жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
JVMCPUProfilerжҠҖжңҜеҺҹзҗҶеҸҠжәҗз Ғзҡ„зӨәдҫӢеҲҶжһҗпјҢеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
еј•иЁҖ
CPU Profilingз»Ҹеёёиў«з”ЁдәҺеҲҶжһҗд»Јз Ғзҡ„жү§иЎҢзғӯзӮ№пјҢеҰӮвҖңе“ӘдёӘж–№жі•еҚ з”ЁCPUзҡ„жү§иЎҢж—¶й—ҙжңҖй•ҝвҖқгҖҒвҖңжҜҸдёӘж–№жі•еҚ з”ЁCPUзҡ„жҜ”дҫӢжҳҜеӨҡе°‘вҖқзӯүзӯүпјҢйҖҡиҝҮCPU Profilingеҫ—еҲ°дёҠиҝ°зӣёе…ідҝЎжҒҜеҗҺпјҢз ”еҸ‘дәәе‘ҳе°ұеҸҜд»ҘиҪ»жқҫй’ҲеҜ№зғӯзӮ№з“¶йўҲиҝӣиЎҢеҲҶжһҗе’ҢжҖ§иғҪдјҳеҢ–пјҢиҝӣиҖҢзӘҒз ҙжҖ§иғҪ瓶йўҲпјҢеӨ§е№…жҸҗеҚҮзі»з»ҹзҡ„еҗһеҗҗйҮҸгҖӮ
CPU Profilerз®Җд»Ӣ
зӨҫеҢәе®һзҺ°зҡ„JVM ProfilerеҫҲеӨҡпјҢжҜ”еҰӮе·Із»Ҹе•Ҷз”Ёдё”еҠҹиғҪејәеӨ§зҡ„JProfilerпјҢд№ҹжңүе…Қиҙ№ејҖжәҗзҡ„дә§е“ҒпјҢеҰӮJVM-ProfilerпјҢеҠҹиғҪеҗ„жңүжүҖй•ҝгҖӮжҲ‘们ж—ҘеёёдҪҝз”Ёзҡ„Intellij IDEAжңҖж–°зүҲеҶ…йғЁд№ҹйӣҶжҲҗдәҶдёҖдёӘз®ҖеҚ•еҘҪз”Ёзҡ„ProfilerпјҢиҜҰз»Ҷзҡ„д»Ӣз»ҚеҸӮи§Ғе®ҳж–№BlogгҖӮ
еңЁз”ЁIDEAжү“ејҖйңҖиҰҒиҜҠж–ӯзҡ„JavaйЎ№зӣ®еҗҺпјҢеңЁвҖңPreferences -> Build, Execution, Deployment -> Java ProfilerвҖқз•Ңйқўж·»еҠ дёҖдёӘвҖңCPU ProfilerвҖқпјҢ然еҗҺеӣһеҲ°йЎ№зӣ®пјҢеҚ•еҮ»еҸідёҠи§’зҡ„вҖңRun with ProfilerвҖқеҗҜеҠЁйЎ№зӣ®е№¶ејҖе§ӢCPU ProfilingиҝҮзЁӢгҖӮдёҖе®ҡж—¶й—ҙеҗҺпјҲжҺЁиҚҗ5minпјүпјҢеңЁProfilerз•ҢйқўзӮ№еҮ»вҖңStop Profiling and Show ResultsвҖқпјҢеҚіеҸҜзңӢеҲ°Profilingзҡ„з»“жһңпјҢеҢ…еҗ«зҒ«з„°еӣҫе’Ңи°ғз”Ёж ‘пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
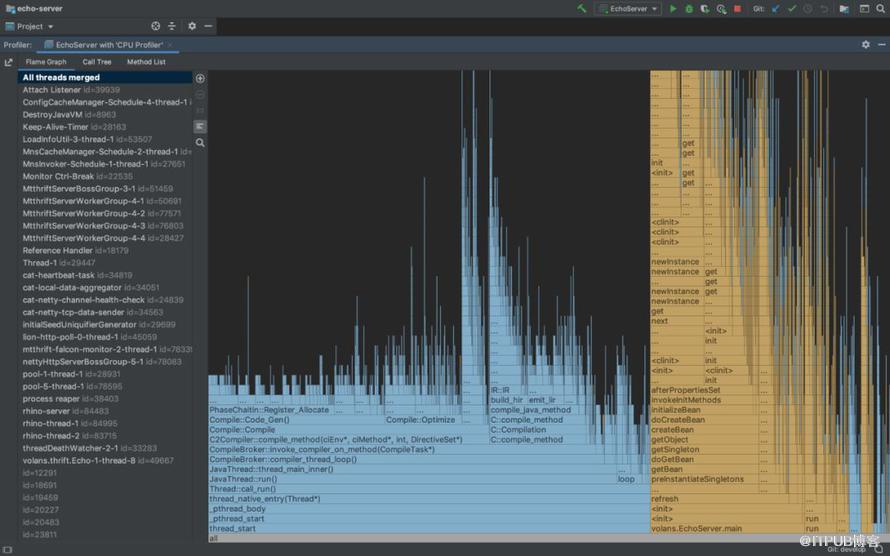 Intellij IDEA - жҖ§иғҪзҒ«з„°еӣҫ
Intellij IDEA - жҖ§иғҪзҒ«з„°еӣҫ
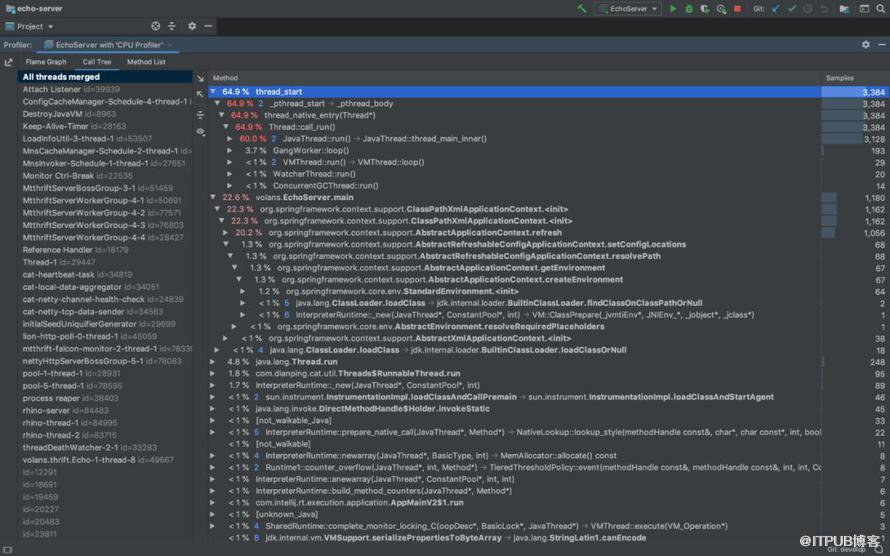
Intellij IDEA - и°ғз”Ёе Ҷж Ҳж ‘
зҒ«з„°еӣҫжҳҜж №жҚ®и°ғз”Ёж Ҳзҡ„ж ·жң¬йӣҶз”ҹжҲҗзҡ„еҸҜи§ҶеҢ–жҖ§иғҪеҲҶжһҗеӣҫпјҢгҖҠеҰӮдҪ•иҜ»жҮӮзҒ«з„°еӣҫпјҹгҖӢдёҖж–ҮеҜ№зҒ«з„°еӣҫиҝӣиЎҢдәҶдёҚй”ҷзҡ„и®Іи§ЈпјҢеӨ§е®¶еҸҜд»ҘеҸӮиҖғдёҖдёӢгҖӮз®ҖиҖҢиЁҖд№ӢпјҢзңӢзҒ«з„°еӣҫж—¶жҲ‘们йңҖиҰҒе…іжіЁвҖңе№ійЎ¶вҖқпјҢеӣ дёәйӮЈйҮҢе°ұжҳҜжҲ‘们зЁӢеәҸзҡ„CPUзғӯзӮ№гҖӮи°ғз”Ёж ‘жҳҜеҸҰдёҖз§ҚеҸҜи§ҶеҢ–еҲҶжһҗзҡ„жүӢж®өпјҢдёҺзҒ«з„°еӣҫдёҖж ·пјҢд№ҹжҳҜж №жҚ®еҗҢдёҖд»Ҫж ·жң¬йӣҶиҖҢз”ҹжҲҗпјҢжҢүйңҖйҖүжӢ©еҚіеҸҜгҖӮ
иҝҷйҮҢиҰҒиҜҙжҳҺдёҖдёӢпјҢеӣ дёәжҲ‘们没жңүеңЁйЎ№зӣ®дёӯеј•е…Ҙд»»дҪ•дҫқиө–пјҢд»…д»…жҳҜвҖңRun with ProfilerвҖқпјҢProfilerе°ұиғҪиҺ·еҸ–жҲ‘们зЁӢеәҸиҝҗиЎҢж—¶зҡ„дҝЎжҒҜгҖӮиҝҷдёӘеҠҹиғҪе…¶е®һжҳҜйҖҡиҝҮJVM Agentе®һзҺ°зҡ„пјҢдёәдәҶжӣҙеҘҪең°её®еҠ©еӨ§е®¶зі»з»ҹжҖ§зҡ„дәҶи§Је®ғпјҢжҲ‘们еңЁиҝҷйҮҢе…ҲеҜ№JVM AgentеҒҡдёӘз®ҖеҚ•зҡ„д»Ӣз»ҚгҖӮ
JVM Agentз®Җд»Ӣ
JVM AgentжҳҜдёҖдёӘжҢүдёҖе®ҡ规еҲҷзј–еҶҷзҡ„зү№ж®ҠзЁӢеәҸеә“пјҢеҸҜд»ҘеңЁеҗҜеҠЁйҳ¶ж®өйҖҡиҝҮе‘Ҫд»ӨиЎҢеҸӮж•°дј йҖ’з»ҷJVMпјҢдҪңдёәдёҖдёӘдјҙз”ҹеә“дёҺзӣ®ж ҮJVMиҝҗиЎҢеңЁеҗҢдёҖдёӘиҝӣзЁӢдёӯгҖӮеңЁAgentдёӯеҸҜд»ҘйҖҡиҝҮеӣәе®ҡзҡ„жҺҘеҸЈиҺ·еҸ–JVMиҝӣзЁӢеҶ…зҡ„зӣёе…ідҝЎжҒҜгҖӮAgentж—ўеҸҜд»ҘжҳҜз”ЁC/C++/Rustзј–еҶҷзҡ„JVMTI AgentпјҢд№ҹеҸҜд»ҘжҳҜз”ЁJavaзј–еҶҷзҡ„Java AgentгҖӮ
жү§иЎҢJavaе‘Ҫд»ӨпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°Agentзӣёе…ізҡ„е‘Ҫд»ӨиЎҢеҸӮж•°пјҡ
-agentlib:<еә“еҗҚ>[=<йҖүйЎ№>]
еҠ иҪҪжң¬жңәд»ЈзҗҶеә“ <еә“еҗҚ>, дҫӢеҰӮ -agentlib:jdwp
еҸҰиҜ·еҸӮйҳ… -agentlib:jdwp=help
-agentpath:<и·Ҝеҫ„еҗҚ>[=<йҖүйЎ№>]
жҢүе®Ңж•ҙи·Ҝеҫ„еҗҚеҠ иҪҪжң¬жңәд»ЈзҗҶеә“
-javaagent:<jar и·Ҝеҫ„>[=<йҖүйЎ№>]
еҠ иҪҪ Java зј–зЁӢиҜӯиЁҖд»ЈзҗҶ, иҜ·еҸӮйҳ… java.lang.instrument
JVMTI Agent
JVMTIпјҲJVM Tool InterfaceпјүжҳҜJVMжҸҗдҫӣзҡ„дёҖеҘ—ж ҮеҮҶзҡ„C/C++зј–зЁӢжҺҘеҸЈпјҢжҳҜе®һзҺ°DebuggerгҖҒProfilerгҖҒMonitorгҖҒThread Analyserзӯүе·Ҙе…·зҡ„з»ҹдёҖеҹәзЎҖпјҢеңЁдё»жөҒJavaиҷҡжӢҹжңәдёӯйғҪжңүе®һзҺ°гҖӮ
еҪ“жҲ‘们иҰҒеҹәдәҺJVMTIе®һзҺ°дёҖдёӘAgentж—¶пјҢйңҖиҰҒе®һзҺ°еҰӮдёӢе…ҘеҸЈеҮҪж•°пјҡ
// $JAVA_HOME/include/jvmti.h
JNIEXPORT jint JNICALL Agent_OnLoad(JavaVM *vm, char *options, void *reserved);
дҪҝз”ЁC/C++е®һзҺ°иҜҘеҮҪж•°пјҢ并е°Ҷд»Јз Ғзј–иҜ‘дёәеҠЁжҖҒиҝһжҺҘеә“пјҲLinuxдёҠжҳҜ.soпјүпјҢйҖҡиҝҮ-agentpathеҸӮж•°е°Ҷеә“зҡ„е®Ңж•ҙи·Ҝеҫ„дј йҖ’з»ҷJavaиҝӣзЁӢпјҢJVMе°ұдјҡеңЁеҗҜеҠЁйҳ¶ж®өзҡ„еҗҲйҖӮж—¶жңәжү§иЎҢиҜҘеҮҪж•°гҖӮеңЁеҮҪж•°еҶ…йғЁпјҢжҲ‘们еҸҜд»ҘйҖҡиҝҮJavaVMжҢҮй’ҲеҸӮж•°жӢҝеҲ°JNIе’ҢJVMTIзҡ„еҮҪж•°жҢҮй’ҲиЎЁпјҢиҝҷж ·жҲ‘们е°ұжӢҘжңүдәҶдёҺJVMиҝӣиЎҢеҗ„з§ҚеӨҚжқӮдәӨдә’зҡ„иғҪеҠӣгҖӮ
жӣҙеӨҡJVMTIзӣёе…ізҡ„з»ҶиҠӮеҸҜд»ҘеҸӮиҖғе®ҳж–№ж–ҮжЎЈгҖӮ
Java Agent
еңЁеҫҲеӨҡеңәжҷҜдёӢпјҢжҲ‘们没жңүеҝ…иҰҒеҝ…йЎ»дҪҝз”ЁC/C++жқҘејҖеҸ‘JVMTI AgentпјҢеӣ дёәжҲҗжң¬й«ҳдё”дёҚжҳ“з»ҙжҠӨгҖӮJVMиҮӘиә«еҹәдәҺJVMTIе°ҒиЈ…дәҶдёҖеҘ—Javaзҡ„Instrument APIжҺҘеҸЈпјҢе…Ғи®ёдҪҝз”ЁJavaиҜӯиЁҖејҖеҸ‘Java AgentпјҲеҸӘжҳҜдёҖдёӘjarеҢ…пјүпјҢеӨ§еӨ§йҷҚдҪҺдәҶAgentзҡ„ејҖеҸ‘жҲҗжң¬гҖӮзӨҫеҢәејҖжәҗзҡ„дә§е“ҒеҰӮGreysгҖҒArthasгҖҒJVM-SandboxгҖҒJVM-ProfilerзӯүйғҪжҳҜзәҜJavaзј–еҶҷзҡ„пјҢд№ҹжҳҜд»ҘJava AgentеҪўејҸжқҘиҝҗиЎҢгҖӮ
еңЁJava AgentдёӯпјҢжҲ‘们йңҖиҰҒеңЁjarеҢ…зҡ„MANIFEST.MFдёӯе°ҶPremain-ClassжҢҮе®ҡдёәдёҖдёӘе…ҘеҸЈзұ»пјҢ并еңЁиҜҘе…ҘеҸЈзұ»дёӯе®һзҺ°еҰӮдёӢж–№жі•пјҡ
public static void premain(String args, Instrumentation ins) {
// implement
}
иҝҷж ·жү“еҢ…еҮәжқҘзҡ„jarе°ұжҳҜдёҖдёӘJava AgentпјҢеҸҜд»ҘйҖҡиҝҮ-javaagentеҸӮж•°е°Ҷjarдј йҖ’з»ҷJavaиҝӣзЁӢдјҙйҡҸеҗҜеҠЁпјҢJVMеҗҢж ·дјҡеңЁеҗҜеҠЁйҳ¶ж®өзҡ„еҗҲйҖӮж—¶жңәжү§иЎҢиҜҘж–№жі•гҖӮ
еңЁиҜҘж–№жі•еҶ…йғЁпјҢеҸӮж•°InstrumentationжҺҘеҸЈжҸҗдҫӣдәҶRetransform Classesзҡ„иғҪеҠӣпјҢжҲ‘们еҲ©з”ЁиҜҘжҺҘеҸЈе°ұеҸҜд»ҘеҜ№е®ҝдё»иҝӣзЁӢзҡ„ClassиҝӣиЎҢдҝ®ж”№пјҢе®һзҺ°ж–№жі•иҖ—ж—¶з»ҹи®ЎгҖҒж•…йҡңжіЁе…ҘгҖҒTraceзӯүеҠҹиғҪгҖӮInstrumentationжҺҘеҸЈжҸҗдҫӣзҡ„иғҪеҠӣиҫғдёәеҚ•дёҖпјҢд»…дёҺClassеӯ—иҠӮз Ғж“ҚдҪңзӣёе…іпјҢдҪҶз”ұдәҺжҲ‘们зҺ°еңЁе·Із»ҸеӨ„дәҺе®ҝдё»иҝӣзЁӢзҺҜеўғеҶ…пјҢе°ұеҸҜд»ҘеҲ©з”ЁJMXзӣҙжҺҘиҺ·еҸ–е®ҝдё»иҝӣзЁӢзҡ„еҶ…еӯҳгҖҒзәҝзЁӢгҖҒй”ҒзӯүдҝЎжҒҜгҖӮж— и®әжҳҜInstrument APIиҝҳжҳҜJMXпјҢе®ғ们еҶ…йғЁд»ҚжҳҜз»ҹдёҖеҹәдәҺJVMTIжқҘе®һзҺ°гҖӮ
жӣҙеӨҡInstrument APIзӣёе…ізҡ„з»ҶиҠӮеҸҜд»ҘеҸӮиҖғе®ҳж–№ж–ҮжЎЈгҖӮ
CPU ProfilerеҺҹзҗҶи§Јжһҗ
еңЁдәҶи§Је®ҢProfilerеҰӮдҪ•д»ҘAgentзҡ„еҪўејҸжү§иЎҢеҗҺпјҢжҲ‘们еҸҜд»ҘејҖе§Ӣе°қиҜ•жһ„йҖ дёҖдёӘз®ҖеҚ•зҡ„CPU ProfilerгҖӮдҪҶеңЁжӯӨд№ӢеүҚпјҢиҝҳжңүеҝ…иҰҒдәҶи§ЈдёӢCPU ProfilingжҠҖжңҜзҡ„дёӨз§Қе®һзҺ°ж–№ејҸеҸҠе…¶еҢәеҲ«гҖӮ
Sampling vs Instrumentation
дҪҝз”ЁиҝҮJProfilerзҡ„еҗҢеӯҰеә”иҜҘйғҪзҹҘйҒ“пјҢJProfilerзҡ„CPU ProfilingеҠҹиғҪжҸҗдҫӣдәҶдёӨз§Қж–№ејҸйҖүйЎ№: Samplingе’ҢInstrumentationпјҢе®ғ们д№ҹжҳҜе®һзҺ°CPU Profilerзҡ„дёӨз§ҚжүӢж®өгҖӮ
Samplingж–№ејҸйЎҫеҗҚжҖқд№үпјҢеҹәдәҺеҜ№StackTraceзҡ„вҖңйҮҮж ·вҖқиҝӣиЎҢе®һзҺ°пјҢж ёеҝғеҺҹзҗҶеҰӮдёӢпјҡ
еј•е…ҘProfilerдҫқиө–пјҢжҲ–зӣҙжҺҘеҲ©з”ЁAgentжҠҖжңҜжіЁе…Ҙзӣ®ж ҮJVMиҝӣзЁӢ并еҗҜеҠЁProfilerгҖӮ
еҗҜеҠЁдёҖдёӘйҮҮж ·е®ҡж—¶еҷЁпјҢд»Ҙеӣәе®ҡзҡ„йҮҮж ·йў‘зҺҮжҜҸйҡ”дёҖж®өж—¶й—ҙпјҲжҜ«з§’зә§пјүеҜ№жүҖжңүзәҝзЁӢзҡ„и°ғз”Ёж ҲиҝӣиЎҢDumpгҖӮ
жұҮжҖ»е№¶з»ҹи®ЎжҜҸж¬Ўи°ғз”Ёж Ҳзҡ„Dumpз»“жһңпјҢеңЁдёҖе®ҡж—¶й—ҙеҶ…йҮҮеҲ°и¶іеӨҹзҡ„ж ·жң¬еҗҺпјҢеҜјеҮәз»ҹи®Ўз»“жһңпјҢеҶ…е®№жҳҜжҜҸдёӘж–№жі•иў«йҮҮж ·еҲ°зҡ„ж¬Ўж•°еҸҠж–№жі•зҡ„и°ғз”Ёе…ізі»гҖӮ
InstrumentationеҲҷжҳҜеҲ©з”ЁInstrument APIпјҢеҜ№жүҖжңүеҝ…иҰҒзҡ„ClassиҝӣиЎҢеӯ—иҠӮз ҒеўһејәпјҢеңЁиҝӣе…ҘжҜҸдёӘж–№жі•еүҚиҝӣиЎҢеҹӢзӮ№пјҢж–№жі•жү§иЎҢз»“жқҹеҗҺз»ҹи®Ўжң¬ж¬Ўж–№жі•жү§иЎҢиҖ—ж—¶пјҢжңҖз»ҲиҝӣиЎҢжұҮжҖ»гҖӮдәҢиҖ…йғҪиғҪеҫ—еҲ°жғіиҰҒзҡ„з»“жһңпјҢйӮЈд№Ҳе®ғ们жңүд»Җд№ҲеҢәеҲ«е‘ўпјҹжҲ–иҖ…иҜҙпјҢеӯ°дјҳеӯ°еҠЈпјҹ
Instrumentationж–№ејҸеҜ№еҮ д№ҺжүҖжңүж–№жі•ж·»еҠ дәҶйўқеӨ–зҡ„AOPйҖ»иҫ‘пјҢиҝҷдјҡеҜјиҮҙеҜ№зәҝдёҠжңҚеҠЎйҖ жҲҗе·Ёйўқзҡ„жҖ§иғҪеҪұе“ҚпјҢдҪҶе…¶дјҳеҠҝжҳҜпјҡз»қеҜ№зІҫеҮҶзҡ„ж–№жі•и°ғз”Ёж¬Ўж•°гҖҒи°ғз”Ёж—¶й—ҙз»ҹи®ЎгҖӮ
Samplingж–№ејҸеҹәдәҺж— дҫөе…Ҙзҡ„йўқеӨ–зәҝзЁӢеҜ№жүҖжңүзәҝзЁӢзҡ„и°ғз”Ёж Ҳеҝ«з…§иҝӣиЎҢеӣәе®ҡйў‘зҺҮжҠҪж ·пјҢзӣёеҜ№еүҚиҖ…жқҘиҜҙе®ғзҡ„жҖ§иғҪејҖй”ҖеҫҲдҪҺгҖӮдҪҶз”ұдәҺе®ғеҹәдәҺвҖңйҮҮж ·вҖқзҡ„жЁЎејҸпјҢд»ҘеҸҠJVMеӣәжңүзҡ„еҸӘиғҪеңЁе®үе…ЁзӮ№пјҲSafe PointпјүиҝӣиЎҢйҮҮж ·зҡ„вҖңзјәйҷ·вҖқпјҢдјҡеҜјиҮҙз»ҹи®Ўз»“жһңеӯҳеңЁдёҖе®ҡзҡ„еҒҸе·®гҖӮиӯ¬еҰӮиҜҙпјҡжҹҗдәӣж–№жі•жү§иЎҢж—¶й—ҙжһҒзҹӯпјҢдҪҶжү§иЎҢйў‘зҺҮеҫҲй«ҳпјҢзңҹе®һеҚ з”ЁдәҶеӨ§йҮҸзҡ„CPU TimeпјҢдҪҶSampling Profilerзҡ„йҮҮж ·е‘ЁжңҹдёҚиғҪж— йҷҗи°ғе°ҸпјҢиҝҷдјҡеҜјиҮҙжҖ§иғҪејҖй”ҖйӘӨеўһпјҢжүҖд»ҘдјҡеҜјиҮҙеӨ§йҮҸзҡ„ж ·жң¬и°ғз”Ёж Ҳдёӯ并дёҚеӯҳеңЁеҲҡжүҚжҸҗеҲ°зҡ„вҖқй«ҳйў‘е°Ҹж–№жі•вҖңпјҢиҝӣиҖҢеҜјиҮҙжңҖз»Ҳз»“жһңж— жі•еҸҚжҳ зңҹе®һзҡ„CPUзғӯзӮ№гҖӮжӣҙеӨҡSamplingзӣёе…ізҡ„й—®йўҳеҸҜд»ҘеҸӮиҖғгҖҠWhy (Most) Sampling Java Profilers Are Fucking TerribleгҖӢгҖӮ
е…·дҪ“еҲ°вҖңеӯ°дјҳеӯ°еҠЈвҖқзҡ„й—®йўҳеұӮйқўпјҢиҝҷдёӨз§Қе®һзҺ°жҠҖжңҜ并没жңүйқһеёёжҳҺжҳҫзҡ„й«ҳдёӢд№ӢеҲӨпјҢеҸӘжңүеңЁеҲҶеңәжҷҜи®Ёи®әдёӢжүҚжңүж„Ҹд№үгҖӮSamplingз”ұдәҺдҪҺејҖй”Җзҡ„зү№жҖ§пјҢжӣҙйҖӮеҗҲз”ЁеңЁCPUеҜҶйӣҶеһӢзҡ„еә”з”ЁдёӯпјҢд»ҘеҸҠдёҚеҸҜжҺҘеҸ—еӨ§йҮҸжҖ§иғҪејҖй”Җзҡ„зәҝдёҠжңҚеҠЎдёӯгҖӮиҖҢInstrumentationеҲҷжӣҙйҖӮеҗҲз”ЁеңЁI/OеҜҶйӣҶзҡ„еә”з”ЁдёӯгҖҒеҜ№жҖ§иғҪејҖй”ҖдёҚж•Ҹж„ҹд»ҘеҸҠзЎ®е®һйңҖиҰҒзІҫзЎ®з»ҹи®Ўзҡ„еңәжҷҜдёӯгҖӮзӨҫеҢәзҡ„ProfilerжӣҙеӨҡзҡ„жҳҜеҹәдәҺSamplingжқҘе®һзҺ°пјҢжң¬ж–Үд№ҹжҳҜеҹәдәҺSamplingжқҘиҝӣиЎҢи®Іи§ЈгҖӮ
еҹәдәҺJava Agent + JMXе®һзҺ°
дёҖдёӘжңҖз®ҖеҚ•зҡ„Sampling CPU ProfilerеҸҜд»Ҙз”ЁJava Agent + JMXж–№ејҸжқҘе®һзҺ°гҖӮд»ҘJava Agentдёәе…ҘеҸЈпјҢиҝӣе…Ҙзӣ®ж ҮJVMиҝӣзЁӢеҗҺејҖеҗҜдёҖдёӘScheduledExecutorServiceпјҢе®ҡж—¶еҲ©з”ЁJMXзҡ„threadMXBean.dumpAllThreads()жқҘеҜјеҮәжүҖжңүзәҝзЁӢзҡ„StackTraceпјҢжңҖз»ҲжұҮжҖ»е№¶еҜјеҮәеҚіеҸҜгҖӮ
Uberзҡ„JVM-Profilerе®һзҺ°еҺҹзҗҶд№ҹжҳҜеҰӮжӯӨпјҢе…ій”®йғЁеҲҶд»Јз ҒеҰӮдёӢпјҡ
// com/uber/profiling/profilers/StacktraceCollectorProfiler.java
/*
* StacktraceCollectorProfilerзӯүеҗҢдәҺж–ҮдёӯжүҖиҝ°CpuProfilerпјҢд»…е‘ҪеҗҚеҒҸеҘҪдёҚеҗҢиҖҢе·І
* jvm-profilerзҡ„CpuProfilerжҢҮд»Јзҡ„жҳҜCpuLoadжҢҮж Үзҡ„Profiler
*/
// е®һзҺ°дәҶProfilerжҺҘеҸЈпјҢеӨ–йғЁз”ұз»ҹдёҖзҡ„ScheduledExecutorServiceеҜ№жүҖжңүProfilerе®ҡж—¶жү§иЎҢ
@Override
public void profile() {
ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
// ...
for (ThreadInfo threadInfo : threadInfos) {
String threadName = threadInfo.getThreadName();
// ...
StackTraceElement[] stackTraceElements = threadInfo.getStackTrace();
// ...
for (int i = stackTraceElements.length - 1; i >= 0; i--) {
StackTraceElement stackTraceElement = stackTraceElements[i];
// ...
}
// ...
}
}
UberжҸҗдҫӣзҡ„е®ҡж—¶еҷЁй»ҳи®ӨIntervalжҳҜ100msпјҢеҜ№дәҺCPU ProfilerжқҘиҜҙпјҢиҝҷз•ҘжҳҫзІ—зіҷгҖӮдҪҶз”ұдәҺdumpAllThreads()зҡ„жү§иЎҢејҖй”ҖдёҚе®№е°Ҹ觑пјҢIntervalдёҚе®ңи®ҫзҪ®зҡ„иҝҮе°ҸпјҢжүҖд»ҘиҜҘж–№жі•зҡ„CPU Profilingз»“жһңдјҡеӯҳеңЁдёҚе°Ҹзҡ„иҜҜе·®гҖӮ
JVM-Profilerзҡ„дјҳзӮ№еңЁдәҺж”ҜжҢҒеӨҡз§ҚжҢҮж Үзҡ„ProfilingпјҲStackTraceгҖҒCPUBusyгҖҒMemoryгҖҒI/OгҖҒMethodпјүпјҢдё”ж”ҜжҢҒе°ҶProfilingз»“жһңйҖҡиҝҮKafkaдёҠжҠҘеӣһдёӯеҝғServerиҝӣиЎҢеҲҶжһҗпјҢд№ҹеҚіж”ҜжҢҒйӣҶзҫӨиҜҠж–ӯгҖӮ
еҹәдәҺJVMTI + GetStackTraceе®һзҺ°
дҪҝз”ЁJavaе®һзҺ°ProfilerзӣёеҜ№иҫғз®ҖеҚ•пјҢдҪҶд№ҹеӯҳеңЁдёҖдәӣй—®йўҳпјҢиӯ¬еҰӮиҜҙJava Agentд»Јз ҒдёҺдёҡеҠЎд»Јз Ғе…ұдә«AppClassLoaderпјҢиў«JVMзӣҙжҺҘеҠ иҪҪзҡ„agent.jarеҰӮжһңеј•е…ҘдәҶ第дёүж–№дҫқиө–пјҢеҸҜиғҪдјҡеҜ№дёҡеҠЎClassйҖ жҲҗжұЎжҹ“гҖӮжҲӘжӯўеҸ‘зЁҝж—¶пјҢJVM-ProfilerйғҪеӯҳеңЁиҝҷдёӘй—®йўҳпјҢе®ғеј•е…ҘдәҶKafka-ClientгҖҒhttp-ClientгҖҒJacksonзӯү组件пјҢеҰӮжһңдёҺдёҡеҠЎд»Јз Ғдёӯзҡ„组件зүҲжң¬еҸ‘з”ҹеҶІзӘҒпјҢеҸҜиғҪдјҡеј•еҸ‘жңӘзҹҘй”ҷиҜҜгҖӮGreys/Arthas/JVM-Sandboxзҡ„и§ЈеҶіж–№ејҸжҳҜеҲҶзҰ»е…ҘеҸЈдёҺж ёеҝғд»Јз ҒпјҢдҪҝз”Ёе®ҡеҲ¶зҡ„ClassLoaderеҠ иҪҪж ёеҝғд»Јз ҒпјҢйҒҝе…ҚеҪұе“ҚдёҡеҠЎд»Јз ҒгҖӮ
еңЁжӣҙеә•еұӮзҡ„C/C++еұӮйқўпјҢжҲ‘们еҸҜд»ҘзӣҙжҺҘеҜ№жҺҘJVMTIжҺҘеҸЈпјҢдҪҝз”ЁеҺҹз”ҹC APIеҜ№JVMиҝӣиЎҢж“ҚдҪңпјҢеҠҹиғҪжӣҙдё°еҜҢжӣҙејәеӨ§пјҢдҪҶејҖеҸ‘ж•ҲзҺҮеҒҸдҪҺгҖӮеҹәдәҺдёҠиҠӮеҗҢж ·зҡ„еҺҹзҗҶејҖеҸ‘CPU ProfilerпјҢдҪҝз”ЁJVMTIйңҖиҰҒиҝӣиЎҢеҰӮдёӢиҝҷдәӣжӯҘйӘӨпјҡ
1. зј–еҶҷAgent_OnLoad()пјҢеңЁе…ҘеҸЈйҖҡиҝҮJNIзҡ„JavaVM*жҢҮй’Ҳзҡ„GetEnv()еҮҪж•°жӢҝеҲ°JVMTIзҡ„jvmtiEnvжҢҮй’Ҳпјҡ
// agent.c
JNIEXPORT jint JNICALL Agent_OnLoad(JavaVM *vm, char *options, void *reserved) {
jvmtiEnv *jvmti;
(*vm)->GetEnv((void **)&jvmti, JVMTI_VERSION_1_0);
// ...
return JNI_OK;
}
2. ејҖеҗҜдёҖдёӘзәҝзЁӢе®ҡж—¶еҫӘзҺҜпјҢе®ҡж—¶дҪҝз”ЁjvmtiEnvжҢҮй’Ҳй…ҚеҗҲи°ғз”ЁеҰӮдёӢеҮ дёӘJVMTIеҮҪж•°пјҡ
// иҺ·еҸ–жүҖжңүзәҝзЁӢзҡ„jthread
jvmtiError GetAllThreads(jvmtiEnv *env, jint *threads_count_ptr, jthread **threads_ptr);
// ж №жҚ®jthreadиҺ·еҸ–иҜҘзәҝзЁӢдҝЎжҒҜпјҲnameгҖҒdaemonгҖҒpriority...пјү
jvmtiError GetThreadInfo(jvmtiEnv *env, jthread thread, jvmtiThreadInfo* info_ptr);
// ж №жҚ®jthreadиҺ·еҸ–иҜҘзәҝзЁӢи°ғз”Ёж Ҳ
jvmtiError GetStackTrace(jvmtiEnv *env,
jthread thread,
jint start_depth,
jint max_frame_count,
jvmtiFrameInfo *frame_buffer,
jint *count_ptr);
дё»йҖ»иҫ‘еӨ§иҮҙжҳҜпјҡйҰ–е…Ҳи°ғз”ЁGetAllThreads()иҺ·еҸ–жүҖжңүзәҝзЁӢзҡ„вҖңеҸҘжҹ„вҖқjthreadпјҢ然еҗҺйҒҚеҺҶж №жҚ®jthreadи°ғз”ЁGetThreadInfo()иҺ·еҸ–зәҝзЁӢдҝЎжҒҜпјҢжҢүзәҝзЁӢеҗҚиҝҮж»ӨжҺүдёҚйңҖиҰҒзҡ„зәҝзЁӢеҗҺпјҢ继з»ӯйҒҚеҺҶж №жҚ®jthreadи°ғз”ЁGetStackTrace()иҺ·еҸ–зәҝзЁӢзҡ„и°ғз”Ёж ҲгҖӮ
3. еңЁBufferдёӯдҝқеӯҳжҜҸдёҖж¬Ўзҡ„йҮҮж ·з»“жһңпјҢжңҖз»Ҳз”ҹжҲҗеҝ…иҰҒзҡ„з»ҹи®Ўж•°жҚ®еҚіеҸҜгҖӮ
жҢүеҰӮдёҠжӯҘйӘӨеҚіеҸҜе®һзҺ°еҹәдәҺJVMTIзҡ„CPU ProfilerгҖӮдҪҶйңҖиҰҒиҜҙжҳҺзҡ„жҳҜпјҢеҚідҫҝжҳҜеҹәдәҺеҺҹз”ҹJVMTIжҺҘеҸЈдҪҝз”ЁGetStackTrace()зҡ„ж–№ејҸиҺ·еҸ–и°ғз”Ёж ҲпјҢд№ҹеӯҳеңЁдёҺJMXзӣёеҗҢзҡ„й—®йўҳвҖ”вҖ”еҸӘиғҪеңЁе®үе…ЁзӮ№пјҲSafe PointпјүиҝӣиЎҢйҮҮж ·гҖӮ
SafePoint Biasй—®йўҳ
ж ·жң¬еҝ…йЎ»и¶іеӨҹеӨҡгҖӮ
зЁӢеәҸдёӯжүҖжңүжӯЈеңЁиҝҗиЎҢзҡ„д»Јз ҒзӮ№йғҪеҝ…йЎ»д»ҘзӣёеҗҢзҡ„жҰӮзҺҮиў«ProfilerйҮҮж ·гҖӮ
дёҠж–ҮжҲ‘们жҸҗеҲ°пјҢеҹәдәҺJMXдёҺеҹәдәҺJVMTIзҡ„Profilerе®һзҺ°йғҪеӯҳеңЁSafePoint BiasпјҢдҪҶдёҖдёӘеҖјеҫ—дәҶи§Јзҡ„з»ҶиҠӮжҳҜпјҡеҚ•зӢ¬жқҘиҜҙпјҢJVMTIзҡ„GetStackTrace()еҮҪ数并дёҚйңҖиҰҒеңЁCallerзҡ„е®үе…ЁзӮ№жү§иЎҢпјҢдҪҶеҪ“и°ғз”ЁGetStackTrace()иҺ·еҸ–е…¶д»–зәҝзЁӢзҡ„и°ғз”Ёж Ҳж—¶пјҢеҝ…йЎ»зӯүеҫ…пјҢзӣҙеҲ°зӣ®ж ҮзәҝзЁӢиҝӣе…Ҙе®үе…ЁзӮ№пјӣиҖҢдё”пјҢGetStackTrace()д»…иғҪйҖҡиҝҮеҚ•зӢ¬зҡ„зәҝзЁӢеҗҢжӯҘе®ҡж—¶и°ғз”ЁпјҢдёҚиғҪеңЁUNIXдҝЎеҸ·еӨ„зҗҶеҷЁзҡ„Handlerдёӯиў«ејӮжӯҘи°ғз”ЁгҖӮз»јеҗҲжқҘиҜҙпјҢGetStackTrace()еӯҳеңЁдёҺJMXдёҖж ·зҡ„SafePoint BiasгҖӮжӣҙеӨҡе®үе…ЁзӮ№зӣёе…ізҡ„зҹҘиҜҶеҸҜд»ҘеҸӮиҖғгҖҠSafepoints: Meaning, Side Effects and OverheadsгҖӢгҖӮ
йӮЈд№ҲпјҢеҰӮдҪ•йҒҝе…ҚSafePoint BiasпјҹзӨҫеҢәжҸҗдҫӣдәҶдёҖз§ҚHackжҖқи·ҜвҖ”вҖ”AsyncGetCallTraceгҖӮ
еҹәдәҺJVMTI + AsyncGetCallTraceе®һзҺ°
еҰӮдёҠиҠӮжүҖиҝ°пјҢеҒҮеҰӮжҲ‘们жӢҘжңүдёҖдёӘеҮҪж•°еҸҜд»ҘиҺ·еҸ–еҪ“еүҚзәҝзЁӢзҡ„и°ғз”Ёж Ҳдё”дёҚеҸ—е®үе…ЁзӮ№е№Іжү°пјҢеҸҰеӨ–е®ғиҝҳж”ҜжҢҒеңЁUNIXдҝЎеҸ·еӨ„зҗҶеҷЁдёӯиў«ејӮжӯҘи°ғз”ЁпјҢйӮЈд№ҲжҲ‘们еҸӘйңҖжіЁеҶҢдёҖдёӘUNIXдҝЎеҸ·еӨ„зҗҶеҷЁпјҢеңЁHandlerдёӯи°ғз”ЁиҜҘеҮҪж•°иҺ·еҸ–еҪ“еүҚзәҝзЁӢзҡ„и°ғз”Ёж ҲеҚіеҸҜгҖӮз”ұдәҺUNIXдҝЎеҸ·дјҡиў«еҸ‘йҖҒз»ҷиҝӣзЁӢзҡ„йҡҸжңәдёҖзәҝзЁӢиҝӣиЎҢеӨ„зҗҶпјҢеӣ жӯӨжңҖз»ҲдҝЎеҸ·дјҡеқҮеҢҖеҲҶеёғеңЁжүҖжңүзәҝзЁӢдёҠпјҢд№ҹе°ұеқҮеҢҖиҺ·еҸ–дәҶжүҖжңүзәҝзЁӢзҡ„и°ғз”Ёж Ҳж ·жң¬гҖӮ
OracleJDK/OpenJDKеҶ…йғЁжҸҗдҫӣдәҶиҝҷд№ҲдёҖдёӘеҮҪж•°вҖ”вҖ”AsyncGetCallTraceпјҢе®ғзҡ„еҺҹеһӢеҰӮдёӢпјҡ
// ж Ҳеё§
typedef struct {
jint lineno;
jmethodID method_id;
} AGCT_CallFrame;
// и°ғз”Ёж Ҳ
typedef struct {
JNIEnv *env;
jint num_frames;
AGCT_CallFrame *frames;
} AGCT_CallTrace;
// ж №жҚ®ucontextе°Ҷи°ғз”Ёж ҲеЎ«е……иҝӣtraceжҢҮй’Ҳ
void AsyncGetCallTrace(AGCT_CallTrace *trace, jint depth, void *ucontext);
йҖҡиҝҮеҺҹеһӢеҸҜд»ҘзңӢеҲ°пјҢиҜҘеҮҪж•°зҡ„дҪҝз”Ёж–№ејҸйқһеёёз®ҖжҙҒпјҢзӣҙжҺҘйҖҡиҝҮucontextе°ұиғҪиҺ·еҸ–еҲ°е®Ңж•ҙзҡ„Javaи°ғз”Ёж ҲгҖӮ
йЎҫеҗҚжҖқд№үпјҢAsyncGetCallTraceжҳҜвҖңasyncвҖқзҡ„пјҢдёҚеҸ—е®үе…ЁзӮ№еҪұе“ҚпјҢиҝҷж ·зҡ„иҜқйҮҮж ·е°ұеҸҜиғҪеҸ‘з”ҹеңЁд»»дҪ•ж—¶й—ҙпјҢеҢ…жӢ¬Nativeд»Јз Ғжү§иЎҢжңҹй—ҙгҖҒGCжңҹй—ҙзӯүпјҢеңЁиҝҷж—¶жҲ‘们жҳҜж— жі•иҺ·еҸ–Javaи°ғз”Ёж Ҳзҡ„пјҢAGCT_CallTraceзҡ„num_framesеӯ—ж®өжӯЈеёёжғ…еҶөдёӢж ҮиҜҶдәҶиҺ·еҸ–еҲ°зҡ„и°ғз”Ёж Ҳж·ұеәҰпјҢдҪҶеңЁеҰӮеүҚжүҖиҝ°зҡ„ејӮеёёжғ…еҶөдёӢе®ғе°ұиЎЁзӨәдёәиҙҹж•°пјҢжңҖеёёи§Ғзҡ„-2д»ЈиЎЁжӯӨеҲ»жӯЈеңЁGCгҖӮ
з”ұдәҺAsyncGetCallTraceйқһж ҮеҮҶJVMTIеҮҪж•°пјҢеӣ жӯӨжҲ‘д»¬ж— жі•еңЁjvmti.hдёӯжүҫеҲ°иҜҘеҮҪж•°еЈ°жҳҺпјҢдё”з”ұдәҺе…¶зӣ®ж Үж–Ү件д№ҹж—©е·Ій“ҫжҺҘиҝӣJVMдәҢиҝӣеҲ¶ж–Ү件дёӯпјҢжүҖд»Ҙж— жі•йҖҡиҝҮз®ҖеҚ•зҡ„еЈ°жҳҺжқҘиҺ·еҸ–иҜҘеҮҪж•°зҡ„ең°еқҖпјҢиҝҷйңҖиҰҒйҖҡиҝҮдёҖдәӣTrickж–№ејҸжқҘи§ЈеҶігҖӮз®ҖеҚ•иҜҙпјҢAgentжңҖз»ҲжҳҜдҪңдёәеҠЁжҖҒй“ҫжҺҘеә“еҠ иҪҪеҲ°зӣ®ж ҮJVMиҝӣзЁӢзҡ„ең°еқҖз©әй—ҙдёӯпјҢеӣ жӯӨеҸҜд»ҘеңЁAgent_OnLoadеҶ…йҖҡиҝҮglibcжҸҗдҫӣзҡ„dlsym()еҮҪж•°жӢҝеҲ°еҪ“еүҚең°еқҖз©әй—ҙпјҲеҚізӣ®ж ҮJVMиҝӣзЁӢең°еқҖз©әй—ҙпјүеҗҚдёәвҖңAsyncGetCallTraceвҖқзҡ„з¬ҰеҸ·ең°еқҖгҖӮиҝҷж ·е°ұжӢҝеҲ°дәҶиҜҘеҮҪж•°зҡ„жҢҮй’ҲпјҢжҢүз…§дёҠиҝ°еҺҹеһӢиҝӣиЎҢзұ»еһӢиҪ¬жҚўеҗҺпјҢе°ұеҸҜд»ҘжӯЈеёёи°ғз”ЁдәҶгҖӮ
йҖҡиҝҮAsyncGetCallTraceе®һзҺ°CPU Profilerзҡ„еӨ§иҮҙжөҒзЁӢпјҡ
1. зј–еҶҷAgent_OnLoad()пјҢеңЁе…ҘеҸЈжӢҝеҲ°jvmtiEnvе’ҢAsyncGetCallTraceжҢҮй’ҲпјҢиҺ·еҸ–AsyncGetCallTraceж–№ејҸеҰӮдёӢ:
typedef void (*AsyncGetCallTrace)(AGCT_CallTrace *traces, jint depth, void *ucontext);
// ...
AsyncGetCallTrace agct_ptr = (AsyncGetCallTrace)dlsym(RTLD_DEFAULT, "AsyncGetCallTrace");
if (agct_ptr == NULL) {
void *libjvm = dlopen("libjvm.so", RTLD_NOW);
if (!libjvm) {
// еӨ„зҗҶdlerror()...
}
agct_ptr = (AsyncGetCallTrace)dlsym(libjvm, "AsyncGetCallTrace");
}
2. еңЁOnLoadйҳ¶ж®өпјҢжҲ‘们иҝҳйңҖиҰҒеҒҡдёҖ件дәӢпјҢеҚіжіЁеҶҢOnClassLoadе’ҢOnClassPrepareиҝҷдёӨдёӘHookпјҢеҺҹеӣ жҳҜjmethodIDжҳҜ延иҝҹеҲҶй…Қзҡ„пјҢдҪҝз”ЁAGCTиҺ·еҸ–Tracesдҫқиө–йў„е…ҲеҲҶй…ҚеҘҪзҡ„ж•°жҚ®гҖӮжҲ‘们еңЁOnClassPrepareзҡ„CallBackдёӯе°қиҜ•иҺ·еҸ–иҜҘClassзҡ„жүҖжңүMethodsпјҢиҝҷж ·е°ұдҪҝJVMTIжҸҗеүҚеҲҶй…ҚдәҶжүҖжңүж–№жі•зҡ„jmethodIDпјҢеҰӮдёӢжүҖзӨәпјҡ
void JNICALL OnClassLoad(jvmtiEnv *jvmti, JNIEnv* jni, jthread thread, jclass klass) {}
void JNICALL OnClassPrepare(jvmtiEnv *jvmti, JNIEnv *jni, jthread thread, jclass klass) {
jint method_count;
jmethodID *methods;
jvmti->GetClassMethods(klass, &method_count, &methods);
delete [] methods;
}
// ...
jvmtiEventCallbacks callbacks = {0};
callbacks.ClassLoad = OnClassLoad;
callbacks.ClassPrepare = OnClassPrepare;
jvmti->SetEventCallbacks(&callbacks, sizeof(callbacks));
jvmti->SetEventNotificationMode(JVMTI_ENABLE, JVMTI_EVENT_CLASS_LOAD, NULL);
jvmti->SetEventNotificationMode(JVMTI_ENABLE, JVMTI_EVENT_CLASS_PREPARE, NULL);
3. еҲ©з”ЁSIGPROFдҝЎеҸ·жқҘиҝӣиЎҢе®ҡж—¶йҮҮж ·пјҡ
// иҝҷйҮҢдҝЎеҸ·handlerдј иҝӣжқҘзҡ„зҡ„ucontextеҚіAsyncGetCallTraceйңҖиҰҒзҡ„ucontext
void signal_handler(int signo, siginfo_t *siginfo, void *ucontext) {
// дҪҝз”ЁAsyncCallTraceиҝӣиЎҢйҮҮж ·пјҢжіЁж„ҸеӨ„зҗҶnum_framesдёәиҙҹзҡ„ејӮеёёжғ…еҶө
}
// ...
// жіЁеҶҢSIGPROFдҝЎеҸ·зҡ„handler
struct sigaction sa;
sigemptyset(&sa.sa_mask);
sa.sa_sigaction = signal_handler;
sa.sa_flags = SA_RESTART | SA_SIGINFO;
sigaction(SIGPROF, &sa, NULL);
// е®ҡж—¶дә§з”ҹSIGPROFдҝЎеҸ·
// intervalжҳҜnanosecondsиЎЁзӨәзҡ„йҮҮж ·й—ҙйҡ”пјҢAsyncGetCallTraceзӣёеҜ№дәҺеҗҢжӯҘйҮҮж ·жқҘиҜҙеҸҜд»ҘйҖӮеҪ“й«ҳйў‘дёҖдәӣ
long sec = interval / 1000000000;
long usec = (interval % 1000000000) / 1000;
struct itimerval tv = {{sec, usec}, {sec, usec}};
setitimer(ITIMER_PROF, &tv, NULL);
4.еңЁBufferдёӯдҝқеӯҳжҜҸдёҖж¬Ўзҡ„йҮҮж ·з»“жһңпјҢжңҖз»Ҳз”ҹжҲҗеҝ…иҰҒзҡ„з»ҹи®Ўж•°жҚ®еҚіеҸҜгҖӮ
жҢүеҰӮдёҠжӯҘйӘӨеҚіеҸҜе®һзҺ°еҹәдәҺAsyncGetCallTraceзҡ„CPU ProfilerпјҢиҝҷжҳҜзӨҫеҢәдёӯзӣ®еүҚжҖ§иғҪејҖй”ҖжңҖдҪҺгҖҒзӣёеҜ№ж•ҲзҺҮжңҖй«ҳзҡ„CPU Profilerе®һзҺ°ж–№ејҸпјҢеңЁLinuxзҺҜеўғдёӢз»“еҗҲperf_eventsиҝҳиғҪеҒҡеҲ°еҗҢж—¶йҮҮж ·Javaж ҲдёҺNativeж ҲпјҢд№ҹе°ұиғҪеҗҢж—¶еҲҶжһҗNativeд»Јз ҒдёӯеӯҳеңЁзҡ„жҖ§иғҪзғӯзӮ№гҖӮиҜҘж–№ејҸзҡ„е…ёеһӢејҖжәҗе®һзҺ°жңүAsync-Profilerе’ҢHonest-ProfilerпјҢAsync-Profilerе®һзҺ°иҙЁйҮҸиҫғй«ҳпјҢж„ҹе…ҙи¶Јзҡ„иҜқе»әи®®еӨ§е®¶йҳ…иҜ»еҸӮиҖғжәҗз ҒгҖӮжңүи¶Јзҡ„жҳҜпјҢIntelliJ IDEAеҶ…зҪ®зҡ„Java ProfilerпјҢе…¶е®һе°ұжҳҜAsync-Profilerзҡ„еҢ…иЈ…гҖӮжӣҙеӨҡе…ідәҺAsyncGetCallTraceзҡ„еҶ…е®№пјҢеӨ§е®¶еҸҜд»ҘеҸӮиҖғгҖҠThe Pros and Cons of AsyncGetCallTrace ProfilersгҖӢгҖӮ
з”ҹжҲҗжҖ§иғҪзҒ«з„°еӣҫ
зҺ°еңЁжҲ‘们жӢҘжңүдәҶйҮҮж ·и°ғз”Ёж Ҳзҡ„иғҪеҠӣпјҢдҪҶжҳҜи°ғз”Ёж Ҳж ·жң¬йӣҶжҳҜд»ҘдәҢз»ҙж•°з»„зҡ„ж•°жҚ®з»“жһ„еҪўејҸеӯҳеңЁдәҺеҶ…еӯҳдёӯзҡ„пјҢеҰӮдҪ•е°Ҷе…¶иҪ¬жҚўдёәеҸҜи§ҶеҢ–зҡ„зҒ«з„°еӣҫе‘ўпјҹ
зҒ«з„°еӣҫйҖҡеёёжҳҜдёҖдёӘsvgж–Ү件пјҢйғЁеҲҶдјҳз§ҖйЎ№зӣ®еҸҜд»Ҙж №жҚ®ж–Үжң¬ж–Ү件иҮӘеҠЁз”ҹжҲҗзҒ«з„°еӣҫж–Ү件пјҢд»…еҜ№ж–Үжң¬ж–Ү件зҡ„ж јејҸжңүдёҖе®ҡиҰҒжұӮгҖӮFlameGraphйЎ№зӣ®зҡ„ж ёеҝғеҸӘжҳҜдёҖдёӘPerlи„ҡжң¬пјҢеҸҜд»Ҙж №жҚ®жҲ‘们жҸҗдҫӣзҡ„и°ғз”Ёж Ҳж–Үжң¬з”ҹжҲҗзӣёеә”зҡ„зҒ«з„°еӣҫsvgж–Ү件гҖӮи°ғз”Ёж Ҳзҡ„ж–Үжң¬ж јејҸзӣёеҪ“з®ҖеҚ•пјҢеҰӮдёӢжүҖзӨәпјҡ
base_func;func1;func2;func3 10
base_func;funca;funcb 15
е°ҶжҲ‘们йҮҮж ·еҲ°зҡ„и°ғз”Ёж Ҳж ·жң¬йӣҶиҝӣиЎҢж•ҙеҗҲеҗҺпјҢйңҖиҫ“еҮәеҰӮдёҠжүҖзӨәзҡ„ж–Үжң¬ж јејҸгҖӮжҜҸдёҖиЎҢд»ЈиЎЁдёҖвҖңзұ»вҖңи°ғз”Ёж ҲпјҢз©әж је·Ұиҫ№жҳҜи°ғз”Ёж Ҳзҡ„ж–№жі•еҗҚжҺ’еҲ—пјҢд»ҘеҲҶеҸ·еҲҶеүІпјҢе·Ұж Ҳеә•еҸіж ҲйЎ¶пјҢз©әж јеҸіиҫ№жҳҜиҜҘж ·жң¬еҮәзҺ°зҡ„ж¬Ўж•°гҖӮ
е°Ҷж ·жң¬ж–Ү件дәӨз»ҷflamegraph.plи„ҡжң¬жү§иЎҢпјҢе°ұиғҪиҫ“еҮәзӣёеә”зҡ„зҒ«з„°еӣҫдәҶпјҡ
$ flamegraph.pl stacktraces.txt > stacktraces.svg
ж•ҲжһңеҰӮдёӢеӣҫжүҖзӨәпјҡ
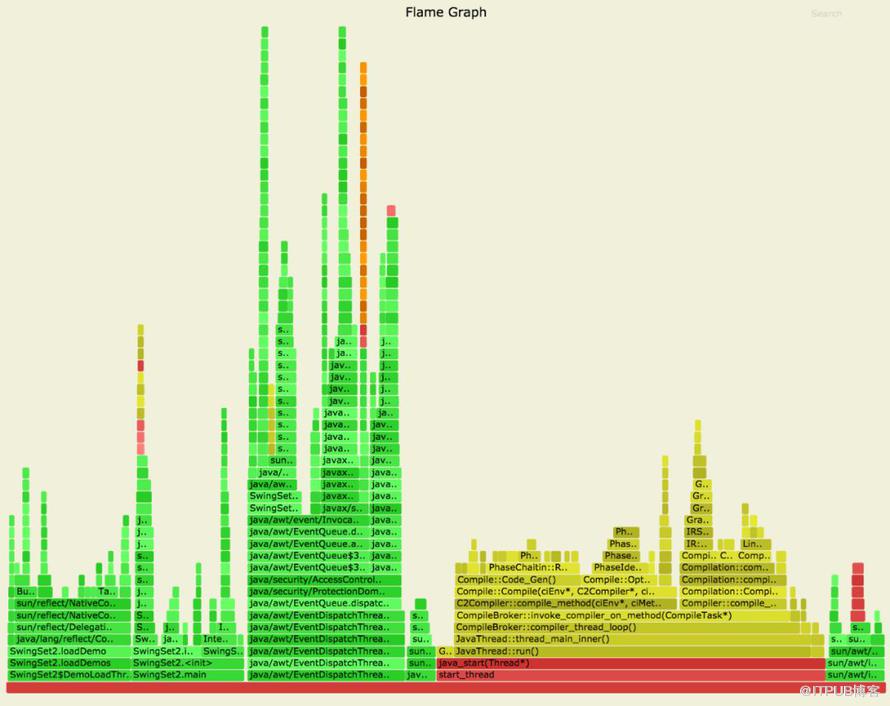 йҖҡиҝҮflamegraph.plз”ҹжҲҗзҡ„зҒ«з„°еӣҫ
йҖҡиҝҮflamegraph.plз”ҹжҲҗзҡ„зҒ«з„°еӣҫ
HotSpotзҡ„Dynamic AttachжңәеҲ¶и§Јжһҗ
еҲ°зӣ®еүҚдёәжӯўпјҢжҲ‘们已з»ҸдәҶи§ЈдәҶCPU Profilerе®Ңж•ҙзҡ„е·ҘдҪңеҺҹзҗҶпјҢ然иҖҢдҪҝз”ЁиҝҮJProfiler/Arthasзҡ„еҗҢеӯҰеҸҜиғҪдјҡжңүз–‘й—®пјҢеҫҲеӨҡжғ…еҶөдёӢеҸҜд»ҘзӣҙжҺҘеҜ№зәҝдёҠиҝҗиЎҢдёӯзҡ„жңҚеҠЎиҝӣиЎҢProflingпјҢ并дёҚйңҖиҰҒеңЁJavaиҝӣзЁӢзҡ„еҗҜеҠЁеҸӮж•°ж·»еҠ AgentеҸӮж•°пјҢиҝҷжҳҜйҖҡиҝҮд»Җд№ҲжүӢж®өеҒҡеҲ°зҡ„пјҹзӯ”жЎҲжҳҜDynamic AttachгҖӮ
JDKеңЁ1.6д»ҘеҗҺжҸҗдҫӣдәҶAttach APIпјҢе…Ғи®ёеҗ‘иҝҗиЎҢдёӯзҡ„JVMиҝӣзЁӢж·»еҠ AgentпјҢиҝҷйЎ№жүӢж®өиў«е№ҝжіӣдҪҝз”ЁеңЁеҗ„з§ҚProfilerе’Ңеӯ—иҠӮз Ғеўһејәе·Ҙе…·дёӯпјҢе…¶е®ҳж–№з®Җд»ӢеҰӮдёӢпјҡ
This is a Sun extension that allows a tool to 'attach' to another process running Java code and launch a JVM TI agent or a java.lang.instrument agent in that process.
жҖ»зҡ„жқҘиҜҙпјҢDynamic AttachжҳҜHotSpotжҸҗдҫӣзҡ„дёҖз§Қзү№ж®ҠиғҪеҠӣпјҢе®ғе…Ғи®ёдёҖдёӘиҝӣзЁӢеҗ‘еҸҰдёҖдёӘиҝҗиЎҢдёӯзҡ„JVMиҝӣзЁӢеҸ‘йҖҒдёҖдәӣе‘Ҫд»Ө并жү§иЎҢпјҢе‘Ҫд»Ө并дёҚйҷҗдәҺеҠ иҪҪAgentпјҢиҝҳеҢ…жӢ¬DumpеҶ…еӯҳгҖҒDumpзәҝзЁӢзӯүзӯүгҖӮ
йҖҡиҝҮsun.toolsиҝӣиЎҢAttach
AttachиҷҪ然жҳҜHotSpotжҸҗдҫӣзҡ„иғҪеҠӣпјҢдҪҶJDKеңЁJavaеұӮйқўд№ҹеҜ№е…¶еҒҡдәҶе°ҒиЈ…гҖӮ
еүҚж–Үе·Із»ҸжҸҗеҲ°пјҢеҜ№дәҺJava AgentжқҘиҜҙпјҢPreMainж–№жі•еңЁAgentдҪңдёәеҗҜеҠЁеҸӮж•°иҝҗиЎҢзҡ„ж—¶еҖҷжү§иЎҢпјҢе…¶е®һжҲ‘们иҝҳеҸҜд»ҘйўқеӨ–е®һзҺ°дёҖдёӘAgentMainж–№жі•пјҢ并еңЁMANIFEST.MFдёӯе°ҶAgent-ClassжҢҮе®ҡдёәиҜҘClassпјҡ
public static void agentmain(String args, Instrumentation ins) {
// implement
}
иҝҷж ·жү“еҢ…еҮәжқҘзҡ„jarпјҢж—ўеҸҜд»ҘдҪңдёә-javaagentеҸӮж•°еҗҜеҠЁпјҢд№ҹеҸҜд»Ҙиў«AttachеҲ°иҝҗиЎҢдёӯзҡ„зӣ®ж ҮJVMиҝӣзЁӢгҖӮJDKе·Із»Ҹе°ҒиЈ…дәҶз®ҖеҚ•зҡ„APIи®©жҲ‘们зӣҙжҺҘAttachдёҖдёӘJava AgentпјҢдёӢйқўд»ҘArthasдёӯзҡ„д»Јз ҒиҝӣиЎҢжј”зӨәпјҡ
// com/taobao/arthas/core/Arthas.java
import com.sun.tools.attach.VirtualMachine;
import com.sun.tools.attach.VirtualMachineDescriptor;
// ...
private void attachAgent(Configure configure) throws Exception {
VirtualMachineDescriptor virtualMachineDescriptor = null;
// жӢҝеҲ°жүҖжңүJVMиҝӣзЁӢпјҢжүҫеҮәзӣ®ж ҮиҝӣзЁӢ
for (VirtualMachineDescriptor descriptor : VirtualMachine.list()) {
String pid = descriptor.id();
if (pid.equals(Integer.toString(configure.getJavaPid()))) {
virtualMachineDescriptor = descriptor;
}
}
VirtualMachine virtualMachine = null;
try {
// й’ҲеҜ№жҹҗдёӘJVMиҝӣзЁӢи°ғз”ЁVirtualMachine.attach()ж–№жі•пјҢжӢҝеҲ°VirtualMachineе®һдҫӢ
if (null == virtualMachineDescriptor) {
virtualMachine = VirtualMachine.attach("" + configure.getJavaPid());
} else {
virtualMachine = VirtualMachine.attach(virtualMachineDescriptor);
}
// ...
// и°ғз”ЁVirtualMachine#loadAgent()пјҢе°ҶarthasAgentPathжҢҮе®ҡзҡ„jar attachеҲ°зӣ®ж ҮJVMиҝӣзЁӢдёӯ
// 第дәҢдёӘеҸӮж•°дёәattachеҸӮж•°пјҢеҚіagentmainзҡ„йҰ–дёӘStringеҸӮж•°args
virtualMachine.loadAgent(arthasAgentPath, configure.getArthasCore() + ";" + configure.toString());
} finally {
if (null != virtualMachine) {
// и°ғз”ЁVirtualMachine#detach()йҮҠж”ҫ
virtualMachine.detach();
}
}
}
зӣҙжҺҘеҜ№HotSpotиҝӣиЎҢAttach
sun.toolsе°ҒиЈ…зҡ„APIи¶іеӨҹз®ҖеҚ•жҳ“з”ЁпјҢдҪҶеҸӘиғҪдҪҝз”ЁJavaзј–еҶҷпјҢд№ҹеҸӘиғҪз”ЁеңЁJava AgentдёҠпјҢеӣ жӯӨжңүдәӣж—¶еҖҷжҲ‘们еҝ…йЎ»жүӢе·ҘеҜ№JVMиҝӣзЁӢзӣҙжҺҘиҝӣиЎҢAttachгҖӮеҜ№дәҺJVMTIпјҢйҷӨдәҶAgent_OnLoad()д№ӢеӨ–пјҢжҲ‘们иҝҳйңҖе®һзҺ°дёҖдёӘAgent_OnAttach()еҮҪж•°пјҢеҪ“е°ҶJVMTI Agent AttachеҲ°зӣ®ж ҮиҝӣзЁӢж—¶пјҢд»ҺиҜҘеҮҪж•°ејҖе§Ӣжү§иЎҢпјҡ
// $JAVA_HOME/include/jvmti.h
JNIEXPORT jint JNICALL Agent_OnAttach(JavaVM *vm, char *options, void *reserved);
дёӢйқўжҲ‘们д»ҘAsync-Profilerдёӯзҡ„jattachжәҗз ҒдёәзәҝзҙўпјҢжҺўз©¶дёҖдёӢеҰӮдҪ•еҲ©з”ЁAttachжңәеҲ¶з»ҷиҝҗиЎҢдёӯзҡ„JVMиҝӣзЁӢеҸ‘йҖҒе‘Ҫд»ӨгҖӮjattachжҳҜAsync-ProfilerжҸҗдҫӣзҡ„дёҖдёӘDriverпјҢдҪҝз”Ёж–№ејҸжҜ”иҫғзӣҙи§Ӯпјҡ
Usage:
jattach <pid> <cmd> [args ...]
Args:
<pid> зӣ®ж ҮJVMиҝӣзЁӢзҡ„иҝӣзЁӢID
<cmd> иҰҒжү§иЎҢзҡ„е‘Ҫд»Ө
<args> е‘Ҫд»ӨеҸӮж•°
дҪҝз”Ёж–№ејҸеҰӮпјҡ
$ jattach 1234 load /absolute/path/to/agent/libagent.so true
жү§иЎҢдёҠиҝ°е‘Ҫд»ӨпјҢlibagent.soе°ұиў«еҠ иҪҪеҲ°IDдёә1234зҡ„JVMиҝӣзЁӢдёӯ并ејҖе§Ӣжү§иЎҢAgent_OnAttachеҮҪж•°дәҶгҖӮжңүдёҖзӮ№йңҖиҰҒжіЁж„ҸпјҢжү§иЎҢAttachзҡ„иҝӣзЁӢeuidеҸҠegidпјҢдёҺиў«Attachзҡ„зӣ®ж ҮJVMиҝӣзЁӢеҝ…йЎ»зӣёеҗҢгҖӮжҺҘдёӢжқҘејҖе§ӢеҲҶжһҗjattachжәҗз ҒгҖӮ
еҰӮдёӢжүҖзӨәзҡ„MainеҮҪж•°жҸҸиҝ°дәҶдёҖж¬ЎAttachзҡ„ж•ҙдҪ“жөҒзЁӢпјҡ
// async-profiler/src/jattach/jattach.c
int main(int argc, char** argv) {
// и§Јжһҗе‘Ҫд»ӨиЎҢеҸӮж•°
// жЈҖжҹҘeuidдёҺegid
// ...
if (!check_socket(nspid) && !start_attach_mechanism(pid, nspid)) {
perror("Could not start attach mechanism");
return 1;
}
int fd = connect_socket(nspid);
if (fd == -1) {
perror("Could not connect to socket");
return 1;
}
printf("Connected to remote JVM\n");
if (!write_command(fd, argc - 2, argv + 2)) {
perror("Error writing to socket");
close(fd);
return 1;
}
printf("Response code = ");
fflush(stdout);
int result = read_response(fd);
close(fd);
return result;
}
еҝҪз•ҘжҺүе‘Ҫд»ӨиЎҢеҸӮж•°и§ЈжһҗдёҺжЈҖжҹҘeuidе’Ңegidзҡ„иҝҮзЁӢгҖӮjattachйҰ–е…Ҳи°ғз”ЁдәҶcheck_socketеҮҪж•°иҝӣиЎҢдәҶвҖңsocketжЈҖжҹҘпјҹвҖқпјҢcheck_socketжәҗз ҒеҰӮдёӢпјҡ
// async-profiler/src/jattach/jattach.c
// Check if remote JVM has already opened socket for Dynamic Attach
static int check_socket(int pid) {
char path[MAX_PATH];
snprintf(path, MAX_PATH, "%s/.java_pid%d", get_temp_directory(), pid); // get_temp_directory()еңЁLinuxдёӢеӣәе®ҡиҝ”еӣһ"/tmp"
struct stat stats;
return stat(path, &stats) == 0 && S_ISSOCK(stats.st_mode);
}
жҲ‘们зҹҘйҒ“пјҢUNIXж“ҚдҪңзі»з»ҹжҸҗдҫӣдәҶдёҖз§ҚеҹәдәҺж–Ү件зҡ„SocketжҺҘеҸЈпјҢз§°дёәвҖңUNIX SocketвҖқпјҲдёҖз§Қеёёз”Ёзҡ„иҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸпјүгҖӮеңЁиҜҘеҮҪж•°дёӯдҪҝз”ЁS_ISSOCKе®ҸжқҘеҲӨж–ӯиҜҘж–Ү件жҳҜеҗҰиў«з»‘е®ҡеҲ°дәҶUNIX SocketпјҢеҰӮжӯӨзңӢжқҘпјҢвҖң/tmp/.java_pid<pid>
жҹҘйҳ…е®ҳж–№ж–ҮжЎЈпјҢеҫ—еҲ°еҰӮдёӢжҸҸиҝ°пјҡ
The attach listener thread then communicates with the source JVM in an OS dependent manner:
On Solaris, the Doors IPC mechanism is used. The door is attached to a file in the file system so that clients can access it.
On Linux, a Unix domain socket is used. This socket is bound to a file in the filesystem so that clients can access it.
On Windows, the created thread is given the name of a pipe which is served by the client. The result of the operations are written to this pipe by the target JVM.
иҜҒжҳҺдәҶжҲ‘们зҡ„зҢңжғіжҳҜжӯЈзЎ®зҡ„гҖӮзӣ®еүҚдёәжӯўcheck_socketеҮҪж•°зҡ„дҪңз”ЁеҫҲе®№жҳ“зҗҶи§ЈдәҶпјҡеҲӨж–ӯеӨ–йғЁиҝӣзЁӢдёҺзӣ®ж ҮJVMиҝӣзЁӢд№Ӣй—ҙжҳҜеҗҰе·Із»Ҹе»әз«ӢдәҶUNIX SocketиҝһжҺҘгҖӮ
еӣһеҲ°MainеҮҪж•°пјҢеңЁдҪҝз”Ёcheck_socketзЎ®е®ҡиҝһжҺҘе°ҡжңӘе»әз«ӢеҗҺпјҢзҙ§жҺҘзқҖи°ғз”Ёstart_attach_mechanismеҮҪж•°пјҢеҮҪж•°еҗҚеҫҲзӣҙи§Ӯең°жҸҸиҝ°дәҶе®ғзҡ„дҪңз”ЁпјҢжәҗз ҒеҰӮдёӢпјҡ
// async-profiler/src/jattach/jattach.c
// Force remote JVM to start Attach listener.
// HotSpot will start Attach listener in response to SIGQUIT if it sees .attach_pid file
static int start_attach_mechanism(int pid, int nspid) {
char path[MAX_PATH];
snprintf(path, MAX_PATH, "/proc/%d/cwd/.attach_pid%d", nspid, nspid);
int fd = creat(path, 0660);
if (fd == -1 || (close(fd) == 0 && !check_file_owner(path))) {
// Failed to create attach trigger in current directory. Retry in /tmp
snprintf(path, MAX_PATH, "%s/.attach_pid%d", get_temp_directory(), nspid);
fd = creat(path, 0660);
if (fd == -1) {
return 0;
}
close(fd);
}
// We have to still use the host namespace pid here for the kill() call
kill(pid, SIGQUIT);
// Start with 20 ms sleep and increment delay each iteration
struct timespec ts = {0, 20000000};
int result;
do {
nanosleep(&ts, NULL);
result = check_socket(nspid);
} while (!result && (ts.tv_nsec += 20000000) < 300000000);
unlink(path);
return result;
}
start_attach_mechanismеҮҪж•°йҰ–е…ҲеҲӣе»әдәҶдёҖдёӘеҗҚдёәвҖң/tmp/.attach_pid<pid>
еҰӮжӯӨзңӢжқҘпјҢHotSpotдјјд№ҺжҸҗдҫӣдәҶдёҖз§Қзү№ж®Ҡзҡ„жңәеҲ¶пјҢеҸӘиҰҒз»ҷе®ғеҸ‘йҖҒдёҖдёӘSIGQUITдҝЎеҸ·пјҢ并预е…ҲеҮҶеӨҮеҘҪ.attach_pid
жҹҘйҳ…ж–ҮжЎЈпјҢеҫ—еҲ°еҰӮдёӢжҸҸиҝ°пјҡ
Dynamic attach has an attach listener thread in the target JVM. This is a thread that is started when the first attach request occurs. On Linux and Solaris, the client creates a file named .attach_pid(pid) and sends a SIGQUIT to the target JVM process. The existence of this file causes the SIGQUIT handler in HotSpot to start the attach listener thread. On Windows, the client uses the Win32 CreateRemoteThread function to create a new thread in the target process.
иҝҷж ·дёҖжқҘе°ұеҫҲжҳҺзЎ®дәҶпјҢеңЁLinuxдёҠжҲ‘们еҸӘйңҖеҲӣе»әдёҖдёӘвҖң/tmp/.attach_pid
继з»ӯзңӢjattachзҡ„жәҗз ҒпјҢжһңдёҚ其然пјҢе®ғи°ғз”ЁдәҶconnect_socketеҮҪж•°еҜ№вҖң/tmp/.java_pid
// async-profiler/src/jattach/jattach.c
// Connect to UNIX domain socket created by JVM for Dynamic Attach
static int connect_socket(int pid) {
int fd = socket(PF_UNIX, SOCK_STREAM, 0);
if (fd == -1) {
return -1;
}
struct sockaddr_un addr;
addr.sun_family = AF_UNIX;
snprintf(addr.sun_path, sizeof(addr.sun_path), "%s/.java_pid%d", get_temp_directory(), pid);
if (connect(fd, (struct sockaddr*)&addr, sizeof(addr)) == -1) {
close(fd);
return -1;
}
return fd;
}
дёҖдёӘеҫҲжҷ®йҖҡзҡ„SocketеҲӣе»әеҮҪж•°пјҢиҝ”еӣһSocketж–Ү件жҸҸиҝ°з¬ҰгҖӮ
еӣһеҲ°MainеҮҪж•°пјҢдё»жөҒзЁӢзҙ§жҺҘзқҖи°ғз”Ёwrite_commandеҮҪж•°еҗ‘иҜҘSocketеҶҷе…ҘдәҶд»Һе‘Ҫд»ӨиЎҢдј иҝӣжқҘзҡ„еҸӮж•°пјҢ并且и°ғз”Ёread_responseеҮҪж•°жҺҘ收д»Һзӣ®ж ҮJVMиҝӣзЁӢиҝ”еӣһзҡ„ж•°жҚ®гҖӮдёӨдёӘеҫҲеёёи§Ғзҡ„SocketиҜ»еҶҷеҮҪж•°пјҢжәҗз ҒеҰӮдёӢпјҡ
// async-profiler/src/jattach/jattach.c
// Send command with arguments to socket
static int write_command(int fd, int argc, char** argv) {
// Protocol version
if (write(fd, "1", 2) <= 0) {
return 0;
}
int i;
for (i = 0; i < 4; i++) {
const char* arg = i < argc ? argv[i] : "";
if (write(fd, arg, strlen(arg) + 1) <= 0) {
return 0;
}
}
return 1;
}
// Mirror response from remote JVM to stdout
static int read_response(int fd) {
char buf[8192];
ssize_t bytes = read(fd, buf, sizeof(buf) - 1);
if (bytes <= 0) {
perror("Error reading response");
return 1;
}
// First line of response is the command result code
buf[bytes] = 0;
int result = atoi(buf);
do {
fwrite(buf, 1, bytes, stdout);
bytes = read(fd, buf, sizeof(buf));
} while (bytes > 0);
return result;
}
жөҸи§Ҳwrite_commandеҮҪж•°е°ұеҸҜзҹҘеӨ–йғЁиҝӣзЁӢдёҺзӣ®ж ҮJVMиҝӣзЁӢд№Ӣй—ҙеҸ‘йҖҒзҡ„ж•°жҚ®ж јејҸзӣёеҪ“з®ҖеҚ•пјҢеҹәжң¬еҰӮдёӢжүҖзӨәпјҡ
<PROTOCOL VERSION>\0<COMMAND>\0<ARG1>\0<ARG2>\0<ARG3>\0
д»Ҙе…ҲеүҚжҲ‘们дҪҝз”Ёзҡ„Loadе‘Ҫд»ӨдёәдҫӢпјҢеҸ‘йҖҒз»ҷHotSpotж—¶ж јејҸеҰӮдёӢпјҡ
1\0load\0/absolute/path/to/agent/libagent.so\0true\0\0
иҮіжӯӨпјҢжҲ‘们已з»ҸдәҶи§ЈдәҶеҰӮдҪ•жүӢе·ҘеҜ№JVMиҝӣзЁӢзӣҙжҺҘиҝӣиЎҢAttachгҖӮ
AttachиЎҘе……д»Ӣз»Қ
Loadе‘Ҫд»Өд»…д»…жҳҜHotSpotжүҖж”ҜжҢҒзҡ„иҜёеӨҡе‘Ҫд»Өдёӯзҡ„дёҖз§ҚпјҢз”ЁдәҺеҠЁжҖҒеҠ иҪҪеҹәдәҺJVMTIзҡ„AgentпјҢе®Ңж•ҙзҡ„е‘Ҫд»ӨиЎЁеҰӮдёӢжүҖзӨәпјҡ
static AttachOperationFunctionInfo funcs[] = {
{ "agentProperties", get_agent_properties },
{ "datadump", data_dump },
{ "dumpheap", dump_heap },
{ "load", JvmtiExport::load_agent_library },
{ "properties", get_system_properties },
{ "threaddump", thread_dump },
{ "inspectheap", heap_inspection },
{ "setflag", set_flag },
{ "printflag", print_flag },
{ "jcmd", jcmd },
{ NULL, NULL }
};
иҜ»иҖ…еҸҜд»Ҙе°қиҜ•дёӢthreaddumpе‘Ҫд»ӨпјҢ然еҗҺеҜ№зӣёеҗҢзҡ„иҝӣзЁӢиҝӣиЎҢjstackпјҢеҜ№жҜ”и§ӮеҜҹиҫ“еҮәпјҢе…¶е®һжҳҜе®Ңе…ЁзӣёеҗҢзҡ„пјҢе…¶е®ғе‘Ҫд»ӨеӨ§е®¶еҸҜд»ҘиҮӘиЎҢиҝӣиЎҢжҺўзҙўгҖӮ
жҖ»зҡ„жқҘиҜҙпјҢе–„з”Ёеҗ„зұ»ProfilerжҳҜжҸҗеҚҮжҖ§иғҪдјҳеҢ–ж•ҲзҺҮзҡ„дёҖжҠҠеҲ©еҷЁпјҢдәҶи§ЈProfilerжң¬иә«зҡ„е®һзҺ°еҺҹзҗҶжӣҙиғҪеё®еҠ©жҲ‘们йҒҝе…ҚеҜ№е·Ҙе…·зҡ„еҗ„з§ҚиҜҜз”ЁгҖӮCPU ProfilerжүҖдҫқиө–зҡ„AttachгҖҒJVMTIгҖҒInstrumentationгҖҒJMXзӯүзҡҶжҳҜJVMе№іеҸ°жҜ”иҫғйҖҡз”Ёзҡ„жҠҖжңҜпјҢеңЁжӯӨеҹәзЎҖдёҠпјҢжҲ‘们еҺ»е®һзҺ°Memory ProfilerгҖҒThread ProfilerгҖҒGC Analyzerзӯүе·Ҙе…·д№ҹжІЎжңүжғіиұЎдёӯйӮЈд№ҲзҘһз§ҳе’ҢеӨҚжқӮдәҶгҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ