жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶеҰӮдҪ•дҪҝз”Ё.NET CoreеҶҷзҲ¬иҷ«зҲ¬еҸ–з”өеҪұеӨ©е ӮпјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
иҮӘд»ҺдёҠдёҖдёӘйЎ№зӣ®д»Һ.NETиҝҒ移еҲ°.NET coreд№ӢеҗҺпјҢзЈ•зЈ•зў°зў°зЈЁи№ӯдәҶдёҖдёӘжңҲжүҚжӯЈејҸдёҠзәҝеҲ°ж–°зүҲжң¬гҖӮ
然еҗҺжңҖиҝ‘еҸҲејҖдәҶдёӘж–°еқ‘пјҢжҗһдәҶдёӘзҲ¬иҷ«з”ЁжқҘзҲ¬dy2018з”өеҪұеӨ©е ӮдёҠйқўзҡ„з”өеҪұиө„жәҗгҖӮиҝҷйҮҢд№ҹеҖҹжңәз®ҖеҚ•д»Ӣз»ҚдёҖдёӢеҰӮдҪ•еҹәдәҺ.NET CoreеҶҷдёҖдёӘзҲ¬иҷ«гҖӮеҮҶеӨҮе·ҘдҪңпјҲ.NET CoreеҮҶеӨҮпјү
йҰ–е…ҲпјҢиӮҜе®ҡжҳҜе…Ҳе®үиЈ….NET Coreе’ҜгҖӮдёӢиҪҪеҸҠе®үиЈ…ж•ҷзЁӢеңЁиҝҷйҮҢпјҡ https://www.jb51.net/article/87907.htm https://www.jb51.net/article/88735.htmгҖӮж— и®әдҪ жҳҜWindowsгҖҒlinuxиҝҳжҳҜmacпјҢз»ҹз»ҹеҸҜд»ҘзҺ©гҖӮ
жҲ‘иҝҷйҮҢзҡ„зҺҜеўғжҳҜпјҡWindows10 + VS2015 community updata3 + .NET Core 1.1.0 SDK + .NET Core 1.0.1 tools Preview 2.
зҗҶи®әдёҠпјҢеҸӘйңҖиҰҒе®үиЈ…дёҖдёӢ .NET Core 1.1.0 SDK еҚіеҸҜејҖеҸ‘.NET CoreзЁӢеәҸпјҢиҮідәҺз”Ёд»Җд№Ҳе·Ҙе…·еҶҷд»Јз ҒйғҪж— е…ізҙ§иҰҒдәҶгҖӮ
е®үиЈ…еҘҪд»ҘдёҠе·Ҙе…·д№ӢеҗҺпјҢеңЁVS2015зҡ„ж–°е»әйЎ№зӣ®е°ұеҸҜд»ҘзңӢеҲ°.NET Coreзҡ„жЁЎжқҝдәҶгҖӮеҰӮдёӢеӣҫпјҡ
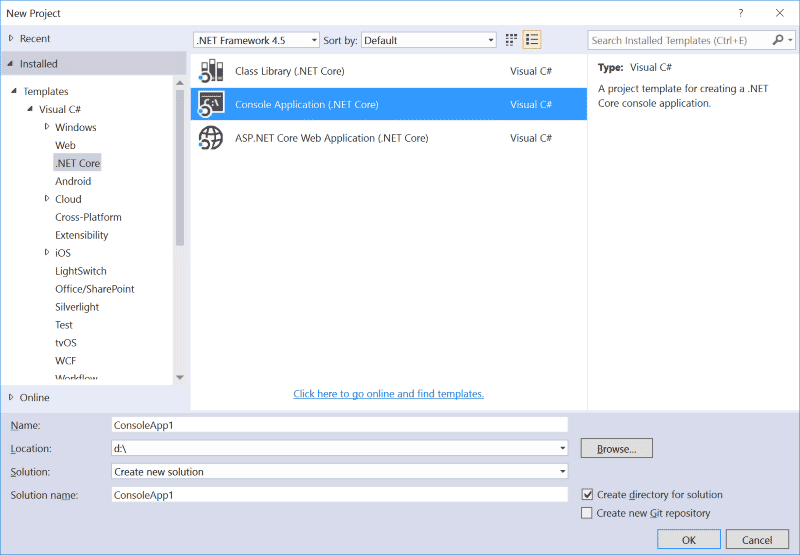
дёәдәҶз®ҖеҚ•иө·и§ҒпјҢжҲ‘们еҲӣе»әзҡ„ж—¶еҖҷпјҢзӣҙжҺҘйҖүжӢ©VS .NET Core toolsиҮӘеёҰзҡ„жЁЎжқҝгҖӮ
дёҖдёӘзҲ¬иҷ«зҡ„иҮӘжҲ‘дҝ®е…» еҲҶжһҗзҪ‘йЎө
еҶҷзҲ¬иҷ«д№ӢеүҚпјҢжҲ‘们йҰ–е…ҲиҰҒе…ҲеҺ»дәҶи§ЈдёҖдёӢеҚіе°ҶиҰҒзҲ¬еҸ–зҡ„зҪ‘йЎөж•°жҚ®з»„жҲҗгҖӮ
е…·дҪ“еҲ°зҪ‘йЎөзҡ„иҜқпјҢдҫҝжҳҜеҲҶжһҗжҲ‘们иҰҒжҠ“еҸ–зҡ„ж•°жҚ®еңЁHTMLйҮҢйқўжҳҜз”Ёд»Җд№Ҳж ҮзӯҫжҠ‘жҲ–жңүд»Җд№Ҳж ·зҡ„ж Үи®°пјҢ然еҗҺдҪҝз”ЁиҝҷдёӘж Үи®°жҠҠж•°жҚ®д»ҺHTMLдёӯжҸҗеҸ–еҮәжқҘгҖӮеңЁжҲ‘иҝҷйҮҢзҡ„иҜқпјҢз”Ёзҡ„жӣҙеӨҡзҡ„жҳҜHTMLж Үзӯҫзҡ„IDе’ҢCSSеұһжҖ§гҖӮ
д»Ҙжң¬ж–Үз« жғіиҰҒзҲ¬еҸ–зҡ„dy2018.comдёәдҫӢ,з®ҖеҚ•жҸҸиҝ°дёҖдёӢиҝҷдёӘиҝҮзЁӢгҖӮdy2018.comдё»йЎөеҰӮдёӢеӣҫпјҡ
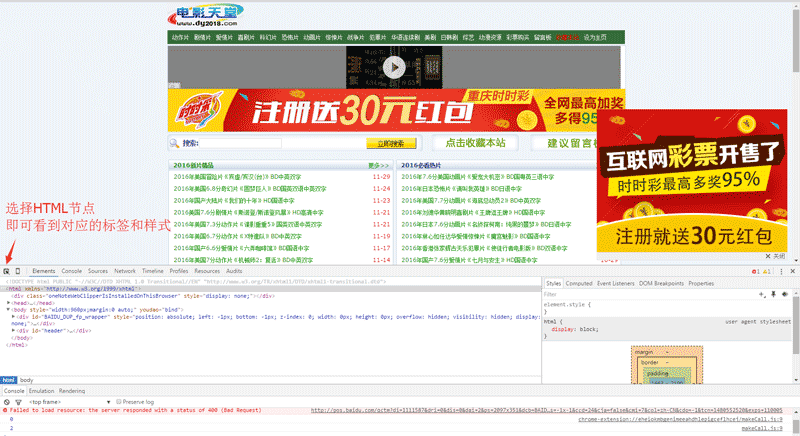
еңЁchromeйҮҢйқўпјҢжҢүF12иҝӣе…ҘејҖеҸ‘иҖ…жЁЎејҸпјҢжҺҘзқҖеҰӮдёӢеӣҫдҪҝз”Ёйј ж ҮйҖүжӢ©еҜ№еә”йЎөйқўж•°жҚ®пјҢ然еҗҺеҺ»еҲҶжһҗйЎөйқўHTMLз»„жҲҗгҖӮ
жҺҘзқҖжҲ‘们ејҖе§ӢеҲҶжһҗйЎөйқўж•°жҚ®:
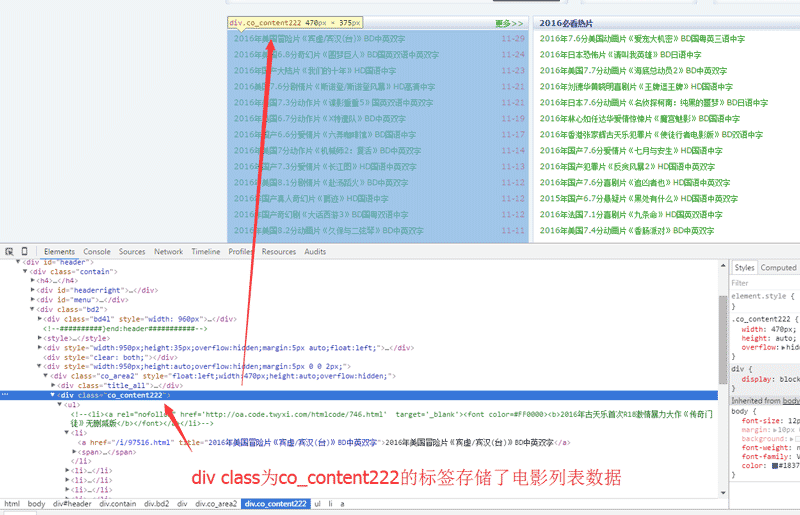
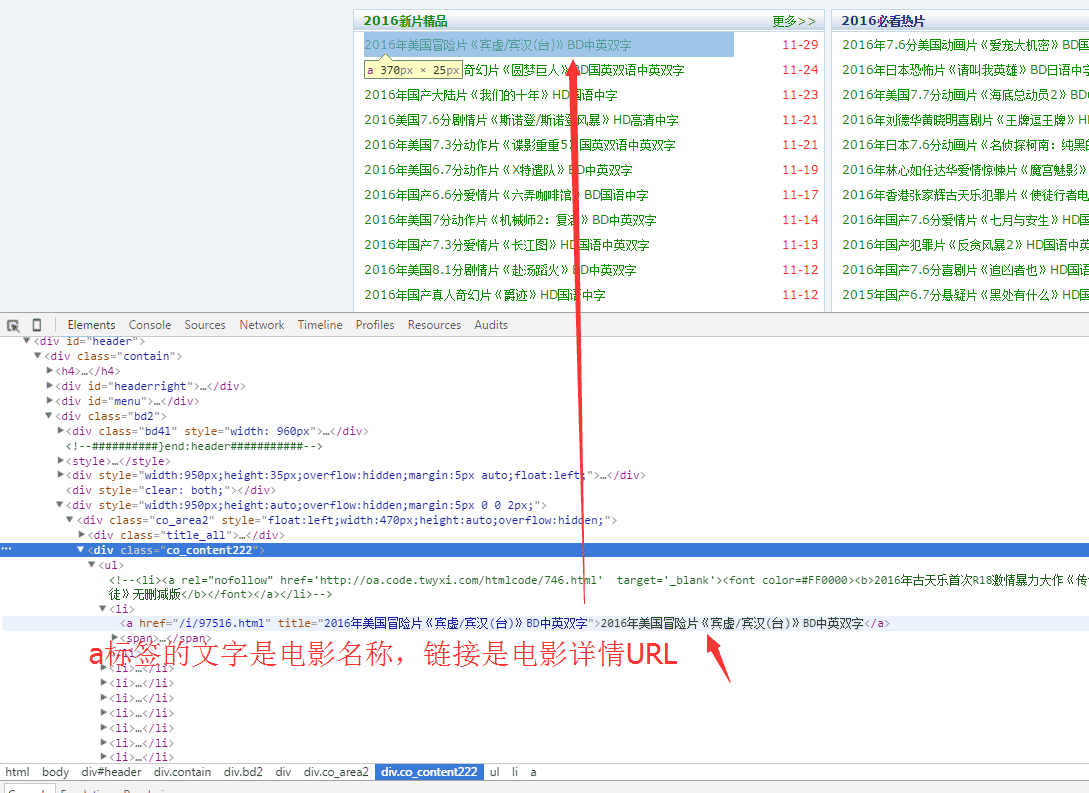
з»ҸиҝҮз®ҖеҚ•еҲҶжһҗHTMLпјҢжҲ‘们еҫ—еҲ°д»ҘдёӢз»“и®әпјҡ
www.dy2018.comйҰ–йЎөзҡ„з”өеҪұж•°жҚ®еӯҳеӮЁеңЁдёҖдёӘclassдёәco_content222зҡ„divж ҮзӯҫйҮҢйқў
з”өеҪұиҜҰжғ…й“ҫжҺҘдёәaж ҮзӯҫпјҢж ҮзӯҫжҳҫзӨәж–Үжң¬е°ұжҳҜз”өеҪұеҗҚз§°пјҢURLеҚіиҜҰжғ…URL
йӮЈд№ҲжҖ»з»“дёӢжқҘпјҢжҲ‘们зҡ„е·ҘдҪңе°ұжҳҜпјҡжүҫеҲ°class='co_content222' зҡ„divж ҮзӯҫпјҢд»ҺйҮҢйқўжҸҗеҸ–жүҖжңүзҡ„aж Үзӯҫж•°жҚ®гҖӮ
ејҖе§ӢеҶҷд»Јз ҒвҖҰ
д№ӢеүҚеңЁеҶҷеҒҡйЎ№зӣ®зҡ„ж—¶еҖҷз”ЁеҲ°иҝҮAngleSharpеә“пјҢдёҖдёӘеҹәдәҺ.NETпјҲC#пјүејҖеҸ‘зҡ„дё“й—Ёдёәи§ЈжһҗxHTMLжәҗз Ғзҡ„DLL组件гҖӮ
AngleSharpдё»йЎөеңЁиҝҷйҮҢпјҡ https://anglesharp.github.io/ пјҢ
иҜҰз»Ҷд»Ӣз»Қпјҡhttps://www.jb51.net/article/99082.htm
Nugetең°еқҖ: Nuget AngleSharp е®үиЈ…е‘Ҫд»ӨпјҡInstall-Package AngleSharp
иҺ·еҸ–з”өеҪұеҲ—иЎЁж•°жҚ®
private static HtmlParser htmlParser = new HtmlParser();
private ConcurrentDictionary<string, MovieInfo> _cdMovieInfo = new ConcurrentDictionary<string, MovieInfo>();
privatevoidAddToHotMovieList()
{
//жӯӨж“ҚдҪңдёҚйҳ»еЎһеҪ“еүҚе…¶д»–ж“ҚдҪңпјҢжүҖд»ҘдҪҝз”ЁTask
// _cdMovieInfo дёәзәҝзЁӢе®үе…Ёеӯ—е…ёпјҢеӯҳеӮЁдәҶеҪ“жңҹжүҖжңүзҡ„з”өеҪұж•°жҚ®
Task.Factory.StartNew(()=>
{
try
{
//йҖҡиҝҮURLиҺ·еҸ–HTML
var htmlDoc = HTTPHelper.GetHTMLByURL("http://www.dy2018.com/");
//HTML и§ЈжһҗжҲҗ IDocument
var dom = htmlParser.Parse(htmlDoc);
//д»ҺdomдёӯжҸҗеҸ–жүҖжңүclass='co_content222'зҡ„divж Үзӯҫ
//QuerySelectorAllж–№жі•жҺҘеҸ— йҖүжӢ©еҷЁиҜӯжі•
var lstDivInfo = dom.QuerySelectorAll("div.co_content222");
if (lstDivInfo != null)
{
//еүҚдёүдёӘDIVдёәж–°з”өеҪұ
foreach (var divInfo in lstDivInfo.Take(3))
{
//иҺ·еҸ–divдёӯжүҖжңүзҡ„aж Үзӯҫдё”aж Үзӯҫдёӯеҗ«жңү"/i/"зҡ„
//Contains("/i/") жқЎд»¶зҡ„иҝҮж»ӨжҳҜеӣ дёәеңЁжөӢиҜ•дёӯеҸ‘зҺ°иҝҷдёҖеқ—divдёӯзҡ„aж ҮзӯҫжңүеҸҜиғҪжҳҜе№ҝе‘Ҡй“ҫжҺҘ
divInfo.QuerySelectorAll("a").Where(a =>
a.GetAttribute("href").Contains("/i/"))
.ToList().ForEach(
a =>
{
//жӢјжҺҘжҲҗе®Ңж•ҙй“ҫжҺҘ
var onlineURL = "http://www.dy2018.com" + a.GetAttribute("href");
//зңӢдёҖдёӢжҳҜеҗҰе·Із»ҸеӯҳеңЁдәҺзҺ°жңүж•°жҚ®дёӯ
if (!_cdMovieInfo.ContainsKey(onlineURL))
{
//иҺ·еҸ–з”өеҪұзҡ„иҜҰз»ҶдҝЎжҒҜ
MovieInfo movieInfo = FillMovieInfoFormWeb(a, onlineURL);
//дёӢиҪҪй“ҫжҺҘдёҚдёәз©әжүҚж·»еҠ еҲ°зҺ°жңүж•°жҚ®
if (movieInfo.XunLeiDownLoadURLList != null
&& movieInfo.XunLeiDownLoadURLList.Count != 0)
{
_cdMovieInfo.TryAdd
(movieInfo.Dy2018OnlineUrl,movieInfo);
}
}
});
}
}
}
catch(Exception ex)
{
}
});
}иҺ·еҸ–з”өеҪұиҜҰз»ҶдҝЎжҒҜ
privateMovieInfoFillMovieInfoFormWeb(AngleSharp.Dom.IElement a,
string onlineURL)
{
var movieHTML = HTTPHelper.GetHTMLByURL(onlineURL);
var movieDoc = htmlParser.Parse(movieHTML);
//http://www.dy2018.com/i/97462.html еҲҶжһҗиҝҮзЁӢи§ҒдёҠпјҢдёҚеҶҚиөҳиҝ°
//з”өеҪұзҡ„иҜҰз»Ҷд»Ӣз»Қ еңЁidдёәZoomзҡ„ж Үзӯҫдёӯ
var zoom = movieDoc.GetElementById("Zoom");
//дёӢиҪҪй“ҫжҺҘеңЁ bgcolor='#fdfddf'зҡ„tdдёӯпјҢжңүеҸҜиғҪжңүеӨҡдёӘй“ҫжҺҘ
var lstDownLoadURL = movieDoc.QuerySelectorAll("[bgcolor='#fdfddf']");
//еҸ‘еёғж—¶й—ҙ еңЁclass='updatetime'зҡ„spanж Үзӯҫдёӯ
var updatetime = movieDoc.QuerySelector("span.updatetime");
var pubDate = DateTime.Now;
if(updatetime!=null && !string.IsNullOrEmpty(updatetime.InnerHtml))
{
//еҶ…е®№еёҰжңүвҖңеҸ‘еёғж—¶й—ҙпјҡвҖқеӯ—ж ·пјҢ
//replaceжҲҗ""д№ӢеҗҺеҶҚеҺ»иҪ¬жҚўпјҢиҪ¬жҚўеӨұиҙҘдёҚеҪұе“ҚжөҒзЁӢ
DateTime.TryParse(updatetime.InnerHtml.Replace("еҸ‘еёғж—¶й—ҙпјҡ",
""), out pubDate);
}
var movieInfo = new MovieInfo()
{
//InnerHtmlдёӯеҸҜиғҪиҝҳеҢ…еҗ«fontж ҮзӯҫпјҢеҒҡеӨҡдёҖдёӘReplace
MovieName = a.InnerHtml.Replace("<font color=\"#0c9000\">","")
.Replace("<font color=\" #0c9000\">","")
.Replace("</font>", ""),
Dy2018OnlineUrl = onlineURL,
MovieIntro = zoom != null ? WebUtility.HtmlEncode(zoom.InnerHtml) : "жҡӮж— д»Ӣз»Қ...",
//еҸҜиғҪжІЎжңүз®Җд»ӢпјҢиҷҪ然еҘҪеғҸдёҚжҖҺд№ҲеҸҜиғҪ
XunLeiDownLoadURLList = lstDownLoadURL != null ?
lstDownLoadURL.Select(d => d.FirstElementChild.InnerHtml).ToList() : null,
//еҸҜиғҪжІЎжңүдёӢиҪҪй“ҫжҺҘ
PubDate = pubDate,
};
return movieInfo;
}HTTPHelper
иҝҷиҫ№жңүдёӘе°Ҹеқ‘пјҢdy2018зҪ‘йЎөзј–з Ғж јејҸжҳҜGB2312,.NET Coreй»ҳи®ӨдёҚж”ҜжҢҒGB2312пјҢдҪҝз”ЁEncoding.GetEncoding(вҖңGB2312вҖқ)зҡ„ж—¶еҖҷдјҡжҠӣеҮәејӮеёёгҖӮ
и§ЈеҶіж–№жЎҲжҳҜжүӢеҠЁе®үиЈ…System.Text.Encoding.CodePagesеҢ…(Install-Package System.Text.Encoding.CodePages),
然еҗҺеңЁStarup.csзҡ„Configureж–№жі•дёӯеҠ е…ҘEncoding.RegisterProvider(CodePagesEncodingProvider.Instance),жҺҘзқҖе°ұеҸҜд»ҘжӯЈеёёдҪҝз”ЁEncoding.GetEncoding(вҖңGB2312вҖқ)дәҶгҖӮ
using System;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
namespace Dy2018Crawler
{
public class HTTPHelper
{
public static HttpClient Client { get; } = new HttpClient();
publicstaticstringGetHTMLByURL(stringurl)
{
try
{
System.Net.WebRequest wRequest = System.Net.WebRequest.Create(url);
wRequest.ContentType = "text/html; charset=gb2312";
wRequest.Method = "get";
wRequest.UseDefaultCredentials = true;
// Get the response instance.
var task = wRequest.GetResponseAsync();
System.Net.WebResponse wResp = task.Result;
System.IO.Stream respStream = wResp.GetResponseStream();
//dy2018иҝҷдёӘзҪ‘з«ҷзј–з Ғж–№ејҸжҳҜGB2312,
using (System.IO.StreamReader reader =
new System.IO.StreamReader(respStream,
Encoding.GetEncoding("GB2312")))
{
return reader.ReadToEnd();
}
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
return string.Empty;
}
}
}
}е®ҡж—¶д»»еҠЎзҡ„е®һзҺ°
е®ҡж—¶д»»еҠЎжҲ‘иҝҷйҮҢдҪҝз”Ёзҡ„жҳҜ Pomelo.AspNetCore.TimedJob гҖӮ
Pomelo.AspNetCore.TimedJobжҳҜдёҖдёӘ.NET Coreе®һзҺ°зҡ„е®ҡж—¶д»»еҠЎjobеә“пјҢж”ҜжҢҒжҜ«з§’зә§е®ҡж—¶д»»еҠЎгҖҒд»Һж•°жҚ®еә“иҜ»еҸ–е®ҡж—¶й…ҚзҪ®гҖҒеҗҢжӯҘејӮжӯҘе®ҡж—¶д»»еҠЎзӯүеҠҹиғҪгҖӮ
з”ұ.NET CoreзӨҫеҢәеӨ§зҘһе…јеүҚеҫ®иҪҜMVP AmamiyaYuuko (е…ҘиҒҢеҫ®иҪҜд№ӢеҗҺе°ұеҚёд»»MVPвҖҰ)ејҖеҸ‘з»ҙжҠӨпјҢдёҚиҝҮеҘҪеғҸжІЎжңүејҖжәҗпјҢеӣһеӨҙй—®дёӢзңӢзңӢиғҪдёҚиғҪејҖжәҗжҺүгҖӮ
nugetдёҠжңүеҗ„з§ҚзүҲжң¬пјҢжҢүйңҖиҮӘеҸ–гҖӮең°еқҖпјҡ https://www.nuget.org/packages/Pomelo.AspNetCore.TimedJob/1.1.0-rtm-10026
дҪңиҖ…иҮӘе·ұзҡ„д»Ӣз»Қж–Үз« пјҡ Timed Job - Pomeloжү©еұ•еҢ…зі»еҲ—
Startup.csзӣёе…ід»Јз Ғ
жҲ‘иҝҷиҫ№дҪҝз”Ёзҡ„иҜқпјҢйҰ–е…ҲиӮҜе®ҡжҳҜе…Ҳе®үиЈ…еҜ№еә”зҡ„еҢ…пјҡInstall-Package Pomelo.AspNetCore.TimedJob -Pre
然еҗҺеңЁStartup.csзҡ„ConfigureServicesеҮҪж•°йҮҢйқўж·»еҠ Service,еңЁConfigureеҮҪж•°йҮҢйқўUseдёҖдёӢгҖӮ
// This method gets called by the runtime. Use this method to add services to the container.
publicvoidConfigureServices(IServiceCollection services)
{
// Add framework services.
services.AddMvc();
//Add TimedJob services
services.AddTimedJob();
}
publicvoidConfigure(IApplicationBuilder app,
IHostingEnvironment env, ILoggerFactory loggerFactory)
{
//дҪҝз”ЁTimedJob
app.UseTimedJob();
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseBrowserLink();
}
else
{
app.UseExceptionHandler("/Home/Error");
}
app.UseStaticFiles();
app.UseMvc(routes =>
{
routes.MapRoute(
name: "default",
template: "{controller=Home}/{action=Index}/{id?}");
});
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
}Jobзӣёе…ід»Јз Ғ
жҺҘзқҖж–°е»әдёҖдёӘзұ»пјҢжҳҺжҳҺдёәXXXJob.cs,еј•з”Ёе‘ҪеҗҚз©әй—ҙusing Pomelo.AspNetCore.TimedJobпјҢXXXJob继жүҝдәҺJobпјҢж·»еҠ д»ҘдёӢд»Јз ҒгҖӮ
public class AutoGetMovieListJob:Job
{
// Begin иө·е§Ӣж—¶й—ҙпјӣIntervalжү§иЎҢж—¶й—ҙй—ҙйҡ”пјҢеҚ•дҪҚжҳҜжҜ«з§’пјҢе»әи®®дҪҝз”Ёд»ҘдёӢж јејҸпјҢжӯӨеӨ„дёә3е°Ҹж—¶пјӣ
//SkipWhileExecutingжҳҜеҗҰзӯүеҫ…дёҠдёҖдёӘжү§иЎҢе®ҢжҲҗпјҢtrueдёәзӯүеҫ…пјӣ
[Invoke(Begin = "2016-11-29 22:10", Interval = 1000 * 3600*3, SkipWhileExecuting =true)]
publicvoidRun()
{
//JobиҰҒжү§иЎҢзҡ„йҖ»иҫ‘д»Јз Ғ
//LogHelper.Info("Start crawling");
//AddToLatestMovieList(100);
//AddToHotMovieList();
//LogHelper.Info("Finish crawling");
}
}йЎ№зӣ®еҸ‘еёғзӣёе…і ж–°еўһruntimesиҠӮзӮ№
дҪҝз”ЁVS2015ж–°е»әзҡ„жЁЎжқҝе·ҘзЁӢпјҢproject.jsonй…ҚзҪ®й»ҳи®ӨжҳҜжІЎжңүruntimesиҠӮзӮ№зҡ„.
жҲ‘们жғіиҰҒеҸ‘еёғеҲ°йқһWindowsе№іеҸ°зҡ„ж—¶еҖҷпјҢйңҖиҰҒжүӢеҠЁй…ҚзҪ®дёҖдёӢжӯӨиҠӮзӮ№д»Ҙдҫҝз”ҹжҲҗгҖӮ
"runtimes": {
"win7-x64": {},
"win7-x86": {},
"osx.10.10-x64": {},
"osx.10.11-x64": {},
"ubuntu.14.04-x64": {}
}еҲ йҷӨ/жіЁйҮҠscriptsиҠӮзӮ№
з”ҹжҲҗж—¶дјҡи°ғз”Ёnode.jsи„ҡжң¬жһ„е»әеүҚз«Ҝд»Јз ҒпјҢиҝҷдёӘдёҚиғҪзЎ®дҝқжҜҸдёӘзҺҜеўғйғҪжңүbowerеӯҳеңЁвҖҰжіЁйҮҠе®ҢдәӢгҖӮ
//"scripts": {
// "prepublish": [ "bower install", "dotnet bundle" ],
// "postpublish": [ "dotnet publish-iis --publish-folder %publish:OutputPath% --framework %publish:FullTargetFramework%" ]
//},еҲ йҷӨ/жіЁйҮҠdependenciesиҠӮзӮ№йҮҢйқўзҡ„type
"dependencies": {
"Microsoft.NETCore.App": {
"version": "1.1.0"
//"type": "platform"
},project.jsonзҡ„зӣёе…ій…ҚзҪ®иҜҙжҳҺеҸҜд»ҘзңӢдёӢиҝҷдёӘе®ҳж–№ж–ҮжЎЈпјҡ Project.json-file ,
жҲ–иҖ…еј е–„еҸӢиҖҒеёҲзҡ„ж–Үз« .NET Coreзі»еҲ— пјҡ 2 гҖҒproject.json иҝҷи‘«иҠҰйҮҢеҚ–зҡ„д»Җд№ҲиҚҜ
ејҖеҸ‘зј–иҜ‘еҸ‘еёғ
//иҝҳеҺҹеҗ„з§ҚеҢ…ж–Ү件 dotnet restore; //еҸ‘еёғеҲ°C:\code\website\Dy2018Crawlerж–Ү件еӨ№ dotnet publish -r ubuntu.14.04-x64 -c Release -o "C:\code\website\Dy2018Crawler";
жңҖеҗҺпјҢз…§ж—§ејҖжәҗгҖӮ
дёҠиҝ°еҶ…е®№е°ұжҳҜеҰӮдҪ•дҪҝз”Ё.NET CoreеҶҷзҲ¬иҷ«зҲ¬еҸ–з”өеҪұеӨ©е ӮпјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ