жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶPython3зј–з ҒжҖҺж ·е®һзҺ°зӣёдә’иҪ¬еҢ–пјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢйңҖиҰҒзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢгҖӮеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·гҖӮдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
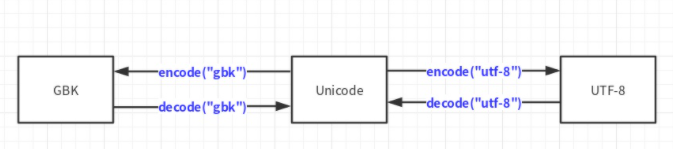
еҸҜд»ҘйҖҡиҝҮ Unicode зј–з ҒжқҘиҝӣиЎҢдёҚеҗҢзј–з Ғд№Ӣй—ҙзҡ„зӣёдә’иҪ¬еҢ–
дәҶи§Ј ASCIIгҖҒUnicodeгҖҒUTF-8гҖҒGBK иҝҷеӣӣз§Қзј–з Ғзҡ„зӣёе…іжҰӮеҝө
дёҚеҗҢзҡ„зј–з Ғд№Ӣй—ҙдёҚиғҪдә’зӣёиҜҶеҲ«пјҢдёҚиғҪзӣёдә’иҪ¬еҢ–пјҢдјҡжҠҘй”ҷжҲ–еҮәзҺ°д№ұз Ғ
еӣҪйҷ…йҖҡз”Ёж ҮеҮҶпјҡж–Үеӯ—йҖҡиҝҮзҪ‘з»ңдј иҫ“гҖҒжҲ–зЎ¬зӣҳеӯҳеӮЁзӯүдёҚиғҪдҪҝз”Ё Unicode зј–з Ғж–№ејҸпјҢеӣ дёә Unicode дҪҝз”Ёзҡ„жҳҜеҚҮзә§зүҲ 32 дҪҚзҡ„пјҢеӨӘиҙ№жөҒйҮҸе’Ңз©әй—ҙ
еңЁ Python3 зүҲжң¬дёӯпјҢе”ҜзӢ¬ string еңЁеҶ…еӯҳдёӯзҡ„зј–з Ғж–№ејҸжҳҜ UnicodeпјҢжүҖд»Ҙеӯ—з¬ҰдёІдёҚиғҪзӣҙжҺҘиҝӣиЎҢзҪ‘з»ңдј иҫ“еҸҠиҝӣиЎҢж–Ү件зҡ„еӯҳеӮЁ
bytesпјҡд№ҹжҳҜдёҖз§Қж•°жҚ®зұ»еһӢпјҢдёҚжҳҜеӯ—иҠӮпјҢдёҺ string зұ»еһӢе°ұеғҸжҳҜеӯӘз”ҹе…„ејҹ
дёәе•ҘиҰҒжңү bytes пјҹвҖ”вҖ” bytes еҶ…йғЁзј–з ҒдёҚжҳҜ Unicode ж–№ејҸпјҢеӣ жӯӨеҸҜд»ҘиҝӣиЎҢзҪ‘з»ңдј иҫ“е’Ңж–Ү件зҡ„еӯҳеӮЁ
еүҚйқўжҸҗеҲ°пјҢstring зұ»еһӢеҚҙжҳҜ Unicode ж–№ејҸпјҢдёәе•Ҙе№іж—¶жҲ‘们用зҡ„жҳҜ string иҖҢдёҚжҳҜ bytesпјҹвҖ”вҖ”еӣ дёә bytes зҡ„дёӯж–ҮжҳҜ 16 иҝӣеҲ¶ж–№ејҸеӯҳеңЁ
еӣ жӯӨпјҢдёҖиҲ¬еҪ“йңҖиҰҒзҪ‘з»ңдј иҫ“ж•°жҚ®жҲ–иҖ…ж–Ү件еӯҳеӮЁж—¶иҰҒиҖғиҷ‘з”Ё bytes зұ»еһӢгҖӮ
s1 = "abc" s2 = b"abc" print(type(s1)) # <class 'str'> print(type(s2)) # <class 'bytes'>
string иҪ¬еҢ–жҲҗ bytes зҡ„ж–№жі•
######## ж–№жі•дёҖ ########
# Unicodeзј–з Ғж–№ејҸзҡ„ string --> GBKзј–з Ғж–№ејҸзҡ„ string --> GBKзј–з Ғж–№ејҸзҡ„ bytes
# encode зј–з Ғ
# decode и§Јз Ғ
# Python3 зүҲжң¬дёӯпјҢеӯ—з¬ҰдёІзҡ„зј–з Ғж–№ејҸе°ұжҳҜ Unicode, жүҖд»ҘиҝҷйҮҢзӯүеҗҢдәҺ s = u"дёӯеӣҪ"
s1 = "дёӯеӣҪ"
b = s1.encode("gbk")
s2 = b.decode("gbk")
print(s1) # дёӯеӣҪ
print(b) # b'\xd6\xd0\xb9\xfa'
print(s2) # дёӯеӣҪ
print(type(s1)) # <class 'str'>
print(type(b)) # <class 'bytes'>
print(type(s2)) # <class 'str'>
# еҺҹеӣ и§ЈжһҗпјҡйҰ–е…Ҳ s1 жҳҜд»Ҙ Unicode зј–з Ғж–№ејҸзҡ„ string
# 然еҗҺ b жҳҜе°Ҷ Unicode зј–з Ғж–№ејҸзҡ„ string иҪ¬еҢ–жҲҗ GBK зј–з Ғж–№ејҸзҡ„ bytes
# жңҖеҗҺ s2 жҳҜе°Ҷ GBK зј–з Ғж–№ејҸзҡ„ bytes иҪ¬еҢ–жҲҗ Unicode зј–з Ғж–№ејҸзҡ„ string
######## ж–№жі•дәҢ ########
# Unicodeзј–з Ғж–№ејҸзҡ„ string --> UTF-8 зј–з Ғж–№ејҸзҡ„ string --> GBKзј–з Ғж–№ејҸзҡ„ bytes
s1 = "дёӯеӣҪ"
b = s1.encode("utf-8")
s2 = b.decode("utf-8")
print(s1) # дёӯеӣҪ
print(b) # b'\xe4\xb8\xad\xe5\x9b\xbd'
print(s2) # дёӯеӣҪ
print(type(s1)) # <class 'str'>
print(type(b)) # <class 'bytes'>
print(type(s2)) # <class 'str'>ејәи°ғдёҖзӮ№пјҡдёҚеҗҢзј–з Ғд№Ӣй—ҙеҸӘиғҪйҖҡиҝҮ Unicode зј–з Ғж–№ејҸжқҘзӣёдә’иҪ¬еҢ–
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«Python3зј–з ҒжҖҺж ·е®һзҺ°зӣёдә’иҪ¬еҢ–еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢйҒҮеҲ°й—®йўҳе°ұжүҫдәҝйҖҹдә‘пјҢиҜҰз»Ҷзҡ„и§ЈеҶіж–№жі•зӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ