

您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“mysql为什么InnoDB表最好要有自增列做主键”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
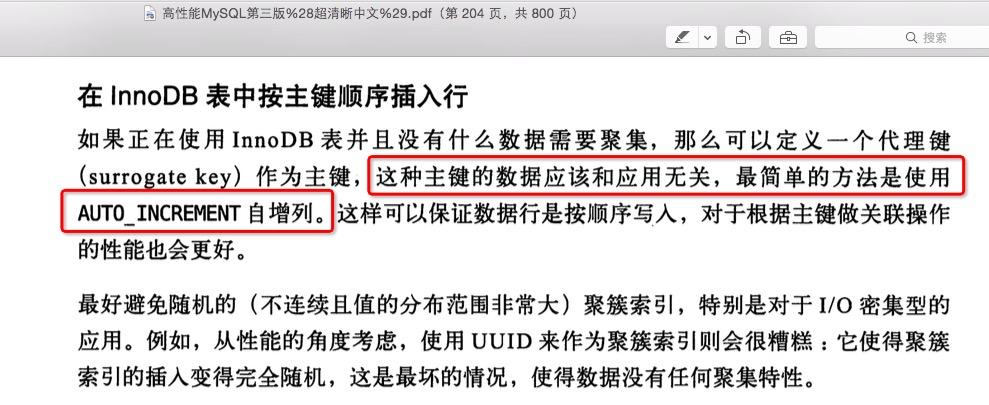
1、为什么InnoDB表最好要有自增列做主键?
InnoDB引擎表是基于B+树的索引组织表(IOT)
关于B+树
(图片来源于网上)
B+ 树的特点:
a、所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
b、不可能在非叶子结点命中;
c、非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层。
1、如果我们定义了主键(PRIMARY KEY)
那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
2、数据记录本身被存于主索引(一颗B+Tree)的叶子节点上
这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
3、如果表使用自增主键
那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
4、如果使用非自增主键(如果身份证号或学号等)
由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
总结:如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
a、使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
b、该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
c、如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差。
一下是来自《高性能MySQL》中的原话
引用链接:https://segmentfault.com/q/1010000003856705
2、为什么需要设置双1才能保证主从数据的一致性?
双1:innodb_flush_log_at_trx_commit=1 and sync_binlog=1
sync_binlog=n,当每次提交N次事务提交之后,MySQL将进行一次fsny之类的磁盘同步指令来将binlog_cache中的数据强制写入磁盘。 在MySQL中sync_binlog=0,也就是不做任何强制性的磁盘刷新指令,这时候性能是最好的,但是风险也是最大的。因为一旦系统crash,在binlog_cache中的所有binlog信息都会丢失。
innodb_flush_log_at_trx_commit=1 是每一次事务提交或事务的指令都需要把日志写入(flush)硬盘,这是很费时的,在使用电池供电缓存(Battery backed up cache)时。
innodb_flush_log_at_trx_commit=2 是不写入硬盘而是写入系统缓存,日志仍然会每秒flush到硬盘,所以一般不会丢失超过1-2秒的更新,系统挂了时才可能丢数据
innodb_flush_log_at_trx_commit=0 会更快一些,安全性比较差,即使mysql挂了可能会丢失事务的数据
3、有几种binlog格式,区别是什么 ?
Row,Statement,Mixed=Row+Statement
1. Row
日志中会记录成每一行数据被修改的形式,然后在 slave 端再对相同的数据进行修改。
优点:在 row 模式下,bin-log 中可以不记录执行的 SQL 语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以 row 的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程或 function ,以及 trigger 的调用和触发无法被正确复制的问题。
缺点:在 row 模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
2. Statement
每一条会修改数据的 SQL 都会记录到 master 的 bin-log 中。slave 在复制的时候 SQL 进程会解析成和原来 master 端执行过的相同的 SQL 再次执行。
优点:在 statement 模式下,首先就是解决了 row 模式的缺点,不需要记录每一行数据的变化,减少了 bin-log 日志量,节省 I/O 以及存储资源,提高性能。因为他只需要记录在 master 上所执行的语句的细节,以及执行语句时候的上下文的信息。
缺点:在 statement 模式下,由于他是记录的执行语句,所以,为了让这些语句在 slave 端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在 slave 端杯执行的时候能够得到和在 master 端执行时候相同的结果。另外就是,由于 MySQL 现在发展比较快,很多的新功能不断的加入,使 MySQL 的复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug 也就越容易出现。在 statement 中,目前已经发现的就有不少情况会造成 MySQL 的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep() 函数在有些版本中就不能被正确复制,在存储过程中使用了 last_insert_id() 函数,可能会使 slave 和 master 上得到不一致的 id 等等。由于 row 是基于每一行来记录的变化,所以不会出现类似的问题。
3. Mixed
从官方文档中看到,之前的 MySQL 一直都只有基于 statement 的复制模式,直到 5.1.5 版本的 MySQL 才开始支持 row 复制。从 5.0 开始,MySQL 的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给 MySQL Replication 又带来了更大的新挑战。另外,看到官方文档说,从 5.1.8 版本开始,MySQL 提供了除 Statement 和 Row 之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。在 Mixed 模式下,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。新版本中的 statment 还是和以前一样,仅仅记录执行的语句。而新版本的 MySQL 中对 row 模式也被做了优化,并不是所有的修改都会以 row 模式来记录,比如遇到表结构变更的时候就会以 statement 模式来记录,如果 SQL 语句确实就是 update 或者 delete 等修改数据的语句,那么还是会记录所有行的变更。
注意:
条件1:当binlog format设置为mixed时,普通复制不会有问题,但是级联复制在特殊情况下会binlog丢失.
条件2:当出现大量数据(400W左右)扫描的更新,删除,插入的时候,且有不确定dml语句(如:delete from table where data<’N’ limit )的时候.
当条件1 和 条件2 同时满足时,会导致主从复制数据丢失问题的发生.只能设置binlog_format=Row
引用:http://tshare365.com/archives/2054.html
“mysql为什么InnoDB表最好要有自增列做主键”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。