жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңHadoopжһ¶жһ„еҺҹзҗҶжҖҺд№ҲзҗҶи§ЈвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңHadoopжһ¶жһ„еҺҹзҗҶжҖҺд№ҲзҗҶи§ЈвҖқеҗ§!
дёҖгҖҒжҰӮеҝө
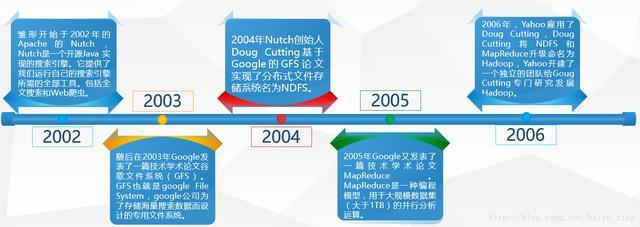
HadoopиҜһз”ҹдәҺ2006е№ҙпјҢжҳҜдёҖж¬ҫж”ҜжҢҒж•°жҚ®еҜҶйӣҶеһӢеҲҶеёғејҸеә”用并д»ҘApache 2.0и®ёеҸҜеҚҸи®®еҸ‘еёғзҡ„ејҖжәҗиҪҜ件жЎҶжһ¶гҖӮе®ғж”ҜжҢҒеңЁе•Ҷе“Ғ硬件жһ„е»әзҡ„еӨ§еһӢйӣҶзҫӨдёҠиҝҗиЎҢзҡ„еә”з”ЁзЁӢеәҸгҖӮHadoopжҳҜж №жҚ®Googleе…¬еҸёеҸ‘иЎЁзҡ„MapReduceе’ҢGoogleжЎЈжЎҲзі»з»ҹзҡ„и®әж–ҮиҮӘиЎҢе®һдҪңиҖҢжҲҗгҖӮ
HadoopдёҺGoogleдёҖж ·пјҢйғҪжҳҜе°Ҹеӯ©е‘ҪеҗҚзҡ„пјҢжҳҜдёҖдёӘиҷҡжһ„зҡ„еҗҚеӯ—пјҢжІЎжңүзү№еҲ«зҡ„еҗ«д№үгҖӮд»Һи®Ўз®—жңәдё“дёҡзҡ„и§’еәҰзңӢпјҢHadoopжҳҜдёҖдёӘеҲҶеёғејҸзі»з»ҹеҹәзЎҖжһ¶жһ„пјҢз”ұApacheеҹәйҮ‘дјҡејҖеҸ‘гҖӮHadoopзҡ„дё»иҰҒзӣ®ж ҮжҳҜеҜ№еҲҶеёғејҸзҺҜеўғдёӢзҡ„вҖңеӨ§ж•°жҚ®вҖқд»ҘдёҖз§ҚеҸҜйқ гҖҒй«ҳж•ҲгҖҒеҸҜдјёзј©зҡ„ж–№ејҸеӨ„зҗҶгҖӮ
HadoopжЎҶжһ¶йҖҸжҳҺең°дёәеә”з”ЁжҸҗдҫӣеҸҜйқ жҖ§е’Ңж•°жҚ®з§»еҠЁгҖӮе®ғе®һзҺ°дәҶеҗҚдёәMapReduceзҡ„зј–зЁӢиҢғејҸпјҡеә”з”ЁзЁӢеәҸиў«еҲҶеүІжҲҗи®ёеӨҡе°ҸйғЁеҲҶпјҢиҖҢжҜҸдёӘйғЁеҲҶйғҪиғҪеңЁйӣҶзҫӨдёӯзҡ„д»»ж„ҸиҠӮзӮ№дёҠжү§иЎҢжҲ–йҮҚж–°жү§иЎҢгҖӮ
HadoopиҝҳжҸҗдҫӣдәҶеҲҶеёғејҸж–Ү件系з»ҹпјҢз”Ёд»ҘеӯҳеӮЁжүҖжңүи®Ўз®—иҠӮзӮ№зҡ„ж•°жҚ®пјҢиҝҷдёәж•ҙдёӘйӣҶзҫӨеёҰжқҘдәҶйқһеёёй«ҳзҡ„еёҰе®ҪгҖӮMapReduceе’ҢеҲҶеёғејҸж–Ү件系з»ҹзҡ„и®ҫи®ЎпјҢдҪҝеҫ—ж•ҙдёӘжЎҶжһ¶иғҪеӨҹиҮӘеҠЁеӨ„зҗҶиҠӮзӮ№ж•…йҡңгҖӮе®ғдҪҝеә”з”ЁзЁӢеәҸдёҺжҲҗеҚғдёҠдёҮзҡ„зӢ¬з«Ӣи®Ўз®—зҡ„з”өи„‘е’ҢPBзә§зҡ„ж•°жҚ®гҖӮ
дәҢгҖҒз»„жҲҗ
1.Hadoopзҡ„ж ёеҝғ组件
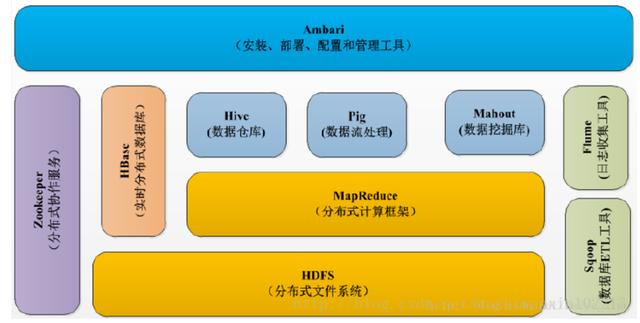
еҲҶжһҗпјҡHadoopзҡ„ж ёеҝғ组件еҲҶдёәпјҡHDFS(еҲҶеёғејҸж–Ү件系з»ҹ)гҖҒMapRuduce(еҲҶеёғејҸиҝҗз®—зј–зЁӢжЎҶжһ¶)гҖҒYARN(иҝҗз®—иө„жәҗи°ғеәҰзі»з»ҹ)
2.HDFSзҡ„ж–Ү件系з»ҹ
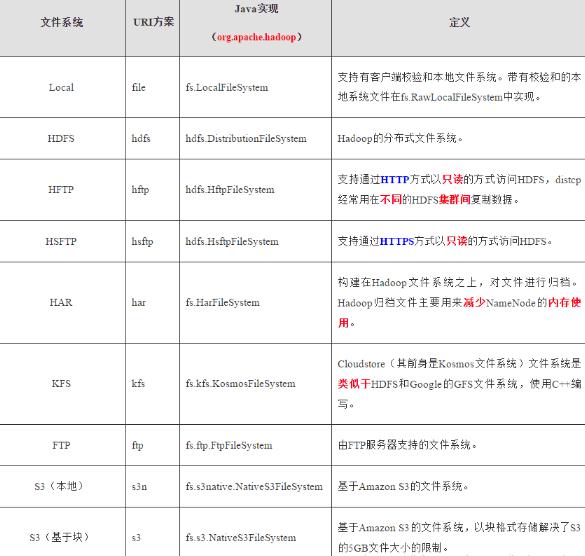
HDFS
1.е®ҡд№ү
ж•ҙдёӘHadoopзҡ„дҪ“зі»з»“жһ„дё»иҰҒжҳҜйҖҡиҝҮHDFS(HadoopеҲҶеёғејҸж–Ү件系з»ҹ)жқҘе®һзҺ°еҜ№еҲҶеёғејҸеӯҳеӮЁзҡ„еә•еұӮж”ҜжҢҒпјҢ并йҖҡиҝҮMRжқҘе®һзҺ°еҜ№еҲҶеёғејҸ并иЎҢд»»еҠЎеӨ„зҗҶзҡ„зЁӢеәҸж”ҜжҢҒгҖӮ
HDFSжҳҜHadoopдҪ“зі»дёӯж•°жҚ®еӯҳеӮЁз®ЎзҗҶзҡ„еҹәзЎҖгҖӮе®ғжҳҜдёҖдёӘй«ҳеәҰе®№й”ҷзҡ„зі»з»ҹпјҢиғҪжЈҖжөӢе’Ңеә”еҜ№зЎ¬д»¶ж•…йҡңпјҢз”ЁдәҺеңЁдҪҺжҲҗжң¬зҡ„йҖҡ用硬件дёҠиҝҗиЎҢгҖӮHDFSз®ҖеҢ–дәҶж–Ү件зҡ„дёҖиҮҙжҖ§жЁЎеһӢпјҢйҖҡиҝҮжөҒејҸж•°жҚ®и®ҝй—®пјҢжҸҗдҫӣй«ҳеҗһеҗҗйҮҸеә”з”ЁзЁӢеәҸж•°жҚ®и®ҝй—®еҠҹиғҪпјҢйҖӮеҗҲеёҰжңүеӨ§еһӢж•°жҚ®йӣҶзҡ„еә”з”ЁзЁӢеәҸгҖӮ
2.з»„жҲҗ
HDFSйҮҮз”Ёдё»д»Һ(Master/Slave)з»“жһ„жЁЎеһӢпјҢдёҖдёӘHDFSйӣҶзҫӨжҳҜз”ұдёҖдёӘNameNodeе’ҢиӢҘе№ІдёӘDataNodeз»„жҲҗзҡ„гҖӮNameNodeдҪңдёәдё»жңҚеҠЎеҷЁпјҢз®ЎзҗҶж–Ү件系з»ҹе‘ҪеҗҚз©әй—ҙе’Ңе®ўжҲ·з«ҜеҜ№ж–Ү件зҡ„и®ҝй—®ж“ҚдҪңгҖӮDataNodeз®ЎзҗҶеӯҳеӮЁзҡ„ж•°жҚ®гҖӮHDFSж”ҜжҢҒж–Ү件еҪўејҸзҡ„ж•°жҚ®гҖӮ
д»ҺеҶ…йғЁжқҘзңӢпјҢж–Ү件被еҲҶжҲҗиӢҘе№ІдёӘж•°жҚ®еқ—пјҢиҝҷиӢҘе№ІдёӘж•°жҚ®еқ—еӯҳж”ҫеңЁдёҖз»„DataNodeдёҠгҖӮNameNodeжү§иЎҢж–Ү件系з»ҹзҡ„е‘ҪеҗҚз©әй—ҙпјҢеҰӮжү“ејҖгҖҒе…ій—ӯгҖҒйҮҚе‘ҪеҗҚж–Ү件жҲ–зӣ®еҪ•зӯүпјҢд№ҹиҙҹиҙЈж•°жҚ®еқ—еҲ°е…·дҪ“DataNodeзҡ„жҳ е°„гҖӮDataNodeиҙҹиҙЈеӨ„зҗҶж–Ү件系з»ҹе®ўжҲ·з«Ҝзҡ„ж–Ү件иҜ»еҶҷпјҢ并еңЁNameNodeзҡ„з»ҹдёҖи°ғеәҰдёӢиҝӣиЎҢж•°жҚ®еә“зҡ„еҲӣе»әгҖҒеҲ йҷӨе’ҢеӨҚеҲ¶е·ҘдҪңгҖӮNameNodeжҳҜжүҖжңүHDFSе…ғж•°жҚ®зҡ„з®ЎзҗҶиҖ…пјҢз”ЁжҲ·ж•°жҚ®ж°ёиҝңдёҚдјҡз»ҸиҝҮNameNodeгҖӮ
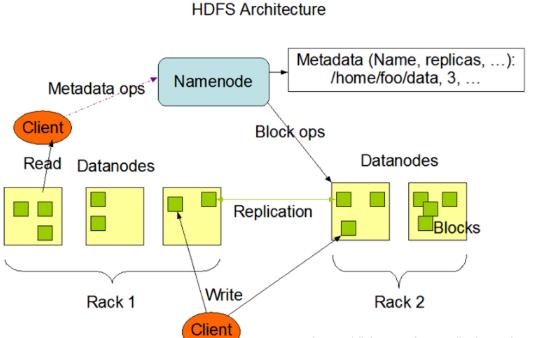
еҲҶжһҗпјҡNameNodeжҳҜз®ЎзҗҶиҖ…пјҢDataNodeжҳҜж–Ү件еӯҳеӮЁиҖ…гҖҒClientжҳҜйңҖиҰҒиҺ·еҸ–еҲҶеёғејҸж–Ү件系з»ҹзҡ„еә”з”ЁзЁӢеәҸгҖӮ
MapReduce
1.е®ҡд№ү
Hadoop MapReduceжҳҜgoogle MapReduce е…ӢйҡҶзүҲгҖӮ
MapReduceжҳҜдёҖз§Қи®Ўз®—жЁЎеһӢпјҢз”Ёд»ҘиҝӣиЎҢеӨ§ж•°жҚ®йҮҸзҡ„и®Ўз®—гҖӮе…¶дёӯMapеҜ№ж•°жҚ®йӣҶдёҠзҡ„зӢ¬з«Ӣе…ғзҙ иҝӣиЎҢжҢҮе®ҡзҡ„ж“ҚдҪңпјҢз”ҹжҲҗй”®-еҖјеҜ№еҪўејҸдёӯй—ҙз»“жһңгҖӮReduceеҲҷеҜ№дёӯй—ҙз»“жһңдёӯзӣёеҗҢвҖңй”®вҖқзҡ„жүҖжңүвҖңеҖјвҖқиҝӣиЎҢ规зәҰпјҢд»Ҙеҫ—еҲ°жңҖз»Ҳз»“жһңгҖӮMapReduceиҝҷж ·зҡ„еҠҹиғҪеҲ’еҲҶпјҢйқһеёёйҖӮеҗҲеңЁеӨ§йҮҸи®Ўз®—жңәз»„жҲҗзҡ„еҲҶеёғејҸ并иЎҢзҺҜеўғйҮҢиҝӣиЎҢж•°жҚ®еӨ„зҗҶгҖӮ
2.з»„жҲҗ
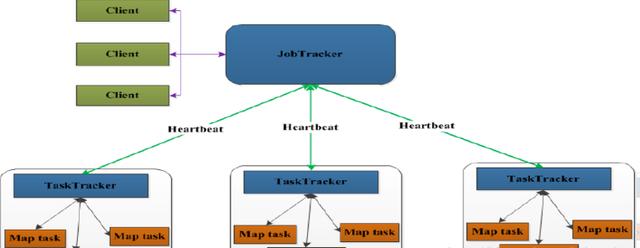
еҲҶжһҗпјҡ
(1)JobTracker
JobTrackerеҸ«дҪңдёҡи·ҹиёӘеҷЁпјҢиҝҗиЎҢеҲ°дё»иҠӮзӮ№(Namenode)дёҠзҡ„дёҖдёӘеҫҲйҮҚиҰҒзҡ„иҝӣзЁӢпјҢжҳҜMapReduceдҪ“зі»зҡ„и°ғеәҰеҷЁгҖӮз”ЁдәҺеӨ„зҗҶдҪңдёҡ(з”ЁжҲ·жҸҗдәӨзҡ„д»Јз Ғ)зҡ„еҗҺеҸ°зЁӢеәҸпјҢеҶіе®ҡжңүе“Әдәӣж–Ү件еҸӮдёҺдҪңдёҡзҡ„еӨ„зҗҶпјҢ然еҗҺжҠҠдҪңдёҡеҲҮеүІжҲҗдёәдёҖдёӘдёӘзҡ„е°ҸtaskпјҢ并жҠҠе®ғ们еҲҶй…ҚеҲ°жүҖйңҖиҰҒзҡ„ж•°жҚ®жүҖеңЁзҡ„еӯҗиҠӮзӮ№гҖӮ
Hadoopзҡ„еҺҹеҲҷе°ұжҳҜе°ұиҝ‘иҝҗиЎҢпјҢж•°жҚ®е’ҢзЁӢеәҸиҰҒеңЁеҗҢдёҖдёӘзү©зҗҶиҠӮзӮ№йҮҢпјҢж•°жҚ®еңЁе“ӘйҮҢпјҢзЁӢеәҸе°ұи·‘еҺ»е“ӘйҮҢиҝҗиЎҢгҖӮиҝҷдёӘе·ҘдҪңжҳҜJobTrackerеҒҡзҡ„пјҢзӣ‘жҺ§taskпјҢиҝҳдјҡйҮҚеҗҜеӨұиҙҘзҡ„task(дәҺдёҚеҗҢзҡ„иҠӮзӮ№)пјҢжҜҸдёӘйӣҶзҫӨеҸӘжңүе”ҜдёҖдёҖдёӘJobTrackerпјҢзұ»дјјеҚ•зӮ№зҡ„NameNodeпјҢдҪҚдәҺMasterиҠӮзӮ№
(2)TaskTracker
TaskTrackerеҸ«д»»еҠЎи·ҹиёӘеҷЁпјҢMapReduceдҪ“зі»зҡ„жңҖеҗҺдёҖдёӘеҗҺеҸ°иҝӣзЁӢпјҢдҪҚдәҺжҜҸдёӘslaveиҠӮзӮ№дёҠпјҢдёҺdatanodeз»“еҗҲ(д»Јз ҒдёҺж•°жҚ®дёҖиө·зҡ„еҺҹеҲҷ)пјҢз®ЎзҗҶеҗ„иҮӘиҠӮзӮ№дёҠзҡ„task(з”ұjobtrackerеҲҶй…Қ)пјҢ
жҜҸдёӘиҠӮзӮ№еҸӘжңүдёҖдёӘtasktrackerпјҢдҪҶдёҖдёӘtasktrackerеҸҜд»ҘеҗҜеҠЁеӨҡдёӘJVMпјҢиҝҗиЎҢMap Taskе’ҢReduce Task;并дёҺJobTrackerдәӨдә’пјҢжұҮжҠҘд»»еҠЎзҠ¶жҖҒпјҢ
Map Taskпјҡи§ЈжһҗжҜҸжқЎж•°жҚ®и®°еҪ•пјҢдј йҖ’з»ҷз”ЁжҲ·зј–еҶҷзҡ„map(),并жү§иЎҢпјҢе°Ҷиҫ“еҮәз»“жһңеҶҷе…Ҙжң¬ең°зЈҒзӣҳ(еҰӮжһңдёәmap-onlyдҪңдёҡпјҢзӣҙжҺҘеҶҷе…ҘHDFS)гҖӮ
Reducer Taskпјҡд»ҺMap Taskзҡ„жү§иЎҢз»“жһңдёӯпјҢиҝңзЁӢиҜ»еҸ–иҫ“е…Ҙж•°жҚ®пјҢеҜ№ж•°жҚ®иҝӣиЎҢжҺ’еәҸпјҢе°Ҷж•°жҚ®жҢүз…§еҲҶз»„дј йҖ’з»ҷз”ЁжҲ·зј–еҶҷзҡ„reduceеҮҪж•°жү§иЎҢгҖӮ
Hive
1.е®ҡд№ү
HiveжҳҜеҹәдәҺHadoopзҡ„дёҖдёӘж•°жҚ®д»“еә“е·Ҙе…·пјҢеҸҜд»Ҙе°Ҷз»“жһ„еҢ–зҡ„ж•°жҚ®ж–Ү件жҳ е°„дёәдёҖеј ж•°жҚ®еә“иЎЁпјҢ并жҸҗдҫӣе®Ңж•ҙзҡ„sqlжҹҘиҜўеҠҹиғҪпјҢеҸҜд»Ҙе°ҶsqlиҜӯеҸҘиҪ¬жҚўдёәMapReduceд»»еҠЎиҝӣиЎҢиҝҗиЎҢгҖӮ
HiveжҳҜе»әз«ӢеңЁ Hadoop дёҠзҡ„ж•°жҚ®д»“еә“еҹәзЎҖжһ„жһ¶гҖӮе®ғжҸҗдҫӣдәҶдёҖзі»еҲ—зҡ„е·Ҙе…·пјҢеҸҜд»Ҙз”ЁжқҘиҝӣиЎҢж•°жҚ®жҸҗеҸ–иҪ¬еҢ–еҠ иҪҪ(ETL)пјҢиҝҷжҳҜдёҖз§ҚеҸҜд»ҘеӯҳеӮЁгҖҒжҹҘиҜўе’ҢеҲҶжһҗеӯҳеӮЁеңЁ Hadoop дёӯзҡ„еӨ§и§„жЁЎж•°жҚ®зҡ„жңәеҲ¶гҖӮ
Hive е®ҡд№үдәҶз®ҖеҚ•зҡ„зұ» SQL жҹҘиҜўиҜӯиЁҖпјҢз§°дёә HQLпјҢе®ғе…Ғи®ёзҶҹжӮү SQL зҡ„з”ЁжҲ·жҹҘиҜўж•°жҚ®гҖӮеҗҢж—¶пјҢиҝҷдёӘиҜӯиЁҖд№ҹе…Ғи®ёзҶҹжӮү MapReduce ејҖеҸ‘иҖ…зҡ„ејҖеҸ‘иҮӘе®ҡд№үзҡ„ mapper е’Ң reducer жқҘеӨ„зҗҶеҶ…е»әзҡ„ mapper е’Ң reducer ж— жі•е®ҢжҲҗзҡ„еӨҚжқӮзҡ„еҲҶжһҗе·ҘдҪңгҖӮ
2.з»„жҲҗ
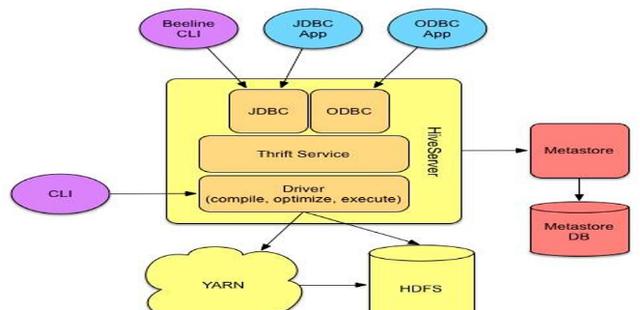
еҲҶжһҗпјҡHiveжһ¶жһ„еҢ…жӢ¬пјҡCLI(Command Line Interface)гҖҒJDBC/ODBCгҖҒThrift ServerгҖҒWEB GUIгҖҒMetastoreе’ҢDriver(ComplierгҖҒOptimizerе’ҢExecutor)пјҢиҝҷдәӣ组件еҲҶдёәдёӨеӨ§зұ»пјҡжңҚеҠЎз«Ҝ组件е’Ңе®ўжҲ·з«Ҝ组件
3.е®ўжҲ·з«ҜдёҺжңҚеҠЎз«Ҝ组件
(1)е®ўжҲ·з«Ҝ组件пјҡ
CLIпјҡCommand Line InterfaceпјҢе‘Ҫд»ӨиЎҢжҺҘеҸЈгҖӮ
Thriftе®ўжҲ·з«ҜпјҡдёҠйқўзҡ„жһ¶жһ„еӣҫйҮҢжІЎжңүеҶҷдёҠThriftе®ўжҲ·з«ҜпјҢдҪҶжҳҜHiveжһ¶жһ„зҡ„и®ёеӨҡе®ўжҲ·з«ҜжҺҘеҸЈжҳҜе»әз«ӢеңЁThriftе®ўжҲ·з«Ҝд№ӢдёҠпјҢеҢ…жӢ¬JDBCе’ҢODBCжҺҘеҸЈгҖӮ
WEBGUIпјҡHiveе®ўжҲ·з«ҜжҸҗдҫӣдәҶдёҖз§ҚйҖҡиҝҮзҪ‘йЎөзҡ„ж–№ејҸи®ҝй—®HiveжүҖжҸҗдҫӣзҡ„жңҚеҠЎгҖӮиҝҷдёӘжҺҘеҸЈеҜ№еә”Hiveзҡ„HWI组件(Hive Web Interface)пјҢдҪҝз”ЁеүҚиҰҒеҗҜеҠЁHWIжңҚеҠЎгҖӮ
(2)жңҚеҠЎз«Ҝ组件пјҡ
Driver组件пјҡиҜҘ组件еҢ…жӢ¬ComplierгҖҒOptimizerе’ҢExecutorпјҢе®ғзҡ„дҪңз”ЁжҳҜе°ҶHiveQL(зұ»SQL)иҜӯеҸҘиҝӣиЎҢи§ЈжһҗгҖҒзј–иҜ‘дјҳеҢ–пјҢз”ҹжҲҗжү§иЎҢи®ЎеҲ’пјҢ然еҗҺи°ғз”Ёеә•еұӮзҡ„MapReduceи®Ўз®—жЎҶжһ¶
Metastore组件пјҡе…ғж•°жҚ®жңҚеҠЎз»„件пјҢиҝҷдёӘ组件еӯҳеӮЁHiveзҡ„е…ғж•°жҚ®пјҢHiveзҡ„е…ғж•°жҚ®еӯҳеӮЁеңЁе…ізі»ж•°жҚ®еә“йҮҢпјҢHiveж”ҜжҢҒзҡ„е…ізі»ж•°жҚ®еә“жңүDerbyе’ҢMysqlгҖӮе…ғж•°жҚ®еҜ№дәҺHiveеҚҒеҲҶйҮҚиҰҒпјҢеӣ жӯӨHiveж”ҜжҢҒжҠҠMetastoreжңҚеҠЎзӢ¬з«ӢеҮәжқҘпјҢе®үиЈ…еҲ°иҝңзЁӢзҡ„жңҚеҠЎеҷЁйӣҶзҫӨйҮҢпјҢд»ҺиҖҢи§ЈиҖҰHiveжңҚеҠЎе’ҢMetastoreжңҚеҠЎпјҢдҝқиҜҒHiveиҝҗиЎҢзҡ„еҒҘеЈ®жҖ§;
ThriftжңҚеҠЎпјҡThriftжҳҜFacebookејҖеҸ‘зҡ„дёҖдёӘиҪҜ件жЎҶжһ¶пјҢе®ғз”ЁжқҘиҝӣиЎҢеҸҜжү©еұ•дё”и·ЁиҜӯиЁҖзҡ„жңҚеҠЎзҡ„ејҖеҸ‘пјҢHiveйӣҶжҲҗдәҶиҜҘжңҚеҠЎпјҢиғҪи®©дёҚеҗҢзҡ„зј–зЁӢиҜӯиЁҖи°ғз”ЁHiveзҡ„жҺҘеҸЈгҖӮ
4.HiveдёҺдј з»ҹж•°жҚ®еә“зҡ„ејӮеҗҢ
(1)жҹҘиҜўиҜӯиЁҖ
з”ұдәҺ SQL иў«е№ҝжіӣзҡ„еә”з”ЁеңЁж•°жҚ®д»“еә“дёӯпјҢеӣ жӯӨдё“й—Ёй’ҲеҜ№Hiveзҡ„зү№жҖ§и®ҫи®ЎдәҶзұ»SQLзҡ„жҹҘиҜўиҜӯиЁҖHQLгҖӮзҶҹжӮүSQLејҖеҸ‘зҡ„ејҖеҸ‘иҖ…еҸҜд»ҘеҫҲж–№дҫҝзҡ„дҪҝз”ЁHiveиҝӣиЎҢејҖеҸ‘гҖӮ
(2)ж•°жҚ®еӯҳеӮЁдҪҚзҪ®
HiveжҳҜе»әз«ӢеңЁHadoopд№ӢдёҠзҡ„пјҢжүҖжңүHiveзҡ„ж•°жҚ®йғҪжҳҜеӯҳеӮЁеңЁHDFSдёӯзҡ„гҖӮиҖҢж•°жҚ®еә“еҲҷеҸҜд»Ҙе°Ҷж•°жҚ®дҝқеӯҳеңЁеқ—и®ҫеӨҮжҲ–иҖ…жң¬ең°ж–Ү件系з»ҹдёӯгҖӮ
(3)ж•°жҚ®ж јејҸ
HiveдёӯжІЎжңүе®ҡд№үдё“й—Ёзҡ„ж•°жҚ®ж јејҸпјҢж•°жҚ®ж јејҸеҸҜд»Ҙз”ұз”ЁжҲ·жҢҮе®ҡпјҢз”ЁжҲ·е®ҡд№үж•°жҚ®ж јејҸйңҖиҰҒжҢҮе®ҡдёүдёӘеұһжҖ§пјҡеҲ—еҲҶйҡ”з¬Ұ(йҖҡеёёдёәз©әж јгҖҒвҖқ\tвҖқгҖҒвҖқ\\x001″)гҖҒиЎҢеҲҶйҡ”з¬Ұ(вҖқ\nвҖқ)д»ҘеҸҠиҜ»еҸ–ж–Ү件数жҚ®зҡ„ж–№жі•(Hiveдёӯй»ҳи®ӨжңүдёүдёӘж–Үд»¶ж јејҸTextFileпјҢSequenceFileд»ҘеҸҠRCFile)гҖӮ
(4)ж•°жҚ®жӣҙж–°
з”ұдәҺHiveжҳҜй’ҲеҜ№ж•°жҚ®д»“еә“еә”з”Ёи®ҫи®Ўзҡ„пјҢиҖҢж•°жҚ®д»“еә“зҡ„еҶ…е®№жҳҜиҜ»еӨҡеҶҷе°‘зҡ„гҖӮеӣ жӯӨпјҢHiveдёӯдёҚж”ҜжҢҒ
еҜ№ж•°жҚ®зҡ„ж”№еҶҷе’Ңж·»еҠ пјҢжүҖжңүзҡ„ж•°жҚ®йғҪжҳҜеңЁеҠ иҪҪзҡ„ж—¶еҖҷдёӯзЎ®е®ҡеҘҪзҡ„гҖӮиҖҢж•°жҚ®еә“дёӯзҡ„ж•°жҚ®йҖҡеёёжҳҜйңҖиҰҒз»ҸеёёиҝӣиЎҢдҝ®ж”№зҡ„пјҢеӣ жӯӨеҸҜд»ҘдҪҝз”ЁINSERT INTO … VALUESж·»еҠ ж•°жҚ®пјҢдҪҝз”ЁUPDATE … SETдҝ®ж”№ж•°жҚ®гҖӮ
(5)зҙўеј•
HiveеңЁеҠ иҪҪж•°жҚ®зҡ„иҝҮзЁӢдёӯдёҚдјҡеҜ№ж•°жҚ®иҝӣиЎҢд»»дҪ•еӨ„зҗҶпјҢз”ҡиҮідёҚдјҡеҜ№ж•°жҚ®иҝӣиЎҢжү«жҸҸпјҢеӣ жӯӨд№ҹжІЎжңүеҜ№ж•°жҚ®дёӯзҡ„жҹҗдәӣKeyе»әз«Ӣзҙўеј•гҖӮHiveиҰҒи®ҝй—®ж•°жҚ®дёӯж»Ўи¶іжқЎд»¶зҡ„зү№е®ҡеҖјж—¶пјҢйңҖиҰҒжҡҙеҠӣжү«жҸҸж•ҙдёӘж•°жҚ®пјҢеӣ жӯӨи®ҝ问延иҝҹиҫғй«ҳгҖӮз”ұдәҺMapReduceзҡ„еј•е…ҘпјҢ HiveеҸҜд»Ҙ并иЎҢи®ҝй—®ж•°жҚ®пјҢеӣ жӯӨеҚідҪҝжІЎжңүзҙўеј•пјҢеҜ№дәҺеӨ§ж•°жҚ®йҮҸзҡ„и®ҝй—®пјҢHiveд»Қ然еҸҜд»ҘдҪ“зҺ°еҮәдјҳеҠҝгҖӮж•°жҚ®еә“дёӯпјҢйҖҡеёёдјҡй’ҲеҜ№дёҖдёӘжҲ–иҖ…еҮ дёӘеҲ—е»әз«Ӣзҙўеј•пјҢеӣ жӯӨеҜ№дәҺе°‘йҮҸзҡ„зү№е®ҡжқЎд»¶зҡ„ж•°жҚ®зҡ„и®ҝй—®пјҢж•°жҚ®еә“еҸҜд»ҘжңүеҫҲй«ҳзҡ„ж•ҲзҺҮпјҢиҫғдҪҺзҡ„延иҝҹгҖӮз”ұдәҺж•°жҚ®зҡ„и®ҝ问延иҝҹиҫғй«ҳпјҢеҶіе®ҡдәҶHiveдёҚйҖӮеҗҲеңЁзәҝж•°жҚ®жҹҘиҜўгҖӮ
(6)жү§иЎҢ
HiveдёӯеӨ§еӨҡж•°жҹҘиҜўзҡ„жү§иЎҢжҳҜйҖҡиҝҮHadoopжҸҗдҫӣзҡ„MapReduceжқҘе®һзҺ°зҡ„(зұ»дјјselect * from tblзҡ„жҹҘиҜўдёҚйңҖиҰҒMapReduce)гҖӮиҖҢж•°жҚ®еә“йҖҡеёёжңүиҮӘе·ұзҡ„жү§иЎҢеј•ж“ҺгҖӮ
(7)жү§иЎҢ延иҝҹ
HiveеңЁжҹҘиҜўж•°жҚ®зҡ„ж—¶еҖҷпјҢз”ұдәҺжІЎжңүзҙўеј•пјҢйңҖиҰҒжү«жҸҸж•ҙдёӘиЎЁпјҢеӣ жӯӨ延иҝҹиҫғй«ҳгҖӮеҸҰеӨ–дёҖдёӘеҜјиҮҙHiveжү§иЎҢ延иҝҹй«ҳзҡ„еӣ зҙ жҳҜMapReduceжЎҶжһ¶гҖӮз”ұдәҺMapReduceжң¬иә«е…·жңүиҫғй«ҳзҡ„延иҝҹпјҢеӣ жӯӨеңЁеҲ©з”ЁMapReduceжү§иЎҢHiveжҹҘиҜўж—¶пјҢд№ҹдјҡжңүиҫғй«ҳзҡ„延иҝҹгҖӮзӣёеҜ№зҡ„пјҢж•°жҚ®еә“зҡ„жү§иЎҢ延иҝҹиҫғдҪҺгҖӮеҪ“然пјҢиҝҷдёӘдҪҺжҳҜжңүжқЎд»¶зҡ„пјҢеҚіж•°жҚ®и§„жЁЎиҫғе°ҸпјҢеҪ“ж•°жҚ®и§„жЁЎеӨ§еҲ°и¶…иҝҮж•°жҚ®еә“зҡ„еӨ„зҗҶиғҪеҠӣзҡ„ж—¶еҖҷпјҢHiveзҡ„并иЎҢи®Ўз®—жҳҫ然иғҪдҪ“зҺ°еҮәдјҳеҠҝгҖӮ
(8)еҸҜжү©еұ•жҖ§
з”ұдәҺHiveжҳҜе»әз«ӢеңЁHadoopд№ӢдёҠзҡ„пјҢеӣ жӯӨHiveзҡ„еҸҜжү©еұ•жҖ§жҳҜе’ҢHadoopзҡ„еҸҜжү©еұ•жҖ§жҳҜдёҖиҮҙзҡ„(дё–з•ҢдёҠжңҖеӨ§зҡ„HadoopйӣҶзҫӨеңЁYahoo!пјҢ2009е№ҙзҡ„规模еңЁ4000еҸ°иҠӮзӮ№е·ҰеҸі)гҖӮиҖҢж•°жҚ®еә“з”ұдәҺACIDиҜӯд№үзҡ„дёҘж јйҷҗеҲ¶пјҢжү©еұ•иЎҢйқһеёёжңүйҷҗгҖӮзӣ®еүҚжңҖе…Ҳиҝӣзҡ„并иЎҢж•°жҚ®еә“OracleеңЁзҗҶи®әдёҠзҡ„жү©еұ•иғҪеҠӣд№ҹеҸӘжңү100еҸ°е·ҰеҸігҖӮ
(9)ж•°жҚ®и§„жЁЎ
з”ұдәҺHiveе»әз«ӢеңЁйӣҶзҫӨдёҠ并еҸҜд»ҘеҲ©з”ЁMapReduceиҝӣиЎҢ并иЎҢи®Ўз®—пјҢеӣ жӯӨеҸҜд»Ҙж”ҜжҢҒеҫҲеӨ§и§„жЁЎзҡ„ж•°жҚ®;еҜ№еә”зҡ„пјҢж•°жҚ®еә“еҸҜд»Ҙж”ҜжҢҒзҡ„ж•°жҚ®и§„жЁЎиҫғе°ҸгҖӮ
Hbase
1.е®ҡд№ү
HBase – Hadoop DatabaseпјҢжҳҜдёҖдёӘй«ҳеҸҜйқ жҖ§гҖҒй«ҳжҖ§иғҪгҖҒйқўеҗ‘еҲ—гҖҒеҸҜдјёзј©зҡ„еҲҶеёғејҸеӯҳеӮЁзі»з»ҹпјҢеҲ©з”ЁHBaseжҠҖжңҜеҸҜеңЁе»үд»·PC ServerдёҠжҗӯе»әиө·еӨ§и§„жЁЎз»“жһ„еҢ–еӯҳеӮЁйӣҶзҫӨгҖӮ
HBaseжҳҜGoogle Bigtableзҡ„ејҖжәҗе®һзҺ°пјҢзұ»дјјGoogle BigtableеҲ©з”ЁGFSдҪңдёәе…¶ж–Ү件еӯҳеӮЁзі»з»ҹпјҢHBaseеҲ©з”ЁHadoop HDFSдҪңдёәе…¶ж–Ү件еӯҳеӮЁзі»з»ҹ;
GoogleиҝҗиЎҢMapReduceжқҘеӨ„зҗҶBigtableдёӯзҡ„жө·йҮҸж•°жҚ®пјҢHBaseеҗҢж ·еҲ©з”ЁHadoop MapReduceжқҘеӨ„зҗҶHBaseдёӯзҡ„жө·йҮҸж•°жҚ®;
Google BigtableеҲ©з”Ё ChubbyдҪңдёәеҚҸеҗҢжңҚеҠЎпјҢHBaseеҲ©з”ЁZookeeperдҪңдёәеҚҸеҗҢжңҚеҠЎгҖӮ
2.з»„жҲҗ
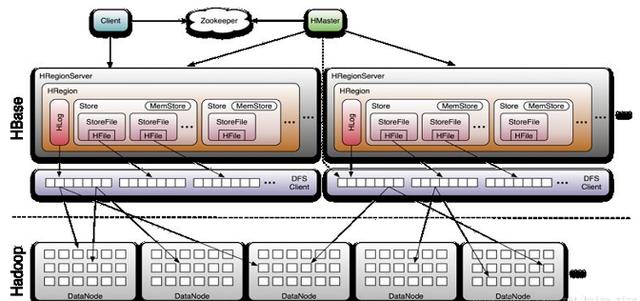
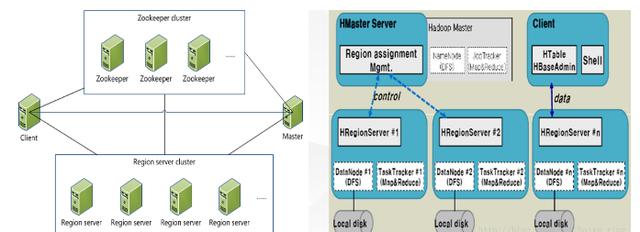
еҲҶжһҗпјҡд»ҺдёҠеӣҫеҸҜд»ҘзңӢеҮәпјҡHbaseдё»иҰҒз”ұClientгҖҒZookeeperгҖҒHMasterе’ҢHRegionServerз»„жҲҗпјҢз”ұHstoreдҪңеӯҳеӮЁзі»з»ҹгҖӮ
Client
HBase ClientдҪҝз”ЁHBaseзҡ„RPCжңәеҲ¶дёҺHMasterе’ҢHRegionServerиҝӣиЎҢйҖҡдҝЎпјҢеҜ№дәҺз®ЎзҗҶзұ»ж“ҚдҪңпјҢClientдёҺ HMasterиҝӣиЎҢRPC;еҜ№дәҺж•°жҚ®иҜ»еҶҷзұ»ж“ҚдҪңпјҢClientдёҺHRegionServerиҝӣиЎҢRPC
Zookeeper
Zookeeper Quorum дёӯйҷӨдәҶеӯҳеӮЁдәҶ -ROOT- иЎЁзҡ„ең°еқҖе’Ң HMaster зҡ„ең°еқҖпјҢHRegionServer д№ҹдјҡжҠҠиҮӘе·ұд»Ҙ Ephemeral ж–№ејҸжіЁеҶҢеҲ° Zookeeper дёӯпјҢдҪҝеҫ— HMaster еҸҜд»ҘйҡҸж—¶ж„ҹзҹҘеҲ°еҗ„дёӘHRegionServer зҡ„еҒҘеә·зҠ¶жҖҒгҖӮ
HMaster
HMaster жІЎжңүеҚ•зӮ№й—®йўҳпјҢHBase дёӯеҸҜд»ҘеҗҜеҠЁеӨҡдёӘ HMaster пјҢйҖҡиҝҮ Zookeeper зҡ„ Master Election жңәеҲ¶дҝқиҜҒжҖ»жңүдёҖдёӘ Master иҝҗиЎҢпјҢHMaster еңЁеҠҹиғҪдёҠдё»иҰҒиҙҹиҙЈ Tableе’ҢRegionзҡ„з®ЎзҗҶе·ҘдҪңпјҡ
з®ЎзҗҶз”ЁжҲ·еҜ№ Table зҡ„еўһгҖҒеҲ гҖҒж”№гҖҒжҹҘж“ҚдҪң
з®ЎзҗҶ HRegionServer зҡ„иҙҹиҪҪеқҮиЎЎпјҢи°ғж•ҙ Region еҲҶеёғ
еңЁ Region Split еҗҺпјҢиҙҹиҙЈж–° Region зҡ„еҲҶй…Қ
еңЁ HRegionServer еҒңжңәеҗҺпјҢиҙҹиҙЈеӨұж•Ҳ HRegionServer дёҠзҡ„ Regions иҝҒ移
HStoreеӯҳеӮЁжҳҜHBaseеӯҳеӮЁзҡ„ж ёеҝғдәҶпјҢе…¶дёӯз”ұдёӨйғЁеҲҶз»„жҲҗпјҢдёҖйғЁеҲҶжҳҜMemStoreпјҢдёҖйғЁеҲҶжҳҜStoreFilesгҖӮ
MemStoreжҳҜSorted Memory BufferпјҢз”ЁжҲ·еҶҷе…Ҙзҡ„ж•°жҚ®йҰ–е…Ҳдјҡж”ҫе…ҘMemStoreпјҢеҪ“MemStoreж»ЎдәҶд»ҘеҗҺдјҡFlushжҲҗдёҖдёӘStoreFile(еә•еұӮе®һзҺ°жҳҜHFile)пјҢ еҪ“StoreFileж–Ү件数йҮҸеўһй•ҝеҲ°дёҖе®ҡйҳҲеҖјпјҢдјҡи§ҰеҸ‘CompactеҗҲ并ж“ҚдҪңпјҢе°ҶеӨҡдёӘ StoreFiles еҗҲ并жҲҗдёҖдёӘ StoreFileпјҢеҗҲ并иҝҮзЁӢдёӯдјҡиҝӣиЎҢзүҲжң¬еҗҲ并е’Ңж•°жҚ®еҲ йҷӨгҖӮ
еӣ жӯӨеҸҜд»ҘзңӢеҮәHBaseе…¶е®һеҸӘжңүеўһеҠ ж•°жҚ®пјҢжүҖжңүзҡ„жӣҙж–°е’ҢеҲ йҷӨж“ҚдҪңйғҪжҳҜеңЁеҗҺз»ӯзҡ„ compact иҝҮзЁӢдёӯиҝӣиЎҢзҡ„пјҢиҝҷдҪҝеҫ—з”ЁжҲ·зҡ„еҶҷж“ҚдҪңеҸӘиҰҒиҝӣе…ҘеҶ…еӯҳдёӯе°ұеҸҜд»Ҙз«ӢеҚіиҝ”еӣһпјҢдҝқиҜҒдәҶ HBase I/O зҡ„й«ҳжҖ§иғҪгҖӮ
еҪ“StoreFiles CompactеҗҺпјҢдјҡйҖҗжӯҘеҪўжҲҗи¶ҠжқҘи¶ҠеӨ§зҡ„StoreFileпјҢеҪ“еҚ•дёӘ StoreFile еӨ§е°Ҹи¶…иҝҮдёҖе®ҡйҳҲеҖјеҗҺпјҢдјҡи§ҰеҸ‘Splitж“ҚдҪңпјҢеҗҢж—¶жҠҠеҪ“еүҚ Region SplitжҲҗ2дёӘRegionпјҢзҲ¶ RegionдјҡдёӢзәҝпјҢж–°SplitеҮәзҡ„2дёӘеӯ©еӯҗRegionдјҡиў«HMasterеҲҶй…ҚеҲ°зӣёеә”зҡ„HRegionServer дёҠпјҢдҪҝеҫ—еҺҹе…Ҳ1дёӘRegionзҡ„еҺӢеҠӣеҫ—д»ҘеҲҶжөҒеҲ°2дёӘRegionдёҠгҖӮ
дёүгҖҒHadoopзҡ„еә”з”Ёе®һдҫӢ
1.еӣһйЎҫHadoopзҡ„ж•ҙдҪ“жһ¶жһ„
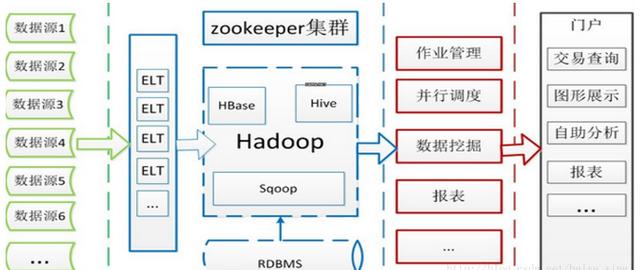
2.Hadoopзҡ„еә”з”Ё——жөҒйҮҸжҹҘиҜўзі»з»ҹ
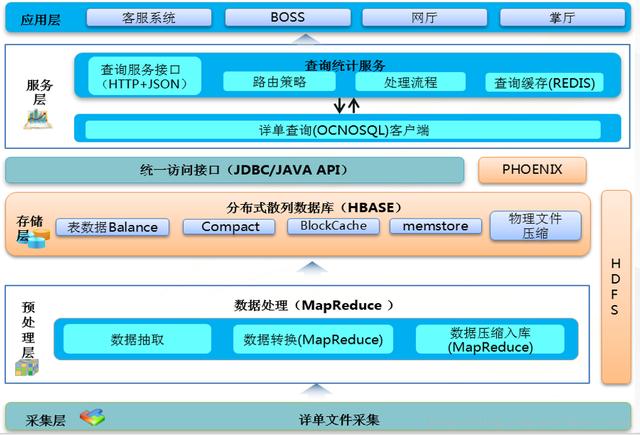
(1)жөҒйҮҸжҹҘиҜўзі»з»ҹжҖ»дҪ“жЎҶжһ¶
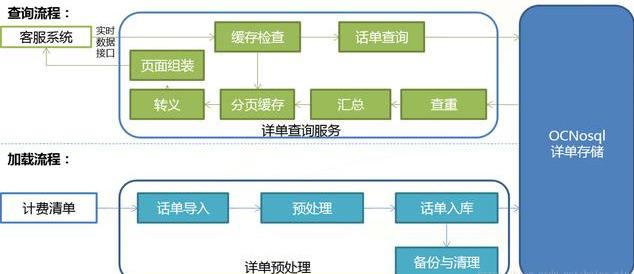
(2)жөҒйҮҸжҹҘиҜўзі»з»ҹжҖ»дҪ“жөҒзЁӢ
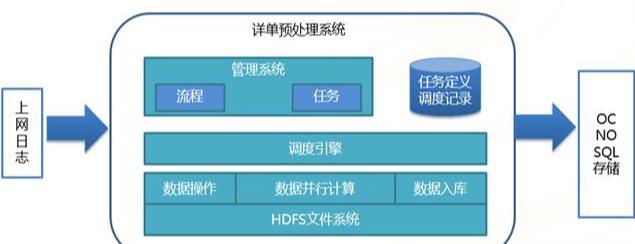
(3)жөҒйҮҸжҹҘиҜўзі»з»ҹж•°жҚ®йў„еӨ„зҗҶеҠҹиғҪжЎҶжһ¶
(4)жөҒйҮҸжҹҘиҜўзі»з»ҹж•°жҚ®йў„еӨ„зҗҶжөҒзЁӢ
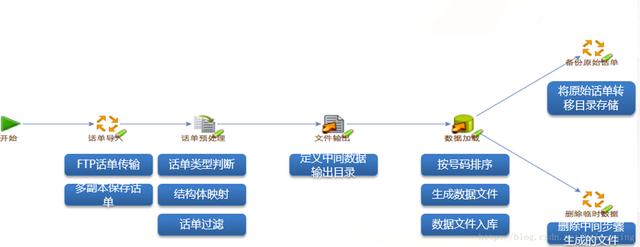
(5)жөҒйҮҸжҹҘиҜўNoSQLж•°жҚ®еә“еҠҹиғҪжЎҶжһ¶
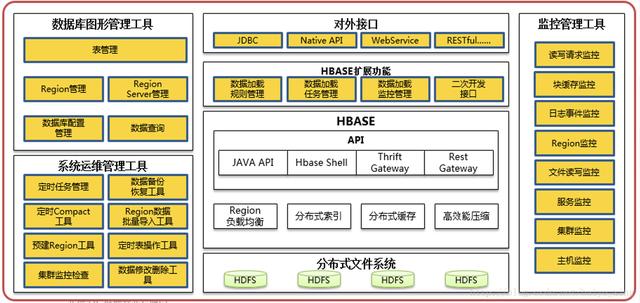
(6)жөҒйҮҸжҹҘиҜўжңҚеҠЎеҠҹиғҪжЎҶжһ¶
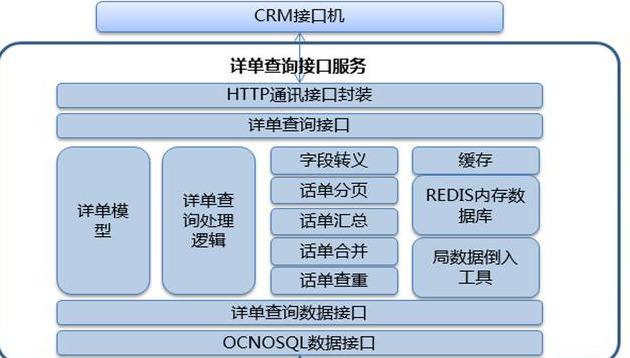
(7)е®һж—¶жөҒи®Ўз®—ж•°жҚ®еӨ„зҗҶжөҒзЁӢеӣҫ
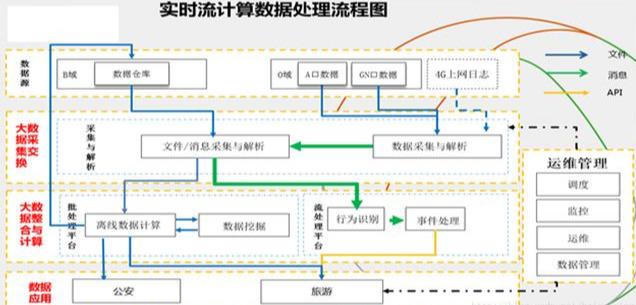
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңHadoopжһ¶жһ„еҺҹзҗҶжҖҺд№ҲзҗҶи§ЈвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ