您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何利用python的KMeans和PCA包实现聚类算法,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
题目: 通过给出的驾驶员行为数据(trip.csv),对驾驶员不同时段的驾驶类型进行聚类,聚成普通驾驶类型,激进类型和超冷静型3类 。 利用Python的scikit-learn包中的Kmeans算法进行聚类算法的应用练习。并利用scikit-learn包中的PCA算法来对聚类后的数据进行降维,然后画图展示出聚类效果。通过调节聚类算法的参数,来观察聚类效果的变化,练习调参。
数据介绍: 选取某一个驾驶员的经过处理的数据集trip.csv,将该驾驶人的各个时间段的特征进行聚类。(注:其中的driver 和trip_no 不参与聚类)
字段介绍: driver :驾驶员编号;trip_no:trip编号;v_avg:平均速度;v_var:速度的方差;a_avg:平均加速度;a_var:加速度的方差;r_avg:平均转速;r_var:转速的方差; v_a:速度level为a时的时间占比(同理v_b , v_c , v_d ); a_a:加速度level为a时的时间占比(同理a_b, a_c); r_a:转速level为a时的时间占比( r_b, r_c)
聚类算法要求:
(1)统计各个类别的数目
(2)找出聚类中心
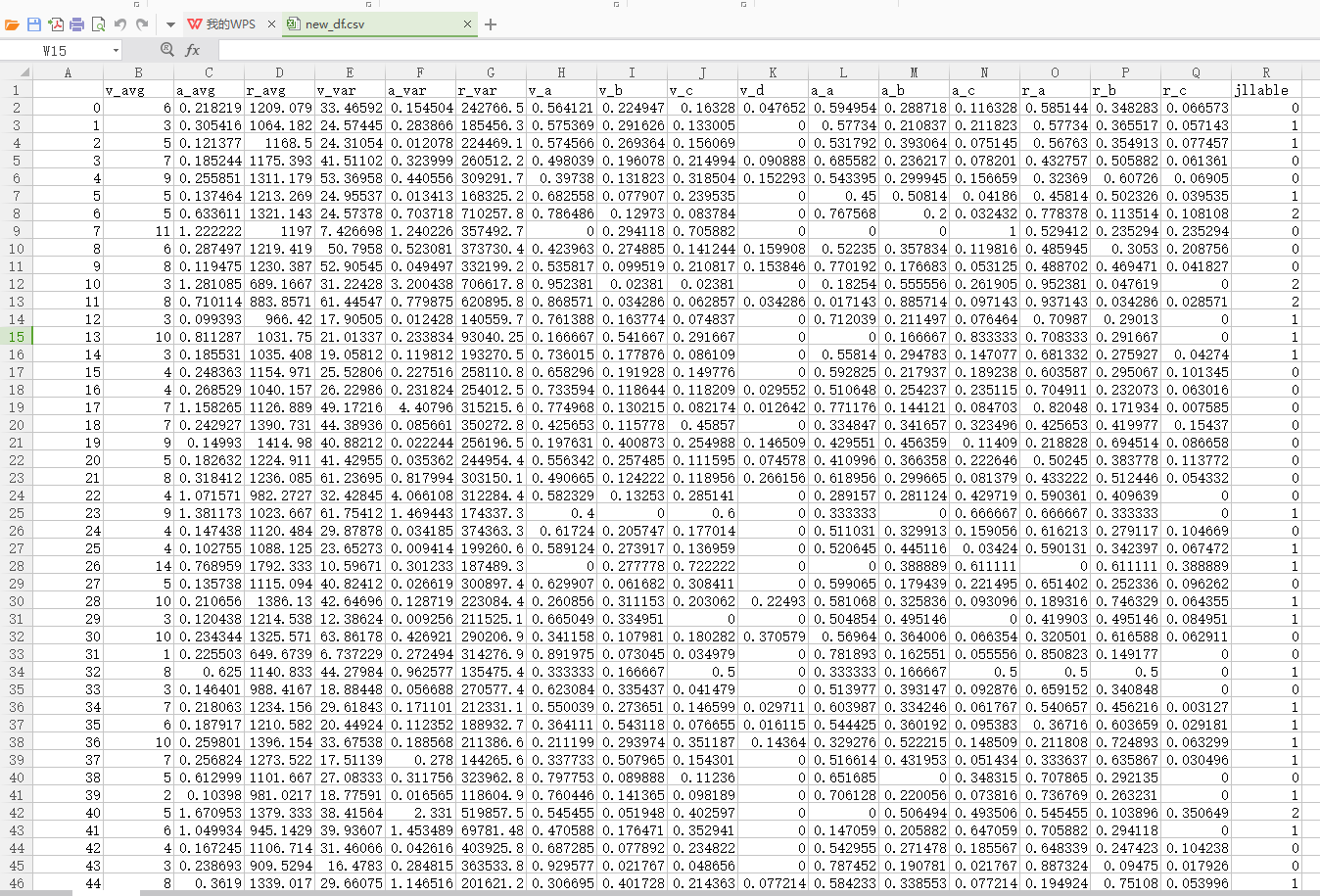
(3)将每条数据聚成的类别(该列命名为jllable )和原始数据集进行合并,形成新的dataframe,命名为new_df ,并输出到本地,命名为new_df.csv。
降维算法要求:
(1)将用于聚类的数据的特征的维度降至2维,并输出降维后的数据,形成一个dataframe名字new_pca
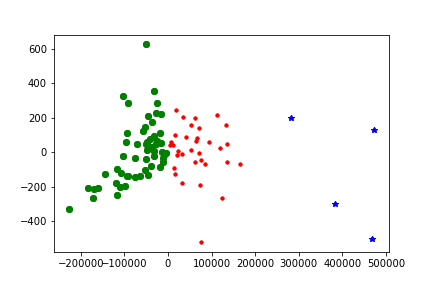
(2)画图来展示聚类效果(可用如下代码):
import matplotlib.pyplot asplt
d = new_pca[new_df['jllable'] == 0]
plt.plot(d[0], d[1], 'r.')
d = new_pca[new_df['jllable'] == 1]
plt.plot(d[0], d[1], 'go')
d = new_pca[new_df['jllable'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.gcf().savefig('D:/workspace/python/Practice/ddsx/kmeans.png')
plt.show()
python实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
运行结果如下:
##各个类别的数目
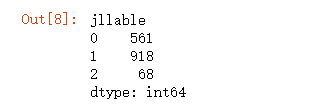
##聚类中心

##新的dataframe,命名为new_df ,并输出到本地,命名为new_df.csv。
##可视化------kmeans.png
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。