您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章为大家展示了如何用Python爬虫抓取代理IP,内容简明扼要并且容易理解,绝对能使你眼前一亮,通过这篇文章的详细介绍希望你能有所收获。
目前网上有许多代理ip,有免费的也有付费的。免费的虽然不用花钱但有效的代理很少且不稳定,付费的可能会好一点 下面讲一下代理IP的试用,将可用ip存入MongoDB,方便下次取出。
运行平台:Windows
Python版本:Python3.6
IDE: Sublime Text
其他:Chrome浏览器
简述流程为:
步骤1:了解requests代理如何使用
步骤2:从代理网页爬取到ip和端口
步骤3:检测爬取到的ip是否可用
步骤4:将爬取的可用代理存入MongoDB
步骤5:从存入可用ip的数据库里随机抽取一个ip,测试成功后返回
对于requests来说,代理的设置比较简单,只需要传入proxies参数即可。
不过需要注意的是,这里我是在本机安装了抓包工具Fiddler,并用它在本地端口8888创建了一个HTTP代理服务(用Chrome插件SwitchyOmega),即代理服务为:127.0.0.1:8888,我们只要设置好这个代理,就可以成功将本机ip切换成代理软件连接的服务器ip了。
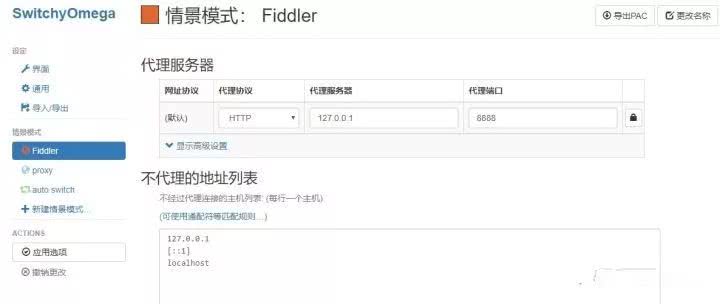
这里我是用来http://httpbin.org/get作为测试网站,我们访问该网页可以得到请求的有关信息,其中origin字段就是客户端ip,我们可以根据返回的结果判断代理是否成功。返回结果如下:
接下来我们便开始爬取代理IP,首先我们打开Chrome浏览器查看网页,并找到ip和端口元素的信息。
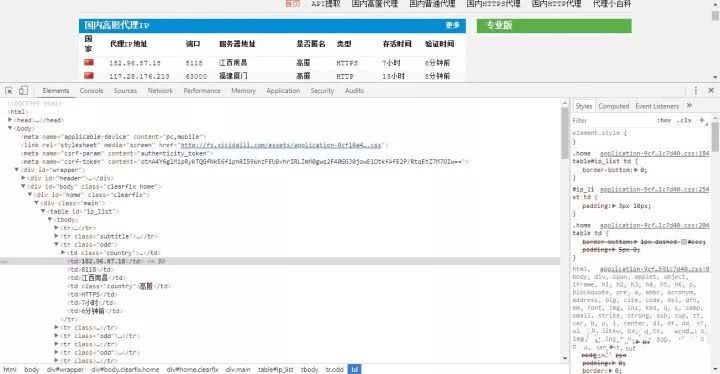
可以看到,代理IP以表格存储ip地址及其相关信息,所以我们用BeautifulSoup提取时很方便便能提取出相关信息,但是我们需要注意的是,爬取的ip很有可能出现重复的现象,尤其是我们同时爬取多个代理网页又存储到同一数组中时,所以我们可以使用集合来去除重复的ip。

将要爬取页数的ip爬取好后存入数组,然后再对其中的ip逐一测试。
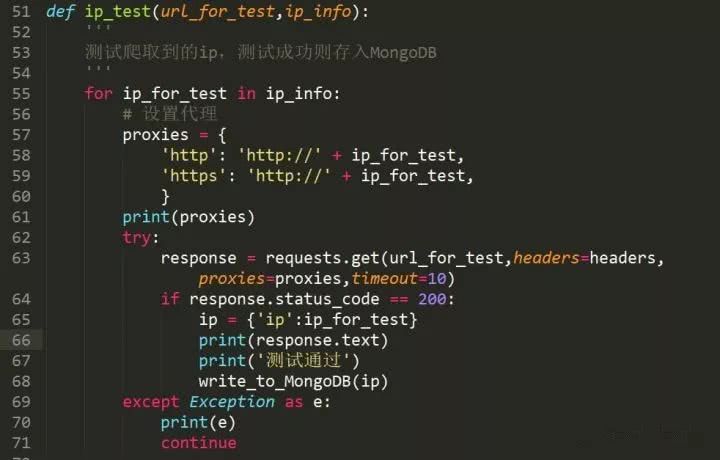
这里就用到了上面提到的requests设置代理的方法,我们使用http://httpbin.org/ip作为测试网站,它可以直接返回我们的ip地址,测试通过后再存入MomgoDB数据库。
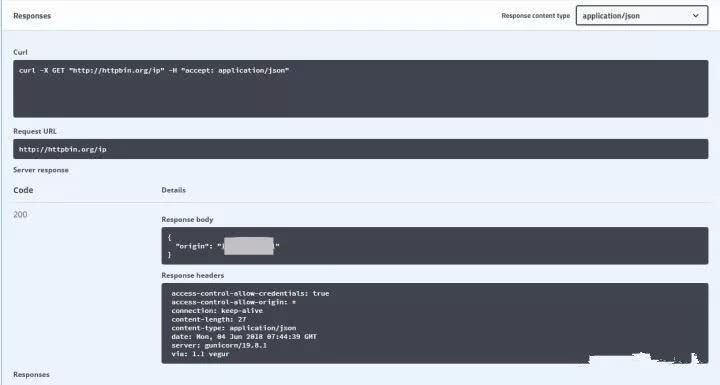
连接数据库然后指定数据库和集合,再将数据插入就OK了。
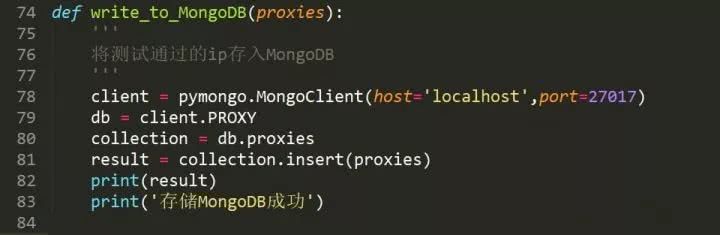
最后运行查看一下结果吧
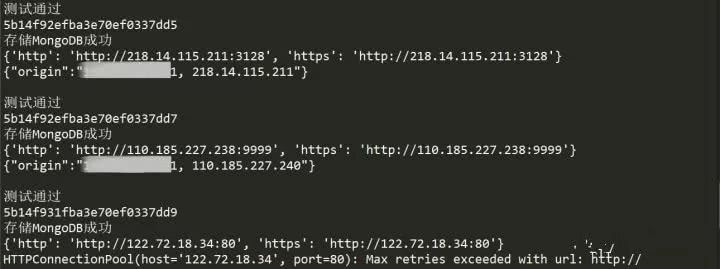
运行了一段时间后,难得看到一连三个测试通过,赶紧截图保存一下,事实上是,毕竟是免费代理IP,有效的还是很少的,并且存活时间确实很短,不过,爬取的量大,还是能找到可用的,我们只是用作练习的话,还是勉强够用的。现在看看数据库里存储的吧。

因为爬取的页数不多,加上有效ip也少,再加上我没怎么爬,所以现在数据库里的ip并不多,不过也算是将这些ip给存了下来。现在就来看看怎么随机取出来吧。
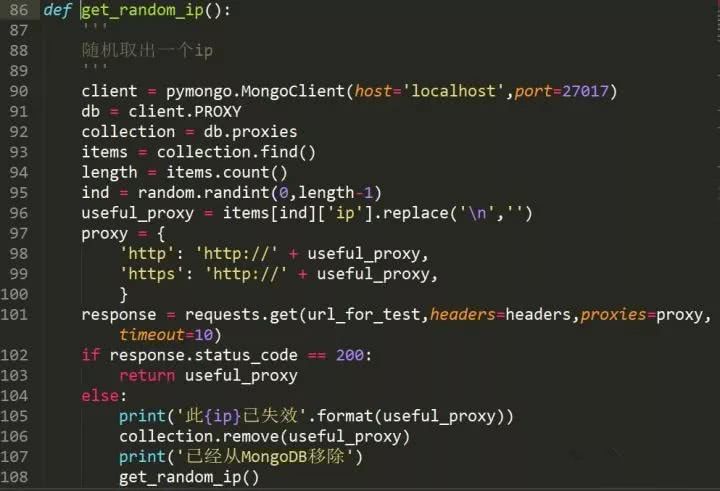
由于担心放入数据库一段时间后ip会失效,所以取出前我重新进行了一次测试,如果成功再返回ip,不成功的话就直接将其移出数据库。
这样我们需要使用代理的时候,就能通过数据库随时取出来了。
总的代码如下:
zhihu.com/people/hdmi-blog
上述内容就是如何用Python爬虫抓取代理IP,你们学到知识或技能了吗?如果还想学到更多技能或者丰富自己的知识储备,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。