жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶMySQL MHAйӣҶзҫӨж–№жЎҲжҳҜжҖҺж ·зҡ„пјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
MySQL MHAйӣҶзҫӨж–№жЎҲи°ғз ”
MHAжҳҜз”ұж—Ҙжң¬Mysql专家用PerlеҶҷзҡ„дёҖеҘ—Mysqlж•…йҡңеҲҮжҚўж–№жЎҲд»Ҙдҝқйҡңж•°жҚ®еә“зҡ„й«ҳеҸҜз”ЁжҖ§пјҢе®ғзҡ„еҠҹиғҪжҳҜиғҪеңЁ0-30sд№ӢеҶ…е®һзҺ°дё»Mysqlж•…йҡңиҪ¬з§»пјҲfailoverпјүпјҢ
MHAж•…йҡңиҪ¬з§»еҸҜд»ҘеҫҲеҘҪзҡ„её®жҲ‘们解еҶід»Һеә“ж•°жҚ®зҡ„дёҖиҮҙжҖ§й—®йўҳпјҢеҗҢж—¶жңҖеӨ§еҢ–жҢҪеӣһж•…йҡңеҸ‘з”ҹеҗҺзҡ„ж•°жҚ®гҖӮMHAйҮҢжңүдёӨдёӘи§’иүІдёҖдёӘжҳҜnodeиҠӮзӮ№ дёҖдёӘжҳҜmanagerиҠӮзӮ№пјҢиҰҒе®һзҺ°иҝҷдёӘMHAпјҢеҝ…йЎ»жңҖе°‘иҰҒдёүеҸ°ж•°жҚ®еә“жңҚеҠЎеҷЁпјҢдёҖдё»еӨҡеӨҮпјҢеҚідёҖеҸ°е……еҪ“masterпјҢдёҖеҸ°е……еҪ“masterзҡ„еӨҮд»ҪжңәпјҢеҸҰеӨ–дёҖеҸ°жҳҜд»ҺеұһжңәгҖӮ
е®ҳж–№иө„ж–ҷзҪ‘з«ҷпјҡ
https://code.google.com/p/mysql-master-ha/w/list
https://code.google.com/p/mysql-master-ha/wiki/Tutorial
еңЁеҹәдәҺMySQLеӨҚеҲ¶зҡ„MHAйӣҶзҫӨжһ¶жһ„дёӯпјҢеҪ“MasterеҸ‘з”ҹж•…йҡңж—¶пјҢMHA йҖҡиҝҮеҰӮдёӢжӯҘйӘӨжқҘдҝқиҜҒж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҡ
пјҲ1пјү жүҫеҮәеҗҢжӯҘжңҖжҲҗеҠҹзҡ„дёҖеҸ°д»ҺжңҚеҠЎеҷЁпјҲд№ҹе°ұжҳҜдёҺдё»жңҚеҠЎеҷЁж•°жҚ®жңҖжҺҘиҝ‘зҡ„йӮЈеҸ°д»ҺжңҚеҠЎеҷЁпјүгҖӮ
пјҲ2пјү еҰӮжһңдё»жңәиҝҳиғҪеӨҹи®ҝй—®пјҢд»Һдё»жңҚеҠЎеҷЁдёҠжүҫеӣһжңҖж–°д»ҺжңәдёҺдё»жңәй—ҙзҡ„ж•°жҚ®е·®ејӮгҖӮ
пјҲ3пјү еңЁжҜҸдёҖеҸ°д»ҺжңҚеҠЎеҷЁдёҠж“ҚдҪңпјҢзЎ®е®ҡ他们зјәе°‘е“ӘдәӣeventsпјҢ并еҲҶеҲ«иҝӣиЎҢиЎҘе……гҖӮ
пјҲ4пјү е°ҶжңҖж–°зҡ„дёҖеҸ°д»ҺжңҚеҠЎеҷЁжҸҗеҚҮдёәдё»жңҚеҠЎеҷЁеҗҺгҖӮ
пјҲ5пјү е°Ҷе…¶е®ғд»ҺжңҚеҠЎеҷЁйҮҚж–°жҢҮеҗ‘ж–°зҡ„дё»жңҚеҠЎеҷЁгҖӮ
иҷҪ然MHAиҜ•еӣҫд»Һе®•жңәзҡ„дё»жңҚеҠЎеҷЁдёҠдҝқеӯҳдәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢдҪҶ并дёҚжҳҜжҖ»жҳҜеҸҜиЎҢзҡ„гҖӮдҫӢеҰӮпјҢеҰӮжһңдё»жңҚеҠЎеҷЁзЎ¬д»¶ж•…йҡңжҲ–ж— жі•йҖҡиҝҮsshи®ҝй—®пјҢMHAжІЎжі•дҝқеӯҳдәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢеҸӘиҝӣиЎҢж•…йҡңиҪ¬з§»иҖҢдёўеӨұжңҖж–°ж•°жҚ®гҖӮ
з»“еҗҲеҚҠеҗҢжӯҘеӨҚеҲ¶пјҢеҸҜд»ҘеӨ§еӨ§йҷҚдҪҺж•°жҚ®дёўеӨұзҡ„йЈҺйҷ©гҖӮMHAеҸҜд»ҘдёҺеҚҠеҗҢжӯҘеӨҚеҲ¶з»“еҗҲиө·жқҘпјҢеҰӮжһңеҸӘжңүдёҖдёӘslaveе·Із»Ҹ收еҲ°дәҶжңҖж–°зҡ„дәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢMHAеҸҜд»Ҙе°ҶжңҖж–°зҡ„дәҢиҝӣеҲ¶ж—Ҙеҝ—еә”з”ЁдәҺе…¶д»–жүҖжңүзҡ„slaveжңҚеҠЎеҷЁдёҠпјҢеӣ жӯӨ他们еҪјжӯӨдҝқжҢҒдёҖиҮҙжҖ§гҖӮ
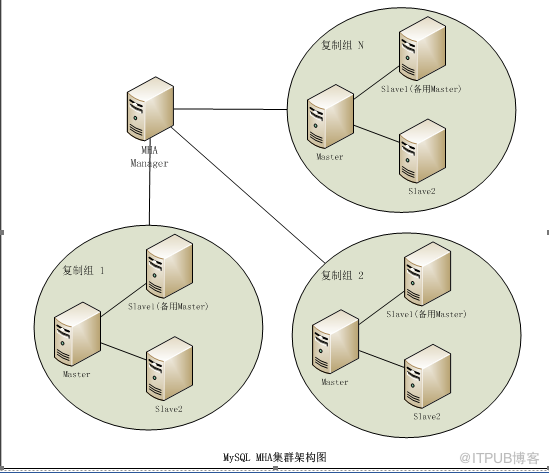
1.3.2 MHAз»„еҶ…жһ¶жһ„еӣҫ
еӨҚеҲ¶з»„еҶ…дҪҝз”ЁKeepalived + LVS пјҡ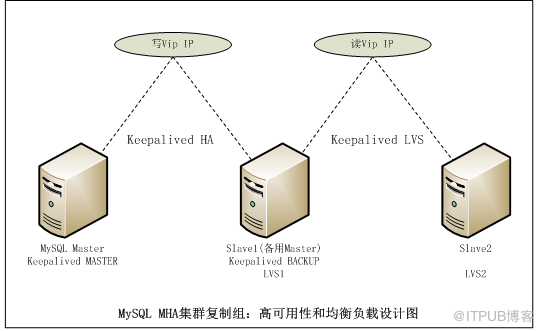
еңЁеҪ“еүҚе·ІеӯҳеңЁзҡ„дё»д»ҺеӨҚеҲ¶зҺҜеўғдёӯпјҢMHAеҸҜд»Ҙзӣ‘жҺ§masterдё»жңәж•…йҡңпјҢ并且故йҡңиҮӘеҠЁиҪ¬з§»гҖӮеҚідҪҝжңүдёҖдәӣslaveжІЎжңүжҺҘеҸ—ж–°зҡ„relay log eventsпјҢMHAд№ҹдјҡд»ҺжңҖж–°зҡ„slaveиҮӘеҠЁиҜҶеҲ«е·®ејӮзҡ„relay log eventsпјҢ并applyе·®ејӮзҡ„eventеҲ°е…¶д»–slavesгҖӮеӣ жӯӨжүҖжңүзҡ„slaveйғҪжҳҜдёҖиҮҙзҡ„гҖӮ MHAз§’зә§еҲ«ж•…йҡңиҪ¬з§», еҸҰеӨ–пјҢеңЁй…ҚзҪ®ж–Ү件йҮҢеҸҜд»Ҙй…ҚзҪ®дёҖдёӘslaveдјҳе…ҲжҲҗдёәMasterгҖӮ
еҪ“иҝҒ移新зҡ„masterд№ӢеҗҺпјҢ并иЎҢжҒўеӨҚе…¶д»–slaveгҖӮеҚідҪҝжңүжҲҗеҚғдёҠдёҮзҡ„slave,д№ҹдёҚдјҡеҪұе“ҚжҒўеӨҚmasterж—¶й—ҙпјҢslaveд№ҹеҫҲеҝ«е®ҢжҲҗгҖӮж•ҙдёӘиҝҮзЁӢж— йңҖDBAе№Ійў„гҖӮ
еңЁеҫҲеӨҡжғ…еҶөдёӢпјҢжңүеҝ…иҰҒе°ҶmasterиҪ¬з§»еҲ°е…¶д»–дё»жңәдёҠпјҲеҰӮжӣҝжҚўraidжҺ§еҲ¶еҷЁпјҢжҸҗеҚҮmasterжңәеҷЁзЎ¬д»¶зӯүзӯүпјүгҖӮиҝҷ并дёҚжҳҜmasterеҙ©жәғпјҢдҪҶжҳҜи®ЎеҲ’з»ҙжҠӨеҝ…йЎ»еҺ»еҒҡгҖӮи®ЎеҲ’з»ҙжҠӨеҜјиҮҙdowntimeпјҢеҝ…йЎ»е°ҪеҸҜиғҪеҝ«зҡ„жҒўеӨҚгҖӮеҝ«йҖҹзҡ„masterеҲҮжҚўе’Ңдјҳйӣ…зҡ„йҳ»еЎһеҶҷж“ҚдҪңжҳҜеҝ…йңҖзҡ„пјҢMHAжҸҗдҫӣдәҶиҝҷз§Қж–№ејҸгҖӮдјҳйӣ…зҡ„masterеҲҮжҚўпјҢ 0.5-2з§’еҶ…йҳ»еЎһеҶҷж“ҚдҪңгҖӮеңЁеҫҲеӨҡжғ…еҶөдёӢ0.5-2з§’зҡ„downtimeжҳҜеҸҜд»ҘжҺҘеҸ—зҡ„пјҢ并且еҚідҪҝдёҚеңЁи®ЎеҲ’з»ҙжҠӨзӘ—еҸЈгҖӮиҝҷж„Ҹе‘ізқҖеҪ“йңҖиҰҒжӣҙжҚўжӣҙеҝ«жңәеҷЁпјҢеҚҮзә§й«ҳзүҲжң¬ж—¶пјҢdbaеҸҜд»ҘеҫҲе®№жҳ“йҮҮеҸ–еҠЁдҪңгҖӮ
еҪ“master е®•еҗҺпјҢMHAиҮӘеҠЁиҜҶеҲ«slaveй—ҙrelay logeventsзҡ„дёҚеҗҢпјҢ然еҗҺеә”з”ЁдёҺдёҚеҗҢзҡ„slaveпјҢжңҖз»ҲжүҖжңүslaveйғҪеҗҢжӯҘгҖӮз»“еҗҲйҖҡиҝҮеҚҠеҗҢжӯҘдёҖиө·дҪҝз”ЁпјҢеҮ д№ҺжІЎжңүд»»дҪ•ж•°жҚ®дёўеӨұгҖӮ
MHAжңҖйҮҚиҰҒзҡ„дёҖдёӘи®ҫи®ЎзҗҶеҝөе°ұжҳҜе°ҪеҸҜиғҪдҪҝз”Ёз®ҖеҚ•гҖӮе…¶еҸӘиҰҒжҳҜеңЁдё»д»ҺзҺҜеўғдёӢпјҢMHAйӣҶзҫӨж— йңҖж”№еҸҳзҺ°жңүйғЁзҪІдҫҝеҸҜйғЁзҪІпјҢж— и®әжҳҜеңЁеҗҢжӯҘе’ҢеҚҠеҗҢжӯҘзҺҜеўғйғҪеҸҜд»Ҙз”ЁгҖӮеҗҜеҠЁ/еҒңжӯў/еҚҮзә§/йҷҚзә§/е®үиЈ…/еҚёиҪҪ MHAйғҪдёҚз”Ёж”№еҸҳmysqlдё»д»ҺпјҲеҰӮеҗҜеҠЁ/еҒңжӯўпјүгҖӮиҖҢе®ғйӣҶзҫӨж–№жЎҲйңҖиҰҒж”№еҸҳmysqlйғЁзҪІи®ҫзҪ®гҖӮ
еҪ“йңҖиҰҒеҚҮзә§MHAеҲ°ж–°зүҲжң¬ж—¶пјҢдёҚйңҖиҰҒеҒңжӯўmysqlпјҢд»…д»…жӣҙж–°HMAзүҲжң¬пјҢ然еҗҺйҮҚж–°еҗҜеҠЁMHAmangerеҚіеҸҜгҖӮ
MHA еҢ…еҗ«MHA Managerе’ҢMHA nodeгҖӮдёҖдёӘMHA ManagerеҸҜд»Ҙз®ЎзҗҶеӨҡдёӘMHA nodeйӣҶзҫӨз»„гҖӮеўһеҠ йӣҶзҫӨз»„ж—¶пјҢеҜ№ж–°еўһзҡ„йӣҶзҫӨз»„й…ҚзҪ®еӨҚеҲ¶пјҢ并且жӣҙж–°MHA Managerзҡ„й…ҚзҪ®еҚіеҸҜгҖӮеҜ№зҺ°жңүзҡ„йӣҶзҫӨз»„еҹәжң¬ж— еҪұе“ҚгҖӮеўһеҠ йӣҶзҫӨз»„ж•°йҮҸд№ҹдёҚдјҡеҜ№MHA ManagerжңүеӨӘеӨ§иҙҹжӢ…гҖӮManagerеҸҜд»ҘеҚ•зӢ¬йғЁзҪІдёҖеҸ°жңәеҷЁпјҢд№ҹеҸҜд»ҘиҝҗиЎҢеңЁslavesдёӯзҡ„дёҖеҸ°жңәеҷЁдёҠгҖӮ
MHAзӣ‘жҺ§MasterдёҚеҸ‘йҖҒеӨ§зҡ„жҹҘиҜўпјҢдё»д»ҺеӨҚеҲ¶жҖ§иғҪдёҚеҸ—еҪұе“ҚгҖӮжң¬жЎҲдҫӢйҖҡиҝҮиҮӘе®ҡд№үи„ҡжң¬пјҢе®ҡжңҹе°қиҜ•зҷ»йҷҶMaster еҰӮжһңзҷ»йҷҶеӨұиҙҘпјҢеҚіе®һж–Ҫж•…йҡңеҲҮжҚўгҖӮиҝҷд№Ҳзӣ‘жҺ§еҠһжі•пјҢеҜ№жҖ§иғҪеҹәжң¬жІЎд»Җд№ҲеҪұе“ҚгҖӮ
MysqlдёҚд»…д»…йҖӮз”ЁдәҺдәӢеҠЎе®үе…Ёзҡ„innodbеј•ж“ҺпјҢеңЁдё»д»ҺдёӯйҖӮз”Ёзҡ„еј•ж“ҺпјҢMHAйғҪеҸҜд»ҘйҖӮз”ЁгҖӮеҚідҪҝз”ЁйҒ—з•ҷзҺҜеўғзҡ„mysiamеј•ж“ҺпјҢдёҚиҝӣиЎҢиҝҒ移пјҢд№ҹеҸҜд»Ҙз”ЁMHAгҖӮ
MHAеҸҜйҖҡеёёжңүдёӨз§Қж–№ејҸе®һзҺ°дёҡеҠЎеұӮйқўзҡ„йҖҸжҳҺж•…йҡңиҪ¬з§»пјҡдёҖз§ҚжҳҜиҷҡжӢҹIPең°еқҖпјҢMHAз»“еҗҲKeepalived е’ҢLVSпјҢеҪ“зҫӨйӣҶеҶ…зҡ„ж•°жҚ®еә“иҝӣиЎҢж•…йҡңиҪ¬з§»ж—¶пјҢеҜ№еӨ–жҸҗдҫӣжңҚеҠЎзҡ„иҷҡжӢҹIPд№ҹиҝӣиЎҢиҪ¬з§»пјӣ第дәҢз§ҚжҳҜе…ЁеұҖй…ҚзҪ®ж–Ү件пјҢйҖҡиҝҮй…ҚзҪ®MHAзҡ„master_ip_failover_script гҖҒmaster_ip_online_change_scriptеҸӮж•°жқҘе®һзҺ°гҖӮ
MHAзҡ„MasterдёәеҸҜиҜ»еҶҷпјҢиҖҢеӨҮз”ЁMasterе’ҢSlaveйғҪеҸҜз”ЁдәҺжҹҘиҜўпјҢеҲҶжӢ…иҜ»еҺӢеҠӣгҖӮ
Master downжҺүеҗҺпјҢеҰӮйңҖйҮҚж–°еҠ е…ҘйӣҶзҫӨпјҢйңҖиҰҒжүӢе·Ҙжү§иЎҢе‘Ҫд»ӨеҲҮжҚўгҖӮ
еӨҮз”Ёзҡ„Master й»ҳи®ӨжҳҜеҸҜеҶҷзҡ„пјҢеҰӮжһңдёҚи®ҫзҪ®дёәread onlyпјҢеӯҳеңЁж•°жҚ®дёҚдёҖиҮҙжҖ§зҡ„йЈҺйҷ©гҖӮ并且read-onlyеҜ№superз”ЁжҲ·дёҚиө·дҪңз”ЁгҖӮ
з”ұдәҺдҪҝз”ЁдәҶMySQLзҡ„еӨҚеҲ¶пјҢиҖҢMySQLзҡ„еӨҚеҲ¶жҳҜеӯҳеңЁе»¶иҝҹзҡ„гҖӮMySQLзҡ„еӨҚеҲ¶е»¶иҝҹдё»иҰҒжҳҜеӣ дёәMasterеӨҡзәҝзЁӢеҜ№SlaveеҚ•зәҝзЁӢзҡ„иҝҹ延гҖӮ
дёәдәҶе®һзҺ°жӣҙеҘҪзҡ„ж•ҲжһңпјҢжң¬е®һйӘҢдҪҝз”ЁеӣӣеҸ°жңәеҷЁгҖӮдҪҝз”ЁMySQLзҡ„еҚҠеҗҢжӯҘеӨҚеҲ¶пјҢдҝқиҜҒж•°жҚ®зҡ„е®Ңж•ҙжҖ§гҖӮз»“еҗҲKeepalivedе’ҢLVS е®һзҺ°IPж•…йҡңйҖҸжҳҺиҪ¬з§»е’ҢиҜ»еҶҷеҲҶзҰ»гҖӮйңҖиҰҒиҜҙжҳҺзҡ„жҳҜдёҖж—Ұдё»жңҚеҠЎеҷЁе®•жңәпјҢеӨҮд»ҪжңәеҚіејҖе§Ӣе……еҪ“masterжҸҗдҫӣжңҚеҠЎпјҢеҰӮжһңдё»жңҚеҠЎеҷЁдёҠзәҝд№ҹдёҚдјҡеҶҚжҲҗдёәmasterдәҶпјҢеӣ дёәеҰӮжһңиҝҷж ·ж•°жҚ®еә“зҡ„дёҖиҮҙжҖ§е°ұиў«ж”№еҸҳдәҶгҖӮ
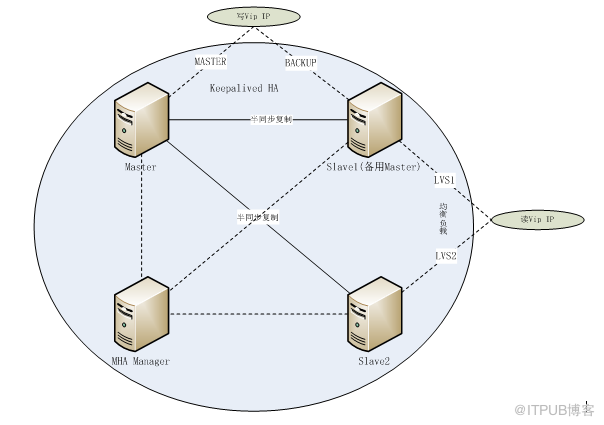
IP | дё»жңә | з”ЁйҖ”иҜҙжҳҺ |
192.168.0.11 | Master | MasterпјҢKeepalived HAзҡ„Master |
192.168.0.12 | Slave1(еӨҮз”ЁMaster) | еӨҮз”ЁMasterпјҢKeepalived HAзҡ„BACKUPпјҢLVSеқҮиЎЎиҙҹиҪҪдё»жңә |
192.168.0.13 | Slave2 | SlaveпјҢLVSеқҮиЎЎиҙҹиҪҪдё»жңә |
192.168.0.14 | MHA Manager | MHAйӣҶзҫӨзҡ„з®ЎзҗҶдё»жңә |
192.168.0.20 | иҷҡжӢҹIPең°еқҖ | MHAйӣҶзҫӨеҶҷVIPең°еқҖ |
192.168.0.21 | иҷҡжӢҹIPең°еқҖ | MHAйӣҶзҫӨиҜ»VIPең°еқҖ |
пјҲ1пјүйҰ–е…Ҳз”Ёssh-keygenе®һзҺ°еӣӣеҸ°дё»жңәд№Ӣй—ҙзӣёдә’е…ҚеҜҶй’Ҙзҷ»еҪ•
пјҲ2пјүе®үиЈ…MHAmha4mysql-nodeпјҢmha4mysql-manager иҪҜ件еҢ…
пјҲ3пјүе»әз«ӢmasterпјҢslave1пјҢslave2д№Ӣй—ҙдё»д»ҺеӨҚеҲ¶
пјҲ4пјүз®ЎзҗҶжңәmanagerдёҠй…ҚзҪ®MHAж–Ү件
пјҲ5пјүmasterha_check_sshе·Ҙе…·йӘҢиҜҒsshдҝЎд»»зҷ»еҪ•жҳҜеҗҰжҲҗеҠҹ
пјҲ6пјүmasterha_check_replе·Ҙе…·йӘҢиҜҒmysqlеӨҚеҲ¶жҳҜеҗҰжҲҗеҠҹ
пјҲ7пјүеҗҜеҠЁMHA manager,并зӣ‘жҺ§ж—Ҙеҝ—ж–Ү件
пјҲ8пјүжөӢиҜ•master(156)е®•жңәеҗҺпјҢжҳҜеҗҰдјҡиҮӘеҠЁеҲҮжҚў
еңЁMHAжүҖжңүдё»жңәдёӯз”ҹжҲҗrsaеҠ еҜҶи®ӨиҜҒпјҢ并й…ҚзҪ®дёәзӣёдә’и®ҝй—®ж— йңҖеҜҶз Ғ
ssh-keygen -t rsa
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.11
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.12
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.13
ssh-copy-id -i .ssh/id_rsa.pub root@192.168.0.14
еңЁ3дёӘMySQLдё»д»ҺиҠӮзӮ№дёҠе®үиЈ…MySQLиҪҜ件гҖӮ
rpm -qa mysql
rpm -e mysql-devel
rpm -e mysql
cd /media/RHEL_6.4\ x86_64\ Disc\ 1/Packages/
rpm -ivh cmake-2.6.4-5.el6.x86_64.rpm
cd /root
tar zxvf mysql-5.6.19.tar.gz
cd /root/mysql-5.6.19
mkdir -p /usr/local/mysql/data
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_DATADIR=/usr/local/mysql/data
make && make install
groupadd mysql
useradd -r -g mysql mysql
пјҲ5пјүеҲқе§ӢеҢ–MySQL
cd /usr/local/mysql
chown -R mysql .
chgrp -R mysql .
scripts/mysql_install_db --user=mysql
chown -R root .
chown -R mysql data
./bin/mysqld_safe --user=mysql &
cp support-files/mysql.server /etc/init.d/mysql.server
vi ~/.bash_profile
PATHеҠ дёҠпјҡ
:/usr/local/mysql/bin
source ~/.bash_profile
cp /usr/local/mysql/my.cnf /etc/
vi /etc/my.cnf
log_bin # mha3 дёҚдјҡжҳҜmasterпјҢеӣ жӯӨдёҚз”ЁиҜҘеҸӮж•°
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
port = 3306
server_id = 1 #дё»д»ҺеҗҢжӯҘйңҖиҰҒ
socket = /tmp/mysql.sock
йҮҚеҗҜMySQL пјҡservice mysql.server restart
GRANT ALL ON *.* TO root@localhost IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO root@'%' IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO root@mha1 IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
FLUSH PRIVILEGES;
пјҲ1пјүдҝ®ж”№MASTERдёҠзҡ„/etc/my.cnfпјҢеҠ е…Ҙпјҡ
server_id=1
log_bin
пјҲ2пјүдҝ®ж”№SLAVE1(еӨҮз”ЁMASTER)дёҠзҡ„/etc/my.cnfпјҢеҠ е…Ҙпјҡ
server_id=2
log_bin
пјҲ3пјүдҝ®ж”№SLAVE2дёҠзҡ„/etc/my.cnfпјҢеҠ е…Ҙпјҡ
server_id=3
пјҲ1пјүеңЁmasterдёҠжҺҲжқғ
mysql> grant replication slave on *.* to repl@'192.168.0.%' identified by 'repl';
пјҲ2пјүеңЁеӨҮйҖүmasterдёҠжҺҲжқғпјҡ
mysql> grant replication slave on *.* to repl@'192.168.0.%' identified by 'repl';
пјҲ1пјүеңЁMasterжҹҘзңӢеҪ“еүҚдҪҝз”Ёзҡ„дәҢиҝӣеҲ¶ж—Ҙеҝ—еҗҚз§°е’ҢдҪҚзҪ®
mysql> show master status;
и®°еҪ•дёӢ вҖңFileвҖқе’ҢвҖңPositionвҖқеҚіеҪ“еүҚдё»еә“дҪҝз”Ёзҡ„дәҢиҝӣеҲ¶ж—Ҙеҝ—еҗҚз§°е’ҢдҪҚзҪ®гҖӮ
пјҲ2пјүеҲҮжҚўеҲ°д»Һеә“жЁЎејҸ
еңЁSlave1(еӨҮз”ЁMaster)е’ҢSlave2 дёҠеҲҮжҚўеҲ°д»Һеә“жЁЎејҸ
mysql> change master to master_host="mha1",master_user="repl",master_password="repl",master_log_file="mha1-bin.000005",master_log_pos=120;
master_log_file е’Ң master_log_pos жҳҜдёҠйқўи®°дёӢзҡ„дёңиҘҝгҖӮ
пјҲ3пјүеҗҜеҠЁеӨҚеҲ¶
еңЁSlave1(еӨҮз”ЁMaster)е’Ңslave2дёҠеҗҜз”ЁеӨҚеҲ¶пјҡ
mysql>start slaveпјӣ
пјҲ6пјүеңЁslave2дёҠи®ҫзҪ®дёәеҸӘиҜ»
mysql>set global read_only=1
жіЁж„Ҹпјҡread-onlyеҜ№superжқғйҷҗзҡ„з”ЁжҲ·дёҚиө·дҪңз”Ё
пјҲ1пјүжҹҘзңӢеҮәеә“зҡ„зҠ¶жҖҒ
mysql>show master status\G;
пјҲ2пјүжҹҘзңӢд»Һеә“зҡ„зҠ¶жҖҒ
mysql>show slave status\G;
# еҰӮжһң Slave_IO_Running: Yes е’Ң Slave_SQL_Running: Yes еҲҷиҜҙжҳҺдё»д»Һй…ҚзҪ®жҲҗеҠҹгҖӮ
# иҝҳеҸҜд»ҘеҲ°masterдёҠжү§иЎҢ Mysql>show global status like вҖңrpl%вҖқ;
еҰӮжһңRpl_semi_sync_master_clients жҳҜ2иҜҙжҳҺеҚҠеҗҢжӯҘеӨҚеҲ¶жӯЈеёё
ж—Ҙеҝ—зҡ„еҗҢжӯҘж јејҸжңү3з§Қпјҡ
пјҲ1пјүеҹәдәҺSQLиҜӯеҸҘзҡ„еӨҚеҲ¶(statement-based replication, SBR)
пјҲ2пјүеҹәдәҺиЎҢзҡ„еӨҚеҲ¶(row-based replication, RBR)
пјҲ3пјүж··еҗҲжЁЎејҸеӨҚеҲ¶(mixed-based replication, MBR)
зӣёеә”ең°пјҢbinlogзҡ„ж јејҸд№ҹжңүдёүз§ҚпјҡSTATEMENTпјҢROWпјҢMIXEDгҖӮ MBR жЁЎејҸдёӯпјҢSBR жЁЎејҸжҳҜй»ҳи®Өзҡ„гҖӮдёәдәҶж•°жҚ®зҡ„дёҖиҮҙжҖ§пјҢе»әи®®йҖүжӢ©ROWжҲ–MIXEDжЁЎејҸгҖӮ
жҜ”еҰӮ,жңүеҮҪж•°пјҡ
CREATE DEFINER = 'root'@'%' FUNCTION f_test2
(
pid int
)
RETURNS int(11)
BEGIN
insert into t1 values (pid,sysdate());
RETURN 1;
END
еңЁдё»еә“жү§иЎҢ select f_test2(8)еҗҺпјҢеңЁдё»еә“е’Ңеҗ„дёӘд»Һеә“дёҠпјҢжҸ’е…Ҙзҡ„sysdate()зҡ„еҖјжҳҜдёҚеҗҢзҡ„;
й…ҚзҪ®MySQLеҚҠеҗҢжӯҘеӨҚеҲ¶зҡ„еүҚжҸҗжҳҜе·Із»Ҹй…ҚзҪ®дәҶMySQLзҡ„еӨҚеҲ¶гҖӮеҚҠеҗҢжӯҘеӨҚеҲ¶е·ҘдҪңзҡ„жңәеҲ¶еӨ„дәҺеҗҢжӯҘе’ҢејӮжӯҘд№Ӣй—ҙпјҢMasterзҡ„дәӢеҠЎжҸҗдәӨйҳ»еЎһпјҢеҸӘиҰҒдёҖдёӘSlave已收еҲ°иҜҘдәӢеҠЎзҡ„дәӢ件且已记еҪ•гҖӮе®ғдёҚдјҡзӯүеҫ…жүҖжңүзҡ„SlaveйғҪе‘ҠзҹҘ已收еҲ°пјҢдё”е®ғеҸӘжҳҜжҺҘ收пјҢ并дёҚз”Ёзӯүе…¶е®Ңе…Ёжү§иЎҢдё”жҸҗдәӨгҖӮ
еңЁж•…йҡңеҲҮжҚўзҡ„ж—¶еҖҷпјҢMasterе’ҢSlave1(еӨҮз”ЁMaster)йғҪжңүеҸҜиғҪжҲҗдёәMasterжҲ–SlaveпјҢеӣ жӯӨиҝҷдёӨдёӘжңҚеҠЎеҷЁдёҠйғҪиҰҒе®үиЈ…'semisync_master.so'е’Ң'semisync_slave.so'гҖӮ
пјҲ1пјүе®үиЈ…еҚҠеҗҢжӯҘжҸ’件
пјҲдҪңдёәMasterж—¶йңҖиҰҒе®үиЈ…зҡ„жҸ’件пјү
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';
пјҲдҪңдёәSlaveж—¶йңҖиҰҒе®үиЈ…зҡ„жҸ’件пјү
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
пјҲ2пјүи®ҫзҪ®еҸӮж•°
пјҲдҪңдёәMasterж—¶йңҖиҰҒи®ҫзҪ®зҡ„еҸӮж•°пјү
mysql> set global rpl_semi_sync_master_enabled=1;
mysql> set global rpl_semi_sync_master_timeout=1000;
mysql> show global status like 'rpl%';
пјҲдҪңдёәSlaveж—¶йңҖиҰҒи®ҫзҪ®зҡ„еҸӮж•°пјү
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
mysql> set global rpl_semi_sync_slave_enabled=1;
пјҲ3пјүдҝ®ж”№й…ҚзҪ®ж–Ү件
дёәдәҶи®©mysqlеңЁйҮҚеҗҜж—¶иҮӘеҠЁеҠ иҪҪиҜҘеҠҹиғҪпјҢеңЁ/etc/my.cnf еҠ е…Ҙпјҡ
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000
rpl_semi_sync_slave_enabled=1
пјҲ1пјүе®үиЈ…еҚҠеҗҢжӯҘжҸ’件
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
пјҲ2пјүи®ҫзҪ®еҸӮж•°
mysql> set global rpl_semi_sync_slave_enabled=1;
пјҲ3пјүдҝ®ж”№й…ҚзҪ®ж–Ү件
еңЁ/etc/my.cnfдёӯеҠ е…Ҙпјҡ
rpl_semi_sync_slave_enabled=1
еҸҜд»ҘеҲ°masterдёҠжү§иЎҢ Mysql>show global status like 'rpl%';
еҰӮжһңRpl_semi_sync_master_clients жҳҜ2.иҜҙжҳҺеҚҠеҗҢжӯҘеӨҚеҲ¶жӯЈеёё
MHAжңүдёӘдёҚж–№дҫҝзҡ„ең°ж–№жҳҜпјҢж— и®әе®•жңәеҜјиҮҙзҡ„masterеҲҮжҚўиҝҳжҳҜжүӢеҠЁеҲҮжҚўmaster, еҺҹжқҘзҡ„masterйғҪдёҚеңЁMHAжһ¶жһ„еҶ…дәҶпјҢйҮҚж–°еҗҜеҠЁд№ҹдёҚдјҡеҠ е…ҘпјҢеҝ…йЎ»жүӢеҠЁеҠ е…ҘгҖӮжүӢеҠЁеҠ е…Ҙзҡ„жӯҘйӘӨзұ»дјјпјҢе…ҲжҠҠеҪ“еүҚmasterж•°жҚ®еӨҚеҲ¶еҲ°иҰҒеҠ е…Ҙзҡ„жңәеҷЁпјҢ然еҗҺchange master,еҶҚstart slave, е…ій”®еңЁеҒҡиҝҷдёҖиҝҮзЁӢдёӯпјҢзі»з»ҹдёҚиғҪеҶҷе…ҘпјҢиҝҷзӮ№иҰҒдәәе‘ҪгҖӮ
дёҖдёӘMHAдё»жңәеҸҜд»Ҙз®ЎзҗҶеӨҡдёӘMySQLеӨҚеҲ¶з»„пјҢе®үиЈ…MHAйңҖиҰҒе…Ҳе®үиЈ…DBD-MySQLпјҢдёәдәҶе®үиЈ…DBD-MySQLж–№дҫҝпјҢе…Ҳе®үиЈ…yumе·Ҙе…·гҖӮ
vim /etc/yum.repos.d/rhel-source.repo
[rhel-source]
name=Red Hat Enterprise Linux $releasever - $basearch - Source
#baseurl=ftp://ftp.redhat.com/pub/redhat/linux/enterprise/$releasever/en/os/SRPMS/
baseurl=file:///mnt
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
[rhel-source-beta]
name=Red Hat Enterprise Linux $releasever Beta - $basearch - Source
#baseurl=ftp://ftp.redhat.com/pub/redhat/linux/beta/$releasever/en/os/SRPMS/
baseurl=file:///mnt
enabled=1
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-beta,file:///etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release
umount /dev/cdrom
mount /dev/cdrom /mnt
yum clean all
yum list
yum install perl-DBD-MySQL
cd /root
tar zxvf mha4mysql-node-0.54.tar.gz
cd mha4mysql-node-0.54
perl Makefile.PL
make
make install
пјҲ1пјүдёӢиҪҪе’Ңе®үиЈ…еҝ…иҰҒзҡ„еҢ…
дёӢиҪҪең°еқҖпјҡhttp://apt.sw.be/redhat/el6/en/i386/extras/RPMS/perl-Config-Tiny-2.12-1.el6.rfx.noarch.rpm
http://apt.sw.be/redhat/el6/en/x86_64/rpmforge/RPMS/perl-Log-Dispatch-2.26-1.el6.rf.noarch.rpm
http://apt.sw.be/redhat/el6/en/x86_64/rpmforge/RPMS/perl-Parallel-ForkManager-0.7.5-2.2.el6.rf.noarch.rpm
пјҲ2пјүе®үиЈ…еҝ…иҰҒзҡ„еҢ…
rpm -ivh perl-Params-Validate-0.92-3.el6.x86_64.rpm
rpm вҖ“ivh perl-Config-Tiny-2.12-1.el6.rfx.noarch.rpm
rpm вҖ“ivh perl-Log-Dispatch-2.26-1.el6.rf.noarch.rpm
rpm вҖ“ivh perl-Parallel-ForkManager-0.7.5-2.2.el6.rf.noarch.rpm
пјҲ3пјүе®үиЈ…MHA managerиҪҜ件
cd /mnt/Packages
cd /root
tar zxvf mha4mysql-manager-0.55.tar.gz
cd mha4mysql-manager-0.55
perl Makefile.PL
make
make install
еңЁMHA ManagerдёҠеҲӣе»әMHAй…ҚзҪ®
[root@mha4 ~]# more /etc/masterha/app1.cnf
[server default]
# mysql user and password
user=root
password=revenco123
ssh_user=root
repl_user=repl
repl_password=repl
ping_interval=1
shutdown_script=""
# working directory on the manager
manager_workdir=/var/log/masterha/app1
manager_log=/var/log/masterha/app1/manager.log
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=mha1
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server2]
hostname=mha2
master_binlog_dir=/usr/local/mysql/data
candidate_master=1
[server3]
hostname=mha3
master_binlog_dir=/usr/local/mysql/data
no_master=1
жіЁйҮҠпјҡе…·дҪ“зҡ„еҸӮж•°иҜ·жҹҘзңӢе®ҳж–№ж–ҮжЎЈ
https://code.google.com/p/mysql-master-ha/wiki/Parameters
еңЁMHA ManagerдёҠжү§иЎҢ
masterha_check_ssh --conf=/etc/masterha/app1.cnf
masterha_check_repl --conf=/etc/masterha/app1.cnf
еҰӮжһңжҠҘй”ҷпјҢиҜ·жЈҖжҹҘй…ҚзҪ®гҖӮ
й—®йўҳ1 пјҡ
Can't exec "mysqlbinlog": No such file or directory at /usr/local/share/perl/5.10.1/MHA/BinlogManager.pm line 99.
mysqlbinlog version not found!
и§ЈеҶіеҠһжі•пјҡ
#vi ~/.bashrcжҲ–vi /etc/bashrc,然еҗҺеңЁж–Ү件жң«е°ҫж·»еҠ
PATH="$PATH:/usr/local/mysql/bin"
export PATH
source /etc/bashrc
й—®йўҳ2пјҡ
Testing mysql connection and privileges..Warning: Using a password on the command line interface can be insecure.
ERROR 1045 (28000): Access denied for user 'root'@'mha2' (using password: YES)
и§ЈеҶіеҠһжі•пјҡ жҹҘзңӢз”ЁжҲ·иЎЁгҖӮ
RANT ALL PRIVILEGES ON *.* TO root@mha1 IDENTIFIED BY 'revenco123' WITH GRANT OPTION;
еҗҜеҠЁз®ЎзҗҶиҠӮзӮ№иҝӣзЁӢ
masterha_manager --conf=/etc/masterha/app1.cnf &
жіЁпјҡеҒңжӯўе’ҢеҗҜеҠЁMHAжңҚеҠЎпјҢдёҚеҪұе“ҚMySQLеҜ№еӨ–жҸҗдҫӣжңҚеҠЎгҖӮ
еҪ“MHAзҫӨйӣҶеҶ…зҡ„ж•°жҚ®еә“иҝӣиЎҢж•…йҡңиҪ¬з§»ж—¶пјҢеҜ№еӨ–жҸҗдҫӣжңҚеҠЎзҡ„иҷҡжӢҹIPд№ҹиҝӣиЎҢиҪ¬з§»пјӣжң¬е®һйӘҢжЎҲдҫӢйҖҡиҝҮдҪҝз”ЁKeepalived + LVSзҡ„ж–№жі•пјҢе®һзҺ°иҜ»еҶҷеҲҶзҰ»пјҢIPж•…йҡңйҖҸжҳҺиҪ¬з§»гҖӮ
еҶҷеҲҶзҰ»пјҢMasterе’ҢSlave1пјҲеӨҮз”ЁMasterпјүе…ұз”ЁдёҖдёӘеҶҷиҷҡжӢҹIPпјҢд»»дҪ•ж—¶еҲ»пјҢеҸӘиғҪжңүдёҖеҸ°жңәеҸҜеҶҷпјҢжӯЈеёёжғ…еҶөдёӢпјҢеҶҷж“ҚдҪңеңЁMasterжү§иЎҢпјҢеҪ“Master downжңәеҗҺпјҢMHAжҠҠSlave1пјҲеӨҮз”ЁMasterпјүжҸҗеҚҮдёәMasterпјҢжӯӨеҗҺпјҢSlave1пјҲеӨҮз”ЁMasterпјүеҸҜеҶҷпјҢеҪ“Masterдҝ®еӨҚиө·жқҘеҗҺпјҢе®ғжҲҗдёәSlaveпјҢд»Қ然жҳҜSlave1пјҲеӨҮз”ЁMasterпјүеҸҜеҶҷгҖӮйҷӨйқһдәәе·Ҙе№Ійў„пјҢе°Ҷдҝ®еӨҚеҗҺзҡ„MasterжҸҗеҚҮдёәMasterгҖӮ
иҜ»еҲҶзҰ»пјҢSlave1пјҲеӨҮз”ЁMasterпјүе’ҢSlave2 е…ұз”ЁдёҖдёӘиҜ»иҷҡжӢҹIPгҖӮйҮҮз”ЁLVSзҡ„иҪ®иҜўз®—жі•пјҢиҪ®жөҒи®ҝй—®Slave1пјҲеӨҮз”ЁMasterпјүе’ҢSlave2пјҢеҰӮжһңе…¶дёӯдёҖеҸ°дёҚеҸҜи®ҝй—®пјҢеҲҷи®ҝй—®еҸҰеӨ–дёҖеҸ°жңҚеҠЎеҷЁгҖӮ
жіЁж„ҸпјҡдёҖж—Ұдё»жңҚеҠЎеҷЁе®•жңәпјҢеӨҮд»ҪжңәеҚіејҖе§Ӣе……еҪ“masterжҸҗдҫӣжңҚеҠЎпјҢеҰӮжһңдё»жңҚеҠЎеҷЁдёҠзәҝд№ҹдёҚдјҡеҶҚжҲҗдёәmasterдәҶпјҢеӣ дёәеҰӮжһңиҝҷж ·ж•°жҚ®еә“зҡ„дёҖиҮҙжҖ§е°ұиў«ж”№еҸҳдәҶгҖӮ

еңЁMasterе’ҢSlave1(еӨҮд»ҪMaster)дёҠе®үиЈ…Keepalived
rpm -ivh openssl-devel-1.0.0-27.el6.x86_64
tar zxvf keepalived-1.2.13.tar.gz
cd keepalived-1.2.13
./configure --prefix=/usr/local/keepalived
зј–иҜ‘еҗҺзңӢеҲ°дёүдёӘyesжүҚз®—жҲҗеҠҹеҰӮжһңеҮәзҺ°дёӨдёӘyesжҲ–иҖ…дёҖдёӘеә”иҜҘиҰҒжЈҖжҹҘдёӢеҶ…ж ёиҪҜиҝһжҺҘеҒҡеҜ№дәҶжІЎжңүпјҡ
Use IPVS Framework : Yes #еҝ…йЎ»дёәYES
IPVS sync daemon support : Yes #еҝ…йЎ»дёәYES
IPVS use libnl : No
fwmark socket support : Yes
Use VRRP Framework : Yes #еҝ…йЎ»дёәYES
Use VRRP VMAC : Yes
make
make install
cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/
cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
mkdir -pv /etc/keepalived
cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
ln -s /usr/local/keepalived/sbin/keepalived /sbin/
service keepalived restart
ж•ҙдёӘMHAдҪҝз”Ёkeepalived зҡ„"HA + LVS"жЁЎејҸпјҢеңЁmha1е’Ңmha2 дёҠй…ҚзҪ® Keepalived HA жЁЎејҸпјҢеҚідёӢйқўд»Јз Ғзҡ„вҖңvrrp_instance VI_1вҖқе®һдҫӢз»„пјӣеңЁmha2е’Ңmha3 дёҠй…ҚзҪ® Keepalived LVS жЁЎејҸ,еҚідёӢйқўд»Јз Ғзҡ„вҖңvrrp_instance VI_2вҖқе®һдҫӢз»„гҖӮдёӨдёӘдё»жңәй…ҚзҪ®зҡ„йғҪжҳҜвҖңstate BACKUPвҖқпјҢдҪҶдјҳе…Ҳзә§priority дёҚеҗҢгҖӮй…ҚзҪ®еҰӮдёӢпјҡ
[root@mha1 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id mha1
}
vrrp_script check_mysql {
script "/usr/local/keepalived/bin/keepalived_check_mysql.sh"
interval 3
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_sync_group VG2 {
group {
VI_2
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco123
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.20
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco1234
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.21
}
}
virtual_server 192.168.0.21 80 {
delay_loop 6
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.0.12 80 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
real_server 192.168.0.13 80 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
}
}
[root@mha2 ~]# more /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id mha2
}
vrrp_script check_mysql {
script "/usr/local/keepalived/bin/keepalived_check_mysql.sh"
interval 3
}
vrrp_sync_group VG1 {
group {
VI_1
}
}
vrrp_sync_group VG2 {
group {
VI_2
}
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco123
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.20
}
}
vrrp_instance VI_2 {
state BACKUP
interface eth0
virtual_router_id 52
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass revenco1234
}
track_script {
check_mysql
}
virtual_ipaddress {
192.168.0.21
}
}
virtual_server 192.168.0.21 3306 {
delay_loop 6
lb_algo rr
lb_kind DR
protocol TCP
real_server 192.168.0.12 3306 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
real_server 192.168.0.13 3306 {
weight 3
TCP_CHECK {
connect_timeout 3
}
}
}
еңЁдёӨеҸ°Keepalivedдё»жңәдёҠпјҢй…ҚзҪ®жЈҖжөӢmysqlзҠ¶жҖҒи„ҡжң¬(дёӨеҸ°mysqlдёҖж ·зҡ„й…ҚзҪ®)пјҢи„ҡжң¬ж–Ү件иҰҒе®һзҺ°зҡ„еҠҹиғҪеӨ§дҪ“дёәпјҡеҸӘиҰҒжЈҖжөӢеҲ°mysqlжңҚеҠЎеҒңжӯўkeepalivedжңҚеҠЎд№ҹеҒңжӯў пјҢеӣ дёәkeepalivedжҳҜйҖҡиҝҮз»„ж’ӯж–№ејҸе‘ҠиҜүжң¬зҪ‘ж®өиҮӘе·ұиҝҳжҙ»зқҖеҪ“mysqlжңҚеҠЎеҒңжӯўеҗҺkeepalivedиҝҳдҫқ然иҝҗиЎҢ иҝҷж—¶е°ұйңҖиҰҒеҒңжӯўkeepalivedи®©еҸҰдёҖдёӘдё»жңәиҺ·еҫ—иҷҡжӢҹIPпјҢеҸҜд»ҘеңЁеҗҺеҸ°иҝҗиЎҢиҝҷдёӘи„ҡжң¬ д№ҹеҸҜд»ҘеңЁkeepalivedй…ҚзҪ®ж–Ү件еҠ е…ҘиҝҷдёӘи„ҡжң¬пјҢжң¬е®һйӘҢжҠҠиҜҘи„ҡжң¬й…ҚзҪ®еңЁkeepalivedй…ҚзҪ®ж–Ү件дёӯгҖӮ
и„ҡжң¬ж–Ү件еҗҚпјҡ /usr/local/keepalived/bin/keepalived_check_mysql.sh
#!/bin/bash
MYSQL=/usr/local/mysql/bin/mysql
MYSQL_HOST=localhost
MYSQL_USER=root
MYSQL_PASSWORD=revenco123
CHECK_TIME=3
#mysql is working MYSQL_OK is 1 , mysql down MYSQL_OK is 0
MYSQL_OK=1
function check_mysql_helth (){
$MYSQL -h $MYSQL_HOST -u$MYSQL_USER -p$MYSQL_PASSWORD -e "show status;" >/dev/null 2>&1
if [ $? = 0 ] ;then
MYSQL_OK=1
else
MYSQL_OK=0
fi
return $MYSQL_OK
}
while [ $CHECK_TIME -ne 0 ]
do
let "CHECK_TIME -= 1"
check_mysql_helth
if [ $MYSQL_OK = 1 ] ; then
CHECK_TIME=0
exit 0
fi
if [ $MYSQL_OK -eq 0 ] && [ $CHECK_TIME -eq 0 ]
then
/etc/init.d/keepalived stop
exit 1
fi
sleep 1
done
дҪҝз”ЁLVSжҠҖжңҜиҰҒиҫҫеҲ°зҡ„зӣ®ж ҮжҳҜпјҡйҖҡиҝҮLVSжҸҗдҫӣзҡ„иҙҹиҪҪеқҮиЎЎжҠҖжңҜе’ҢLinuxж“ҚдҪңзі»з»ҹе®һзҺ°дёҖдёӘй«ҳжҖ§иғҪгҖҒй«ҳеҸҜз”Ёзҡ„жңҚеҠЎеҷЁзҫӨйӣҶпјҢе®ғе…·жңүиүҜеҘҪеҸҜйқ жҖ§гҖҒеҸҜжү©еұ•жҖ§е’ҢеҸҜж“ҚдҪңжҖ§гҖӮд»ҺиҖҢд»ҘдҪҺе»үзҡ„жҲҗжң¬е®һзҺ°жңҖдјҳзҡ„жңҚеҠЎжҖ§иғҪгҖӮжң¬е®һйӘҢйҖҡиҝҮдҪҝз”ЁLVSиҪҜ件пјҢеңЁSlave1пјҲеӨҮз”ЁMasterпјүе’ҢSlave2дёҠе®һзҺ°иҜ»иҙҹиҪҪеқҮиЎЎгҖӮ
Keepalived йҷ„еёҰдәҶLVSзҡ„еҠҹиғҪпјҢеӣ жӯӨLVSжңҚеҠЎеҷЁз«Ҝзҡ„й…ҚзҪ®жҳҜзӣҙжҺҘеңЁKeepalivedзҡ„й…ҚзҪ®ж–Ү件дёӯй…ҚзҪ®зҡ„пјҢKeepalivedзҡ„й…ҚзҪ®ж–Ү件зҡ„вҖңvirtual_serverвҖқйғЁеҲҶзҡ„й…ҚзҪ®пјҢдҫҝжҳҜLVSзҡ„й…ҚзҪ®гҖӮе…·дҪ“иҜ·жҹҘзңӢKeepalivedзҡ„й…ҚзҪ®ж–Ү件зҡ„вҖңvirtual_serverвҖқйғЁеҲҶгҖӮ
еңЁжң¬е®һйӘҢжЎҲдҫӢдёӯпјҢLVSзҡ„зңҹе®һжңәжҳҜSlave1пјҲеӨҮз”ЁMasterпјүе’ҢSlave2
еңЁlvsзҡ„DRе’ҢTUnжЁЎејҸдёӢпјҢз”ЁжҲ·зҡ„и®ҝй—®иҜ·жұӮеҲ°иҫҫзңҹе®һжңҚеҠЎеҷЁеҗҺпјҢжҳҜзӣҙжҺҘиҝ”еӣһз»ҷз”ЁжҲ·зҡ„пјҢиҖҢдёҚеҶҚз»ҸиҝҮеүҚз«Ҝзҡ„Director ServerпјҢеӣ жӯӨпјҢе°ұйңҖиҰҒеңЁжҜҸдёӘReal serverиҠӮзӮ№дёҠеўһеҠ иҷҡжӢҹзҡ„VIPең°еқҖпјҢиҝҷж ·ж•°жҚ®жүҚиғҪзӣҙжҺҘиҝ”еӣһз»ҷз”ЁжҲ·пјҢеўһеҠ VIPең°еқҖзҡ„ж“ҚдҪңеҸҜд»ҘйҖҡиҝҮеҲӣе»әи„ҡжң¬зҡ„ж–№ејҸжқҘе®һзҺ°пјҢеҲӣе»әж–Ү件/etc/init.d/lvsrsпјҢи„ҡжң¬еҶ…е®№еҰӮдёӢ
[root@mha3 ~]# more /etc/init.d/lvsrs
#!/bin/bash
#description : Start Real Server
VIP=192.168.0.21
. /etc/rc.d/init.d/functions
case "$1" in
start)
echo " Start LVS of Real Server"
/sbin/ifconfig lo:0 $VIP broadcast $VIP netmask 255.255.255.255 up
echo "1" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
stop)
/sbin/ifconfig lo:0 down
echo "close LVS Director server"
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/lo/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
;;
*)
echo "Usage: $0 {start|stop}"
exit 1
esac
vim /etc/iptables
/etc/init.d/iptables restart
# е…Ғи®ёvrrpеҚҸи®®йҖҡиҝҮ
пјҲ1пјү. еҗҜеҠЁmha1,mha2зҡ„keepalivedпјҢи®ҝй—®дёӨдёӘVIPжүҖи®ҝй—®зҡ„дё»жңәгҖӮ
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha1пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ2пјү. е…ій—ӯmha1зҡ„keepalived
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha2пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ3пјү. еҶҚеҗҜеҠЁmha1зҡ„keepalived
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha2пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ4пјү. е…ій—ӯmha2зҡ„keepalived
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha1пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ5пјү. еҶҚеҗҜеҠЁmha2зҡ„keepalived
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha1пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ6пјү. йҮҚеӨҚдёҖж¬ЎвҖң1--5вҖқжӯҘйӘӨгҖӮ
жөӢиҜ•з»“жһңпјҡжөӢиҜ•з»“жһңзӣёеҗҢгҖӮ
пјҲ7пјү. еҗҢж—¶е…ій—ӯmha1,mha2зҡ„keepalived
жөӢиҜ•з»“жһңпјҡдёӨдёӘVIPйғҪдёҚиғҪи®ҝй—®гҖӮ
жөӢиҜ•зҡ„жңҚеҠЎдёәhttpd:
пјҲжІЎжңүеҠ и„ҡжң¬пјҢи®©httpdжңҚеҠЎеҷЁеҒңжӯўпјҢkeepalivedжңҚеҠЎд№ҹеҒңжӯўгҖӮеҰӮжһңжҳҜMysqlжңҚеҠЎеҷЁжҳҜжңүзӣёеә”зҡ„и„ҡжң¬зҡ„пјү
пјҲ1пјү. еҗҜеҠЁmha1,mha2зҡ„keepalived е’ҢhttpdжңҚеҠЎпјҢи®ҝй—®дёӨдёӘVIPжүҖи®ҝй—®зҡ„дё»жңәгҖӮ
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha1пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ2пјү. е…ій—ӯmha1зҡ„httpd
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha2пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ3пјү. еҶҚеҗҜеҠЁmha1зҡ„httpd
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢи®ҝй—®mha2пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ4пјү. е…ій—ӯmha2зҡ„httpd
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢж— жі•и®ҝй—®пјӣеҜ№дәҺVIP2пјҢи®ҝй—®mha3гҖӮ
пјҲеә”иҜҘеңЁkeepaliveдёӯе®ҡжңҹжЈҖжөӢhttpdжңҚеҠЎпјҢhttpdжңҚеҠЎеҒңжӯўпјҢйӮЈд№ҲkeepalivedжңҚеҠЎд№ҹеҒңжӯўпјҢи®©mha1дҪңдёәMasterпјҢйӮЈж ·VIP1е°ұеҸҜд»Ҙи®ҝй—®mha1пјҢиҖҢдёҚжҳҜзҺ°еңЁзҡ„вҖңж— жі•и®ҝй—®вҖқпјү
пјҲ5пјү. еҶҚеҗҜеҠЁmha2зҡ„httpd
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1пјҢжҒўеӨҚи®ҝй—®mha2пјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ6пјү. е…ій—ӯmha3зҡ„httpd
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1 ж— д»»дҪ•еҪұе“ҚпјӣеҜ№дәҺVIP2пјҢи®ҝй—®mha2гҖӮ
пјҲ7пјү. еҶҚеҗҜеҠЁmha3зҡ„httpd
жөӢиҜ•з»“жһңпјҡеҜ№дәҺVIP1 ж— д»»дҪ•еҪұе“ҚпјӣеҜ№дәҺVIP2пјҢиҪ®жөҒи®ҝй—®mha2е’Ңmha3гҖӮ
пјҲ8пјү. еҗҢж—¶е…ій—ӯmha1,mha2зҡ„httpd
жөӢиҜ•з»“жһңпјҡдёӨдёӘVIPйғҪдёҚиғҪи®ҝй—®гҖӮ
пјҲ1пјүе…ҲдҪҝз”Ёmha-w-vip иҝһжҺҘеҲ°mhaйӣҶзҫӨпјҢжҹҘзңӢжүҖиҝһжҺҘзҡ„ж•°жҚ®еә“дё»жңәдҝЎжҒҜгҖӮ
mysql -uroot -ptest123 -h 172.20.52.252
use mysql
select host,user,password from user;
пјҲ2пјүе…ій—ӯеҪ“еүҚзҡ„master зҡ„mysqlжңҚеҠЎгҖӮ
пјҲ3пјүжҹҘзңӢmha-w-vip(еҶҷVIP) иҝһжҺҘжҳҜеҗҰеҸҜиҝһжҺҘеҲ°mhaйӣҶзҫӨпјҢеҪ“еүҚиҝһжҺҘжҳҜеҗҰж–ӯжҺүгҖӮ
пјҲ4пјүжөӢиҜ•з»“жһңпјҡеҒңжӯўmasterдёҠзҡ„mysqlжңҚеҠЎеҗҺпјҢ3з§’еҶ…иҝӣиЎҢеҲҮжҚў "еҶҷVIP"гҖӮеҪ“masterдёҠзҡ„mysqlжңҚеҠЎdownеҗҺпјҢеӨҮз”ЁmasterжҲҗдёәmasterпјҢйӣҶзҫӨеҸҜз”ЁгҖӮеҪ“еҺҹmasterжҒўеӨҚеҗҺпјҢйңҖиҰҒжүӢе·ҘжҠҠе®ғеҲҮжҚўеҲ°еӨҚеҲ¶зҠ¶жҖҒгҖӮ
еҸӘиғҪеҒҡеҲ°иҝһжҺҘзҡ„й«ҳеҸҜз”ЁжҖ§пјҢеҒҡдёҚеҲ°дјҡиҜқзә§еҲ«зҡ„й«ҳеҸҜз”ЁжҖ§гҖӮеҚіпјҢdownеҗҺпјҢеҺҹжңүзҡ„дјҡиҜқе°Ҷж–ӯејҖпјҢ然еҗҺ马дёҠйҮҚж–°иҝһжҺҘгҖӮ
иҪ®жөҒеҒңжӯўеӨҮз”Ёmasterе’ҢгҖҒslaveпјҢ然еҗҺдҪҝз”ЁиҜ»vipиҝһжҺҘеҗҺпјҢжҹҘзңӢеҪ“еүҚжүҖиҝһжҺҘзҡ„еә“зҡ„дё»жңәдҝЎжҒҜгҖӮ
пјҲ1пјүе…ҲдҪҝз”Ёmha-r-vip (иҜ»VIP)иҝһжҺҘеҲ°mhaйӣҶзҫӨпјҢжҹҘзңӢжүҖиҝһжҺҘзҡ„ж•°жҚ®еә“дё»жңәдҝЎжҒҜгҖӮ
mysql -uroot -ptest -h 172.20.52.253
use mysql
select host,user,password from user;
пјҲ2пјүжү“ејҖеӨҡдёӘдјҡиҜқпјҢйҮҚеӨҚдёҠдёҖжӯҘгҖӮ
пјҲ3пјүжҹҘзңӢеҗ„дёӘдјҡиҜқжҳҜиҝһжҺҘеҲ°е“ӘдёӘдё»жңәдёҠгҖӮ
пјҲ4пјүжөӢиҜ•з»“жһңпјҡеӨҮз”ЁmasterгҖҒslaveйғҪеңЁзәҝж—¶пјҢиҪ®жөҒи®ҝй—®гҖӮ
пјҲ1пјүе…ҲдҪҝз”Ёmha-r-vip (иҜ»VIP)иҝһжҺҘеҲ°mhaйӣҶзҫӨпјҢжҹҘзңӢжүҖиҝһжҺҘзҡ„ж•°жҚ®еә“дё»жңәдҝЎжҒҜгҖӮ
mysql -uroot -ptest123 -h mha1-r-vip
use mysql
select host,user,password from user;
пјҲ2пјүиҪ®жөҒеҒңжӯўеӨҮз”Ёmasterе’ҢslaveпјҢ然еҗҺдҪҝз”ЁиҜ»vipиҝһжҺҘеҗҺпјҢжҹҘзңӢеҪ“еүҚжүҖиҝһжҺҘзҡ„еә“зҡ„дё»жңәдҝЎжҒҜгҖӮ
пјҲ3пјүжөӢиҜ•з»“жһңпјҡеӨҮз”ЁmasterгҖҒslaveд»»дҪ•дёҖеҸ°зҡ„mysqlжңҚеҠЎdownжҺүпјҢйӣҶзҫӨйғҪеҸҜиҜ»гҖӮ
еңЁдё»еә“дёҠжү§иЎҢеҲӣе»әеә“гҖҒиЎЁгҖҒ并жҸ’е…Ҙж•°жҚ®пјҢжҹҘзңӢеӨҮз”Ёmasterе’Ңslaveзҡ„ж•°жҚ®еҗҢжӯҘжғ…еҶөгҖӮ
пјҲ1пјүеңЁдё»еә“дёҠжү§иЎҢеҲӣе»әеә“гҖҒиЎЁгҖҒ并жҸ’е…Ҙж•°жҚ®
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql> create table t1 (id int ,name varchar(20));
ERROR 1046 (3D000): No database selected
mysql> use test;
Database changed
mysql> create table t1 (id int ,name varchar(20));
Query OK, 0 rows affected (0.04 sec)
mysql> insert into t1 values (1,'a');
Query OK, 1 row affected (0.02 sec)
mysql> insert into t1 values (2,'b');
пјҲ2пјүзҷ»еҪ•еӨҮеә“пјҢжҹҘзңӢж•°жҚ®
Use test
Select * from t1;
(3)жөӢиҜ•з»“жһңпјҡ
еӨҮз”Ёmaster slaveйғҪиғҪ马дёҠиҮӘеҠЁеҗҢжӯҘж•°жҚ®гҖӮ(еҗҺеҸ°еңЁжҜ«з§’зә§еҲ«дёҠе®ҢжҲҗеҗҢжӯҘ)
жөӢиҜ•жҠҠеӨҮз”Ёmasterе’Ңslaveи®ҫзҪ®дёәread_onlyеҗҺпјҢж•ҲжһңеҰӮдҪ•
пјҲ1пјүи®ҫзҪ®дёәеҸӘиҜ»
set global read_only=1;
пјҲ2пјүзҷ»еҪ•е№¶жҸ’е…Ҙж•°жҚ®
Mysql вҖ“uroot вҖ“prtest123 вҖ“D test
Insert into t1 values(1,вҖҷaвҖҷ);
жҸ’е…ҘжҲҗеҠҹ
пјҲ3пјүеҲӣе»әжҷ®йҖҡз”ЁжҲ·
GRANT ALL ON test.* TO test@'%' IDENTIFIED BY 'test' WITH GRANT OPTION;
GRANT ALL ON test* TO test@localhost IDENTIFIED BY 'test' WITH GRANT OPTION;
пјҲ3пјүзҷ»еҪ•е№¶жҸ’е…Ҙж•°жҚ®
Mysql вҖ“utestвҖ“ptestвҖ“D test
Insert into t1 values(1,вҖҷaвҖҷ);
жҸ’е…ҘеӨұиҙҘ
пјҲ4пјүжөӢиҜ•з»“жһңпјҡread_onlyеҜ№superз”ЁжҲ·ж— еҪұе“ҚпјҢеҜ№жҷ®йҖҡз”ЁжҲ·иғҪиө·еҲ°йҷҗеҲ¶дҪңз”ЁгҖӮ
дё»еә“
mysql -utest-ptest-D test
insert into t1 values(3,'c');
еӨҮз”ЁmasterгҖҒslaveжҹҘиҜўпјҡ
select * from t1;
жөӢиҜ•
еӨҮз”ЁmasterгҖҒslaveжҸ’е…Ҙпјҡ
mysql -utest -ptest -D test
insert into t1 values(4,'d');
ERROR 1290 (HY000): The MySQL server is running with the --read-only option so it cannot execute this statement
з»“и®әпјҡеңЁеӨҮз”ЁmasterгҖҒslaveи®ҫзҪ®еҸӘиҜ»пјҢеҸҜйҷҗеҲ¶еӨҮз”ЁmasterгҖҒslaveзҡ„еҶҷеҠҹиғҪпјҢ并且дёҚеҪұе“Қдё»д»ҺеӨҚеҲ¶еҠҹиғҪгҖӮ
еҺҹmasterжҒўеӨҚеҗҺпјҢеҰӮжһңжғіи®©еҺҹmasterпјҲmha1пјүдёҖзӣҙдёәslaveпјҢйңҖиҰҒеҒҡд»ҘдёӢпјҡ
1). йңҖиҰҒжӣҙж”№mha managerж–Ү件дёӯmha1зҡ„йЎәеәҸгҖӮ
2). еҲ йҷӨ rm /var/log/masterha/app1/app1.failover.complete
3). еҶҚж¬ЎеҗҜеҠЁmha managerиҝӣзЁӢ
4). и®©mha2зҡ„keepalivedдёәHA зҡ„MasterпјҢmha1дёә"BACKUP"зҠ¶жҖҒпјҢдҝқиҜҒвҖңеҶҷvipвҖқжҳҜе…іиҒ”еҲ°MasterдёҠзҡ„гҖӮ
5). дҝ®ж”№иҜ»VIPгҖӮиҜ»VIPдёәmha1гҖҒmha3пјҲеҺҹmha2гҖҒmha3пјү
6). и®ҫзҪ®еҺҹmasterпјҲmha1пјүдёәread_only
7). жЈҖжҹҘ show slave status \G; show master status;
еҺҹmasterжҒўеӨҚеҗҺпјҢеҰӮжһңжғіи®©еҺҹmasterпјҲmha1пјүйҮҚж–°жҲҗдёәMasterпјҢйңҖиҰҒеҒҡд»ҘдёӢпјҡ
1). еңЁmha managerдёҠпјҢжүӢе·ҘжҠҠmha1еҲҮжҚўдёәMasterгҖӮ
2). и®ҫзҪ®еӨҮз”ЁmasterпјҲmha2пјүдёәread_only.
3). еҲ йҷӨ rm /var/log/masterha/app1/app1.failover.complete
4). йҮҚж–°еҗҜеҠЁmha managerиҝӣзЁӢгҖӮ
5). и®©mha1зҡ„keepalivedдёәHA зҡ„MasterпјҢmha2дёә"BACKUP"зҠ¶жҖҒпјҢдҝқиҜҒвҖңеҶҷvipвҖқжҳҜе…іиҒ”еҲ°MasterдёҠзҡ„гҖӮ
6). жЈҖжҹҘ show slave status \G; show master status;
пјҲ1пјү.еҒңжӯўmaster_managerиҝӣзЁӢпјҡmasterha_stop --conf=/etc/app1.cnf
пјҲ2пјү.жү§иЎҢеҲҮжҚўе‘Ҫд»ӨпјҢеҸҜж №жҚ®йңҖиҰҒжү§иЎҢдҪҝз”ЁдёҚеҗҢзҡ„еҸӮж•°гҖӮ
дё»еә“downзҡ„жғ…еҶө
masterha_master_switch --master_state=dead --conf=/etc/conf/masterha/app1.cnf --dead_master_host=mha2
йқһдәӨдә’ејҸж•…йҡңиҪ¬з§»
masterha_master_switch --master_state=dead --conf=/etc/conf/masterha/app1.cnf --dead_master_host=mha2 --new_master_host=mha1 --interactive=0
еңЁзәҝеҲҮжҚўпјҢеҲҮжҚўеҗҺеҺҹжқҘзҡ„дё»еә“дёҚиҰҒ
masterha_master_switch --master_state=alive --conf=/etc/masterha/app1.cnf --new_master_host=mha1
еңЁзәҝеҲҮжҚўпјҢеҲҮжҚўеҗҺеҺҹжқҘзҡ„дё»еә“еҸҳжҲҗд»Һеә“
masterha_master_switch --master_state=alive --conf=/etc/masterha/app1.cnf --new_master_host=mha1 --orig_master_is_new_slave
еҜјеҮәпјҡ
mysqldump -uroot -p123456 test > test_20140704.sql
еҜје…Ҙпјҡ
mysql -uroot -ptest123 test< test_20140704.sql
жөӢиҜ•з»“жһңпјҡеңЁдё»еә“жү§иЎҢеҜје…ҘпјҢд»Һеә“иҮӘеҠЁеҗҢжӯҘж•°жҚ®гҖӮ
еңЁMasterдёҠеҲӣе»әеӯҳеӮЁиҝҮзЁӢ`f_test`пјҢ然еҗҺеңЁеӨҮз”Ёmasterе’ҢslaveдёҠеҲӣе»әпјҢеҰӮжһңжҸҗзӨәеӯҳеӮЁиҝҮзЁӢе·ІеӯҳеңЁпјҢеҲҷиҜҙжҳҺеҲӣе»әеӯҳеӮЁиҝҮзЁӢд№ҹдјҡеҗҢжӯҘеҲ°еӨҮз”Ёmasterе’ҢslaveгҖӮ
DELIMITER $$
CREATE DEFINER=`root`@`%` PROCEDURE `f_test`(
IN p_id int,
IN p_name varchar(20)
)
begin
insert into t1 values(p_id,p_name);
END;
$$
DELIMITER ;
жөӢиҜ•з»“жһңпјҡеҲӣе»әеӯҳеӮЁиҝҮзЁӢд№ҹдјҡеҗҢжӯҘеҲ°еӨҮз”Ёmasterе’ҢslaveгҖӮ
еңЁmasterдёҠжү§иЎҢ
call f_test(4,'d');(f_testзҡ„еҠҹиғҪжҳҜжҸ’е…ҘдёҖжқЎи®°еҪ•еҲ°t1пјү
жҹҘиҜўselect * from t1;
еңЁеӨҮз”Ёmasterе’ҢslaveжҹҘиҜўselect * from t1;
ж•°жҚ®дёҺMasterдёҠдёҖиҮҙпјҢеӯҳеӮЁиҝҮзЁӢеҶ…дҝ®ж”№ж•°жҚ®дјҡеҗҢжӯҘгҖӮ
жөӢиҜ•з»“жһңпјҡеӯҳеӮЁиҝҮзЁӢеҶ…дҝ®ж”№ж•°жҚ®дјҡеҗҢжӯҘгҖӮ
mysqlдё»д»ҺеӨҚеҲ¶пјҢз»ҸеёёдјҡйҒҮеҲ°й”ҷиҜҜиҖҢеҜјиҮҙslaveз«ҜеӨҚеҲ¶дёӯж–ӯпјҢиҝҷдёӘж—¶еҖҷдёҖиҲ¬е°ұйңҖиҰҒдәәе·Ҙе№Ійў„пјҢи·іиҝҮй”ҷиҜҜжүҚиғҪ继з»ӯгҖӮи·іиҝҮй”ҷиҜҜжңүдёӨз§Қж–№ејҸпјҡ
mysql> stop slave;
mysql>SET GLOBAL SQL_SLAVE_SKIP_COUNTER = 1 #и·іиҝҮдёҖдёӘдәӢеҠЎ
mysql>slave start
йҖҡиҝҮslave_skip_errorsеҸӮж•°жқҘи·іжүҖжңүй”ҷиҜҜжҲ–жҢҮе®ҡзұ»еһӢзҡ„й”ҷиҜҜ
vi /etc/my.cnf
[mysqld]
#slave-skip-errors=1062,1053,1146 #и·іиҝҮжҢҮе®ҡerror noзұ»еһӢзҡ„й”ҷиҜҜ
#slave-skip-errors=all #и·іиҝҮжүҖжңүй”ҷиҜҜ
Mysql еҜ№еҮҪж•°зҡ„еҗҢжӯҘжңүйҷҗеҲ¶гҖӮеҸӘжңүиў«жҳҺзЎ®еЈ°жҳҺдёәDETERMINISTICжҲ–NO SQL жҲ–READS SQL DATAзҡ„еҮҪж•°пјҢжүҚеҸҜд»ҘеҲӣе»әпјҢ并еҸҜиҮӘеҠЁеҗҢжӯҘеҲ°д»Һеә“пјҢеҗҰеҲҷеҲӣе»әеҮҪж•°дјҡеӨұиҙҘгҖӮеҸҜд»ҘйҖҡиҝҮи®ҫзҪ®еҸӮж•°вҖңset global log_bin_trust_function_creators = 1вҖқпјҢдҪҝеҫ—еҮҪж•°иғҪеҲӣе»әжҲҗеҠҹпјҢ并еҗҢжӯҘеҲ°д»Һеә“гҖӮжӯӨеҸӮж•°еҸӘжңүеңЁејҖеҗҜlog-binзҡ„жғ…еҶөдёӢжүҚжңүз”ЁгҖӮlog_bin_trust_function_creators=0зҡ„жғ…еҶөдёӢпјҢйңҖиҰҒжңүSUPERжқғйҷҗпјҢ并且дёҚеҢ…еҗ«дҝ®ж”№ж•°жҚ®зҡ„SQL,жүҚиғҪеҲӣе»әеҮҪж•°гҖӮ
пјҲ1пјүжөӢиҜ•жӯЈеёёдё»д»ҺеӨҚеҲ¶жғ…еҶөдёӢпјҢеҮҪж•°зҡ„еҲӣе»ә
mysql> set global log_bin_trust_function_creators = 1;
CREATE DEFINER = 'root'@'%' FUNCTION f_test2
(
pid int
)
RETURNS int(11)
BEGIN
insert into t1 values (pid,sysdate());
RETURN 1;
END
жөӢиҜ•з»“жһңпјҡеңЁдё»д»ҺзҺҜеўғдёӢпјҢеҰӮжһңеҮҪж•°жІЎжңүеЈ°жҳҺDETERMINISTICжҲ–NO SQL жҲ–READS SQL DATAпјҢеҲӣе»әеҮҪж•°еӨұиҙҘгҖӮ
пјҲ2пјүејәиЎҢеЈ°жҳҺдёәDETERMINISTICжҲ–NO SQL жҲ–READS SQL DATAзҡ„еҮҪж•°жөӢиҜ•
CREATE DEFINER = 'root'@'%' FUNCTION f_test2
(
pid int
)
RETURNS int(11)
DETERMINISTIC
BEGIN
insert into t1 values (pid,sysdate());
RETURN 1;
END
жөӢиҜ•з»“жһңпјҡеҸҜд»ҘеҲӣе»әжҲҗеҠҹпјҢ并且еҸҜеҗҢжӯҘеҲ°д»Һеә“гҖӮдҪҶж— жі•жү§иЎҢиҜҘеҮҪж•°пјҢжү§иЎҢж—¶жҠҘй”ҷгҖӮ
пјҲ3пјүжҠҠglobal log_bin_trust_function_creators = 1еҗҺпјҢдёҚеЈ°жҳҺеҮҪж•°зҡ„дёәDETERMINISTICжҲ–NO SQL жҲ–READS SQL DATAеұһжҖ§гҖӮ
mysql> set global log_bin_trust_function_creators = 0;
еҲӣе»әеҮҪж•°жҲҗеҠҹпјҢд№ҹеҸҜд»ҘеҗҢжӯҘеҲ°д»Һеә“пјҲејҖеҗҜbin-logзҡ„д»Һеә“еҝ…йЎ»еҒҡеҗҢж ·зҡ„еҸӮж•°й…ҚзҪ®пјүгҖӮ
еңЁдё»еә“жү§иЎҢеҮҪж•°
mysql> select f_test2(7);
mysql> select * from t1;
еңЁдё»еә“зҡ„t1иЎЁжңүжҸ’е…Ҙи®°еҪ•пјҢ并且жңүеҗҢжӯҘеҲ°д»Һеә“гҖӮ
binlog_format = STATEMEN зҡ„жғ…еҶөдёӢпјҡ
еҲӣе»әеӯҳеӮЁиҝҮзЁӢp_test1пјҢиҮӘеҠЁеҗҢжӯҘеҲ°д»Һеә“пјҢ并дёҚйңҖиҰҒвҖңset global log_bin_trust_function_creators = 1;вҖқпјҢз”ұжӯӨзңӢеҮәпјҢеӯҳеӮЁиҝҮзЁӢзҡ„еӨҚеҲ¶ж—¶е®үе…Ёзҡ„пјӣжү§иЎҢcall p_test1пјҲ14пјү;ж•°жҚ®е®Ңе…ЁеҗҢжӯҘеҲ°д»Һеә“гҖӮеҰӮжһңжҳҜеҮҪж•°пјҢ并дёҚе®Ңе…ЁеҗҢжӯҘпјҢsysdate()иҺ·еҸ–зҡ„еҖјдёҚеҗҢгҖӮ
p_test1д»Јз Ғпјҡ
DELIMITER |
CREATE DEFINER = 'root'@'%' PROCEDURE p_test1
(
pid int
)
BEGIN
declare v_time datetime;
set v_time = sysdate();
insert into t1 values (pid,v_time);
END|
DELIMITER ;
жөӢиҜ•з»“жһңпјҡз»“еҗҲеҮҪж•°еҗҢжӯҘзҡ„жөӢиҜ•жғ…еҶөпјҢеҸҜеҫ—еҮәпјҡ
еңЁbinlog_format = STATEMENзҡ„жғ…еҶөдёӢпјҢжү§иЎҢеӯҳеӮЁиҝҮзЁӢж—¶пјҢеҗҺеҸ°йҮҮз”Ёbinlog_format =ROWзҡ„ж–№ејҸеҗҢжӯҘж—Ҙеҝ—пјӣиҖҢжү§иЎҢеҮҪж•°ж—¶пјҢеҗҺеҸ°йҮҮз”Ёbinlog_format =STATEMENзҡ„ж–№ејҸеҗҢжӯҘж—Ҙеҝ—гҖӮ
пјҲ1пјүжҹҘзңӢsshзҷ»йҷҶжҳҜеҗҰжҲҗеҠҹ
masterha_check_ssh --conf=/etc/masterha/app1.cnf
пјҲ2пјүжҹҘзңӢеӨҚеҲ¶жҳҜеҗҰе»әз«ӢеҘҪ
masterha_check_repl --conf=/etc/masterha/app1.cnf
пјҲ3пјүеҗҜеҠЁmha
nohup masterha_manager --conf=/etc/masterha/app1.cnf > /tmp/mha_manager.log < /dev/null 2>&1 &
еҪ“жңүslaveиҠӮзӮ№е®•жҺүзҡ„жғ…еҶөжҳҜеҗҜеҠЁдёҚдәҶзҡ„пјҢеҠ дёҠ--ignore_fail_on_startеҚідҪҝжңүиҠӮзӮ№е®•жҺүд№ҹиғҪеҗҜеҠЁmha
nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_fail_on_start > /tmp/mha_manager.log < /dev/null 2>&1 &
пјҲ4пјүжЈҖжҹҘеҗҜеҠЁзҡ„зҠ¶жҖҒ
masterha_check_status --conf=/etc/masterha/app1.cnf
пјҲ5пјүеҒңжӯўmha
masterha_stop --conf=/etc/masterha/app1.cnf
пјҲ6пјүfailoverеҗҺдёӢж¬ЎйҮҚеҗҜ
жҜҸж¬ЎfailoverеҲҮжҚўеҗҺдјҡеңЁз®ЎзҗҶзӣ®еҪ•з”ҹжҲҗж–Ү件app1.failover.complete пјҢдёӢж¬ЎеңЁеҲҮжҚўзҡ„ж—¶еҖҷдјҡеҸ‘зҺ°жңүиҝҷдёӘж–Ү件еҜјиҮҙеҲҮжҚўдёҚжҲҗеҠҹпјҢйңҖиҰҒжүӢеҠЁжё…зҗҶжҺүгҖӮ
rm -rf /masterha/app1/app1.failover.complete
д№ҹеҸҜд»ҘеҠ дёҠеҸӮж•°--ignore_last_failover
пјҲ7пјүжүӢеҠЁеңЁзәҝеҲҮжҚў
1пјү.жүӢеҠЁеҲҮжҚўж—¶йңҖиҰҒе°ҶеңЁиҝҗиЎҢзҡ„mhaеҒңжҺүеҗҺжүҚиғҪеҲҮжҚўгҖӮеҸҜд»ҘйҖҡиҝҮеҰӮдёӢе‘Ҫд»ӨеҒңжӯўmha
masterha_stop --conf=/etc/app1.cnf
2пјү.жү§иЎҢеҲҮжҚўе‘Ҫд»Ө
жүӢе·ҘfailoverеңәжҷҜпјҢmasterжӯ»жҺүпјҢдҪҶжҳҜmasterha_managerжІЎжңүејҖеҗҜпјҢеҸҜд»ҘйҖҡиҝҮжүӢе·Ҙfailoverпјҡ
masterha_master_switch --master_state=dead --conf=/etc/app1.cnf --dead_master_host=host1 --new_master_host=host5
жҲ–иҖ…
masterha_master_switch --conf=/etc/app1.cnf --master_state=alive --new_master_host=host1 --orig_master_is_new_slave
жҲ–иҖ…
masterha_master_switch --conf=/etc/app1.cnf --master_state=alive --new_master_host=host1 --orig_master_is_new_slave --running_updates_limit=10000 --interactive=0
еҸӮж•°и§ЈйҮҠ
--orig_master_is_new_slaveеҲҮжҚўж—¶еҠ дёҠжӯӨеҸӮж•°жҳҜе°ҶеҺҹmasterеҸҳдёәslaveиҠӮзӮ№пјҢеҰӮжһңдёҚеҠ жӯӨеҸӮж•°пјҢеҺҹжқҘзҡ„masterе°ҶдёҚеҗҜеҠЁпјҢйңҖиҰҒи®ҫзҪ®еңЁй…ҚзҪ®ж–Ү件дёӯй…ҚзҪ®repl_user гҖҒrepl_passwordеҸӮж•° гҖӮ
--running_updates_limit=10000 еҲҮжҚўж—¶еҖҷйҖүmasterеҰӮжһңжңү延иҝҹзҡ„иҜқпјҢmhaеҲҮжҚўдёҚиғҪжҲҗеҠҹпјҢеҠ дёҠжӯӨеҸӮж•°иЎЁзӨә延иҝҹеңЁжӯӨж—¶й—ҙиҢғеӣҙеҶ…йғҪеҸҜеҲҮжҚўпјҲеҚ•дҪҚдёәsпјүпјҢдҪҶжҳҜеҲҮжҚўзҡ„ж—¶й—ҙй•ҝзҹӯжҳҜз”ұrecoverж—¶relayж—Ҙеҝ—зҡ„еӨ§е°ҸеҶіе®ҡгҖӮ
--interactive=0пјҢеҲҮжҚўж—¶жҳҜеҗҰдә’дәӨпјҢй»ҳи®ӨжҳҜдә’дәӨзҡ„гҖӮдә’дәӨзҡ„ж„ҸжҖқе°ұжҳҜиҰҒдҪ йҖүжӢ©дёҖдәӣйҖүйЎ№пјҢеҰӮж №жҚ®жҸҗзӨәиҫ“е…ҘвҖңyes or noвҖқгҖӮ
--master_state=alive masterеңЁзәҝеҲҮжҚўпјҢйңҖиҰҒеҰӮдёӢжқЎд»¶,第дёҖпјҢеңЁжүҖжңүslaveдёҠIOзәҝзЁӢиҝҗиЎҢпјӣ第дәҢпјҢSQLзәҝзЁӢеңЁжүҖжңүзҡ„slaveдёҠжӯЈеёёиҝҗиЎҢпјӣ第дёүпјҢеңЁжүҖжңүзҡ„slavesдёҠ Seconds_Behind_Master иҰҒе°ҸдәҺзӯүдәҺ running_updates_limit secondsпјӣ第еӣӣпјҢеңЁmasterдёҠпјҢеңЁshow processlistиҫ“еҮәз»“жһңдёҠпјҢжІЎжңүжӣҙж–°жҹҘиҜўж“ҚдҪңеӨҡдәҺrunning_updates_limit secondsгҖӮ
еңЁеӨҮеә“е…Ҳжү§иЎҢDDLпјҢдёҖиҲ¬е…Ҳstop slaveпјҢдёҖиҲ¬дёҚи®°еҪ•mysqlж—Ҙеҝ—пјҢеҸҜд»ҘйҖҡиҝҮset SQL_LOG_BIN = 0е®һзҺ°гҖӮ然еҗҺиҝӣиЎҢдёҖж¬Ўдё»еӨҮеҲҮжҚўж“ҚдҪңпјҢеҶҚеңЁеҺҹжқҘзҡ„дё»еә“дёҠжү§иЎҢDDLгҖӮиҝҷз§Қж–№жі•йҖӮз”ЁдәҺеўһеҮҸзҙўеј•пјҢеҰӮжһңжҳҜеўһеҠ еӯ—ж®өе°ұйңҖиҰҒйўқеӨ–жіЁж„ҸгҖӮ
дёҠиҝ°еҶ…е®№е°ұжҳҜMySQL MHAйӣҶзҫӨж–№жЎҲжҳҜжҖҺж ·зҡ„пјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ