您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
原文请戳
本文大概需要10分钟看完
要求:Linux编辑器,python3版本
vim test1.py
# test1.py内容:
import sys, locale
s = "王佳"
print(s)
print(sys.getdefaultencoding())
print(locale.getdefaultlocale())
with open("utf8_1.txt","w",encoding = "utf-8") as f:
f.write(s)
with open("gbk_1.txt","w",encoding = "gbk") as f:
f.write(s)
sys.getdefaultencoding():python编译器的编码
locale.getdefaultlocale():本地操作系统的编码
上述代码返回结果:
王佳
utf-8 # python编译器的编码
('en_US', 'UTF-8') # 本地操作系统的编码
再来看一下生成的两个文件中的内容,我们使用notepad打开,并且将这两个的文件编码都设置成utf-8
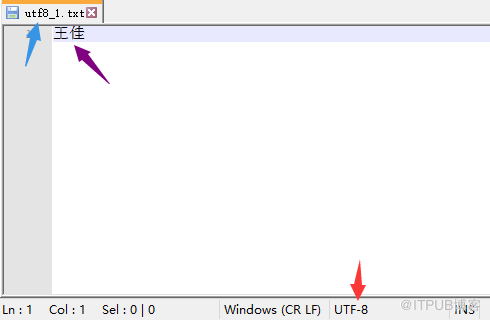
utf8_1.txt:
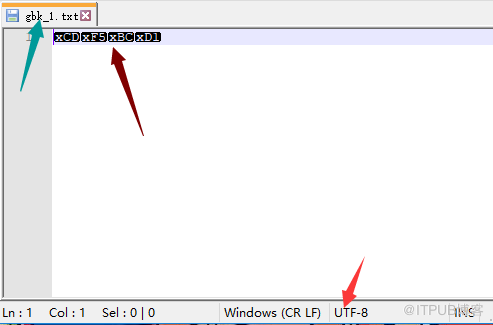
gbk_1.txt:
分析如下:
#1 对于utf8_1.txt来说
# 第一步:由于linux的编辑器是utf8,所以:
'王佳'.encode('utf8') = \xe7\x8e\x8b\xe4\xbd\xb3 (写入文件时)
# 第二步:由于没有指定py文件的coding,所以python解释器将默认按照系统编码utf8进行解码
\xe7\x8e\x8b\xe4\xbd\xb3.decode('utf8') = '王佳'
# 第三步:open时指定了encoding=utf8去编码写入到文件中
'王佳'.encode('utf8')= \xe7\x8e\x8b\xe4\xbd\xb3
# 第四步:在notepadd中指定了utf8去解码
\xe7\x8e\x8b\xe4\xbd\xb3.decode('utf8')='王佳'
#2 对于gbk_1.txt来说
# 第一步:由于linux的编辑器是utf8,所以:
'王佳'.encode('utf8') = \xe7\x8e\x8b\xe4\xbd\xb3 (写入文件时)
# 第二步:由于没有指定py文件的coding,所以python解释器将默认按照系统编码utf8进行解码
\xe7\x8e\x8b\xe4\xbd\xb3.decode('utf8') = '王佳'
# 第三步:open时指定了encoding=gbk去编码写入到文件中
'王佳'.encode('gbk')= \xcd\xf5\xbc\xd1
# 第四步:在notepadd中指定了utf8去解码
\xcd\xf5\xbc\xd1.decode('utf8')=这样写会报错,因为utf8编码,没有这几个。所以notepad就显示其gbk的字节码。
# test2.py
#coding=gbk
import sys, locale
s = "王佳"
print(s)
print(sys.getdefaultencoding())
print(locale.getdefaultlocale())
with open("utf8_2.txt","w",encoding = "utf-8") as f:
f.write(s)
with open("gbk_2.txt","w",encoding = "gbk") as f:
f.write(s)
此时,再看一下文件中的结果:
utf8_2.txt:
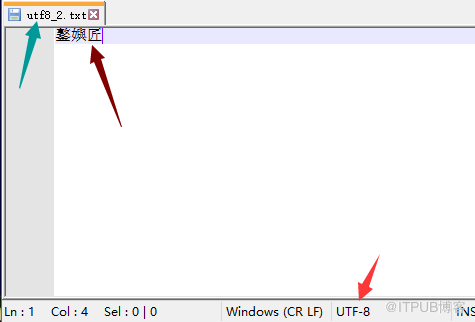
# 出现 鐜嬩匠 的原因分析
# 第一步:由于linux的编辑器是utf8,所以:
'王佳'.encode('utf8') = \xe7\x8e\x8b\xe4\xbd\xb3 (写入文件时)
# 第二步:由于指定py文件的coding=gbk,所以python解释器将默认按照系统编码gbk进行解码读取
\xe7\x8e\x8b\xe4\xbd\xb3.decode('gbk') = '鐜嬩匠'
# 第三步:open时指定了encoding=utf8去编码写入到文件中
'鐜嬩匠'.encode('utf8')= ??\xe5\x8c\xa0
# 第四步:在notepadd中指定了utf8去解码
??\xe5\x8c\xa0.decode('utf8')='鐜嬩匠'
gbk_2.txt:
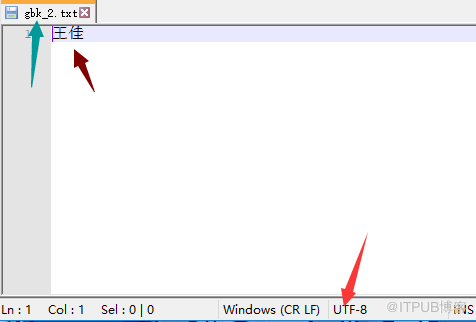
# 正常显示的原因
# 第一步:由于linux的编辑器是utf8,所以:
'王佳'.encode('utf8') = \xe7\x8e\x8b\xe4\xbd\xb3 (写入文件时)
# 第二步:由于指定py文件的coding=gbk,所以python解释器将默认按照系统编码gbk进行解码读取
\xe7\x8e\x8b\xe4\xbd\xb3.decode('gbk') = '鐜嬩匠'
# 第三步:open时指定了encoding=gbk去编码写入到文件中
'鐜嬩匠'.encode('gbk')= \xe7\x8e\x8b\xe4\xbd\xb3
# 第四步:在notepadd中指定了utf8去解码
\xe7\x8e\x8b\xe4\xbd\xb3.decode('utf8')='王佳'
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。