жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ

Aе…¬еҸёдё“жіЁдёәеҗ„з§Қ规模е’ҢеӨҚжқӮзЁӢеәҰзҡ„йҮ‘иһҚжҠ•иө„жңәжһ„жҸҗдҫӣдёҖдҪ“еҢ–жҠ•иө„з®ЎзҗҶзі»з»ҹпјҢзі»з»ҹдё»иҰҒз”ұжҠ•иө„з»„еҗҲз®ЎзҗҶгҖҒдәӨжҳ“жү§иЎҢз®ЎзҗҶгҖҒе®һж—¶зӣ‘жҺ§з®ЎзҗҶгҖҒйЈҺйҷ©з®ЎзҗҶзӯүеҠҹиғҪжЁЎеқ—жһ„жҲҗгҖӮйҡҸзқҖдјҒдёҡз®ЎзҗҶдә§е“Ғж•°йҮҸзҡ„дёҚж–ӯеўһеӨҡпјҢеӨ§йҮҸж•°жҚ®еҲҶж•ЈеңЁеҗ„еҲёе•Ҷзі»з»ҹдёӯдё”ж•°жҚ®еӯҳеӮЁж јејҸеҗ„ејӮпјҢйҡҫд»Ҙз®ЎзҗҶе’ҢеҲ©з”ЁгҖӮ
дёәеё®еҠ©жҠ•иө„жңәжһ„жңҖеӨ§йҷҗеәҰең°жҸҗй«ҳжҠ•иө„еҶізӯ–е’ҢиҝҗиҗҘж•ҲзҺҮпјҢAе…¬еҸёйңҖиҰҒе®һж—¶зӣ‘жҺ§иҮӘе·ұзҡ„з”ЁжҲ·еңЁеҗ„дёӘдәӨжҳ“е№іеҸ°зҡ„еҹәжң¬дҝЎжҒҜгҖҒдҪҷйўқгҖҒи®ўеҚ•дәӨжҳ“жғ…еҶөпјҢе№¶ж №жҚ®еҲҶжһҗз»“жһңеҸҠж—¶з»ҷеҮәжҠ•иө„е»әи®®гҖӮ
Aе…¬еҸёзҡ„иҝҷз§Қжғ…еҶө并дёҚжҳҜдёӘдҫӢгҖӮзӣ®еүҚпјҢи¶ҠжқҘи¶ҠеӨҡзҡ„дјҒдёҡеңЁж•°жҚ®дј иҫ“зҡ„йңҖжұӮеңәжҷҜдёӯпјҢйҷӨдәҶд»ҺдёҠжёёдёҚеҗҢдёҡеҠЎж•°жҚ®еә“дёӯе®һж—¶гҖҒе®ҡж—¶еҲҶй…ҚеҲ°дёӢжёёзі»з»ҹд№ӢеӨ–пјҢиҝҳжңүи®ёеӨҡйңҖжұӮеңәжҷҜйңҖиҰҒд»ҺеӨ–йғЁеҗҲдҪңе•ҶгҖҒдҫӣеә”е•ҶдёӯиҺ·еҸ–дёҡеҠЎж•°жҚ®гҖӮ
еҰӮжһңжғіиҰҒжҜҸеӨ©д»ҺдјҒдёҡеӨ–йғЁзі»з»ҹдёӯиҺ·еҸ–ж•°жҚ®пјҢйҖҡеёёдјҡйҮҮз”Ёд»Җд№Ҳж–№жі•е‘ўпјҹ
дёҖдәӣз”ЁжҲ·з»ҷеҮәзҡ„зӯ”жЎҲжҳҜпјҡж №жҚ®йңҖиҰҒзј–еҶҷдёҚеҗҢзҡ„и„ҡжң¬пјҢжүӢеҠЁи°ғ用第дёүж–№зі»з»ҹжҸҗдҫӣзҡ„APIжҺҘеҸЈпјҢеңЁжҠ“еҸ–ж•°жҚ®еҗҺпјҢиҮӘиЎҢзј–еҶҷжё…жҙ—йҖ»иҫ‘пјҢжңҖеҗҺе®һзҺ°ж•°жҚ®иҗҪең°гҖӮ
然иҖҢйҡҸзқҖ第дёүж–№зі»з»ҹзҡ„ж—ҘзӣҠеўһеӨҡпјҢеҰӮжһңжҢүеҺҹжңүж–№ејҸдјҡеёҰжқҘиҝҮеӨҡзҡ„и„ҡжң¬з»ҙжҠӨжҲҗжң¬е’Ңж•°жҚ®дј иҫ“д»»еҠЎз®ЎзҗҶжҲҗжң¬гҖӮдёәи§ЈеҶідёҠиҝ°з—ӣзӮ№пјҢDataPipelineеңЁж–°зүҲжң¬зҡ„ж•°жҚ®еҗҢжӯҘд»»еҠЎдёӯеўһеҠ дәҶгҖҢиҮӘе®ҡд№үж•°жҚ®жәҗгҖҚеҠҹиғҪпјҢз”ЁжҲ·еҸҜд»ҘйҖҡиҝҮдёҠдј JARеҢ…зҡ„ж–№ејҸиҮӘе®ҡд№үиҺ·еҸ–ж•°жҚ®йҖ»иҫ‘гҖӮж–°еҠҹиғҪж”ҜжҢҒд»»ж„Ҹзҡ„MySQLгҖҒOracleгҖҒSQLServerгҖҒHiveгҖҒHBaseзӯүеёёи§Ғж•°жҚ®жәҗпјҢеҶ·й—Ёж•°жҚ®еә“зӯүпјҲеҰӮи…ҫи®Ҝдә‘TDSQLпјүпјҢеёёз”Ёзҡ„APIи°ғз”ЁпјҢз”ЁжҲ·иҮӘе®ҡд№үзҡ„SDKпјҢжҲ–иҖ…йҖҡиҝҮPythonжҠ“еҸ–ж•°жҚ®зӯүгҖӮ
дёҖгҖҒгҖҢиҮӘе®ҡд№үж•°жҚ®жәҗгҖҚжҸҗдҫӣзҡ„д»·еҖј
1 йҖҡиҝҮгҖҢиҮӘе®ҡд№үж•°жҚ®жәҗгҖҚпјҢз”ЁжҲ·еҸҜд»Ҙпјҡ
з»ҹдёҖз®ЎзҗҶж•°жҚ®иҺ·еҸ–йҖ»иҫ‘пјҢеҝ«йҖҹеҗҲ并JARеҮҸе°‘и„ҡжң¬ејҖеҸ‘йҮҸгҖӮ
еҪ“дёҠжёёеҸ‘з”ҹеҸҳеҢ–ж—¶пјҢдёҚйңҖиҰҒеҜ№жҜҸдёҖдёӘж•°жҚ®дј иҫ“д»»еҠЎиҝӣиЎҢи°ғж•ҙгҖӮ
2 еҰӮдҪ•дҪҝз”ЁгҖҢиҮӘе®ҡд№үж•°жҚ®жәҗгҖҚеҠҹиғҪ
з”ЁжҲ·еҸҜйҖҡиҝҮд»ҘдёӢеӣӣжӯҘдҪҝз”ЁгҖҢиҮӘе®ҡд№үж•°жҚ®жәҗгҖҚеҠҹиғҪпјҡ
еҲӣе»әиҮӘе®ҡд№үж•°жҚ®жәҗпјҢ并дёҠдј JARеҢ…пјҲжҲ–и°ғеҸ–е·ІдёҠдј иҝҮзҡ„JARеҢ…пјүгҖӮ
йҖүжӢ©ж•°жҚ®еӯҳж”ҫзҡ„зӣ®зҡ„ең°гҖӮ
дҪҝз”Ёжё…жҙ—е·Ҙе…·е®ҢжҲҗж•°жҚ®и§ЈжһҗйҖ»иҫ‘гҖӮ
3 е…ідәҺгҖҢиҮӘе®ҡд№үж•°жҚ®жәҗгҖҚзҡ„ж ёеҝғйЎөйқўпјҡ
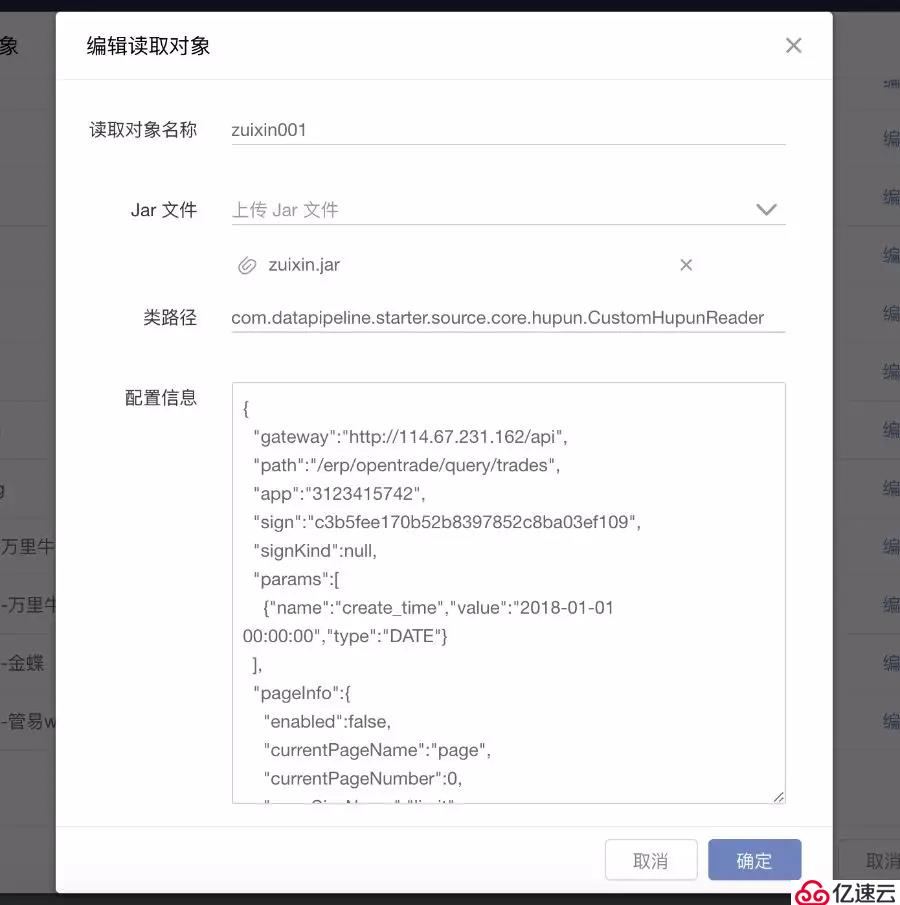
пјҲ1пјүз”ЁжҲ·еңЁйҖүжӢ©иҮӘе®ҡд№үж•°жҚ®жәҗе’Ңзӣ®зҡ„ең°еҗҺпјҢйңҖиҰҒеңЁиҜ»еҸ–и®ҫзҪ®жӯҘйӘӨдёӯдёҠдј JARеҢ…
з”ЁжҲ·еҸҜд»ҘдёҠдј ж–°зҡ„JARеҢ…пјҢд№ҹеҸҜд»ҘзӮ№еҮ»жӢ–ж”ҫжЎҶйҖүжӢ©еҺҶеҸІе·Із»ҸдёҠдј зҡ„JARз”ЁдҪңжң¬ж¬Ўд»»еҠЎгҖӮ
пјҲ2пјү з”ЁжҲ·еҸҜд»ҘеңЁдёҖдёӘд»»еҠЎдёӯйҖүжӢ©дёҖдёӘжҲ–еӨҡдёӘиҜ»еҸ–еҜ№иұЎпјҢжҜҸдёӘиҜ»еҸ–еҜ№иұЎеҸҜд»Ҙжҳ е°„еҲ°зӣ®ж ҮиЎЁзҡ„иЎЁдёӯ

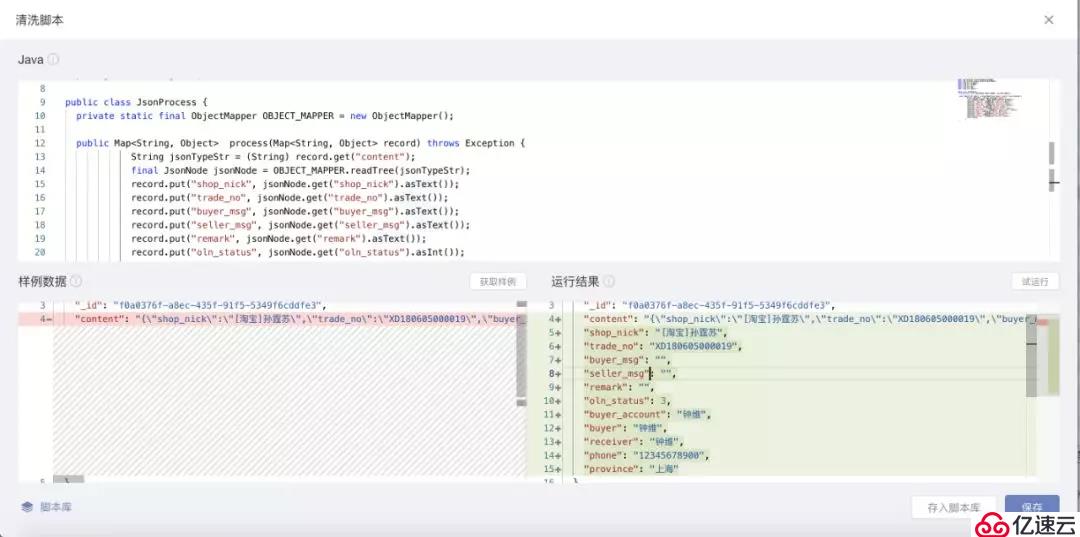
пјҲ3пјүе®ҢжҲҗиҜ»еҸ–и®ҫзҪ®еҗҺпјҢеңЁеҶҷе…Ҙи®ҫзҪ®жӯҘйӘӨдёӯе…ҲзЎ®е®ҡжҜҸдёӘиҜ»еҸ–еҜ№иұЎзҡ„ж•°жҚ®и§ЈжһҗйҖ»иҫ‘
DataPipelineдјҡжҸҗдҫӣJSONи§Јжһҗж ·дҫӢпјҢз”ЁжҲ·д№ҹеҸҜд»ҘеҸӮиҖғж ·дҫӢпјҢиҮӘе®ҡд№үи§ЈжһҗйҖ»иҫ‘гҖӮ
гҖҢж ·дҫӢж•°жҚ®гҖҚжЁЎеқ—дјҡжҳҫзӨәйҖҡиҝҮиҜ»еҸ–еҜ№иұЎй…ҚзҪ®иҺ·еҸ–зҡ„ж•°жҚ®гҖӮ
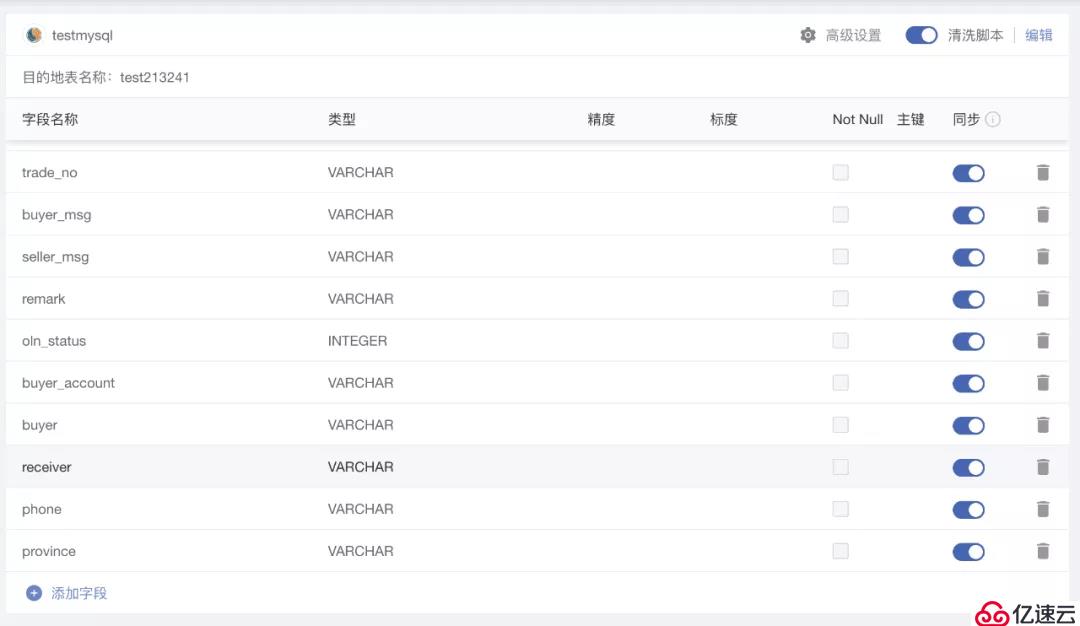
4 е®ҢжҲҗи§ЈжһҗйҖ»иҫ‘еҗҺпјҢз”ЁжҲ·еҸҜд»ҘжүӢеҠЁж·»еҠ еҗҚ称并йҖүжӢ©еҜ№еә”зҡ„ж•°жҚ®зұ»еһӢ пјҢжқҘе®ҢжҲҗзӣ®зҡ„ең°иЎЁз»“жһ„
DataPipelineжҜҸдёҖж¬ЎзүҲжң¬зҡ„иҝӯд»ЈйғҪеҮқиҒҡдәҶеӣўйҳҹеҜ№дјҒдёҡж•°жҚ®дҪҝз”ЁйңҖжұӮзҡ„ж·ұе…ҘжҖқзҙўпјҢе…¶е®ғж–°еҠҹиғҪиҝҳеңЁи·ҜдёҠпјҢеҫҲеҝ«е°ұдјҡи·ҹеӨ§е®¶и§ҒйқўдәҶпјҢеёҢжңӣиғҪеӨҹеҲҮе®һеё®еҠ©еӨ§е®¶жӣҙж•ҸжҚ·й«ҳж•Ҳең°иҺ·еҸ–ж•°жҚ®гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ