您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“如何用Numpy分析各类用户占比”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“如何用Numpy分析各类用户占比”吧!
观察上次的数据,数据中有的数据有会员与非会员两种用户类别。
这次我们主要分析一下两种类别用户在数据中占比。
根据流程示意图我们主要遵循下面几个步骤:

此处代码为:
# 数据读取,数据清洗
def read_clean_data():
clndata_arr_list = []
for data_filename in data_filenames:
file = os.path.join(data_path, data_filename)
data_arr = np.loadtxt(file, skiprows=1, delimiter=',', dtype=bytes).astype(str)
cln_arr = np.core.defchararray.replace(data_arr[:, -1], '"', '')
cln_arr = cln_arr.reshape(-1,1)
clndata_arr_list.append(cln_arr)
year_cln_arr = np.concatenate(clndata_arr_list)
return year_cln_arr
这里需要注意两点:
因为数据较大,我们没有数据文件具体数据量,所以在使用numpy.reshape时我们可以使用numpy.reshape(-1,1)这样numpy可以使用统计后的具体数值替换-1。
我们对数据的需求不再是获取时间的平均值,只需获取数据最后一列并使用concatenate方法堆叠到一起以便下一步处理。
根据这次的分析目标,我们取出最后一列Member type。
在上一步我们已经获取了全部的数值,在本部只需筛选统计出会员与非会员的数值就可以了。
我们可以先看下完成后的这部分代码:
# 数据分析
def mean_data(year_cln_arr):
member = year_cln_arr[year_cln_arr == 'Member'].shape[0]
casual = year_cln_arr[year_cln_arr == 'Casual'].shape[0]
users = [member,casual]
print(users)
return users
同样,这里使用numpy.shape获取用户分类的具体数据。
生成的饼图:
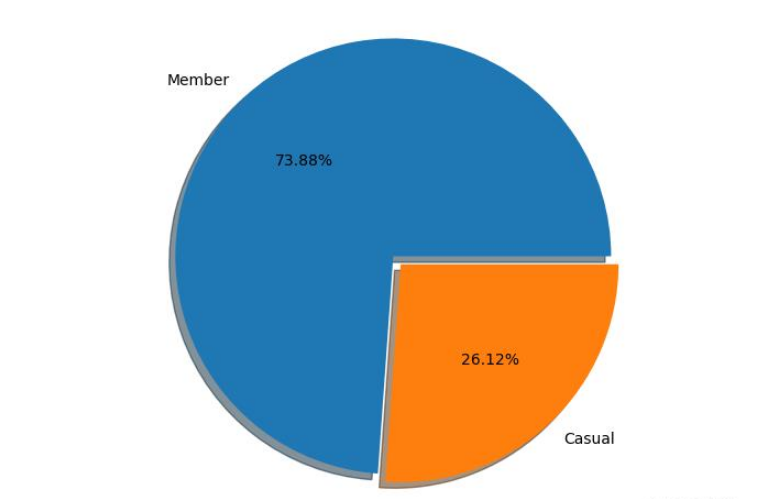
下面是生成饼图的代码:
# 结果展示
plt.figure()
plt.pie(users, labels=['Member', 'Casual'], autopct='%.2f%%', shadow=True, explode=(0.05, 0))
plt.axis('equal')
plt.tight_layout()
plt.savefig(os.path.join(output_path, './piechart.png'))
plt.show()
到此,相信大家对“如何用Numpy分析各类用户占比”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。