҝҮ8 KbгҖӮпјҲ-2жҳҜRedisз»ҷеҮәзҡ„й»ҳи®ӨеҖјпјү
-1: жҜҸдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistеӨ§е°ҸдёҚиғҪи¶…иҝҮ4 KbгҖӮ
еҸҰеӨ–пјҢlistзҡ„и®ҫи®Ўзӣ®ж ҮжҳҜиғҪеӨҹз”ЁжқҘеӯҳеӮЁеҫҲй•ҝзҡ„ж•°жҚ®еҲ—иЎЁзҡ„гҖӮжҜ”еҰӮпјҢRedisе®ҳзҪ‘з»ҷеҮәзҡ„иҝҷдёӘж•ҷзЁӢпјҡ Writing a simple Twitter clone with PHP and RedisпјҢе°ұжҳҜдҪҝз”ЁlistжқҘеӯҳеӮЁзұ»дјјTwitterзҡ„timelineж•°жҚ®гҖӮ
еҪ“еҲ—иЎЁеҫҲй•ҝзҡ„ж—¶еҖҷпјҢжңҖе®№жҳ“иў«и®ҝй—®зҡ„еҫҲеҸҜиғҪжҳҜдёӨз«Ҝзҡ„ж•°жҚ®пјҢдёӯй—ҙзҡ„ж•°жҚ®иў«и®ҝй—®зҡ„йў‘зҺҮжҜ”иҫғдҪҺпјҲи®ҝй—®иө·жқҘжҖ§иғҪд№ҹеҫҲдҪҺпјүгҖӮеҰӮжһңеә”з”ЁеңәжҷҜз¬ҰеҗҲиҝҷдёӘзү№зӮ№пјҢйӮЈд№ҲlistиҝҳжҸҗдҫӣдәҶдёҖдёӘйҖүйЎ№пјҢиғҪеӨҹжҠҠдёӯй—ҙзҡ„ж•°жҚ®иҠӮзӮ№иҝӣиЎҢеҺӢзј©пјҢд»ҺиҖҢиҝӣдёҖжӯҘиҠӮзңҒеҶ…еӯҳз©әй—ҙгҖӮRedisзҡ„й…ҚзҪ®еҸӮж•°list-compress-depthе°ұжҳҜз”ЁжқҘе®ҢжҲҗиҝҷдёӘи®ҫзҪ®зҡ„гҖӮ
list-compress-depth 0
иҝҷдёӘеҸӮж•°иЎЁзӨәдёҖдёӘquicklistдёӨз«ҜдёҚиў«еҺӢзј©зҡ„иҠӮзӮ№дёӘж•°гҖӮжіЁпјҡиҝҷйҮҢзҡ„иҠӮзӮ№дёӘж•°жҳҜжҢҮquicklistеҸҢеҗ‘й“ҫиЎЁзҡ„иҠӮзӮ№дёӘж•°пјҢиҖҢдёҚжҳҜжҢҮziplistйҮҢйқўзҡ„ж•°жҚ®йЎ№дёӘж•°гҖӮе®һйҷ…дёҠпјҢдёҖдёӘquicklistиҠӮзӮ№дёҠзҡ„ziplistпјҢеҰӮжһңиў«еҺӢзј©пјҢе°ұжҳҜж•ҙдҪ“иў«еҺӢзј©зҡ„гҖӮ
еҸӮж•°list-compress-depthзҡ„еҸ–еҖјеҗ«д№үеҰӮдёӢпјҡ
0: жҳҜдёӘзү№ж®ҠеҖјпјҢиЎЁзӨәйғҪдёҚеҺӢзј©гҖӮиҝҷжҳҜRedisзҡ„й»ҳи®ӨеҖјгҖӮ
1: иЎЁзӨәquicklistдёӨз«Ҝеҗ„жңү1дёӘиҠӮзӮ№дёҚеҺӢзј©пјҢдёӯй—ҙзҡ„иҠӮзӮ№еҺӢзј©гҖӮ
2: иЎЁзӨәquicklistдёӨз«Ҝеҗ„жңү2дёӘиҠӮзӮ№дёҚеҺӢзј©пјҢдёӯй—ҙзҡ„иҠӮзӮ№еҺӢзј©гҖӮ
3: иЎЁзӨәquicklistдёӨз«Ҝеҗ„жңү3дёӘиҠӮзӮ№дёҚеҺӢзј©пјҢдёӯй—ҙзҡ„иҠӮзӮ№еҺӢзј©гҖӮ
дҫқжӯӨзұ»жҺЁвҖҰ
з”ұдәҺ0жҳҜдёӘзү№ж®ҠеҖјпјҢеҫҲе®№жҳ“зңӢеҮәquicklistзҡ„еӨҙиҠӮзӮ№е’Ңе°ҫиҠӮзӮ№жҖ»жҳҜдёҚиў«еҺӢзј©зҡ„пјҢд»ҘдҫҝдәҺеңЁиЎЁзҡ„дёӨз«ҜиҝӣиЎҢеҝ«йҖҹеӯҳеҸ–гҖӮ
RedisеҜ№дәҺquicklistеҶ…йғЁиҠӮзӮ№зҡ„еҺӢзј©з®—жі•пјҢйҮҮз”Ёзҡ„ LZFвҖ”вҖ”дёҖз§Қж— жҚҹеҺӢзј©з®—жі•гҖӮ
quicklistзӣёе…ізҡ„ж•°жҚ®з»“жһ„е®ҡд№үеҸҜд»ҘеңЁquicklist.hдёӯжүҫеҲ°пјҡ
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned int len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;quicklistNodeз»“жһ„д»ЈиЎЁquicklistзҡ„дёҖдёӘиҠӮзӮ№пјҢе…¶дёӯеҗ„дёӘеӯ—ж®өзҡ„еҗ«д№үеҰӮдёӢпјҡ
prev: жҢҮеҗ‘й“ҫиЎЁеүҚдёҖдёӘиҠӮзӮ№зҡ„жҢҮй’ҲгҖӮ
next: жҢҮеҗ‘й“ҫиЎЁеҗҺдёҖдёӘиҠӮзӮ№зҡ„жҢҮй’ҲгҖӮ
zl: ж•°жҚ®жҢҮй’ҲгҖӮеҰӮжһңеҪ“еүҚиҠӮзӮ№зҡ„ж•°жҚ®жІЎжңүеҺӢзј©пјҢйӮЈд№Ҳе®ғжҢҮеҗ‘дёҖдёӘziplistз»“жһ„пјӣеҗҰеҲҷпјҢе®ғжҢҮеҗ‘дёҖдёӘquicklistLZFз»“жһ„гҖӮ
sz: иЎЁзӨәzlжҢҮеҗ‘зҡ„ziplistзҡ„жҖ»еӨ§е°ҸпјҲеҢ…жӢ¬zlbytes,
zltail,
zllen,
zlendе’Ңеҗ„дёӘж•°жҚ®йЎ№пјүгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡеҰӮжһңziplistиў«еҺӢзј©дәҶпјҢйӮЈд№ҲиҝҷдёӘszзҡ„еҖјд»Қ然жҳҜеҺӢзј©еүҚзҡ„ziplistеӨ§е°ҸгҖӮ
count: иЎЁзӨәziplistйҮҢйқўеҢ…еҗ«зҡ„ж•°жҚ®йЎ№дёӘж•°гҖӮиҝҷдёӘеӯ—ж®өеҸӘжңү16bitгҖӮзЁҚеҗҺжҲ‘们дјҡдёҖиө·и®Ўз®—дёҖдёӢиҝҷ16bitжҳҜеҗҰеӨҹз”ЁгҖӮ
encoding: иЎЁзӨәziplistжҳҜеҗҰеҺӢзј©дәҶпјҲд»ҘеҸҠз”ЁдәҶе“ӘдёӘеҺӢзј©з®—жі•пјүгҖӮзӣ®еүҚеҸӘжңүдёӨз§ҚеҸ–еҖјпјҡ2иЎЁзӨәиў«еҺӢзј©дәҶпјҲиҖҢдё”з”Ёзҡ„жҳҜ LZFеҺӢзј©з®—жі•пјүпјҢ1иЎЁзӨәжІЎжңүеҺӢзј©гҖӮ
container: жҳҜдёҖдёӘйў„з•ҷеӯ—ж®өгҖӮжң¬жқҘи®ҫи®ЎжҳҜз”ЁжқҘиЎЁжҳҺдёҖдёӘquicklistиҠӮзӮ№дёӢйқўжҳҜзӣҙжҺҘеӯҳж•°жҚ®пјҢиҝҳжҳҜдҪҝз”Ёziplistеӯҳж•°жҚ®пјҢжҲ–иҖ…з”Ёе…¶е®ғзҡ„з»“жһ„жқҘеӯҳж•°жҚ®пјҲз”ЁдҪңдёҖдёӘж•°жҚ®е®№еҷЁпјҢжүҖд»ҘеҸ«containerпјүгҖӮдҪҶжҳҜпјҢеңЁзӣ®еүҚзҡ„е®һзҺ°дёӯпјҢиҝҷдёӘеҖјжҳҜдёҖдёӘеӣәе®ҡзҡ„еҖј2пјҢиЎЁзӨәдҪҝз”ЁziplistдҪңдёәж•°жҚ®е®№еҷЁгҖӮ
recompress: еҪ“жҲ‘们дҪҝз”Ёзұ»дјјlindexиҝҷж ·зҡ„е‘Ҫд»ӨжҹҘзңӢдәҶжҹҗдёҖйЎ№жң¬жқҘеҺӢзј©зҡ„ж•°жҚ®ж—¶пјҢйңҖиҰҒжҠҠж•°жҚ®жҡӮж—¶и§ЈеҺӢпјҢиҝҷж—¶е°ұи®ҫзҪ®recompress=1еҒҡдёҖдёӘж Үи®°пјҢзӯүжңүжңәдјҡеҶҚжҠҠж•°жҚ®йҮҚж–°еҺӢзј©гҖӮ
attempted_compress: иҝҷдёӘеҖјеҸӘеҜ№Redisзҡ„иҮӘеҠЁеҢ–жөӢиҜ•зЁӢеәҸжңүз”ЁгҖӮжҲ‘们дёҚз”Ёз®Ўе®ғгҖӮ
extra: е…¶е®ғжү©еұ•еӯ—ж®өгҖӮзӣ®еүҚRedisзҡ„е®һзҺ°йҮҢд№ҹжІЎз”ЁдёҠгҖӮ
quicklistLZFз»“жһ„иЎЁзӨәдёҖдёӘиў«еҺӢзј©иҝҮзҡ„ziplistгҖӮе…¶дёӯпјҡ
sz: иЎЁзӨәеҺӢзј©еҗҺзҡ„ziplistеӨ§е°ҸгҖӮ
compressed: жҳҜдёӘжҹ”жҖ§ж•°з»„пјҲ flexible array memberпјүпјҢеӯҳж”ҫеҺӢзј©еҗҺзҡ„ziplistеӯ—иҠӮж•°з»„гҖӮ
зңҹжӯЈиЎЁзӨәquicklistзҡ„ж•°жҚ®з»“жһ„жҳҜеҗҢеҗҚзҡ„quicklistиҝҷдёӘstructпјҡ
head: жҢҮеҗ‘еӨҙиҠӮзӮ№пјҲе·Ұдҫ§з¬¬дёҖдёӘиҠӮзӮ№пјүзҡ„жҢҮй’ҲгҖӮ
tail: жҢҮеҗ‘е°ҫиҠӮзӮ№пјҲеҸідҫ§з¬¬дёҖдёӘиҠӮзӮ№пјүзҡ„жҢҮй’ҲгҖӮ
count: жүҖжңүziplistж•°жҚ®йЎ№зҡ„дёӘж•°жҖ»е’ҢгҖӮ
len: quicklistиҠӮзӮ№зҡ„дёӘж•°гҖӮ
fill: 16bitпјҢziplistеӨ§е°Ҹи®ҫзҪ®пјҢеӯҳж”ҫlist-max-ziplist-sizeеҸӮж•°зҡ„еҖјгҖӮ
compress: 16bitпјҢиҠӮзӮ№еҺӢзј©ж·ұеәҰи®ҫзҪ®пјҢеӯҳж”ҫlist-compress-depthеҸӮж•°зҡ„еҖјгҖӮ
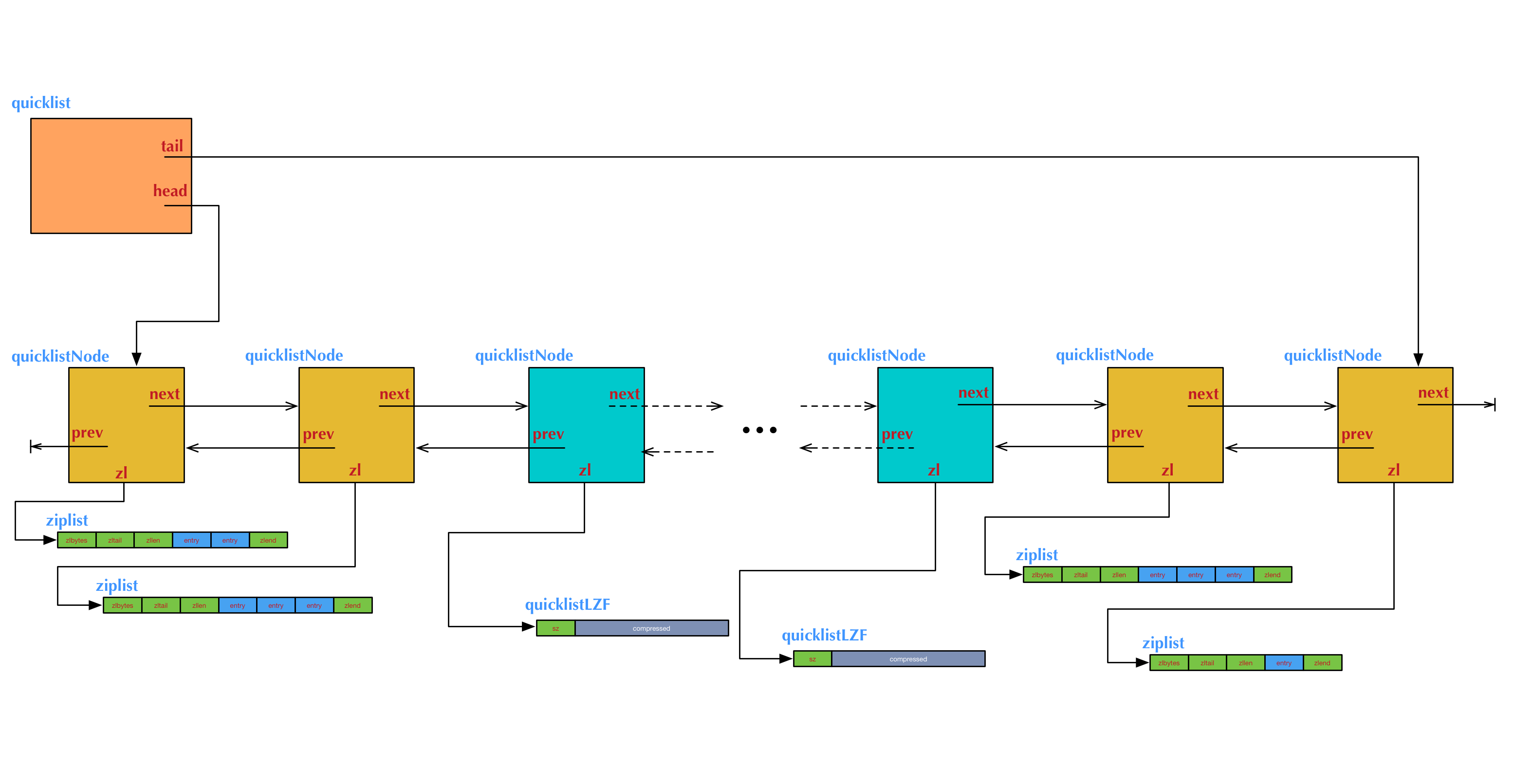
дёҠеӣҫжҳҜдёҖдёӘquicklistзҡ„з»“жһ„еӣҫдёҫдҫӢгҖӮеӣҫдёӯдҫӢеӯҗеҜ№еә”зҡ„ziplistеӨ§е°Ҹй…ҚзҪ®е’ҢиҠӮзӮ№еҺӢзј©ж·ұеәҰй…ҚзҪ®пјҢеҰӮдёӢпјҡ
list-max-ziplist-size 3 list-compress-depth 2
иҝҷдёӘдҫӢеӯҗдёӯжҲ‘们йңҖиҰҒжіЁж„Ҹзҡ„еҮ зӮ№жҳҜпјҡ
дёӨз«Ҝеҗ„жңү2дёӘж©ҷй»„иүІзҡ„иҠӮзӮ№пјҢжҳҜжІЎжңүиў«еҺӢзј©зҡ„гҖӮе®ғ们зҡ„ж•°жҚ®жҢҮй’ҲzlжҢҮеҗ‘зңҹжӯЈзҡ„ziplistгҖӮдёӯй—ҙзҡ„е…¶е®ғиҠӮзӮ№жҳҜиў«еҺӢзј©иҝҮзҡ„пјҢе®ғ们зҡ„ж•°жҚ®жҢҮй’ҲzlжҢҮеҗ‘иў«еҺӢзј©еҗҺзҡ„ziplistз»“жһ„пјҢеҚідёҖдёӘquicklistLZFз»“жһ„гҖӮ
е·Ұдҫ§еӨҙиҠӮзӮ№дёҠзҡ„ziplistйҮҢжңү2йЎ№ж•°жҚ®пјҢеҸідҫ§е°ҫиҠӮзӮ№дёҠзҡ„ziplistйҮҢжңү1йЎ№ж•°жҚ®пјҢдёӯй—ҙе…¶е®ғиҠӮзӮ№дёҠзҡ„ziplistйҮҢйғҪжңү3йЎ№ж•°жҚ®пјҲеҢ…жӢ¬еҺӢзј©зҡ„иҠӮзӮ№еҶ…йғЁпјүгҖӮиҝҷиЎЁзӨәеңЁиЎЁзҡ„дёӨз«Ҝжү§иЎҢиҝҮеӨҡж¬Ўpushе’Ңpopж“ҚдҪңеҗҺзҡ„дёҖдёӘзҠ¶жҖҒгҖӮ
зҺ°еңЁжҲ‘们жқҘеӨ§жҰӮи®Ўз®—дёҖдёӢquicklistNodeз»“жһ„дёӯзҡ„countеӯ—ж®өиҝҷ16bitжҳҜеҗҰеӨҹз”ЁгҖӮ
жҲ‘们已з»ҸзҹҘйҒ“пјҢziplistеӨ§е°ҸеҸ—еҲ°list-max-ziplist-sizeеҸӮж•°зҡ„йҷҗеҲ¶гҖӮжҢүз…§жӯЈеҖје’ҢиҙҹеҖјжңүдёӨз§Қжғ…еҶөпјҡ
еҪ“иҝҷдёӘеҸӮж•°еҸ–жӯЈеҖјзҡ„ж—¶еҖҷпјҢе°ұжҳҜжҒ°еҘҪиЎЁзӨәдёҖдёӘquicklistNodeз»“жһ„дёӯzlжүҖжҢҮеҗ‘зҡ„ziplistжүҖеҢ…еҗ«зҡ„ж•°жҚ®йЎ№зҡ„жңҖеӨ§еҖјгҖӮlist-max-ziplist-sizeеҸӮж•°жҳҜз”ұquicklistз»“жһ„зҡ„fillеӯ—ж®өжқҘеӯҳеӮЁзҡ„пјҢиҖҢfillеӯ—ж®өжҳҜ16bitпјҢжүҖд»Ҙе®ғжүҖиғҪиЎЁиҫҫзҡ„еҖјиғҪеӨҹз”Ё16bitжқҘиЎЁзӨәгҖӮ
еҪ“иҝҷдёӘеҸӮж•°еҸ–иҙҹеҖјзҡ„ж—¶еҖҷпјҢиғҪеӨҹиЎЁзӨәзҡ„ziplistжңҖеӨ§й•ҝеәҰжҳҜ64 KbгҖӮиҖҢziplistдёӯжҜҸдёҖдёӘж•°жҚ®йЎ№пјҢжңҖе°‘йңҖиҰҒ2дёӘеӯ—иҠӮжқҘиЎЁзӨәпјҡ1дёӘеӯ—иҠӮзҡ„prevrawlenпјҢ1дёӘеӯ—иҠӮзҡ„dataпјҲlenеӯ—ж®өе’ҢdataеҗҲдәҢдёәдёҖпјӣиҜҰи§Ғ
дёҠдёҖзҜҮпјүгҖӮжүҖд»ҘпјҢziplistдёӯж•°жҚ®йЎ№зҡ„дёӘж•°дёҚдјҡи¶…иҝҮ32 KпјҢз”Ё16bitжқҘиЎЁиҫҫи¶іеӨҹдәҶгҖӮ
е®һйҷ…дёҠпјҢеңЁзӣ®еүҚзҡ„quicklistзҡ„е®һзҺ°дёӯпјҢziplistзҡ„еӨ§е°ҸиҝҳдјҡеҸ—еҲ°еҸҰеӨ–зҡ„йҷҗеҲ¶пјҢж №жң¬дёҚдјҡиҫҫеҲ°иҝҷйҮҢжүҖеҲҶжһҗзҡ„жңҖеӨ§еҖјгҖӮ
дёӢйқўиҝӣе…Ҙд»Јз ҒеҲҶжһҗйҳ¶ж®өгҖӮ
еҪ“жҲ‘们дҪҝз”ЁlpushжҲ–rpushе‘Ҫд»Ө第дёҖж¬Ўеҗ‘дёҖдёӘдёҚеӯҳеңЁзҡ„listйҮҢйқўжҸ’е…Ҙж•°жҚ®зҡ„ж—¶еҖҷпјҢRedisдјҡйҰ–е…Ҳи°ғз”ЁquicklistCreateжҺҘеҸЈеҲӣе»әдёҖдёӘз©әзҡ„quicklistгҖӮ
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
quicklist = zmalloc(sizeof(*quicklist));
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
return quicklist;
}еңЁеҫҲеӨҡд»Ӣз»Қж•°жҚ®з»“жһ„зҡ„д№ҰдёҠпјҢе®һзҺ°еҸҢеҗ‘й“ҫиЎЁзҡ„ж—¶еҖҷз»ҸеёёдјҡеӨҡеўһеҠ дёҖдёӘз©әдҪҷзҡ„еӨҙиҠӮзӮ№пјҢдё»иҰҒжҳҜдёәдәҶжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңзҡ„ж–№дҫҝгҖӮд»ҺдёҠйқўquicklistCreateзҡ„д»Јз ҒеҸҜд»ҘзңӢеҮәпјҢquicklistжҳҜдёҖдёӘдёҚеҢ…еҗ«з©әдҪҷеӨҙиҠӮзӮ№зҡ„еҸҢеҗ‘й“ҫиЎЁпјҲheadе’ҢtailйғҪеҲқе§ӢеҢ–дёәNULLпјүгҖӮ
quicklistзҡ„pushж“ҚдҪңжҳҜи°ғз”ЁquicklistPushжқҘе®һзҺ°зҡ„гҖӮ
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
quicklistPushTail(quicklist, value, sz);
}
}
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
/* Add new entry to tail node of quicklist.
*
* Returns 0 if used existing tail.
* Returns 1 if new tail created. */
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(quicklist->tail);
} else {
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}дёҚз®ЎжҳҜеңЁеӨҙйғЁиҝҳжҳҜе°ҫйғЁжҸ’е…Ҙж•°жҚ®пјҢйғҪеҢ…еҗ«дёӨз§Қжғ…еҶөпјҡ
еҰӮжһңеӨҙиҠӮзӮ№пјҲжҲ–е°ҫиҠӮзӮ№пјүдёҠziplistеӨ§е°ҸжІЎжңүи¶…иҝҮйҷҗеҲ¶пјҲеҚі_quicklistNodeAllowInsertиҝ”еӣһ1пјүпјҢйӮЈд№Ҳж–°ж•°жҚ®иў«зӣҙжҺҘжҸ’е…ҘеҲ°ziplistдёӯпјҲи°ғз”ЁziplistPushпјүгҖӮ
еҰӮжһңеӨҙиҠӮзӮ№пјҲжҲ–е°ҫиҠӮзӮ№пјүдёҠziplistеӨӘеӨ§дәҶпјҢйӮЈд№Ҳж–°еҲӣе»әдёҖдёӘquicklistNodeиҠӮзӮ№пјҲеҜ№еә”ең°д№ҹдјҡж–°еҲӣе»әдёҖдёӘziplistпјүпјҢ然еҗҺжҠҠиҝҷдёӘж–°еҲӣе»әзҡ„иҠӮзӮ№жҸ’е…ҘеҲ°quicklistеҸҢеҗ‘й“ҫиЎЁдёӯпјҲи°ғз”Ё_quicklistInsertNodeAfterпјүгҖӮ
еңЁ_quicklistInsertNodeAfterзҡ„е®һзҺ°дёӯпјҢиҝҳдјҡж №жҚ®list-compress-depthзҡ„й…ҚзҪ®е°ҶйҮҢйқўзҡ„иҠӮзӮ№иҝӣиЎҢеҺӢзј©гҖӮе®ғзҡ„е®һзҺ°жҜ”иҫғз№ҒзҗҗпјҢжҲ‘们иҝҷйҮҢе°ұдёҚеұ•ејҖи®Ёи®әдәҶгҖӮ
quicklistзҡ„ж“ҚдҪңиҫғеӨҡпјҢдё”е®һзҺ°з»ҶиҠӮйғҪжҜ”иҫғз№ҒжқӮпјҢиҝҷйҮҢе°ұдёҚдёҖдёҖеҲҶжһҗжәҗз ҒдәҶпјҢжҲ‘们з®ҖеҚ•д»Ӣз»ҚдёҖдәӣжҜ”иҫғйҮҚиҰҒзҡ„ж“ҚдҪңгҖӮ
quicklistзҡ„popж“ҚдҪңжҳҜи°ғз”ЁquicklistPopCustomжқҘе®һзҺ°зҡ„гҖӮquicklistPopCustomзҡ„е®һзҺ°иҝҮзЁӢеҹәжң¬дёҠи·ҹquicklistPushзӣёеҸҚпјҢе…Ҳд»ҺеӨҙйғЁжҲ–е°ҫйғЁиҠӮзӮ№зҡ„ziplistдёӯжҠҠеҜ№еә”зҡ„ж•°жҚ®йЎ№еҲ йҷӨпјҢеҰӮжһңеңЁеҲ йҷӨеҗҺziplistдёәз©әдәҶпјҢйӮЈд№ҲеҜ№еә”зҡ„еӨҙйғЁжҲ–е°ҫйғЁиҠӮзӮ№д№ҹиҰҒеҲ йҷӨгҖӮеҲ йҷӨеҗҺиҝҳеҸҜиғҪж¶үеҸҠеҲ°йҮҢйқўиҠӮзӮ№зҡ„и§ЈеҺӢзј©й—®йўҳгҖӮ
quicklistдёҚд»…е®һзҺ°дәҶд»ҺеӨҙйғЁжҲ–е°ҫйғЁжҸ’е…ҘпјҢд№ҹе®һзҺ°дәҶд»Һд»»ж„ҸжҢҮе®ҡзҡ„дҪҚзҪ®жҸ’е…ҘгҖӮquicklistInsertAfterе’ҢquicklistInsertBeforeе°ұжҳҜеҲҶеҲ«еңЁжҢҮе®ҡдҪҚзҪ®еҗҺйқўе’ҢеүҚйқўжҸ’е…Ҙж•°жҚ®йЎ№гҖӮиҝҷз§ҚеңЁд»»ж„ҸжҢҮе®ҡдҪҚзҪ®жҸ’е…Ҙж•°жҚ®зҡ„ж“ҚдҪңпјҢжғ…еҶөжҜ”иҫғеӨҚжқӮпјҢжңүдј—еӨҡзҡ„йҖ»иҫ‘еҲҶж”ҜгҖӮ
еҪ“жҸ’е…ҘдҪҚзҪ®жүҖеңЁзҡ„ziplistеӨ§е°ҸжІЎжңүи¶…иҝҮйҷҗеҲ¶ж—¶пјҢзӣҙжҺҘжҸ’е…ҘеҲ°ziplistдёӯе°ұеҘҪдәҶпјӣ
еҪ“жҸ’е…ҘдҪҚзҪ®жүҖеңЁзҡ„ziplistеӨ§е°Ҹи¶…иҝҮдәҶйҷҗеҲ¶пјҢдҪҶжҸ’е…Ҙзҡ„дҪҚзҪ®дҪҚдәҺziplistдёӨз«ҜпјҢ并且зӣёйӮ»зҡ„quicklistй“ҫиЎЁиҠӮзӮ№зҡ„ziplistеӨ§е°ҸжІЎжңүи¶…иҝҮйҷҗеҲ¶пјҢйӮЈд№Ҳе°ұиҪ¬иҖҢжҸ’е…ҘеҲ°зӣёйӮ»зҡ„йӮЈдёӘquicklistй“ҫиЎЁиҠӮзӮ№зҡ„ziplistдёӯпјӣ
еҪ“жҸ’е…ҘдҪҚзҪ®жүҖеңЁзҡ„ziplistеӨ§е°Ҹи¶…иҝҮдәҶйҷҗеҲ¶пјҢдҪҶжҸ’е…Ҙзҡ„дҪҚзҪ®дҪҚдәҺziplistдёӨз«ҜпјҢ并且зӣёйӮ»зҡ„quicklistй“ҫиЎЁиҠӮзӮ№зҡ„ziplistеӨ§е°Ҹд№ҹи¶…иҝҮйҷҗеҲ¶пјҢиҝҷж—¶йңҖиҰҒж–°еҲӣе»әдёҖдёӘquicklistй“ҫиЎЁиҠӮзӮ№жҸ’е…ҘгҖӮ
еҜ№дәҺжҸ’е…ҘдҪҚзҪ®жүҖеңЁзҡ„ziplistеӨ§е°Ҹи¶…иҝҮдәҶйҷҗеҲ¶зҡ„е…¶е®ғжғ…еҶөпјҲдё»иҰҒеҜ№еә”дәҺеңЁziplistдёӯй—ҙжҸ’е…Ҙж•°жҚ®зҡ„жғ…еҶөпјүпјҢеҲҷйңҖиҰҒжҠҠеҪ“еүҚziplistеҲҶиЈӮдёәдёӨдёӘиҠӮзӮ№пјҢ然еҗҺеҶҚе…¶дёӯдёҖдёӘиҠӮзӮ№дёҠжҸ’е…Ҙж•°жҚ®гҖӮ
quicklistSetOptionsз”ЁдәҺи®ҫзҪ®ziplistеӨ§е°Ҹй…ҚзҪ®еҸӮж•°пјҲlist-max-ziplist-sizeпјүе’ҢиҠӮзӮ№еҺӢзј©ж·ұеәҰй…ҚзҪ®еҸӮж•°пјҲlist-compress-depthпјүгҖӮд»Јз ҒжҜ”иҫғз®ҖеҚ•пјҢе°ұжҳҜе°Ҷзӣёеә”зҡ„еҖјеҲҶеҲ«и®ҫзҪ®з»ҷquicklistз»“жһ„зҡ„fillеӯ—ж®өе’Ңcompressеӯ—ж®өгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎRedisдёӯеҶ…йғЁж•°жҚ®з»“жһ„quicklistзҡ„дҪңз”ЁжҳҜд»Җд№Ҳзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ