您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
MongoDB数据是特别灵活的,与SQL数据库相比,它不需要在插入数据前先定义表的结构。MongoDB的集合不强调固定的文档结构。这种灵活性使它能够轻松映射文档结构。每一个文档都可以映射它要表达的对象,即使这些数据有实质性的不同。其实在实际中,同一集合下的文档通常采用相似的结构。
MongoDB数据建模的主要问题时在应用程序的需求,数据库引擎的性能特性和数据检索模型之间做一个平衡。设计数据模型是,总是要考虑应用程序使用到的数据(查询、更新以及需要处理的数据等等)以及数据结构本身。
文档结构
设计MongoDB数据模型的关键是考虑好文档结构和应用程序表示的数据之间的关系。有两种方式可以表达这种关系:引用(references)和嵌入文档(embedded documents)。
引用(References)
引用(References)存储数据之间的关系,包括从一个文档链接或引用到另外一个文档。这样应用程序就解决了访问关联数据的问题,一般来说,这些都是规范数据的数据模型。

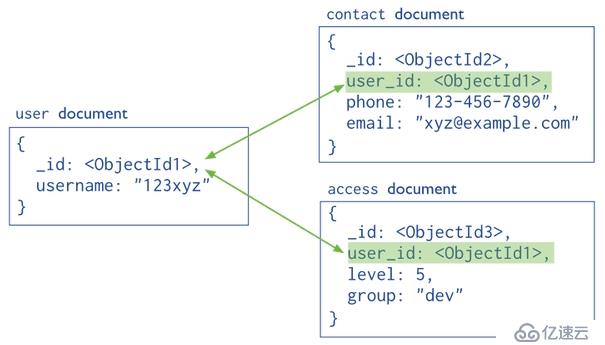
嵌入式文档通过存储相关的数据在一个文档结构中来捕获数据之间的关系。MongoDB文档可以在当前文档的字段或数组中嵌入文档作为子文档。这些非规范化数据模型允许应用程序检索和操作相关的数据在一个单一的数据库操作。

写操作的原子性
在MongoDB中,写操作的原子性限制在文档级别,没有一个写操作可以自动影响到多个文档或多个集合。规范化的嵌入式数据模型整合了所有的关联数据在一个文档中来展现实体。这有助于原子写操作在一个写操作中插入和更新实体的数据。规范化数据能够分隔多个集合的数据并且需要在非原子性操作中需要多个写操作。
然后,促进原子写的模式可能限制应用程序使用数据,也可能限制修改应用程序的方法。原子性考虑设计模式的挑战,平衡灵活性和原子性。
文档增加
像添加元素到数组或者增加新字段这样的更新,会增加文档的大小。如果文档的大小超过了为该文档分配空间,MongoDB会重新分配磁盘空间。考虑到空间的增加,应该规范化或使用规范的数据。
数据使用和性能
当设计数据模型的时候,应考虑应用程序如何使用数据库。比如,如果应用程序仅使用最近插入的文档,考虑使用顶端集合(Capped Collections)。如果应用程序需要频繁的读取集合,添加索引能够提高数据查询效率。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。