жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶRedisдёӯеҶ…йғЁж•°жҚ®з»“жһ„ziplistзҡ„дҪңз”ЁжҳҜд»Җд№ҲпјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
д»Җд№ҲжҳҜziplist
Redisе®ҳж–№еҜ№дәҺziplistзҡ„е®ҡд№үжҳҜпјҲеҮәиҮӘziplist.cзҡ„ж–Ү件еӨҙйғЁжіЁйҮҠпјүпјҡ
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time.
зҝ»иҜ‘дёҖдёӢе°ұжҳҜиҜҙпјҡziplistжҳҜдёҖдёӘз»ҸиҝҮзү№ж®Ҡзј–з Ғзҡ„еҸҢеҗ‘й“ҫиЎЁпјҢе®ғзҡ„и®ҫи®Ўзӣ®ж Үе°ұжҳҜдёәдәҶжҸҗй«ҳеӯҳеӮЁж•ҲзҺҮгҖӮziplistеҸҜд»Ҙз”ЁдәҺеӯҳеӮЁеӯ—з¬ҰдёІжҲ–ж•ҙж•°пјҢе…¶дёӯж•ҙж•°жҳҜжҢүзңҹжӯЈзҡ„дәҢиҝӣеҲ¶иЎЁзӨәиҝӣиЎҢзј–з Ғзҡ„пјҢиҖҢдёҚжҳҜзј–з ҒжҲҗеӯ—з¬ҰдёІеәҸеҲ—гҖӮе®ғиғҪд»ҘO(1)зҡ„ж—¶й—ҙеӨҚжқӮеәҰеңЁиЎЁзҡ„дёӨз«ҜжҸҗдҫӣpushе’Ңpopж“ҚдҪңгҖӮ
е®һйҷ…дёҠпјҢziplistе……еҲҶдҪ“зҺ°дәҶRedisеҜ№дәҺеӯҳеӮЁж•ҲзҺҮзҡ„иҝҪжұӮгҖӮдёҖдёӘжҷ®йҖҡзҡ„еҸҢеҗ‘й“ҫиЎЁпјҢй“ҫиЎЁдёӯжҜҸдёҖйЎ№йғҪеҚ з”ЁзӢ¬з«Ӣзҡ„дёҖеқ—еҶ…еӯҳпјҢеҗ„йЎ№д№Ӣй—ҙз”Ёең°еқҖжҢҮй’ҲпјҲжҲ–еј•з”ЁпјүиҝһжҺҘиө·жқҘгҖӮиҝҷз§Қж–№ејҸдјҡеёҰжқҘеӨ§йҮҸзҡ„еҶ…еӯҳзўҺзүҮпјҢиҖҢдё”ең°еқҖжҢҮй’Ҳд№ҹдјҡеҚ з”ЁйўқеӨ–зҡ„еҶ…еӯҳгҖӮиҖҢziplistеҚҙжҳҜе°ҶиЎЁдёӯжҜҸдёҖйЎ№еӯҳж”ҫеңЁеүҚеҗҺиҝһз»ӯзҡ„ең°еқҖз©әй—ҙеҶ…пјҢдёҖдёӘziplistж•ҙдҪ“еҚ з”ЁдёҖеӨ§еқ—еҶ…еӯҳгҖӮе®ғжҳҜдёҖдёӘиЎЁпјҲlistпјүпјҢдҪҶе…¶е®һдёҚжҳҜдёҖдёӘй“ҫиЎЁпјҲlinked listпјүгҖӮ
еҸҰеӨ–пјҢziplistдёәдәҶеңЁз»ҶиҠӮдёҠиҠӮзңҒеҶ…еӯҳпјҢеҜ№дәҺеҖјзҡ„еӯҳеӮЁйҮҮз”ЁдәҶеҸҳй•ҝзҡ„зј–з Ғж–№ејҸпјҢеӨ§жҰӮж„ҸжҖқжҳҜиҜҙпјҢеҜ№дәҺеӨ§зҡ„ж•ҙж•°пјҢе°ұеӨҡз”ЁдёҖдәӣеӯ—иҠӮжқҘеӯҳеӮЁпјҢиҖҢеҜ№дәҺе°Ҹзҡ„ж•ҙж•°пјҢе°ұе°‘з”ЁдёҖдәӣеӯ—иҠӮжқҘеӯҳеӮЁгҖӮжҲ‘们жҺҘдёӢжқҘеҫҲеҝ«е°ұдјҡи®Ёи®әеҲ°иҝҷдәӣе®һзҺ°з»ҶиҠӮгҖӮ
ziplistзҡ„ж•°жҚ®з»“жһ„з»„жҲҗжҳҜжң¬ж–ҮиҰҒи®Ёи®әзҡ„йҮҚзӮ№гҖӮе®һйҷ…дёҠпјҢziplistиҝҳжҳҜзЁҚеҫ®жңүзӮ№еӨҚжқӮзҡ„пјҢе®ғеӨҚжқӮзҡ„ең°ж–№е°ұеңЁдәҺе®ғзҡ„ж•°жҚ®з»“жһ„е®ҡд№үгҖӮдёҖж—ҰзҗҶи§ЈдәҶж•°жҚ®з»“жһ„пјҢе®ғзҡ„дёҖдәӣж“ҚдҪңд№ҹе°ұжҜ”иҫғе®№жҳ“зҗҶи§ЈдәҶгҖӮ
жҲ‘们жҺҘдёӢжқҘе…Ҳд»ҺжҖ»дҪ“дёҠд»Ӣз»ҚдёҖдёӢziplistзҡ„ж•°жҚ®з»“жһ„е®ҡд№үпјҢ然еҗҺдёҫдёҖдёӘе®һйҷ…зҡ„дҫӢеӯҗпјҢйҖҡиҝҮдҫӢеӯҗжқҘи§ЈйҮҠziplistзҡ„жһ„жҲҗгҖӮеҰӮжһңдҪ зңӢжҮӮдәҶиҝҷдёҖйғЁеҲҶпјҢжң¬ж–Үзҡ„д»»еҠЎе°ұз®—е®ҢжҲҗдәҶдёҖеӨ§еҚҠдәҶгҖӮ
д»Һе®Ҹи§ӮдёҠзңӢпјҢziplistзҡ„еҶ…еӯҳз»“жһ„еҰӮдёӢпјҡ
<zlbytes><zltail><zllen><entry>...<entry><zlend>
еҗ„дёӘйғЁеҲҶеңЁеҶ…еӯҳдёҠжҳҜеүҚеҗҺзӣёйӮ»зҡ„пјҢе®ғ们еҲҶеҲ«зҡ„еҗ«д№үеҰӮдёӢпјҡ
<zlbytes>: 32bitпјҢиЎЁзӨәziplistеҚ з”Ёзҡ„еӯ—иҠӮжҖ»ж•°пјҲд№ҹеҢ…жӢ¬<zlbytes>жң¬иә«еҚ з”Ёзҡ„4дёӘеӯ—иҠӮпјүгҖӮ
<zltail>: 32bitпјҢиЎЁзӨәziplistиЎЁдёӯжңҖеҗҺдёҖйЎ№пјҲentryпјүеңЁziplistдёӯзҡ„еҒҸ移еӯ—иҠӮж•°гҖӮ<zltail>зҡ„еӯҳеңЁпјҢдҪҝеҫ—жҲ‘们еҸҜд»ҘеҫҲж–№дҫҝең°жүҫеҲ°жңҖеҗҺдёҖйЎ№пјҲдёҚз”ЁйҒҚеҺҶж•ҙдёӘziplistпјүпјҢд»ҺиҖҢеҸҜд»ҘеңЁziplistе°ҫз«Ҝеҝ«йҖҹең°жү§иЎҢpushжҲ–popж“ҚдҪңгҖӮ
<zllen>: 16bitпјҢ иЎЁзӨәziplistдёӯж•°жҚ®йЎ№пјҲentryпјүзҡ„дёӘж•°гҖӮzllenеӯ—ж®өеӣ дёәеҸӘжңү16bitпјҢжүҖд»ҘеҸҜд»ҘиЎЁиҫҫзҡ„жңҖеӨ§еҖјдёә2^16-1гҖӮиҝҷйҮҢйңҖиҰҒзү№еҲ«жіЁж„Ҹзҡ„жҳҜпјҢеҰӮжһңziplistдёӯж•°жҚ®йЎ№дёӘж•°и¶…иҝҮдәҶ16bitиғҪиЎЁиҫҫзҡ„жңҖеӨ§еҖјпјҢziplistд»Қ然еҸҜд»ҘжқҘиЎЁзӨәгҖӮйӮЈжҖҺд№ҲиЎЁзӨәе‘ўпјҹиҝҷйҮҢеҒҡдәҶиҝҷж ·зҡ„规е®ҡпјҡеҰӮжһң<zllen>е°ҸдәҺзӯүдәҺ2^16-2пјҲд№ҹе°ұжҳҜдёҚзӯүдәҺ2^16-1пјүпјҢйӮЈд№Ҳ<zllen>е°ұиЎЁзӨәziplistдёӯж•°жҚ®йЎ№зҡ„дёӘж•°пјӣеҗҰеҲҷпјҢд№ҹе°ұжҳҜ<zllen>зӯүдәҺ16bitе…Ёдёә1зҡ„жғ…еҶөпјҢйӮЈд№Ҳ<zllen>е°ұдёҚиЎЁзӨәж•°жҚ®йЎ№дёӘж•°дәҶпјҢиҝҷж—¶еҖҷиҰҒжғізҹҘйҒ“ziplistдёӯж•°жҚ®йЎ№жҖ»ж•°пјҢйӮЈд№Ҳеҝ…йЎ»еҜ№ziplistд»ҺеӨҙеҲ°е°ҫйҒҚеҺҶеҗ„дёӘж•°жҚ®йЎ№пјҢжүҚиғҪи®Ўж•°еҮәжқҘгҖӮ
<entry>: иЎЁзӨәзңҹжӯЈеӯҳж”ҫж•°жҚ®зҡ„ж•°жҚ®йЎ№пјҢй•ҝеәҰдёҚе®ҡгҖӮдёҖдёӘж•°жҚ®йЎ№пјҲentryпјүд№ҹжңүе®ғиҮӘе·ұзҡ„еҶ…йғЁз»“жһ„пјҢиҝҷдёӘзЁҚеҗҺеҶҚи§ЈйҮҠгҖӮ
<zlend>: ziplistжңҖеҗҺ1дёӘеӯ—иҠӮпјҢжҳҜдёҖдёӘз»“жқҹж Үи®°пјҢеҖјеӣәе®ҡзӯүдәҺ255гҖӮ
дёҠйқўзҡ„е®ҡд№үдёӯиҝҳеҖјеҫ—жіЁж„Ҹзҡ„дёҖзӮ№жҳҜпјҡ<zlbytes>,
<zltail>,
<zllen>既然еҚ жҚ®еӨҡдёӘеӯ—иҠӮпјҢйӮЈд№ҲеңЁеӯҳеӮЁзҡ„ж—¶еҖҷе°ұжңүеӨ§з«ҜпјҲbig endianпјүе’Ңе°Ҹз«ҜпјҲlittle endianпјүзҡ„еҢәеҲ«гҖӮziplistйҮҮеҸ–зҡ„жҳҜе°Ҹз«ҜжЁЎејҸжқҘеӯҳеӮЁпјҢиҝҷеңЁдёӢйқўжҲ‘们д»Ӣз»Қе…·дҪ“дҫӢеӯҗзҡ„ж—¶еҖҷиҝҳдјҡеҶҚиҜҰз»Ҷи§ЈйҮҠгҖӮ
жҲ‘们еҶҚжқҘзңӢдёҖдёӢжҜҸдёҖдёӘж•°жҚ®йЎ№<entry>зҡ„жһ„жҲҗпјҡ
<prevrawlen><len><data>
жҲ‘们зңӢеҲ°еңЁзңҹжӯЈзҡ„ж•°жҚ®пјҲ<data>пјүеүҚйқўпјҢиҝҳжңүдёӨдёӘеӯ—ж®өпјҡ
<prevrawlen>: иЎЁзӨәеүҚдёҖдёӘж•°жҚ®йЎ№еҚ з”Ёзҡ„жҖ»еӯ—иҠӮж•°гҖӮиҝҷдёӘеӯ—ж®өзҡ„з”ЁеӨ„жҳҜдёәдәҶи®©ziplistиғҪеӨҹд»ҺеҗҺеҗ‘еүҚйҒҚеҺҶпјҲд»ҺеҗҺдёҖйЎ№зҡ„дҪҚзҪ®пјҢеҸӘйңҖеҗ‘еүҚеҒҸ移prevrawlenдёӘеӯ—иҠӮпјҢе°ұжүҫеҲ°дәҶеүҚдёҖйЎ№пјүгҖӮиҝҷдёӘеӯ—ж®өйҮҮз”ЁеҸҳй•ҝзј–з ҒгҖӮ
<len>: иЎЁзӨәеҪ“еүҚж•°жҚ®йЎ№зҡ„ж•°жҚ®й•ҝеәҰпјҲеҚі<data>йғЁеҲҶзҡ„й•ҝеәҰпјүгҖӮд№ҹйҮҮз”ЁеҸҳй•ҝзј–з ҒгҖӮ
йӮЈд№Ҳ<prevrawlen>е’Ң<len>жҳҜжҖҺд№ҲиҝӣиЎҢеҸҳй•ҝзј–з Ғзҡ„е‘ўпјҹеҗ„дҪҚиҜ»иҖ…жү“иө·зІҫзҘһдәҶпјҢжҲ‘们з»ҲдәҺи®ІеҲ°дәҶziplistзҡ„е®ҡд№үдёӯжңҖз№Ғзҗҗзҡ„ең°ж–№дәҶгҖӮ
е…ҲиҜҙ<prevrawlen>гҖӮе®ғжңүдёӨз§ҚеҸҜиғҪпјҢжҲ–иҖ…жҳҜ1дёӘеӯ—иҠӮпјҢжҲ–иҖ…жҳҜ5дёӘеӯ—иҠӮпјҡ
еҰӮжһңеүҚдёҖдёӘж•°жҚ®йЎ№еҚ з”Ёеӯ—иҠӮж•°е°ҸдәҺ254пјҢйӮЈд№Ҳ<prevrawlen>е°ұеҸӘз”ЁдёҖдёӘеӯ—иҠӮжқҘиЎЁзӨәпјҢиҝҷдёӘеӯ—иҠӮзҡ„еҖје°ұжҳҜеүҚдёҖдёӘж•°жҚ®йЎ№зҡ„еҚ з”Ёеӯ—иҠӮж•°гҖӮ
еҰӮжһңеүҚдёҖдёӘж•°жҚ®йЎ№еҚ з”Ёеӯ—иҠӮж•°еӨ§дәҺзӯүдәҺ254пјҢйӮЈд№Ҳ<prevrawlen>е°ұз”Ё5дёӘеӯ—иҠӮжқҘиЎЁзӨәпјҢе…¶дёӯ第1дёӘеӯ—иҠӮзҡ„еҖјжҳҜ254пјҲдҪңдёәиҝҷз§Қжғ…еҶөзҡ„дёҖдёӘж Үи®°пјүпјҢиҖҢеҗҺйқў4дёӘеӯ—иҠӮз»„жҲҗдёҖдёӘж•ҙеһӢеҖјпјҢжқҘзңҹжӯЈеӯҳеӮЁеүҚдёҖдёӘж•°жҚ®йЎ№зҡ„еҚ з”Ёеӯ—иҠӮж•°гҖӮ
жңүдәәдјҡй—®дәҶпјҢдёәд»Җд№ҲжІЎжңү255зҡ„жғ…еҶөе‘ўпјҹ
иҝҷжҳҜеӣ дёәпјҡ255е·Із»Ҹе®ҡд№үдёәziplistз»“жқҹж Үи®°<zlend>зҡ„еҖјдәҶгҖӮеңЁziplistзҡ„еҫҲеӨҡж“ҚдҪңзҡ„е®һзҺ°дёӯпјҢйғҪдјҡж №жҚ®ж•°жҚ®йЎ№зҡ„第1дёӘеӯ—иҠӮжҳҜдёҚжҳҜ255жқҘеҲӨж–ӯеҪ“еүҚжҳҜдёҚжҳҜеҲ°иҫҫziplistзҡ„з»“е°ҫдәҶпјҢеӣ жӯӨдёҖдёӘжӯЈеёёзҡ„ж•°жҚ®зҡ„第1дёӘеӯ—иҠӮпјҲд№ҹе°ұжҳҜ<prevrawlen>зҡ„第1дёӘеӯ—иҠӮпјүжҳҜдёҚиғҪеӨҹеҸ–255иҝҷдёӘеҖјзҡ„пјҢеҗҰеҲҷе°ұеҶІзӘҒдәҶгҖӮ
иҖҢ<len>еӯ—ж®өе°ұжӣҙеҠ еӨҚжқӮдәҶпјҢе®ғж №жҚ®з¬¬1дёӘеӯ—иҠӮзҡ„дёҚеҗҢпјҢжҖ»е…ұеҲҶдёә9з§Қжғ…еҶөпјҲдёӢйқўзҡ„иЎЁзӨәжі•жҳҜжҢүдәҢиҝӣеҲ¶иЎЁзӨәпјүпјҡ
|00pppppp| - 1 byteгҖӮ第1дёӘеӯ—иҠӮжңҖй«ҳдёӨдёӘbitжҳҜ00пјҢйӮЈд№Ҳ<len>еӯ—ж®өеҸӘжңү1дёӘеӯ—иҠӮпјҢеү©дҪҷзҡ„6дёӘbitз”ЁжқҘиЎЁзӨәй•ҝеәҰеҖјпјҢжңҖй«ҳеҸҜд»ҘиЎЁзӨә63 (2^6-1)гҖӮ
|01pppppp|qqqqqqqq| - 2 bytesгҖӮ第1дёӘеӯ—иҠӮжңҖй«ҳдёӨдёӘbitжҳҜ01пјҢйӮЈд№Ҳ<len>еӯ—ж®өеҚ 2дёӘеӯ—иҠӮпјҢжҖ»е…ұжңү14дёӘbitз”ЁжқҘиЎЁзӨәй•ҝеәҰеҖјпјҢжңҖй«ҳеҸҜд»ҘиЎЁзӨә16383 (2^14-1)гҖӮ
|10__|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5 bytesгҖӮ第1дёӘеӯ—иҠӮжңҖй«ҳдёӨдёӘbitжҳҜ10пјҢйӮЈд№Ҳlenеӯ—ж®өеҚ 5дёӘеӯ—иҠӮпјҢжҖ»е…ұдҪҝз”Ё32дёӘbitжқҘиЎЁзӨәй•ҝеәҰеҖјпјҲ6дёӘbitиҲҚејғдёҚз”ЁпјүпјҢжңҖй«ҳеҸҜд»ҘиЎЁзӨә2^32-1гҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡеңЁеүҚдёүз§Қжғ…еҶөдёӢпјҢ<data>йғҪжҳҜжҢүеӯ—з¬ҰдёІжқҘеӯҳеӮЁзҡ„пјӣд»ҺдёӢйқўз¬¬4з§Қжғ…еҶөејҖе§ӢпјҢ<data>ејҖе§ӢеҸҳдёәжҢүж•ҙж•°жқҘеӯҳеӮЁдәҶгҖӮ
|11000000| - 1 byteгҖӮ<len>еӯ—ж®өеҚ з”Ё1дёӘеӯ—иҠӮпјҢеҖјдёә0xC0пјҢеҗҺйқўзҡ„ж•°жҚ®<data>еӯҳеӮЁдёә2дёӘеӯ—иҠӮзҡ„int16_tзұ»еһӢгҖӮ
|11010000| - 1 byteгҖӮ<len>еӯ—ж®өеҚ з”Ё1дёӘеӯ—иҠӮпјҢеҖјдёә0xD0пјҢеҗҺйқўзҡ„ж•°жҚ®<data>еӯҳеӮЁдёә4дёӘеӯ—иҠӮзҡ„int32_tзұ»еһӢгҖӮ
|11100000| - 1 byteгҖӮ<len>еӯ—ж®өеҚ з”Ё1дёӘеӯ—иҠӮпјҢеҖјдёә0xE0пјҢеҗҺйқўзҡ„ж•°жҚ®<data>еӯҳеӮЁдёә8дёӘеӯ—иҠӮзҡ„int64_tзұ»еһӢгҖӮ
|11110000| - 1 byteгҖӮ<len>еӯ—ж®өеҚ з”Ё1дёӘеӯ—иҠӮпјҢеҖјдёә0xF0пјҢеҗҺйқўзҡ„ж•°жҚ®<data>еӯҳеӮЁдёә3дёӘеӯ—иҠӮй•ҝзҡ„ж•ҙж•°гҖӮ
|11111110| - 1 byteгҖӮ<len>еӯ—ж®өеҚ з”Ё1дёӘеӯ—иҠӮпјҢеҖјдёә0xFEпјҢеҗҺйқўзҡ„ж•°жҚ®<data>еӯҳеӮЁдёә1дёӘеӯ—иҠӮзҡ„ж•ҙж•°гҖӮ
|1111xxxx| - - (xxxxзҡ„еҖјеңЁ0001е’Ң1101д№Ӣй—ҙ)гҖӮиҝҷжҳҜдёҖз§Қзү№ж®Ҡжғ…еҶөпјҢxxxxд»Һ1еҲ°13дёҖе…ұ13дёӘеҖјпјҢиҝҷж—¶е°ұз”Ёиҝҷ13дёӘеҖјжқҘиЎЁзӨәзңҹжӯЈзҡ„ж•°жҚ®гҖӮжіЁж„ҸпјҢиҝҷйҮҢжҳҜиЎЁзӨәзңҹжӯЈзҡ„ж•°жҚ®пјҢиҖҢдёҚжҳҜж•°жҚ®й•ҝеәҰдәҶгҖӮд№ҹе°ұжҳҜиҜҙпјҢеңЁиҝҷз§Қжғ…еҶөдёӢпјҢеҗҺйқўдёҚеҶҚйңҖиҰҒдёҖдёӘеҚ•зӢ¬зҡ„<data>еӯ—ж®өжқҘиЎЁзӨәзңҹжӯЈзҡ„ж•°жҚ®дәҶпјҢиҖҢжҳҜ<len>е’Ң<data>еҗҲдәҢдёәдёҖдәҶгҖӮеҸҰеӨ–пјҢз”ұдәҺxxxxеҸӘиғҪеҸ–0001е’Ң1101иҝҷ13дёӘеҖјдәҶпјҲе…¶е®ғеҸҜиғҪзҡ„еҖје’Ңе…¶е®ғжғ…еҶөеҶІзӘҒдәҶпјҢжҜ”еҰӮ0000е’Ң1110еҲҶеҲ«еҗҢеүҚйқўз¬¬7з§Қ第8з§Қжғ…еҶөеҶІзӘҒпјҢ1111и·ҹз»“жқҹж Үи®°еҶІзӘҒпјүпјҢиҖҢе°Ҹж•°еҖјеә”иҜҘд»Һ0ејҖе§ӢпјҢеӣ жӯӨиҝҷ13дёӘеҖјеҲҶеҲ«иЎЁзӨә0еҲ°12пјҢеҚіxxxxзҡ„еҖјеҮҸеҺ»1жүҚжҳҜе®ғжүҖиҰҒиЎЁзӨәзҡ„йӮЈдёӘж•ҙж•°ж•°жҚ®зҡ„еҖјгҖӮ
еҘҪдәҶпјҢziplistзҡ„ж•°жҚ®з»“жһ„е®ҡд№үпјҢжҲ‘们д»Ӣз»Қе®ҢдәҶпјҢзҺ°еңЁжҲ‘们зңӢдёҖдёӘе…·дҪ“зҡ„дҫӢеӯҗгҖӮ
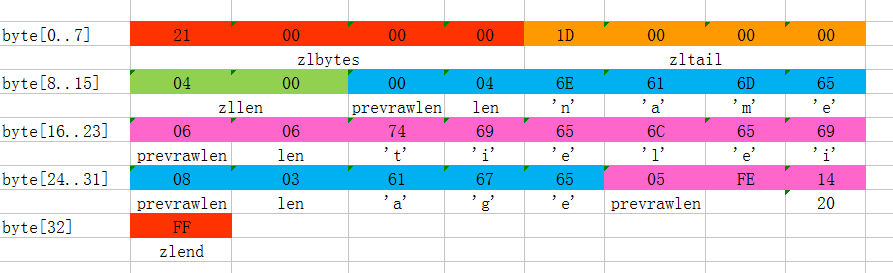
дёҠеӣҫжҳҜдёҖд»Ҫзңҹе®һзҡ„ziplistж•°жҚ®гҖӮжҲ‘们йҖҗйЎ№и§ЈиҜ»дёҖдёӢпјҡ
иҝҷдёӘziplistдёҖе…ұеҢ…еҗ«33дёӘеӯ—иҠӮгҖӮеӯ—иҠӮзј–еҸ·д»Һbyte[0]еҲ°byte[32]гҖӮеӣҫдёӯжҜҸдёӘеӯ—иҠӮзҡ„еҖјдҪҝз”Ё16иҝӣеҲ¶иЎЁзӨәгҖӮ
еӨҙ4дёӘеӯ—иҠӮпјҲ0x21000000пјүжҳҜжҢүе°Ҹз«ҜпјҲlittle endianпјүжЁЎејҸеӯҳеӮЁзҡ„<zlbytes>еӯ—ж®өгҖӮд»Җд№ҲжҳҜе°Ҹз«Ҝе‘ўпјҹе°ұжҳҜжҢҮж•°жҚ®зҡ„дҪҺеӯ—иҠӮдҝқеӯҳеңЁеҶ…еӯҳзҡ„дҪҺең°еқҖдёӯпјҲеҸӮи§Ғз»ҙеҹәзҷҫ科иҜҚжқЎ
EndiannessпјүгҖӮеӣ жӯӨпјҢиҝҷйҮҢ<zlbytes>зҡ„еҖјеә”иҜҘи§ЈжһҗжҲҗ0x00000021пјҢз”ЁеҚҒиҝӣеҲ¶иЎЁзӨәжӯЈеҘҪе°ұжҳҜ33гҖӮ
жҺҘдёӢжқҘ4дёӘеӯ—иҠӮпјҲbyte[4..7]пјүжҳҜ<zltail>пјҢз”Ёе°Ҹз«ҜеӯҳеӮЁжЁЎејҸжқҘи§ЈйҮҠпјҢе®ғзҡ„еҖјжҳҜ0x0000001DпјҲеҖјдёә29пјүпјҢиЎЁзӨәжңҖеҗҺдёҖдёӘж•°жҚ®йЎ№еңЁbyte[29]зҡ„дҪҚзҪ®пјҲйӮЈдёӘж•°жҚ®йЎ№дёә0x05FE14пјүгҖӮ
еҶҚжҺҘдёӢжқҘ2дёӘеӯ—иҠӮпјҲbyte[8..9]пјүпјҢеҖјдёә0x0004пјҢиЎЁзӨәиҝҷдёӘziplistйҮҢдёҖе…ұеӯҳжңү4йЎ№ж•°жҚ®гҖӮ
жҺҘдёӢжқҘ6дёӘеӯ—иҠӮпјҲbyte[10..15]пјүжҳҜ第1дёӘж•°жҚ®йЎ№гҖӮе…¶дёӯпјҢprevrawlen=0пјҢеӣ дёәе®ғеүҚйқўжІЎжңүж•°жҚ®йЎ№пјӣlen=4пјҢзӣёеҪ“дәҺеүҚйқўе®ҡд№үзҡ„9з§Қжғ…еҶөдёӯзҡ„第1з§ҚпјҢиЎЁзӨәеҗҺйқў4дёӘеӯ—иҠӮжҢүеӯ—з¬ҰдёІеӯҳеӮЁж•°жҚ®пјҢж•°жҚ®зҡ„еҖјдёәвҖқnameвҖқгҖӮ
жҺҘдёӢжқҘ8дёӘеӯ—иҠӮпјҲbyte[16..23]пјүжҳҜ第2дёӘж•°жҚ®йЎ№пјҢдёҺеүҚйқўж•°жҚ®йЎ№еӯҳеӮЁж јејҸзұ»дјјпјҢеӯҳеӮЁ1дёӘеӯ—з¬ҰдёІвҖқtieleiвҖқгҖӮ
жҺҘдёӢжқҘ5дёӘеӯ—иҠӮпјҲbyte[24..28]пјүжҳҜ第3дёӘж•°жҚ®йЎ№пјҢдёҺеүҚйқўж•°жҚ®йЎ№еӯҳеӮЁж јејҸзұ»дјјпјҢеӯҳеӮЁ1дёӘеӯ—з¬ҰдёІвҖқageвҖқгҖӮ
жҺҘдёӢжқҘ3дёӘеӯ—иҠӮпјҲbyte[29..31]пјүжҳҜжңҖеҗҺдёҖдёӘж•°жҚ®йЎ№пјҢе®ғзҡ„ж јејҸдёҺеүҚйқўзҡ„ж•°жҚ®йЎ№еӯҳеӮЁж јејҸдёҚеӨӘдёҖж ·гҖӮе…¶дёӯпјҢ第1дёӘеӯ—иҠӮprevrawlen=5пјҢиЎЁзӨәеүҚдёҖдёӘж•°жҚ®йЎ№еҚ з”Ё5дёӘеӯ—иҠӮпјӣ第2дёӘеӯ—иҠӮ=FEпјҢзӣёеҪ“дәҺеүҚйқўе®ҡд№үзҡ„9з§Қжғ…еҶөдёӯзҡ„第8з§ҚпјҢжүҖд»ҘеҗҺйқўиҝҳжңү1дёӘеӯ—иҠӮз”ЁжқҘиЎЁзӨәзңҹжӯЈзҡ„ж•°жҚ®пјҢ并且д»Ҙж•ҙж•°иЎЁзӨәгҖӮе®ғзҡ„еҖјжҳҜ20пјҲ0x14пјүгҖӮ
жңҖеҗҺ1дёӘеӯ—иҠӮпјҲbyte[32]пјүиЎЁзӨә<zlend>пјҢжҳҜеӣәе®ҡзҡ„еҖј255пјҲ0xFFпјүгҖӮ
жҖ»з»“дёҖдёӢпјҢиҝҷдёӘziplistйҮҢеӯҳдәҶ4дёӘж•°жҚ®йЎ№пјҢеҲҶеҲ«дёәпјҡ
еӯ—з¬ҰдёІ: вҖңnameвҖқ
еӯ—з¬ҰдёІ: вҖңtieleiвҖқ
еӯ—з¬ҰдёІ: вҖңageвҖқ
ж•ҙж•°: 20
пјҲеҘҪеҗ§пјҢиў«дҪ еҸ‘зҺ°дәҶ~~tieleiе®һйҷ…дёҠеҪ“然дёҚжҳҜ20еІҒпјҢд»–е“ӘжңүйӮЈд№Ҳе№ҙиҪ»е•ҠвҖҰвҖҰпјү
е®һйҷ…дёҠпјҢиҝҷдёӘziplistжҳҜйҖҡиҝҮдёӨдёӘhsetе‘Ҫд»ӨеҲӣе»әеҮәжқҘзҡ„гҖӮиҝҷдёӘжҲ‘们еҗҺеҚҠйғЁеҲҶдјҡеҶҚжҸҗеҲ°гҖӮ
еҘҪдәҶпјҢ既然дҪ е·Із»Ҹйҳ…иҜ»еҲ°иҝҷйҮҢдәҶпјҢиҜҙжҳҺдҪ иҝҳжҳҜеҫҲжңүиҖҗеҝғзҡ„пјҲе…¶е®һжҲ‘еҶҷеҲ°иҝҷйҮҢд№ҹе·Із»ҸзҙҜеҫ—дёҚиЎҢдәҶпјүгҖӮеҸҜд»Ҙе…ҲжҠҠжң¬ж–Ү收и—ҸпјҢдј‘жҒҜдёҖдёӢпјҢеӣһеӨҙеҶҚзңӢеҗҺеҚҠйғЁеҲҶгҖӮ
жҺҘдёӢжқҘжҲ‘иҰҒиҙҙдёҖдәӣд»Јз ҒдәҶгҖӮ
жҲ‘们е…ҲдёҚзқҖжҖҘзңӢе®һзҺ°пјҢе…ҲжқҘжҢ‘еҮ дёӘziplistзҡ„йҮҚиҰҒзҡ„жҺҘеҸЈпјҢзңӢзңӢе®ғ们й•ҝд»Җд№Ҳж ·еӯҗпјҡ
unsigned char *ziplistNew(void); unsigned char *ziplistMerge(unsigned char **first, unsigned char **second); unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where); unsigned char *ziplistIndex(unsigned char *zl, int index); unsigned char *ziplistNext(unsigned char *zl, unsigned char *p); unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p); unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen); unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p); unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip); unsigned int ziplistLen(unsigned char *zl);
жҲ‘们д»ҺиҝҷдәӣжҺҘеҸЈзҡ„еҗҚеӯ—е°ұеҸҜд»ҘзІ—з•ҘзҢңеҮәе®ғ们зҡ„еҠҹиғҪпјҢдёӢйқўз®ҖеҚ•и§ЈйҮҠдёҖдёӢпјҡ
ziplistзҡ„ж•°жҚ®зұ»еһӢпјҢжІЎжңүз”ЁиҮӘе®ҡд№үзҡ„structд№Ӣзұ»зҡ„жқҘиЎЁиҫҫпјҢиҖҢе°ұжҳҜз®ҖеҚ•зҡ„unsigned char *гҖӮиҝҷжҳҜеӣ дёәziplistжң¬иҙЁдёҠе°ұжҳҜдёҖеқ—иҝһз»ӯеҶ…еӯҳпјҢеҶ…йғЁз»„жҲҗз»“жһ„еҸҲжҳҜдёҖдёӘй«ҳеәҰеҠЁжҖҒзҡ„и®ҫи®ЎпјҲеҸҳй•ҝзј–з ҒпјүпјҢд№ҹжІЎжі•з”ЁдёҖдёӘеӣәе®ҡзҡ„ж•°жҚ®з»“жһ„жқҘиЎЁиҫҫгҖӮ
ziplistNew: еҲӣе»әдёҖдёӘз©әзҡ„ziplistпјҲеҸӘеҢ…еҗ«<zlbytes><zltail><zllen><zlend>пјүгҖӮ
ziplistMerge: е°ҶдёӨдёӘziplistеҗҲ并жҲҗдёҖдёӘж–°зҡ„ziplistгҖӮ
ziplistPush: еңЁziplistзҡ„еӨҙйғЁжҲ–е°ҫз«ҜжҸ’е…ҘдёҖж®өж•°жҚ®пјҲдә§з”ҹдёҖдёӘж–°зҡ„ж•°жҚ®йЎ№пјүгҖӮжіЁж„ҸдёҖдёӢиҝҷдёӘжҺҘеҸЈзҡ„иҝ”еӣһеҖјпјҢжҳҜдёҖдёӘж–°зҡ„ziplistгҖӮи°ғз”Ёж–№еҝ…йЎ»з”ЁиҝҷйҮҢиҝ”еӣһзҡ„ж–°зҡ„ziplistпјҢжӣҝжҚўд№ӢеүҚдј иҝӣжқҘзҡ„ж—§зҡ„ziplistеҸҳйҮҸпјҢиҖҢз»ҸиҝҮиҝҷдёӘеҮҪж•°еӨ„зҗҶд№ӢеҗҺпјҢеҺҹжқҘж—§зҡ„ziplistеҸҳйҮҸе°ұеӨұж•ҲдәҶгҖӮдёәд»Җд№ҲдёҖдёӘз®ҖеҚ•зҡ„жҸ’е…Ҙж“ҚдҪңдјҡеҜјиҮҙдә§з”ҹдёҖдёӘж–°зҡ„ziplistе‘ўпјҹиҝҷжҳҜеӣ дёәziplistжҳҜдёҖеқ—иҝһз»ӯз©әй—ҙпјҢеҜ№е®ғзҡ„иҝҪеҠ ж“ҚдҪңпјҢдјҡеј•еҸ‘еҶ…еӯҳзҡ„reallocпјҢеӣ жӯӨziplistзҡ„еҶ…еӯҳдҪҚзҪ®еҸҜиғҪдјҡеҸ‘з”ҹеҸҳеҢ–гҖӮе®һйҷ…дёҠпјҢжҲ‘们еңЁд№ӢеүҚд»Ӣз»Қsdsзҡ„ж–Үз« дёӯжҸҗеҲ°иҝҮзұ»дјјиҝҷз§ҚжҺҘеҸЈдҪҝз”ЁжЁЎејҸпјҲеҸӮи§ҒsdscatlenеҮҪж•°зҡ„иҜҙжҳҺпјүгҖӮ
ziplistIndex: иҝ”еӣһindexеҸӮж•°жҢҮе®ҡзҡ„ж•°жҚ®йЎ№зҡ„еҶ…еӯҳдҪҚзҪ®гҖӮindexеҸҜд»ҘжҳҜиҙҹж•°пјҢиЎЁзӨәд»Һе°ҫз«Ҝеҗ‘еүҚиҝӣиЎҢзҙўеј•гҖӮ
ziplistNextе’ҢziplistPrevеҲҶеҲ«иҝ”еӣһдёҖдёӘziplistдёӯжҢҮе®ҡж•°жҚ®йЎ№pзҡ„еҗҺдёҖйЎ№е’ҢеүҚдёҖйЎ№гҖӮ
ziplistInsert: еңЁziplistзҡ„д»»ж„Ҹж•°жҚ®йЎ№еүҚйқўжҸ’е…ҘдёҖдёӘж–°зҡ„ж•°жҚ®йЎ№гҖӮ
ziplistDelete: еҲ йҷӨжҢҮе®ҡзҡ„ж•°жҚ®йЎ№гҖӮ
ziplistFind: жҹҘжүҫз»ҷе®ҡзҡ„ж•°жҚ®пјҲз”ұvstrе’ҢvlenжҢҮе®ҡпјүгҖӮжіЁж„Ҹе®ғжңүдёҖдёӘskipеҸӮж•°пјҢиЎЁзӨәжҹҘжүҫзҡ„ж—¶еҖҷжҜҸж¬ЎжҜ”иҫғд№Ӣй—ҙиҰҒи·іиҝҮеҮ дёӘж•°жҚ®йЎ№гҖӮдёәд»Җд№Ҳдјҡжңүиҝҷд№ҲдёҖдёӘеҸӮж•°е‘ўпјҹе…¶е®һиҝҷдёӘеҸӮж•°зҡ„дё»иҰҒз”ЁйҖ”жҳҜеҪ“з”ЁziplistиЎЁзӨәhashз»“жһ„зҡ„ж—¶еҖҷпјҢжҳҜжҢүз…§дёҖдёӘfieldпјҢдёҖдёӘvalueжқҘдҫқж¬Ўеӯҳе…Ҙziplistзҡ„гҖӮд№ҹе°ұжҳҜиҜҙпјҢеҒ¶ж•°зҙўеј•зҡ„ж•°жҚ®йЎ№еӯҳfieldпјҢеҘҮж•°зҙўеј•зҡ„ж•°жҚ®йЎ№еӯҳvalueгҖӮеҪ“жҢүз…§fieldзҡ„еҖјиҝӣиЎҢжҹҘжүҫзҡ„ж—¶еҖҷпјҢе°ұйңҖиҰҒжҠҠеҘҮж•°йЎ№и·іиҝҮеҺ»гҖӮ
ziplistLen: и®Ўз®—ziplistзҡ„й•ҝеәҰпјҲеҚіеҢ…еҗ«ж•°жҚ®йЎ№зҡ„дёӘж•°пјүгҖӮ
ziplistзҡ„зӣёе…іжҺҘеҸЈзҡ„е…·дҪ“е®һзҺ°пјҢиҝҳжҳҜжңүдәӣеӨҚжқӮзҡ„пјҢйҷҗдәҺзҜҮе№…зҡ„еҺҹеӣ пјҢжҲ‘们иҝҷйҮҢеҸӘз»“еҗҲд»Јз ҒжқҘи®Іи§ЈжҸ’е…Ҙзҡ„йҖ»иҫ‘гҖӮжҸ’е…ҘжҳҜеҫҲжңүд»ЈиЎЁжҖ§зҡ„ж“ҚдҪңпјҢйҖҡиҝҮиҝҷйғЁеҲҶжқҘдёҖзӘҘziplistеҶ…йғЁзҡ„е®һзҺ°пјҢе…¶е®ғйғЁеҲҶзҡ„е®һзҺ°жҲ‘们д№ҹе°ұдјҡеҫҲе®№жҳ“зҗҶи§ЈдәҶгҖӮ
ziplistPushе’ҢziplistInsertйғҪжҳҜжҸ’е…ҘпјҢеҸӘжҳҜеҜ№дәҺжҸ’е…ҘдҪҚзҪ®зҡ„йҷҗе®ҡдёҚеҗҢгҖӮе®ғ们еңЁеҶ…йғЁе®һзҺ°йғҪдҫқиө–дёҖдёӘеҗҚдёә__ziplistInsertзҡ„еҶ…йғЁеҮҪж•°пјҢе…¶д»Јз ҒеҰӮдёӢпјҲеҮәиҮӘziplist.cпјү:
static unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* Find out prevlen for the entry that is inserted. */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipEncodeLength will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipPrevEncodeLength(NULL,prevlen);
reqlen += zipEncodeLength(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
/* Store offset because a realloc may change the address of zl. */
offset = p-zl;
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* Apply memory move when necessary and update tail offset. */
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
zipPrevEncodeLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* Write the entry */
p += zipPrevEncodeLength(p,prevlen);
p += zipEncodeLength(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}жҲ‘们жқҘз®ҖеҚ•и§ЈжһҗдёҖдёӢиҝҷж®өд»Јз Ғпјҡ
иҝҷдёӘеҮҪж•°жҳҜеңЁжҢҮе®ҡзҡ„дҪҚзҪ®pжҸ’е…ҘдёҖж®өж–°зҡ„ж•°жҚ®пјҢеҫ…жҸ’е…Ҙж•°жҚ®зҡ„ең°еқҖжҢҮй’ҲжҳҜsпјҢй•ҝеәҰдёәslenгҖӮжҸ’е…ҘеҗҺеҪўжҲҗдёҖдёӘж–°зҡ„ж•°жҚ®йЎ№пјҢеҚ жҚ®еҺҹжқҘpзҡ„й…ҚзҪ®пјҢеҺҹжқҘдҪҚдәҺpдҪҚзҪ®зҡ„ж•°жҚ®йЎ№д»ҘеҸҠеҗҺйқўзҡ„жүҖжңүж•°жҚ®йЎ№пјҢйңҖиҰҒз»ҹдёҖеҗ‘еҗҺ移еҠЁпјҢз»ҷж–°жҸ’е…Ҙзҡ„ж•°жҚ®йЎ№з•ҷеҮәз©әй—ҙгҖӮеҸӮж•°pжҢҮеҗ‘зҡ„жҳҜziplistдёӯжҹҗдёҖдёӘж•°жҚ®йЎ№зҡ„иө·е§ӢдҪҚзҪ®пјҢжҲ–иҖ…еңЁеҗ‘е°ҫз«ҜжҸ’е…Ҙзҡ„ж—¶еҖҷпјҢе®ғжҢҮеҗ‘ziplistзҡ„з»“жқҹж Үи®°<zlend>гҖӮ
еҮҪж•°ејҖе§Ӣе…Ҳи®Ўз®—еҮәеҫ…жҸ’е…ҘдҪҚзҪ®еүҚдёҖдёӘж•°жҚ®йЎ№зҡ„й•ҝеәҰprevlenгҖӮиҝҷдёӘй•ҝеәҰиҰҒеӯҳе…Ҙж–°жҸ’е…Ҙзҡ„ж•°жҚ®йЎ№зҡ„<prevrawlen>еӯ—ж®өгҖӮ
然еҗҺи®Ўз®—еҪ“еүҚж•°жҚ®йЎ№еҚ з”Ёзҡ„жҖ»еӯ—иҠӮж•°reqlenпјҢе®ғеҢ…еҗ«дёүйғЁеҲҶпјҡ<prevrawlen>,
<len>е’ҢзңҹжӯЈзҡ„ж•°жҚ®гҖӮе…¶дёӯзҡ„ж•°жҚ®йғЁеҲҶдјҡйҖҡиҝҮи°ғз”ЁzipTryEncodingе…ҲжқҘе°қиҜ•иҪ¬жҲҗж•ҙж•°гҖӮ
з”ұдәҺжҸ’е…ҘеҜјиҮҙзҡ„ziplistеҜ№дәҺеҶ…еӯҳзҡ„ж–°еўһйңҖжұӮпјҢйҷӨдәҶеҫ…жҸ’е…Ҙж•°жҚ®йЎ№еҚ з”Ёзҡ„reqlenд№ӢеӨ–пјҢиҝҳиҰҒиҖғиҷ‘еҺҹжқҘpдҪҚзҪ®зҡ„ж•°жҚ®йЎ№пјҲзҺ°еңЁиҰҒжҺ’еңЁеҫ…жҸ’е…Ҙж•°жҚ®йЎ№д№ӢеҗҺпјүзҡ„<prevrawlen>еӯ—ж®өзҡ„еҸҳеҢ–гҖӮжң¬жқҘе®ғдҝқеӯҳзҡ„жҳҜеүҚдёҖйЎ№зҡ„жҖ»й•ҝеәҰпјҢзҺ°еңЁеҸҳжҲҗдәҶдҝқеӯҳеҪ“еүҚжҸ’е…Ҙзҡ„ж•°жҚ®йЎ№зҡ„жҖ»й•ҝеәҰгҖӮиҝҷж ·е®ғзҡ„<prevrawlen>еӯ—ж®өжң¬иә«йңҖиҰҒзҡ„еӯҳеӮЁз©әй—ҙд№ҹеҸҜиғҪеҸ‘з”ҹеҸҳеҢ–пјҢиҝҷдёӘеҸҳеҢ–еҸҜиғҪжҳҜеҸҳеӨ§д№ҹеҸҜиғҪжҳҜеҸҳе°ҸгҖӮиҝҷдёӘеҸҳеҢ–дәҶеӨҡе°‘зҡ„еҖјnextdiffпјҢжҳҜи°ғз”ЁzipPrevLenByteDiffи®Ўз®—еҮәжқҘзҡ„гҖӮеҰӮжһңеҸҳеӨ§дәҶпјҢnextdiffжҳҜжӯЈеҖјпјҢеҗҰеҲҷжҳҜиҙҹеҖјгҖӮ
зҺ°еңЁеҫҲе®№жҳ“з®—еҮәжқҘжҸ’е…ҘеҗҺж–°зҡ„ziplistйңҖиҰҒеӨҡе°‘еӯ—иҠӮдәҶпјҢ然еҗҺи°ғз”ЁziplistResizeжқҘйҮҚж–°и°ғж•ҙеӨ§е°ҸгҖӮziplistResizeзҡ„е®һзҺ°йҮҢдјҡи°ғз”Ёallocatorзҡ„zreallocпјҢе®ғжңүеҸҜиғҪдјҡйҖ жҲҗж•°жҚ®жӢ·иҙқгҖӮ
зҺ°еңЁйўқеӨ–зҡ„з©әй—ҙжңүдәҶпјҢжҺҘдёӢжқҘе°ұжҳҜе°ҶеҺҹжқҘpдҪҚзҪ®зҡ„ж•°жҚ®йЎ№д»ҘеҸҠеҗҺйқўзҡ„жүҖжңүж•°жҚ®йғҪеҗ‘еҗҺжҢӘеҠЁпјҢ并дёәе®ғи®ҫзҪ®ж–°зҡ„<prevrawlen>еӯ—ж®өгҖӮжӯӨеӨ–пјҢиҝҳеҸҜиғҪйңҖиҰҒи°ғж•ҙziplistзҡ„<zltail>еӯ—ж®өгҖӮ
жңҖеҗҺпјҢз»„иЈ…ж–°зҡ„еҫ…жҸ’е…Ҙж•°жҚ®йЎ№пјҢж”ҫеңЁдҪҚзҪ®pгҖӮ
hashжҳҜRedisдёӯеҸҜд»Ҙз”ЁжқҘеӯҳеӮЁдёҖдёӘеҜ№иұЎз»“жһ„зҡ„жҜ”иҫғзҗҶжғізҡ„ж•°жҚ®зұ»еһӢгҖӮдёҖдёӘеҜ№иұЎзҡ„еҗ„дёӘеұһжҖ§пјҢжӯЈеҘҪеҜ№еә”дёҖдёӘhashз»“жһ„зҡ„еҗ„дёӘfieldгҖӮ
жҲ‘们еңЁзҪ‘дёҠеҫҲе®№жҳ“жүҫеҲ°иҝҷж ·дёҖдәӣжҠҖжңҜж–Үз« пјҢе®ғ们дјҡиҜҙеӯҳеӮЁдёҖдёӘеҜ№иұЎпјҢдҪҝз”ЁhashжҜ”stringиҰҒиҠӮзңҒеҶ…еӯҳгҖӮе®һйҷ…дёҠиҝҷд№ҲиҜҙжҳҜжңүеүҚжҸҗзҡ„пјҢе…·дҪ“еҸ–еҶідәҺеҜ№иұЎжҖҺд№ҲжқҘеӯҳеӮЁгҖӮеҰӮжһңдҪ жҠҠеҜ№иұЎзҡ„еӨҡдёӘеұһжҖ§еӯҳеӮЁеҲ°еӨҡдёӘkeyдёҠпјҲеҗ„дёӘеұһжҖ§еҖјеӯҳжҲҗstringпјүпјҢеҪ“然еҚ зҡ„еҶ…еӯҳиҰҒеӨҡгҖӮдҪҶеҰӮжһңдҪ йҮҮз”ЁдёҖдәӣеәҸеҲ—еҢ–ж–№жі•пјҢжҜ”еҰӮ Protocol BuffersпјҢжҲ–иҖ… Apache ThriftпјҢе…ҲжҠҠеҜ№иұЎеәҸеҲ—еҢ–дёәеӯ—иҠӮж•°з»„пјҢ然еҗҺеҶҚеӯҳе…ҘеҲ°Redisзҡ„stringдёӯпјҢйӮЈд№Ҳи·ҹhashзӣёжҜ”пјҢе“ӘдёҖз§ҚжӣҙзңҒеҶ…еӯҳпјҢе°ұдёҚдёҖе®ҡдәҶгҖӮ
еҪ“然пјҢhashжҜ”еәҸеҲ—еҢ–еҗҺеҶҚеӯҳе…Ҙstringзҡ„ж–№ејҸпјҢеңЁж”ҜжҢҒзҡ„ж“ҚдҪңе‘Ҫд»ӨдёҠпјҢиҝҳжҳҜжңүдјҳеҠҝзҡ„пјҡе®ғж—ўж”ҜжҢҒеӨҡдёӘfieldеҗҢж—¶еӯҳеҸ–пјҲhmset/hmgetпјүпјҢд№ҹж”ҜжҢҒжҢүз…§жҹҗдёӘзү№е®ҡзҡ„fieldеҚ•зӢ¬еӯҳеҸ–пјҲhset/hgetпјүгҖӮ
е®һйҷ…дёҠпјҢhashйҡҸзқҖж•°жҚ®зҡ„еўһеӨ§пјҢе…¶еә•еұӮж•°жҚ®з»“жһ„зҡ„е®һзҺ°жҳҜдјҡеҸ‘з”ҹеҸҳеҢ–зҡ„пјҢеҪ“然еӯҳеӮЁж•ҲзҺҮд№ҹе°ұдёҚеҗҢгҖӮеңЁfieldжҜ”иҫғе°‘пјҢеҗ„дёӘvalueеҖјд№ҹжҜ”иҫғе°Ҹзҡ„ж—¶еҖҷпјҢhashйҮҮз”ЁziplistжқҘе®һзҺ°пјӣиҖҢйҡҸзқҖfieldеўһеӨҡе’ҢvalueеҖјеўһеӨ§пјҢhashеҸҜиғҪдјҡеҸҳжҲҗdictжқҘе®һзҺ°гҖӮеҪ“hashеә•еұӮеҸҳжҲҗdictжқҘе®һзҺ°зҡ„ж—¶еҖҷпјҢе®ғзҡ„еӯҳеӮЁж•ҲзҺҮе°ұжІЎжі•и·ҹйӮЈдәӣеәҸеҲ—еҢ–ж–№ејҸзӣёжҜ”дәҶгҖӮ
еҪ“жҲ‘们дёәжҹҗдёӘkey第дёҖж¬Ўжү§иЎҢ
hset key field value е‘Ҫд»Өзҡ„ж—¶еҖҷпјҢRedisдјҡеҲӣе»әдёҖдёӘhashз»“жһ„пјҢиҝҷдёӘж–°еҲӣе»әзҡ„hashеә•еұӮе°ұжҳҜдёҖдёӘziplistгҖӮ
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}дёҠйқўзҡ„createHashObjectеҮҪж•°пјҢеҮәиҮӘobject.cпјҢе®ғиҙҹиҙЈзҡ„д»»еҠЎе°ұжҳҜеҲӣе»әдёҖдёӘж–°зҡ„hashз»“жһ„гҖӮеҸҜд»ҘзңӢеҮәпјҢе®ғеҲӣе»әдәҶдёҖдёӘtype = OBJ_HASHдҪҶencoding = OBJ_ENCODING_ZIPLISTзҡ„robjеҜ№иұЎгҖӮ
е®һйҷ…дёҠпјҢжң¬ж–ҮеүҚйқўз»ҷеҮәзҡ„йӮЈдёӘziplistе®һдҫӢпјҢе°ұжҳҜз”ұеҰӮдёӢдёӨдёӘе‘Ҫд»Өжһ„е»әеҮәжқҘзҡ„гҖӮ
hset user:100 name tielei hset user:100 age 20
жҜҸжү§иЎҢдёҖж¬Ўhsetе‘Ҫд»ӨпјҢжҸ’е…Ҙзҡ„fieldе’ҢvalueеҲҶеҲ«дҪңдёәдёҖдёӘж–°зҡ„ж•°жҚ®йЎ№жҸ’е…ҘеҲ°ziplistдёӯпјҲеҚіжҜҸж¬Ўhsetдә§з”ҹдёӨдёӘж•°жҚ®йЎ№пјүгҖӮ
еҪ“йҡҸзқҖж•°жҚ®зҡ„жҸ’е…ҘпјҢhashеә•еұӮзҡ„иҝҷдёӘziplistе°ұеҸҜиғҪдјҡиҪ¬жҲҗdictгҖӮйӮЈд№ҲеҲ°еә•жҸ’е…ҘеӨҡе°‘жүҚдјҡиҪ¬е‘ўпјҹ
иҝҳи®°еҫ—жң¬ж–ҮејҖеӨҙжҸҗеҲ°зҡ„дёӨдёӘRedisй…ҚзҪ®еҗ—пјҹ
hash-max-ziplist-entries 512 hash-max-ziplist-value 64
иҝҷдёӘй…ҚзҪ®зҡ„ж„ҸжҖқжҳҜиҜҙпјҢеңЁеҰӮдёӢдёӨдёӘжқЎд»¶д№ӢдёҖж»Ўи¶ізҡ„ж—¶еҖҷпјҢziplistдјҡиҪ¬жҲҗdictпјҡ
еҪ“hashдёӯзҡ„ж•°жҚ®йЎ№пјҲеҚіfield-valueеҜ№пјүзҡ„ж•°зӣ®и¶…иҝҮ512зҡ„ж—¶еҖҷпјҢд№ҹе°ұжҳҜziplistж•°жҚ®йЎ№и¶…иҝҮ1024зҡ„ж—¶еҖҷпјҲиҜ·еҸӮиҖғt_hash.cдёӯзҡ„hashTypeSetеҮҪж•°пјүгҖӮ
еҪ“hashдёӯжҸ’е…Ҙзҡ„д»»ж„ҸдёҖдёӘvalueзҡ„й•ҝеәҰи¶…иҝҮдәҶ64зҡ„ж—¶еҖҷпјҲиҜ·еҸӮиҖғt_hash.cдёӯзҡ„hashTypeTryConversionеҮҪж•°пјүгҖӮ
Redisзҡ„hashд№ӢжүҖд»Ҙиҝҷж ·и®ҫи®ЎпјҢжҳҜеӣ дёәеҪ“ziplistеҸҳеҫ—еҫҲеӨ§зҡ„ж—¶еҖҷпјҢе®ғжңүеҰӮдёӢеҮ дёӘзјәзӮ№пјҡ
жҜҸж¬ЎжҸ’е…ҘжҲ–дҝ®ж”№еј•еҸ‘зҡ„reallocж“ҚдҪңдјҡжңүжӣҙеӨ§зҡ„жҰӮзҺҮйҖ жҲҗеҶ…еӯҳжӢ·иҙқпјҢд»ҺиҖҢйҷҚдҪҺжҖ§иғҪгҖӮ
дёҖж—ҰеҸ‘з”ҹеҶ…еӯҳжӢ·иҙқпјҢеҶ…еӯҳжӢ·иҙқзҡ„жҲҗжң¬д№ҹзӣёеә”еўһеҠ пјҢеӣ дёәиҰҒжӢ·иҙқжӣҙеӨ§зҡ„дёҖеқ—ж•°жҚ®гҖӮ
еҪ“ziplistж•°жҚ®йЎ№иҝҮеӨҡзҡ„ж—¶еҖҷпјҢеңЁе®ғдёҠйқўжҹҘжүҫжҢҮе®ҡзҡ„ж•°жҚ®йЎ№е°ұдјҡжҖ§иғҪеҸҳеҫ—еҫҲдҪҺпјҢеӣ дёәziplistдёҠзҡ„жҹҘжүҫйңҖиҰҒиҝӣиЎҢйҒҚеҺҶгҖӮ
дёҠиҝ°еҶ…е®№е°ұжҳҜRedisдёӯеҶ…йғЁж•°жҚ®з»“жһ„ziplistзҡ„дҪңз”ЁжҳҜд»Җд№ҲпјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ