您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Kafka producer如何使用?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
一、producer工作流程
producer使用用户启动producer的线程,将待发送的消息封装到一个ProducerRecord类实例,然后将其序列化之后发送给partitioner,再由后者确定目标分区后一同发送到位于producer程序中的一块内存缓冲区中。而producer的另外一个线程(Sender线程)则负责实时从该缓冲区中提取出准备就绪的消息封装进一个批次(batch),统一发送给对应的broker,具体流程如下图:
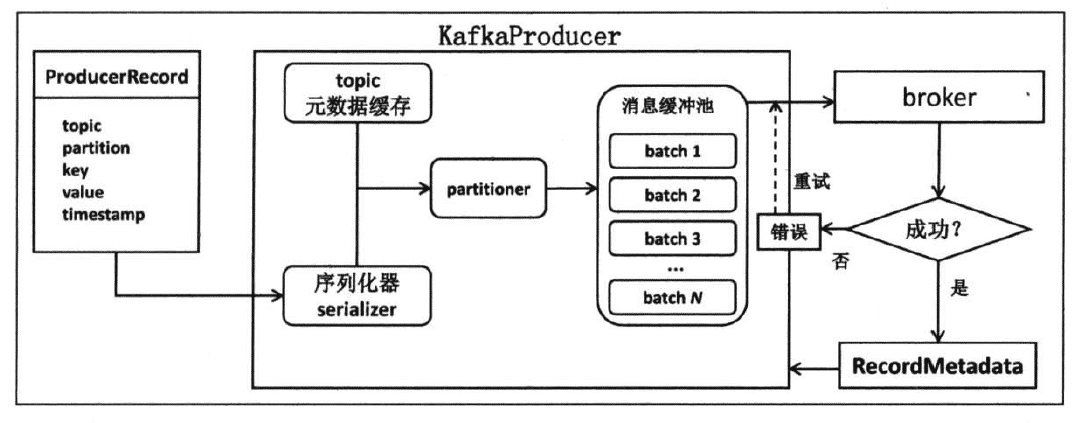
二、producer示例程序开发
首先引入kafka相关依赖,在pom.xml文件中加入如下依赖:
<!--kafka--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>2.2.0</version> </dependency>
在resources下面创建kafka-producer.properties配置文件,用于设置kafka参数,内容如下:
bootstrap.servers=192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 key.serializer=org.apache.kafka.common.serialization.StringSerializer value.serializer=org.apache.kafka.common.serialization.StringSerializer acks=-1 retries=3 batch.size=323840 linger.ms=10 buffer.memory=33554432 max.block.ms=3000
其中,前三个参数必须明确指定,因为这三个参数没有默认值(注:kafka的producer参数配置可以参考http://kafka.apache.org/documentation/),然后编写producer发送消息的代码:
/**
* Kafka发送消息测试
* @throws IOException
*/
public void sendMsg() throws IOException {
//1.构造properties对象
Properties properties = new Properties();
FileInputStream fileInputStream = new FileInputStream("F:\\javaCode\\jvmdemo\\src\\main\\resources\\kafka-producer.properties");
properties.load(fileInputStream);
fileInputStream.close();
//2.构造kafkaProducer对象
KafkaProducer producer = new KafkaProducer(properties);
for (int i = 0; i < 100; i++) {
//3.构造待发送消息的producerRecord对象,并指定消息要发送到哪个topic,消息的key和value
ProducerRecord testTopic = new ProducerRecord("testTopic", Integer.toString(i), Integer.toString(i));
//4.调用kafkaProducer对象的send方法发送消息
producer.send(testTopic);
}
//5.关闭kafkaProducer
producer.close();
}然后登陆kafka所在服务器,执行以下命令监听消息:
cd /usr/local/kafka/bin
./kafka-console-consumer.sh --bootstrap-server 192.168.184.128:9092,192.168.184.128:9093,192.168.184.128:9094 --topic testTopic --from-beginning
运行sendMsg方法,注意观察消费端,

可以看到有0-99之间的数字依次被消费到,说明消息发送成功。
三、异步和同步发送消息
上面发送消息的示例程序中,没有对发送结果进行处理,如果消息发送失败我们也是无法得知的,这种方法在实际应用中是不推荐的。在实际使用场景中,一般使用异步和同步两种常见发送方式。Java版本producer的send方法会返回一个Future对象,如果调用Future.get()方法就会无限等待返回结果,实现同步发送的效果,否则就是异步发送。
1.异步发送消息
Java版本producer的send()方法提供了回调类参数来实现异步发送以及对发送结果进行的响应,具体代码如下:
/**
* 异步发送消息
*
* @throws IOException
*/
public void sendMsg() throws IOException {
//1.构造properties对象
Properties properties = new Properties();
FileInputStream fileInputStream = new FileInputStream("F:\\javaCode\\jvmdemo\\src\\main\\resources\\kafka-producer.properties");
properties.load(fileInputStream);
fileInputStream.close();
//2.构造kafkaProducer对象
KafkaProducer producer = new KafkaProducer(properties);
for (int i = 0; i < 100; i++) {
//3.构造待发送消息的producerRecord对象,并指定消息要发送到哪个topic,消息的key和value
ProducerRecord testTopic = new ProducerRecord("testTopic", Integer.toString(i), Integer.toString(i));
//4.调用kafkaProducer对象的send方法发送消息,传入Callback回调参数
producer.send(testTopic, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception exception) {
if (null == exception) {
//消息发送成功后的处理
System.out.println("消息发送成功");
} else {
//消息发送失败后的处理
System.out.println("消息发送失败");
}
}
});
}
//5.关闭kafkaProducer
producer.close();
}以上代码中,send方法第二个参数传入一个匿名内部类对象,也可以传入实现了org.apache.kafka.clients.producer.Callback接口的类对象。同时onCompletion方法的两个入参recordMetadata和exception不会同时为空,当消息发送成功后,exception为null,消息发送失败后recordMetadata为null。因此可以按照两个入参进行成功和失败逻辑的处理。
其次,Kafka发送消息失败的类型包含两类,可重试异常和不可重试异常。所有的可重试异常都继承自org.apache.kafka.common.errors.RetriableException抽象类,理论上所有没有继承RetriableException 类的其他异常都属于不可重试异常,鉴于此,可以在消息发送失败后,按照是否可以重试,来进行不同的处理逻辑处理:
//4.调用kafkaProducer对象的send方法发送消息
producer.send(testTopic, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception exception) {
if (null == exception) {
//消息发送成功后的处理
System.out.println("消息发送成功");
} else {
if(exception instanceof RetriableException){
// 可重试异常
System.out.println("可重试异常");
}else{
// 不可重试异常
System.out.println("不可重试异常");
}
}
}
});2.同步发送消息
同步发送和异步发送是通过Java的Futrue来区分的,调用Future.get()无限等待结果返回,即实现了同步发送的结果,具体代码如下:
// 发送消息
Future future = producer.send(testTopic);
try {
// 调用get方法等待结果返回,发送失败则会抛出异常
future.get();
} catch (Exception e) {
System.out.println("消息发送失败");
}四、其他高级特性
1.消息分区机制
kafka producer提供了分区策略以及分区器(partitioner)用于确定将消息发送到指定topic的哪个分区中。默认分区器根据murmur2算法计算消息key的哈希值,然后对总分区数求模确认消息要被发送的目标分区号(这点让我想起了redis集群中key值的分配方法),这样就确保了相同key的消息被发送到相同分区。若消息没有key值,将采用轮询的方式确保消息在topic的所有分区上均匀分配。
除了使用kafka默认的分区机制,也可以通过实现org.apache.kafka.clients.producer.Partitioner接口来自定义分区器,此时需要在构造KafkaProducer的 properties中增加partitioner.class来指明分区器实现类,如:partitioner.class=com.demo.service.CustomerPartitioner。
2.消息序列化
在本篇开始的producer示例程序中,在构造KafkaProducer对象的时候,有两个配置项
分别用于配置消息key和value的序列化方式为String类型,除此之外,Kafka中还提供了如下默认的序列化器:
ByteArraySerializer:本质上什么也不做,因为网络中传输就是以字节传输的;
ByteBufferSerializer:序列化ByteBuffer消息;
BytesSerializer:序列化kafka自定义的Bytes类型;
IntegerSerializer:序列化Integer类型;
DoubleSerializer:序列化Double类型;
LongSerializer:序列化Long类型;
如果要自定义序列化器,则需要实现org.apache.kafka.common.serialization.Serializer接口,并且将key.serializer和value.serializer配置为自定义的序列化器。
3.消息压缩
消息压缩可以显著降低磁盘占用以及带宽占用,从而有效提升I/O密集型应用性能,但是引入压缩同时会消耗额外的CPU,因此压缩是I/O性能和CPU资源的平衡。kafka目前支持3种压缩算法:CZIP,Snappy和LZ4,性能测试结果显示三种压缩算法的性能如下:LZ4>>Snappy>GZIP,目前启用LZ4进行消息压缩的producer的吞吐量是最高的。
默认情况下Kafka是不压缩消息的,但是可以通过在创建KafkaProducer 对象的时候设置producer端参数compression.type来开启消息压缩,如配置compression.type=LZ4。那么什么时候开启压缩呢?首先判断是否启用压缩的依据是I/O资源消耗与CPU资源消耗的对比,如果环境上I/O资源非常紧张,比如producer程序占用了大量的网络带宽或broker端的磁盘占用率很高,而producer端的CPU资源非常富裕,那么就可以考虑为producer开启压缩。
4.无消息丢失配置
在使用KafkaProducer.send()方法发送消息的时候,其实是把消息放入缓冲区中,再由一个专属I/O线程负责从缓冲区提取消息并封装消息到batch中,然后再发送出去。如果在I/O线程将消息发送出去之前,producer奔溃了,那么所有的消息都将丢失。同时,存在多消息发送时候由于网络抖动导致消息乱序的问题,为了解决这两个问题,可以通过在producer端以及broker端进行配置进行避免。
4.1 producer端配置
max.block.ms=3000:设置block的时长,当缓冲区被填满或者metadata丢失时产生block,停止接收新的消息;
acks=all:等待所有follower都响应了发送消息认为消息发送成功;
retries=Integer.MAX_VALUE:设置重试次数,设置一个比较大的值可以保证消息不丢失;
max.in.flight.requests.per.connection=1:限制producer在单个broker连接上能够发送的未响应请求的数量,从而防止同topic统一分区下消息乱序问题;
除了设置以上参数之外,在发送消息的时候,应该尽量使用带有回调参数的send方法来处理发送结果,如果数据发送失败,则显示调用KafkaProducer.close(0)方法来立即关闭producer,防止消息乱序。
4.2 broker端配置
unclean.leader.election.enable=false:关闭unclean leader选举,即不允许非ISR中的副本被选举为leader;
replication.factor>=3:至少使用3个副本保存数据;
min.issync.replicas>1:控制某条消息至少被写入到ISR中多少个副本才算成功,当且仅当producer端acks参数设置为all或者-1时,该参数才有效。
最后,确保replication.factor>min.issync.replicas,如果两者相等,那么只要有一个副本挂掉,分区就无法工作,推荐配置replication.factor=min.issync.replicas+1。
关于producer端的开发就介绍到这儿,下一篇将介绍consumer端的开发。
关于Kafka producer如何使用问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。