您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关用python爬虫收集知乎大V头像的示例,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
一:请求头(headers)
每个网站的请求头都会不一样,但爬取得网站,都有例子,大家在不初期,跟着选就行
Authorization:HTTP授权的授权证书
User-Agent:代表你用哪种浏览器
X-UDID:一串验证码
二:真实的urls
异步加载中,真实的url并非https://www.zhihu.com/people/feifeimao/followers,真正的url需要我们通过抓包获取,流程如图:
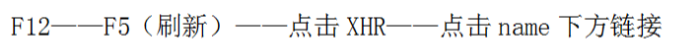
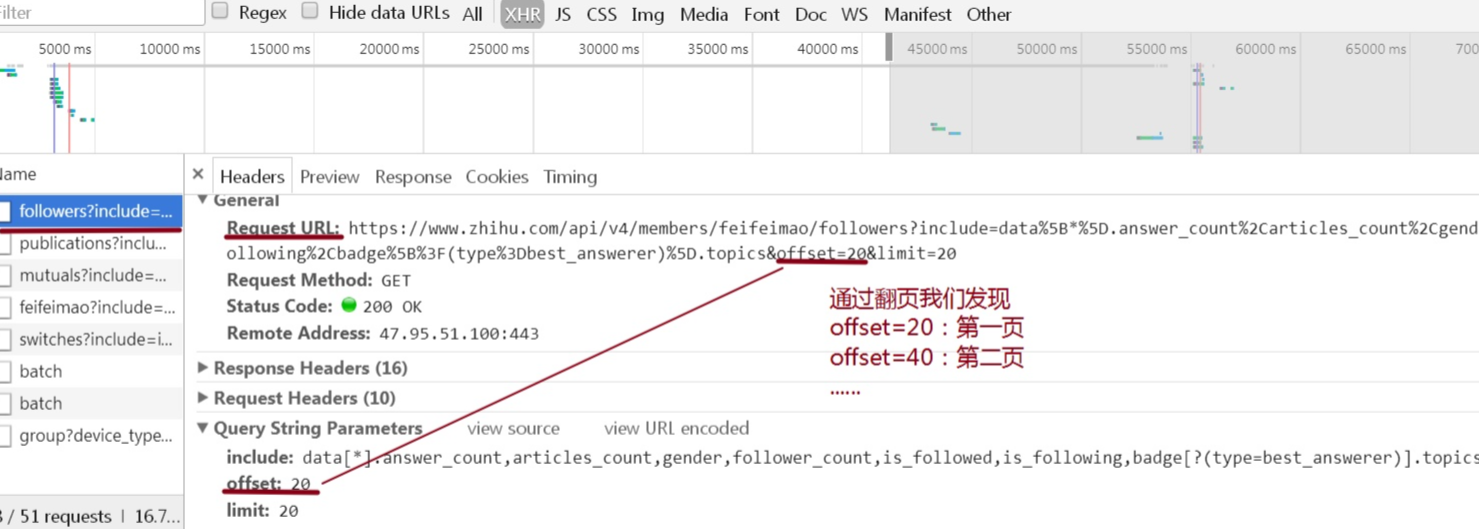
所以我们得出真实url:
https://www.zhihu.com/api/v4/members/feifeimao/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=20&limit=20
通过加载更多,我们发现url中start随之同步变化,变化的间隔为20,即offset=20(第一页),start=40(第二页),以此类推,所以我们得出.format(i*20),大家可以对比第三篇的翻页。
三:img_url
我们抓取的img的url需要有序的排列,即采用append函数,依次把他们放入img_url。
四:json
之前我们用得.text是需要网页返回文本的信息,而这里返回的是json文件,所以用.json
json结构很清晰,大家一层一层选取就好了
取出字典中的值,需要在方括号中指明值对应的键
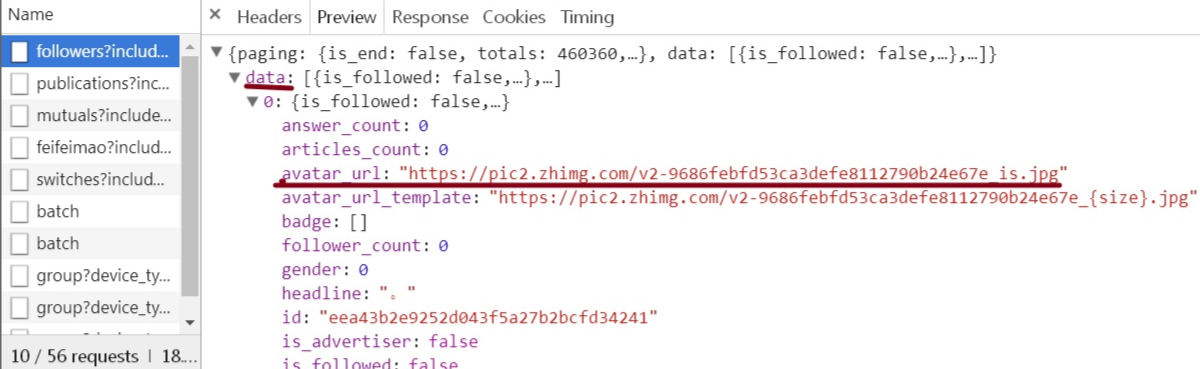
以下为全部代码:
# -*- coding: utf-8 -*-
import requests
import json
from urllib.request import urlretrieve
headers = {'authorization':'Bearer Mi4xQXN3S0F3QUFBQUFBUUVJSjdTempDaGNBQUFCaEFsVk5BQzRmV3dDVVJzeU9NOWxNU0pZT1BNdFJ5bTlrSzk3MU1B|1513218048|1e03f7e7f26825482a72e4a629ef80292847548e',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'x-udid':'AEBCCe0s4wqPToZZF6LV3roAjT8uEikZF1k=',
} #请求头
urls = ['https://www.zhihu.com/api/v4/members/feifeimao/followers?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_' \
'followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset={}&limit=20'.format(i*20) for i in range (0,5)]
img_urls = [] #用来存所有的img_url
for url in urls:
datas = requests.get(url,headers = headers).json()['data'] #获取json文件下的data
for it in datas:
img_url = it['avatar_url'] #获取头像url
img_urls.append(img_url) #把获取的url依次放入img_urls
i = 0 #计数
for it in img_urls:
urlretrieve(it,'D://%s.jpg' % i) #通过url,依次下载头像,并保存于D盘
i = i+1 #i依次累加关于用python爬虫收集知乎大V头像的示例就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。