жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
MySQLж•°жҚ®еә“дёӯжҖҺд№ҲиҝӣиЎҢдә’иҒ”зҪ‘еёёз”Ёжһ¶жһ„зҡ„жҗӯе»әпјҢзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
1гҖҒй«ҳеҸҜз”Ё
2гҖҒй«ҳжҖ§иғҪ
3гҖҒдёҖиҮҙжҖ§
4гҖҒжү©еұ•жҖ§
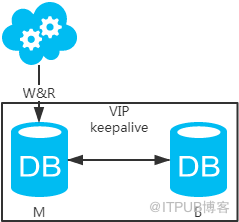
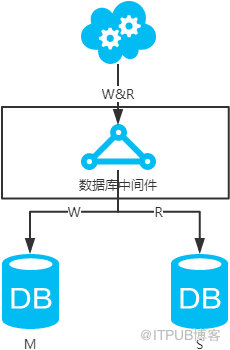
jdbc:mysql://vip:3306/xxdb
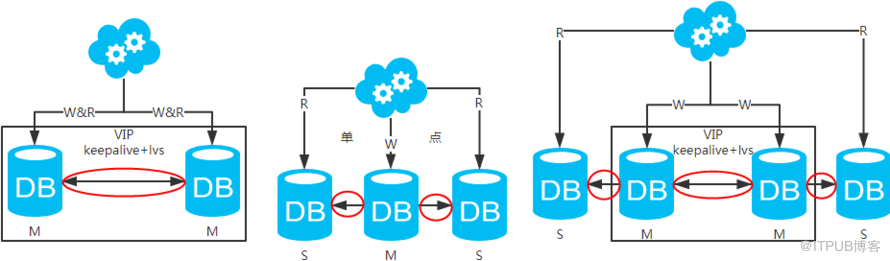
й«ҳеҸҜз”ЁеҲҶжһҗпјҡй«ҳеҸҜз”ЁпјҢдё»еә“жҢӮдәҶпјҢkeepaliveпјҲеҸӘжҳҜдёҖз§Қе·Ҙе…·пјүдјҡиҮӘеҠЁеҲҮжҚўеҲ°еӨҮеә“гҖӮиҝҷдёӘиҝҮзЁӢеҜ№дёҡеҠЎеұӮжҳҜйҖҸжҳҺзҡ„пјҢж— йңҖдҝ®ж”№д»Јз ҒжҲ–й…ҚзҪ®гҖӮ
й«ҳжҖ§иғҪеҲҶжһҗпјҡиҜ»еҶҷйғҪж“ҚдҪңдё»еә“пјҢеҫҲе®№жҳ“дә§з”ҹ瓶йўҲгҖӮеӨ§йғЁеҲҶдә’иҒ”зҪ‘еә”з”ЁиҜ»еӨҡеҶҷе°‘пјҢиҜ»дјҡе…ҲжҲҗдёә瓶йўҲпјҢиҝӣиҖҢеҪұе“ҚеҶҷжҖ§иғҪгҖӮеҸҰеӨ–пјҢеӨҮеә“еҸӘжҳҜеҚ•зәҜзҡ„еӨҮд»ҪпјҢиө„жәҗеҲ©з”ЁзҺҮ50%пјҢиҝҷзӮ№ж–№жЎҲдәҢеҸҜи§ЈеҶігҖӮ
дёҖиҮҙжҖ§еҲҶжһҗпјҡиҜ»еҶҷйғҪж“ҚдҪңдё»еә“пјҢдёҚеӯҳеңЁж•°жҚ®дёҖиҮҙжҖ§й—®йўҳгҖӮ
жү©еұ•жҖ§еҲҶжһҗпјҡж— жі•йҖҡиҝҮеҠ д»Һеә“жқҘжү©еұ•иҜ»жҖ§иғҪпјҢиҝӣиҖҢжҸҗй«ҳж•ҙдҪ“жҖ§иғҪгҖӮ
еҸҜиҗҪең°еҲҶжһҗпјҡдёӨзӮ№еҪұе“ҚиҗҪең°дҪҝз”ЁгҖӮ第дёҖпјҢжҖ§иғҪдёҖиҲ¬пјҢиҝҷзӮ№еҸҜд»ҘйҖҡиҝҮе»әз«Ӣй«ҳж•Ҳзҡ„зҙўеј•е’Ңеј•е…Ҙзј“еӯҳжқҘеўһеҠ иҜ»жҖ§иғҪпјҢиҝӣиҖҢжҸҗй«ҳжҖ§иғҪгҖӮиҝҷд№ҹжҳҜйҖҡз”Ёзҡ„ж–№жЎҲгҖӮ第дәҢпјҢжү©еұ•жҖ§е·®пјҢиҝҷзӮ№еҸҜд»ҘйҖҡиҝҮеҲҶеә“еҲҶиЎЁжқҘжү©еұ•гҖӮ
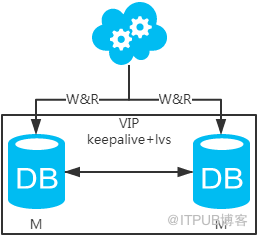
jdbc:mysql://vip:3306/xxdb
й«ҳеҸҜз”ЁеҲҶжһҗпјҡй«ҳеҸҜз”ЁпјҢдёҖдёӘдё»еә“жҢӮдәҶпјҢдёҚеҪұе“ҚеҸҰдёҖеҸ°дё»еә“жҸҗдҫӣжңҚеҠЎгҖӮиҝҷдёӘиҝҮзЁӢеҜ№дёҡеҠЎеұӮжҳҜйҖҸжҳҺзҡ„пјҢж— йңҖдҝ®ж”№д»Јз ҒжҲ–й…ҚзҪ®гҖӮ
й«ҳжҖ§иғҪеҲҶжһҗпјҡиҜ»еҶҷжҖ§иғҪзӣёжҜ”дәҺж–№жЎҲдёҖйғҪеҫ—еҲ°жҸҗеҚҮпјҢжҸҗеҚҮдёҖеҖҚгҖӮ
дёҖиҮҙжҖ§еҲҶжһҗпјҡеӯҳеңЁж•°жҚ®дёҖиҮҙжҖ§й—®йўҳгҖӮиҜ·зңӢпјҢдёҖиҮҙжҖ§и§ЈеҶіж–№жЎҲгҖӮ
жү©еұ•жҖ§еҲҶжһҗпјҡеҪ“然еҸҜд»Ҙжү©еұ•жҲҗдёүдё»еҫӘзҺҜпјҢдҪҶ笔иҖ…дёҚе»әи®®пјҲдјҡеӨҡдёҖеұӮж•°жҚ®еҗҢжӯҘпјҢиҝҷж ·еҗҢжӯҘзҡ„ж—¶й—ҙдјҡжӣҙй•ҝпјүгҖӮеҰӮжһңйқһеҫ—еңЁж•°жҚ®еә“жһ¶жһ„еұӮйқўжү©еұ•зҡ„иҜқпјҢжү©еұ•дёәж–№жЎҲеӣӣгҖӮ
еҸҜиҗҪең°еҲҶжһҗпјҡдёӨзӮ№еҪұе“ҚиҗҪең°дҪҝз”ЁгҖӮ第дёҖпјҢж•°жҚ®дёҖиҮҙжҖ§й—®йўҳпјҢдёҖиҮҙжҖ§и§ЈеҶіж–№жЎҲеҸҜи§ЈеҶій—®йўҳгҖӮ第дәҢпјҢдё»й”®еҶІзӘҒй—®йўҳпјҢIDз»ҹдёҖең°з”ұеҲҶеёғејҸIDз”ҹжҲҗжңҚеҠЎжқҘз”ҹжҲҗеҸҜи§ЈеҶій—®йўҳгҖӮ
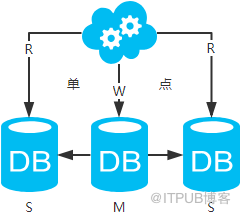
jdbc:mysql://master-ip:3306/xxdb
jdbc:mysql://slave1-ip:3306/xxdb
jdbc:mysql://slave2-ip:3306/xxdb
й«ҳеҸҜз”ЁеҲҶжһҗпјҡдё»еә“еҚ•зӮ№пјҢд»Һеә“й«ҳеҸҜз”ЁгҖӮдёҖж—Ұдё»еә“жҢӮдәҶпјҢеҶҷжңҚеҠЎд№ҹе°ұж— жі•жҸҗдҫӣгҖӮ
й«ҳжҖ§иғҪеҲҶжһҗпјҡеӨ§йғЁеҲҶдә’иҒ”зҪ‘еә”з”ЁиҜ»еӨҡеҶҷе°‘пјҢиҜ»дјҡе…ҲжҲҗдёә瓶йўҲпјҢиҝӣиҖҢеҪұе“Қж•ҙдҪ“жҖ§иғҪгҖӮиҜ»зҡ„жҖ§иғҪжҸҗй«ҳдәҶпјҢж•ҙдҪ“жҖ§иғҪд№ҹжҸҗй«ҳдәҶгҖӮеҸҰеӨ–пјҢдё»еә“еҸҜд»ҘдёҚз”Ёзҙўеј•пјҢзәҝдёҠд»Һеә“е’ҢзәҝдёӢд»Һеә“д№ҹеҸҜд»Ҙе»әз«ӢдёҚеҗҢзҡ„зҙўеј•пјҲзәҝдёҠд»Һеә“еҰӮжһңжңүеӨҡдёӘиҝҳжҳҜиҰҒе»әз«ӢзӣёеҗҢзҡ„зҙўеј•пјҢдёҚ然еҫ—дёҚеҒҝеӨұпјӣзәҝдёӢд»Һеә“жҳҜе№іж—¶ејҖеҸ‘дәәе‘ҳжҺ’жҹҘзәҝдёҠй—®йўҳж—¶жҹҘзҡ„еә“пјҢеҸҜд»Ҙе»әжӣҙеӨҡзҡ„зҙўеј•пјүгҖӮ
дёҖиҮҙжҖ§еҲҶжһҗпјҡеӯҳеңЁж•°жҚ®дёҖиҮҙжҖ§й—®йўҳгҖӮиҜ·зңӢпјҢдёҖиҮҙжҖ§и§ЈеҶіж–№жЎҲгҖӮ
жү©еұ•жҖ§еҲҶжһҗпјҡеҸҜд»ҘйҖҡиҝҮеҠ д»Һеә“жқҘжү©еұ•иҜ»жҖ§иғҪпјҢиҝӣиҖҢжҸҗй«ҳж•ҙдҪ“жҖ§иғҪгҖӮпјҲеёҰжқҘзҡ„й—®йўҳжҳҜпјҢд»Һеә“и¶ҠеӨҡйңҖиҰҒд»Һдё»еә“жӢүеҸ–binlogж—Ҙеҝ—зҡ„з«Ҝе°ұи¶ҠеӨҡпјҢиҝӣиҖҢеҪұе“Қдё»еә“зҡ„жҖ§иғҪпјҢ并且数жҚ®еҗҢжӯҘе®ҢжҲҗзҡ„ж—¶й—ҙд№ҹдјҡжӣҙй•ҝпјү
еҸҜиҗҪең°еҲҶжһҗпјҡдёӨзӮ№еҪұе“ҚиҗҪең°дҪҝз”ЁгҖӮ第дёҖпјҢж•°жҚ®дёҖиҮҙжҖ§й—®йўҳпјҢдёҖиҮҙжҖ§и§ЈеҶіж–№жЎҲеҸҜи§ЈеҶій—®йўҳгҖӮ第дәҢпјҢдё»еә“еҚ•зӮ№й—®йўҳпјҢ笔иҖ…жҡӮж—¶жІЎжғіеҲ°еҫҲеҘҪзҡ„и§ЈеҶіж–№жЎҲгҖӮ
жіЁпјҡжҖқиҖғдёҖдёӘй—®йўҳпјҢдёҖеҸ°д»Һеә“жҢӮдәҶдјҡжҖҺж ·пјҹиҜ»еҶҷеҲҶзҰ»д№ӢиҜ»зҡ„иҙҹиҪҪеқҮиЎЎзӯ–з•ҘжҖҺд№Ҳе®№й”ҷпјҹ
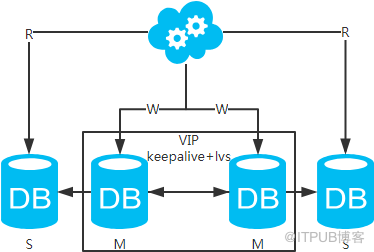
jdbc:mysql://vip:3306/xxdb
jdbc:mysql://slave1-ip:3306/xxdb
jdbc:mysql://slave2-ip:3306/xxdb
й«ҳеҸҜз”ЁеҲҶжһҗпјҡй«ҳеҸҜз”ЁгҖӮ
й«ҳжҖ§иғҪеҲҶжһҗпјҡй«ҳжҖ§иғҪгҖӮ
дёҖиҮҙжҖ§еҲҶжһҗпјҡеӯҳеңЁж•°жҚ®дёҖиҮҙжҖ§й—®йўҳгҖӮиҜ·зңӢпјҢдёҖиҮҙжҖ§и§ЈеҶіж–№жЎҲгҖӮ
жү©еұ•жҖ§еҲҶжһҗпјҡеҸҜд»ҘйҖҡиҝҮеҠ д»Һеә“жқҘжү©еұ•иҜ»жҖ§иғҪпјҢиҝӣиҖҢжҸҗй«ҳж•ҙдҪ“жҖ§иғҪгҖӮпјҲеёҰжқҘзҡ„й—®йўҳеҗҢж–№жЎҲдәҢпјү
еҸҜиҗҪең°еҲҶжһҗпјҡеҗҢж–№жЎҲдәҢпјҢдҪҶж•°жҚ®еҗҢжӯҘеҸҲеӨҡдәҶдёҖеұӮпјҢж•°жҚ®е»¶иҝҹжӣҙдёҘйҮҚгҖӮ
既然зҹҘйҒ“дәҶж•°жҚ®дёҚдёҖиҮҙжҖ§дә§з”ҹзҡ„еҺҹеӣ пјҢжңүдёӢйқўеҮ дёӘи§ЈеҶіж–№жЎҲдҫӣеҸӮиҖғпјҡ
1гҖҒзӣҙжҺҘеҝҪз•ҘпјҢеҰӮжһңдёҡеҠЎе…Ғ许延时еӯҳеңЁпјҢйӮЈд№Ҳе°ұдёҚеҺ»з®Ўе®ғгҖӮ
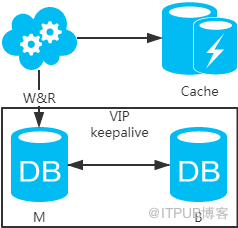
2гҖҒејәеҲ¶иҜ»дё»пјҢйҮҮз”Ёдё»еӨҮжһ¶жһ„ж–№жЎҲпјҢиҜ»еҶҷйғҪиө°дё»еә“гҖӮз”Ёзј“еӯҳжқҘжү©еұ•ж•°жҚ®еә“иҜ»жҖ§иғҪ гҖӮжңүдёҖзӮ№йңҖиҰҒзҹҘйҒ“пјҡеҰӮжһңзј“еӯҳжҢӮдәҶпјҢеҸҜиғҪдјҡдә§з”ҹйӣӘеҙ©зҺ°иұЎпјҢдёҚиҝҮдёҖиҲ¬еҲҶеёғејҸзј“еӯҳйғҪжҳҜй«ҳеҸҜз”Ёзҡ„гҖӮ
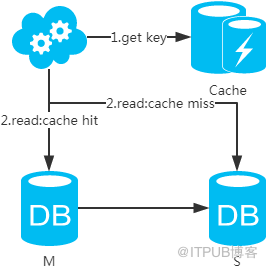
3гҖҒйҖүжӢ©иҜ»дё»пјҢеҶҷж“ҚдҪңж—¶ж №жҚ®еә“+иЎЁ+дёҡеҠЎзү№еҫҒз”ҹжҲҗдёҖдёӘkeyж”ҫеҲ°CacheйҮҢ并и®ҫзҪ®и¶…ж—¶ж—¶й—ҙпјҲеӨ§дәҺзӯүдәҺдё»д»Һж•°жҚ®еҗҢжӯҘж—¶й—ҙпјүгҖӮиҜ»иҜ·жұӮж—¶пјҢеҗҢж ·зҡ„ж–№ејҸз”ҹжҲҗkeyе…ҲеҺ»жҹҘCacheпјҢеҶҚеҲӨж–ӯжҳҜеҗҰе‘ҪдёӯгҖӮиӢҘе‘ҪдёӯпјҢеҲҷиҜ»дё»еә“пјҢеҗҰеҲҷиҜ»д»Һеә“гҖӮд»Јд»·жҳҜеӨҡдәҶдёҖж¬Ўзј“еӯҳиҜ»еҶҷпјҢеҹәжң¬еҸҜд»ҘеҝҪз•ҘгҖӮ
4гҖҒеҚҠеҗҢжӯҘеӨҚеҲ¶пјҢзӯүдё»д»ҺеҗҢжӯҘе®ҢжҲҗпјҢеҶҷиҜ·жұӮжүҚиҝ”еӣһгҖӮе°ұжҳҜеӨ§е®¶еёёиҜҙзҡ„вҖңеҚҠеҗҢжӯҘеӨҚеҲ¶вҖқsemi-syncгҖӮиҝҷеҸҜд»ҘеҲ©з”Ёж•°жҚ®еә“еҺҹз”ҹеҠҹиғҪпјҢе®һзҺ°жҜ”иҫғз®ҖеҚ•гҖӮд»Јд»·жҳҜеҶҷиҜ·жұӮ时延еўһй•ҝпјҢеҗһеҗҗйҮҸйҷҚдҪҺгҖӮ
5гҖҒж•°жҚ®еә“дёӯй—ҙ件пјҢеј•е…ҘејҖжәҗпјҲmycatзӯүпјүжҲ–иҮӘз ”зҡ„ж•°жҚ®еә“дёӯй—ҙеұӮгҖӮдёӘдәәзҗҶи§ЈпјҢжҖқи·ҜеҗҢйҖүжӢ©иҜ»дё»гҖӮж•°жҚ®еә“дёӯй—ҙ件зҡ„жҲҗжң¬жҜ”иҫғй«ҳпјҢ并且иҝҳеӨҡеј•е…ҘдәҶдёҖеұӮгҖӮ
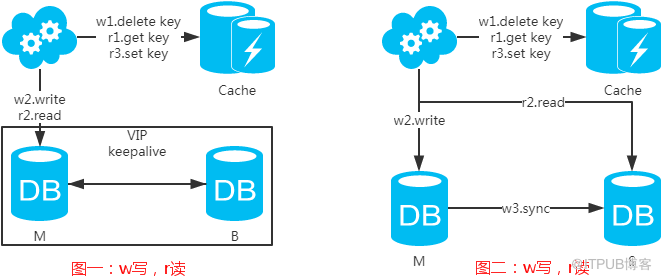
е…ҲжқҘзңӢдёҖдёӢеёёз”Ёзҡ„зј“еӯҳдҪҝз”Ёж–№ејҸпјҡ
第дёҖжӯҘпјҡж·ҳжұ°зј“еӯҳпјӣ
第дәҢжӯҘпјҡеҶҷе…Ҙж•°жҚ®еә“пјӣ
第дёүжӯҘпјҡиҜ»еҸ–зј“еӯҳпјҹиҝ”еӣһпјҡиҜ»еҸ–ж•°жҚ®еә“пјӣ
第еӣӣжӯҘпјҡиҜ»еҸ–ж•°жҚ®еә“еҗҺеҶҷе…Ҙзј“еӯҳгҖӮ
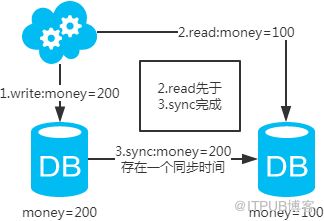
жіЁпјҡеҰӮжһңжҢүз…§иҝҷз§Қж–№ејҸпјҢеӣҫдёҖпјҢдёҚдјҡдә§з”ҹDBе’Ңзј“еӯҳдёҚдёҖиҮҙй—®йўҳпјӣеӣҫдәҢпјҢдјҡдә§з”ҹDBе’Ңзј“еӯҳдёҚдёҖиҮҙй—®йўҳпјҢеҚі4.readе…ҲдәҺ3.syncжү§иЎҢгҖӮеҰӮжһңдёҚеҒҡеӨ„зҗҶпјҢзј“еӯҳйҮҢзҡ„ж•°жҚ®еҸҜиғҪдёҖзӣҙжҳҜи„Ҹж•°жҚ®гҖӮи§ЈеҶіж–№ејҸеҰӮдёӢпјҡ
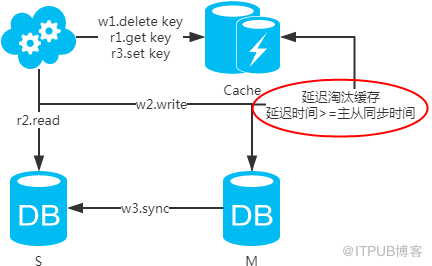
жіЁпјҡи®ҫзҪ®зј“еӯҳж—¶пјҢдёҖе®ҡиҰҒеҠ дёҠеӨұж•Ҳж—¶й—ҙпјҢд»ҘйҳІе»¶ж—¶ж·ҳжұ°зј“еӯҳеӨұиҙҘзҡ„жғ…еҶөпјҒ
1гҖҒжһ¶жһ„жј”еҸҳдёҖпјҡж–№жЎҲдёҖ -> ж–№жЎҲдёҖ+еҲҶеә“еҲҶиЎЁ -> ж–№жЎҲдәҢ+еҲҶеә“еҲҶиЎЁ -> ж–№жЎҲеӣӣ+еҲҶеә“еҲҶиЎЁпјӣ
2гҖҒжһ¶жһ„жј”еҸҳдәҢпјҡж–№жЎҲдёҖ -> ж–№жЎҲдёҖ+еҲҶеә“еҲҶиЎЁ -> ж–№жЎҲдёү+еҲҶеә“еҲҶиЎЁ -> ж–№жЎҲеӣӣ+еҲҶеә“еҲҶиЎЁпјӣ
3гҖҒжһ¶жһ„жј”еҸҳдёүпјҡж–№жЎҲдёҖ -> ж–№жЎҲдәҢ -> ж–№жЎҲеӣӣ -> ж–№жЎҲеӣӣ+еҲҶеә“еҲҶиЎЁпјӣ
4гҖҒжһ¶жһ„жј”еҸҳеӣӣпјҡж–№жЎҲдёҖ -> ж–№жЎҲдёү -> ж–№жЎҲеӣӣ -> ж–№жЎҲеӣӣ+еҲҶеә“еҲҶиЎЁпјӣ
1гҖҒеҠ зј“еӯҳе’Ңзҙўеј•жҳҜйҖҡз”Ёзҡ„жҸҗеҚҮж•°жҚ®еә“жҖ§иғҪзҡ„ж–№ејҸпјӣ
2гҖҒеҲҶеә“еҲҶиЎЁеёҰжқҘзҡ„еҘҪеӨ„жҳҜе·ЁеӨ§зҡ„пјҢдҪҶеҗҢж ·д№ҹдјҡеёҰжқҘдёҖдәӣй—®йўҳпјҢ
3гҖҒдёҚз®ЎжҳҜдё»еӨҮ+еҲҶеә“еҲҶиЎЁиҝҳжҳҜдё»д»Һ+иҜ»еҶҷеҲҶзҰ»+еҲҶеә“еҲҶиЎЁпјҢйғҪиҰҒиҖғиҷ‘е…·дҪ“зҡ„дёҡеҠЎеңәжҷҜгҖӮжҹҗ8еҲ°е®¶еҸ‘еұ•еӣӣе№ҙпјҢз»қеӨ§йғЁеҲҶзҡ„ж•°жҚ®еә“жһ¶жһ„иҝҳжҳҜйҮҮз”Ёж–№жЎҲдёҖе’Ңж–№жЎҲдёҖ+еҲҶеә“еҲҶиЎЁпјҢеҸӘжңүжһҒе°‘йғЁеҲҶз”Ёж–№жЎҲдёү+иҜ»еҶҷеҲҶзҰ»+еҲҶеә“еҲҶиЎЁгҖӮеҸҰеӨ–пјҢйҳҝйҮҢдә‘жҸҗдҫӣзҡ„ж•°жҚ®еә“дә‘жңҚеҠЎд№ҹйғҪжҳҜдё»еӨҮж–№жЎҲпјҢиҰҒжғідё»д»Һ+иҜ»еҶҷеҲҶзҰ»йңҖиҰҒдәҢж¬Ўжһ¶жһ„гҖӮ
4гҖҒи®°дҪҸдёҖеҸҘиҜқпјҡдёҚиҖғиҷ‘дёҡеҠЎеңәжҷҜзҡ„жһ¶жһ„йғҪжҳҜиҖҚжөҒж°“гҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎMySQLж•°жҚ®еә“дёӯжҖҺд№ҲиҝӣиЎҢдә’иҒ”зҪ‘еёёз”Ёжһ¶жһ„зҡ„жҗӯе»әзҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ