您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
第一部分 InnoDB引擎表的特点
1、InnoDB引擎表是基于B+树的索引组织表(IOT)
关于B+树
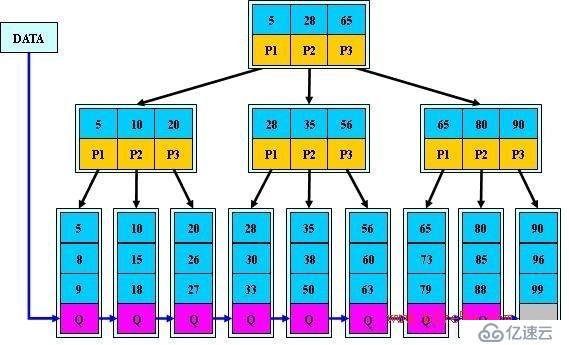
B+ 树的特点:
(1)所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
(2)不可能在非叶子结点命中;
(3)非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
2、如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
3、数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)
4、如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页
5、如果使用非自增主键(如果×××号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
综上总结,如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
1、使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
2、该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差。
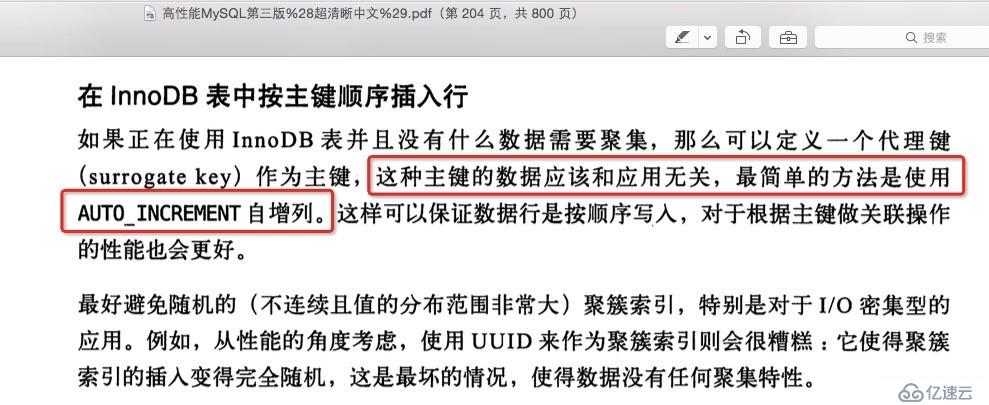
《高性能MySQL》中的原话

第二部分 关于自增锁的分析
自增锁,在提交前释放,并发插入高,共享锁和排它锁在COMMIT提交后释放。对于自增列的值不能回滚。
insert -like:
simple-insert:插入前就能确定插入行数语句
bulk insert :插入前不确定插入行数的语句 replace ... select
mixed-mode inserts:insert into t1(c1,c2) values(1,"a"),(null,"b"),(4,"c"),(null,"d")
insert ... on duplicate key update:自身扩展 (任何KEY 重复,就执行 )参数innodb_autoinc_lock_mode有三种模式:
0:传统方式 ,
simple insert:传统方式
bulk insert :传统方式
对于 INSERT ... SELECT ... 些时其他事务不能插,分配的ID是连续得 ,其他事务不能插入
SQL执行完才释放自增锁
1.(默认配置)
simple insert 并发
bulk insert 传统方式
2.最宽松方式
所有自增都以并发方式
同一SQL语句自增可能不连接
row-based binlog
工作模式1:
工作原理:
BULK INSERT:
ACQUIRE AI
INSERT ..SELECT :如果执行时间长,自增锁持有时间就长,不确定插入的记录数,只能等插入完 才自增,其他事务等待插入
AI=AI+N
RELEASE AI
SIMPLE INSERT : 无SQL 语句执行等待
ACQURE AI
AI=AI+N
RELESE AI
工作模式为 2时的工作原理:
FOR I=AI;I++; //对BULK INSERT 也能并发插入,对单线插入变差,无益,对多线程插入是益的,自增值可能不连续的
{
ACQUIRE AI LOCK
INSERT ONE REC
AI=Ai+1
RELEAS AI LOCK
}
这样做的好处是,对于批量的、耗时的插入,SQL不会长时间的持有AI自增锁,而是插入 一条 (有且仅插入一条,而simple inserts是确定好的M条)语句后就 释放 ,这样可以给别的事物使用,实现并发。
但是这种方式 并发度是增加了 ,但是性能不一定变好,尤其是单线程导入数据时,要 不断的申请和释放锁
对于批量插入来说,自增就可能变的不连续了(需要和开发沟通,是否可以接受)
innodb_autoinc_lock_mode 是 read-only 的, 需要 修改后 重启 MySQL实例。
自增列的创建:
对于联合索引,自增列必须放在第一个列
create table jjj ( a int auto_increment,b int ,key( a,b)); // KEY(b,a)
自增锁:
AUTO_INCREMENT PK 不能持久化,速度快
当重起MYSQL 服务器重新计算值:
SELECT MAX(AUTO_INC_COL) FROM XX 基于索引查找,而不是全表扫
自增锁相关参数:
auto_increment_increment:步长值
auto_increment_offset:初始值
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。