您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇“服务器数据沉淀的方案分析”文章的知识点大部分人都不太理解,所以小编给大家总结了以下内容,内容详细,步骤清晰,具有一定的借鉴价值,希望大家阅读完这篇文章能有所收获,下面我们一起来看看这篇“服务器数据沉淀的方案分析”文章吧。
从数据层面来理解,数据可以分为几个维度,比如流水型数据,状态型数据库,配置型数据。流水型数据的依赖最低,基本就是时间维度的扩展,所以从数据的安全角度来说,如果丢数据对业务的影响还是有限的,配置型数据是数据字典级别的,影响范围更是小很多。关键的就是状态型数据,这是非常核心的,因为只是标识状态的变化,如果换做一个场景,比如是金额,那这个维度的影响是很大的。
从数据架构的角度来说,尽可能希望把一些状态型数据的变化,通过流水数据的方式来做一个历史沉淀,我们暂且成为历史数据吧。
比如 更新状态数据,余额为200
Account_id, balance,effective_date, expire_date, status
100 100 20171004010100 20181104010200 1
可以改造为:
Account_id, balance,effective_date, expire_date, status
100 100 20171004010100 20171104010200 0 -->update语句
100 200 20171104010200 20181104010200 1 -->insert语句
所以显而易见的,一个update被改造为了两条语句,从数据生命周期来看,确实有了一定的保障,这也是我们需要和开发同学强调的一种设计方式。
然后我们看一下这种历史数据的处理方案和想法。
一般来说,从设计的角度,尽可能是希望这样来处理历史数据的变化,即从程序层面来解读这个数据的变化情况,可以包装在一个事务里,也可以根据需求来拆分成为异步的方式。当然这种方式是一种看起来很自然的方式,其实也是一种相对来说最理想的方式,从我刻意来画的图来看,是强应用型的。
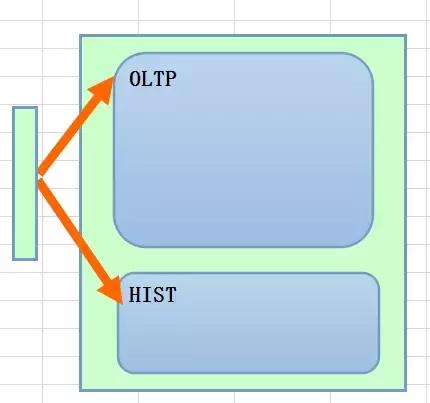
如果换一个角度来说,对于应用来说,历史数据的生成对于他们是透明的,即他们不需要刻意关注这个逻辑,那么这个逻辑就会下沉到数据库层面,所以我画的图中,HIST的部分就会放大,这个逻辑如果在数据库层面来处理,一种自然的方式就是存储过程,当然会对应有一系列的逻辑处理,比如一类业务需要这些历史数据的生成方式,其他类似的业务也是这种思路,那么就需要有一种更加通用的方式,其实从数据库层面来说,这种算是重系统层面的实现,因为数据库层面如果绑定了这个逻辑,那么如果来做扩展就是一个难题了。
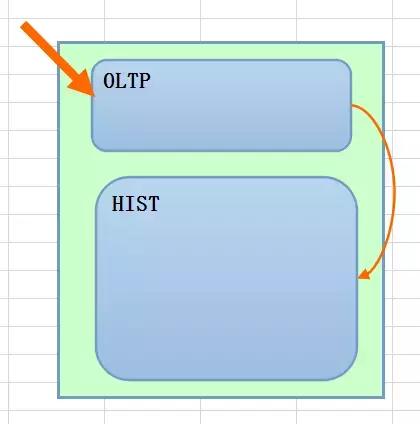
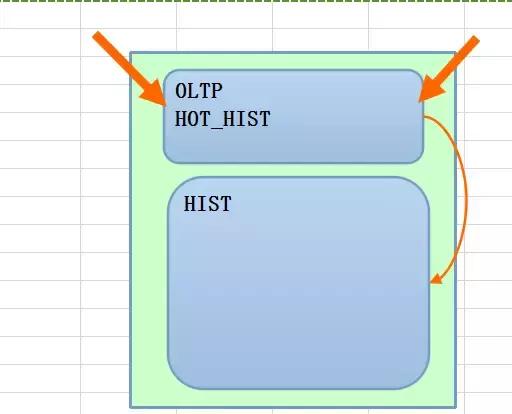
还有一种方式,可能折衷一些,即程序可能下沉到数据处理层,数据库处理层不用刻意去关系数据的意义,数据层可以做数据的写入和流转,可以通过程序层来包装事务来生成历史数据或者是透明的通过OLTP数据生成历史数据,但是关键的一点是,历史数据和OLTP的数据是放在一起的,当然这个表的数据会放大,所以我们需要做一种偏离线的数据归档,比如保留近7天的数据即可。而历史数据可能保留有几个月甚至几年,这样一来历史的数据倒是可以实现分布式存储,可能实际的意义和成本需要做平衡。
以上就是关于“服务器数据沉淀的方案分析”这篇文章的内容,相信大家都有了一定的了解,希望小编分享的内容对大家有帮助,若想了解更多相关的知识内容,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。