您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Hadoop模式架构是怎么样的,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
一、Hadoop 1.0的模型:
|
split 0->map-[sort]->[1,3..]| /merge
| ==> reducer-->part 0=>HDFS replication
split 1->map-[sort]->[2,6..]|—————————————
| ==> reducre--->part 1 =>HDFS replication
split 2->map-[sort]->[4,2..]|
|
|
//INPUT HDFS| //output HDFS
//启动有3个map,reducer只启动了2个,sort:本地排序后发送给reducer
相同的key发送到同一个reducer
//merge:把多个数据流整合为一个数据流
工作流程:
Client--->Job--->Hadoop MapReduce master
|
|
V
/ \
Job parts Job parts
| |
VV
[Input]-- map1reduceA---->[Output]
[Data ]---map2 =》reduceB---->[Data ]
\__map3
//其中map1,2,3和reduceA,B是交叉使用的。也就是说map1可以同时对应reduceA和reduceB,其他的也都可以
//MapReduce将需要处理的任务分成两个部分,Map和Reduce
Client App
(MapReduce Client)----> Job Tracker
|
____________________|_____________________________
[task tracker1] [task tracker1] [task tracker1]
map reduce reduce reduce map map reduce map
JobTracker:有任务列表,以及状态信息
JobA---->[map task1]
JobB[map task2]
JobC[map task3]
...[reduce task 1]
[reduce task 2]
//任何一个task tracker能够运行的任务数量是有限的,可以进行定义
//任务槽:决定可以运行多少个job
Jobtracker:
1.负责任务分发
2.检查Task tracker状态,tracker故障重启等
3.监控任务的状态
Job tracker存在单点故障的问题,在hadoop2.0后这几个功能分别实现了
Mapreduce 2.0之后切割为两部分
二、HadooP 1.0 和 2.0
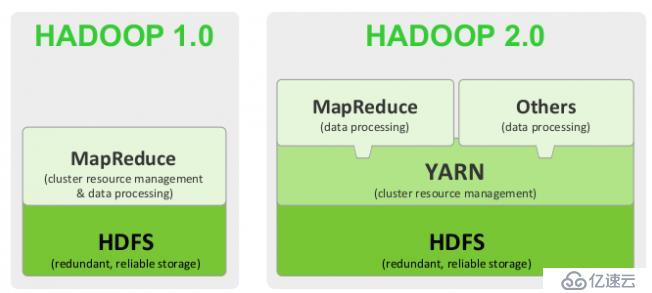
1.0: pig:data flow,Hive:sql ,
2.0: MR:batch批处理,Pig:data flow,Hive:sql
RT:stream graph:实时流式图形处理
Tez:execution engine//执行引擎
MRv1:cluster resouce manager,Data procession
MRV2:
1.YARN:Cluster resource manager
Yet Another Resource Negotiator,另一种资源协调者
2.MRv2:Data procession
MR:batch作业
Tez:execution engine //提供运行时环境
可以直接在YARN之上的程序有:
MapReduce:Batch,Tez,HBase,Streaming,Graph,SPark,HPC MPI[高性能],Weave
Hadoop2.0
clinet-->RM--->node1/node2/node n...
Resouce Manager: RM是独立的
node上运行的有[node manager+App Master+ Container]
Node manager:NM,运行在各node上,周期向RM报告node信息,
clinet请求作业:node上的Application master决定要启动几个mapper几个 reducer
mapper和reducer 称为 Container //作业都在容器内运行。
Application master只有一个,且同一个任务的APP M只在一个节点上,但是Container会分别运行在多个节点上,并周期向APP M报告其处理状态
APP M向RM报告任务运行状况,在任务执行完毕后,RM会把APP M关闭
某一个任务故障后,由App M进行管理,而不是RM管理
2.0工作模型
A 【NM/Container 1/APP M(B)】
\/
【RM】 -- 【NM/Container 2/APP M(A)】
/\
B 【NM/Container 3 /A&A 】
//任务 A运行了3个container,在两个节点上
//任务B运行了1个container,在一个节点上
Mapreduce status:container向APP M报告 //container包括map和reducer任务
Job submission:
node status:NM周期向RM报告
Resouce Request :由App M向RM申请,然后APP M就可以使用其他node 的container
client请求-->RM查找空闲node,空闲node上运行APP M-->APP M向RM申请运行container资源,RM向NM提请container,RM分配好coantainer后,告诉给APP M
APP M使用container运行任务。Container在运行过程中,不断向APP M反馈自己的状态和进度,APP M向RM报告运行状态。
APP M报告运行完成,RM收回container和关闭APP M
RM:resource manager
NM:node manager
AM:application master
container:mr任务运行
Hadoop 发展路线:
2003 nutch //蜘蛛程序
2004-2006:Mapreduce + GFS,论文
2011:hadoop 1.0.0
2013:hadoop 2.0
http://hadoop.apache.org/
可以直接在YARN之上的程序有:
MapReduce:Batch,Tez,HBase,Streaming,Graph,SPark,HPC MPI[高性能],Weave
三、Hadoop 2.0生态系统与基本组件
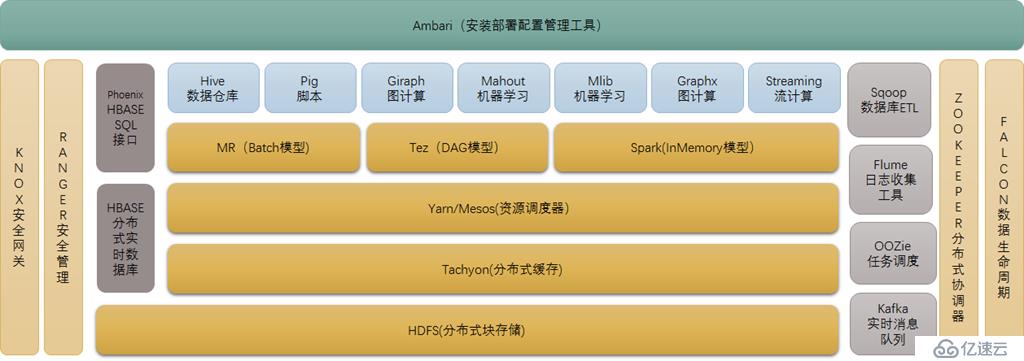
//在YARN之上是依赖于YARN的,其他的都是可以独立使用的
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。
HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
源自于google的MapReduce论文,发表于2004年12月,Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种分布式计算模型,用以进行大数据量的计算。它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分,
其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。
MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
4. HBASE(分布式列存数据库)
源自Google的Bigtable论文,发表于2006年11月,HBase是Google Bigtable克隆版
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
HBase:山寨版的BitTable,列式存储,SQL为行式存储。
列祖:把多个常用的列存放在一个中。
cell:行和列的交叉位置,每个cell在存储时,可以多版本共存,之前的版本不会被删除,可以追溯老版本。
可以指定保存几个版本。每个cell都是键值对,任何一个行多一个字段或者少一个字段,都是可以的,没有强schema约束
HBASE是工作在HDFS之上,转化为chunk的
需要用到大数据块时,读取到HBase中,进行读取和修改,然后覆盖或者写入HDFS
从而实现随机读写。HDFS是不支持随机读写的
HBase接口:
HBase基于分布式实现:需要另起一套集群,严重依赖于ZooKeeper解决脑裂
HDFS本身就有冗余功能,每个chunk存储为了多个副本
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现。
HBase以Google BigTable为蓝本,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
HBase是一个数据库,一个NoSql的数据库,像其他数据库一样提供随即读写功能,Hadoop不能满足实时需要,HBase正可以满足。
如果你需要实时访问一些数据,就把它存入HBase。
你可以用Hadoop作为静态数据仓库,HBase作为数据存储,放那些进行一些操作会改变的数据
5. Zookeeper(分布式协作服务)
源自Google的Chubby论文,发表于2006年11月,Zookeeper是Chubby克隆版
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
6. HIVE(数据仓库)小蜜蜂
由facebook开源,最初用于解决海量结构化的日志数据统计问题。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
Hive:帮忙转换成MapReduce任务//MapReduce:是bat程序,速度较慢
HQ与SQl语句接近,适合在离线下进行数据的操作,在真实的生产环境中进行实时的在线查询或操作很“慢”
Hive在Hadoop中扮演数据仓库的角色。
你可以用 HiveQL进行select,join,等等操作。
如果你有数据仓库的需求并且你擅长写SQL并且不想写MapReduce jobs就可以用Hive代替。
熟悉SQL的朋友可以使用Hive对离线的进行数据处理与分析工作
7.Pig(ad-hoc脚本)
由yahoo!开源,设计动机是提供一种基于MapReduce的ad-hoc(计算在query时发生)数据分析工具
Pig定义了一种数据流语言—Pig Latin,它是MapReduce编程的复杂性的抽象,Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。
其编译器将Pig Latin翻译成MapReduce程序序列将脚本转换为MapReduce任务在Hadoop上执行。通常用于进行离线分析。
Pig:脚本编程语言接口 一种操作hadoop的轻量级脚本语言,最初又雅虎公司推出,不过现在正在走下坡路了。
不过个人推荐使用Hive
8.Sqoop(数据ETL/同步工具)
Sqoop是SQL-to-Hadoop的缩写,主要用于传统数据库和Hadoop之前传输数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据。
9.Flume(日志收集工具)
Cloudera开源的日志收集系统,具有分布式、高可靠、高容错、易于定制和扩展的特点。
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。
总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。当然也可以用于收集其他类型数据
Mahout起源于2008年,最初是Apache Lucent的子项目,它在极短的时间内取得了长足的发展,现在是Apache的顶级项目。
Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
Mahout现在已经包含了聚类、分类、推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。
除了算法,Mahout还包含数据的输入/输出工具、与其他存储系统(如数据库、MongoDB 或Cassandra)集成等数据挖掘支持架构。
11. Oozie(工作流调度器)
Oozie是一个可扩展的工作体系,集成于Hadoop的堆栈,用于协调多个MapReduce作业的执行。它能够管理一个复杂的系统,基于外部事件来执行,外部事件包括数据的定时和数据的出现。
Oozie工作流是放置在控制依赖DAG(有向无环图 Direct Acyclic Graph)中的一组动作(例如,Hadoop的Map/Reduce作业、Pig作业等),其中指定了动作执行的顺序。
Oozie使用hPDL(一种XML流程定义语言)来描述这个图。
12. Yarn(分布式资源管理器)
- 资源管理:包括应用程序管理和机器资源管理
- 资源双层调度
- 容错性:各个组件均有考虑容错性
- 扩展性:可扩展到上万个节点
13. Mesos(分布式资源管理器)
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache项目,当前有一些公司使用Mesos管理集群资源,比如Twitter。
与yarn类似,Mesos是一个资源统一管理和调度的平台,同样支持比如MR、steaming等多种运算框架。
14. Tachyon(分布式内存文件系统)
Tachyon(/'tki:n/ 意为超光速粒子)是以内存为中心的分布式文件系统,拥有高性能和容错能力,
能够为集群框架(如Spark、MapReduce)提供可靠的内存级速度的文件共享服务。
Tachyon诞生于UC Berkeley的AMPLab。
15. Tez(DAG计算模型)
Tez是Apache最新开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,
即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,
这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。
目前hive支持mr、tez计算模型,tez能完美二进制mr程序,提升运算性能。
16. Spark(内存DAG计算模型)
Spark是一个Apache项目,它被标榜为“快如闪电的集群计算”。它拥有一个繁荣的开源社区,并且是目前最活跃的Apache项目。
最早Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架。
Spark提供了一个更快、更通用的数据处理平台。和Hadoop相比,Spark可以让你的程序在内存中运行时速度提升100倍,或者在磁盘上运行时速度提升10倍
17. Giraph(图计算模型)
Apache Giraph是一个可伸缩的分布式迭代图处理系统, 基于Hadoop平台,灵感来自 BSP (bulk synchronous parallel) 和 Google 的 Pregel。
最早出自雅虎。雅虎在开发Giraph时采用了Google工程师2010年发表的论文《Pregel:大规模图表处理系统》中的原理。后来,雅虎将Giraph捐赠给Apache软件基金会。
目前所有人都可以下载Giraph,它已经成为Apache软件基金会的开源项目,并得到Facebook的支持,获得多方面的改进。
18. GraphX(图计算模型)
Spark GraphX最先是伯克利AMPLAB的一个分布式图计算框架项目,目前整合在spark运行框架中,为其提供BSP大规模并行图计算能力。
19. MLib(机器学习库)
Spark MLlib是一个机器学习库,它提供了各种各样的算法,这些算法用来在集群上针对分类、回归、聚类、协同过滤等。
20. Streaming(流计算模型)
Spark Streaming支持对流数据的实时处理,以微批的方式对实时数据进行计算
21. Kafka(分布式消息队列)
Kafka是Linkedin于2010年12月份开源的消息系统,它主要用于处理活跃的流式数据。
活跃的流式数据在web网站应用中非常常见,这些数据包括网站的pv、用户访问了什么内容,搜索了什么内容等。
这些数据通常以日志的形式记录下来,然后每隔一段时间进行一次统计处理。
22. Phoenix(hbase sql接口)
Apache Phoenix 是HBase的SQL驱动,Phoenix 使得Hbase 支持通过JDBC的方式进行访问,并将你的SQL查询转换成Hbase的扫描和相应的动作。
23. ranger(安全管理工具)
Apache ranger是一个hadoop集群权限框架,提供操作、监控、管理复杂的数据权限,它提供一个集中的管理机制,管理基于yarn的hadoop生态圈的所有数据权限。
24. knox(hadoop安全网关)
Apache knox是一个访问hadoop集群的restapi网关,它为所有rest访问提供了一个简单的访问接口点,能完成3A认证(Authentication,Authorization,Auditing)和SSO(单点登录)等
25. falcon(数据生命周期管理工具)
Apache Falcon 是一个面向Hadoop的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。它使终端用户可以快速地将他们的数据及其相关的处理和管理任务“上载(onboard)”到Hadoop集群。
26.Ambari(安装部署配置管理工具)
Apache Ambari 的作用来说,就是创建、管理、监视 Hadoop 的集群,是为了让 Hadoop 以及相关的大数据软件更容易使用的一个web工具。
注意:Hadoop尽量不要运行在虚拟机上,因为对IO影响比较大
Hadoop Distribution:
社区版:Apache Hadoop
第三方发行版:
Cloudera:hadoop源创始人:CDH //iso镜像,最成型的
Hortonworks:原有的hadoop人员:HDP //iso镜像,非开源
Intel:IDH
MapR:
Amazon Elastic Map Reduce(EMR)
推荐使用Apache hadoop或者CDH
以上是“Hadoop模式架构是怎么样的”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。