жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶжҖҺд№Ҳи§Јжһҗsparkзҡ„е®ҪзӘ„дҫқиө–е’ҢжҢҒд№…еҢ–пјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
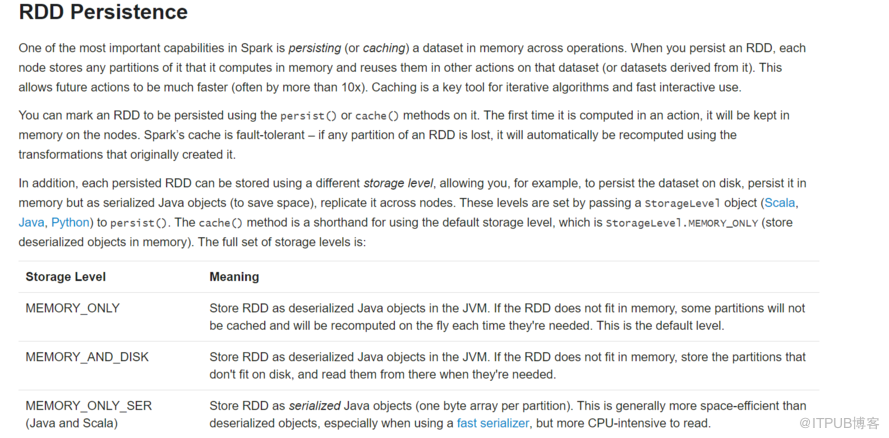
cacheеә•еұӮи°ғз”Ёзҡ„жҳҜpersisit пјҢй»ҳи®ӨеҸӮж•°жҳҜStorageLevel.MEMORY_ONLY cache з”Ёе®ҢжңҖеҘҪжүӢеҠЁе№ІжҺү

жҳҜеҗҰдҪҝз”ЁзЈҒзӣҳ жҳҜеҗҰдҪҝз”ЁеҶ…еӯҳ дёҚз®Ў еҸҚеәҸеҲ—еҢ– еүҜжң¬
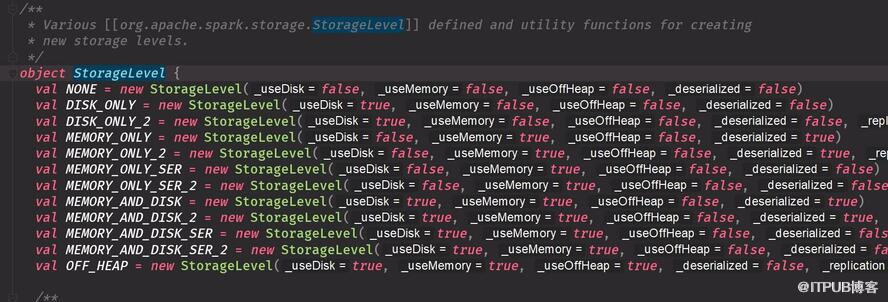

йҖүжӢ©й»ҳи®Ө第дёҖз§ҚMEMORY_ONLY еҶ…еӯҳдёҚеӨҹйҖүжҖҺеәҸеҲ—еҢ– зЈҒзӣҳжңҖеҘҪеҲ«йҖүжӢ© дёҚиҰҒз”ЁиҝҷдёӘеүҜжң¬еҪўејҸиҖ—еҶ…еӯҳ зј“еӯҳйҖүжӢ©пјҡ SparkвҖҷs storage levels are meant to provide different trade-offs пјҲжқғиЎЎпјүbetween memory usage and CPU efficiency.We recommend going through the following process to select one: йҖүжӢ©ж–№ејҸ дјҳе…Ҳзә§д»ҺдёҠеҲ°дёӢ дјҳе…ҲйҖүжӢ©з¬¬дёҖдёӘMEMORY_ONLY пјҢеҶ…еӯҳе®һеңЁдёҚеӨҹе°ұеәҸеҲ—еҢ– If your RDDs fit comfortably with the default storage level (MEMORY_ONLY), leave them that way й»ҳи®ӨеҸҜд»Ҙжҗһе®ҡе°ұз”Ёй»ҳи®Өзҡ„. This is the most CPU-efficient option, allowing operations on the RDDs to run as fast as possible. дёҚиҰҒйҖүжӢ©javaзҡ„еәҸеҲ—еҢ– If not, try using MEMORY_ONLY_SER and selecting a fast serialization library to make the objects much more space-efficient з©әй—ҙеҫҲеҘҪ, but still reasonably fast to access. (Java and Scala) DonвҖҷt spill to disk дёҚиҰҒж”ҫеҲ°зЈҒзӣҳ unless the functions that computed your datasets are expensive, or they filter a large amount of the data. Otherwise, recomputing a partition may be as fast as reading it from disk.
е®Ҫдҫқиө–з”Ёshufer е®ҪзӘ„дҫқиө–е®№й”ҷзЁӢеәҰдёҚдёҖж · дёҖдёӘshufferдә§з”ҹдёӨдёӘstageпјҢдёӨдёӘдә§з”ҹдёүдёӘstageзӯүзӯү Lineage иЎҖзјҳе…ізі» з”ЁдәҺе®№й”ҷеҫҲеӨҡйғҪжҳҜи®°еҪ•зҡ„ textfile =гҖӢ xx => yy жҸҸиҝ°зҡ„жҳҜдёҖдёӘRDDеҰӮдҪ•д»ҺзҲ¶RDDиҝҮжқҘзҡ„ RDDдҪңз”ЁдёҖдёӘеҮҪж•°е°ұжҳҜеҜ№RDDйҮҢйқўзҡ„еҲҶеҢәдҪңз”ЁдёҖдёӘеҮҪж•° дёўеӨұдәҶж №жҚ®зҲ¶RDDйҮҚж–°з®—дёҖдёӢ dependence е®Ҫдҫқиө–пјҡдёҖдёӘзҲ¶RDDзҡ„partitionиҮіеӨҡиў«еӯҗRDDзҡ„жҹҗдёӘpartitionдҪҝз”ЁдёҖж¬Ў жІЎshuffer pipline дёўдёҖдёӘе°ұзӣҙжҺҘжӢҝеҮәжқҘи®Ўз®—е°ұеҸҜд»Ҙ зӘ„дҫқиө–пјҡдёҖдёӘзҲ¶RDDзҡ„parttitonдјҡиў«еӯҗRDDзҡ„partitioдҪҝз”ЁеӨҡж¬Ў жңүshuffer е®Ҫдҫқиө–жҢӮжҺүдәҶиҰҒд»ҺзҲ¶RDDе…ЁйғЁи®Ўз®— жңүзҡ„ж—¶еҖҷи§ЈеҶіж•°жҚ®еҖҫж–ңйңҖиҰҒshuffer 他们容й”ҷзЁӢеәҰдёҚдёҖж ·зҡ„ жңүshufferе°ұдјҡз”ҹжҲҗstage жҖ»з»“пјҡиҖҒеӯҗиў«е„ҝеӯҗз”ЁеҮ ж¬ЎпјҢеӨҡдёӘеӯ©еӯҗпјҲе®ҪпјүжҲ–еҚ•дёӘеӯ©еӯҗпјҲзӘ„пјү
driver е°ұжҳҜmainж–№жі• дёӯеҲӣе»әsparkcontext action дә§з”ҹjob ,shuffer дә§з”ҹstage ,stage йҮҢжҳҜtask
дёҠиҝ°еҶ…е®№е°ұжҳҜжҖҺд№Ҳи§Јжһҗsparkзҡ„е®ҪзӘ„дҫқиө–е’ҢжҢҒд№…еҢ–пјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ