жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ

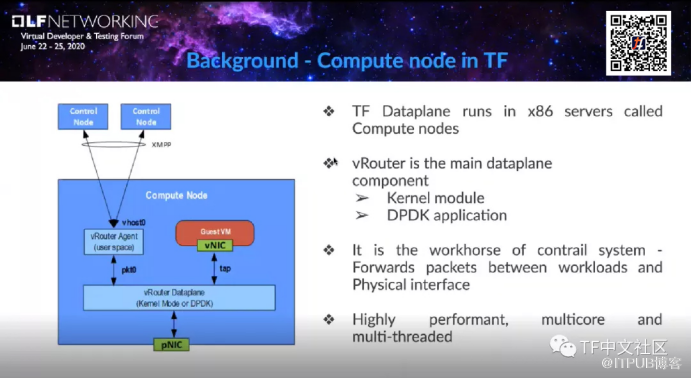
е®һйҷ…дёҠпјҢvRouterеҸҜд»ҘйғЁзҪІеңЁеёёи§„X86жңҚеҠЎеҷЁдёҠпјҢд№ҹеҸҜд»ҘеңЁOpenStackжҲ–K8sзҡ„и®Ўз®—иҠӮзӮ№еҪ“дёӯгҖӮvRouterжҳҜдё»иҰҒзҡ„ж•°жҚ®е№ійқўз»„件пјҢжңүдёӨз§ҚйғЁзҪІзҡ„жЁЎејҸпјҢеҲҶеҲ«жҳҜvRouter:kernel moduleпјҢд»ҘеҸҠvRouter:DPDKжЁЎејҸгҖӮ
https://tungstenfabric.org.cn/assets/uploads/files/tf-vrouter-performance-improvements.pdf
гҖҗ и§Ҷйў‘й“ҫжҺҘ гҖ‘
https://v.qq.com/x/page/j3108a4m1va.html


е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ