жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢMySQLдёӯдёәд»Җд№ҲиҰҒдҪҝз”Ёзҙўеј•пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
MySQL е®ҳж–№еҜ№зҙўеј•зҡ„е®ҡд№үдёәпјҡзҙўеј•жҳҜеё®еҠ© MySQL й«ҳж•ҲиҺ·еҸ–ж•°жҚ®зҡ„ж•°жҚ®з»“жһ„гҖӮ
еңЁж•°жҚ®д№ӢеӨ–пјҢж•°жҚ®еә“зі»з»ҹиҝҳз»ҙжҠӨзқҖж»Ўи¶ізү№е®ҡжҹҘжүҫз®—жі•зҡ„ж•°жҚ®з»“жһ„пјҢиҝҷдәӣж•°жҚ®з»“жһ„д»Ҙжҹҗз§Қж–№ејҸеј•з”ЁпјҲжҢҮеҗ‘пјүж•°жҚ®пјҢиҝҷж ·е°ұеҸҜд»ҘеңЁиҝҷдәӣж•°жҚ®з»“жһ„дёҠе®һзҺ°й«ҳзә§жҹҘжүҫз®—жі•гҖӮиҝҷз§Қж•°жҚ®з»“жһ„пјҢе°ұжҳҜзҙўеј•гҖӮ
зҙўеј•зҡ„еҮәзҺ°е°ұжҳҜдёәдәҶжҸҗй«ҳжҹҘиҜўж•ҲзҺҮпјҢе°ұеғҸд№Ұзҡ„зӣ®еҪ•гҖӮе…¶е®һиҜҙзҷҪдәҶпјҢзҙўеј•иҰҒи§ЈеҶізҡ„е°ұжҳҜжҹҘиҜўй—®йўҳгҖӮ
жҹҘиҜўпјҢжҳҜж•°жҚ®еә“жүҖжҸҗдҫӣзҡ„дёҖдёӘйҮҚиҰҒеҠҹиғҪпјҢжҲ‘们йғҪжғіе°ҪеҸҜиғҪеҝ«зҡ„иҺ·еҸ–еҲ°зӣ®ж Үж•°жҚ®пјҢеӣ жӯӨе°ұйңҖиҰҒдјҳеҢ–ж•°жҚ®еә“зҡ„жҹҘиҜўз®—жі•пјҢйҖүжӢ©еҗҲйҖӮзҡ„жҹҘиҜўжЁЎеһӢжқҘе®һзҺ°зҙўеј•гҖӮ
еҸҰеӨ–пјҢдёәиЎЁи®ҫзҪ®зҙўеј•иҰҒд»ҳеҮәд»Јд»·зҡ„пјҡдёҖжҳҜеўһеҠ дәҶж•°жҚ®еә“зҡ„еӯҳеӮЁз©әй—ҙпјҢдәҢжҳҜеңЁжҸ’е…Ҙе’Ңдҝ®ж”№ж•°жҚ®ж—¶иҰҒиҠұиҙ№иҫғеӨҡзҡ„ж—¶й—ҙпјҢеӣ дёәзҙўеј•д№ҹиҰҒйҡҸд№ӢеҸҳеҠЁгҖӮ
зҙўеј•зҡ„е®һзҺ°жЁЎеһӢжңүеҫҲеӨҡпјҢиҝҷйҮҢжҲ‘们е…ҲдәҶи§ЈдёҖдёӢеёёз”Ёзҡ„жҹҘиҜўжЁЎеһӢгҖӮ
йЎәеәҸж•°з»„жҳҜдёҖз§Қзү№ж®Ҡзҡ„ж•°з»„пјҢйҮҢйқўзҡ„е…ғзҙ пјҢжҢүдёҖе®ҡзҡ„йЎәеәҸжҺ’еҲ—гҖӮ
йЎәеәҸж•°з»„еңЁжҹҘиҜўдёҠжңүзқҖдёҖе®ҡзҡ„дјҳеҠҝпјҢеӣ дёәжҳҜжңүеәҸзҡ„ж•°жҚ®пјҢйҮҮз”ЁдәҢеҲҶжҹҘжүҫзҡ„иҜқпјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜ O(log(N))гҖӮ
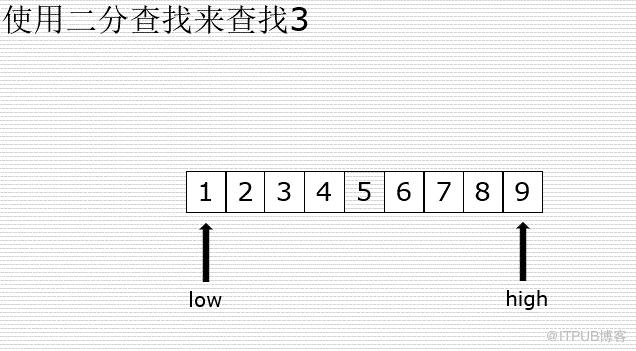
йЎәеәҸж•°з»„зҡ„дјҳзӮ№е°ұжҳҜжҹҘиҜўж•ҲзҺҮйқһеёёй«ҳпјҢдҪҶжҳҜиҰҒжӣҙж–°ж•°жҚ®зҡ„иҜқпјҢе°ұйқһеёёйә»зғҰдәҶгҖӮеҲ йҷӨе’ҢжҸ’е…Ҙе…ғзҙ йғҪиҰҒж¶үеҸҠеҲ°еӨ§йҮҸе…ғзҙ дҪҚзҪ®зҡ„移еҠЁпјҢжҲҗжң¬еҫҲй«ҳгҖӮ
еӣ жӯӨпјҢеҜ№дәҺйЎәеәҸж•°з»„жӣҙйҖӮеҗҲз”ЁдәҺжҹҘиҜўзҡ„йўҶеҹҹпјҢйҖӮеҗҲеӯҳеӮЁдёҖдәӣж”№еҠЁиҫғе°Ҹзҡ„йқҷжҖҒеӯҳеӮЁеј•ж“ҺгҖӮ
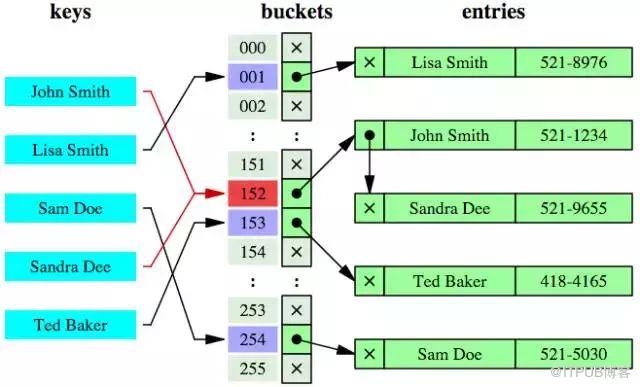
е“ҲеёҢиЎЁжҳҜдёҖз§Қд»Ҙ й”®-еҖјпјҲkey-valueпјү еӯҳеӮЁж•°жҚ®зҡ„з»“жһ„пјҢжҲ‘们еҸӘиҰҒиҫ“е…Ҙеҫ…жҹҘжүҫзҡ„еҖјеҚі keyпјҢе°ұеҸҜд»ҘжүҫеҲ°е…¶еҜ№еә”зҡ„еҖјеҚі valueгҖӮ
е“ҲеёҢзҙўеј•йҮҮз”ЁдёҖе®ҡзҡ„е“ҲеёҢз®—жі•пјҢеҜ№дәҺжҜҸдёҖиЎҢпјҢеӯҳеӮЁеј•ж“Һи®Ўз®—еҮәдәҶиў«зҙўеј•еӯ—ж®өзҡ„е“ҲеёҢз ҒпјҲHash CodeпјүпјҢжҠҠе“ҲеёҢз ҒдҝқеӯҳеңЁзҙўеј•дёӯпјҢ并且дҝқеӯҳдәҶдёҖдёӘжҢҮеҗ‘е“ҲеёҢиЎЁдёӯзҡ„жҜҸдёҖиЎҢзҡ„жҢҮй’ҲгҖӮ
иҝҷж ·еңЁжЈҖзҙўж—¶еҸӘйңҖдёҖж¬Ўе“ҲеёҢз®—жі•еҚіеҸҜз«ӢеҲ»е®ҡдҪҚеҲ°зӣёеә”зҡ„дҪҚзҪ®пјҢйҖҹеәҰйқһеёёеҝ«гҖӮ
Hash зҙўеј•з»“жһ„зҡ„зү№ж®ҠжҖ§пјҢе…¶жЈҖзҙўж•ҲзҺҮйқһеёёд№Ӣй«ҳпјҢеә”иҜҘжҳҜ O(1) зҡ„ж—¶й—ҙеӨҚжқӮеәҰгҖӮ
иҷҪ然 Hash зҙўеј•ж•ҲзҺҮй«ҳпјҢдҪҶжҳҜ Hash зҙўеј•жң¬иә«з”ұдәҺе…¶зү№ж®ҠжҖ§д№ҹеёҰжқҘдәҶеҫҲеӨҡйҷҗеҲ¶е’ҢејҠз«ҜпјҢдё»иҰҒжңүд»ҘдёӢиҝҷдәӣпјҡ
1гҖҒHashзҙўеј•д»…д»…иғҪж»Ўи¶і =пјҢIN е’Ң <=> жҹҘиҜўпјҢеҰӮжһңжҳҜиҢғеӣҙжҹҘиҜўжЈҖзҙўпјҢиҝҷж—¶еҖҷе“ҲеёҢзҙўеј•е°ұжҜ«ж— з”ЁжӯҰд№Ӣең°дәҶгҖӮ
еӣ дёәеҺҹе…ҲжҳҜжңүеәҸзҡ„й”®еҖјпјҢз»ҸиҝҮе“ҲеёҢз®—жі•еҗҺпјҢжңүеҸҜиғҪеҸҳжҲҗдёҚиҝһз»ӯзҡ„дәҶпјҢе°ұжІЎеҠһжі•еҶҚеҲ©з”Ёзҙўеј•е®ҢжҲҗиҢғеӣҙжҹҘиҜўжЈҖзҙўпјӣ
2гҖҒHash зҙўеј•ж— жі•еҲ©з”Ёзҙўеј•е®ҢжҲҗжҺ’еәҸпјҢеӣ дёәеӯҳж”ҫзҡ„ж—¶еҖҷжҳҜз»ҸиҝҮ Hash и®Ўз®—иҝҮзҡ„пјҢи®Ўз®—зҡ„ Hash еҖје’ҢеҺҹе§Ӣж•°жҚ®дёҚдёҖе®ҡзӣёзӯүпјҢжүҖд»Ҙж— жі•жҺ’еәҸпјӣ
3гҖҒиҒ”еҗҲзҙўеј•дёӯпјҢHash зҙўеј•дёҚиғҪеҲ©з”ЁйғЁеҲҶзҙўеј•й”®жҹҘиҜўгҖӮ
Hash зҙўеј•еңЁи®Ўз®— Hash еҖјзҡ„ж—¶еҖҷжҳҜиҒ”еҗҲзҙўеј•й”®еҗҲ并еҗҺеҶҚдёҖиө·и®Ўз®— Hash еҖјпјҢиҖҢдёҚжҳҜеҚ•зӢ¬и®Ўз®— Hash еҖјгҖӮ
жүҖд»ҘеҜ№дәҺиҒ”еҗҲзҙўеј•дёӯзҡ„еӨҡдёӘеҲ—пјҢHash жҳҜиҰҒд№Ҳе…ЁйғЁдҪҝз”ЁпјҢиҰҒд№Ҳе…ЁйғЁдёҚдҪҝз”ЁгҖӮйҖҡиҝҮеүҚйқўдёҖдёӘжҲ–еҮ дёӘзҙўеј•й”®иҝӣиЎҢжҹҘиҜўзҡ„ж—¶еҖҷпјҢHash зҙўеј•д№ҹж— жі•иў«еҲ©з”ЁгҖӮ
4гҖҒHashзҙўеј•еңЁд»»дҪ•ж—¶еҖҷйғҪдёҚиғҪйҒҝе…ҚиЎЁжү«жҸҸгҖӮ
еүҚйқўе·Із»ҸзҹҘйҒ“пјҢHash зҙўеј•жҳҜе°Ҷзҙўеј•й”®йҖҡиҝҮ Hash иҝҗз®—д№ӢеҗҺпјҢе°Ҷ Hash иҝҗз®—з»“жһңзҡ„ Hash еҖје’ҢжүҖеҜ№еә”зҡ„иЎҢжҢҮй’ҲдҝЎжҒҜеӯҳж”ҫдәҺдёҖдёӘ Hash иЎЁдёӯпјҢз”ұдәҺдёҚеҗҢзҙўеј•й”®еҸҜиғҪеӯҳеңЁзӣёеҗҢ Hash еҖјпјҢжүҖд»ҘеҚідҪҝеҸ–ж»Ўи¶іжҹҗдёӘ Hash й”®еҖјзҡ„ж•°жҚ®зҡ„и®°еҪ•жқЎж•°пјҢд№ҹж— жі•д»Һ Hash зҙўеј•дёӯзӣҙжҺҘе®ҢжҲҗжҹҘиҜўпјҢиҝҳжҳҜиҰҒйҖҡиҝҮи®ҝй—®иЎЁдёӯзҡ„е®һйҷ…ж•°жҚ®иҝӣиЎҢзӣёеә”зҡ„жҜ”иҫғпјҢ并еҫ—еҲ°зӣёеә”зҡ„з»“жһңгҖӮ
5гҖҒеңЁжңүеӨ§йҮҸйҮҚеӨҚй”®еҖјжғ…еҶөдёӢпјҢе“ҲеёҢзҙўеј•зҡ„ж•ҲзҺҮд№ҹжҳҜжһҒдҪҺзҡ„пјҢеӣ дёәеӯҳеңЁжүҖи°“зҡ„е“ҲеёҢзў°ж’һй—®йўҳгҖӮ
з»јдёҠпјҢе“ҲеёҢиЎЁиҝҷз§Қз»“жһ„йҖӮз”ЁдәҺеҸӘжңүзӯүеҖјжҹҘиҜўзҡ„еңәжҷҜпјҢжҜ”еҰӮ MemcachedгҖҒredis еҸҠе…¶д»–дёҖдәӣ NoSQL еј•ж“ҺгҖӮ
дәҢеҸүжҗңзҙўж ‘зҡ„жҜҸдёӘиҠӮзӮ№йғҪеҸӘеӯҳеӮЁдёҖдёӘй”®еҖјпјҢ并且е·Ұеӯҗж ‘пјҲеҰӮжһңжңүпјүжүҖжңүиҠӮзӮ№зҡ„еҖјйғҪиҰҒе°ҸдәҺж №иҠӮзӮ№зҡ„еҖјпјҢеҸіеӯҗж ‘пјҲеҰӮжһңжңүпјүжүҖжңүиҠӮзӮ№зҡ„еҖјйғҪиҰҒеӨ§дәҺж №иҠӮзӮ№зҡ„еҖјгҖӮ
еҪ“дәҢеҸүжҗңзҙўж ‘зҡ„жүҖжңүйқһеҸ¶еӯҗиҠӮзӮ№зҡ„е·ҰеҸіеӯҗж ‘зҡ„иҠӮзӮ№ж•°зӣ®еқҮдҝқжҢҒе·®дёҚеӨҡж—¶пјҲе№іиЎЎпјүпјҢиҝҷж—¶ж ‘зҡ„жҗңзҙўжҖ§иғҪйҖјиҝ‘дәҢеҲҶжҹҘжүҫпјӣ并且е®ғжҜ”иҝһз»ӯеҶ…еӯҳз©әй—ҙзҡ„дәҢеҲҶжҹҘжүҫжӣҙжңүдјҳеҠҝзҡ„жҳҜпјҢж”№еҸҳж ‘з»“жһ„пјҲжҸ’е…ҘдёҺеҲ йҷӨз»“зӮ№пјүдёҚйңҖиҰҒ移еҠЁеӨ§ж®өзҡ„еҶ…еӯҳж•°жҚ®пјҢз”ҡиҮійҖҡеёёжҳҜеёёж•°ејҖй”ҖгҖӮ
зү№ж®Ҡжғ…еҶөдёӢпјҢж №иҠӮзӮ№зҡ„е·ҰеҸіеӯҗж ‘зҡ„й«ҳеәҰзӣёе·®дёҚи¶…иҝҮ 1 ж—¶пјҢиҝҷж ·зҡ„дәҢеҸүж ‘иў«з§°дёәе№іиЎЎдәҢеҸүж ‘пјӣдёҺд№ӢзӣёеҜ№зҡ„жҳҜпјҢдәҢеҸүжҗңзҙўж ‘жңүеҸҜиғҪйҖҖеҢ–жҲҗзәҝжҖ§ж ‘гҖӮ
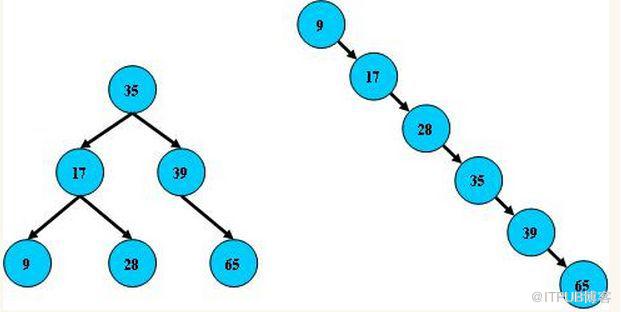
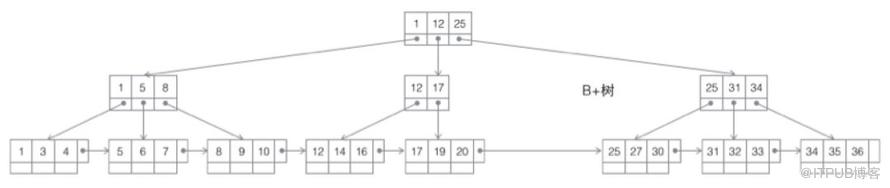
дёӢеӣҫеұ•зӨәдәҶдёҖз§ҚеҸҜиғҪзҡ„зҙўеј•ж–№ејҸгҖӮе·Ұиҫ№жҳҜж•°жҚ®иЎЁпјҢдёҖе…ұжңүдёӨеҲ—дёғжқЎи®°еҪ•пјҢжңҖе·Ұиҫ№зҡ„жҳҜж•°жҚ®и®°еҪ•зҡ„зү©зҗҶең°еқҖпјҲжіЁж„ҸйҖ»иҫ‘дёҠзӣёйӮ»зҡ„и®°еҪ•еңЁзЈҒзӣҳдёҠд№ҹ并дёҚжҳҜдёҖе®ҡзү©зҗҶзӣёйӮ»зҡ„пјүгҖӮ
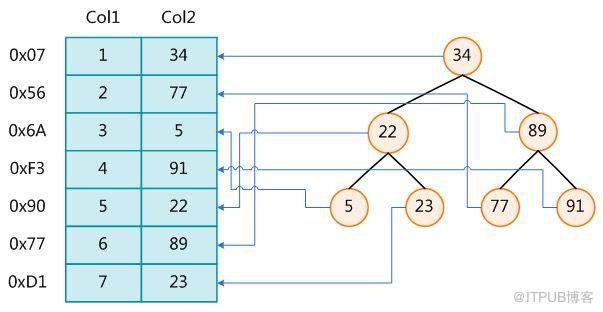
дёәдәҶеҠ еҝ« Col2 зҡ„жҹҘжүҫпјҢеҸҜд»Ҙз»ҙжҠӨдёҖдёӘеҸіиҫ№жүҖзӨәзҡ„дәҢеҸүжҹҘжүҫж ‘пјҢжҜҸдёӘиҠӮзӮ№еҲҶеҲ«еҢ…еҗ«зҙўеј•й”®еҖје’ҢдёҖдёӘжҢҮеҗ‘еҜ№еә”ж•°жҚ®и®°еҪ•зү©зҗҶең°еқҖзҡ„жҢҮй’ҲпјҢиҝҷж ·е°ұеҸҜд»Ҙиҝҗз”ЁдәҢеҸүжҹҘжүҫеңЁ O(log2n) зҡ„еӨҚжқӮеәҰеҶ…иҺ·еҸ–еҲ°зӣёеә”ж•°жҚ®гҖӮ
зңӢеҫ—еҮәжқҘпјҢдәҢеҸүж ‘еңЁжҹҘиҜўе’Ңдҝ®ж”№дёҠеҒҡеҲ°дәҶдёҖдёӘе№іиЎЎпјҢйғҪжңүзқҖдёҚй”ҷзҡ„ж•ҲзҺҮпјҢдҪҶжҳҜзҺ°е®һжҳҜеҫҲе°‘жңүж•°жҚ®еә“еј•ж“ҺдҪҝз”ЁдәҢеҸүж ‘жқҘе®һзҺ°зҙўеј•пјҢдёәд»Җд№Ҳе‘ўпјҹ
ж•°жҚ®еә“еӯҳеӮЁеӨ§еӨҡдёҚйҖӮз”ЁдәҢеҸүж ‘пјҢж•°жҚ®йҮҸиҫғеӨ§ж—¶пјҢж ‘й«ҳдјҡиҝҮй«ҳгҖӮ
дҪ еҸҜд»ҘжғіиұЎдёҖдёӢдёҖжЈө 100 дёҮиҠӮзӮ№зҡ„е№іиЎЎдәҢеҸүж ‘пјҢж ‘й«ҳ 20пјҢжҜҸдёӘеҸ¶еӯҗз»“зӮ№е°ұжҳҜдёҖдёӘеқ—пјҢжҜҸдёӘеқ—еҢ…еҗ«дёӨдёӘж•°жҚ®пјҢеқ—д№Ӣй—ҙйҖҡиҝҮй“ҫејҸж–№ејҸй“ҫжҺҘгҖӮ
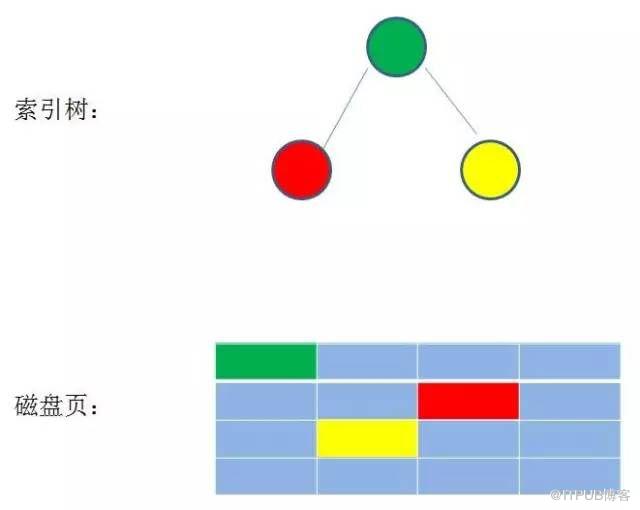
ж ‘й«ҳ 20 зҡ„иҜқпјҢе°ұиҰҒйҒҚеҺҶ 20 дёӘеқ—жүҚиғҪеҫ—еҲ°зӣ®ж Үж•°жҚ®пјҢзҙўеј•еӯҳеӮЁеңЁзЈҒзӣҳж—¶пјҢиҝҷе°ҶжҳҜйқһеёёиҖ—ж—¶зҡ„гҖӮ
еӣ жӯӨпјҢдёәдәҶеҮҸе°‘зЈҒзӣҳзҡ„иҜ»еҸ–пјҢжҹҘиҜўж—¶е°ұиҰҒе°ҪйҮҸе°‘зҡ„йҒҚеҺҶж•°жҚ®еқ—пјҢеӣ жӯӨдёҖиҲ¬дҪҝз”Ё N еҸүж ‘гҖӮ
иҝҷйҮҢе°ұжңүдәҶ Bж ‘пјҲBalanced TreeпјүгҖӮ

究з«ҹд»Җд№ҲжҳҜ B ж ‘пјҹ
жҲ‘们е…ҲзңӢдёҖдёӘдҫӢеӯҗпјҡ
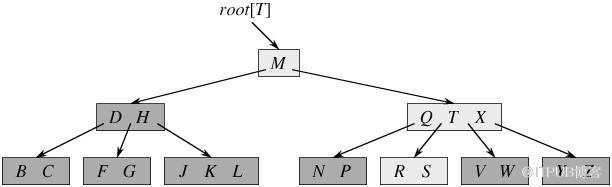
д»ҺдёҠеӣҫдҪ иғҪиҪ»жҳ“зҡ„зңӢеҲ°пјҢдёҖдёӘеҶ…з»“зӮ№ x иӢҘеҗ«жңү n[x] дёӘе…ій”®еӯ—пјҢйӮЈд№Ҳ x е°Ҷеҗ«жңү n[x]+1 дёӘеӯҗеҘігҖӮеҰӮеҗ«жңү 2 дёӘе…ій”®еӯ— D H зҡ„еҶ…з»“зӮ№жңү 3 дёӘеӯҗеҘіпјҢиҖҢеҗ«жңү 3 дёӘе…ій”®еӯ— Q T X зҡ„еҶ…з»“зӮ№жңү 4 дёӘеӯҗеҘігҖӮ
B ж ‘зҡ„зү№жҖ§
жҷ®еҸҠдёҖдәӣжҰӮеҝөпјҡ
иҠӮзӮ№зҡ„еәҰпјҡдёҖдёӘиҠӮзӮ№еҗ«жңүзҡ„еӯҗж ‘зҡ„дёӘж•°з§°дёәиҜҘиҠӮзӮ№зҡ„еәҰпјӣ
ж ‘зҡ„еәҰпјҡдёҖжЈөж ‘дёӯпјҢжңҖеӨ§зҡ„иҠӮзӮ№зҡ„еәҰз§°дёәж ‘зҡ„еәҰпјӣ
еҸ¶иҠӮзӮ№жҲ–з»Ҳз«ҜиҠӮзӮ№пјҡеәҰдёәйӣ¶зҡ„иҠӮзӮ№пјӣ
йқһз»Ҳз«ҜиҠӮзӮ№жҲ–еҲҶж”ҜиҠӮзӮ№пјҡеәҰдёҚдёәйӣ¶зҡ„иҠӮзӮ№пјӣ
йҰ–е…Ҳе®ҡд№үдёӨдёӘеҸҳйҮҸпјҡd дёәеӨ§дәҺ 1 зҡ„дёҖдёӘжӯЈж•ҙж•°пјҢз§°дёә B ж ‘зҡ„еәҰгҖӮh дёәдёҖдёӘжӯЈж•ҙж•°пјҢз§°дёә B ж ‘зҡ„й«ҳеәҰгҖӮ
B ж ‘жҳҜж»Ўи¶ідёӢеҲ—жқЎд»¶зҡ„ж•°жҚ®з»“жһ„пјҡ
1гҖҒжҜҸдёӘйқһеҸ¶еӯҗиҠӮзӮ№з”ұ n-1 дёӘ key е’Ң n дёӘжҢҮй’Ҳз»„жҲҗпјҢе…¶дёӯ d<=n<=2dгҖӮ
2гҖҒжҜҸдёӘеҸ¶еӯҗиҠӮзӮ№жңҖе°‘еҢ…еҗ«дёҖдёӘ key е’ҢдёӨдёӘжҢҮй’ҲпјҢжңҖеӨҡеҢ…еҗ« 2d-1 дёӘ key е’Ң 2d дёӘжҢҮй’ҲпјҢеҸ¶иҠӮзӮ№зҡ„жҢҮй’ҲеқҮдёә null гҖӮ
3гҖҒйҷӨж №з»“зӮ№е’ҢеҸ¶еӯҗз»“зӮ№еӨ–пјҢе…¶е®ғжҜҸдёӘз»“зӮ№иҮіе°‘жңү [ceil(m / 2)] дёӘеӯ©еӯҗпјҲе…¶дёӯ ceil(x) жҳҜдёҖдёӘеҸ–дёҠйҷҗзҡ„еҮҪж•°пјүпјӣ
4гҖҒжүҖжңүеҸ¶иҠӮзӮ№е…·жңүзӣёеҗҢзҡ„ж·ұеәҰпјҢзӯүдәҺж ‘й«ҳ hпјҢдё”еҸ¶еӯҗз»“зӮ№дёҚеҢ…еҗ«д»»дҪ•е…ій”®еӯ—дҝЎжҒҜгҖӮ
5гҖҒkey е’ҢжҢҮй’Ҳдә’зӣёй—ҙйҡ”пјҢиҠӮзӮ№дёӨз«ҜжҳҜжҢҮй’ҲгҖӮ
6гҖҒдёҖдёӘиҠӮзӮ№дёӯзҡ„ key д»Һе·ҰеҲ°еҸійқһйҖ’еҮҸжҺ’еҲ—гҖӮ
7гҖҒжҜҸдёӘжҢҮй’ҲиҰҒд№Ҳдёә nullпјҢиҰҒд№ҲжҢҮеҗ‘еҸҰеӨ–дёҖдёӘиҠӮзӮ№гҖӮ
8гҖҒжҜҸдёӘйқһз»Ҳз«Ҝз»“зӮ№дёӯеҢ…еҗ«жңү n дёӘе…ій”®еӯ—дҝЎжҒҜпјҡ (nпјҢP0пјҢK1пјҢP1пјҢK2пјҢP2пјҢвҖҰвҖҰпјҢKnпјҢPn)гҖӮ
е…¶дёӯпјҡ
a) Ki (i=1вҖҰn) дёәе…ій”®еӯ—пјҢдё”е…ій”®еӯ—жҢүйЎәеәҸеҚҮеәҸжҺ’еәҸ K(i-1)< KiгҖӮ
b) Pi дёәжҢҮеҗ‘еӯҗж ‘ж №зҡ„жҺҘзӮ№пјҢдё”жҢҮй’Ҳ P(i-1) жҢҮеҗ‘еӯҗж ‘з§ҚжүҖжңүз»“зӮ№зҡ„е…ій”®еӯ—еқҮе°ҸдәҺ KiпјҢдҪҶйғҪеӨ§дәҺ K(i-1)гҖӮ
c) е…ій”®еӯ—зҡ„дёӘж•° n еҝ…йЎ»ж»Ўи¶іпјҡ [ceil(m / 2)-1]<= n <= m-1гҖӮ
B ж ‘жҹҘжүҫиҝҮзЁӢ
з”ұдәҺ B ж ‘зҡ„зү№жҖ§пјҢеңЁ B ж ‘дёӯжҢү key жЈҖзҙўж•°жҚ®зҡ„з®—жі•йқһеёёзӣҙи§ӮпјҡйҰ–е…Ҳд»Һж №иҠӮзӮ№иҝӣиЎҢдәҢеҲҶжҹҘжүҫпјҢеҰӮжһңжүҫеҲ°еҲҷиҝ”еӣһеҜ№еә”иҠӮзӮ№зҡ„ dataпјҢеҗҰеҲҷеҜ№зӣёеә”еҢәй—ҙзҡ„жҢҮй’ҲжҢҮеҗ‘зҡ„иҠӮзӮ№йҖ’еҪ’иҝӣиЎҢжҹҘжүҫпјҢзӣҙеҲ°жүҫеҲ°иҠӮзӮ№жҲ–жүҫеҲ° null жҢҮй’ҲпјҢеүҚиҖ…жҹҘжүҫжҲҗеҠҹпјҢеҗҺиҖ…жҹҘжүҫеӨұиҙҘгҖӮ

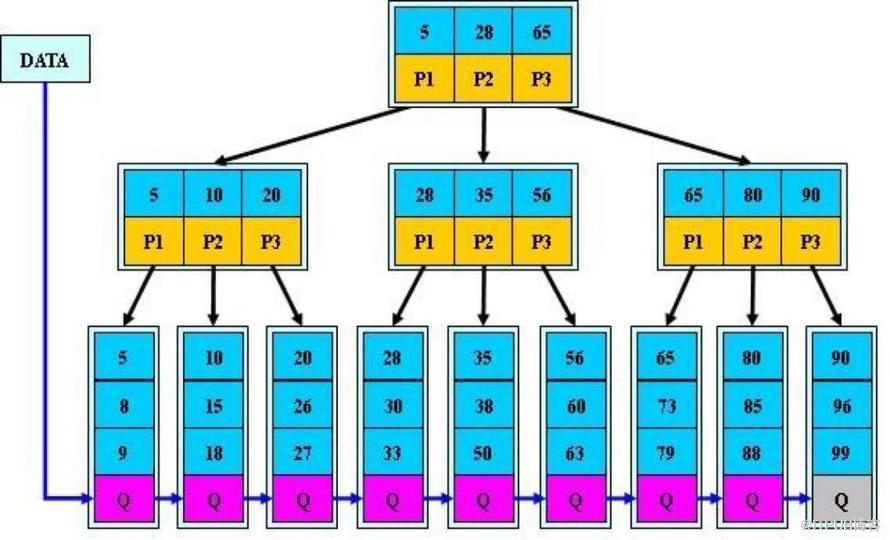
еҰӮдёҠеӣҫжүҖзӨәпјҢжҲ‘们жқҘжЁЎжӢҹдёӢжҹҘжүҫж–Ү件 29 зҡ„иҝҮзЁӢпјҡ
1гҖҒж №жҚ®ж №з»“зӮ№жҢҮй’ҲжүҫеҲ°ж–Ү件зӣ®еҪ•зҡ„ж №зЈҒзӣҳеқ— 1пјҢе°Ҷе…¶дёӯзҡ„дҝЎжҒҜеҜје…ҘеҶ…еӯҳгҖӮгҖҗзЈҒзӣҳ IO ж“ҚдҪң 1 ж¬ЎгҖ‘
2гҖҒжӯӨж—¶еҶ…еӯҳдёӯжңүдёӨдёӘж–Ү件еҗҚ 17гҖҒ35 е’ҢдёүдёӘеӯҳеӮЁе…¶д»–зЈҒзӣҳйЎөйқўең°еқҖзҡ„ж•°жҚ®гҖӮж №жҚ®з®—жі•жҲ‘们еҸ‘зҺ°пјҡ17<29<35пјҢеӣ жӯӨжҲ‘们жүҫеҲ°жҢҮй’Ҳ p2пјӣ
3гҖҒж №жҚ® p2 жҢҮй’ҲпјҢжҲ‘们е®ҡдҪҚеҲ°зЈҒзӣҳеқ— 3пјҢ并е°Ҷе…¶дёӯзҡ„дҝЎжҒҜеҜје…ҘеҶ…еӯҳгҖӮгҖҗзЈҒзӣҳ IO ж“ҚдҪң 20ж¬ЎгҖ‘
4гҖҒжӯӨж—¶еҶ…еӯҳдёӯжңүдёӨдёӘж–Ү件еҗҚ 26пјҢ30 е’ҢдёүдёӘеӯҳеӮЁе…¶д»–зЈҒзӣҳйЎөйқўең°еқҖзҡ„ж•°жҚ®гҖӮж №жҚ®з®—жі•жҲ‘们еҸ‘зҺ°пјҡ26<29<30пјҢеӣ жӯӨжҲ‘们жүҫеҲ°жҢҮй’Ҳ p2пјӣ
5гҖҒж №жҚ® p2 жҢҮй’ҲпјҢжҲ‘们е®ҡдҪҚеҲ°зЈҒзӣҳеқ— 8пјҢ并е°Ҷе…¶дёӯзҡ„дҝЎжҒҜеҜје…ҘеҶ…еӯҳгҖӮгҖҗзЈҒзӣҳ IO ж“ҚдҪң 3 ж¬ЎгҖ‘пјӣ
6гҖҒжӯӨж—¶еҶ…еӯҳдёӯжңүдёӨдёӘж–Ү件еҗҚ 28пјҢ29гҖӮж №жҚ®з®—жі•жҲ‘们жҹҘжүҫеҲ°ж–Ү件еҗҚ 29пјҢ并е®ҡдҪҚдәҶиҜҘж–Ү件еҶ…еӯҳзҡ„зЈҒзӣҳең°еқҖгҖӮ
еҲҶжһҗдёҠйқўзҡ„иҝҮзЁӢпјҢеҸ‘зҺ°йңҖиҰҒ 3 ж¬ЎзЈҒзӣҳ IO ж“ҚдҪңе’Ң 3 ж¬ЎеҶ…еӯҳжҹҘжүҫж“ҚдҪңгҖӮе…ідәҺеҶ…еӯҳдёӯзҡ„ж–Ү件еҗҚжҹҘжүҫпјҢз”ұдәҺжҳҜдёҖдёӘжңүеәҸиЎЁз»“жһ„пјҢеҸҜд»ҘеҲ©з”ЁжҠҳеҚҠжҹҘжүҫжҸҗй«ҳж•ҲзҺҮгҖӮ
B+ ж ‘пјҡжҳҜеә”ж–Ү件系з»ҹжүҖйңҖиҖҢдә§з”ҹзҡ„дёҖз§Қ B ж ‘зҡ„еҸҳеҪўж ‘гҖӮ
дёҖжЈө m йҳ¶зҡ„ B+ ж ‘е’Ң m йҳ¶зҡ„ B ж ‘зҡ„ејӮеҗҢзӮ№еңЁдәҺпјҡ
1гҖҒжҜҸдёӘиҠӮзӮ№зҡ„жҢҮй’ҲдёҠйҷҗдёә 2d иҖҢдёҚжҳҜ2d+1гҖӮ
2гҖҒжүҖжңүзҡ„еҸ¶еӯҗз»“зӮ№дёӯеҢ…еҗ«дәҶе…ЁйғЁе…ій”®еӯ—зҡ„дҝЎжҒҜпјҢеҸҠжҢҮеҗ‘еҗ«жңүиҝҷдәӣе…ій”®еӯ—и®°еҪ•зҡ„жҢҮй’ҲпјҢдё”еҸ¶еӯҗз»“зӮ№жң¬иә«дҫқе…ій”®еӯ—зҡ„еӨ§е°ҸиҮӘе°ҸиҖҢеӨ§зҡ„йЎәеәҸй“ҫжҺҘгҖӮпјҲB ж ‘зҡ„еҸ¶еӯҗиҠӮзӮ№е№¶жІЎжңүеҢ…жӢ¬е…ЁйғЁйңҖиҰҒжҹҘжүҫзҡ„дҝЎжҒҜпјү
3гҖҒжүҖжңүзҡ„йқһз»Ҳз«Ҝз»“зӮ№еҸҜд»ҘзңӢжҲҗжҳҜзҙўеј•йғЁеҲҶпјҢз»“зӮ№дёӯд»…еҗ«жңүе…¶еӯҗж ‘ж №з»“зӮ№дёӯжңҖеӨ§пјҲжҲ–жңҖе°Ҹпјүе…ій”®еӯ—пјҢдёҚеӯҳеӮЁ dataгҖӮпјҲB ж ‘зҡ„йқһз»ҲиҠӮзӮ№д№ҹеҢ…еҗ«йңҖиҰҒжҹҘжүҫзҡ„жңүж•ҲдҝЎжҒҜпјү
дёәд»Җд№ҲиҜҙ B+ ж ‘жҜ” B ж ‘жӣҙйҖӮеҗҲеҒҡж•°жҚ®еә“зҙўеј•пјҹ
1пјүB+ ж ‘зҡ„зЈҒзӣҳиҜ»еҶҷд»Јд»·жӣҙдҪҺ
B+ ж ‘зҡ„еҶ…йғЁз»“зӮ№е№¶жІЎжңүеӯҳеӮЁе…ій”®еӯ—е…·дҪ“дҝЎжҒҜгҖӮеӣ жӯӨе…¶еҶ…йғЁз»“зӮ№зӣёеҜ№ B ж ‘жӣҙе°ҸгҖӮ
еҰӮжһңжҠҠжүҖжңүеҗҢдёҖеҶ…йғЁз»“зӮ№зҡ„е…ій”®еӯ—еӯҳж”ҫеңЁеҗҢдёҖзӣҳеқ—дёӯпјҢйӮЈд№Ҳзӣҳеқ—жүҖиғҪе®№зәізҡ„е…ій”®еӯ—ж•°йҮҸд№ҹи¶ҠеӨҡгҖӮдёҖж¬ЎжҖ§иҜ»е…ҘеҶ…еӯҳдёӯзҡ„йңҖиҰҒжҹҘжүҫзҡ„е…ій”®еӯ—д№ҹе°ұи¶ҠеӨҡгҖӮзӣёеҜ№жқҘиҜҙ IO иҜ»еҶҷж¬Ўж•°д№ҹе°ұйҷҚдҪҺдәҶгҖӮ
2) B+ ж ‘зҡ„жҹҘиҜўж•ҲзҺҮжӣҙеҠ зЁіе®ҡ
з”ұдәҺйқһз»Ҳз«Ҝз»“зӮ№е№¶дёҚжҳҜжңҖз»ҲжҢҮеҗ‘ж–Ү件еҶ…е®№зҡ„з»“зӮ№пјҢиҖҢеҸӘжҳҜеҸ¶еӯҗз»“зӮ№дёӯе…ій”®еӯ—зҡ„зҙўеј•гҖӮжүҖд»Ҙд»»дҪ•е…ій”®еӯ—зҡ„жҹҘжүҫеҝ…йЎ»иө°дёҖжқЎд»Һж №з»“зӮ№еҲ°еҸ¶еӯҗз»“зӮ№зҡ„и·ҜгҖӮжүҖжңүе…ій”®еӯ—жҹҘиҜўзҡ„и·Ҝеҫ„й•ҝеәҰзӣёеҗҢпјҢиҝӣиҖҢжҜҸдёҖдёӘж•°жҚ®зҡ„жҹҘиҜўж•ҲзҺҮзӣёеҪ“гҖӮ
еҮ з§Қж ‘зҡ„еҜ№жҜ”
д»ҘдёҠпјҢдёәдәҶд»Ӣз»Қзҙўеј•еҶ…е®№пјҢжҲ‘们иҠұиҙ№дәҶеӨ§йҮҸзҡ„зҜҮе№…д»Ӣз»ҚдәҶеҮ з§Қж•°жҚ®з»“жһ„жЁЎеһӢпјҢзү№еҲ«жҳҜж ‘зҡ„зӣёе…іжҰӮеҝөгҖӮ
еҸҰеӨ–пјҢж¶үеҸҠеҲ°ж ‘зҡ„ж·»еҠ е’ҢеҲ йҷӨе…ғзҙ пјҢж“ҚдҪңжӣҙеҠ еӨҚжқӮпјҢжң¬ж–ҮзҜҮе№…жңүйҷҗпјҲе…¶е®һжҳҜе°Ҹзј–д№ҹжҗһдёҚеӨӘжҳҺзҷҪпјүпјҢиҝҷйҮҢе°ұдёҚеҶҚеұ•ејҖгҖӮ
жңүе…ҙи¶Јзҡ„пјҢејәзғҲе»әи®®й’»з ”дёӢеҸӮиҖғй“ҫжҺҘйҮҢзҡ„еҶ…е®№гҖӮ
еҘҪдәҶпјҢдёӢйқўжҲ‘们жқҘзңӢ MySQL дёӯзҡ„ InnoDB еј•ж“Һзҡ„зҙўеј•жҳҜеҰӮдҪ•е®һзҺ°зҡ„гҖӮ
иҜҙдәҶиҝҷд№ҲеӨҡпјҢз»ҲдәҺеҲ°зҙўеј•еҮәеңәдәҶгҖӮ
зҙўеј•е°ұжҳҜиҝҷз§ҚзҘһеҘҮдјҹеӨ§зҡ„еӯҳеңЁгҖӮзҙўеј•зӣёеҪ“дәҺж•°жҚ®еә“зҡ„иЎЁж•°жҚ®д№ӢеӨ–ж–°е»әзҡ„ж•°жҚ®з»“жһ„пјҢиҜҘж•°жҚ®з»“жһ„зҡ„ж•°жҚ®ж®өдёӯеӯҳеӮЁзқҖеӯ—ж®өзҡ„еҖјд»ҘеҸҠжҢҮеҗ‘е®һйҷ…ж•°жҚ®и®°еҪ•зҡ„жҢҮй’ҲгҖӮ
ж•°жҚ®еә“иЎЁзҡ„зҙўеј•д»Һж•°жҚ®еӯҳеӮЁж–№ејҸдёҠеҸҜд»ҘеҲҶдёәиҒҡз°Үзҙўеј•е’ҢйқһиҒҡз°Үзҙўеј•пјҲеҸҲеҸ«дәҢзә§зҙўеј•пјүдёӨз§ҚгҖӮ
1гҖҒиҒҡз°Үзҙўеј•
иЎЁж•°жҚ®жҢүз…§зҙўеј•зҡ„йЎәеәҸжқҘеӯҳеӮЁзҡ„пјҢд№ҹе°ұжҳҜиҜҙзҙўеј•йЎ№зҡ„йЎәеәҸдёҺиЎЁдёӯи®°еҪ•зҡ„зү©зҗҶйЎәеәҸдёҖиҮҙгҖӮ
еҜ№дәҺиҒҡз°Үзҙўеј•пјҢеҸ¶еӯҗз»“зӮ№еҚіеӯҳеӮЁдәҶзңҹе®һзҡ„ж•°жҚ®иЎҢпјҢдёҚеҶҚжңүеҸҰеӨ–еҚ•зӢ¬зҡ„ж•°жҚ®йЎөгҖӮ еңЁдёҖеј иЎЁдёҠжңҖеӨҡеҸӘиғҪеҲӣе»әдёҖдёӘиҒҡйӣҶзҙўеј•пјҢеӣ дёәзңҹе®һж•°жҚ®зҡ„зү©зҗҶйЎәеәҸеҸӘиғҪжңүдёҖз§ҚгҖӮ
иҒҡз°ҮйӣҶжҳҜжҢҮе®һйҷ…зҡ„ж•°жҚ®иЎҢе’Ңзӣёе…ізҡ„й”®еҖјйғҪдҝқеӯҳеңЁдёҖиө·гҖӮ
жіЁж„Ҹпјҡж•°жҚ®зҡ„зү©зҗҶеӯҳж”ҫйЎәеәҸдёҺзҙўеј•йЎәеәҸжҳҜдёҖиҮҙзҡ„пјҢеҚіпјҡеҸӘиҰҒзҙўеј•жҳҜзӣёйӮ»зҡ„пјҢйӮЈд№ҲеҜ№еә”зҡ„ж•°жҚ®дёҖе®ҡд№ҹжҳҜзӣёйӮ»ең°еӯҳж”ҫеңЁзЈҒзӣҳдёҠзҡ„гҖӮ
еҰӮжһңдё»й”®дёҚжҳҜиҮӘеўһ idпјҢйӮЈд№ҲеҸҜд»ҘжғіиұЎпјҢе®ғдјҡе№Ідәӣд»Җд№ҲпјҢдёҚж–ӯең°и°ғж•ҙж•°жҚ®зҡ„зү©зҗҶең°еқҖгҖҒеҲҶйЎөгҖӮеҰӮжһңжҳҜиҮӘеўһзҡ„пјҢйӮЈе°ұз®ҖеҚ•дәҶпјҢе®ғеҸӘйңҖиҰҒдёҖйЎөдёҖйЎөең°еҶҷпјҢзҙўеј•з»“жһ„зӣёеҜ№зҙ§еҮ‘пјҢзЈҒзӣҳзўҺзүҮе°‘пјҢж•ҲзҺҮд№ҹй«ҳгҖӮ
иҒҡз°Үзҙўеј•зҡ„дәҢзә§зҙўеј•пјҡеҸ¶еӯҗиҠӮзӮ№дёҚдјҡдҝқеӯҳеј•з”Ёзҡ„иЎҢзҡ„зү©зҗҶдҪҚзҪ®,иҖҢжҳҜдҝқеӯҳдәҶиЎҢзҡ„дё»й”®еҖј
2гҖҒйқһиҒҡйӣҶзҙўеј•
иЎЁж•°жҚ®еӯҳеӮЁйЎәеәҸдёҺзҙўеј•йЎәеәҸж— е…ігҖӮеҜ№дәҺйқһиҒҡйӣҶзҙўеј•пјҢеҸ¶з»“зӮ№еҢ…еҗ«зҙўеј•еӯ—ж®өеҖјеҸҠжҢҮеҗ‘ж•°жҚ®йЎөж•°жҚ®иЎҢзҡ„йҖ»иҫ‘жҢҮй’ҲпјҢе…¶иЎҢж•°йҮҸдёҺж•°жҚ®иЎЁиЎҢж•°жҚ®йҮҸдёҖиҮҙгҖӮ
иҒҡз°Үзҙўеј•жҳҜеҜ№зЈҒзӣҳдёҠе®һйҷ…ж•°жҚ®йҮҚж–°з»„з»Үд»ҘжҢүжҢҮе®ҡзҡ„дёҖдёӘжҲ–еӨҡдёӘеҲ—зҡ„еҖјжҺ’еәҸзҡ„з®—жі•гҖӮзү№зӮ№жҳҜеӯҳеӮЁж•°жҚ®зҡ„йЎәеәҸе’Ңзҙўеј•йЎәеәҸдёҖиҮҙгҖӮдёҖиҲ¬жғ…еҶөдёӢдё»й”®дјҡй»ҳи®ӨеҲӣе»әиҒҡз°Үзҙўеј•пјҢдё”дёҖеј иЎЁеҸӘе…Ғи®ёеӯҳеңЁдёҖдёӘиҒҡз°Үзҙўеј•гҖӮ
иҝҷдёӨдёӘеҗҚеӯ—иҷҪ然йғҪеҸ«еҒҡзҙўеј•пјҢдҪҶиҝҷ并дёҚжҳҜдёҖз§ҚеҚ•зӢ¬зҡ„зҙўеј•зұ»еһӢпјҢиҖҢжҳҜдёҖз§Қж•°жҚ®еӯҳеӮЁж–№ејҸгҖӮ
дёӢйқўпјҢжҲ‘们еҸҜд»ҘзңӢдёҖдёӢ MYSQL дёӯ MyISAM е’Ң InnoDB дёӨз§Қеј•ж“Һзҡ„зҙўеј•з»“жһ„гҖӮ
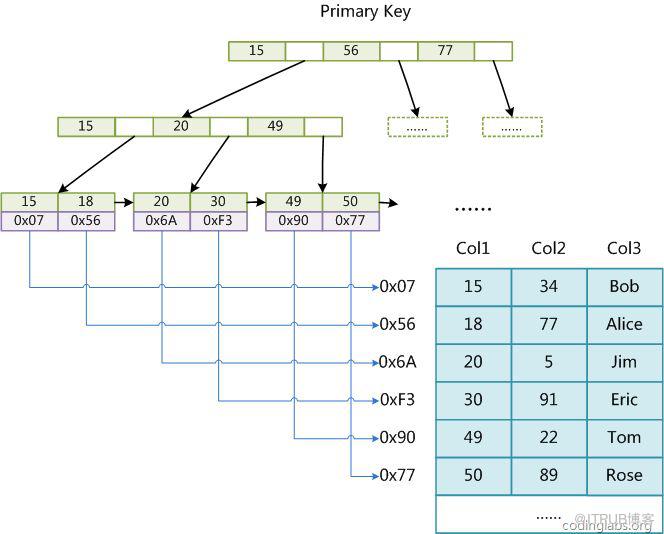
MyISAM еј•ж“ҺдҪҝз”Ё B+ ж ‘дҪңдёәзҙўеј•з»“жһ„пјҢеҸ¶иҠӮзӮ№зҡ„ data еҹҹеӯҳж”ҫзҡ„жҳҜж•°жҚ®и®°еҪ•зҡ„ең°еқҖпјҢе°ұжҳҜйқһиҒҡйӣҶзҙўеј•гҖӮ
дёӢеӣҫжҳҜ MyISAM зҙўеј•зҡ„еҺҹзҗҶеӣҫпјҡ
иҷҪ然 InnoDB д№ҹдҪҝз”Ё B+ ж ‘дҪңдёәзҙўеј•з»“жһ„пјҢдҪҶе…·дҪ“е®һзҺ°ж–№ејҸеҚҙдёҺ MyISAM жҲӘ然дёҚеҗҢгҖӮ
第дёҖдёӘйҮҚеӨ§еҢәеҲ«жҳҜ InnoDB зҡ„ж•°жҚ®ж–Ү件жң¬иә«е°ұжҳҜзҙўеј•ж–Ү件гҖӮ
еңЁ InnoDB дёӯпјҢиЎЁж•°жҚ®ж–Ү件жң¬иә«е°ұжҳҜжҢү B+ ж ‘з»„з»Үзҡ„дёҖдёӘзҙўеј•з»“жһ„пјҢиҝҷжЈөж ‘зҡ„еҸ¶иҠӮзӮ№ data еҹҹдҝқеӯҳдәҶе®Ңж•ҙзҡ„ж•°жҚ®и®°еҪ•гҖӮиҝҷдёӘзҙўеј•зҡ„ key жҳҜж•°жҚ®иЎЁзҡ„дё»й”®пјҢеӣ жӯӨ InnoDB иЎЁж•°жҚ®ж–Ү件жң¬иә«е°ұжҳҜдё»зҙўеј•гҖӮ
еҸҰеӨ–пјҢ第дәҢдёӘдёҺ MyISAM зҙўеј•зҡ„дёҚеҗҢжҳҜ InnoDB зҡ„иҫ…еҠ©зҙўеј• data еҹҹеӯҳеӮЁзӣёеә”и®°еҪ•дё»й”®зҡ„еҖјиҖҢдёҚжҳҜең°еқҖгҖӮ
еҜ№дәҺиҒҡз°Үзҙўеј•еӯҳеӮЁжқҘиҜҙпјҢиЎҢж•°жҚ®е’Ңдё»й”® B+ ж ‘еӯҳеӮЁеңЁдёҖиө·пјҢиҫ…еҠ©зҙўеј•еҸӘеӯҳеӮЁиҫ…еҠ©й”®е’Ңдё»й”®пјҢдё»й”®е’Ңйқһдё»й”® B+ ж ‘еҮ д№ҺжҳҜдёӨз§Қзұ»еһӢзҡ„ж ‘гҖӮ
еҜ№дәҺйқһиҒҡз°Үзҙўеј•еӯҳеӮЁжқҘиҜҙпјҢдё»й”® B+ ж ‘еңЁеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁжҢҮеҗ‘зңҹжӯЈж•°жҚ®иЎҢзҡ„жҢҮй’ҲпјҢиҖҢйқһдё»й”®гҖӮ
дёәдәҶжӣҙеҪўиұЎиҜҙжҳҺиҝҷдёӨз§Қзҙўеј•зҡ„еҢәеҲ«пјҢжҲ‘们еҒҮжғідёҖдёӘиЎЁеҰӮдёӢеӣҫеӯҳеӮЁдәҶ 4 иЎҢж•°жҚ®гҖӮе…¶дёӯ Id дҪңдёәдё»зҙўеј•пјҢName дҪңдёәиҫ…еҠ©зҙўеј•гҖӮеӣҫзӨәжё…жҷ°зҡ„жҳҫзӨәдәҶиҒҡз°Үзҙўеј•е’ҢйқһиҒҡз°Үзҙўеј•зҡ„е·®ејӮгҖӮ
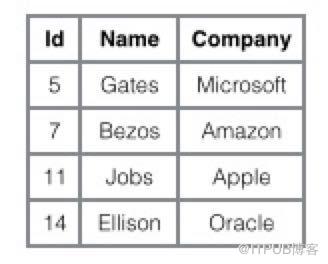
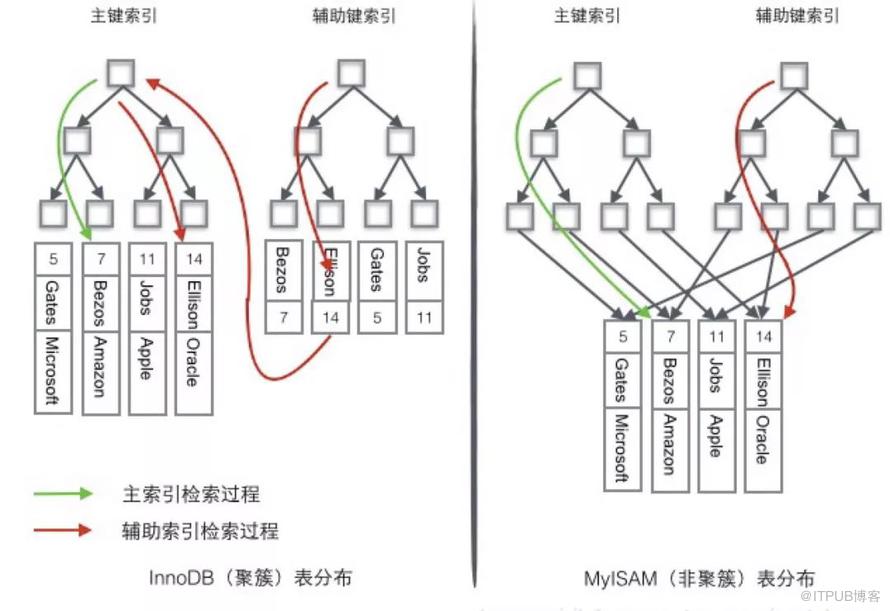
where id = 14 иҝҷж ·зҡ„жқЎд»¶жҹҘжүҫдё»й”®пјҢеҲҷжҢүз…§ B+ ж ‘зҡ„жЈҖзҙўз®—жі•еҚіеҸҜжҹҘжүҫеҲ°еҜ№еә”зҡ„еҸ¶иҠӮзӮ№пјҢд№ӢеҗҺиҺ·еҫ—иЎҢж•°жҚ®гҖӮиӢҘдҪҝз”Ёиҫ…еҠ©зҙўеј•иҝӣиЎҢжҹҘиҜўпјҢеҜ№ Name еҲ—иҝӣиЎҢжқЎд»¶жҗңзҙўпјҢеҲҷйңҖиҰҒдёӨдёӘжӯҘйӘӨпјҡ
1гҖҒ第дёҖжӯҘеңЁиҫ…еҠ©зҙўеј• B+ ж ‘дёӯжЈҖзҙў NameпјҢеҲ°иҫҫе…¶еҸ¶еӯҗиҠӮзӮ№иҺ·еҸ–еҜ№еә”зҡ„дё»й”®гҖӮ
2гҖҒ第дәҢжӯҘж №жҚ®дё»й”®еңЁдё»зҙўеј• B+ ж ‘з§ҚеҶҚжү§иЎҢдёҖж¬Ў B+ ж ‘жЈҖзҙўж“ҚдҪңпјҢжңҖз»ҲеҲ°иҫҫеҸ¶еӯҗиҠӮзӮ№еҚіеҸҜиҺ·еҸ–ж•ҙиЎҢж•°жҚ®гҖӮиҝҷдёӘиҝҮзЁӢз§°дёәеӣһиЎЁгҖӮ
1гҖҒз”ұдәҺиЎҢж•°жҚ®е’ҢеҸ¶еӯҗиҠӮзӮ№еӯҳеӮЁеңЁдёҖиө·пјҢиҝҷж ·дё»й”®е’ҢиЎҢж•°жҚ®жҳҜдёҖиө·иў«иҪҪе…ҘеҶ…еӯҳзҡ„пјҢжүҫеҲ°еҸ¶еӯҗиҠӮзӮ№е°ұеҸҜд»Ҙз«ӢеҲ»е°ҶиЎҢж•°жҚ®иҝ”еӣһдәҶпјҢеҰӮжһңжҢүз…§дё»й”® Id жқҘз»„з»Үж•°жҚ®пјҢиҺ·еҫ—ж•°жҚ®жӣҙеҝ«гҖӮ
2гҖҒиҫ…еҠ©зҙўеј•дҪҝз”Ёдё»й”®дҪңдёәжҢҮй’ҲиҖҢдёҚжҳҜдҪҝз”Ёең°еқҖеҖјдҪңдёәжҢҮй’Ҳзҡ„еҘҪеӨ„жҳҜпјҢеҮҸе°‘дәҶеҪ“еҮәзҺ°иЎҢ移еҠЁжҲ–иҖ…ж•°жҚ®йЎөеҲҶиЈӮж—¶иҫ…еҠ©зҙўеј•зҡ„з»ҙжҠӨе·ҘдҪңгҖӮ
дҪҝз”Ёдё»й”®еҖјеҪ“дҪңжҢҮй’Ҳдјҡи®©иҫ…еҠ©зҙўеј•еҚ з”ЁжӣҙеӨҡзҡ„з©әй—ҙпјҢжҚўжқҘзҡ„еҘҪеӨ„жҳҜ InnoDB еңЁз§»еҠЁиЎҢж—¶ж— йЎ»жӣҙж–°иҫ…еҠ©зҙўеј•дёӯзҡ„иҝҷдёӘжҢҮй’ҲгҖӮ
д№ҹе°ұжҳҜиҜҙиЎҢзҡ„дҪҚзҪ®дјҡйҡҸзқҖж•°жҚ®еә“йҮҢж•°жҚ®зҡ„дҝ®ж”№иҖҢеҸ‘з”ҹеҸҳеҢ–пјҢдҪҝз”ЁиҒҡз°Үзҙўеј•е°ұеҸҜд»ҘдҝқиҜҒдёҚз®ЎиҝҷдёӘдё»й”® B+ ж ‘зҡ„иҠӮзӮ№еҰӮдҪ•еҸҳеҢ–пјҢиҫ…еҠ©зҙўеј•ж ‘йғҪдёҚеҸ—еҪұе“ҚгҖӮ
д»ҘдёҠжҳҜвҖңMySQLдёӯдёәд»Җд№ҲиҰҒдҪҝз”Ёзҙўеј•вҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ