жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е“ҲеёҢиЎЁпјҲhash tableпјүд№ҹеҸ«ж•ЈеҲ—иЎЁпјҢжҳҜдёҖз§ҚйқһеёёйҮҚиҰҒзҡ„ж•°жҚ®з»“жһ„пјҢеә”з”ЁеңәжҷҜеҸҠе…¶дё°еҜҢпјҢи®ёеӨҡзј“еӯҳжҠҖжңҜпјҲжҜ”еҰӮmemcachedпјүзҡ„ж ёеҝғе…¶е®һе°ұжҳҜеңЁеҶ…еӯҳдёӯз»ҙжҠӨдёҖеј еӨ§зҡ„е“ҲеёҢиЎЁпјҢиҖҢHashMapзҡ„е®һзҺ°еҺҹзҗҶд№ҹеёёеёёеҮәзҺ°еңЁеҗ„зұ»зҡ„йқўиҜ•йўҳдёӯпјҢйҮҚиҰҒжҖ§еҸҜи§ҒдёҖж–‘гҖӮжң¬ж–ҮдјҡеҜ№javaйӣҶеҗҲжЎҶжһ¶дёӯзҡ„еҜ№еә”е®һзҺ°HashMapзҡ„е®һзҺ°еҺҹзҗҶиҝӣиЎҢи®Іи§ЈпјҢ然еҗҺдјҡеҜ№JDK7зҡ„HashMapжәҗз ҒиҝӣиЎҢеҲҶжһҗгҖӮ
зӣ®еҪ•
гҖҖгҖҖдёҖгҖҒ д»Җд№ҲжҳҜе“ҲеёҢиЎЁ
гҖҖгҖҖдәҢгҖҒ HashMapе®һзҺ°еҺҹзҗҶ
гҖҖгҖҖдёүгҖҒ дёәдҪ•HashMapзҡ„ж•°з»„й•ҝеәҰдёҖе®ҡжҳҜ2зҡ„ж¬Ўе№Ӯпјҹ
гҖҖгҖҖеӣӣгҖҒ йҮҚеҶҷequalsж–№жі•йңҖеҗҢж—¶йҮҚеҶҷhashCodeж–№жі•
гҖҖгҖҖдә”гҖҒ жҖ»з»“
гҖҖгҖҖеңЁи®Ёи®әе“ҲеёҢиЎЁд№ӢеүҚпјҢжҲ‘们е…ҲеӨ§жҰӮдәҶи§ЈдёӢе…¶д»–ж•°жҚ®з»“жһ„еңЁж–°еўһпјҢжҹҘжүҫзӯүеҹәзЎҖж“ҚдҪңжү§иЎҢжҖ§иғҪ
гҖҖгҖҖ ж•°з»„ пјҡйҮҮз”ЁдёҖж®өиҝһз»ӯзҡ„еӯҳеӮЁеҚ•е…ғжқҘеӯҳеӮЁж•°жҚ®гҖӮеҜ№дәҺжҢҮе®ҡдёӢж Үзҡ„жҹҘжүҫпјҢж—¶й—ҙеӨҚжқӮеәҰдёәO(1)пјӣйҖҡиҝҮз»ҷе®ҡеҖјиҝӣиЎҢжҹҘжүҫпјҢйңҖиҰҒйҒҚеҺҶж•°з»„пјҢйҖҗдёҖжҜ”еҜ№з»ҷе®ҡе…ій”®еӯ—е’Ңж•°з»„е…ғзҙ пјҢж—¶й—ҙеӨҚжқӮеәҰдёәO(n)пјҢеҪ“然пјҢеҜ№дәҺжңүеәҸж•°з»„пјҢеҲҷеҸҜйҮҮз”ЁдәҢеҲҶжҹҘжүҫпјҢжҸ’еҖјжҹҘжүҫпјҢж–җжіўйӮЈеҘ‘жҹҘжүҫзӯүж–№ејҸпјҢеҸҜе°ҶжҹҘжүҫеӨҚжқӮеәҰжҸҗй«ҳдёәO(logn)пјӣеҜ№дәҺдёҖиҲ¬зҡ„жҸ’е…ҘеҲ йҷӨж“ҚдҪңпјҢж¶үеҸҠеҲ°ж•°з»„е…ғзҙ зҡ„移еҠЁпјҢе…¶е№іеқҮеӨҚжқӮеәҰд№ҹдёәO(n)
гҖҖгҖҖ зәҝжҖ§й“ҫиЎЁ пјҡеҜ№дәҺй“ҫиЎЁзҡ„ж–°еўһпјҢеҲ йҷӨзӯүж“ҚдҪңпјҲеңЁжүҫеҲ°жҢҮе®ҡж“ҚдҪңдҪҚзҪ®еҗҺпјүпјҢд»…йңҖеӨ„зҗҶз»“зӮ№й—ҙзҡ„еј•з”ЁеҚіеҸҜпјҢж—¶й—ҙеӨҚжқӮеәҰдёәO(1)пјҢиҖҢжҹҘжүҫж“ҚдҪңйңҖиҰҒйҒҚеҺҶй“ҫиЎЁйҖҗдёҖиҝӣиЎҢжҜ”еҜ№пјҢеӨҚжқӮеәҰдёәO(n)
гҖҖгҖҖ дәҢеҸүж ‘ пјҡеҜ№дёҖжЈөзӣёеҜ№е№іиЎЎзҡ„жңүеәҸдәҢеҸүж ‘пјҢеҜ№е…¶иҝӣиЎҢжҸ’е…ҘпјҢжҹҘжүҫпјҢеҲ йҷӨзӯүж“ҚдҪңпјҢе№іеқҮеӨҚжқӮеәҰеқҮдёәO(logn)гҖӮ
гҖҖгҖҖ е“ҲеёҢиЎЁ пјҡзӣёжҜ”дёҠиҝ°еҮ з§Қж•°жҚ®з»“жһ„пјҢеңЁе“ҲеёҢиЎЁдёӯиҝӣиЎҢж·»еҠ пјҢеҲ йҷӨпјҢжҹҘжүҫзӯүж“ҚдҪңпјҢжҖ§иғҪеҚҒеҲҶд№Ӣй«ҳпјҢдёҚиҖғиҷ‘е“ҲеёҢеҶІзӘҒзҡ„жғ…еҶөдёӢпјҢд»…йңҖдёҖж¬Ўе®ҡдҪҚеҚіеҸҜе®ҢжҲҗпјҢж—¶й—ҙеӨҚжқӮеәҰдёәO(1)пјҢжҺҘдёӢжқҘжҲ‘们е°ұжқҘзңӢзңӢе“ҲеёҢиЎЁжҳҜеҰӮдҪ•е®һзҺ°иҫҫеҲ°жғҠиүізҡ„еёёж•°йҳ¶O(1)зҡ„гҖӮ
гҖҖгҖҖжҲ‘们зҹҘйҒ“пјҢж•°жҚ®з»“жһ„зҡ„зү©зҗҶеӯҳеӮЁз»“жһ„еҸӘжңүдёӨз§Қпјҡ йЎәеәҸеӯҳеӮЁз»“жһ„ е’Ң й“ҫејҸеӯҳеӮЁз»“жһ„ пјҲеғҸж ҲпјҢйҳҹеҲ—пјҢж ‘пјҢеӣҫзӯүжҳҜд»ҺйҖ»иҫ‘з»“жһ„еҺ»жҠҪиұЎзҡ„пјҢжҳ е°„еҲ°еҶ…еӯҳдёӯпјҢд№ҹиҝҷдёӨз§Қзү©зҗҶз»„з»ҮеҪўејҸпјүпјҢиҖҢеңЁдёҠйқўжҲ‘们жҸҗеҲ°иҝҮпјҢеңЁж•°з»„дёӯж №жҚ®дёӢж ҮжҹҘжүҫжҹҗдёӘе…ғзҙ пјҢдёҖж¬Ўе®ҡдҪҚе°ұеҸҜд»ҘиҫҫеҲ°пјҢе“ҲеёҢиЎЁеҲ©з”ЁдәҶиҝҷз§Қзү№жҖ§пјҢ е“ҲеёҢиЎЁзҡ„дё»е№Іе°ұжҳҜж•°з»„ гҖӮ
гҖҖгҖҖжҜ”еҰӮжҲ‘们иҰҒж–°еўһжҲ–жҹҘжүҫжҹҗдёӘе…ғзҙ пјҢжҲ‘们йҖҡиҝҮжҠҠеҪ“еүҚе…ғзҙ зҡ„е…ій”®еӯ— йҖҡиҝҮжҹҗдёӘеҮҪж•°жҳ е°„еҲ°ж•°з»„дёӯзҡ„жҹҗдёӘдҪҚзҪ®пјҢйҖҡиҝҮж•°з»„дёӢж ҮдёҖж¬Ўе®ҡдҪҚе°ұеҸҜе®ҢжҲҗж“ҚдҪңгҖӮ
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ еӯҳеӮЁдҪҚзҪ® = f(е…ій”®еӯ—)
гҖҖ гҖҖе…¶дёӯпјҢиҝҷдёӘеҮҪж•°fдёҖиҲ¬з§°дёә е“ҲеёҢеҮҪж•° пјҢиҝҷдёӘеҮҪж•°зҡ„и®ҫи®ЎеҘҪеқҸдјҡзӣҙжҺҘеҪұе“ҚеҲ°е“ҲеёҢиЎЁзҡ„дјҳеҠЈгҖӮдёҫдёӘдҫӢеӯҗпјҢжҜ”еҰӮжҲ‘们иҰҒеңЁе“ҲеёҢиЎЁдёӯжү§иЎҢжҸ’е…Ҙж“ҚдҪңпјҡ
гҖҖгҖҖ
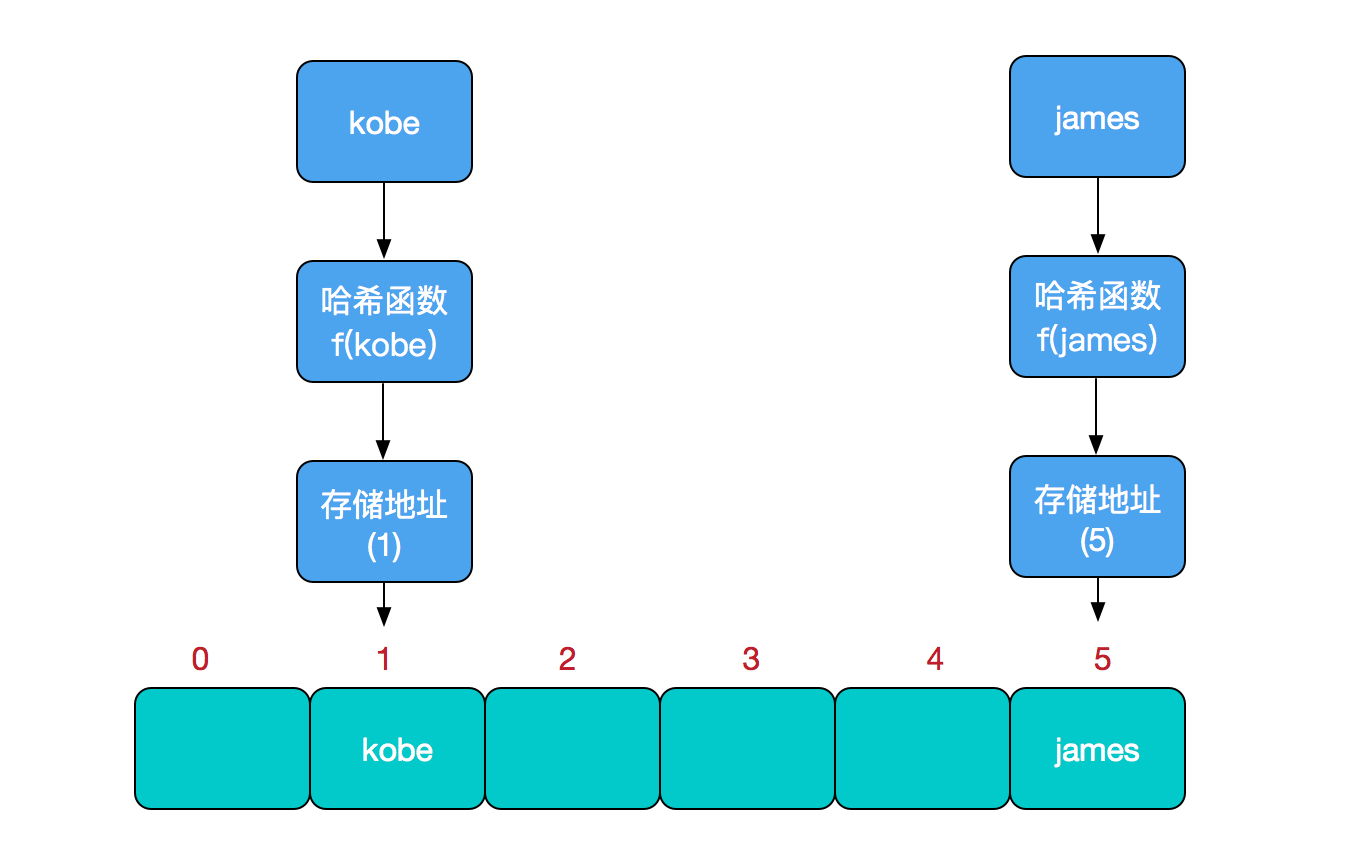
гҖҖгҖҖжҹҘжүҫж“ҚдҪңеҗҢзҗҶпјҢе…ҲйҖҡиҝҮе“ҲеёҢеҮҪж•°и®Ўз®—еҮәе®һйҷ…еӯҳеӮЁең°еқҖпјҢ然еҗҺд»Һж•°з»„дёӯеҜ№еә”ең°еқҖеҸ–еҮәеҚіеҸҜгҖӮ
гҖҖгҖҖ е“ҲеёҢеҶІзӘҒ
гҖҖгҖҖ然иҖҢдёҮдәӢж— е®ҢзҫҺпјҢеҰӮжһңдёӨдёӘдёҚеҗҢзҡ„е…ғзҙ пјҢйҖҡиҝҮе“ҲеёҢеҮҪж•°еҫ—еҮәзҡ„е®һйҷ…еӯҳеӮЁең°еқҖзӣёеҗҢжҖҺд№ҲеҠһпјҹд№ҹе°ұжҳҜиҜҙпјҢеҪ“жҲ‘们еҜ№жҹҗдёӘе…ғзҙ иҝӣиЎҢе“ҲеёҢиҝҗз®—пјҢеҫ—еҲ°дёҖдёӘеӯҳеӮЁең°еқҖпјҢ然еҗҺиҰҒиҝӣиЎҢжҸ’е…Ҙзҡ„ж—¶еҖҷпјҢеҸ‘зҺ°е·Із»Ҹиў«е…¶д»–е…ғзҙ еҚ з”ЁдәҶпјҢе…¶е®һиҝҷе°ұжҳҜжүҖи°“зҡ„ е“ҲеёҢеҶІзӘҒ пјҢд№ҹеҸ«е“ҲеёҢзў°ж’һгҖӮеүҚйқўжҲ‘们жҸҗеҲ°иҝҮпјҢе“ҲеёҢеҮҪж•°зҡ„и®ҫи®ЎиҮіе…ійҮҚиҰҒпјҢеҘҪзҡ„е“ҲеёҢеҮҪж•°дјҡе°ҪеҸҜиғҪең°дҝқиҜҒ и®Ўз®—з®ҖеҚ• е’Ң ж•ЈеҲ—ең°еқҖеҲҶеёғеқҮеҢҖ, дҪҶжҳҜпјҢжҲ‘们йңҖиҰҒжё…жҘҡзҡ„жҳҜпјҢж•°з»„жҳҜдёҖеқ—иҝһз»ӯзҡ„еӣәе®ҡй•ҝеәҰзҡ„еҶ…еӯҳз©әй—ҙпјҢеҶҚеҘҪзҡ„е“ҲеёҢеҮҪж•°д№ҹдёҚиғҪдҝқиҜҒеҫ—еҲ°зҡ„еӯҳеӮЁең°еқҖз»қеҜ№дёҚеҸ‘з”ҹеҶІзӘҒгҖӮйӮЈд№Ҳе“ҲеёҢеҶІзӘҒеҰӮдҪ•и§ЈеҶіе‘ўпјҹе“ҲеёҢеҶІзӘҒзҡ„и§ЈеҶіж–№жЎҲжңүеӨҡз§Қ:ејҖж”ҫе®ҡеқҖжі•пјҲеҸ‘з”ҹеҶІзӘҒпјҢ继з»ӯеҜ»жүҫдёӢдёҖеқ—жңӘиў«еҚ з”Ёзҡ„еӯҳеӮЁең°еқҖпјүпјҢеҶҚж•ЈеҲ—еҮҪж•°жі•пјҢй“ҫең°еқҖжі•пјҢиҖҢHashMapеҚіжҳҜйҮҮз”ЁдәҶй“ҫең°еқҖжі•пјҢд№ҹе°ұжҳҜ ж•°з»„+й“ҫиЎЁ зҡ„ж–№ејҸпјҢ
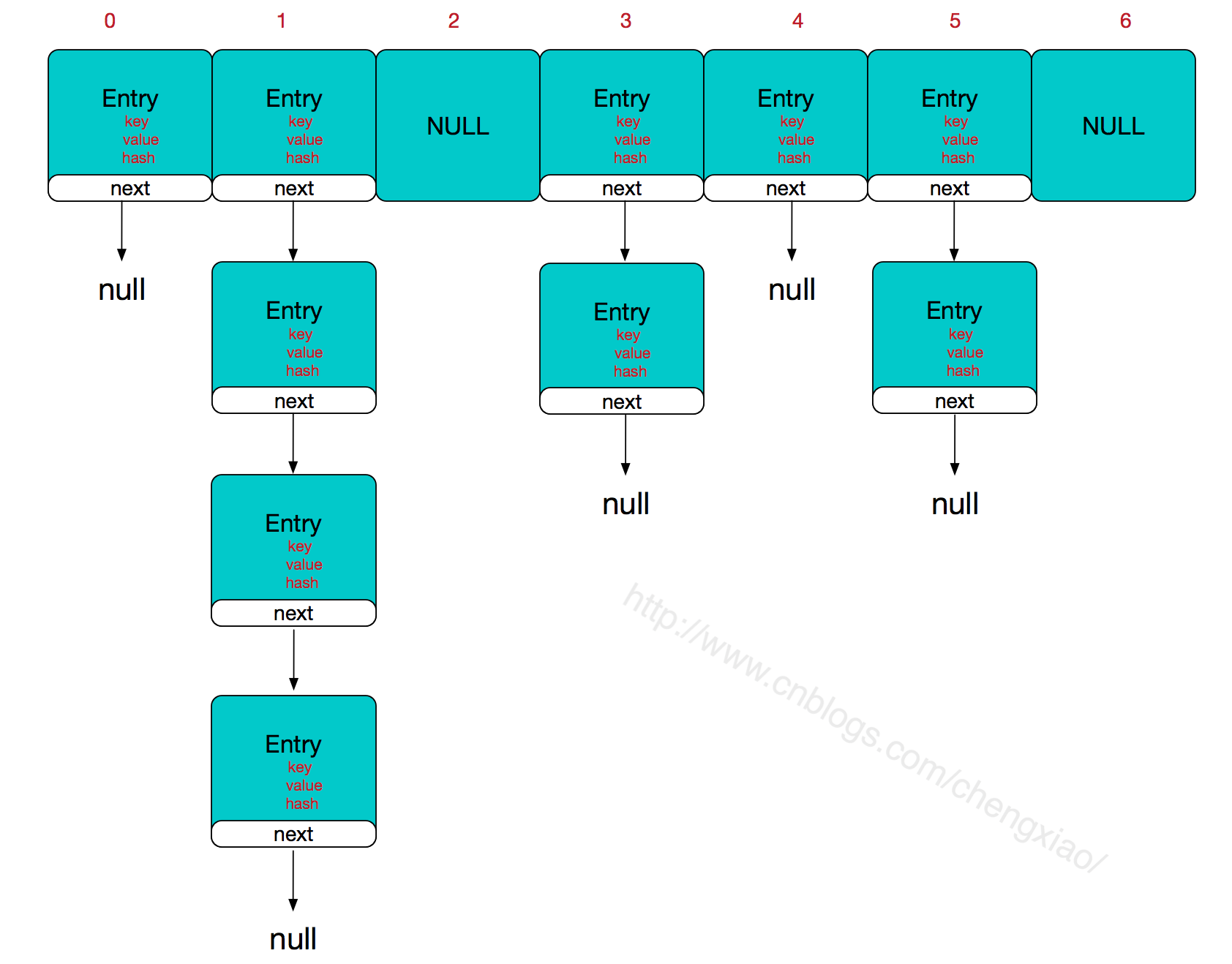
гҖҖHashMapзҡ„дё»е№ІжҳҜдёҖдёӘEntryж•°з»„гҖӮEntryжҳҜHashMapзҡ„еҹәжң¬з»„жҲҗеҚ•е…ғпјҢжҜҸдёҖдёӘEntryеҢ…еҗ«дёҖдёӘkey-valueй”®еҖјеҜ№гҖӮ
//HashMapзҡ„дё»е№Іж•°з»„пјҢеҸҜд»ҘзңӢеҲ°е°ұжҳҜдёҖдёӘEntryж•°з»„пјҢеҲқе§ӢеҖјдёәз©әж•°з»„{}пјҢдё»е№Іж•°з»„зҡ„й•ҝеәҰдёҖе®ҡжҳҜ2зҡ„ж¬Ўе№ӮпјҢиҮідәҺдёәд»Җд№Ҳиҝҷд№ҲеҒҡпјҢеҗҺйқўдјҡжңүиҜҰз»ҶеҲҶжһҗгҖӮ
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
EntryжҳҜHashMapдёӯзҡ„дёҖдёӘйқҷжҖҒеҶ…йғЁзұ»гҖӮд»Јз ҒеҰӮдёӢ
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;//еӯҳеӮЁжҢҮеҗ‘дёӢдёҖдёӘEntryзҡ„еј•з”ЁпјҢеҚ•й“ҫиЎЁз»“жһ„
int hash;//еҜ№keyзҡ„hashcodeеҖјиҝӣиЎҢhashиҝҗз®—еҗҺеҫ—еҲ°зҡ„еҖјпјҢеӯҳеӮЁеңЁEntryпјҢйҒҝе…ҚйҮҚеӨҚи®Ўз®—
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
жүҖд»ҘпјҢHashMapзҡ„ж•ҙдҪ“з»“жһ„еҰӮдёӢ
 гҖҖгҖҖ
гҖҖгҖҖ
гҖҖгҖҖ з®ҖеҚ•жқҘиҜҙпјҢHashMapз”ұж•°з»„+й“ҫиЎЁз»„жҲҗзҡ„пјҢж•°з»„жҳҜHashMapзҡ„дё»дҪ“пјҢй“ҫиЎЁеҲҷжҳҜдё»иҰҒдёәдәҶи§ЈеҶіе“ҲеёҢеҶІзӘҒиҖҢеӯҳеңЁзҡ„пјҢеҰӮжһңе®ҡдҪҚеҲ°зҡ„ж•°з»„дҪҚзҪ®дёҚеҗ«й“ҫиЎЁпјҲеҪ“еүҚentryзҡ„nextжҢҮеҗ‘nullпјү,йӮЈд№ҲеҜ№дәҺжҹҘжүҫпјҢж·»еҠ зӯүж“ҚдҪңеҫҲеҝ«пјҢд»…йңҖдёҖж¬ЎеҜ»еқҖеҚіеҸҜпјӣеҰӮжһңе®ҡдҪҚеҲ°зҡ„ж•°з»„еҢ…еҗ«й“ҫиЎЁпјҢеҜ№дәҺж·»еҠ ж“ҚдҪңпјҢе…¶ж—¶й—ҙеӨҚжқӮеәҰдёәO(n)пјҢйҰ–е…ҲйҒҚеҺҶй“ҫиЎЁпјҢеӯҳеңЁеҚіиҰҶзӣ–пјҢеҗҰеҲҷж–°еўһпјӣеҜ№дәҺжҹҘжүҫж“ҚдҪңжқҘи®ІпјҢд»ҚйңҖйҒҚеҺҶй“ҫиЎЁпјҢ然еҗҺйҖҡиҝҮkeyеҜ№иұЎзҡ„equalsж–№жі•йҖҗдёҖжҜ”еҜ№жҹҘжүҫгҖӮжүҖд»ҘпјҢжҖ§иғҪиҖғиҷ‘пјҢHashMapдёӯзҡ„й“ҫиЎЁеҮәзҺ°и¶Ҡе°‘пјҢжҖ§иғҪжүҚдјҡи¶ҠеҘҪгҖӮ
е…¶д»–еҮ дёӘйҮҚиҰҒеӯ—ж®ө
//е®һйҷ…еӯҳеӮЁзҡ„key-valueй”®еҖјеҜ№зҡ„дёӘж•°
transient int size;
//йҳҲеҖјпјҢеҪ“table == {}ж—¶пјҢиҜҘеҖјдёәеҲқе§Ӣе®№йҮҸпјҲеҲқе§Ӣе®№йҮҸй»ҳи®Өдёә16пјүпјӣеҪ“tableиў«еЎ«е……дәҶпјҢд№ҹе°ұжҳҜдёәtableеҲҶй…ҚеҶ…еӯҳз©әй—ҙеҗҺпјҢthresholdдёҖиҲ¬дёә capacity*loadFactoryгҖӮHashMapеңЁиҝӣиЎҢжү©е®№ж—¶йңҖиҰҒеҸӮиҖғthresholdпјҢеҗҺйқўдјҡиҜҰз»Ҷи°ҲеҲ°
int threshold;
//иҙҹиҪҪеӣ еӯҗпјҢд»ЈиЎЁдәҶtableзҡ„еЎ«е……еәҰжңүеӨҡе°‘пјҢй»ҳи®ӨжҳҜ0.75
final float loadFactor;
//з”ЁдәҺеҝ«йҖҹеӨұиҙҘпјҢз”ұдәҺHashMapйқһзәҝзЁӢе®үе…ЁпјҢеңЁеҜ№HashMapиҝӣиЎҢиҝӯд»Јж—¶пјҢеҰӮжһңжңҹй—ҙе…¶д»–зәҝзЁӢзҡ„еҸӮдёҺеҜјиҮҙHashMapзҡ„з»“жһ„еҸ‘з”ҹеҸҳеҢ–дәҶпјҲжҜ”еҰӮputпјҢremoveзӯүж“ҚдҪңпјүпјҢйңҖиҰҒжҠӣеҮәејӮеёёConcurrentModificationException
transient int modCount;
HashMapжңү4дёӘжһ„йҖ еҷЁпјҢе…¶д»–жһ„йҖ еҷЁеҰӮжһңз”ЁжҲ·жІЎжңүдј е…ҘinitialCapacity е’ҢloadFactorиҝҷдёӨдёӘеҸӮж•°пјҢдјҡдҪҝз”Ёй»ҳи®ӨеҖј
initialCapacityй»ҳи®Өдёә16пјҢloadFactoryй»ҳи®Өдёә0.75
жҲ‘们зңӢдёӢе…¶дёӯдёҖдёӘ
public HashMap(int initialCapacity, float loadFactor) {
гҖҖгҖҖгҖҖгҖҖгҖҖ//жӯӨеӨ„еҜ№дј е…Ҙзҡ„еҲқе§Ӣе®№йҮҸиҝӣиЎҢж ЎйӘҢпјҢжңҖеӨ§дёҚиғҪи¶…иҝҮMAXIMUM_CAPACITY = 1<<30(230)
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
гҖҖгҖҖгҖҖгҖҖгҖҖ
init();//initж–№жі•еңЁHashMapдёӯжІЎжңүе®һйҷ…е®һзҺ°пјҢдёҚиҝҮеңЁе…¶еӯҗзұ»еҰӮ linkedHashMapдёӯе°ұдјҡжңүеҜ№еә”е®һзҺ°
}
гҖҖгҖҖд»ҺдёҠйқўиҝҷж®өд»Јз ҒжҲ‘们еҸҜд»ҘзңӢеҮәпјҢ еңЁеёёи§„жһ„йҖ еҷЁдёӯпјҢжІЎжңүдёәж•°з»„tableеҲҶй…ҚеҶ…еӯҳз©әй—ҙпјҲжңүдёҖдёӘе…ҘеҸӮдёәжҢҮе®ҡMapзҡ„жһ„йҖ еҷЁдҫӢеӨ–пјүпјҢиҖҢжҳҜеңЁжү§иЎҢputж“ҚдҪңзҡ„ж—¶еҖҷжүҚзңҹжӯЈжһ„е»әtableж•°з»„
гҖҖгҖҖOK,жҺҘдёӢжқҘжҲ‘们жқҘзңӢзңӢputж“ҚдҪңзҡ„е®һзҺ°еҗ§
public V put(K key, V value) {
//еҰӮжһңtableж•°з»„дёәз©әж•°з»„{}пјҢиҝӣиЎҢж•°з»„еЎ«е……пјҲдёәtableеҲҶй…Қе®һйҷ…еҶ…еӯҳз©әй—ҙпјүпјҢе…ҘеҸӮдёәthresholdпјҢжӯӨж—¶thresholdдёәinitialCapacity й»ҳи®ӨжҳҜ1<<4(24=16)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
//еҰӮжһңkeyдёәnullпјҢеӯҳеӮЁдҪҚзҪ®дёәtable[0]жҲ–table[0]зҡ„еҶІзӘҒй“ҫдёҠ
if (key == null)
return putForNullKey(value);
int hash = hash(key);//еҜ№keyзҡ„hashcodeиҝӣдёҖжӯҘи®Ўз®—пјҢзЎ®дҝқж•ЈеҲ—еқҮеҢҖ
int i = indexFor(hash, table.length);//иҺ·еҸ–еңЁtableдёӯзҡ„е®һйҷ…дҪҚзҪ®
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
//еҰӮжһңиҜҘеҜ№еә”ж•°жҚ®е·ІеӯҳеңЁпјҢжү§иЎҢиҰҶзӣ–ж“ҚдҪңгҖӮз”Ёж–°valueжӣҝжҚўж—§valueпјҢ并иҝ”еӣһж—§value
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;//дҝқиҜҒ并еҸ‘и®ҝй—®ж—¶пјҢиӢҘHashMapеҶ…йғЁз»“жһ„еҸ‘з”ҹеҸҳеҢ–пјҢеҝ«йҖҹе“Қеә”еӨұиҙҘ
addEntry(hash, key, value, i);//ж–°еўһдёҖдёӘentry
return null;
}
е…ҲжқҘзңӢзңӢinflateTableиҝҷдёӘж–№жі•
private void inflateTable(int toSize) {
int capacity = roundUpToPowerOf2(toSize);//capacityдёҖе®ҡжҳҜ2зҡ„ж¬Ўе№Ӯ
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//жӯӨеӨ„дёәthresholdиөӢеҖјпјҢеҸ–capacity*loadFactorе’ҢMAXIMUM_CAPACITY+1зҡ„жңҖе°ҸеҖјпјҢcapaticyдёҖе®ҡдёҚдјҡи¶…иҝҮMAXIMUM_CAPACITYпјҢйҷӨйқһloadFactorеӨ§дәҺ1
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
гҖҖгҖҖinflateTableиҝҷдёӘж–№жі•з”ЁдәҺдёәдё»е№Іж•°з»„tableеңЁеҶ…еӯҳдёӯеҲҶй…ҚеӯҳеӮЁз©әй—ҙпјҢйҖҡиҝҮroundUpToPowerOf2(toSize)еҸҜд»ҘзЎ®дҝқcapacityдёәеӨ§дәҺжҲ–зӯүдәҺtoSizeзҡ„жңҖжҺҘиҝ‘toSizeзҡ„дәҢж¬Ўе№ӮпјҢжҜ”еҰӮtoSize=13,еҲҷcapacity=16;to_size=16,capacity=16;to_size=17,capacity=32.
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
roundUpToPowerOf2дёӯзҡ„иҝҷж®өеӨ„зҗҶдҪҝеҫ—ж•°з»„й•ҝеәҰдёҖе®ҡдёә2зҡ„ж¬Ўе№ӮпјҢInteger.highestOneBitжҳҜз”ЁжқҘиҺ·еҸ–жңҖе·Ұиҫ№зҡ„bitпјҲе…¶д»–bitдҪҚдёә0пјүжүҖд»ЈиЎЁзҡ„ж•°еҖј.
hashеҮҪж•°
//иҝҷжҳҜдёҖдёӘзҘһеҘҮзҡ„еҮҪж•°пјҢз”ЁдәҶеҫҲеӨҡзҡ„ејӮжҲ–пјҢ移дҪҚзӯүиҝҗз®—пјҢеҜ№keyзҡ„hashcodeиҝӣдёҖжӯҘиҝӣиЎҢи®Ўз®—д»ҘеҸҠдәҢиҝӣеҲ¶дҪҚзҡ„и°ғж•ҙзӯүжқҘдҝқиҜҒжңҖз»ҲиҺ·еҸ–зҡ„еӯҳеӮЁдҪҚзҪ®е°ҪйҮҸеҲҶеёғеқҮеҢҖ
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash42((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
д»ҘдёҠhashеҮҪж•°и®Ўз®—еҮәзҡ„еҖјпјҢйҖҡиҝҮindexForиҝӣдёҖжӯҘеӨ„зҗҶжқҘиҺ·еҸ–е®һйҷ…зҡ„еӯҳеӮЁдҪҚзҪ®
/**
* иҝ”еӣһж•°з»„дёӢж Ү
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
h&пјҲlength-1пјүдҝқиҜҒиҺ·еҸ–зҡ„indexдёҖе®ҡеңЁж•°з»„иҢғеӣҙеҶ…пјҢдёҫдёӘдҫӢеӯҗпјҢй»ҳи®Өе®№йҮҸ16пјҢlength-1=15пјҢh=18,иҪ¬жҚўжҲҗдәҢиҝӣеҲ¶и®Ўз®—дёә
1 0 0 1 0 & 0 1 1 1 1 __________________ 0 0 0 1 0 = 2
гҖҖгҖҖжңҖз»Ҳи®Ўз®—еҮәзҡ„index=2гҖӮжңүдәӣзүҲжң¬зҡ„еҜ№дәҺжӯӨеӨ„зҡ„и®Ўз®—дјҡдҪҝз”Ё еҸ–жЁЎиҝҗз®—пјҢд№ҹиғҪдҝқиҜҒindexдёҖе®ҡеңЁж•°з»„иҢғеӣҙеҶ…пјҢдёҚиҝҮдҪҚиҝҗз®—еҜ№и®Ўз®—жңәжқҘиҜҙпјҢжҖ§иғҪжӣҙй«ҳдёҖдәӣпјҲHashMapдёӯжңүеӨ§йҮҸдҪҚиҝҗз®—пјү
жүҖд»ҘжңҖз»ҲеӯҳеӮЁдҪҚзҪ®зҡ„зЎ®е®ҡжөҒзЁӢжҳҜиҝҷж ·зҡ„пјҡ

еҶҚжқҘзңӢзңӢaddEntryзҡ„е®һзҺ°пјҡ
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);//еҪ“sizeи¶…иҝҮдёҙз•ҢйҳҲеҖјthresholdпјҢ并且еҚіе°ҶеҸ‘з”ҹе“ҲеёҢеҶІзӘҒж—¶иҝӣиЎҢжү©е®№
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
гҖҖгҖҖйҖҡиҝҮд»ҘдёҠд»Јз ҒиғҪеӨҹеҫ—зҹҘпјҢеҪ“еҸ‘з”ҹе“ҲеёҢеҶІзӘҒ并且sizeеӨ§дәҺйҳҲеҖјзҡ„ж—¶еҖҷпјҢйңҖиҰҒиҝӣиЎҢж•°з»„жү©е®№пјҢжү©е®№ж—¶пјҢйңҖиҰҒж–°е»әдёҖдёӘй•ҝеәҰдёәд№ӢеүҚж•°з»„2еҖҚзҡ„ж–°зҡ„ж•°з»„пјҢ然еҗҺе°ҶеҪ“еүҚзҡ„Entryж•°з»„дёӯзҡ„е…ғзҙ е…ЁйғЁдј иҫ“иҝҮеҺ»пјҢжү©е®№еҗҺзҡ„ж–°ж•°з»„й•ҝеәҰдёәд№ӢеүҚзҡ„2еҖҚпјҢжүҖд»Ҙжү©е®№зӣёеҜ№жқҘиҜҙжҳҜдёӘиҖ—иө„жәҗзҡ„ж“ҚдҪңгҖӮ
жҲ‘们жқҘ继з»ӯзңӢдёҠйқўжҸҗеҲ°зҡ„resizeж–№жі•
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
еҰӮжһңж•°з»„иҝӣиЎҢжү©е®№пјҢж•°з»„й•ҝеәҰеҸ‘з”ҹеҸҳеҢ–пјҢиҖҢеӯҳеӮЁдҪҚзҪ® index = h&(length-1),indexд№ҹеҸҜиғҪдјҡеҸ‘з”ҹеҸҳеҢ–пјҢйңҖиҰҒйҮҚж–°и®Ўз®—indexпјҢжҲ‘们е…ҲжқҘзңӢзңӢtransferиҝҷдёӘж–№жі•
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
гҖҖгҖҖгҖҖгҖҖгҖҖ//forеҫӘзҺҜдёӯзҡ„д»Јз ҒпјҢйҖҗдёӘйҒҚеҺҶй“ҫиЎЁпјҢйҮҚж–°и®Ўз®—зҙўеј•дҪҚзҪ®пјҢе°ҶиҖҒж•°з»„ж•°жҚ®еӨҚеҲ¶еҲ°ж–°ж•°з»„дёӯеҺ»пјҲж•°з»„дёҚеӯҳеӮЁе®һйҷ…ж•°жҚ®пјҢжүҖд»Ҙд»…д»…жҳҜжӢ·иҙқеј•з”ЁиҖҢе·Іпјү
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
гҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖгҖҖ //е°ҶеҪ“еүҚentryзҡ„nextй“ҫжҢҮеҗ‘ж–°зҡ„зҙўеј•дҪҚзҪ®,newTable[i]жңүеҸҜиғҪдёәз©әпјҢжңүеҸҜиғҪд№ҹжҳҜдёӘentryй“ҫпјҢеҰӮжһңжҳҜentryй“ҫпјҢзӣҙжҺҘеңЁй“ҫиЎЁеӨҙйғЁжҸ’е…ҘгҖӮ
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
гҖҖгҖҖиҝҷдёӘж–№жі•е°ҶиҖҒж•°з»„дёӯзҡ„ж•°жҚ®йҖҗдёӘй“ҫиЎЁең°йҒҚеҺҶпјҢжү”еҲ°ж–°зҡ„жү©е®№еҗҺзҡ„ж•°з»„дёӯпјҢжҲ‘们зҡ„ж•°з»„зҙўеј•дҪҚзҪ®зҡ„и®Ўз®—жҳҜйҖҡиҝҮ еҜ№keyеҖјзҡ„hashcodeиҝӣиЎҢhashжү°д№ұиҝҗз®—еҗҺпјҢеҶҚйҖҡиҝҮе’Ң length-1иҝӣиЎҢдҪҚиҝҗз®—еҫ—еҲ°жңҖз»Ҳж•°з»„зҙўеј•дҪҚзҪ®гҖӮ
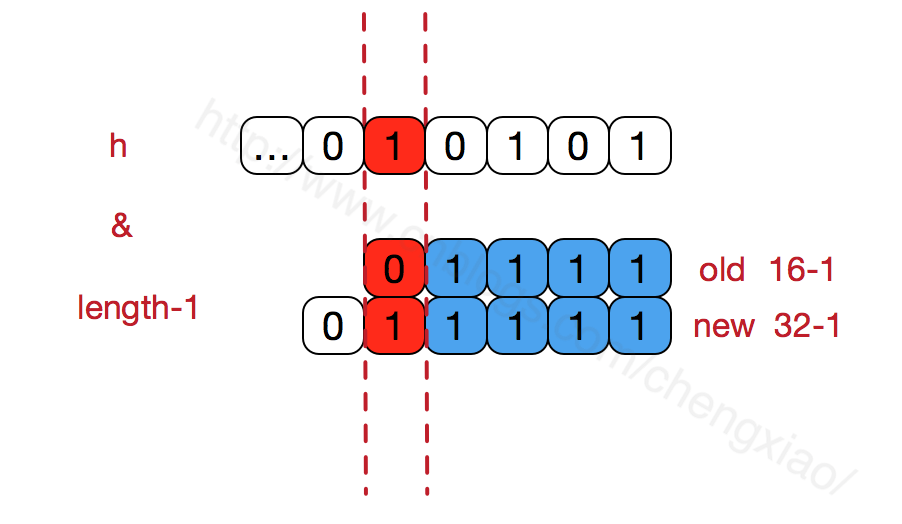
гҖҖгҖҖhashMapзҡ„ж•°з»„й•ҝеәҰдёҖе®ҡдҝқжҢҒ2зҡ„ж¬Ўе№ӮпјҢжҜ”еҰӮ16зҡ„дәҢиҝӣеҲ¶иЎЁзӨәдёә 10000пјҢйӮЈд№Ҳlength-1е°ұжҳҜ15пјҢдәҢиҝӣеҲ¶дёә01111пјҢеҗҢзҗҶжү©е®№еҗҺзҡ„ж•°з»„й•ҝеәҰдёә32пјҢдәҢиҝӣеҲ¶иЎЁзӨәдёә100000пјҢlength-1дёә31пјҢдәҢиҝӣеҲ¶иЎЁзӨәдёә011111гҖӮд»ҺдёӢеӣҫеҸҜд»ҘжҲ‘们д№ҹиғҪзңӢеҲ°иҝҷж ·дјҡдҝқиҜҒдҪҺдҪҚе…Ёдёә1пјҢиҖҢжү©е®№еҗҺеҸӘжңүдёҖдҪҚе·®ејӮпјҢд№ҹе°ұжҳҜеӨҡеҮәдәҶжңҖе·ҰдҪҚзҡ„1пјҢиҝҷж ·еңЁйҖҡиҝҮ h&(length-1)зҡ„ж—¶еҖҷпјҢеҸӘиҰҒhеҜ№еә”зҡ„жңҖе·Ұиҫ№зҡ„йӮЈдёҖдёӘе·®ејӮдҪҚдёә0пјҢе°ұиғҪдҝқиҜҒеҫ—еҲ°зҡ„ж–°зҡ„ж•°з»„зҙўеј•е’ҢиҖҒж•°з»„зҙўеј•дёҖиҮҙ(еӨ§еӨ§еҮҸе°‘дәҶд№ӢеүҚе·Із»Ҹж•ЈеҲ—иүҜеҘҪзҡ„иҖҒж•°з»„зҡ„ж•°жҚ®дҪҚзҪ®йҮҚж–°и°ғжҚў)пјҢдёӘдәәзҗҶи§ЈгҖӮ
гҖҖгҖҖ
иҝҳжңүпјҢж•°з»„й•ҝеәҰдҝқжҢҒ2зҡ„ж¬Ўе№ӮпјҢlength-1зҡ„дҪҺдҪҚйғҪдёә1пјҢдјҡдҪҝеҫ—иҺ·еҫ—зҡ„ж•°з»„зҙўеј•indexжӣҙеҠ еқҮеҢҖпјҢжҜ”еҰӮпјҡ
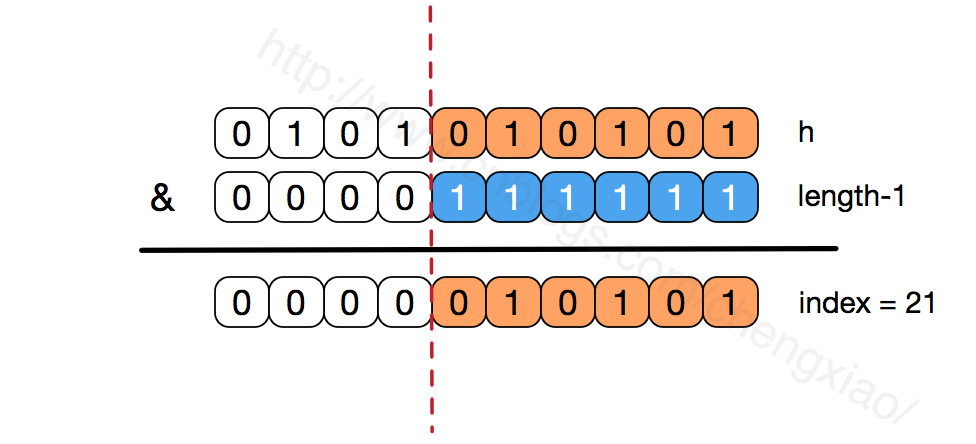
гҖҖгҖҖжҲ‘们зңӢеҲ°пјҢдёҠйқўзҡ„&иҝҗз®—пјҢй«ҳдҪҚжҳҜдёҚдјҡеҜ№з»“жһңдә§з”ҹеҪұе“Қзҡ„пјҲhashеҮҪж•°йҮҮз”Ёеҗ„з§ҚдҪҚиҝҗз®—еҸҜиғҪд№ҹжҳҜдёәдәҶдҪҝеҫ—дҪҺдҪҚжӣҙеҠ ж•ЈеҲ—пјүпјҢжҲ‘们еҸӘе…іжіЁдҪҺдҪҚbitпјҢеҰӮжһңдҪҺдҪҚе…ЁйғЁдёә1пјҢйӮЈд№ҲеҜ№дәҺhдҪҺдҪҚйғЁеҲҶжқҘиҜҙпјҢд»»дҪ•дёҖдҪҚзҡ„еҸҳеҢ–йғҪдјҡеҜ№з»“жһңдә§з”ҹеҪұе“ҚпјҢд№ҹе°ұжҳҜиҜҙпјҢиҰҒеҫ—еҲ°index=21иҝҷдёӘеӯҳеӮЁдҪҚзҪ®пјҢhзҡ„дҪҺдҪҚеҸӘжңүиҝҷдёҖз§Қз»„еҗҲгҖӮиҝҷд№ҹжҳҜж•°з»„й•ҝеәҰи®ҫи®Ўдёәеҝ…йЎ»дёә2зҡ„ж¬Ўе№Ӯзҡ„еҺҹеӣ гҖӮ
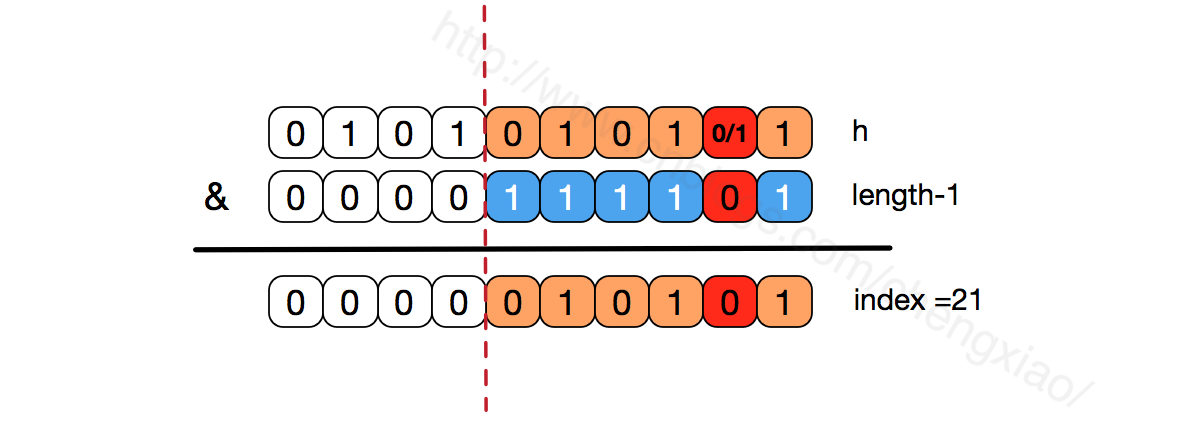
гҖҖгҖҖеҰӮжһңдёҚжҳҜ2зҡ„ж¬Ўе№ӮпјҢд№ҹе°ұжҳҜдҪҺдҪҚдёҚжҳҜе…Ёдёә1жӯӨж—¶пјҢиҰҒдҪҝеҫ—index=21пјҢhзҡ„дҪҺдҪҚйғЁеҲҶдёҚеҶҚе…·жңүе”ҜдёҖжҖ§дәҶпјҢе“ҲеёҢеҶІзӘҒзҡ„еҮ зҺҮдјҡеҸҳзҡ„жӣҙеӨ§пјҢеҗҢж—¶пјҢindexеҜ№еә”зҡ„иҝҷдёӘbitдҪҚж— и®әеҰӮдҪ•дёҚдјҡзӯүдәҺ1дәҶпјҢиҖҢеҜ№еә”зҡ„йӮЈдәӣж•°з»„дҪҚзҪ®д№ҹе°ұиў«зҷҪзҷҪжөӘиҙ№дәҶгҖӮ
getж–№жі•
public V get(Object key) {
гҖҖгҖҖгҖҖгҖҖ //еҰӮжһңkeyдёәnull,еҲҷзӣҙжҺҘеҺ»table[0]еӨ„еҺ»жЈҖзҙўеҚіеҸҜгҖӮ
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
getж–№жі•йҖҡиҝҮkeyеҖјиҝ”еӣһеҜ№еә”valueпјҢеҰӮжһңkeyдёәnullпјҢзӣҙжҺҘеҺ»table[0]еӨ„жЈҖзҙўгҖӮжҲ‘们еҶҚзңӢдёҖдёӢgetEntryиҝҷдёӘж–№жі•
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
//йҖҡиҝҮkeyзҡ„hashcodeеҖји®Ўз®—hashеҖј
int hash = (key == null) ? 0 : hash(key);
//indexFor (hash&length-1) иҺ·еҸ–жңҖз»Ҳж•°з»„зҙўеј•пјҢ然еҗҺйҒҚеҺҶй“ҫиЎЁпјҢйҖҡиҝҮequalsж–№жі•жҜ”еҜ№жүҫеҮәеҜ№еә”и®°еҪ•
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
гҖҖгҖҖеҸҜд»ҘзңӢеҮәпјҢgetж–№жі•зҡ„е®һзҺ°зӣёеҜ№з®ҖеҚ•пјҢkey(hashcode)-->hash-->indexFor-->жңҖз»Ҳзҙўеј•дҪҚзҪ®пјҢжүҫеҲ°еҜ№еә”дҪҚзҪ®table[i]пјҢеҶҚжҹҘзңӢжҳҜеҗҰжңүй“ҫиЎЁпјҢйҒҚеҺҶй“ҫиЎЁпјҢйҖҡиҝҮkeyзҡ„equalsж–№жі•жҜ”еҜ№жҹҘжүҫеҜ№еә”зҡ„и®°еҪ•гҖӮиҰҒжіЁж„Ҹзҡ„жҳҜпјҢжңүдәәи§үеҫ—дёҠйқўеңЁе®ҡдҪҚеҲ°ж•°з»„дҪҚзҪ®д№ӢеҗҺ然еҗҺйҒҚеҺҶй“ҫиЎЁзҡ„ж—¶еҖҷпјҢe.hash == hashиҝҷдёӘеҲӨж–ӯжІЎеҝ…иҰҒпјҢд»…йҖҡиҝҮequalsеҲӨж–ӯе°ұеҸҜд»ҘгҖӮе…¶е®һдёҚ然пјҢиҜ•жғідёҖдёӢпјҢеҰӮжһңдј е…Ҙзҡ„keyеҜ№иұЎйҮҚеҶҷдәҶequalsж–№жі•еҚҙжІЎжңүйҮҚеҶҷhashCodeпјҢиҖҢжҒ°е·§жӯӨеҜ№иұЎе®ҡдҪҚеҲ°иҝҷдёӘж•°з»„дҪҚзҪ®пјҢеҰӮжһңд»…д»…з”ЁequalsеҲӨж–ӯеҸҜиғҪжҳҜзӣёзӯүзҡ„пјҢдҪҶе…¶hashCodeе’ҢеҪ“еүҚеҜ№иұЎдёҚдёҖиҮҙпјҢиҝҷз§Қжғ…еҶөпјҢж №жҚ®Objectзҡ„hashCodeзҡ„зәҰе®ҡпјҢдёҚиғҪиҝ”еӣһеҪ“еүҚеҜ№иұЎпјҢиҖҢеә”иҜҘиҝ”еӣһnullпјҢеҗҺйқўзҡ„дҫӢеӯҗдјҡеҒҡеҮәиҝӣдёҖжӯҘи§ЈйҮҠгҖӮ
гҖҖгҖҖе…ідәҺHashMapзҡ„жәҗз ҒеҲҶжһҗе°ұд»Ӣз»ҚеҲ°иҝҷе„ҝдәҶпјҢжңҖеҗҺжҲ‘们еҶҚиҒҠиҒҠиҖҒз”ҹеёёи°Ҳзҡ„дёҖдёӘй—®йўҳпјҢеҗ„з§Қиө„ж–ҷдёҠйғҪдјҡжҸҗеҲ°пјҢвҖңйҮҚеҶҷequalsж—¶д№ҹиҰҒеҗҢж—¶иҰҶзӣ–hashcodeвҖқпјҢжҲ‘们дёҫдёӘе°ҸдҫӢеӯҗжқҘзңӢзңӢпјҢеҰӮжһңйҮҚеҶҷдәҶequalsиҖҢдёҚйҮҚеҶҷhashcodeдјҡеҸ‘з”ҹд»Җд№Ҳж ·зҡ„й—®йўҳ
/**
* Created by chengxiao on 2016/11/15.
*/
public class MyTest {
private static class Person{
int idCard;
String name;
public Person(int idCard, String name) {
this.idCard = idCard;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()){
return false;
}
Person person = (Person) o;
//дёӨдёӘеҜ№иұЎжҳҜеҗҰзӯүеҖјпјҢйҖҡиҝҮidCardжқҘзЎ®е®ҡ
return this.idCard == person.idCard;
}
}
public static void main(String []args){
HashMap<Person,String> map = new HashMap<Person, String>();
Person person = new Person(1234,"д№”еі°");
//putеҲ°hashmapдёӯеҺ»
map.put(person,"еӨ©йҫҷе…«йғЁ");
//getеҸ–еҮәпјҢд»ҺйҖ»иҫ‘дёҠи®Іеә”иҜҘиғҪиҫ“еҮәвҖңеӨ©йҫҷе…«йғЁвҖқ
System.out.println("з»“жһң:"+map.get(new Person(1234,"иҗ§еі°")));
}
}
е®һйҷ…иҫ“еҮәз»“жһңпјҡ
з»“жһңпјҡnull
гҖҖгҖҖеҰӮжһңжҲ‘们已з»ҸеҜ№HashMapзҡ„еҺҹзҗҶжңүдәҶдёҖе®ҡдәҶи§ЈпјҢиҝҷдёӘз»“жһңе°ұдёҚйҡҫзҗҶи§ЈдәҶгҖӮе°Ҫз®ЎжҲ‘们еңЁиҝӣиЎҢgetе’Ңputж“ҚдҪңзҡ„ж—¶еҖҷпјҢдҪҝз”Ёзҡ„keyд»ҺйҖ»иҫ‘дёҠи®ІжҳҜзӯүеҖјзҡ„пјҲйҖҡиҝҮequalsжҜ”иҫғжҳҜзӣёзӯүзҡ„пјүпјҢдҪҶз”ұдәҺжІЎжңүйҮҚеҶҷhashCodeж–№жі•пјҢжүҖд»Ҙputж“ҚдҪңж—¶пјҢkey(hashcode1)-->hash-->indexFor-->жңҖз»Ҳзҙўеј•дҪҚзҪ® пјҢиҖҢйҖҡиҝҮkeyеҸ–еҮәvalueзҡ„ж—¶еҖҷ key(hashcode1)-->hash-->indexFor-->жңҖз»Ҳзҙўеј•дҪҚзҪ®пјҢз”ұдәҺhashcode1дёҚзӯүдәҺhashcode2пјҢеҜјиҮҙжІЎжңүе®ҡдҪҚеҲ°дёҖдёӘж•°з»„дҪҚзҪ®иҖҢиҝ”еӣһйҖ»иҫ‘дёҠй”ҷиҜҜзҡ„еҖјnullпјҲд№ҹжңүеҸҜиғҪзў°е·§е®ҡдҪҚеҲ°дёҖдёӘж•°з»„дҪҚзҪ®пјҢдҪҶжҳҜд№ҹдјҡеҲӨж–ӯе…¶entryзҡ„hashеҖјжҳҜеҗҰзӣёзӯүпјҢдёҠйқўgetж–№жі•дёӯжңүжҸҗеҲ°гҖӮпјү
гҖҖгҖҖжүҖд»ҘпјҢеңЁйҮҚеҶҷequalsзҡ„ж–№жі•зҡ„ж—¶еҖҷпјҢеҝ…йЎ»жіЁж„ҸйҮҚеҶҷhashCodeж–№жі•пјҢеҗҢж—¶иҝҳиҰҒдҝқиҜҒйҖҡиҝҮequalsеҲӨж–ӯзӣёзӯүзҡ„дёӨдёӘеҜ№иұЎпјҢи°ғз”ЁhashCodeж–№жі•иҰҒиҝ”еӣһеҗҢж ·зҡ„ж•ҙж•°еҖјгҖӮиҖҢеҰӮжһңequalsеҲӨж–ӯдёҚзӣёзӯүзҡ„дёӨдёӘеҜ№иұЎпјҢе…¶hashCodeеҸҜд»ҘзӣёеҗҢпјҲеҸӘдёҚиҝҮдјҡеҸ‘з”ҹе“ҲеёҢеҶІзӘҒпјҢеә”е°ҪйҮҸйҒҝе…ҚпјүгҖӮ
гҖҖгҖҖжң¬ж–ҮжҸҸиҝ°дәҶHashMapзҡ„е®һзҺ°еҺҹзҗҶпјҢ并结еҗҲжәҗз ҒеҒҡдәҶиҝӣдёҖжӯҘзҡ„еҲҶжһҗпјҢд№ҹж¶үеҸҠеҲ°дёҖдәӣжәҗз Ғз»ҶиҠӮи®ҫи®Ўзјҳз”ұпјҢжңҖеҗҺз®ҖеҚ•д»Ӣз»ҚдәҶдёәд»Җд№ҲйҮҚеҶҷequalsзҡ„ж—¶еҖҷйңҖиҰҒйҮҚеҶҷhashCodeж–№жі•гҖӮеёҢжңӣжң¬зҜҮж–Үз« иғҪеё®еҠ©еҲ°еӨ§е®¶пјҢеҗҢж—¶д№ҹж¬ўиҝҺи®Ёи®әжҢҮжӯЈпјҢи°ўи°ўж”ҜжҢҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ