жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
Jsonж•°жҚ®жҖҺд№ҲеҲ©з”ЁPythonзҲ¬иҷ«иҝӣиЎҢзҲ¬еҸ–пјҹзӣёдҝЎеҫҲеӨҡжІЎжңүз»ҸйӘҢзҡ„дәәеҜ№жӯӨжқҹжүӢж— зӯ–пјҢдёәжӯӨжң¬ж–ҮжҖ»з»“дәҶй—®йўҳеҮәзҺ°зҡ„еҺҹеӣ е’Ңи§ЈеҶіж–№жі•пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« еёҢжңӣдҪ иғҪи§ЈеҶіиҝҷдёӘй—®йўҳгҖӮ
иҜҘең°еқҖиҝ”еӣһзҡ„е“Қеә”еҶ…е®№дёәJsonзұ»еһӢпјҢе…¶дёӯзәўжЎҶж Үи®°зҡ„йЎ№еҚідёәAIжөҒиҪ¬зҺҮеҖјпјҡ
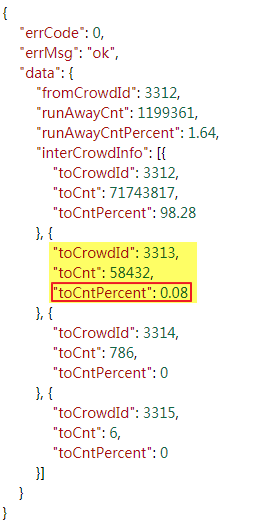
е®һзҺ°д»Јз ҒеҰӮдёӢпјҡ
import requests
import json
import csv
# зҲ¬иҷ«ең°еқҖ
url = 'https://databank.yushanfang.com/api/ecapi?path=/databank/crowdFullLink/flowInfo&fromCrowdId=3312&beginTheDate=201810{}&endTheDate=201810{}&toCrowdIdList[0]=3312&toCrowdIdList[1]=3313&toCrowdIdList[2]=3314&toCrowdIdList[3]=3315'
# жҗәеёҰcookieиҝӣиЎҢи®ҝй—®
headers = {
'Host':'databank.yushanfang.com',
'Referer':'https://databank.yushanfang.com/',
'Connection':'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Cookie':'_tb_token_=iNkDeJLdM3MgvKjhsfdW; bs_n_lang=zh_CN; cna=aaj1EViI7x0CATo9kTKvjzgS; ck2=072de851f1c02d5c7bac555f64c5c66d; c_token=c74594b486f8de731e2608cb9526a3f2; an=5YWo5qOJ5pe25Luj5a6Y5pa55peX6Iiw5bqXOnpmeA%3D%3D; lg=true; sg=\"=19\"; lvc=sAhojs49PcqHQQ%3D%3D; isg=BPT0Md7dE_ic5Ie3Oa85RxaMxbLK3UqJMMiN6o5VjH8C-ZRDtt7aRXb3fXGEAVAP',
}
rows = []
for n in range(20, 31):
row = []
row.append(n)
for m in range (21, 32):
if m < n + 1:
row.append("")
else:
# ж јејҸеҢ–иҜ·жұӮең°еқҖпјҢжӣҙжҚўиҜ·жұӮеҸӮж•°
reqUrl = url.format(n, m)
# жү“еҚ°жң¬ж¬ЎиҜ·жұӮең°еқҖ
print(url)
# еҸ‘йҖҒиҜ·жұӮпјҢиҺ·еҸ–е“Қеә”з»“жһң
response = requests.get(url=reqUrl, headers=headers, verify=False)
text = response.text
# жү“еҚ°жң¬ж¬ЎиҜ·жұӮе“Қеә”еҶ…е®№
print(text)
# е°Ҷе“Қеә”еҶ…е®№иҪ¬жҚўдёәJsonеҜ№иұЎ
jsonobj = json.loads(text)
# д»ҺJsonеҜ№иұЎиҺ·еҸ–жғіиҰҒзҡ„еҶ…е®№
toCntPercent = jsonobj['data']['interCrowdInfo'][1]['toCntPercent']
# з”ҹжҲҗиЎҢж•°жҚ®
row.append(str(toCntPercent)+"%")
# дҝқеӯҳиЎҢж•°жҚ®
rows.append(row)
# з”ҹжҲҗExcelиЎЁеӨҙ
header = ['AIжөҒиҪ¬зҺҮ', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31']
# е°ҶиЎЁеӨҙж•°жҚ®е’ҢзҲ¬иҷ«ж•°жҚ®еҜјеҮәеҲ°Excelж–Ү件
with open('D:\\res\\pachong\\tmall.csv', 'w', encoding='gb18030') as f :
f_csv = csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(rows)import csv
import json
import ssl
import urllib.request
# зҲ¬иҷ«ең°еқҖ
url = 'https://databank.yushanfang.com/api/ecapi?path=/databank/crowdFullLink/flowInfo&fromCrowdId=3312&beginTheDate=201810{}&endTheDate=201810{}&toCrowdIdList[0]=3312&toCrowdIdList[1]=3313&toCrowdIdList[2]=3314&toCrowdIdList[3]=3315'
# дёҚж ЎйӘҢиҜҒд№Ұ
ssl._create_default_https_context = ssl._create_unverified_context
# жҗәеёҰcookieиҝӣиЎҢи®ҝй—®
headers = {
'Host':'databank.yushanfang.com',
'Referer':'https://databank.yushanfang.com/',
'Connection':'keep-alive',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Cookie':'_tb_token_=iNkDeJLdM3MgvKjhsfdW; bs_n_lang=zh_CN; cna=aaj1EViI7x0CATo9kTKvjzgS; ck2=072de851f1c02d5c7bac555f64c5c66d; c_token=c74594b486f8de731e2608cb9526a3f2; an=5YWo5qOJ5pe25Luj5a6Y5pa55peX6Iiw5bqXOnpmeA%3D%3D; lg=true; sg=\"=19\"; lvc=sAhojs49PcqHQQ%3D%3D; isg=BPT0Md7dE_ic5Ie3Oa85RxaMxbLK3UqJMMiN6o5VjH8C-ZRDtt7aRXb3fXGEAVAP',
}
rows = []
n = 20
while n <31:
row = []
row.append(n)
m =21
while m <32:
if m < n + 1:
row.append("")
else:
# ж јејҸеҢ–иҜ·жұӮең°еқҖпјҢжӣҙжҚўиҜ·жұӮеҸӮж•°
reqUrl = url.format(n, m)
# жү“еҚ°жң¬ж¬ЎиҜ·жұӮең°еқҖ
print(reqUrl)
# еҸ‘йҖҒиҜ·жұӮпјҢиҺ·еҸ–е“Қеә”з»“жһң
request = urllib.request.Request(url=reqUrl, headers=headers)
response = urllib.request.urlopen(request)
text = response.read().decode('utf8')
# жү“еҚ°жң¬ж¬ЎиҜ·жұӮе“Қеә”еҶ…е®№
print(text)
# е°Ҷе“Қеә”еҶ…е®№иҪ¬жҚўдёәJsonеҜ№иұЎ
jsonobj = json.loads(text)
# д»ҺJsonеҜ№иұЎиҺ·еҸ–жғіиҰҒзҡ„еҶ…е®№
toCntPercent = jsonobj['data']['interCrowdInfo'][1]['toCntPercent']
# з”ҹжҲҗиЎҢж•°жҚ®
row.append(str(toCntPercent) + "%")
m = m+1
rows.append(row)
n = n+1
# з”ҹжҲҗExcelиЎЁеӨҙ
header = ['AIжөҒиҪ¬зҺҮ', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31']
# е°ҶиЎЁеӨҙж•°жҚ®е’ҢзҲ¬иҷ«ж•°жҚ®еҜјеҮәеҲ°Excelж–Ү件
with open('D:\\res\\pachong\\tmall.csv', 'w', encoding='gb18030') as f :
f_csv = csv.writer(f)
f_csv.writerow(header)
f_csv.writerows(rows)зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们жҺҢжҸЎJsonж•°жҚ®жҖҺд№ҲеҲ©з”ЁPythonзҲ¬иҷ«иҝӣиЎҢзҲ¬еҸ–зҡ„ж–№жі•дәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–жғідәҶи§ЈжӣҙеӨҡзӣёе…іеҶ…е®№пјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ