жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPandasиҪ»жқҫеӨ„зҗҶи¶…еӨ§и§„жЁЎж•°жҚ®зҡ„ж–№жі•жҳҜд»Җд№ҲвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
еӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®йӣҶж—¶еёёжҳҜжЈҳжүӢзҡ„дәӢжғ…пјҢе°Өе…¶еңЁеҶ…еӯҳж— жі•е®Ңе…ЁеҠ иҪҪж•°жҚ®зҡ„жғ…еҶөдёӢгҖӮеңЁиө„жәҗеҸ—йҷҗзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘдҪҝз”Ё Python Pandas жҸҗдҫӣзҡ„дёҖдәӣеҠҹиғҪпјҢйҷҚдҪҺеҠ иҪҪж•°жҚ®йӣҶзҡ„еҶ…еӯҳеҚ з”ЁгҖӮеҸҜз”ЁжҠҖжңҜеҢ…жӢ¬еҺӢзј©гҖҒзҙўеј•е’Ңж•°жҚ®еҲҶеқ—гҖӮ
еңЁдёҠиҝ°иҝҮзЁӢдёӯйңҖиҰҒи§ЈеҶідёҖдәӣй—®йўҳпјҢе…¶дёӯд№ӢдёҖе°ұжҳҜж•°жҚ®йҮҸиҝҮеӨ§гҖӮеҰӮжһңж•°жҚ®йҮҸи¶…еҮәжң¬жңәеҶ…еӯҳзҡ„е®№йҮҸпјҢйЎ№зӣ®жү§иЎҢе°ұдјҡдә§з”ҹй—®йўҳгҖӮ
еҜ№жӯӨжңүе“Әдәӣи§ЈеҶіж–№жЎҲпјҹ
жңүеӨҡз§Қи§ЈеҶіж•°жҚ®йҮҸиҝҮеӨ§й—®йўҳзҡ„ж–№жі•гҖӮе®ғ们жҲ–жҳҜж¶ҲиҖ—ж—¶й—ҙпјҢжҲ–жҳҜйңҖиҰҒеўһеҠ жҠ•иө„гҖӮ
еҸҜиғҪзҡ„и§ЈеҶіж–№жЎҲ
жҠ•иө„и§ЈеҶіпјҡж–°иҙӯжңүиғҪеҠӣеӨ„зҗҶж•ҙдёӘж•°жҚ®йӣҶпјҢе…·жңүжӣҙејә CPU е’ҢжӣҙеӨ§еҶ…еӯҳзҡ„и®Ўз®—жңәгҖӮжҲ–жҳҜеҺ»з§ҹз”Ёдә‘жңҚеҠЎжҲ–иҷҡжӢҹеҶ…еӯҳпјҢеҲӣе»әеӨ„зҗҶе·ҘдҪңиҙҹиҪҪзҡ„йӣҶзҫӨгҖӮ
иҖ—ж—¶и§ЈеҶіпјҡеҰӮжһңеҶ…еӯҳдёҚи¶ід»ҘеӨ„зҗҶж•ҙдёӘж•°жҚ®йӣҶпјҢиҖҢзЎ¬зӣҳзҡ„е®№йҮҸиҰҒиҝңеӨ§дәҺеҶ…еӯҳпјҢжӯӨж—¶еҸҜиҖғиҷ‘дҪҝз”ЁзЎ¬зӣҳеӯҳеӮЁж•°жҚ®гҖӮдҪҶдҪҝз”ЁзЎ¬зӣҳз®ЎзҗҶж•°жҚ®дјҡеӨ§еӨ§йҷҚдҪҺеӨ„зҗҶжҖ§иғҪпјҢеҚідҫҝжҳҜ SSD д№ҹиҰҒжҜ”еҶ…еӯҳж…ўеҫҲеӨҡгҖӮ
еҸӘиҰҒиө„жәҗе…Ғи®ёпјҢиҝҷдёӨз§Қи§ЈеҶіж–№жі•еқҮеҸҜиЎҢгҖӮеҰӮжһңйЎ№зӣ®иө„йҮ‘е……иЈ•пјҢжҲ–жҳҜдёҚжғңд»»дҪ•ж—¶й—ҙд»Јд»·пјҢйӮЈд№ҲдёҠиҝ°дёӨз§Қж–№жі•жҳҜжңҖз®ҖеҚ•д№ҹжҳҜжңҖзӣҙжҺҘзҡ„и§ЈеҶіж–№жЎҲгҖӮ
дҪҶеҰӮжһңжғ…еҶө并йқһеҰӮжӯӨе‘ўпјҹд№ҹи®ёдҪ зҡ„иө„йҮ‘жңүйҷҗпјҢжҲ–жҳҜж•°жҚ®йӣҶиҝҮеӨ§пјҢд»ҺзЈҒзӣҳеҠ иҪҪе°ҶеўһеҠ 5~6 еҖҚз”ҡиҮіжӣҙеӨҡзҡ„еӨ„зҗҶж—¶й—ҙгҖӮжҳҜеҗҰжңүж— йңҖйўқеӨ–иө„йҮ‘жҠ•е…ҘжҲ–ж—¶й—ҙејҖй”Җзҡ„еӨ§ж•°жҚ®и§ЈеҶіж–№жЎҲе‘ўпјҹ
иҝҷдёӘй—®йўҳжӯЈдёӯжҲ‘зҡ„дёӢжҖҖгҖӮ
жңүеӨҡз§ҚжҠҖжңҜеҸҜз”ЁдәҺеӨ§ж•°жҚ®еӨ„зҗҶпјҢе®ғд»¬ж— йңҖйўқеӨ–д»ҳеҮәжҠ•иө„пјҢд№ҹдёҚдјҡиҖ—иҙ№еӨ§йҮҸеҠ иҪҪзҡ„ж—¶й—ҙгҖӮжң¬ж–Үе°Ҷд»Ӣз»Қе…¶дёӯдёүз§ҚдҪҝз”Ё Pandas еӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®йӣҶзҡ„жҠҖжңҜгҖӮ
еҺӢ зј©
第дёҖз§ҚжҠҖжңҜжҳҜж•°жҚ®еҺӢзј©гҖӮеҺӢ缩并йқһжҢҮе°Ҷж•°жҚ®жү“еҢ…дёә ZIP ж–Ү件пјҢиҖҢжҳҜд»ҘеҺӢзј©ж јејҸеңЁеҶ…еӯҳдёӯеӯҳеӮЁж•°жҚ®гҖӮ
жҚўеҸҘиҜқиҜҙпјҢж•°жҚ®еҺӢзј©е°ұжҳҜдёҖз§ҚдҪҝз”Ёжӣҙе°‘еҶ…еӯҳиЎЁзӨәж•°жҚ®зҡ„ж–№жі•гҖӮж•°жҚ®еҺӢзј©жңүдёӨз§Қзұ»еһӢпјҢеҚіж— жҚҹеҺӢзј©е’ҢжңүжҚҹеҺӢзј©гҖӮиҝҷдёӨз§Қзұ»еһӢеҸӘеҪұе“Қж•°жҚ®зҡ„еҠ иҪҪпјҢдёҚдјҡеҪұе“ҚеҲ°еӨ„зҗҶд»Јз ҒгҖӮ
ж— жҚҹеҺӢзј©
ж— жҚҹеҺӢзј©дёҚдјҡеҜ№ж•°жҚ®йҖ жҲҗд»»дҪ•жҚҹеӨұпјҢеҚіеҺҹе§Ӣж•°жҚ®е’ҢеҺӢзј©еҗҺзҡ„ж•°жҚ®еңЁиҜӯд№үдёҠдҝқжҢҒдёҚеҸҳгҖӮжү§иЎҢж— жҚҹеҺӢзј©жңүдёүз§Қж–№ејҸгҖӮеңЁдёӢж–ҮдёӯпјҢе°ҶдҪҝз”ЁзҫҺеӣҪжҢүе·һз»ҹи®Ўзҡ„ж–°еҶ з—…жҜ’з—…дҫӢж•°жҚ®йӣҶдҫқж¬Ўд»Ӣз»ҚгҖӮ
еҠ иҪҪзү№е®ҡзҡ„ж•°жҚ®еҲ—
дҫӢеӯҗдёӯжүҖдҪҝз”Ёзҡ„ж•°жҚ®йӣҶе…·жңүеҰӮдёӢз»“жһ„пјҡ
import pandas as pd data = pd.read_csv("https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv") data.sample(10)
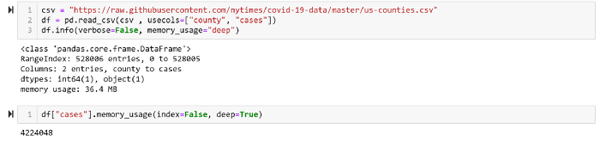
еҠ иҪҪж•ҙдёӘж•°жҚ®йӣҶйңҖиҰҒеҚ з”Ё 111MB еҶ…еӯҳпјҒ

еҰӮжһңжҲ‘们еҸӘйңҖиҰҒж•°жҚ®йӣҶдёӯзҡ„дёӨеҲ—пјҢеҚіе·һеҗҚе’Ңз—…дҫӢж•°пјҢйӮЈд№Ҳдёәд»Җд№ҲиҰҒеҠ иҪҪж•ҙдёӘж•°жҚ®йӣҶе‘ўпјҹеҠ иҪҪжүҖйңҖзҡ„дёӨеҲ—ж•°жҚ®еҸӘйңҖ 36MBпјҢеҸҜйҷҚдҪҺеҶ…еӯҳдҪҝз”Ё 32%гҖӮ

дҪҝз”Ё Pandas еҠ иҪҪжүҖйңҖж•°жҚ®еҲ—зҡ„д»Јз ҒеҰӮдёӢпјҡ

жң¬иҠӮдҪҝз”Ёзҡ„д»Јз ҒзүҮж®өеҰӮдёӢпјҡ
# еҠ иҪҪжүҖйңҖиҪҜ件еә“ Import needed library import pandas as pd # ж•°жҚ®йӣҶ csv = "https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv" # еҠ иҪҪж•ҙдёӘж•°жҚ®йӣҶ data = pd.read_csv(csv) data.info(verbose=False, memory_usage="deep") # еҲӣе»әж•°жҚ®еӯҗйӣҶ df = data[["county", "cases"]] df.info(verbose=False, memory_usage="deep") # еҠ йҖҹжүҖйңҖзҡ„дёӨеҲ—ж•°жҚ® df_2col = pd.read_csv(csv , usecols=["county", "cases"]) df_2col.info(verbose=False, memory_usage="deep")
д»Јз Ғең°еқҖпјҡ
https://gist.github.com/SaraM92/3ba6cac1801b20f6de1ef3cc4a18c843#file-column_selecting-py
ж“ҚдҪңж•°жҚ®зұ»еһӢ
еҸҰдёҖдёӘйҷҚдҪҺж•°жҚ®еҶ…еӯҳдҪҝз”ЁйҮҸзҡ„ж–№жі•жҳҜжҲӘеҸ–ж•°еҖјйЎ№гҖӮдҫӢеҰӮе°Ҷ CSV еҠ иҪҪеҲ° DataFrameпјҢеҰӮжһңж–Ү件дёӯеҢ…еҗ«ж•°еҖјпјҢйӮЈд№ҲдёҖдёӘж•°еҖје°ұйңҖиҰҒ 64 дёӘеӯ—иҠӮеӯҳеӮЁгҖӮдҪҶеҸҜйҖҡиҝҮдҪҝз”Ё int ж јејҸжҲӘеҸ–ж•°еҖјд»ҘиҠӮзңҒеҶ…еӯҳгҖӮ
int8 еӯҳеӮЁеҖјзҡ„иҢғеӣҙжҳҜ -128 еҲ° 127пјӣ
int16 еӯҳеӮЁеҖјзҡ„иҢғеӣҙжҳҜ -32768 еҲ° 32767пјӣ
int64 еӯҳеӮЁеҖјзҡ„иҢғеӣҙжҳҜ -9223372036854775808 еҲ° 9223372036854775807гҖӮ
еҰӮжһңеҸҜйў„е…ҲзЎ®е®ҡж•°еҖјдёҚеӨ§дәҺ 32767пјҢйӮЈд№Ҳе°ұеҸҜд»ҘдҪҝз”Ё int16 жҲ– int32 зұ»еһӢпјҢиҜҘеҲ—зҡ„еҶ…еӯҳеҚ з”ЁиғҪйҷҚдҪҺ 75%гҖӮ
еҒҮе®ҡжҜҸдёӘе·һзҡ„з—…дҫӢж•°дёҚи¶…иҝҮ 32767пјҲиҷҪ然зҺ°е®һдёӯ并йқһеҰӮжӯӨпјүпјҢйӮЈд№Ҳе°ұеҸҜжҲӘеҸ–иҜҘеҲ—дёә int16 зұ»еһӢиҖҢйқһ int64гҖӮ

зЁҖз–ҸеҲ—
еҰӮжһңж•°жҚ®йӣҶзҡ„дёҖжҲ–еӨҡдёӘеҲ—дёӯе…·жңүеӨ§йҮҸзҡ„ NaN з©әеҖјпјҢйӮЈд№ҲеҸҜд»ҘдҪҝз”Ё зЁҖз–ҸеҲ—иЎЁзӨә йҷҚдҪҺеҶ…еӯҳдҪҝз”ЁпјҢд»Ҙе…Қз©әеҖјиҖ—иҙ№еҶ…еӯҳгҖӮ
еҒҮе®ҡе·һеҗҚиҝҷдёҖеҲ—еӯҳеңЁдёҖдәӣз©әеҖјпјҢжҲ‘们йңҖиҰҒи·іиҝҮжүҖжңүеҢ…еҗ«з©әеҖјзҡ„иЎҢгҖӮиҜҘйңҖжұӮеҸҜдҪҝз”Ё pandas.sparse иҪ»жқҫе®һзҺ°пјҲиҜ‘иҖ…жіЁпјҡеҺҹж–ҮдҪҝз”Ё Sparse SeriesпјҢдҪҶеңЁ Pandas 1.0.0 дёӯе·Із»Ҹ移йҷӨдәҶ SparseSeriesпјүгҖӮ

жңүжҚҹеҺӢзј©
еҰӮжһңж— жҚҹеҺӢ缩并дёҚж»Ўи¶ійңҖжұӮпјҢиҝҳйңҖиҰҒиҝӣдёҖжӯҘеҺӢзј©пјҢйӮЈд№Ҳеә”иҜҘеҰӮдҪ•еҒҡпјҹиҝҷж—¶еҸҜдҪҝз”ЁжңүжҚҹеҺӢзј©пјҢжқғиЎЎеҶ…еӯҳеҚ з”ЁиҖҢзүәзүІж•°жҚ®зҷҫеҲҶд№Ӣзҷҫзҡ„еҮҶзЎ®жҖ§гҖӮ
жңүжҚҹеҺӢзј©жңүдёӨз§Қж–№ејҸпјҢеҚідҝ®ж”№ж•°еҖје’ҢжҠҪж ·гҖӮ
дҝ®ж”№ж•°еҖјпјҡжңү时并дёҚйңҖиҰҒж•°еҖјдҝқз•ҷе…ЁйғЁзІҫеәҰпјҢиҝҷж—¶еҸҜд»Ҙе°Ҷ int64 жҲӘеҸ–дёә int32 з”ҡиҮіжҳҜ int16гҖӮ
жҠҪж ·пјҡеҰӮжһңйңҖиҰҒзЎ®и®Өжҹҗдәӣе·һзҡ„ж–°еҶ з—…дҫӢж•°иҰҒй«ҳдәҺе…¶е®ғе·һпјҢеҸҜд»ҘжҠҪж ·йғЁеҲҶе·һзҡ„ж•°жҚ®пјҢжҹҘзңӢе“Әдәӣе·һе…·жңүжӣҙеӨҡзҡ„з—…дҫӢгҖӮиҝҷз§ҚеҒҡжі•жҳҜдёҖз§ҚжңүжҚҹеҺӢзј©пјҢеӣ дёәе…¶дёӯ并жңӘиҖғиҷ‘еҲ°жүҖжңүзҡ„ж•°жҚ®иЎҢгҖӮ
第дәҢз§ҚжҠҖжңҜпјҡж•°жҚ®еҲҶеқ—пјҲchunkingпјү
еҸҰдёҖдёӘеӨ„зҗҶеӨ§и§„жЁЎж•°жҚ®йӣҶзҡ„ж–№жі•жҳҜж•°жҚ®еҲҶеқ—гҖӮе°ҶеӨ§и§„жЁЎж•°жҚ®еҲҮеҲҶдёәеӨҡдёӘе°ҸеҲҶеқ—пјҢиҝӣиҖҢеҜ№еҗ„дёӘеҲҶеқ—еҲҶеҲ«еӨ„зҗҶгҖӮеңЁеӨ„зҗҶе®ҢжүҖжңүеҲҶеқ—еҗҺпјҢеҸҜд»ҘжҜ”иҫғз»“жһң并з»ҷеҮәжңҖз»Ҳз»“и®әгҖӮ
жң¬ж–ҮдҪҝз”Ёзҡ„ж•°жҚ®йӣҶдёӯеҢ…еҗ«дәҶ 1923 иЎҢж•°жҚ®гҖӮ

еҒҮе®ҡжҲ‘们йңҖиҰҒжүҫеҮәе…·жңүжңҖеӨҡз—…дҫӢзҡ„е·һпјҢйӮЈд№ҲеҸҜд»Ҙе°Ҷж•°жҚ®йӣҶеҲҮеҲҶдёәжҜҸеқ— 100 иЎҢж•°жҚ®пјҢеҲҶеҲ«еӨ„зҗҶжҜҸдёӘж•°жҚ®еқ—пјҢд»Һиҝҷеҗ„дёӘе°Ҹз»“жһңдёӯиҺ·еҸ–жңҖеӨ§еҖјгҖӮ
жң¬иҠӮд»Јз ҒзүҮж®өеҰӮдёӢпјҡ
# еҜје…ҘжүҖйңҖиҪҜ件еә“ import pandas as pd # ж•°жҚ®йӣҶ csv = "https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv" # еҫӘзҺҜеӨ„зҗҶжҜҸдёӘж•°жҚ®еқ—пјҢиҺ·еҸ–жҜҸдёӘж•°жҚ®еқ—дёӯзҡ„жңҖеӨ§еҖј result = {} for chunk in pd.read_csv(csv, chunksize=100): max_case = chunk["cases"].max() max_case_county = chunk.loc[chunk[ cases ] == max_case, county ].iloc[0] result[max_case_county] = max_case # з»ҷеҮәз»“жһң print(max(result, key=result.get) , result[max(result, key=result.get)])д»Јз Ғең°еқҖпјҡ
https://gist.github.com/SaraM92/808ed30694601e5eada5e283b2275ed7#file-chuncking-py
第дёүз§Қж–№жі•пјҡзҙўеј•
ж•°жҚ®еҲҶеқ—йқһеёёйҖӮз”ЁдәҺж•°жҚ®йӣҶд»…еҠ иҪҪдёҖж¬Ўзҡ„жғ…еҶөгҖӮдҪҶеҰӮжһңйңҖиҰҒеӨҡж¬ЎеҠ иҪҪж•°жҚ®йӣҶпјҢйӮЈд№ҲеҸҜд»ҘдҪҝз”Ёзҙўеј•жҠҖжңҜгҖӮ
зҙўеј•еҸҜзҗҶи§ЈдёәдёҖжң¬д№Ұзҡ„зӣ®еҪ•гҖӮж— йңҖиҜ»е®Ңж•ҙжң¬д№Ұе°ұеҸҜд»ҘиҺ·еҸ–жүҖйңҖеҫ—дҝЎжҒҜгҖӮ
дҫӢеҰӮпјҢеҲҶеқ—жҠҖжңҜйқһеёёйҖӮз”ЁдәҺиҺ·еҸ–жҢҮе®ҡе·һзҡ„з—…дҫӢж•°гҖӮзј–еҶҷеҰӮдёӢзҡ„з®ҖеҚ•еҮҪж•°пјҢе°ұиғҪе®һзҺ°иҝҷдёҖеҠҹиғҪгҖӮ

зҙўеј• vs еҲҶеқ—
еҲҶеқ—йңҖиҜ»еҸ–жүҖжңүж•°жҚ®пјҢиҖҢзҙўеј•еҸӘйңҖиҜ»еҸ–йғЁеҲҶж•°жҚ®гҖӮ
дёҠйқўзҡ„еҮҪж•°еҠ иҪҪдәҶжҜҸдёӘеҲҶеқ—дёӯзҡ„жүҖжңүиЎҢпјҢдҪҶжҲ‘们еҸӘе…іеҝғе…¶дёӯзҡ„дёҖдёӘе·һпјҢиҝҷеҜјиҮҙеӨ§йҮҸзҡ„йўқеӨ–ејҖй”ҖгҖӮеҸҜдҪҝз”Ё Pandas зҡ„ж•°жҚ®еә“ж“ҚдҪңпјҢдҫӢеҰӮз®ҖеҚ•зҡ„еҒҡжі•жҳҜдҪҝз”Ё SQLite ж•°жҚ®еә“гҖӮ
йҰ–е…ҲпјҢйңҖиҰҒе°Ҷ DataFrame еҠ иҪҪеҲ° SQLite ж•°жҚ®еә“пјҢд»Јз ҒеҰӮдёӢпјҡ
import sqlite3 csv = "https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv" # еҲӣе»әж–°зҡ„ж•°жҚ®еә“ж–Ү件 db = sqlite3.connect("cases.sqlite") # жҢүеқ—еҠ иҪҪ CSV ж–Ү件 for c in pd.read_csv(csv, chunksize=100): # е°ҶжүҖжңүж•°жҚ®иЎҢеҠ иҪҪеҲ°ж–°зҡ„ж•°жҚ®еә“иЎЁдёӯ c.to_sql("cases", db, if_exists="append") # дёәвҖңstateвҖқеҲ—ж·»еҠ зҙўеј• db.execute("CREATE INDEX state ON cases(state)") db.close()д»Јз Ғең°еқҖпјҡ
https://gist.github.com/SaraM92/5b445d5b56be2d349cdfa988204ff5f3#file-load_into_db-py
дёәдҪҝз”Ёж•°жҚ®еә“пјҢдёӢйқўйңҖиҰҒйҮҚеҶҷ get_state_info еҮҪж•°гҖӮ

иҝҷж ·еҸҜйҷҚдҪҺеҶ…еӯҳеҚ з”Ё 50%гҖӮ
вҖңPandasиҪ»жқҫеӨ„зҗҶи¶…еӨ§и§„жЁЎж•°жҚ®зҡ„ж–№жі•жҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ