жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңеҰӮдҪ•еҲ©з”ЁKubernetesе®һзҺ°е®№еҷЁзҡ„жҢҒд№…еҢ–еӯҳеӮЁвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңеҰӮдҪ•еҲ©з”ЁKubernetesе®һзҺ°е®№еҷЁзҡ„жҢҒд№…еҢ–еӯҳеӮЁвҖқеҗ§!
гҖҖгҖҖеҸҜд»ҘиҜҙпјҢе®№еҷЁеҢ–еҪ»еә•ж”№еҸҳдәҶжҲ‘们еҜ№еә”з”ЁзЁӢеәҸејҖеҸ‘зҡ„жҖқиҖғж–№ејҸпјҢе®ғеёҰжқҘеҫҲеӨҡеҘҪеӨ„:ејҖеҸ‘е’Ңз”ҹдә§д№Ӣй—ҙзҡ„дёҖиҮҙзҺҜеўғгҖҒдҪҝз”Ёе…ұдә«зҡ„иө„жәҗдҪҶе®№еҷЁд№Ӣй—ҙзӣёдә’йҡ”зҰ»гҖҒдә‘зҺҜеўғд№Ӣй—ҙзҡ„еҸҜ移жӨҚжҖ§гҖҒеҝ«йҖҹйғЁзҪІвҖҰвҖҰзӯүзӯүдёҚиғңжһҡдёҫгҖӮе®№еҷЁжүҖеӣәжңүзҡ„зҹӯжҡӮжҖ§жҳҜе®ғд№ӢжүҖд»ҘдјҹеӨ§зҡ„ж ёеҝғеҺҹеӣ пјҡдёҚеҸҜеҸҳзҡ„гҖҒзӣёеҗҢзҡ„е®№еҷЁпјҢеҸҜд»ҘеңЁдёҖзһ¬й—ҙеҝ«йҖҹеҗҜеҠЁгҖӮдҪҶе®№еҷЁзҡ„зҹӯжҡӮжҖ§д№ҹжңүдёҚеҲ©зҡ„дёҖйқўпјҡзјәд№ҸжҢҒд№…еҢ–еӯҳеӮЁгҖӮ
гҖҖгҖҖеј•е…ҘKubernetes
гҖҖгҖҖжҢҒд№…зҠ¶жҖҒ(Persistent state)йҖҡеёёж•°йҮҸиҫғеӨ§дё”йҡҫд»Ҙ移еҠЁпјҢиҝҷдёҖжҰӮеҝөдёҺе®№еҷЁиҝҷз§Қеҝ«йҖҹгҖҒиҪ»йҮҸзә§дё”жҳ“дәҺйҡҸж—¶йғЁзҪІеҲ°д»»дҪ•ең°ж–№зҡ„жҰӮеҝөжңүеҫҲеӨ§зҡ„дёҚеҗҢгҖӮжӯЈжҳҜз”ұдәҺиҝҷдёӘеҺҹеӣ пјҢе®№еҷЁи§„иҢғжңүж„Ҹе°ҶжҢҒд№…зҠ¶жҖҒжҺ’йҷӨеңЁеӨ–пјҢиҪ¬иҖҢйҖүжӢ©еӯҳеӮЁжҸ’件пјҢе°Ҷз®ЎзҗҶжҢҒд№…зҠ¶жҖҒзҡ„иҙЈд»»иҪ¬з§»з»ҷеҸҰдёҖж–№гҖӮ
гҖҖгҖҖејҖжәҗе®№еҷЁзј–жҺ’е·Ҙе…·Kubernetesе·Із»ҸејҖе§ӢзқҖжүӢи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮеңЁиҝҷзҜҮж–Үз« дёӯпјҢ笔иҖ…е°Ҷеҗ‘жӮЁд»Ӣз»ҚKubernetesдёӯзҡ„еҮ дёӘ组件пјҢе®ғ们жңүеҠ©дәҺи§ЈеҶіеңЁе®№еҷЁзҺҜеўғдёӯжҢҒд№…еҢ–зҠ¶жҖҒзҡ„й—®йўҳгҖӮ
гҖҖгҖҖжңүзҠ¶жҖҒжҖ§
гҖҖгҖҖз®ЎзҗҶжҢҒд№…зҠ¶жҖҒзҡ„жңҖеӨ§й—®йўҳжҳҜеҶіе®ҡе®ғеә”иҜҘеӯҳз•ҷеңЁдҪ•еӨ„гҖӮеңЁеҶіе®ҡжҢҒд№…еҢ–еӯҳеӮЁеә”иҜҘж”ҫеңЁдҪ•еӨ„ж—¶пјҢжңүдёүз§ҚйҖүжӢ©пјҢжҜҸз§Қж–№жі•еҗ„жңүе…¶дјҳзӮ№:
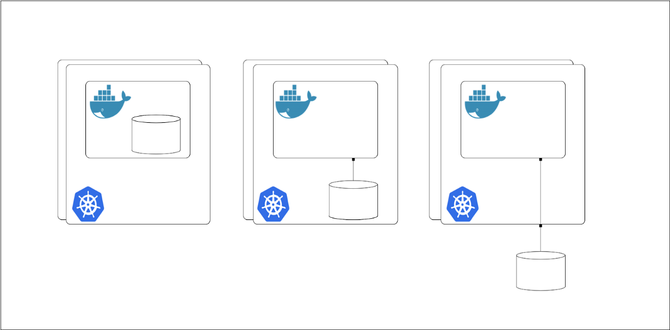
гҖҖгҖҖВ·жҢҒд№…еҢ–еӯҳеӮЁдҝқеӯҳеңЁе®№еҷЁдёӯгҖӮеҰӮжһңж•°жҚ®жҳҜеҸҜеӨҚеҲ¶зҡ„пјҢиҖҢдё”дёҚжҳҜе…ій”®ж•°жҚ®пјҢйӮЈд№Ҳиҝҷдёӯж–№жі•жҳҜйқһеёёжңүж•Ҳзҡ„пјҢдҪҶжҳҜеҪ“е®№еҷЁйҮҚж–°еҗҜеҠЁж—¶пјҢжӮЁе°ҶдёўеӨұиҝҷдәӣж•°жҚ®гҖӮ
гҖҖгҖҖВ·жҢҒд№…еҢ–еӯҳеӮЁдҝқеӯҳеңЁдё»жңәиҠӮзӮ№дёҠгҖӮиҝҷз§Қж–№жі•з»•иҝҮдәҶе®№еҷЁзҡ„зҹӯжҡӮжҖ§й—®йўҳпјҢдҪҶжҳҜжӮЁеҸҜиғҪдјҡеӣ дёәдё»жңәиҠӮзӮ№зҡ„жҳ“еҸ—ж”»еҮ»жҖ§иҖҢйҒҮеҲ°зұ»дјјзҡ„й—®йўҳгҖӮ
гҖҖгҖҖВ·жҢҒд№…еҢ–еӯҳеӮЁдҝқеӯҳеңЁиҝңзЁӢеӯҳеӮЁдёӯгҖӮиҝҷж¶ҲйҷӨдәҶе®№еҷЁе’Ңдё»жңәеӯҳеӮЁзҡ„дёҚеҸҜйқ жҖ§пјҢдҪҶжҳҜйңҖиҰҒд»”з»ҶиҖғиҷ‘еҰӮдҪ•жҸҗдҫӣ/з®ЎзҗҶиҝңзЁӢеӯҳеӮЁгҖӮ
гҖҖгҖҖд»Җд№Ҳж—¶еҖҷйңҖиҰҒиҖғиҷ‘зҠ¶жҖҒ?
гҖҖгҖҖеә”з”ЁзЁӢеәҸжңүдёӨдёӘйңҖиҰҒжҢҒд№…зҠ¶жҖҒзҡ„е…ій”®зү№жҖ§пјҡ1гҖҒйңҖиҰҒеңЁеә”з”ЁзЁӢеәҸдёӯж–ӯе’ҢйҮҚеҗҜд№ӢеүҚжҢҒд№…дҝқеӯҳж•°жҚ®;2гҖҒйңҖиҰҒи·ЁзӣёеҗҢзҡ„дёӯж–ӯе’ҢйҮҚеҗҜпјҢжқҘз®ЎзҗҶеә”з”ЁзЁӢеәҸзҠ¶жҖҒгҖӮжӯӨзұ»еә”з”ЁзЁӢеәҸзҡ„е…ёеһӢдҫӢеӯҗжңүж•°жҚ®еә“еҸҠе…¶еүҜжң¬гҖҒжҹҗз§Қж—Ҙеҝ—и®°еҪ•еә”з”ЁзЁӢеәҸпјҢжҲ–иҖ…йңҖиҰҒиҝңзЁӢеӯҳеӮЁзҡ„еҲҶеёғејҸеә”з”ЁзЁӢеәҸгҖӮ
гҖҖгҖҖдҪҶжҳҜпјҢжӯӨзұ»еә”з”ЁзЁӢеәҸеҜ№жҢҒд№…жҖ§зҡ„йңҖжұӮ并дёҚжҳҜзӣёеҗҢзЁӢеәҰзҡ„пјҢеӣ дёәеҜ№дәҺдёҚеҗҢзҡ„еә”з”ЁзЁӢеәҸпјҢе…¶е…ій”®зЁӢеәҰжҳҫ然жҳҜдёҚеҗҢзҡ„гҖӮз”ұдәҺиҝҷдёӘеҺҹеӣ пјҢ笔иҖ…еңЁи®ҫи®ЎжңүзҠ¶жҖҒзҡ„еә”з”ЁзЁӢеәҸж—¶пјҢеёёеёёдјҡй—®иҮӘе·ұеҮ дёӘй—®йўҳ:
гҖҖгҖҖВ·жҲ‘们иҰҒз®ЎзҗҶеӨҡе°‘ж•°жҚ®?
гҖҖгҖҖВ·д»ҺжңҖж–°зҡ„еҝ«з…§ејҖе§Ӣе°ұеҸҜд»Ҙеҗ—?иҝҳжҳҜйңҖиҰҒз»қеҜ№жңҖж–°зҡ„еҸҜз”Ёж•°жҚ®?
гҖҖгҖҖВ·д»Һеҝ«з…§йҮҚж–°еҗҜеҠЁжҳҜеҗҰиҠұиҙ№дәҶеӨӘй•ҝж—¶й—ҙпјҢжҲ–иҖ…еҜ№иҝҷдёӘеә”з”ЁзЁӢеәҸиҖҢиЁҖе·Із»Ҹи¶іеӨҹдәҶ?
гҖҖгҖҖВ·ж•°жҚ®зҡ„еӨҚеҲ¶жңүеӨҡе®№жҳ“?
гҖҖгҖҖВ·иҝҷдәӣж•°жҚ®еҜ№д»»еҠЎжңүеӨҡйҮҚиҰҒ?иғҪеҗҰеңЁе®№еҷЁжҲ–дё»жңәз»Ҳжӯўж—¶вҖңеӯҳжҙ»вҖқпјҢиҝҳжҳҜйңҖиҰҒиҝңзЁӢеӯҳеӮЁ?
гҖҖгҖҖВ·иҝҷдёӘеә”з”ЁзЁӢеәҸдёӯзҡ„дёҚеҗҢPodsжҳҜеҸҜдә’жҚўзҡ„еҗ—?
гҖҖгҖҖеӯҳеӮЁи§ЈеҶіж–№жЎҲ
гҖҖгҖҖи®ёеӨҡеә”з”ЁзЁӢеәҸиҰҒжұӮж•°жҚ®иғҪеӨҹи·Ёе®№еҷЁе’Ңдё»жңәйҮҚеҗҜе®һзҺ°жҢҒд№…еҢ–пјҢиҝҷе°ұйңҖиҰҒиҝңзЁӢеӯҳеӮЁгҖӮе№ёиҝҗзҡ„жҳҜпјҢKubernetesе·Із»Ҹж„ҸиҜҶеҲ°иҝҷз§ҚйңҖжұӮпјҢ并жҸҗдҫӣдәҶдёҖз§ҚPodдёҺиҝңзЁӢеӯҳеӮЁдәӨдә’зҡ„ж–№ејҸ:еҚ·(Volumes)гҖӮ

гҖҖгҖҖKubernetesеҚ·
гҖҖгҖҖKubernetesеҚ·жҸҗдҫӣдәҶдёҖз§ҚдёҺиҝңзЁӢ(жҲ–жң¬ең°)еӯҳеӮЁдәӨдә’зҡ„ж–№жі•гҖӮеҸҜд»Ҙе°ҶиҝҷдәӣеҚ·и§ҶдёәжҢӮиҪҪзҡ„еӯҳеӮЁпјҢиҝҷдәӣеӯҳеӮЁе°ҶжҢҒз»ӯеӯҳз•ҷеҲ°е°Ғй—ӯPodзҡ„з”ҹеӯҳжңҹгҖӮеҚ·жҜ”еңЁиҜҘPodдёӯspin up/downзҡ„д»»дҪ•е®№еҷЁзҡ„еҜҝе‘ҪйғҪй•ҝпјҢиҝҷдёәе®№еҷЁзҡ„зҹӯжҡӮжҖ§жҸҗдҫӣдәҶдёҖдёӘеҫҲеҘҪзҡ„и§ЈеҶіж–№жЎҲгҖӮдёӢйқўжҳҜдёҖдёӘеҲ©з”ЁеҚ·зҡ„Podе®ҡд№үзӨәдҫӢгҖӮ
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: Pod
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: test-pod
гҖҖгҖҖspec:
гҖҖгҖҖ containers:
гҖҖгҖҖ вҖ” name: test-container
гҖҖгҖҖ image: nginx
гҖҖгҖҖ volumeMounts:
гҖҖгҖҖ вҖ” mountPath: /data
гҖҖгҖҖ name: testvolume
гҖҖгҖҖ volumes:
гҖҖгҖҖ вҖ” name: testvolume
гҖҖгҖҖ # This AWS EBS Volume must already exist.
гҖҖгҖҖ awsElasticBlockStore:
гҖҖгҖҖ volumeID: <volume-id>
гҖҖгҖҖ fsType: ext4
гҖҖгҖҖжӯЈеҰӮжҲ‘们д»ҺдёҠйқўPodе®ҡд№үдёӯзңӢеҲ°зҡ„пјҢspecдёӢзҡ„volumesйғЁеҲҶжҢҮе®ҡдәҶеҚ·зҡ„еҗҚз§°е’Ңе·Із»ҸеҲӣе»әзҡ„еӯҳеӮЁзҡ„ID(еңЁжң¬дҫӢдёӯжҳҜEBSеҚ·)гҖӮиҰҒдҪҝз”ЁжӯӨеҚ·пјҢе®№еҷЁе®ҡд№үеҝ…йЎ»еңЁspecдёӢзҡ„containers volumeMountsеӯ—ж®өдёӯжҢҮе®ҡиҰҒжҢӮиҪҪзҡ„еҚ·гҖӮ
гҖҖгҖҖеңЁеҲ©з”ЁеҚ·ж—¶иҰҒи®°дҪҸзҡ„дёҖдәӣе…ій”®зӮ№:
гҖҖгҖҖВ·KubernetesжҸҗдҫӣи®ёеӨҡзұ»еһӢзҡ„еҚ·пјҢдёҖдёӘPodеҸҜд»ҘеҗҢж—¶дҪҝз”Ёд»»ж„Ҹж•°йҮҸзҡ„еҚ·гҖӮ
гҖҖгҖҖВ·еҚ·д»…иғҪжҢҒз»ӯдёҺе°Ғй—ӯзҡ„PodдёҖж ·й•ҝзҡ„ж—¶й—ҙгҖӮеҪ“PodеҒңжӯўеӯҳеңЁж—¶пјҢеҚ·д№ҹе°ҶеҒңжӯўгҖӮ
гҖҖгҖҖВ·жҢҒд№…еӯҳеӮЁзҡ„дҫӣеә”дёҚжҳҜз”ұеҚ·жҲ–Podжң¬иә«еӨ„зҗҶзҡ„пјҢеҚ·еҗҺзҡ„жҢҒд№…еӯҳеӮЁйңҖиҰҒд»Ҙе…¶д»–ж–№ејҸжҸҗдҫӣгҖӮ
гҖҖгҖҖиҷҪ然еҚ·и§ЈеҶідәҶе®№еҷЁеҢ–еә”з”ЁзЁӢеәҸзҡ„дёҖдёӘе·ЁеӨ§й—®йўҳпјҢдҪҶжҹҗдәӣеә”з”ЁзЁӢеәҸиҰҒжұӮйҷ„еҠ еҚ·зҡ„з”ҹеӯҳжңҹи¶…иҝҮPodзҡ„з”ҹеӯҳжңҹгҖӮеҜ№дәҺиҝҷдёӘз”ЁдҫӢпјҢжҢҒд№…еҚ·е’ҢжҢҒд№…еҚ·еЈ°жҳҺе°Ҷйқһеёёжңүз”ЁгҖӮ
гҖҖгҖҖKubernetesжҢҒд№…еҚ·е’ҢжҢҒд№…еҚ·еЈ°жҳҺ
гҖҖгҖҖKubernetesжҢҒд№…еҚ·е’ҢжҢҒд№…еҚ·еЈ°жҳҺжҸҗдҫӣдәҶдёҖз§Қж–№жі•пјҢд»Ҙдҫҝд»ҺеӯҳеӮЁзҡ„дҪҝз”Ёж–№ејҸдёӯжҸҗеҸ–е…ідәҺеҰӮдҪ•жҸҗдҫӣеӯҳеӮЁзҡ„з»ҶиҠӮгҖӮжҢҒд№…еҚ·(PVпјҢPersistent Volume)жҳҜдёҖдёӘйӣҶзҫӨдёӯз”ұз®ЎзҗҶе‘ҳжҸҗдҫӣзҡ„еҸҜз”ЁжҢҒд№…еӯҳеӮЁпјҢе®ғ们дҪңдёәйӣҶзҫӨиө„жәҗеӯҳеңЁпјҢе°ұеғҸиҠӮзӮ№дёҖж ·пјҢе®ғ们зҡ„з”ҹе‘Ҫе‘ЁжңҹзӢ¬з«ӢдәҺд»»дҪ•еҚ•зӢ¬зҡ„PodгҖӮжҢҒд№…еҚ·еЈ°жҳҺ(PVCпјҢPersistent Volume Claim)жҳҜз”ЁжҲ·еҜ№еӯҳеӮЁзҡ„иҜ·жұӮпјҢдёҺPodж¶ҲиҖ—еҶ…еӯҳе’ҢCPUзӯүиҠӮзӮ№иө„жәҗзҡ„ж–№ејҸзұ»дјјпјҢPVCд№ҹж¶ҲиҖ—еӯҳеӮЁзӯүPVиө„жәҗгҖӮ
гҖҖгҖҖPVзҡ„з”ҹе‘Ҫе‘Ёжңҹз”ұеӣӣдёӘйҳ¶ж®өз»„жҲҗ:дҫӣеә”(provisioning)гҖҒз»‘е®ҡ(binding)гҖҒдҪҝз”Ё(using)е’Ңеӣһ收(reclaiming)гҖӮ
гҖҖгҖҖдҫӣеә”вҖ”вҖ”PVзҡ„дҫӣеә”еҸҜд»ҘйҖҡиҝҮдёӨз§Қж–№ејҸе®ҢжҲҗ:йқҷжҖҒжҲ–еҠЁжҖҒгҖӮ
гҖҖгҖҖВ·йқҷжҖҒдҫӣеә”йңҖиҰҒйӣҶзҫӨз®ЎзҗҶе‘ҳжүӢеҠЁеҲӣе»әеӨ§йҮҸиҰҒдҪҝз”Ёзҡ„PVгҖӮ
гҖҖгҖҖВ·еҠЁжҖҒдҫӣеә”еҸҜд»ҘеңЁPVCиҜ·жұӮPVж—¶еҸ‘з”ҹпјҢиҖҢдёҚйңҖиҰҒйӣҶзҫӨз®ЎзҗҶе‘ҳиҝӣиЎҢд»»дҪ•жүӢеҠЁе№Ійў„гҖӮ
гҖҖгҖҖВ·еҠЁжҖҒдҫӣеә”йңҖиҰҒд»ҘеӯҳеӮЁзұ»(Storage Classes)зҡ„еҪўејҸиҝӣиЎҢдёҖдәӣйў„е…Ҳдҫӣеә”(жҲ‘们зЁҚеҗҺе°ҶеҜ№жӯӨиҝӣиЎҢи®Ёи®ә)гҖӮ
гҖҖгҖҖз»‘е®ҡвҖ”вҖ”еҲӣе»әPVCж—¶пјҢе®ғе…·жңүзү№е®ҡзҡ„еӯҳеӮЁз©әй—ҙе’Ңзү№е®ҡзҡ„и®ҝй—®жЁЎејҸгҖӮеҪ“жңүдёҖдёӘеҢ№й…Қзҡ„PVеҸҜз”Ёж—¶пјҢж— и®әPVCйңҖиҰҒеӨҡй•ҝж—¶й—ҙпјҢе®ғйғҪе°ҶеҸӘдёҺиҜ·жұӮзҡ„PVCз»‘е®ҡгҖӮеҰӮжһңеҢ№й…Қзҡ„PVдёҚеӯҳеңЁпјҢеҲҷPVCе°Ҷж— йҷҗжңҹең°дҝқжҢҒжқҫж•ЈзҠ¶жҖҒгҖӮеңЁеҠЁжҖҒдҫӣеә”PVзҡ„жғ…еҶөдёӢпјҢжҺ§еҲ¶еҫӘзҺҜдјҡе§Ӣз»ҲжҠҠPVз»‘е®ҡеҲ°иҜ·жұӮзҡ„PVCгҖӮеҗҰеҲҷпјҢPVCиҮіе°‘дјҡеҫ—еҲ°е®ғ们иҰҒжұӮзҡ„еӯҳеӮЁз©әй—ҙпјҢдҪҶжҳҜеҚ·еҸҜиғҪдјҡжҜ”иҰҒжұӮжӣҙеӨҡгҖӮ
гҖҖгҖҖдҪҝз”ЁвҖ”вҖ”дёҖж—ҰPVCи®ӨйўҶдәҶPVпјҢе®ғе°ұеҸҜд»ҘдҪңдёәдёҖдёӘе®үиЈ…дҪ“еңЁе°Ғй—ӯзҡ„PodдёӯдҪҝз”ЁгҖӮз”ЁжҲ·еҸҜд»Ҙдёәйҷ„еҠ еҚ·жҢҮе®ҡзү№е®ҡзҡ„жЁЎејҸ(дҫӢеҰӮReadWriteOnceгҖҒReadOnlymanyзӯү)д»ҘеҸҠе…¶д»–жҢӮиҪҪзҡ„еӯҳеӮЁйҖүйЎ№гҖӮеҸӘиҰҒз”ЁжҲ·йңҖиҰҒпјҢе°ұеҸҜд»ҘдҪҝз”Ёе®үиЈ…еҘҪзҡ„PVгҖӮ
гҖҖгҖҖеӣһ收вҖ”вҖ”еҪ“дёҖдёӘз”ЁжҲ·е®ҢжҲҗдәҶеҜ№еӯҳеӮЁзҡ„дҪҝз”ЁеҗҺпјҢд»–йңҖиҰҒеҶіе®ҡеҰӮдҪ•еӨ„зҗҶжӯЈеңЁйҮҠж”ҫзҡ„PVгҖӮеңЁеҶіе®ҡеӣһ收зӯ–з•Ҙж—¶пјҢжңүдёүдёӘйҖүйЎ№пјҡдҝқз•ҷ(retain)гҖҒеҲ йҷӨ(delete)е’ҢеҫӘзҺҜеҲ©з”Ё(recycle)гҖӮ
гҖҖгҖҖВ·дҝқз•ҷPVеҸӘйңҖиҰҒйҮҠж”ҫPVпјҢиҖҢдёҚйңҖиҰҒдҝ®ж”№жҲ–еҲ йҷӨд»»дҪ•еҢ…еҗ«зҡ„ж•°жҚ®пјҢ并е…Ғи®ёзӣёеҗҢзҡ„PVCеңЁзЁҚеҗҺжүӢеҠЁеӣһ收жӯӨPVгҖӮ
гҖҖгҖҖВ·еҲ йҷӨPVе°Ҷе®Ңе…ЁеҲ йҷӨPVд»ҘеҸҠеә•еұӮеӯҳеӮЁиө„жәҗгҖӮ
гҖҖгҖҖВ·еҫӘзҺҜеҲ©з”ЁPVе°Ҷд»ҺеӯҳеӮЁиө„жәҗдёӯеҲ йҷӨж•°жҚ®пјҢ并дҪҝPVеҸҜз”ЁдәҺд»»дҪ•е…¶д»–PVCзҡ„иҜ·жұӮгҖӮ
гҖҖгҖҖдёӢйқўжҳҜдёҖдёӘжҢҒд№…еҚ·(дҪҝз”ЁйқҷжҖҒдҫӣеә”)зҡ„зӨәдҫӢпјҢд»ҘеҸҠжҢҒд№…еҚ·еЈ°жҳҺе®ҡд№үгҖӮ
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: PersistentVolume
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: mypv
гҖҖгҖҖspec:
гҖҖгҖҖ storageClassName: mysc
гҖҖгҖҖ capacity:
гҖҖгҖҖ storage: 8Gi
гҖҖгҖҖ accessModes:
гҖҖгҖҖ вҖ” ReadWriteOnce
гҖҖгҖҖ persistentVolumeReclaimPolicy: Recycle
гҖҖгҖҖ awsElasticBlockStore:
гҖҖгҖҖ volumeID: <volume-id> # This AWS EBS Volume must already exist.
жҢҒд№…еҚ·
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: PersistentVolumeClaim
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: mypvc
гҖҖгҖҖspec:
гҖҖгҖҖ storageClassName: mysc
гҖҖгҖҖ accessModes:
гҖҖгҖҖ вҖ” ReadWriteOnce
гҖҖгҖҖ resources:
гҖҖгҖҖ requests:
гҖҖгҖҖ storage: 8Gi
гҖҖгҖҖжҢҒд№…еҚ·еЈ°жҳҺ
гҖҖгҖҖжҢҒд№…еҚ·е®ҡд№үжҢҮе®ҡеӯҳеӮЁиө„жәҗзҡ„е®№йҮҸпјҢд»ҘеҸҠдёҖдәӣе…¶д»–зү№е®ҡдәҺеҚ·зҡ„еұһжҖ§пјҢеҰӮеӣһ收зӯ–з•Ҙе’Ңи®ҝй—®жЁЎејҸгҖӮеҸҜд»ҘдҪҝз”ЁspecдёӢзҡ„storageClassNameе°ҶPVеҲҶзұ»дёәзү№е®ҡзҡ„еӯҳеӮЁзұ»пјҢPVCеҸҜд»ҘеҲ©з”Ёе®ғжқҘжҢҮе®ҡиҰҒеЈ°жҳҺзҡ„зү№е®ҡеӯҳеӮЁзұ»гҖӮдёҠйқўзҡ„жҢҒд№…еҚ·еЈ°жҳҺе®ҡд№үжҢҮе®ҡдәҶе®ғиҜ•еӣҫеЈ°жҳҺзҡ„жҢҒд№…еҚ·зҡ„еұһжҖ§пјҢе…¶дёӯдёҖдәӣжҳҜеӯҳеӮЁе®№йҮҸе’Ңи®ҝй—®жЁЎејҸгҖӮPVCеҸҜд»ҘйҖҡиҝҮжҢҮе®ҡspecдёӢзҡ„storageClassNameеӯ—ж®өиҜ·жұӮзү№е®ҡзҡ„PVгҖӮзү№е®ҡзұ»зҡ„PVеҸӘиғҪз»‘е®ҡеҲ°иҜ·жұӮиҜҘзұ»зҡ„PVCпјҢжІЎжңүжҢҮе®ҡзұ»зҡ„PVеҸӘиғҪз»‘е®ҡеҲ°жІЎжңүиҜ·жұӮзү№е®ҡзұ»зҡ„PVCгҖӮйҖүжӢ©еҷЁиҝҳеҸҜд»Ҙз”ЁдәҺжҢҮе®ҡиҰҒеЈ°жҳҺзҡ„PVзҡ„зү№е®ҡзұ»еһӢпјҢжңүе…іиҝҷж–№йқўзҡ„жӣҙеӨҡж–ҮжЎЈеҸҜд»ҘеңЁиҝҷйҮҢ(https://kubernetes.io/docs/concepts/storage/persistent-volumes/#selector)жүҫеҲ°гҖӮ
гҖҖгҖҖдёӢйқўжҳҜеҲ©з”ЁжҢҒд№…еҚ·еЈ°жҳҺжқҘиҜ·жұӮеӯҳеӮЁзҡ„Podе®ҡд№үзӨәдҫӢ:
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: Pod
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: test-pod
гҖҖгҖҖspec:
гҖҖгҖҖ containers:
гҖҖгҖҖ вҖ” name: test-container
гҖҖгҖҖ image: nginx
гҖҖгҖҖ volumeMounts:
гҖҖгҖҖ вҖ” mountPath: /data
гҖҖгҖҖ name: myvolume
гҖҖгҖҖ volumes:
гҖҖгҖҖ вҖ” name: myvolume
гҖҖгҖҖ persistentVolumeClaim:
гҖҖгҖҖ claimName: mypvc
гҖҖгҖҖеҪ“е°ҶиҝҷдёӘPodе®ҡд№үдёҺеүҚйқўдҪҝз”ЁеҚ·зҡ„е®ҡд№үиҝӣиЎҢжҜ”иҫғж—¶пјҢжҲ‘们еҸҜд»ҘзңӢеҲ°е®ғ们еҮ д№ҺжҳҜзӣёеҗҢзҡ„гҖӮжҢҒд№…еҚ·еЈ°жҳҺдёҚжҳҜзӣҙжҺҘдёҺеӯҳеӮЁиө„жәҗдәӨдә’пјҢиҖҢжҳҜз”ЁдәҺд»ҺPodжҠҪиұЎеӯҳеӮЁз»ҶиҠӮгҖӮ
гҖҖгҖҖе…ідәҺжҢҒд№…еҚ·е’ҢжҢҒд№…еҚ·еЈ°жҳҺзҡ„дёҖдәӣе…ій”®з»“и®ә:
гҖҖгҖҖ*жҢҒд№…еҚ·зҡ„з”ҹе‘Ҫе‘ЁжңҹзӢ¬з«ӢдәҺPodзҡ„з”ҹе‘Ҫе‘ЁжңҹгҖӮ
гҖҖгҖҖ*жҢҒд№…еҚ·еЈ°жҳҺе°ҶеӯҳеӮЁдҫӣеә”зҡ„з»ҶиҠӮд»ҺPodзҡ„еӯҳеӮЁж¶ҲиҖ—дёӯжҠҪиұЎеҮәжқҘгҖӮ
гҖҖгҖҖ*дёҺеҚ·зұ»дјјпјҢжҢҒд№…еҚ·е’ҢжҢҒд№…еҚ·еЈ°жҳҺдёҚзӣҙжҺҘеӨ„зҗҶеӯҳеӮЁиө„жәҗзҡ„дҫӣеә”гҖӮ
гҖҖгҖҖKubernetesеӯҳеӮЁзұ»е’ҢжҢҒд№…еҚ·еЈ°жҳҺ
гҖҖгҖҖKubernetesеӯҳеӮЁзұ»е’ҢжҢҒд№…еҚ·еЈ°жҳҺжҸҗдҫӣдәҶдёҖз§ҚеңЁиҜ·жұӮж—¶еҠЁжҖҒжҸҗдҫӣеӯҳеӮЁиө„жәҗзҡ„ж–№жі•пјҢд»ҺиҖҢж¶ҲйҷӨдәҶйӣҶзҫӨз®ЎзҗҶе‘ҳиҝҮеәҰжҸҗдҫӣ/жүӢеҠЁжҸҗдҫӣеӯҳеӮЁиө„жәҗд»Ҙж»Ўи¶ійңҖжұӮзҡ„еҝ…иҰҒжҖ§гҖӮеӯҳеӮЁзұ»е…Ғи®ёйӣҶзҫӨз®ЎзҗҶе‘ҳжҸҸиҝ°е…¶жҸҗдҫӣзҡ„еӯҳеӮЁвҖңзұ»вҖқпјҢ并еңЁеҠЁжҖҒеҲӣе»әеӯҳеӮЁиө„жәҗе’ҢжҢҒд№…еҚ·ж—¶еҲ©з”ЁиҝҷдәӣвҖңзұ»вҖқдҪңдёәжЁЎжқҝгҖӮеҸҜд»Ҙж №жҚ®зү№е®ҡзҡ„еә”з”ЁзЁӢеәҸйңҖжұӮ(еҰӮжүҖйңҖзҡ„жңҚеҠЎиҙЁйҮҸзә§еҲ«е’ҢеӨҮд»Ҫзӯ–з•Ҙ)е®ҡд№үдёҚеҗҢзҡ„еӯҳеӮЁзұ»гҖӮ
гҖҖгҖҖеӯҳеӮЁзұ»е®ҡд№үеӣҙз»•дёүдёӘзү№е®ҡеҢәеҹҹ:
гҖҖгҖҖВ·еӣһ收(Reclaim )зӯ–з•Ҙ
гҖҖгҖҖВ·дҫӣеә”зЁӢеәҸ(Provisioner)
гҖҖгҖҖВ·еҸӮж•°(Parameter)
гҖҖгҖҖReclaim вҖ”вҖ”еҰӮжһңжҢҒд№…еҚ·жҳҜз”ұеӯҳеӮЁзұ»еҲӣе»әзҡ„пјҢйӮЈд№ҲеҸӘжңүRetainжҲ–DeleteдҪңдёәеӣһ收зӯ–з•ҘеҸҜз”ЁпјҢиҖҢжүӢеҠЁеҲӣе»әзҡ„гҖҒз”ұеӯҳеӮЁзұ»з®ЎзҗҶзҡ„жҢҒд№…еҚ·еңЁеҲӣе»әж—¶е°Ҷдҝқз•ҷе…¶еҲҶй…Қзҡ„еӣһ收зӯ–з•ҘгҖӮ
гҖҖгҖҖProvisionerвҖ”вҖ”еӯҳеӮЁзұ»жҸҗдҫӣиҖ…иҙҹиҙЈеҶіе®ҡеңЁжҸҗдҫӣPVж—¶йңҖиҰҒдҪҝз”Ёе“ӘдёӘеҚ·жҸ’件(дҫӢеҰӮAWS EBSзҡ„AWSElasticBlockStoreжҲ–Portworx volumeзҡ„PortworxVolume)гҖӮProvisionerеӯ—ж®өдёҚд»…йҷҗдәҺеҶ…йғЁеҸҜз”Ёзҡ„Provisionerзұ»еһӢеҲ—иЎЁпјҢд»»дҪ•йҒөеҫӘжҳҺзЎ®е®ҡд№үзҡ„规иҢғзҡ„зӢ¬з«ӢеӨ–йғЁдҫӣеә”зЁӢеәҸйғҪеҸҜд»Ҙз”ЁжқҘеҲӣе»әж–°зҡ„жҢҒд№…еҚ·зұ»еһӢгҖӮ
гҖҖгҖҖParameterвҖ”вҖ”е®ҡд№үеӯҳеӮЁзұ»зҡ„жңҖеҗҺгҖҒд№ҹеҸҜд»ҘиҜҙжңҖйҮҚиҰҒзҡ„дёҖйғЁеҲҶжҳҜеҸӮж•°йғЁеҲҶгҖӮдёҚеҗҢзҡ„жҸҗдҫӣзЁӢеәҸеҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„еҸӮж•°пјҢиҝҷдәӣеҸӮж•°з”ЁдәҺжҸҸиҝ°зү№е®ҡвҖңзұ»вҖқеӯҳеӮЁзҡ„规иҢғгҖӮ
гҖҖгҖҖдёӢйқўжҳҜжҢҒд№…еҚ·еЈ°жҳҺе’ҢеӯҳеӮЁзұ»е®ҡд№үпјҡ
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: StorageClass
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: myscz
гҖҖгҖҖprovisioner: kubernetes.io/aws-ebs
гҖҖгҖҖparameters:
гҖҖгҖҖ type: io1
гҖҖгҖҖ iopsPerGB: вҖң10вҖқ
гҖҖгҖҖ fsType: ext4
гҖҖгҖҖжҢҒд№…еҚ·еЈ°жҳҺ
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: PersistentVolumeClaim
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: mypvc
гҖҖгҖҖspec:
гҖҖгҖҖ storageClassName: mysc
гҖҖгҖҖ accessModes:
гҖҖгҖҖ вҖ” ReadWriteOnce
гҖҖгҖҖ resources:
гҖҖгҖҖ requests:
гҖҖгҖҖ storage: 8Gi
гҖҖгҖҖеӯҳеӮЁзұ»
гҖҖгҖҖеҰӮжһңжҲ‘们е°ҶPVCе®ҡд№үдёҺдёҠйқўйқҷжҖҒдҫӣеә”з”ЁдҫӢдёӯдҪҝз”Ёзҡ„е®ҡд№үиҝӣиЎҢжҜ”иҫғпјҢеҸҜд»ҘзңӢеҲ°е®ғ们жҳҜзӣёеҗҢзҡ„гҖӮ
гҖҖгҖҖиҝҷжҳҜеӣ дёәеӯҳеӮЁвҖңдҫӣеә”вҖқе’ҢеӯҳеӮЁвҖңж¶Ҳиҙ№вҖқд№Ӣй—ҙеӯҳеңЁжҳҺжҳҫзҡ„еҲҶзҰ»гҖӮдёҺйқҷжҖҒеҲӣе»әзҡ„еӯҳеӮЁзұ»зӣёжҜ”пјҢдҪҝз”ЁеӯҳеӮЁзұ»еҲӣе»әзҡ„жҢҒд№…еҚ·зҡ„ж¶ҲиҖ—жңүдёҖдәӣе·ЁеӨ§зҡ„дјҳеҠҝпјҢжңҖеӨ§зҡ„дјҳзӮ№д№ӢдёҖжҳҜиғҪеӨҹж“ҚдҪңд»…еңЁиө„жәҗеҲӣе»әж—¶еҸҜз”Ёзҡ„еӯҳеӮЁиө„жәҗеҖјгҖӮиҝҷж„Ҹе‘ізқҖжҲ‘们еҸҜд»ҘеҮҶзЎ®ең°жҸҗдҫӣз”ЁжҲ·иҜ·жұӮзҡ„еӯҳеӮЁйҮҸпјҢиҖҢж— йңҖйӣҶзҫӨз®ЎзҗҶе‘ҳиҝӣиЎҢд»»дҪ•жүӢеҠЁе№Ійў„гҖӮз”ұдәҺеӯҳеӮЁзұ»йңҖиҰҒз”ұйӣҶзҫӨз®ЎзҗҶе‘ҳжҸҗеүҚе®ҡд№үпјҢеӣ жӯӨе®ғ们д»Қ然дјҡжҺ§еҲ¶е“Әдәӣзұ»еһӢзҡ„еӯҳеӮЁеҜ№жңҖз»Ҳз”ЁжҲ·еҸҜз”ЁпјҢеҗҢж—¶жҠҪиұЎеҮәжүҖжңүдҫӣеә”йҖ»иҫ‘гҖӮ
гҖҖгҖҖеӯҳеӮЁзұ»е’ҢжҢҒд№…еҚ·еЈ°жҳҺзҡ„иҰҒзӮ№:
гҖҖгҖҖ*еӯҳеӮЁзұ»е’ҢжҢҒд№…еҚ·еЈ°жҳҺе…Ғи®ёжңҖз»Ҳз”ЁжҲ·дҪҝз”ЁеӯҳеӮЁиө„жәҗзҡ„еҠЁжҖҒдҫӣеә”пјҢд»ҺиҖҢж¶ҲйҷӨйӣҶзҫӨз®ЎзҗҶе‘ҳжүҖйңҖзҡ„д»»дҪ•жүӢеҠЁе№Ійў„гҖӮ
гҖҖгҖҖ*еӯҳеӮЁзұ»жҠҪиұЎдәҶеӯҳеӮЁдҫӣеә”зҡ„з»ҶиҠӮпјҢиҖҢдҫқиө–дәҺжҢҮе®ҡзҡ„дҫӣеә”зЁӢеәҸжқҘеӨ„зҗҶдҫӣеә”йҖ»иҫ‘гҖӮ
гҖҖгҖҖеә”з”ЁзЁӢеәҸзҠ¶жҖҒ
гҖҖгҖҖеҪ“жҲ‘们иҖғиҷ‘зҠ¶жҖҒж—¶пјҢжҢҒд№…еӯҳеӮЁжҳҜиҮіе…ійҮҚиҰҒзҡ„гҖӮжҲ‘зҡ„ж•°жҚ®еңЁе“ӘйҮҢ?еҪ“жҲ‘зҡ„еә”з”ЁзЁӢеәҸж•…йҡңж—¶пјҢе®ғжҳҜеҰӮдҪ•еҒҡеҲ°жҢҒд№…еҢ–зҡ„?иҖҢжҹҗдәӣеә”з”ЁзЁӢеәҸжң¬иә«д№ҹйңҖиҰҒзҠ¶жҖҒз®ЎзҗҶпјҢдёҚд»…д»…жҳҜжҢҒд№…еҢ–ж•°жҚ®гҖӮиҝҷеңЁеҲ©з”ЁеӨҡдёӘдёҚеҸҜдә’жҚўPodзҡ„еә”з”ЁзЁӢеәҸдёӯжңҖе®№жҳ“зңӢеҲ°(дҫӢеҰӮпјҢдё»ж•°жҚ®еә“PodеҸҠе…¶жҹҗдәӣеҲҶеёғејҸеә”з”ЁзЁӢеәҸеҰӮZookeeperжҲ–Elasticsearchзҡ„еүҜжң¬)гҖӮиҜёеҰӮжӯӨзұ»зҡ„еә”з”ЁзЁӢеәҸиҰҒжұӮиғҪеӨҹеңЁд»»дҪ•йҮҚж–°и°ғеәҰжңҹй—ҙдёәжҜҸдёӘPod hatеҲҶй…ҚжғҹдёҖж ҮиҜҶз¬ҰгҖӮKubernetesйҖҡиҝҮдҪҝз”ЁStatefulSetжҸҗдҫӣдәҶиҝҷз§ҚеҠҹиғҪгҖӮ
гҖҖгҖҖKubernetes StatefulSets
гҖҖгҖҖKubernetes StatefulSetжҸҗдҫӣзұ»дјјдәҺReplicaSets е’ҢDeploymentsзҡ„еҠҹиғҪпјҢдҪҶжҳҜе…·жңүзЁіе®ҡзҡ„йҮҚж–°и°ғеәҰгҖӮеҜ№дәҺйңҖиҰҒзЁіе®ҡж ҮиҜҶз¬Ұе’ҢжңүеәҸйғЁзҪІгҖҒдјёзј©е’ҢеҲ йҷӨзҡ„еә”з”ЁзЁӢеәҸжқҘиҜҙпјҢиҝҷз§Қе·®ејӮйқһеёёйҮҚиҰҒгҖӮStatefulSetжңүеҮ з§ҚдёҚеҗҢзҡ„зү№жҖ§пјҢеҸҜд»Ҙеё®еҠ©жҸҗдҫӣиҝҷдәӣеҝ…иҰҒзҡ„еҠҹиғҪгҖӮ
гҖҖгҖҖжғҹдёҖзҪ‘з»ңж ҮиҜҶз¬ҰвҖ”вҖ”StatefulSetдёӯзҡ„жҜҸдёӘPodйғҪд»ҺStatefulSetзҡ„еҗҚз§°е’ҢPodзҡ„еәҸеҸ·жҙҫз”ҹе…¶дё»жңәеҗҚгҖӮиҝҷдёӘPodзҡ„ж ҮиҜҶжҳҜзІҳж»һзҡ„пјҢдёҚз®ЎиҝҷдёӘPodиў«и°ғеәҰеҲ°е“ӘдёӘиҠӮзӮ№пјҢд№ҹдёҚз®Ўе®ғиў«йҮҚж–°и°ғеәҰдәҶеӨҡе°‘ж¬ЎгҖӮиҝҷз§ҚеҠҹиғҪеҜ№дәҺдјҡеҪўжҲҗдёҚеҸҜдә’жҚўзҡ„PodйҖ»иҫ‘вҖңз»„вҖқзҡ„еә”з”ЁзЁӢеәҸзү№еҲ«жңүз”ЁпјҢиҝҷзұ»еә”з”ЁзЁӢеәҸе…ёеһӢдҫӢеӯҗжҳҜеҲҶеёғејҸзі»з»ҹдёӯзҡ„ж•°жҚ®еә“еүҜжң¬е’Ңд»ЈзҗҶгҖӮиҜҶеҲ«еҚ•дёӘPodзҡ„иғҪеҠӣжҳҜStatefulSetзҡ„дјҳеҠҝзҡ„ж ёеҝғгҖӮ
гҖҖгҖҖжңүеәҸзҡ„йғЁзҪІгҖҒдјёзј©е’ҢеҲ йҷӨвҖ”вҖ”StatefulSetдёӯзҡ„Podж ҮиҜҶз¬ҰдёҚд»…жҳҜжғҹдёҖзҡ„пјҢиҖҢдё”жҳҜжңүеәҸзҡ„гҖӮStatefulSetдёӯзҡ„PodжҳҜжҢүйЎәеәҸеҲӣе»әзҡ„пјҢеңЁиҪ¬з§»еҲ°дёӢдёҖдёӘPodд№ӢеүҚпјҢзӯүеҫ…дёӯзҡ„дёҠдёҖдёӘPodеӨ„дәҺеҒҘеә·зҠ¶жҖҒгҖӮиҝҷз§ҚиЎҢдёәд№ҹжү©еұ•еҲ°дәҶPodзҡ„дјёзј©е’ҢеҲ йҷӨпјҢеңЁPodзҡ„жүҖжңүеүҚиә«йғҪеӨ„дәҺеҒҘеә·зҠ¶жҖҒд№ӢеүҚпјҢд»»дҪ•PodйғҪдёҚиғҪиҝӣиЎҢжӣҙж–°жҲ–жү©еұ•гҖӮзұ»дјјең°пјҢеңЁPodз»Ҳжӯўд№ӢеүҚпјҢеҝ…йЎ»е…ій—ӯжүҖжңүеҗҺз»ӯзҡ„PodгҖӮиҝҷдәӣеҠҹиғҪе…Ғи®ёеҜ№StatefulSetиҝӣиЎҢзЁіе®ҡзҡ„гҖҒеҸҜйў„жөӢзҡ„жӣҙж”№гҖӮ
гҖҖгҖҖдёӢйқўжҳҜStatefulSetе®ҡд№үзҡ„дёҖдёӘзӨәдҫӢпјҡ
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: StatefulSet
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: web
гҖҖгҖҖspec:
гҖҖгҖҖ selector:
гҖҖгҖҖ matchLabels:
гҖҖгҖҖ app: nginx # has to match .spec.template.metadata.labels
гҖҖгҖҖ replicas: 3
гҖҖгҖҖ template:
гҖҖгҖҖ metadata:
гҖҖгҖҖ labels:
гҖҖгҖҖ app: nginx # has to match .spec.selector.matchLabels
гҖҖгҖҖ spec:
гҖҖгҖҖ terminationGracePeriodSeconds: 10
гҖҖгҖҖ containers:
гҖҖгҖҖ вҖ” name: nginx
гҖҖгҖҖ image: nginx
гҖҖгҖҖ ports:
гҖҖгҖҖ вҖ” containerPort: 80
гҖҖгҖҖ name: web
гҖҖгҖҖ volumeMounts:
гҖҖгҖҖ вҖ” name: www
гҖҖгҖҖ mountPath: /usr/share/nginx/html
гҖҖгҖҖ volumeClaimTemplates:
гҖҖгҖҖ вҖ” metadata:
гҖҖгҖҖ name: www
гҖҖгҖҖ spec:
гҖҖгҖҖ storageClassName: mysc
гҖҖгҖҖ resources:
гҖҖгҖҖ requests:
гҖҖгҖҖ storage: 1Gi
гҖҖгҖҖеҰӮдёҠжүҖзӨәпјҢStatefulSetзҡ„еҗҚз§°еңЁmetadaдёӢзҡ„nameдёӯжҢҮе®ҡпјҢеңЁеҲӣе»әе°Ғй—ӯзҡ„Podж—¶е°ҶдҪҝз”ЁиҜҘеҗҚз§°гҖӮиҝҷдёӘStatefulSetsе®ҡд№үе°Ҷдә§з”ҹеҗҚдёәweb-0гҖҒweb-1е’Ңweb-2зҡ„дёүдёӘPodгҖӮ
гҖҖгҖҖиҝҷдёӘзү№е®ҡзҡ„StatefulSetйҖҡиҝҮspecдёӢзҡ„volumeClaimTemplatesеӯ—ж®өеҲ©з”ЁPvcпјҢд»Ҙдҫҝе°ҶжҢҒд№…еҚ·йҷ„еҠ еҲ°жҜҸдёӘPodгҖӮ
гҖҖгҖҖStatefulSetзҡ„е…ій”®иҰҒзӮ№:
гҖҖгҖҖ* StatefulSetе°Ҷе…¶е°Ғй—ӯзҡ„podе‘ҪеҗҚдёәе”ҜдёҖзҡ„пјҢе…Ғи®ёеӯҳеңЁйңҖиҰҒдёҚеҸҜдә’жҚўpodзҡ„еә”з”ЁзЁӢеәҸ
гҖҖгҖҖ*д»ҘжңүеәҸзҡ„ж–№ејҸеӨ„зҗҶStatefulSetзҡ„йғЁзҪІгҖҒжү©еұ•е’ҢеҲ йҷӨ
гҖҖгҖҖиҷҪ然StatefulSetжҸҗдҫӣдәҶйғЁзҪІе’Ңз®ЎзҗҶдёҚеҸҜдә’жҚўPodзҡ„иғҪеҠӣпјҢдҪҶд»Қ然еӯҳеңЁдёҖдёӘй—®йўҳ:жҲ‘еҰӮдҪ•жүҫеҲ°е’ҢдҪҝз”Ёе®ғ们гҖӮиҝҷе°ұжҳҜHeadless ServiceеҸ‘жҢҘдҪңз”Ёзҡ„ең°ж–№гҖӮ
гҖҖгҖҖKubernetes HeadlessжңҚеҠЎ
гҖҖгҖҖжңүж—¶жҲ‘们зҡ„еә”з”ЁзЁӢеәҸдёҚеёҢжңӣжҲ–дёҚйңҖиҰҒиҙҹиҪҪе№іиЎЎжҲ–еҚ•дёӘжңҚеҠЎIPпјҢиҜёеҰӮжӯӨзұ»зҡ„еә”з”ЁзЁӢеәҸ(дё»ж•°жҚ®еә“е’ҢеүҜжң¬ж•°жҚ®еә“гҖҒеҲҶеёғејҸеә”з”ЁзЁӢеәҸдёӯзҡ„д»ЈзҗҶзӯү)йңҖиҰҒдёҖз§Қе°ҶжөҒйҮҸи·Ҝз”ұеҲ°ж”ҜжҢҒжңҚеҠЎзҡ„еҗ„дёӘеҲҶзҰ»Podзҡ„ж–№жі•гҖӮе…·жңүе”ҜдёҖзҪ‘з»ңж ҮиҜҶз¬Ұзҡ„HeadlessжңҚеҠЎе’ҢPod (дҫӢеҰӮдҪҝз”ЁstatefulsetеҲӣе»әзҡ„йӮЈдәӣж ҮиҜҶз¬Ұ)еҸҜд»ҘеңЁжӯӨз”ЁдҫӢдёӯдёҖиө·дҪҝз”ЁгҖӮиғҪеӨҹзӣҙжҺҘи·Ҝз”ұеҲ°еҚ•дёӘPodе°ҶеӨ§йҮҸзҡ„жҖ§иғҪйҮҚж–°дәӨеҲ°ејҖеҸ‘дәәе‘ҳжүӢдёӯпјҢд»ҺеӨ„зҗҶжңҚеҠЎеҸ‘зҺ°еҲ°зӣҙжҺҘи·Ҝз”ұеҲ°дё»ж•°жҚ®еә“PodгҖӮ
гҖҖгҖҖдёӢйқўжҳҜдёҖдёӘHeadlessжңҚеҠЎзҡ„дҫӢеӯҗпјҡ
гҖҖгҖҖapiVersion: v1
гҖҖгҖҖkind: Service
гҖҖгҖҖmetadata:
гҖҖгҖҖ name: nginx-svc
гҖҖгҖҖspec:
гҖҖгҖҖ clusterIP: None
гҖҖгҖҖ selector:
гҖҖгҖҖ app: nginx
гҖҖгҖҖ ports:
гҖҖгҖҖ вҖ” name: http
гҖҖгҖҖ protocol: TCP
гҖҖгҖҖ port: 80
гҖҖгҖҖ targetPort: 30001
гҖҖгҖҖ вҖ” name: https
гҖҖгҖҖ protocol: TCP
гҖҖгҖҖ port: 443
гҖҖгҖҖ targetPort: 30002
гҖҖгҖҖдҪҝиҜҘ规иҢғзңҹжӯЈвҖңHeadlessвҖқзҡ„еұһжҖ§жҳҜи®ҫзҪ®.specдёӢзҡ„clusterIPдёәNoneгҖӮиҝҷдёӘзү№ж®Ҡзҡ„зӨәдҫӢдҪҝз”ЁspecдёӢзҡ„selectorеӯ—ж®өпјҢд»ҘжҢҮе®ҡеә”иҜҘеҰӮдҪ•й…ҚзҪ®DNSгҖӮеңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢжүҖжңүеҢ№й…Қapp: nginxйҖүжӢ©еҷЁзҡ„Podsе°ҶеҲӣе»әдёҖжқЎAи®°еҪ•пјҢзӣҙжҺҘжҢҮеҗ‘ж”ҜжҢҒжңҚеҠЎзҡ„PodгҖӮе…ідәҺDNSеҰӮдҪ•дёәHeadlessжңҚеҠЎиҮӘеҠЁй…ҚзҪ®зҡ„жӣҙеӨҡдҝЎжҒҜпјҢеҸҜд»ҘеңЁиҝҷйҮҢ(https://kubernetes.io/docs/concepts/services-networking/service/#headless-services)жүҫеҲ°гҖӮиҝҷдёӘзү№ж®Ҡзҡ„规иҢғе°ҶеҲӣе»әз«ҜзӮ№nginx-svc-0гҖҒnginx-svc-1гҖҒnginx-svc-2пјҢе®ғ们е°ҶеҲҶеҲ«зӣҙжҺҘи·Ҝз”ұеҲ°еҗҚдёәweb-0гҖҒweb-1е’Ңweb-2зҡ„PodгҖӮ
гҖҖгҖҖHeadlessжңҚеҠЎзҡ„иҰҒзӮ№:
гҖҖгҖҖ*ж— еӨҙжңҚеҠЎе…Ғи®ёзӣҙжҺҘи·Ҝз”ұеҲ°зү№е®ҡзҡ„иұҶиҚҡ
гҖҖгҖҖ*дҪҝеә”з”ЁзЁӢеәҸејҖеҸ‘дәәе‘ҳиғҪеӨҹд»Ҙ他们и®ӨдёәеҗҲйҖӮзҡ„ж–№ејҸеӨ„зҗҶжңҚеҠЎеҸ‘зҺ°
гҖҖгҖҖз»“и®ә
гҖҖгҖҖKubernetesдҪҝжңүзҠ¶жҖҒеә”з”ЁзЁӢеәҸејҖеҸ‘еңЁе®№еҷЁдё–з•ҢдёӯжҲҗдёәзҺ°е®һпјҢзү№еҲ«жҳҜеңЁз®ЎзҗҶеә”з”ЁзЁӢеәҸзҠ¶жҖҒе’ҢжҢҒд№…ж•°жҚ®ж—¶гҖӮжҢҒд№…еҚ·е’ҢжҢҒд№…еҚ·еЈ°жҳҺе»әз«ӢеңЁеҚ·зҡ„еҹәзЎҖд№ӢдёҠпјҢд»Ҙж”ҜжҢҒжҢҒд№…ж•°жҚ®еӯҳеӮЁпјҢд»ҺиҖҢж”ҜжҢҒеңЁдёҖдёӘдё»иҰҒжҳҜзҹӯжҡӮжҖ§зҡ„зҺҜеўғдёӯдҝқжҢҒж•°жҚ®жҢҒд№…жҖ§гҖӮеӯҳеӮЁзұ»иҝӣдёҖжӯҘжү©еұ•дәҶиҝҷдёҖжҖқжғіпјҢе…Ғи®ёжҢүйңҖжҸҗдҫӣеӯҳеӮЁиө„жәҗгҖӮStatefulSetжҸҗдҫӣPodжғҹдёҖжҖ§е’ҢзІҳж»һж ҮиҜҶпјҢдёәжҜҸдёӘPodжҸҗдҫӣжңүзҠ¶жҖҒж ҮиҜҶпјҢиҝҷдәӣж ҮиҜҶеңЁPodдёӯж–ӯе’ҢйҮҚеҗҜжңҹй—ҙжҢҒз»ӯеӯҳеңЁгҖӮHeadlessжңҚеҠЎеҸҜд»ҘдёҺStatefulSetдёҖиө·дҪҝз”ЁпјҢдёәеә”з”ЁзЁӢеәҸејҖеҸ‘дәәе‘ҳжҸҗдҫӣж №жҚ®еә”з”ЁзЁӢеәҸйңҖжұӮжқҘеҲ©з”ЁPodзҡ„зӢ¬зү№жҖ§зҡ„иғҪеҠӣгҖӮ
гҖҖгҖҖжң¬ж–Үд»Ӣз»ҚдәҶKubernetesдёӯжңүзҠ¶жҖҒеә”з”ЁзЁӢеәҸжүҖйңҖзҡ„еҹәжң¬е…ғзҙ гҖӮйҡҸзқҖKubernetesзҡ„дёҚж–ӯеҸ‘еұ•пјҢеӣҙз»•жңүзҠ¶жҖҒеә”з”ЁзЁӢеәҸзҡ„еҠҹиғҪе°Ҷ继з»ӯеҮәзҺ°гҖӮеҜ№дәҺжңүзҠ¶жҖҒеә”з”ЁзЁӢеәҸејҖеҸ‘дәәе‘ҳе’ҢйӣҶзҫӨз®ЎзҗҶе‘ҳжқҘиҜҙпјҢдәҶи§Јиҝҷдәӣеҹәжң¬е…ғзҙ жҳҜйқһеёёйҮҚиҰҒзҡ„гҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңеҰӮдҪ•еҲ©з”ЁKubernetesе®һзҺ°е®№еҷЁзҡ„жҢҒд№…еҢ–еӯҳеӮЁвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ